

Kubernetes v1.10からv1.21へのアップデート | Kubernetesアップデートストーリー第2話
SREK8sMay 26, 2022
こんにちは、技術戦略部 SREグループのカンタンです。
本記事はKubernetesアップデートストーリーシリーズの第2話になっていて、数年をかけてKubernetesのバージョンを1.10から1.21まで11回アップデートした話になります。是非第1話から読んでいただいたほうが背景と内容がわかりやすくなるかと思います!
Kubernetesアップデートストーリーシリーズのまとめ
- 数年をかけたKubernetes環境の大幅アップデート | Kubernetesアップデートストーリー第1話
- Kubernetes v1.10からv1.21へのアップデート | Kubernetesアップデートストーリー第2話
- Amazon EKSロードバランサー構成の大幅変更 | Kubernetesアップデートストーリー第3話
- 数時間でIstio v1.2からv1.13へアップデート | Kubernetesアップデートストーリー第4話
- Helm v2からv3へのメジャーアップデート | Kubernetesアップデートストーリー第5話
本記事では以下の課題についてお話しします:
- Kubernetes/Amazon EKSアップデートに向けた一般的な準備方法
- Kubernetes API廃止の検知方法、対応方法、対応を楽にするためのコツ
- 本番環境で実績のある安全なKubernetesアップデート実施方法
- Amazon EKSのcontainerd移行方法
課題
Kubernetesのリリース頻度が3ヶ月に一回から4ヶ月に一回になりましたが、それでもリリース頻度は高いほうだと思います。古いKubernetesクラスターを最新バージョンにアップデートするため、SREグループで担当を変えながらk8sバージョン1.10から1.21まで11バージョンアップデートを一つずつ実施しました。KubernetesのAPI廃止が発生した1.16と1.22の準備がかなり大変で、それ以外のアップデートはスムーズだったという印象が残っています(1.22へのアップデートがまだですが準備は完了している状態です)。
アップデート準備
アップデートする前に以下の準備をしています。
- Kubernetesの公式リリースノートとChangelogを確認する
- Amazon EKSの公式ドキュメントを確認する
- Martin Cuberさんの「Amazon EKS Upgrade Journey」シリーズを確認する
- 必要に応じて、クラスターで動いているツールとアプリケーションをアップデートしておく
- アップデートのそれぞれのステップの詳細情報や実行するコマンドなどが含まれているアップデート手順をバージョンごとに細かく用意して他のチームメンバーにレビューしてもらう
k8s API廃止対応
k8s 1.16と1.22バージョンのように、k8s APIが廃止されるアップデートの場合以下の対応が必要です。
- リソース自体の調整:新しいAPI仕様に移行するように対象リソースを調整する
- リソース利用者の調整:対象APIを利用しているControllerやアプリケーションなどが新しい仕様を利用するようにアップデートしたり変更したりする
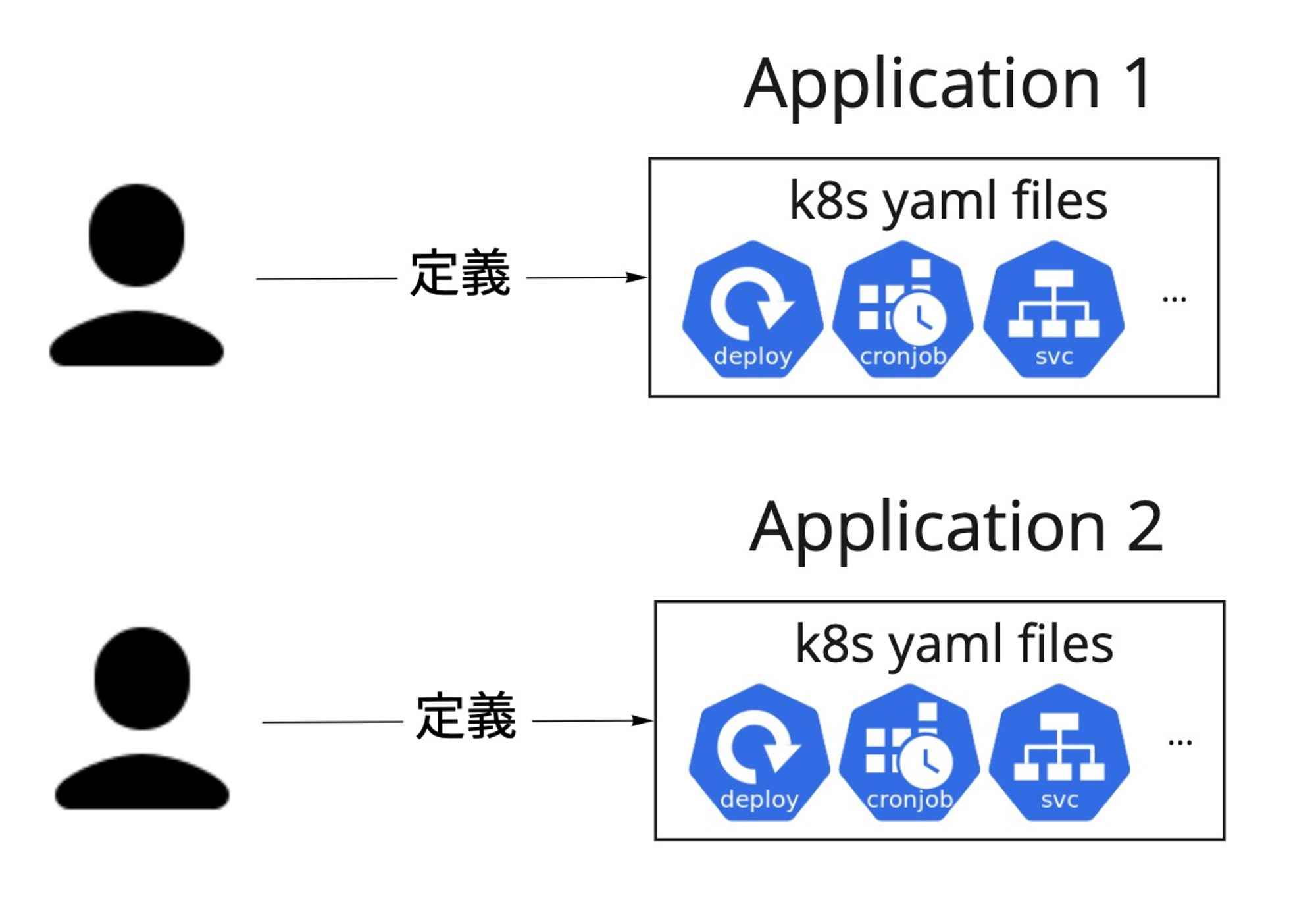
リソース自体の調整に関して、Deployment のAPIバージョンを apps/v1beta1から apps/v1 に切り替えたり、Ingressの kubernetes.io/ingress.classアノテーションを ingressClassNameに切り替えたりすることなど、リソース更新時に適用するYAML情報を変更する必要があります。以下の図のようにリソースYAMLファイルをそのままアプリケーションごとに定義してしまうと、変更が必要になった時の対応がアプリケーションの数だけ発生してしまいます。さらに、時間が経つとそれぞれのアプリケーションのYAMLファイルの差分が徐々に大きくなるため、対応がアプリケーションによって異なり、手間がさらに増えてしまいます。
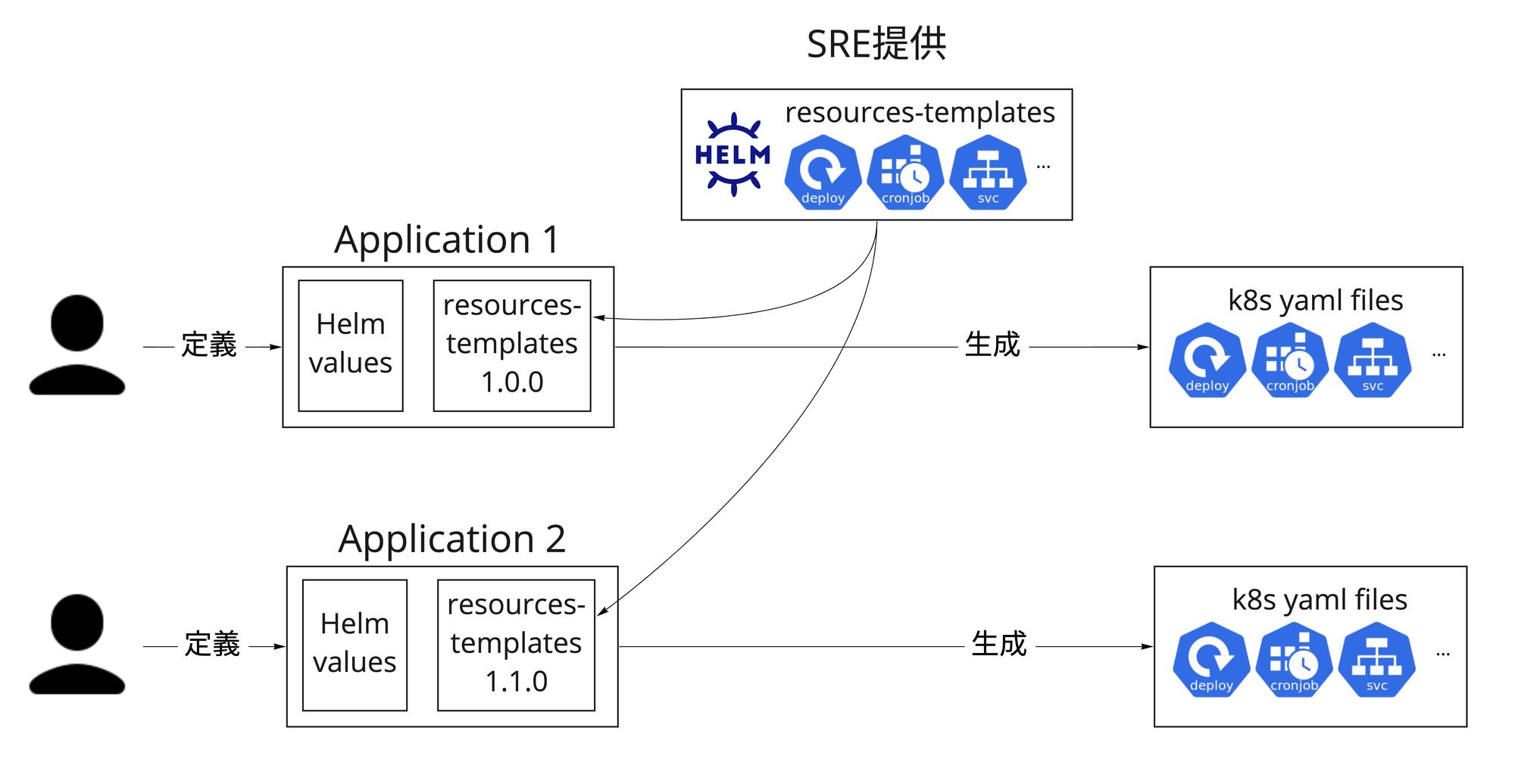
MoTでは利用するk8sリソースのHelmテンプレートをSREがパッケージングしてバージョン管理して用意しています。アプリケーション側でそのパッケージバージョンとアプリケーション固有設定を指定すれば、最終的なYAMLファイルを生成できる仕組みになっています。k8sのAPI仕様変更が発生した際に、移行方法をSRE側で検証した上で、テンプレートパッケージの新しいバージョンをリリースして提供しています。アプリケーション側ではパッケージのバージョンを上げてデプロイするだけで安全かつ楽な移行が可能になっています。API廃止の対応だけではなく、全てのアプリケーションが同じテンプレートを使うことで設定が統一されていてミスが起きづらいですし、ベストプラクティスを一括して実施できるのもこの方法のメリットです。
廃止されるAPIで作成されたリソースが残っていないかを確認するため、kube-no-trouble (kubent)というとても便利なツールを使っています。kubectlが付けている kubectl.kubernetes.io/last-applied-configuration アノテーションやHelmのマニフェストなどを参照して、リソース作成時と更新時に廃止されるAPIが利用されなかったかを確認してくれます。
$ kubent
5:56PM INF >>> Kube No Trouble `kubent` <<<
5:56PM INF version 0.5.1 (git sha a762ff3c6b5622650b86dc982652843cc2bd123c)
5:56PM INF Initializing collectors and retrieving data
5:56PM INF Target K8s version is 1.21.x-eks-yyyyyyy
5:56PM INF Retrieved N resources from collector name=Cluster
5:56PM INF Retrieved 0 resources from collector name="Helm v2"
5:57PM INF Retrieved M resources from collector name="Helm v3"
5:57PM INF Loaded ruleset name=custom.rego.tmpl
5:57PM INF Loaded ruleset name=deprecated-1-16.rego
5:57PM INF Loaded ruleset name=deprecated-1-22.rego
5:57PM INF Loaded ruleset name=deprecated-1-25.rego
__________________________________________________________________________________________
>>> Deprecated APIs removed in 1.25 <<<
------------------------------------------------------------------------------------------
KIND NAMESPACE NAME API_VERSION REPLACE_WITH (SINCE)
PodDisruptionBudget namespace1 application1 policy/v1beta1 policy/v1 (1.21.0)
PodDisruptionBudget namespace2 application2 policy/v1beta1 policy/v1 (1.21.0)
PodSecurityPolicy <undefined> eks.privileged policy/v1beta1 <removed> (1.21.0)指定されたリソースを一つずつ対応すればリソース自体の対応は完了で、あとはリソース利用者の調整だけが残ります。
リソース利用者の調整に関しては、独自のControllerをなるべく作らないこととメンテナンスされているControllerしか使わないようにしています。そうすれば、k8s API仕様変更にあわせて実装を変える必要がないですし、Controllerを最新バージョンにアップデートすることだけで対応ができることが多いです。それでも、ControllerのリリソースノートとChangelogをきちんと読まないと障害が起きる可能性があるため注意が必要です。
アップデートの実施方法
Kubernetesのアップデートはコントロールプレーンのアップデートとデータプレーン(ノード)のアップデートという2段階になっています。
コントロールプレーンに関しては問題が起きたことがなく、ボタンを押せばAmazon EKSが20分〜1時間ぐらいでアップデートしてくれます!
ノードのアップデートはそれなりに大変で、アップデートを楽にするために最初にやったことがセルフマネージドノードのEC2インスタンスからEKSマネージドのEC2インスタンスに切り替えることでした。EKSマネージドノードグループを作って、セルフマネージドノードを一つずつdrainするだけで問題なく移行できました。移行前はセルフマネージドノードを一つずつ作り直してくれる独自スクリプトを使ってローリングアップデートしていました。
EKSマネージドノードに移行してからノードのローリングアップデートが楽になりましたが、それでも事前処理と事後処理として独自スクリプトを実行しています。サービスダウンが発生しないようにKubernetesの PodDisruptionBudget リソースを設定していますが、レガシーなどを理由に冗長化不可能なアプリケーションがクラスター内に動いており、 PodDisruptionBudget にロックされていて動けないPodが存在しています(以下の application1 は動かせないPodの例で、 application2 は問題ないです)。
NAME MIN AVAILABLE MAX UNAVAILABLE ALLOWED DISRUPTIONS AGE
application1 1 N/A 0 1d
application2 1 N/A 1 1d対応しないとノードdrainが終わらずアップデートが失敗します。そのため、ノードのアップデートを以下のように実施しています
- 事前処理:動かせないPodが存在しないように、PDB設定に応じてレプリカ数を一時的に増やす
- ALLOWED DISRUPTIONS=0 、かつ、HPAが設定されている場合、HPAのminReplicasを増やす
- ALLOWED DISRUPTIONS=0 、かつ、HPAが設定されていない場合、Deploymentのreplicasを増やす
- アップデート:EKSマネージドのノードグループのローリングアップデートを実行する
- 事後処理:一時的に増やしたレプリカ数を元に戻す
このスクリプトをGKEクラスターでも使っていて、とても便利です。そういう運用にしてからアップデートがだいぶ楽になりました。サービスの成長に伴ってノード数が増えていくためアップデートの時間も伸びています。EKSマネージドノードグループのローリングアップデートの際に複数のノードを同時にアップデートすることと、複数のノードグループを同時にアップデートすることでアップデート時間を短縮しています。
containerd移行方法
Dockershimの廃止がk8s 1.20のリリースと合わせてアナウンスされて、k8s 1.24でdockershimが利用不可能になる予定です。2021年7月から、Amazon EKSのk8s 1.21のバージョンサポートと合わせてcontainerdを利用できるようになりました。様々な取り組みのおかげでアップデートが楽になったため、1.21バージョンにアップデートしてからcontainerdに移行してしまいました。公式のAmazon EKS AMIを利用しているため、userdataに以下の情報を設定するだけでcontainerdを利用するノードを起動できました。
MIME-Version: 1.0
Content-Type: multipart/mixed; boundary="==MYBOUNDARY=="
--==MYBOUNDARY==
Content-Type: text/x-shellscript; charset="us-ascii"
#!/bin/bash
cat <<-EOF > /etc/profile.d/bootstrap.sh
export CONTAINER_RUNTIME="containerd"
EOF
# Source extra environment variables in bootstrap script
sed -i '/^set -o errexit/a\\nsource /etc/profile.d/bootstrap.sh' /etc/eks/bootstrap.sh
--==MYBOUNDARY==--\containerd用のEKSマネージドノードグループを作って、docker利用しているノードを一つずつdrainするだけで移行ができて、非常にスムーズな移行でした!
まとめ
k8s 1.10からスタートして、SREグループで11バージョンをアップデートしてきて、当初と比較するとアップデートの手間が圧倒的に下がり、これから先行して定期的にアップデートできる自信を得ました。振り返ると、以下の対策が特に効果的だと思います
- アップデート手順を詳しく書いて、レビューしてもらうこと
- アップデート作業を複数人でローテーションで実施すること
- アップデートが楽になるように、スクリプトを作ったり、構成を変更したりすること
- Kubernetesで動いているアプリケーションとControllerを把握して、リソーステンプレートのように作成できるリソースを制御すること
これでKubernetesアップデートストーリーシリーズの第2話が終わります。
第3話では、ロードバランサー構成の大幅変更についてお話しします。是非、お読みください!
We're Hiring!
📢
Mobility Technologies ではともに働くエンジニアを募集しています。
興味のある方は 採用ページ も見ていただけると嬉しいです。
Twitter @mot_techtalk のフォローもよろしくお願いします!