

量子化による物体検出モデルの精度低下の原因分析と対策(YOLOv3・YOLOv5の量子化を例に)
AIDeep LearningコンピュータビジョンQuantizationJune 02, 2022
AI技術開発部の木村です。
Mobility Technologies(以下MoT)では、画像認識モデル(主にニューラルネットワーク)の開発に加え、車載デバイス上でモデルをリアルタイムに動作させるための軽量化・高速化にも取り組んでいます。軽量化・高速化には、こちらの資料で紹介しているように枝刈りや蒸留など色々なアプローチがありますが、本記事では量子化による高速化を取り上げます。
量子化はモデルの軽量化・高速化に非常に効果的ですが、物体検出モデルなど複雑なモデルでは(この記事で実験するように)量子化による精度低下が発生しやすい傾向にあります。本記事では、YOLOv3とYOLOv5の量子化を具体例として、物体検出モデルの精度低下を抑えつつ量子化するためのポイントを解説します。
はじめに
本記事は、2022年4月6日に開催された「MoT TechTalk #11 深掘りコンピュータビジョン!研究開発から社会実装まで」(connpass)での発表「物体検出モデルの量子化に関する検討」をまとめたものです。当日の発表動画と資料を公開していますので、ご興味のある方はそちらもあわせてご覧ください。
また、ニューラルネットワーク一般の量子化についても過去のブログ記事で解説しています。量子化にご興味のある方はそちらもあわせてご覧ください。
ニューラルネットワークの量子化
ニューラルネットワークにおける量子化とは、通常は浮動小数点数として扱われるニューラルネットワークの重みと出力を、整数(int8など)と少数のパラメータで近似する手法のことを言います。
量子化を行うメリットは二つあります。一つ目のメリットとして、重みの量子化により、推論時のメモリ消費量とモデル保存時のファイルサイズを削減できます。二つ目のメリットとして、推論の高速化・省電力化が実現できます。多くのディープ・ニューラルネットワークでは、メモリアクセスが電力消費の支配的な要素となっていますが、量子化によってメモリアクセスの効率を改善できるため、大幅な省電力化が期待できます(例えば32ビットから8ビットへの量子化の場合、メモリアクセスの効率は4倍向上します)。また、浮動小数点数の演算よりも、int8のような整数演算の方が高速に実行できます。量子化によるメモリアクセスの効率向上・整数演算の恩恵により、一般的には2~3倍の高速化が期待できるとされています[1]。さらに、整数演算に特化したアクセラレータ(EdgeTPUなど)を利用することで、量子化したモデルをさらに高速かつ省電力に実行することも可能です。
一方で、量子化誤差(浮動小数点数を少ないビット幅で近似することによる丸め誤差)によって少なからずモデルの精度が低下するというデメリットがあります。特に、物体検出モデルなど比較的複雑なモデルは(本記事の後半で行う実験のとおり)量子化で精度が低下しやすい傾向にありますが、量子化による精度低下の原因を理解した上で適切な手法を選択すれば、精度低下を緩和することが可能です。
以降では、物体検出モデルの量子化による精度低下の原因を考察します。また、YOLOv3とYOLOv5の量子化を例に、精度低下を緩和するための具体的なテクニックを紹介します。
(注)過去のブログ記事でも触れている通り、学習時から量子化を考慮してモデルの重みを最適化する手法(quantization-aware training)もありますが、本記事ではより手軽に利用できる学習済みモデルに対する量子化(post-training quantization)を前提にします。その中でも、キャリブレーションデータを用いて量子化パラメータを予め計算しておくpost-training static quantizationによる量子化を考えます。
per-tensor量子化とper-channel量子化
量子化による精度低下を考察するための前提知識として、まず、ニューラルネットワークに対して量子化がどのように適用されるのかを解説します。
ある浮動小数点数x(例えばモデルの重みや出力)を整数値qに量子化するとき、xとqの関係は式(1)のように表されます。
ここで、Z・Sは量子化パラメータであり、それぞれゼロ点・スケールと呼ばれます。量子化パラメータの決定には様々なアルゴリズムが用いられますが、最も単純な方法としては、量子化したい値xの最小値と最大値(キャリブレーションデータに対する推論結果から推定される)が、量子化後の最小値と最大値(int8の量子化であれば0~255)に対応するように量子化パラメータを設定するというものです。効率化のため、量子化パラメータは各層の重みや出力ごとに共通の値が使用されるのが一般的です。
物体検出モデルの精度低下を考察する上で重要な概念として、per-tensorの量子化とper-channelの量子化があります。per-tensorの量子化では(各層の重みテンソルや出力テンソルといった)テンソル全体で一つの量子化パラメータを共有するのに対し、per-channelの量子化ではテンソルのチャネルごとに量子化パラメータが割り当てられます。per-channelの量子化はper-tensorの量子化に比べて量子化誤差を小さくできますが、推論時のパフォーマンス改善のため、各層の出力に関してはper-tensorの量子化が行われるのが一般的です[1]。TensorFlow LiteやPyTorchの量子化機能では、モデルの重みに関してはper-channelの量子化、出力に関してはper-tensorの量子化を採用しています[2][3]。
図1は、畳み込みニューラルネットワークにおいて、出力をper-tensorで量子化、重みをper-channelで量子化したものです。出力に関しては、3次元の出力テンソルに対して量子化パラメータが一つだけ設定されています。一方で、重みに関しては、4次元の重みテンソルの出力チャネルごとに(つまり畳み込みフィルタごとに)量子化パラメータが割り当てられています。
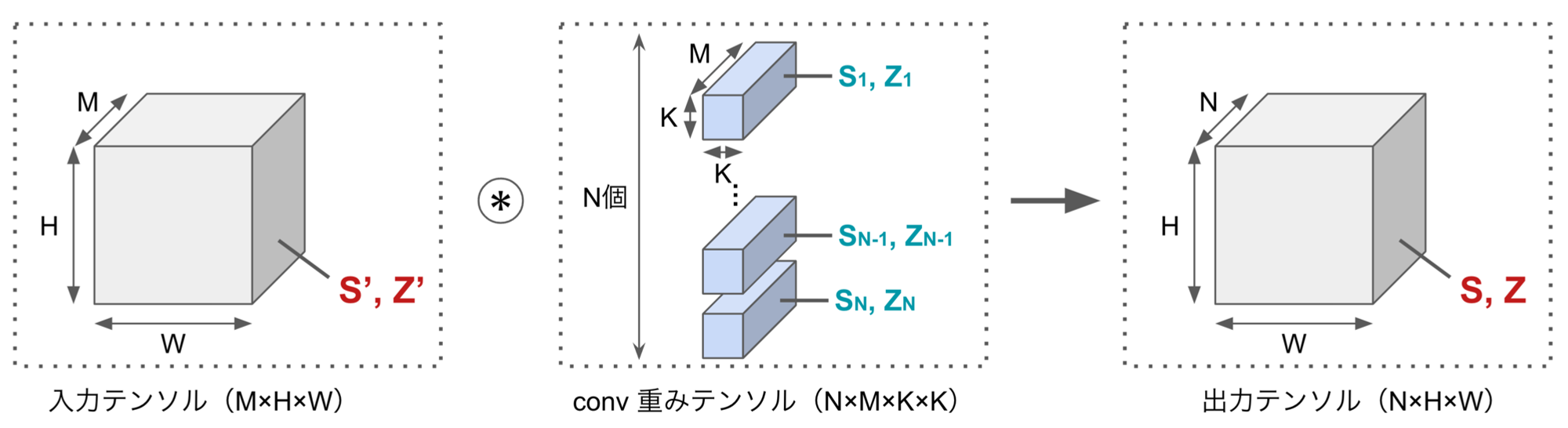
図1. 畳み込み層について、出力をper-tensorで量子化、重みをper-channelで量子化したときのイメージ(S, Zは量子化パラメータのスケールとゼロ点)
per-tensor量子化は物体検出モデルの精度低下を起こしやすい
上で述べたとおり一般的には各層の出力はper-tensorで量子化され、モデルの最終層の出力に関しても同様にper-tensorの量子化が適用されます。この最終層の出力に対するper-tensor量子化こそが、物体検出モデルの精度低下を引き起こしています。
一般に、物体検出モデルの最終層は検出したbbox(bouding box)に関する様々な情報(bboxのx, y, w, h, objectness, class score)をチャネルに分けながら一つのテンソルとして出力します。図2の右側に示すとおり、情報の種類ごとに(つまりチャネルごとに)取りうる値の範囲は異なります。このテンソルに対してper-tensorの量子化を適用した場合、全てのチャネルを内包するような広い範囲を一つの量子化パラメータで量子化するために量子化誤差(量子化による丸め誤差)が大きくなり、検出精度の低下を引き起こします。
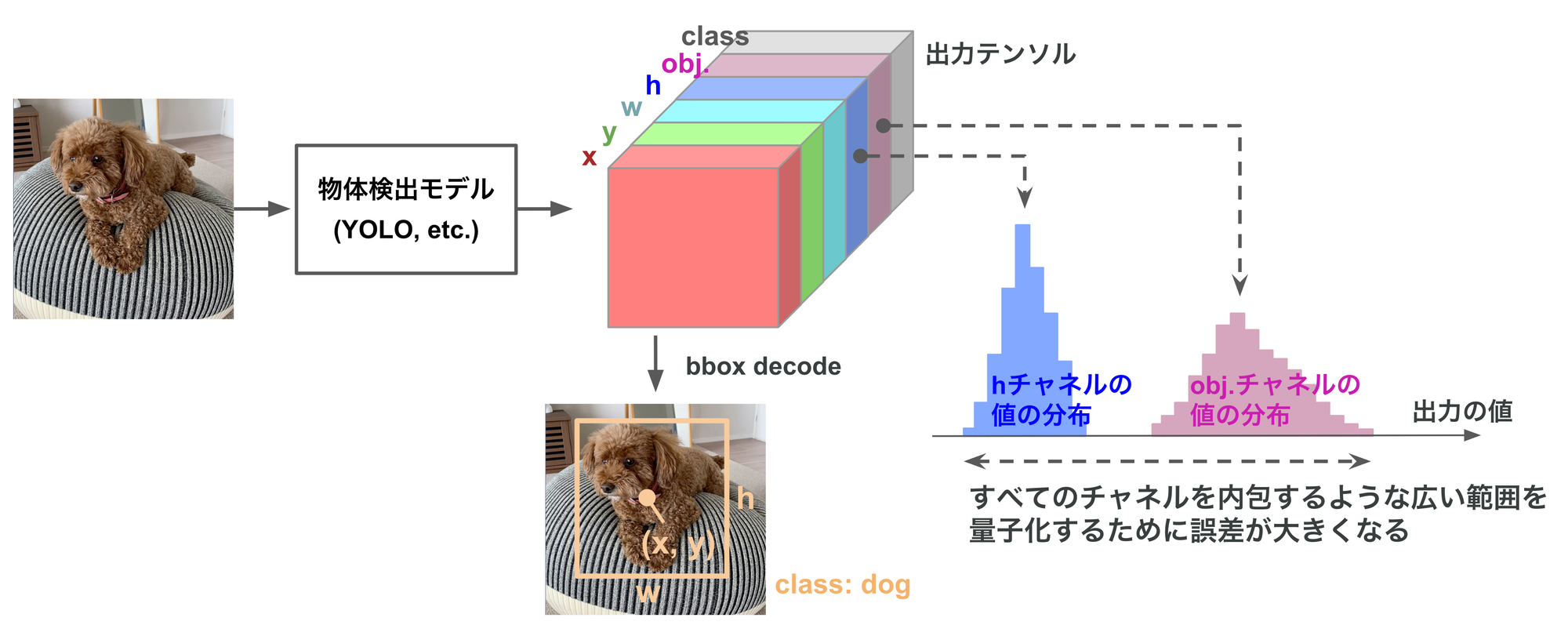
図2. 検出モデルの最終層の出力をper-tensorで量子化した場合、値域が異なる全てのチャネルを内包するような広い範囲を量子化するため、量子化による丸め誤差が増大する
したがって、物体検出モデルの量子化による精度低下を緩和するためには、モデルの最終出力においてはテンソル内の各チャネルで値の範囲をなるべく揃える のがポイントとなります。以降では、YOLOv3とYOLOv5を実際に量子化しながら、上記のポイントにもとづいた精度低下を緩和するための具体的なテクニックをご紹介します。
実験1:YOLOv3の量子化
実験として、物体検出モデルのOSS mmdetectionに実装されたYOLOv3[4]をPyTorchの量子化機能でint8に量子化してみました。表1は、COCOデータセットで量子化前後のモデルを評価した結果です(1行目が量子化前、2行目が量子化後)。量子化によって、YOLOv3の検出精度(mAP)が15.8%低下するという結果になりました。
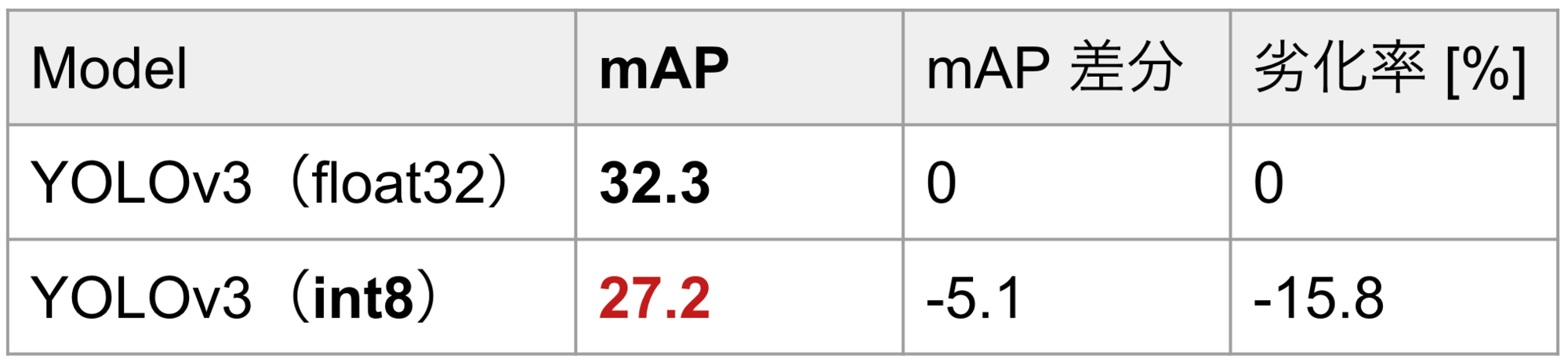
表1. MS COCO 2017 val でのYOLOv3の評価結果(入力サイズ608×608)
精度低下の原因を探るため、最終層の出力テンソルについてチャネルごとに値の分布を可視化してみたところ、図3のようになりました(左側がxとyチャネルの分布、右側がwとhチャネルの分布)。横軸の範囲は左右で共通なので、xとyの分布に比べ、wとhの分布は非常に狭い範囲に集中していることがわかります。上で述べたとおり、このようなチャネルごとに値域が大きく異なるテンソルにper-tensorの量子化を適用した場合、xとyの分布に合わせた広い範囲で量子化が行われるため、特にwとhの量子化誤差が大きくなることが予想されます。
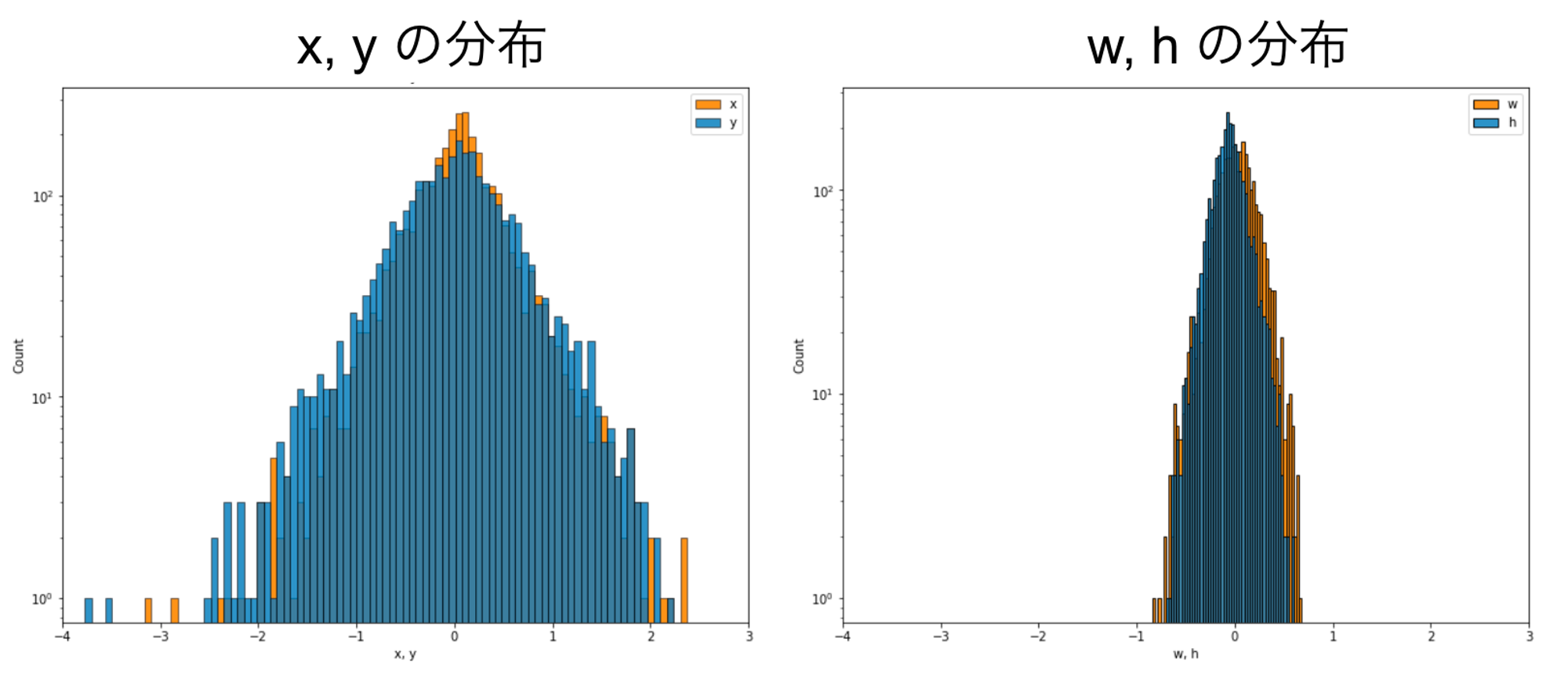
図3. 量子化前のYOLOv3について、最終層の出力テンソルの x, y, w, h チャネルの分布を可視化したもの(横軸の範囲は共通)
実際、モデルによって推論されたbboxの分布を量子化前後で比較すると、図4のようになります(左側がxの分布、右側がwの分布)。オレンジが量子化前の分布、ブルーが量子化後の分布ですが、両者を比較すると、xに比べてwは量子化による分布の変化が顕著であり、wの量子化誤差がかなり大きいということがわかります。
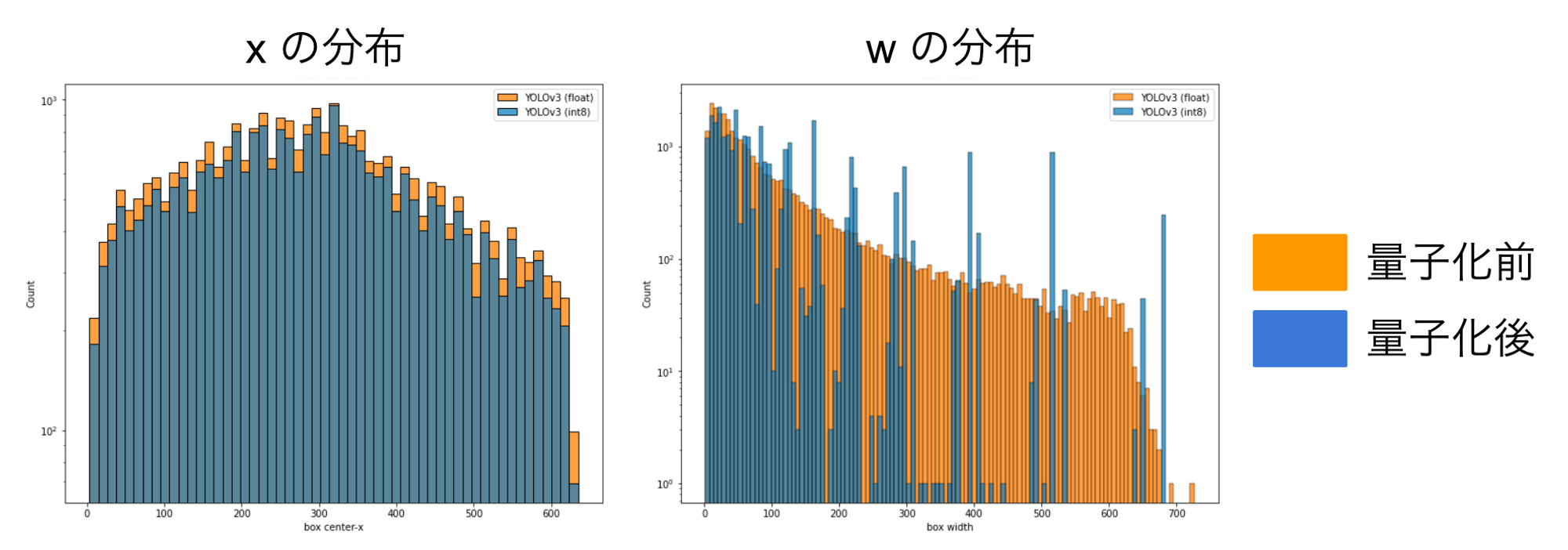
図4. 推論された bbox の x, w の分布を量子化前後で可視化したもの(xと比べてw は量子化による変化が顕著で、量子化誤差が大きいことがわかる)
余談ですが、図3のようにw, hとそれ以外のチャネルで値の範囲が大きく異なるのは、最終層の非線形関数の違いが一因として考えられます。YOLOv3の最終層では、wとhでは指数関数、それ以外のチャネルではシグモイド関数が使われており、この違いが値の範囲を乖離させていると考えられます。
さて、上で述べたポイント「モデルの最終出力においてはテンソル内の全てのチャネルで値の範囲をなるべく揃える」にもとづいて、YOLOv3の精度低下を緩和できないかを考えます。このポイントを逆に考えると、値の範囲が異なるチャネルについては別のテンソルとして分割してしまえば良い、ということになります(個別のテンソルに分割することでそれぞれに最適な範囲で量子化がなされるため、量子化誤差を抑制できると考えられます)。具体的には、図5のように、モデルの最終層(最後の畳み込み層)を、w, hチャネルを出力するフィルタ・それ以外のチャネルを出力するフィルタに分離することで、それぞれに適した範囲で量子化がなされるようにします。
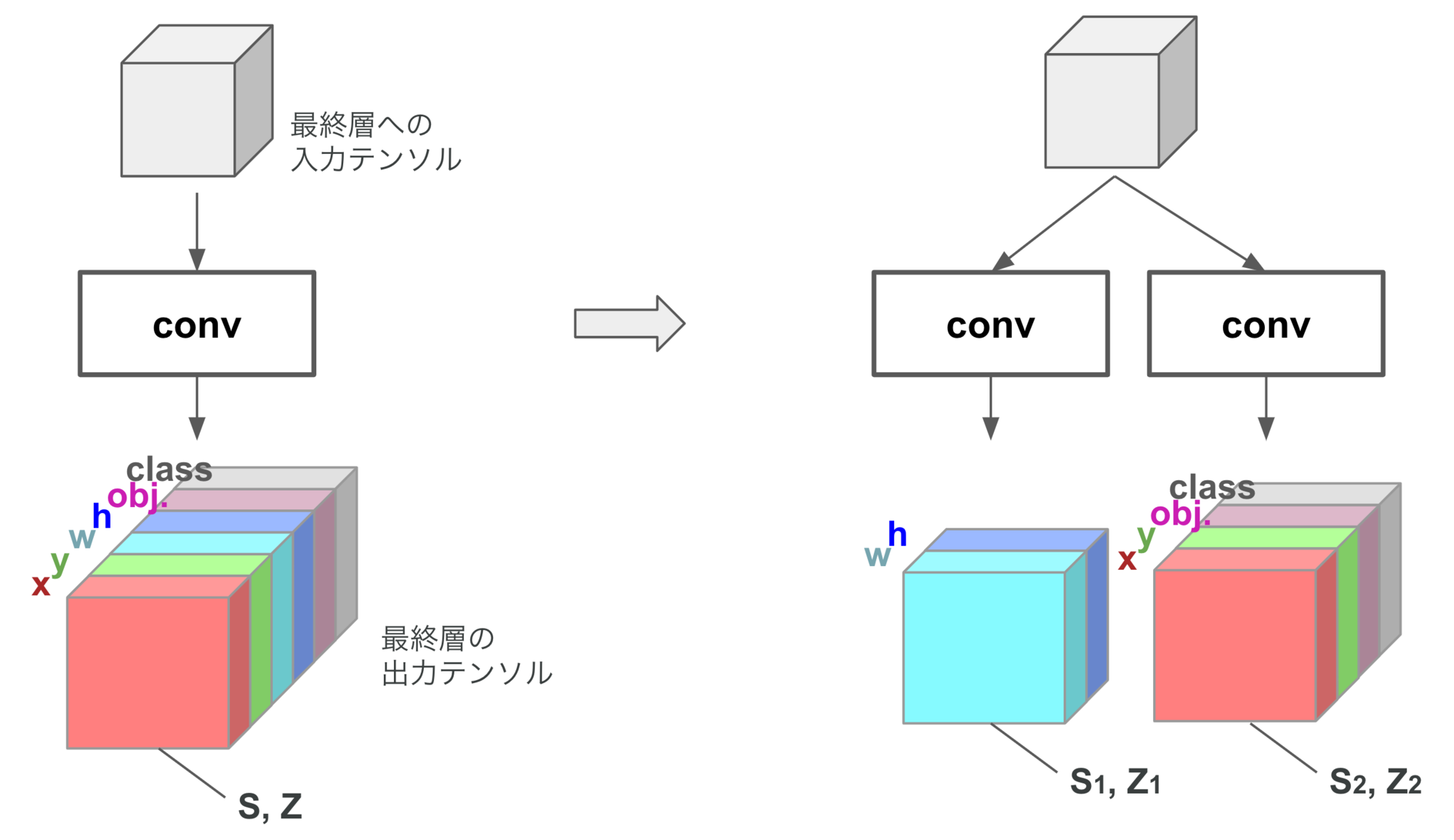
図5. YOLOv3の出力テンソルのper-tensor量子化に起因する精度低下を緩和するため、値の範囲が大きく異なるw, hのチャネルを別のテンソルとして分割する
最終層を分離して量子化したYOLOv3の評価結果を、表2の最終行に示します。量子化によってmAPに15.8%の低下が生じていたところ、最終層を分離してから量子化することにより、mAPの低下を4.1%まで緩和することができました。また、表2の最右列にはレイテンシを示していますが、最終層を分離してもレイテンシに有意な増加はなく、推論速度を犠牲にすることなく精度を大幅に改善できていることがわかります。
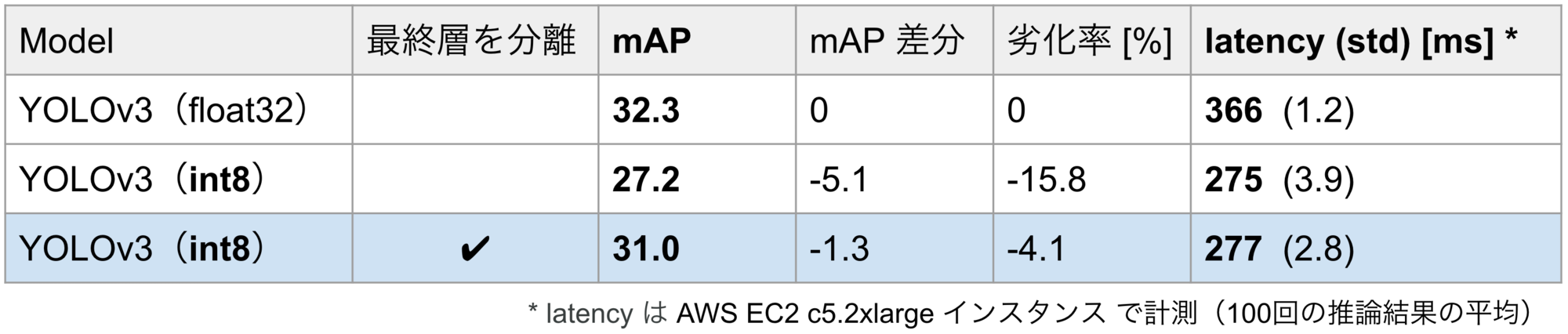
表2. MS COCO 2017 val でのYOLOv3の評価結果(入力サイズ608×608)
実験2:YOLOv5の量子化
続いて、YOLOv5[5]をTensorFlow Lite(TFLite)で量子化する実験を行いました。実験に使用したOSS ultralytics/yolov5では、PyTorchで学習したYOLOv5をTFLiteに変換しint8量子化することができます。
表3に、量子化前後でYOLOv5sをCOCOデータセットで評価した結果を示します。1行目が量子化前、2行目が量子化後で、量子化によってmAPが13.4%低下しています。
また、3行目は(YOLOv3の量子化に適用したような)最終層の分離をして量子化したモデルですが、mAPが11.8%低下しています。YOLOv3では最終層の分離によってmAPの低下を4.1%まで緩和できたにもかかわらず、YOLOv5ではmAPがほとんど回復していません。この原因として、最終層の非線形関数の違いが挙げられます。YOLOv3では、wとhのチャネルに関しては指数関数、それ以外のチャネルに関してはシグモイド関数が使われているのに対して、YOLOv5では全てのチャネルにシグモイド関数が使われています。したがって、YOLOv5では、YOLOv3(図3)でみられたような、w, hのチャネルとそれ以外のチャネルの分布の違いがもともと小さく、最終層の分離の効果が小さかったと考えられます。
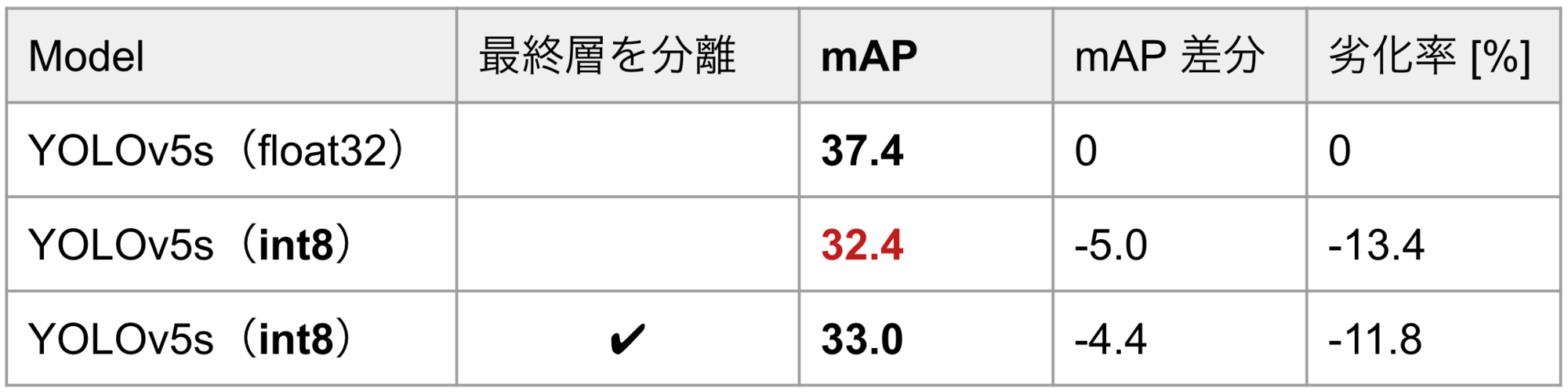
表3. MS COCO 2017 val でのYOLOv5の評価結果(入力サイズ640×640)
では、精度低下の原因はどこにあるのでしょうか?結論から言ってしまうと、bboxのdecodeの計算が量子化されているのが原因になります。実験に使用したYOLOv5の実装では、図6の左側のように、bboxのdecode処理も含めて量子化がされています。一般にdecodeではチャネルごとに異なる計算が行われ、チャネル間の分布の乖離を拡大させます。例えば、w, hに対するdecode処理ではチャネルごと異なるサイズのアンカーが掛け算される(具体的な実装はこちら)ため、図6の中央に示したように、値の範囲がチャネルごと違ったものになります。このようにdecode後のテンソルでは、チャネルごと値の範囲が大きく異なったものとなるため、per-tensorの量子化による量子化誤差が大きくなります。
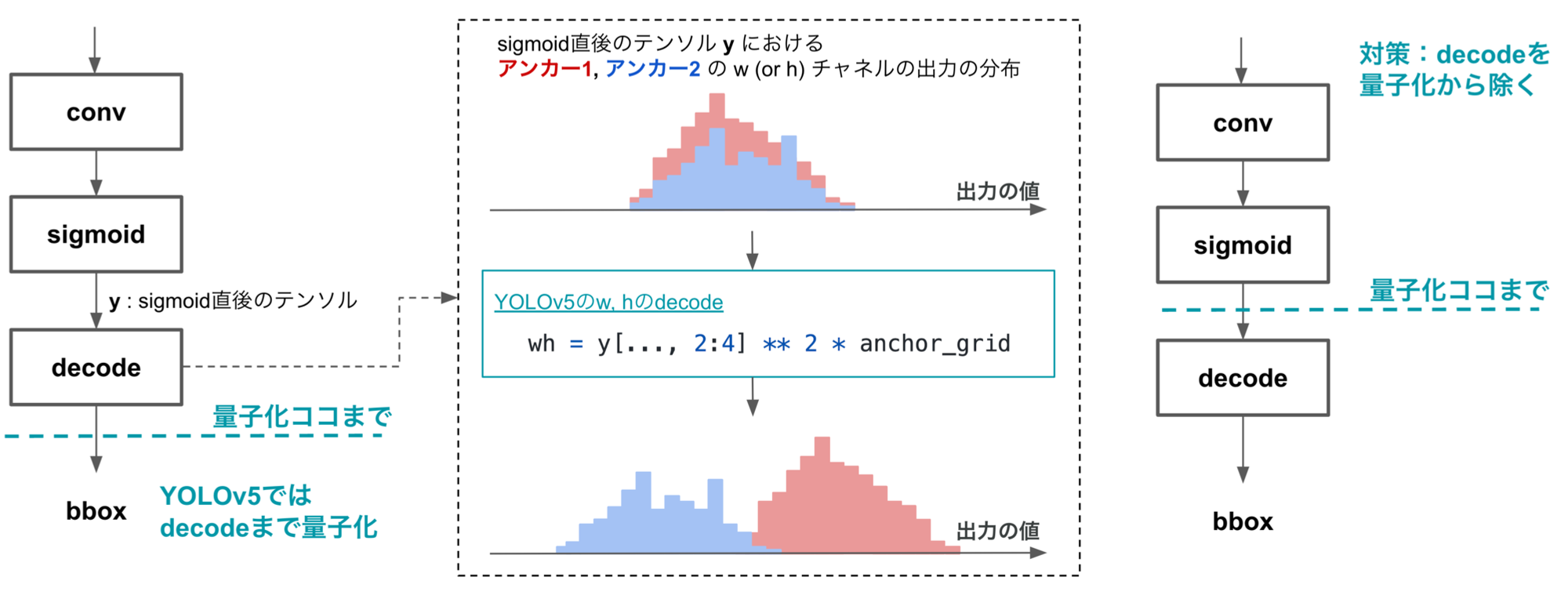
図6. YOLOv5ではbboxのdecode演算も含めて量子化されるが、decodeはチャネル間の分布を乖離させ量子化誤差を拡大するため、decodeは量子化から除外することが望ましい
decodeの量子化による精度低下を緩和するため、decodeを量子化対象から除外した上で、再びYOLOv5を量子化しました。その結果を表4の4行目以降にまとめます。decodeを量子化から除外することで、mAPの低下を13.4%から5.1%まで緩和することができました。さらに、最終層の分離を併用することで、mAPの低下を3.0%まで緩和できました。表4の最右列にはレイテンシを示していますが、decodeを量子化から除外してもレイテンシにほぼ変化はなく、推論速度を犠牲にすることなく精度を大きく向上できていることがわかります。
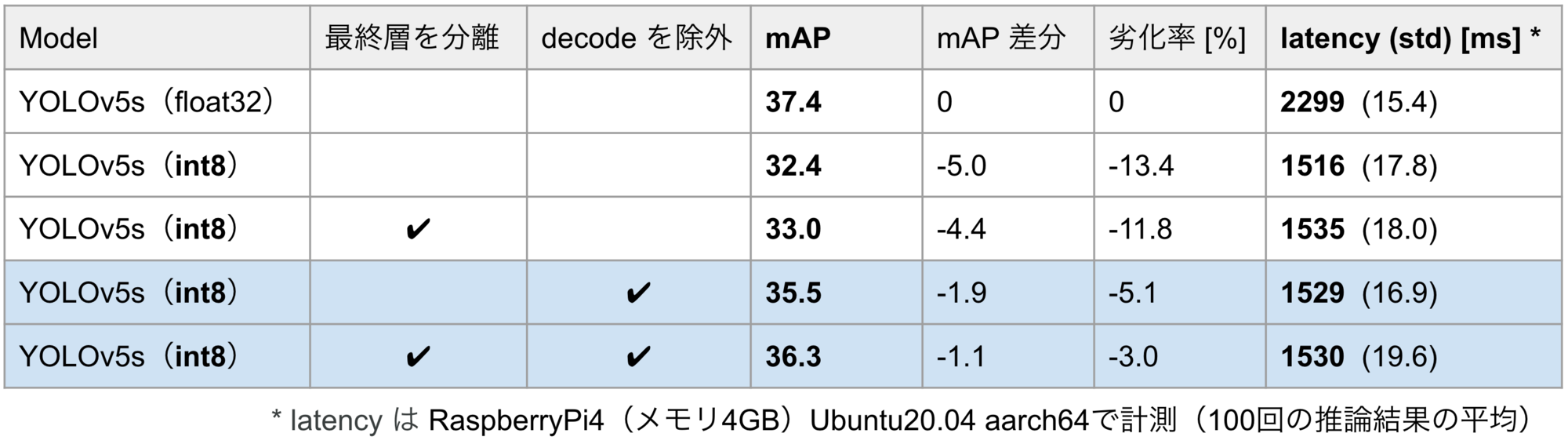
表4. MS COCO 2017 val でのYOLOv5の評価結果(入力サイズ640×640)
このbbox decodeの量子化による精度低下は、YOLOv5というモデル(手法)の問題というよりは実装上の問題であり、YOLOv5以外の物体検出モデルであっても発生しうるものです。decode演算に限らず、チャネル間の分布の乖離を大きくするような演算は量子化から除外することが望ましいでしょう。
まとめ
以上の内容を箇条書きでまとめます:
- 量子化はニューラルネットワークを軽量化・高速化する強力な手法である
- 量子化には様々な方式があるが、推論時のパフォーマンスを向上するため、モデルの各層の出力はper-tensorで量子化されるケースが多い
- 物体検出モデルの最終層はbboxに関する色々な情報をチャネルに分けながら一つのテンソルとして出力するが、情報ごとに値の範囲が異なるため、per-tensorの量子化では量子化誤差が大きくなりやすい
- YOLOv3とYOLOv5を実際に量子化しながら、物体検出モデルの精度を保ちつつ量子化するテクニックの一例を紹介した:
- 最終層について、出力値の範囲が大きく異なるチャネルを別のテンソルとして分割する
- チャネル間の分布の乖離を大きくするような演算(例えばbbox decode)は量子化から除外する
本記事では、物体検出モデルの量子化に伴う精度低下について、精度低下を緩和するための具体的なテクニックをご紹介しました。量子化は、物体検出モデルをはじめ画像認識モデルをエッジに搭載する上で非常に有用な手段であり、今後も注目していきたいと思います。
MoTには、AIドラレコを活用した交通事故削減支援サービス「DRIVE CHART」や「道路情報の自動差分抽出プロジェクト」といったコンピュータビジョン技術をコアとして社会課題の解決に取り組むプロジェクトがあります。これらのプロジェクトでは高精度なモデルを開発するだけではなく、それらのモデルの高速化・軽量化にも取り組んでいます。
ご興味のある方はぜひ CVエンジニア(コンピュータビジョンエンジニア)のポジションもご覧ください!
参考文献
[1] Raghuraman Krishnamoorthi. Quantizing deep convolutional networks for efficient inference: A whitepaper. arXiv:1806.08342, 2017.
[2] TensorFlow Lite 8-bit quantization specification. https://www.tensorflow.org/lite/performance/quantization_spec. accessed on 1 June 2022.
[3] PyTorch Docs Quantized Tensors. https://pytorch.org/docs/stable/quantization.html#quantized-tensors. accessed on 1 June 2022.
[4] Joseph Redmon and Ali Farhadi. YOLOv3: An incremental improvement. arXiv:1804.02767, 2018.
[5] ultralytics YOLOv5 in PyTorch, https://github.com/ultralytics/yolov5. accessed on 1 June 2022.
We're Hiring!
📢
Mobility Technologies ではともに働くエンジニアを募集しています。
興味のある方は 採用ページ も見ていただけると嬉しいです。
Twitter @mot_techtalk のフォローもよろしくお願いします!