

Amazon EKSロードバランサー構成の大幅変更 | Kubernetesアップデートストーリー第3話
SREK8sMay 26, 2022
こんにちは、技術戦略部 SREグループのカンタンです。
本記事はKubernetesアップデートストーリーシリーズの第3話になっていて、ロードバランサーの構成を大幅に変更した話になります。是非第1話から読んでいただいたほうが背景と内容がわかりやすくなるかと思います!
Kubernetesアップデートストーリーシリーズのまとめ
- 数年をかけたKubernetes環境の大幅アップデート | Kubernetesアップデートストーリー第1話
- Kubernetes v1.10からv1.21へのアップデート | Kubernetesアップデートストーリー第2話
- Amazon EKSロードバランサー構成の大幅変更 | Kubernetesアップデートストーリー第3話
- 数時間でIstio v1.2からv1.13へアップデート | Kubernetesアップデートストーリー第4話
- Helm v2からv3へのメジャーアップデート | Kubernetesアップデートストーリー第5話
本記事では以下の課題についてお話しします:
- Amazon EKSでCLBよりALBを使った方がいい理由
- Pod作成と削除時のALBの具体的な挙動とスポットインスタンスとの相性の問題
- Gatewayレイヤーを設けることでALBの挙動を隠蔽してスポットインスタンスを安全に利用できること
- Istioを利用する際のhttpエンドポイントとgRPCエンドポイントの提供方法
課題
Azure AKS、Amazon EKS、GKEを運用してみて、外部向けのロードバランサーがKubernetesの一番大変な部分だと思っています。Kubernetesの中の世界になると、どのクラウドサービスでも大体同様に動いていて差分をあまり感じないですが、ロードバランサーだけは挙動が異なって対応が大変という経験があります。
CLBよりALB!
Amazon EKSに関しては、Kubernetesの LoadBalancer タイプの Serviceを使わないほうがいいという結論に至りました。これを使うとClassic Load Balancer (CLB)が作成され、ノードにNodePortが開かれ、ノードのEC2インスタンスがCLBに登録されます。通信は直接Podに流したいですがLBに登録されるのがノードですので、Podが動いていないノードに通信が流れたり、ノード削除時にリクエストが失敗したりするなど、様々な不具合の原因になってしまいます。例えばexternalTrafficPolicy=Local 設定にするとアプリケーションデプロイ時にPodが別のノードにスケジュールされるとリクエストが失敗して、externalTrafficPolicy=Cluster 設定にするとノードスケールイン時に途中のリクエストが502で失敗することもあります。
そのため、Serviceタイプを ClusterIP にして、AWS Load Balancer Controllerをインストールして Ingress 設定でPodにリクエストを転送したほうが良いと考えています。この場合、Application Load Balancerが作成され、IPモードで通信するようにIngressを設定すると、ターゲットPodのIPがALBに直接登録されます。AWS Load Balancer ControllerがターゲットPodを監視して、新しいPodをALBに登録したり削除されるPodの登録を解除したりしてくれています。ALBからのヘルスチェックも実際のリクエストもPodのIPに直接流れるため、ノードのスケールインなどを意識する必要がなくなり、ノードのメンテナンス作業も楽になります。Pod Readiness Gate機能を使うことで、デプロイ時に新しいPodのALB登録が完了するまで古いPodが削除されないことが保証されるため、ALBへの登録状況と関係なくデプロイが勝手に進むことがなく、アプリケーションを安全にデプロイすることができます。
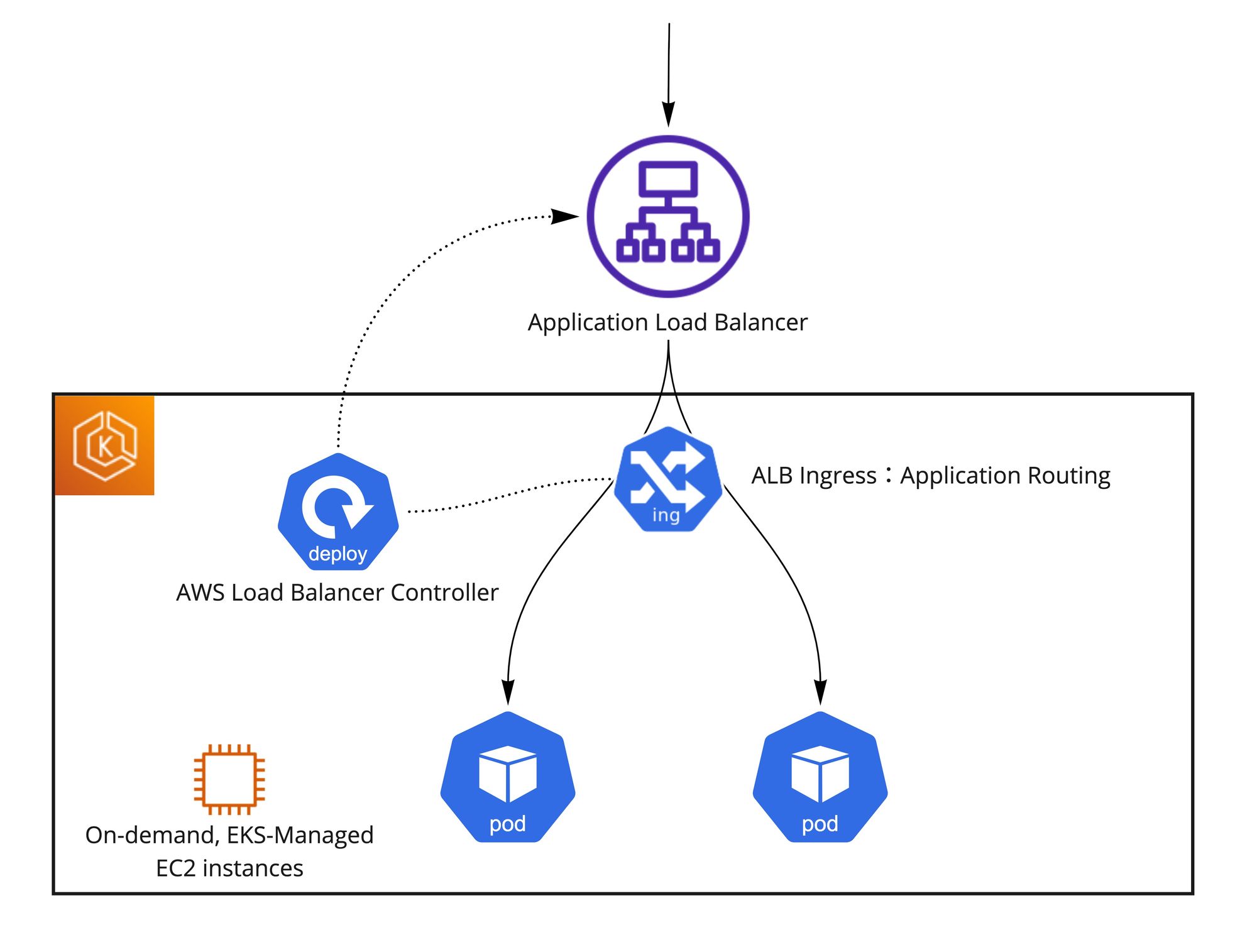
ALBの具体的な挙動と懸念
この構成はシンプルでいいのですが、実際に試すとALBが以下の挙動をしていることがわかります。
Pod登録時の挙動
- 新しいPodが作成される
- PodがRunning状態になる
- AWS Load Balancer ControllerがPodのIPをALBに登録する —> 数秒以内
- ALBがPodのIPにヘルスチェックを送る
- ヘルスチェックが通ると、登録が完了する —> 設定次第、数秒〜数十秒以内
- 通信がPodに流れる —> 数秒以内
Pod登録解除時の挙動
- PodがTerminating状態になる
- AWS Load Balancer ControllerがPod IPのALB登録解除を開始する —> 数秒以内
- Pod IPの登録がDraining状態になる
- Draining状態にも関わらず、十数秒〜数十秒ぐらい新しいリクエストがALBからPod IPに流れていく
- 新しいリクエストがPod IPに流れなくなって、処理中のリクエストだけがまだ残っている
- ALB登録解除が完了する
- Podが終了する
Kubernetesのネットワークをそのまま使う場合、PodがRunning状態になった途端にリクエストが流れ始めて、PodがTerminating状態になった途端に新しいリクエストが流れなくなりますが、AWS Load Balancer ControllerでALBのヘルスチェックとDrainingの仕組みが入ることで、数十秒の時差が発生することがわかりました。運用してみて、AWS Load Balancer Controllerの反応自体はとても早くてあまり気にならないのですが、ヘルスチェックとDrainingの仕組みで時間がかなりかかっています。特に上記に記載した「Pod登録解除時の挙動」のステップ4がボトルネックになっていて、Draining状態にも関わらず新しいリクエストが流れ続けるため、コンテナを停止する前に30秒待つようにPodにPreStopフックを設定する必要がありました。また、ALB登録解除が完了する前にPodが強制的に終了されないように、Podに比較的に長い2分程度のterminationGracePeriodSecondsを設定する必要がありました。
一方、コスト削減のためスポットインスタンスも利用していますが、スポットインスタンスはいつでも中断される可能性があるため、AWS Load Balancer ControllerとALBに完全にマッチしないところがあります。スポットインスタンス中断の2分前に中断通知が来て、EKSマネージドノードグループが新しいノードを作成して中断されるノードのPodを動かしてくれます。しかし、上記のALBの挙動によってPodの終了に時間がかかる場合があり、同じDeploymentの複数Podが同じノードで動いていると、全てのPodが正常に終了する前にインスタンスが中断されてリクエストが失敗する可能性があります。スポットインスタンスを使う以上、ALBの利用と関係なくそのリスクは存在するものの、ALBを使うことでそのリスクがそれなりに上がるということがわかりました。
ALBが利用するヘルスチェック情報をIngressに指定する必要がある関係で、コンテナのヘルスチェックパスを変えたり、例えばhttpとgRPC両方のプロトコルを受けられるようにしたりしたい時、Deploymentの設定だけではなくてIngressの設定も意識する必要が出てきます。Kubernetesをそのまま使う場合Podの状態判定の仕組みとロードバランシングの仕組みが分かれているため、たとえばコンテナのヘルスチェック方法(プローブ)を変更するようにDeploymentの定義を変更してもIngressやロードバランサーの設定を変更する必要がありません。プローブさえ通ればPodがRunning状態になってリクエストを受けられるようになります。ALBを使うとDeploymentとIngressに強い依存関係があって、Deploymentの定義変更で想定外な影響が出てくる可能性があるため十分な注意が必要です。
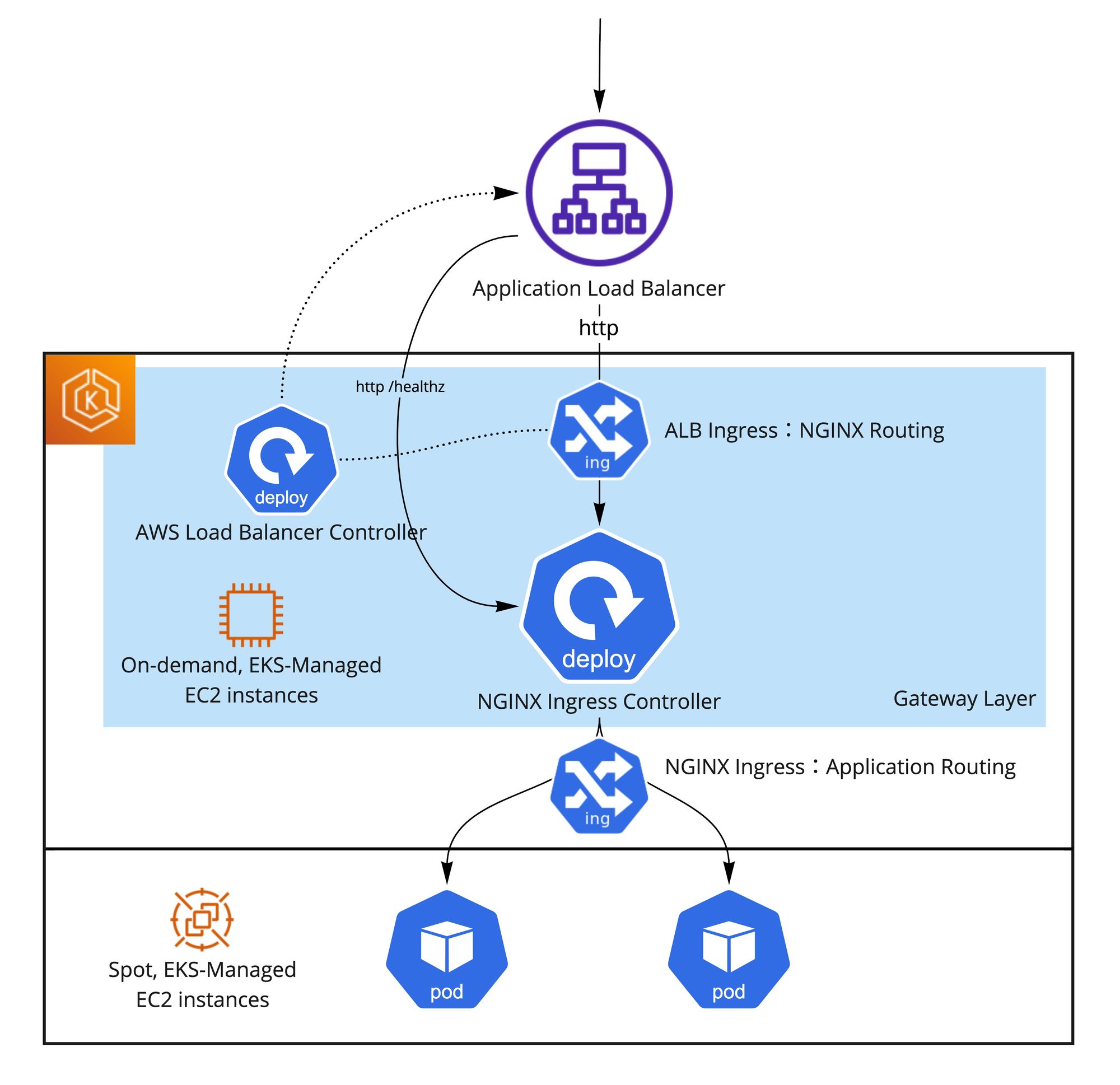
Gatewayレイヤー を設けてクラウドサービス固有の特性を隠蔽する
IP制限、CORS設定、カナリアリリースなど、アプリケーション実装の負担を軽減するためにインフラレイヤーに持っていきたい機能があることと、上記のALBの挙動とスポットインスタンスの挙動もあって、ALBにアプリケーションPodを直接登録せずGatewayレイヤーを挟むことにしました。元々CLBを利用していた時にL7ルーティングを行うために使っていたNGINX Ingress Controller構成をそのまま使えるというメリットも大きかったです。
GatewayレイヤーでNGINX Ingress Controllerを動かすと、ALBに直接登録するのはNGINX Ingress ControllerのPodのみになります。そしてアプリケーションPodへのルーティングとCORS設定やIP制限などはNGINX Ingress Controller側で行うようにしています。NGINX Ingress ControllerをALBに登録するためのIngressと、アプリケーションPodをNGINXに登録するためのIngressという2種類のIngressリソースを定義しています。NGINX Ingress ControllerのDeploymentとALB用のIngressの初期構築を行えば、その後変更することは基本的になくミスが起きづらいです。逆にNGINX Ingress ControllerがKubernetesのPod状態を監視しているためヘルスチェックなどを気にせずにアプリケーションのPod定義を自由に変更できるようになっています。さらに、ALBと直接紐づいているNGINX Ingress ControllerのPodをオンデマンドインスタンスで動かすことで、ALBによるPod終了時間延長でPodが強制終了されることを防げます。ALBに直接紐づいていないアプリケーションPodは安全にスポットインスタンスに動かすことができ、スポットインスタンスのメリットを得られます。
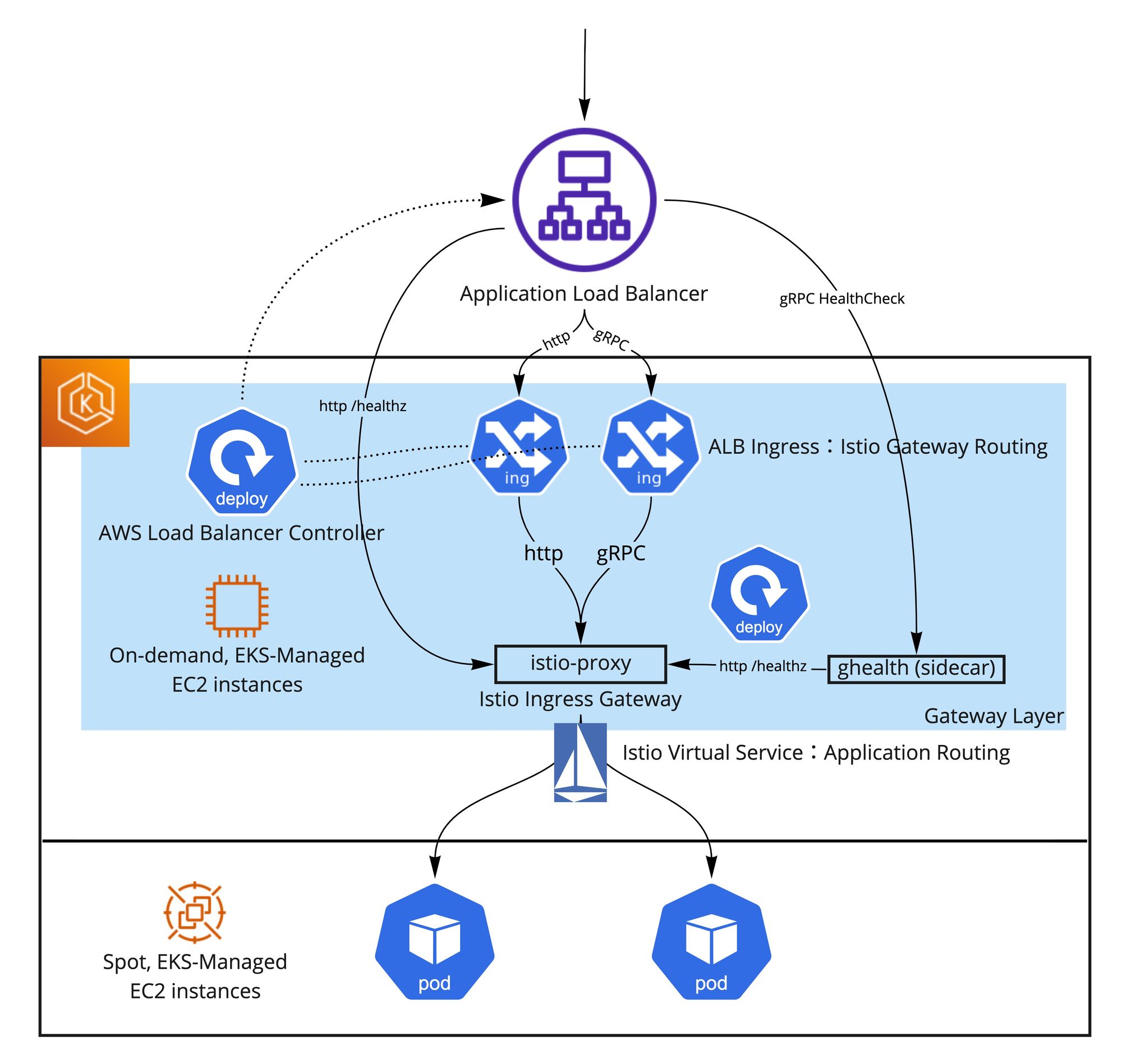
Istio Ingress GatewayによるgRPC外部エンドポイントの提供方法
Pod間のgRPC通信のロードバランシングを実現するため、以前からIstioサービスメッシュをクラスターに導入しています。Pod間の通信に関しては特に問題ないのですが、gRPCサービスの外部エンドポイントを作るには工夫が必要でした。まずここでも先ほど説明した理由により、ALBにgRPCサービスのPodを直接登録せずに、Gatewayレイヤーを挟むことにしました。実現方法として、NGINX Ingress Controllerのバージョンが古かったこととIstioを既に使っていたこともあって、NGINX Ingress ControllerではなくてIstio Ingress GatewayでgRPC通信を受けるようにしています。またIstio Ingress GatewayでgRPCだけではなくて、httpも受けられるようにしたかったため少し複雑な構成にする必要がありました。
具体的に、以下の工夫を凝らしました:
- http通信用のTargetGroupとgRPC通信用のTargetGroupを作るように、http用のIngressとgRPC用のIngressを用意した
- ALBのgRPC TargetGroupのためにgRPCのヘルスチェックが必要でしたがIstio Ingress Gatewayのistio-proxyコンテナがhttpのヘルスチェックしか設けていないため、gRPCヘルスチェックを提供してリクエストをhttpヘルスチェックに転送するsidecarコンテナを自分で用意した (以下ghealthと呼ぶ)
http用のIngressリソースを以下のように設定しています
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
alb.ingress.kubernetes.io/backend-protocol-version: HTTP1
alb.ingress.kubernetes.io/certificate-arn: redacted
alb.ingress.kubernetes.io/group.name: istio-ingressgateway
alb.ingress.kubernetes.io/group.order: "200"
alb.ingress.kubernetes.io/healthcheck-interval-seconds: "10"
alb.ingress.kubernetes.io/healthcheck-path: /healthz/ready
alb.ingress.kubernetes.io/healthcheck-port: "15021"
alb.ingress.kubernetes.io/healthcheck-protocol: HTTP
alb.ingress.kubernetes.io/healthcheck-timeout-seconds: "5"
alb.ingress.kubernetes.io/healthy-threshold-count: "2"
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}]'
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/success-codes: "200"
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/unhealthy-threshold-count: "2"
kubernetes.io/ingress.class: alb
name: istio-system-alb-istio-ingress-gateway-http
namespace: istio-system
spec:
rules:
- http:
paths:
- backend:
service:
name: istio-ingressgateway
port:
number: 80
path: /*
pathType: ImplementationSpecificgRPC用のIngressリソースを以下のように設定しています。http用のIngressより優先順位が高く、 /motpb.* と /grpc.* パスだけが対象になります。MoTで作っている全てのProtocol Buffersのパッケージ名は/motpb.* から始めるようにしています。
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
alb.ingress.kubernetes.io/backend-protocol-version: GRPC
alb.ingress.kubernetes.io/certificate-arn: redacted
alb.ingress.kubernetes.io/group.name: istio-ingressgateway
alb.ingress.kubernetes.io/group.order: "100"
alb.ingress.kubernetes.io/healthcheck-interval-seconds: "10"
alb.ingress.kubernetes.io/healthcheck-path: /grpc.health.v1.Health/Check
alb.ingress.kubernetes.io/healthcheck-port: "25021"
alb.ingress.kubernetes.io/healthcheck-protocol: HTTP
alb.ingress.kubernetes.io/healthcheck-timeout-seconds: "5"
alb.ingress.kubernetes.io/healthy-threshold-count: "2"
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}]'
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/success-codes: "0"
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/unhealthy-threshold-count: "2"
kubernetes.io/ingress.class: alb
name: istio-system-alb-istio-ingress-gateway-grpc
namespace: istio-system
spec:
rules:
- http:
paths:
- backend:
service:
name: istio-ingressgateway
port:
number: 80
path: /motpb.*
pathType: ImplementationSpecific
- backend:
service:
name: istio-ingressgateway
port:
number: 80
path: /grpc.*
pathType: ImplementationSpecificgRPCヘルスチェックを提供してリクエストをhttpヘルスチェックに転送するghealthはGoのプログラムで、以下のイメージで実装しています
package main
import (
"context"
"fmt"
"net"
"net/http"
"google.golang.org/grpc"
"google.golang.org/grpc/codes"
healthpb "google.golang.org/grpc/health/grpc_health_v1"
"google.golang.org/grpc/reflection"
"google.golang.org/grpc/status"
)
const serverPort = "25021"
const httpHealthCheckURL = "http://localhost:15021/healthz/ready"
func main() {
listen, err := net.Listen("tcp", ":"+serverPort)
if err != nil {
panic(err)
}
// Setup
s := &Server{
server: grpc.NewServer(),
}
healthpb.RegisterHealthServer(s.server, s)
reflection.Register(s.server)
if err := s.server.Serve(listen); err != nil {
panic(err)
}
}
type Server struct {
healthpb.UnimplementedHealthServer
server *grpc.Server
}
func (s *Server) Check(ctx context.Context, in *healthpb.HealthCheckRequest) (*healthpb.HealthCheckResponse, error) {
// prepare HTTP request
req, _ := http.NewRequest("GET", httpHealthCheckURL, nil)
// client
client := new(http.Client)
// send request to
resp, err := client.Do(req)
if err != nil {
return nil, status.Error(codes.Internal, fmt.Sprintf("error on healthcheck: %s", err))
}
defer resp.Body.Close()
// return true
return &healthpb.HealthCheckResponse{
Status: healthpb.HealthCheckResponse_SERVING,
}, nil
}この構成に至るまでに少し苦労しましたが、特に問題なく動いていて、httpエンドポイントもgRPCエンドポイントも提供できるようになっています。Istio Ingress Gatewayにsidecarを追加しているだけで、Istioのアップデートも問題なくできています。
まとめ
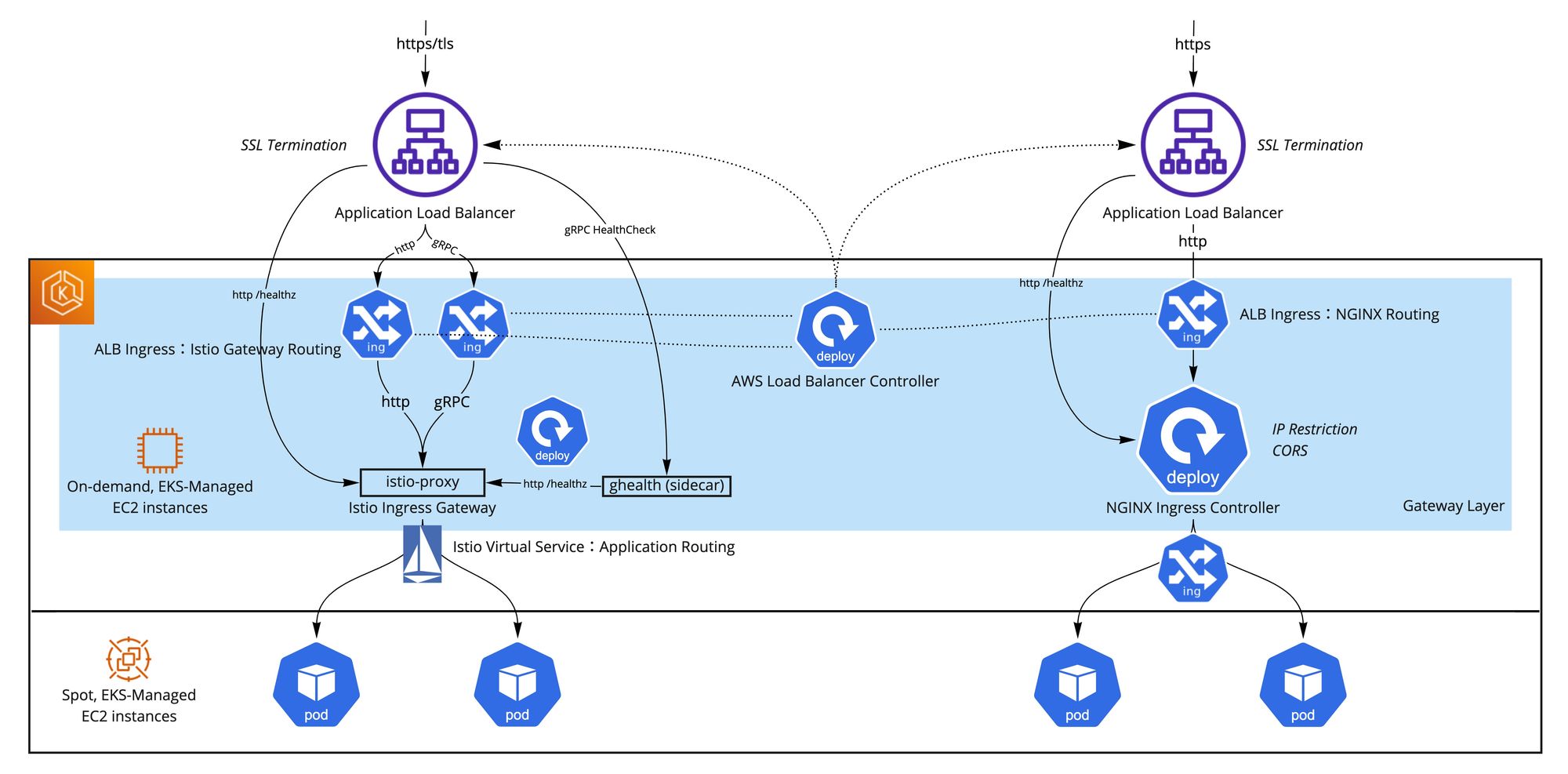
外部向けロードバランサーがKubernetesの一番大変なところだと思っていますが、MoTではGatewayレイヤーを設けることでクラウドサービスの特殊対応をアプリケーションに隠すようにして、アプリケーション開発をなるべく軽くして、定義を柔軟に変更できるようにしています。Gatewayレイヤーを用意するにはいくつか工夫が必要でしたが、現在httpとgRPC外部エンドポイントを安定した形で提供しています。以下の図の通り、Gatewayレイヤーの構成が複雑になっているため、主にレガシーサービスの互換性のために存在しているNGINX Ingress Controllerを将来的に廃止してIstio Ingress Gatewayに一本化できるといいのではないかと思います!
これでKubernetesアップデートストーリーシリーズの第3話が終わります。
第4話では、Istioをバージョン1.2から1.13までに数時間でアップデートした話になります。是非、お読みください!
We're Hiring!
📢
Mobility Technologies ではともに働くエンジニアを募集しています。
興味のある方は 採用ページ も見ていただけると嬉しいです。
Twitter @mot_techtalk のフォローもよろしくお願いします!