

数時間でIstio v1.2からv1.13へアップデート | Kubernetesアップデートストーリー第4話
SREK8sMay 26, 2022
こんにちは、技術戦略部 SREグループのカンタンです。
本記事はKubernetesアップデートストーリーシリーズの第4話になっていて、Istioをバージョン1.2から1.13までに数時間でアップデートした話になります。是非第1話から読んでいただいたほうが背景と内容ががわかりやすくなるかと思います!
Kubernetesアップデートストーリーシリーズのまとめ
- 数年をかけたKubernetes環境の大幅アップデート | Kubernetesアップデートストーリー第1話
- Kubernetes v1.10からv1.21へのアップデート | Kubernetesアップデートストーリー第2話
- Amazon EKSロードバランサー構成の大幅変更 | Kubernetesアップデートストーリー第3話
- 数時間でIstio v1.2からv1.13へアップデート | Kubernetesアップデートストーリー第4話
- Helm v2からv3へのメジャーアップデート | Kubernetesアップデートストーリー第5話
本記事では以下の課題についてお話しします:
- Istioを利用する際の懸念点
- Istioのインストール方法
- Istioがマイクロサービスからモノリスになった話とその影響
- Istio最新バージョンのメトリックス集約と集計方法
- 数時間でダウンタイムなく、Istioを古いバージョンから最新バージョンまでアップデートする方法、注意点とコツ
- 本番環境で実績のあるIstioの最新アップデート方法
課題
Pod間のgRPC通信のロードバランシングを可能にすることと観測性を向上させることを主な目的として約2年前にIstioをクラスターに導入しました。単純なインストールだけで
- サービスメッシュが作れる
- アプリケーションに手を一切入れずにgRPC通信ができるようになる
- アクセスログが出力されるようになり、Istio Mixerが集計してくれる様々なメトリックスをnewrelic-istio-adapter経由でNewRelicに簡単に送ることができる
と非常に便利ですぐに活用できました。NewRelicと組み合わせることで全てのマイクロサービスのRPS、レスポンスタイム、エラー数などを可視化できて、アラートも設定できるため観測性のレベルも一段上がりました。
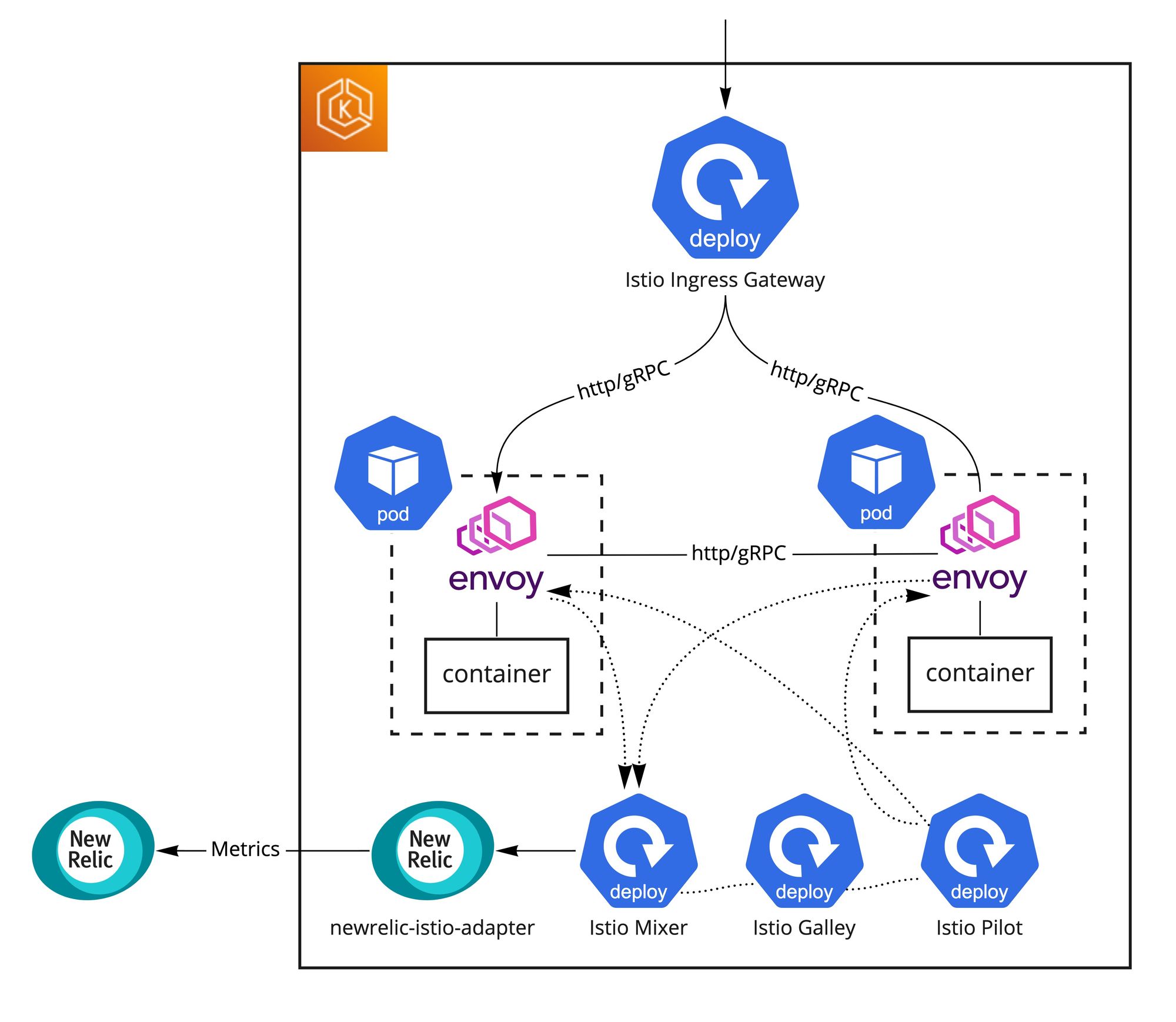
ただ、当時最新だった1.2バージョンをHelmでインストールした際、Pod終了時にEnvoyがコンテナより先に終了してしまう問題に検証段階からぶつかり、Helmチャートをフォークして以下のpreStopフックを追加しました。当時は恐らくこれが唯一の解決方法でした。
lifecycle:
preStop:
exec:
command:
- /bin/sh
- -c
- |
set -e
echo "Exit signal received, waiting for all network connections to clear..." > /dev/termination-log
while [ $(netstat -plunt | grep tcp | grep -v envoy | grep -v pilot-agent | wc -l | xargs) -ne 0 ]; do
printf "." > /dev/termination-log
sleep 3;
done
echo "Network connections cleared, shutting down pilot..." > /dev/termination-log
exit 0この問題もあって、Istioのアップデートを中々できず、気づいたらIstio 1.2のサポート対象に全く入らないKubernetesバージョン1.20までアップデートしてしまいました。開発環境を先にアップデートしてしっかり検証した上で進めていたため問題は特にありませんでしたが、安全な進め方とは言えません。
k8sバージョン1.22からはいよいよIstio 1.2が利用している様々なAPIが使えなくなるため、SREグループでIstioを最新にアップデートすることを決定し、様々な検証と準備を終えてから1.2から1.13まで11バージョンのアップデートを一つずつ数時間で行いました!
最新までアップデートするには様々な課題を解決する必要がありました。主な課題を以下にまとめます。
- Istioの推奨インストール方法が大きく変わってしまった
- Istio 1.5からIstioのアーキテクチャが大幅に変わってしまった
- Istio 1.5からメトリックスの取得方法が大きく変わってしまった
これからその課題と解決方法についてお話しできればと思います。
Istioのインストール方法
Istioの推奨インストール方法が2年で頻繁に変わったことが11バージョンのリリースノート、Changelogとドキュメンテーションを確認して一番最初に気づいたことです。

参考資料:1.2、1.3、1.4、1.5、1.6、1.7、1.8、1.9、1.10、1.11、1.12、1.13
一時期ターゲット状態をYAMLファイルで書いて、適用をクラスターで動くIstio Operatorに任せる方向に行きそうでしたが、セキュリティリスクが高くその方向は廃止されていくようです。その代わりに、元々Operatorに渡していたYAMLファイルをistioctlに渡して実行するのが現在推奨されているやり方のようです。一時的に廃止されて復活してきたHelmチャートを見るとこれからも方針が変わりそうな雰囲気があるものの、istioctlがこの数年でコンスタントのようなので、MoTではistioctl + operator YAMLファイルでインストールとアップデートをするようにしています。Infrastructure As CodeがSREグループの中でとても大事なポイントで、普段からterraform設定、k8sのHelmチャートやYAMLファイルをgitで管理しています。Istioの全ての設定を一つのYAMLファイルにまとめることがその方針とあっているためそのやり方でIstioを管理するようにしました。
とはいえIstio 1.6まではその方法がなかったため、1.6まではHelmチャート形式でアップデートしました。
Istioアーキテクチャ変更
Istio 1.5リリースでIstioのアーキテクチャが大幅に変わり始めて、Istio 1.6リリースでマイクロサービスからモノリスに完全に切り替わりました。Pilot, Galley, Citadelなどが一つのistiodプログラムになって、MixerがWebAssembly(Wasm)ベースの仕組みに切り替わって、なくなりました。
そのアーキテクチャ変更で複雑だった構成がシンプルになり、IstioのCPU使用率が下がって全体のフットプリントが小さくなりました。
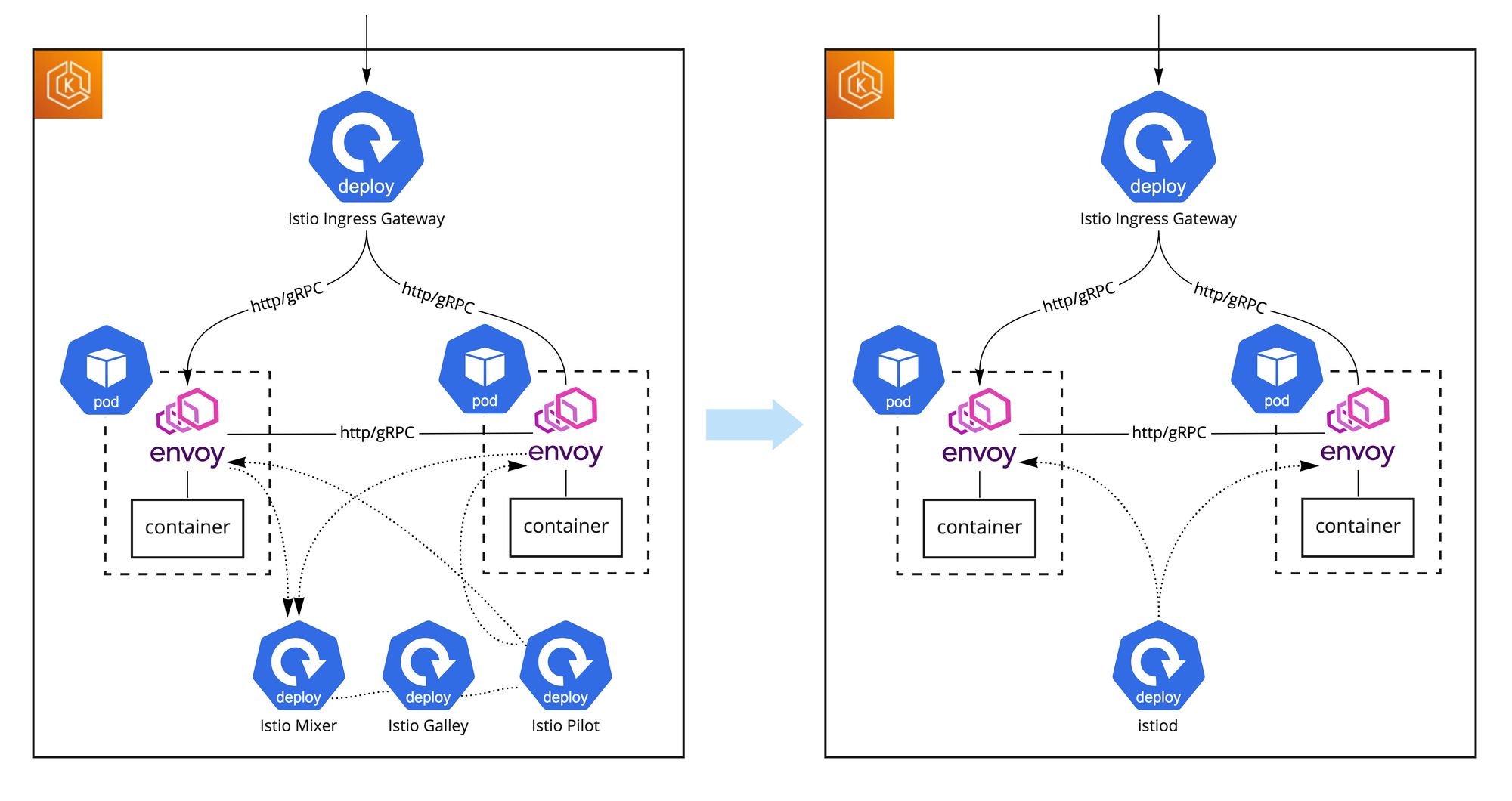
メトリックスの集約方法
Istioのアーキテクチャ変更で唯一調整が大変だったのがメトリックスの収集と集計でした。
アーキテクチャ変更前にレスポンスタイムなど様々なメトリックスがMixerに集約され、リクエスト元サービスとリクエスト先サービスのペアでいい感じに集計されていました。そこからIstioのAdapterパターンを使って、newrelic-istio-adapterに転送するだけでNewRelicまでメトリックスを集約してそのまま活かすことができていました。
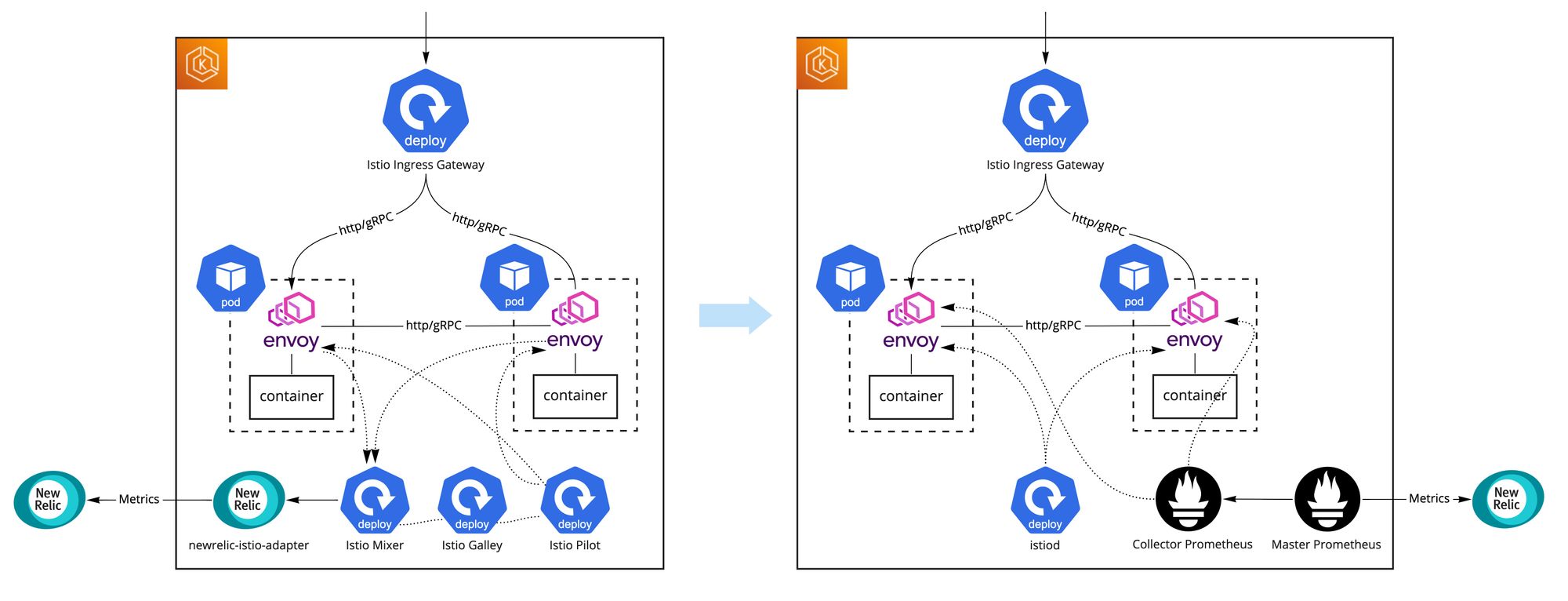
アーキテクチャ変更で、それぞれのPodのenvoyが自分のメトリックスをPrometheusエンドポイントとして提供するようになり、自分でPrometheusを立ててスクレイピングする必要が出てきました。NewRelicのPrometheus OpenMetrics Integrationを使うと全てのメトリックスを比較的簡単にNewRelicまでに送信することができましたが柔軟性が少し不足していたこととデータ量が多かった関係で自分でPrometheusを立てることになりました。具体的にはMixerはメトリックスをリクエスト元サービスとリクエスト先サービスのペアで集計していたのですが、アーキテクチャ変更によりリクエスト元Podとリクエスト先Podの粒度のメトリックスになってしまい、自分で集計せずにそのままNewRelicに送ってしまうとものすごいデータ量になってしまったのでした。そのため、自分で立てたPrometheusでメトリックスを集計してからPrometheusのremote write integrationでデータをNewRelicに送るようにしました。
Prometheusは将来的にもスケールするように、Hierarchical federation構成でクラスターにインストールしました。構成の詳細情報とセットアップ方法についてはIstioのドキュメンテーションとKarl Stoneyさんからの「Federated Prometheus to reduce Metric Cardinality」記事がおすすめです。
最終的に以下のような構成になりました
- 一つの「Collector」Prometheusが全てのenvoyのメトリックスをスクレイピングして集計する。その集計を早くするために数段階で行うことが効果的。集計したメトリックスを自分で提供する
- もう一つの「Master」PrometheusがCollector PrometheusのメトリックスをスクレイピングしてNewRelicに送る
集計されたデータはすぐにそのままNewRelicに送られていくため、Prometheus自身がデータを長く保存する必要がなく、実質ステートレスなワークロードになっていて運用しやすいです。集計前のデータは2時間ぐらいしか保存していませんが、障害が発生した時などさらに細かい分析を行いたい場合、k8sのポートフォワード機能を使ってCollector PrometheusのGUIをそのまま開いて分析することもあります。
Collector Prometheusのrecording ruleサンプルイメージ
- name: istio.workload.istio_requests_total_rate
interval: 10s
rules:
- record: federate:istio_requests_total
expr: |
sum(irate(istio_requests_total{reporter="destination", destination_workload!=""}[1m]))
by (
source_workload_namespace,
source_app,
source_workload,
destination_workload_namespace,
destination_app,
destination_service,
destination_workload,
request_protocol,
response_code,
response_flags,
grpc_response_status
)Master Prometheusのscape configサンプル設定
- job_name: 'federate'
scrape_interval: 10s
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
- '{__name__=~"federate:(.*)"}'
static_configs:
- targets:
- 'prometheus-collector-server:80'
metric_relabel_configs:
- source_labels: [__name__]
regex: 'federate:(.*)'
target_label: __name__
action: replaceMaster Prometheusのremote writeサンプル設定
remoteWrite:
- url: https://metric-api.newrelic.com/prometheus/v1/write?prometheus_server=master_prometheus
bearer_token: redacted
write_relabel_configs:
- source_labels:
- __name__
regex: istio_requests_total
action: keepアップデートの流れ
IstioのアップデートはKubernetesのアップデートと似ていて、2段階で行われます
- コントロールプレーンのアップデート (Pilot, Galley, Mixer, istiod ...)
- Helmチャートインストールの場合、チャートのバージョンを上げてHelmでアップグレードする
- istioctlインストールの場合、Istio Operator YAMLファイルにIstioバージョンを上げてistioctlを実行する
- データプレーンのアップデート (それぞれのPodのenvoyアップデート)
- 全てのDeploymentを再起動する (MoTではDaemonsetやCronJobから作成されるPodはサービスメッシュにいれていない)
アップデートのそれぞれの段階で、以下の確認を必ず行うようにしました
- Pilot, Galley, Mixer, istiod, Istio Ingress Gatewayなど全てのコンポーネントが起動していて、正しいバージョンになっていること
- 全てのコンポーネントのログにエラーが出ていないこと
- siegeやghzなどベンチマークツールを使って通信ができていること
- NewRelicでメトリックスが取れていること
- アプリケーションPodに正しいenvoyバージョンが設定されていること
- envoyにpreStopフックが設定されていること
- envoyのログが出力されていること
- アプリケーションをローリングアップデートしてもエラーが出ないこと
- Istio Ingress GatewayにpreStopフックが設定されていて、ローリングアップデートしてもエラーが出ないこと
Istio 1.2から1.13までにアップデートしようと思うと互換性を保つためにバージョンをひとつずつアップデートする必要があります。途中でIstioのインストール方法が変わったりアーキテクチャ自体が変わったりしているため、主に3つのフェーズに分けてアップデートを行いました
- フェーズ1:旧アーキテクチャの最新バージョンまでアップデート:1.2 —> 1.3 —> 1.4
- フェーズ2:アーキテクチャ変更後のバージョンに一気にアップデートする:1.4 —> 1.6
- フェーズ3:新アーキテクチャの最新バージョンまでアップデート:1.6 —> 1.7 —> 1.8 —> 1.9 —> 1.10 —> 1.11 —> 1.12 —> 1.13
フェーズ1:1.2から1.4へ
IstioをHelmチャートとしてインストールしていたため、そのまま順番にistio-initとistioのチャートをアップデートすることで1.3と1.4バージョンまでに上げることができました。課題のところで話したバグを解決するため、対象バージョンのIstio公式チャートをフォークして手動でpreStopフックを追加する必要がありました。細かい調整が多少必要でしたが比較的シンプルなアップデートでした。
フェーズ2:新アーキテクチャへ
Istioのアーキテクチャ変更とIstioのインストール方法をHelmからistioctlに切り替えた関係で、このフェーズが一番複雑でした。1.4から1.5にアップデートする場合いくつかバグがあるという情報をもらっていたことと、istiod単体アーキテクチャに直接アップデートしたかったこともあって、1.4バージョンから1.6バージョンに直接アップデートしました。
Istio Ingress Gatewayの更新にあたっては、
- Istio Ingress Gatewayが利用しているポート番号が80番から8080に切り替わった
- HTTPヘルスチェックポートが15020ポートから15021ポートに切り替わった
- MoTで作ったgRPCヘルスチェック用のghealthコンテナが15021ポートを使っていた
ということもあって、ダウンタイムが発生しないようにALB設定を徐々に変更しながらIstio Ingress GatewayのDeploymentを複数回デプロイする必要がありかなり大変でした。ALB設定に関しては「Amazon EKSロードバランサー構成の大幅変更 | Kubernetesアップデートストーリー第3話」記事をご参照ください。
細かいところは割愛しますが、以下のようなステップで実施しました
- 初期状態:Pilot, Galley, Mixer, Istio Ingress GatewayがIstioのHelmチャートで管理されている状態
- Prometheus (Collector + Master) をインストールする
- istioctlを使ってistiodのみをインストールする
- Istio Ingress Gatewayは引き続きHelmチャートで管理する
- istiodはまだ利用されない
- Istio Ingress Gatewayポート切り替え
- 初期状態:通信を80ポートで受けて、httpヘルスチェックを15020ポートで受けて、gRPCヘルスチェックを15021ポートでghealth経由で受ける
- 80ポートも8080ポートも受けられるようにGatewayリソースを調整、Istio Ingress Gatewayをデプロイ
- gRPCヘルスチェックを25021ポートで受けるghealthコンテナを追加するようにIstio Ingress Gatewayをデプロイ
- http通信を80番から8080番に切り替えるようにALB設定を変更
- gRPCヘルスチェックを25021ポートで受けるghealthコンテナに送るようにALB設定を変更
- 15021ポートのghealthコンテナを削除するようにIstio Ingress Gatewayをデプロイ
- httpヘルスチェックを15020ポートから15021に切り替えるようにIstio Ingress Gatewayをデプロイ (ALBのPodReadinessGateでデプロイが途中で止まる)
- httpヘルスチェックを15020ポートから15021に切り替えるようにALB設定を変更(前のステップのデプロイが進む)
- 念の為Istio Ingress Gatewayをもう一度デプロイする
- 最終状態:通信を8080ポートで受けて、httpヘルスチェックを15021ポートで受けて、gRPCヘルスチェックを25021ポートでghealth経由で受ける
- アプリケーションPodがistiodを利用するように、データプレーンをアップデート
- カナリアリリースで切り替えるように、ネームスペースに istio.io/rev=1-6-14 ラベルを付ける
- ネームスペースのDeploymentを再起動する: kubectl -n namespace rollout restart deployment
- Istio Ingress GatewayをHelm管理からistioctl管理に切り替える
- Istio operator YAMLファイルでIstio Ingress Gatewayを有効にする
- クラスターにデプロイされているIstio Ingress Gatewayの Deployment YAMLとistioctlが生成するYAMLに差分がないようにIstio operator設定を調整する
- istioctlを実行することでIstio Ingress Gatewayをistioctl管理対象にする
- Istio Ingress Gateway関連のリソースをHelm管理対象外にするように "helm.sh/resource-policy"=keep アノテーションを対象リソースに付ける
- Helmを実行することで、Istio Ingress GatewayをHelm管理対象外にする
- Prometheus経由でメトリックスが取れてNewRelicまで上がっていることを確認する
- メトリックスフォーマットが変わるため、ダッシュボードやアラートなどを調整する
ご覧の通りステップが多く、正しい手順に至るまで苦労しました。検証環境で何回も失敗して、特にステップ 6)で利用していたHelm 2.12バージョンが古すぎて"helm.sh/resource-policy"=keepアノテーションを無視してIstio Ingress Gatewayが削除されてしまったことをよく覚えています。
幸いなことに、本番環境実施時は問題なくアップデートができました!
フェーズ3:最新バージョンへ
バージョン1.6から1.13までのアップデートは非常にスムーズに行きました。微調整は時々必要でしたが、以下の手順で問題なくアップデートできました:
- 新しいバージョンのistioctlをインストールする
- Istio Operator YAMLファイルのIstioバージョンを変更する
- istioctlを実行して新しいコントロールプレーンをインストールする
- (Istio Ingress Gatewayがアップデートされてしまう)
- データプレーンをアップデートする (Deploymentを再起動する)
- istioctlを使って古いコントロールプレーンを削除する
最終的なIstio Operator設定は以下のようになっています(イメージ)
apiVersion: install.istio.io/v1alpha1
kind: IstioOperator
spec:
revision: 1-13-2
meshConfig:
accessLogEncoding: 1 # 0=TEXT, 1=JSON
accessLogFile: /dev/stdout
components:
pilot: # istiod
k8s:
hpaSpec:
minReplicas: 2
maxReplicas: 1000
resources:
limits:
memory: 1Gi
requests:
cpu: 1
memory: 1Gi
ingressGateways:
- name: istio-ingressgateway
enabled: true
k8s:
hpaSpec:
minReplicas: 2
maxReplicas: 1000
resources:
limits:
memory: 1Gi
requests:
cpu: 1
memory: 1Gi
service:
type: ClusterIP
overlays:
- kind: Deployment
name: istio-ingressgateway
patches:
# add lifecycle
- path: spec.template.spec.containers.[name:istio-proxy].lifecycle
value: |
preStop:
exec:
command:
- /bin/sh
- -c
- |
sleep 30
# add ghealth container for gRPC healthcheck
- path: spec.template.spec.containers.[-1]
value:
name: ghealth
image: redacted
ports:
- containerPort: 25021
protocol: TCP
resources:
limits:
memory: 32Mi
requests:
cpu: 10m
memory: 32Mi
lifecycle:
preStop:
exec:
command:
- /bin/sh
- -c
- sleep 30
values:
proxy:
lifecycle:
preStop:
exec:
command:
- /bin/sh
- -c
- |
set -e
echo "Exit signal received, waiting for all network connections to clear..." > /dev/termination-log
while [ $(netstat -plunt | grep tcp | grep -v envoy | grep -v pilot-agent | wc -l | xargs) -ne 0 ]; do
printf "." > /dev/termination-log
sleep 3;
done
echo "Network connections cleared, shutting down pilot..." > /dev/termination-log
exit 0
resources:
limits:
memory: 64Mi
requests:
cpu: 50m
memory: 64Miバージョン1.11からタグを使ったIstioカナリアアップグレードがGAになって、Istioのアップデートがより楽になりました。現在以下の手順でIstioのバージョンアップデートを行なっています:
- 事前準備
- istioctlインストール
- istioctl x precheck 実行
- istioctl analyze --all-namespaces 実行
- 新しいコントロールプレーンをインストール (istiod)
- istioctl install -f istio-operator.yaml --set revision=1-13-2
- Istio Ingress Gatewayもアップデートされる
- データプレーンアップデート検証
- カナリアリリース用のタグを作成する: istioctl tag set canary --revision 1-13-2 --overwrite
- 検証ネームスペースを新バージョンに切り替える: kubectl label namespace <TEST-NAMESPACE> istio.io/rev=canary --overwrite
- 検証Deploymentをアップデートする: kubectl -n <TEST-NAMESPACE> rollout restart deployment <TEST-DEPLOYMENT>
- データプレーン全体アップデート
- stableタグを更新する: istioctl tag set stable --revision 1-13-2 --overwrite
- 検証ネームスペースをstableに切り替える: kubectl label namespace <TEST-NAMESPACE> istio.io/rev=stable --overwrite
- 全てのネームスペースのDeploymentをアップデートする: kubectl -n <NAMESPACE> rollout restart deploy
- 片付け
- インストールの確認: istioctl verify-install --revision 1-13-2
- 古いコントロールプレーンの削除: istioctl x uninstall -f istio-operator.yaml --revision 1-12-0
まとめ
アーキテクチャ変更、Istio Ingress Gatewayのポート変更、gRPCヘルスチェック対応、Helmからistioctlへの切り替えなど様々な課題を解決する必要があって中々準備と検証が大変な大幅アップデートでした。Mixerの削除の影響でメトリックスの集約と集計を最初から考え直さないといけなかったことと、ポートやインストール方法、Istioの様々な仕様変更でダウンタイムが発生しないアップデート方法を見つけるのが一番大変でした。アーキテクチャ変更で様々なマイクロサービスが一つのistiodサービスになったこと自体は特に大きな影響はなかったです。タグを使ったカナリアアップデート方法のおかげで、最新のアップデート方法は非常に安全かつ楽になっています!
振り返ってみると、以下のところが一番重要だったと思います
- リリースノート、Changelogを詳しく確認して課題を予め洗い出すこと
- 手順を予め詳しく書いておくこと(汎用的な手順ではなく、クラスターごとにそのまま実行してもいいコマンドが細かく記載されている手順)
- 検証環境とは別に、本番環境に近い覚悟でアップデートを練習できる環境があること
- 検証環境で気軽に色々試す
- 練習環境でドキドキしながらアップデートを実施する(MoTの場合、開発者が利用している開発環境で実施しましたが、失敗してもサービスには影響しないものの開発が止まる可能性があるため十分なプレッシャーがありました)
- こういう複雑なアップデートが必要にならないように、クラスターで動いている様々なコンポーネントとツールを定期的にアップデートすること!
最終的に本番環境で実施して、バージョン1.2から1.13まで数時間をかけて無事に大きな問題なくアップデートができました!
これでKubernetesアップデートストーリーシリーズの第4話が終わります。
第5話では、Helmのメジャーバージョンをバージョン2からバージョン3にアップデートした話になります。是非、お読みください!
We're Hiring!
📢
Mobility Technologies ではともに働くエンジニアを募集しています。
興味のある方は 採用ページ も見ていただけると嬉しいです。
Twitter @mot_techtalk のフォローもよろしくお願いします!