

深層学習ライブラリと量子化
AIDeep LearningQuantizationはじめまして、AI技術開発部の亀澤です。
AI技術開発部では様々な機械学習モデルの開発に加えて、車載デバイスやクラウド上でDeep neural network (DNN)を使ったリアルタイムな予測を行うための、DNNの高速化や軽量化にも取り組んでいます。
この記事では、エッジデバイスでDNNを動かす上で、高速化、軽量化に効果があるDNNの量子化について次の3点について説明していきます。
- 量子化について
- 量子化の詳細と分類
- DNNライブラリの量子化への対応状況
- TensorFlow
- PyTorch
- TVM
量子化について
ニューラルネットワークにおける量子化とは、通常、浮動小数点数として扱われる値を、整数と少数のパラメータで表現する手法一般のことを指します。もとの浮動小数点数 と量子化された値 の間の関係は二つの量子化パラメーター(オフセット(バイアス、ゼロ点)offset, スケール scale)を用いて、次のようになります。
ここでoffsetは整数、scaleは実数(浮動小数点数)で、これらのパラメーターを決定するために様々なアルゴリズムが用いられます。例えば、量子化したい値の最大値と最小値が量子化後の最大値と最小値に対応するように、オフセットとスケールを計算する方法が最も単純でよく用いられます(下図: 簡単のため5値への量子化)。量子化パラメータはweightやbiasごと、中間層の出力ごとに共通した値を用いるのが一般的です。また、単精度(32 bit)浮動小数点数を半精度(16 bit)浮動小数点数に変換することも量子化と呼ばれる場合がありますが、今回は量子化といったら整数への変換のことを指すものとします。
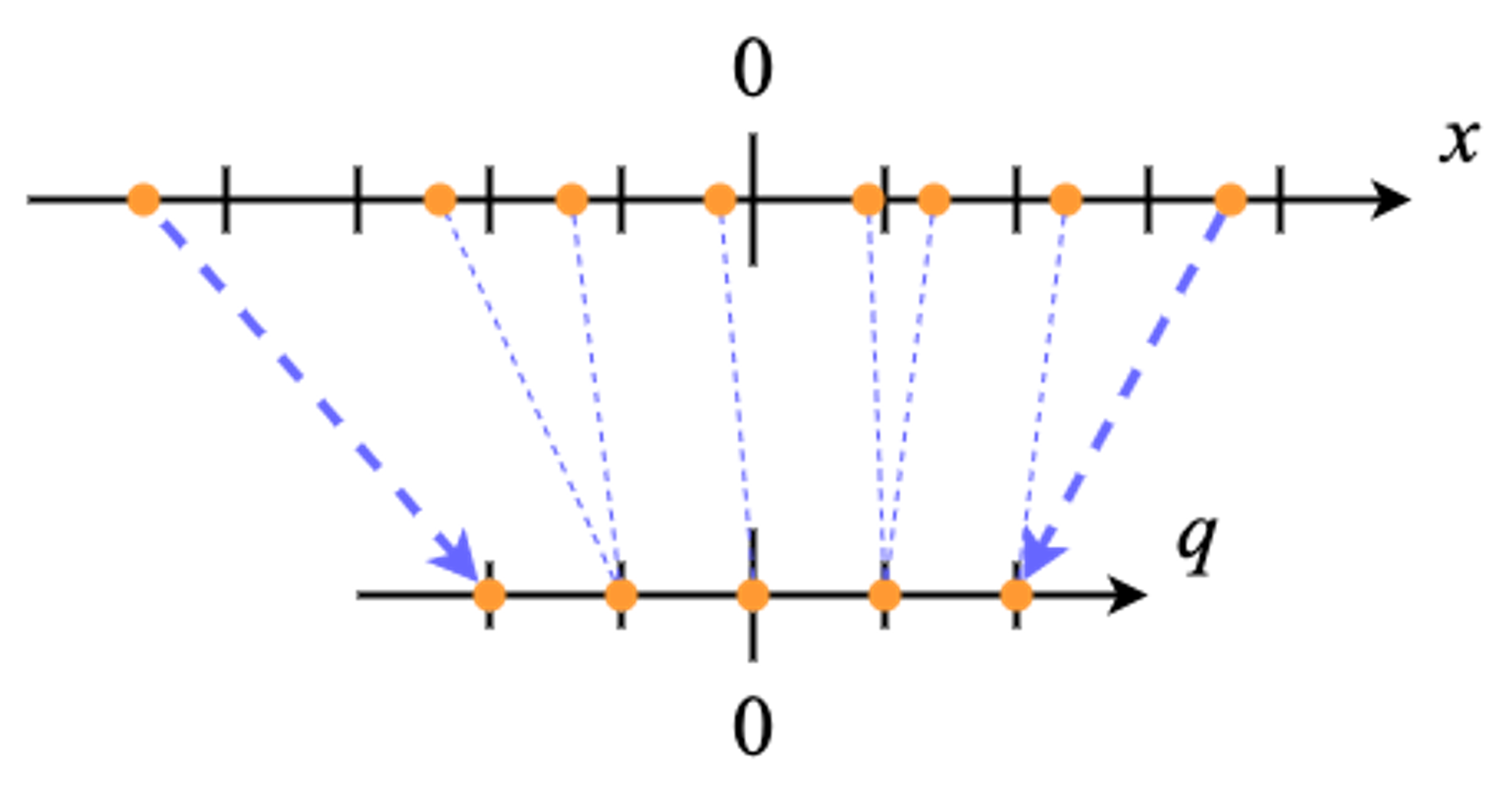
量子化を行うことのメリットは主に二つあります。まず一つ目は、weightを量子化して表現することによる、実行時のメモリ消費量、保存時のファイルサイズの削減です。例えば、32 bitの浮動小数点数を8 bit整数を用いて表現することを考えると、weightのサイズは4分の1になります(量子化パラメーターは複数の値に対して同一なため、weight自体に比べると、ほぼ無視できるサイズになります)。量子化を行うことで、次のようなことが可能になります。
- モデルサイズの大きさによりメモリ転送がボトルネックになっている場合のGPU推論の高速化 (一度にGPUメモリに載るモデルのパラメーター数の増加)
- モデルサイズ削減による、保存コストの削減
- 通信コストの削減による、高頻繁なエッジデバイスへのモデルの配信
二つ目は実行の高速化、省電力化です。一般に浮動小数点数の演算は整数の演算に比べて低速で、消費電力も大きいですが、DNNで行われるような基本的な演算に関しては、量子化したあとの整数表現のまま(浮動小数点数を経由せずに)計算することが可能なため、実行の高速化、省電力化が期待されます [Jacob et al.]。また、一部のアクセラレーター(e.g. EdgeTPU, Hexagon DSP)では、整数演算に特化し、量子化したモデルを高速に実行します。このような場合、アクセラレーターの性能を最大限活かすためには量子化を行うことが必須となります。
一方で量子化することによって生じる問題もあります。もともと浮動小数点数で表現されていた数値をより少ないbit数の整数で表現するので、丸めによる誤差は避けられません。また、浮動小数点数は表現可能な値の範囲が広いのに対し、少数bitの整数では表現可能な値の範囲は限られます(正確には、丸め誤差と値域はトレードオフの関係になっていて、上述のscaleパラメーターによってコントロールされます)。この量子化によって生じる誤差はレイヤー数の増加に伴って増えていくため、DNNの出力ではかなり大きな誤差となってモデルの性能劣化につながります[Lin et al.]。しかし、後述するようなper-channel quantizationやqunatization-aware trainigによって、量子化しても元のモデルと遜色ない性能になる場合もあります。
量子化の詳細と分類
ここからはより詳細に、量子化のフォーマットやアルゴリズムについて、どういう軸で分類ができるのかという観点で説明します。これらの分類は後述のDNNライブラリによっていずれかを選択できたり、あらかじめ決められていたりするため、ライブラリの互換性や性能の比較を考える上で重要になってきます。
Quantized Format (Bit数 / Signed or Unsigned)
まず最初に、量子化したあとの整数のbit数と符号付か符号なしか、という側面で分類できます。bit数に関しては、一般的に用いられるのは8bitの整数です。また、部分的に16bitの整数が用いられる場合もあります。符号の有無に関してはどちらも使われる場合があります。
Symmetric or Asymmetric
符号つき整数に量子化する際に、元の浮動小数点数の0を量子化後の整数の0に対応させるような方法を対称(symmetric), そうではない方法を非対称(asymmetric)といいます。対称な量子化は最初の式 (1) でoffsetが0であるような場合です。一般に量子化したい値の範囲が0を中心に対称に分布するとは限らないので、非対称な方法の方が元の値をより正確に表現することができるため好ましいですが、計算コストの観点から見るとoffsetが0に固定されていた方が良いのでどちらも用いられます。
Per-tensor or Per-channel (per-axis)
量子化は一般的にテンソル(weight, bias, activation)ごとに行います。このテンソルごとに量子化パラメータ(offset, scale)を決める方法(per-tensor)に対して、テンソル内のchannel (axis)ごとにそれぞれ別の量子化パラメータを決める方法(per-channel, per-axis)もあります。channelごとに量子化することによって保存する必要のある量子化パラメータはchannel数倍に増えますが、より正確に元の値を表現することができるので、量子化誤差が少なくなることが知られています [Krishnamoorthi]。
Static or Dynamic
何を量子化するかには大きく分けて2種類あります。一つが重み (weight)、もう一つが中間層 (activation)です(activationと呼ばれる場合が多いですが、実際には活性化関数の出力だけでなく、畳み込み層や全結合層の出力も全て量子化されるので中間層と言い換えています)。
モデルを量子化する場合、重みについては常に推論前に量子化されます。これによってメモリ消費量、ファイルサイズを小さくすることができます。一方、中間層については予め、量子化パラメーターを計算しておく方法と、推論時に動的に量子化パラメーターを求め、計算する方法の2種類があります。前者が静的量子化(static quantization)、後者が動的量子化(dynamic quantization)と呼ばれます。
静的量子化の場合は、全ての中間層について予め量子化パラメーターが求められるため、ほとんど全ての計算が整数演算で完結し、高速に推論できます。しかし、量子化パラメーターが全ての入力に対して固定されているので量子化誤差が大きくなる可能性があります。また、事前に量子化パラメーターを決定するためには代表データ (representative data, calibration data) と呼ばれる、入力空間全体を代表するような入力データの集合を準備する必要があります。経験的には数百データで十分だと言われていますが、これが偏っているとモデルの性能劣化に繋がります。
動的量子化では、各レイヤーが内部的に量子化、計算、浮動小数点数への変換を行うような実装になるので、量子化に対応したレイヤーと対応していないレイヤーを混ぜて使うことができます。また、代表データは必要としないので、手軽に試すことができます。しかし、レイヤーごとに、量子化して、計算を行い、浮動小数点数に戻すという操作を繰り返すので、実行時のオーバーヘッドは大きくなります。
Post quantization or Quantization-aware training
ここまでの説明では量子化すべき値は予め決まっている、すなわち学習後に量子化を行うことを想定していましたが、量子化に合わせてweightの値を学習する方法もあり、これは量子化を考慮した学習(quantization-aware training)と呼ばれます。それに対して学習後に固定されたネットワークを量子化する方法は学習後量子化(post quantization)と呼ばれます。量子化を考慮した学習では浮動小数点数で従来通り学習を行ったあと、fine-tuningとしてforward時に量子化した値を伝播させ、勾配伝播はもとの浮動小数点数を使って行うようなモデルに変換して学習を行います。これはfake quantizationと呼ばれ、このように量子化を考慮した学習をすることで量子化によって引き起こされるモデルの性能劣化を抑えられることが知られています [Krishnamoorthi]。
DNNライブラリの量子化への対応状況
最後に主なDNNライブラリがどのように量子化を行っているのかを比較してみます。2020年8月現在の情報をもとにしていますが、まだ量子化に関する仕様やAPIは不安定なものも多いため、正確ではなくなる可能性があります。
TensorFlow (TFLite)
TensorFlowでの量子化は主にTensorFlow Lite (TFLite)を使って行われます。TFLiteはTensorFlowで学習したモデルをデプロイすることに特化した専用のモデルフォーマット、推論エンジン、変換ツールなどから構成されます。TFLiteでは量子化のフォーマットなど一部の項目は固定されており、以下のようになっています。
- Quantization format: int8 (8bit 符号付き整数)
- Symmetric or Asymmetric: 中間層は非対称, 重みは対称
- Per-tensor or Per-axis: 畳み込みの重みは軸ごと, それ以外はテンソルごと
そして、現在サポートしている量子化の方法には3種類あります。
Post-training dynamic range quantization
これが最も簡単な量子化の方法です。一旦学習したモデルが得られたら、コード上は数行の追加で量子化することができます。しかし、モデルによっては性能劣化が見られる場合もあるので注意が必要です。また、整数演算に特化したEdgeTPUやHexagon DSPなどのハードウェアアクセラレーターで動かす場合にはこの方法は使えません。(example)
Post-training integer (static) quantization
この方法では中間層も含めて全て事前に量子化し、全ての計算を整数演算のみで完結させることができるため、高速に実行できます。中間層を量子化するために、代表データを用意する必要がありますが、こちらも比較的簡単に量子化することができます。ただし、重みに加えて中間層も固定された値で量子化するため、モデルによっては、量子化誤差がdynamic range quantizationよりも大きくなる可能性があります。(example)
Quantization-aware training
学習後量子化ではモデルの性能に問題がある場合は、量子化を意識した学習を行うこともできます。そのためにはfake quantizationに対応したモデルに変換してfine tuningをする必要がありますが、モデル変換のAPIがKeras modelにしか対応していないので、そうではないlow-level APIを使ったモデルはfake quantizationに対応したモデルに自前で変換する必要があります。(example)
PyTorch
PyTorchでも量子化への対応は進んできています。TensorFlowの量子化はTFLiteを中心とした機能になっているため、TensorFlowとは異なるAPIを持ち、異なるランタイムで動きますが、PyTorchは量子化されたモデルも量子化前のモデルと同じAPIをもつため、比較やデバッグなどは容易です。PyTorchでもできることはTensorFlowと大きく変わりませんが、細かい仕様の違いは存在します。量子化フォーマットは基本的に以下のようになっています。
- Quantization format: 重みはint8, 中間層はuint8 (符号なし)
- Symmetric or Asymmetric: 選択可能(moduleによって制限あり)
- Per-tensor or Per-axis: 畳み込みと全結合層の重みは軸ごと、それ以外はテンソルごと
PyTorchの量子化APIには上記のようなフォーマットを設定できるQConfigというクラスがあり、対称かどうかや、量子化のアルゴリズムはある程度選択可能になっています。しかし、全ての組み合わせが利用可能な訳ではなく、バックエンドによっては対応していない組み合わせが存在するので注意が必要です。バックエンドはFBGEMM (x86) とQNNPACK (ARM) の2種類がサポートされており、実行環境によって適切な方が選択されます。
サポートしている量子化の方法自体はTensorFlowと同じです。
- Post-training dynamic quantization (example)
- Post-training static quantization (example)
- Quantization-aware training (example)
TVM
TVMは上の二つとは違い、学習のためのライブラリではなく、推論を多様なデバイスで高速に行うためのdeep learning compilerと呼ばれるフレームワークです。TensorFlowやPyTorchで学習されたモデルを入力として、目的のデバイスで高速に動作するように、計算のスケジューリングやメモリ上のデータ配置、キャッシュの制御などを人手で指定したり、それらのパラメーターの自動チューニング (AutoTVM) を行ったりといった、より低レベルでの最適化を行うことができます。TVMでも量子化への対応は進んできており、automatic integer quantizationとframework pre-quantized model conversionの2種類の方法を使うことができます。どちらの方法も上述のpost-training static quantizationに対応します。
Automatic integer quantization
これはDNNライブラリで学習済みの、量子化前のモデルを入力として、TVM側で量子化を行う方法です。デフォルトで次のフォーマットが使われます。
- Quantization format: int8
- Symmetric or Asymmetric: Symmetric
- Per-tensor or Per-axis: Per-tensor
対称な値への量子化のみ、テンソルごとの量子化のみ、にしか対応していないため、上述のTensorFlowやPyTorchでの量子化に比べると、精度劣化の可能性が高いです。(example)
Framework pre-quantized model conversion
こちらはDNNライブラリで学習、量子化されたモデルを入力とします。Automatic interger quantizationでは量子化フォーマットは限定的でしたが、こちらはDNNライブラリ(フロントエンド)に合わせた量子化フォーマットになります。現在サポートされているフロントエンドは以下の3つです。
- PyTorch
- TensorFlow
- MXNet
注意点として、量子化されたモデルを入力としたとしても、内部的な計算方法(実装)の違いによってDNNライブラリでの推論結果とTVMでの推論結果には誤差が生じます。そもそも、量子化をした時点である程度の誤差はあるのですが、浮動小数点数に比べ、量子化した整数での計算は細かい実装の違いによって簡単に誤差が増加するのでライブラリのユーザーは注意が必要です。(example)
最後に
今回の記事では量子化といくつかのDNNライブラリにおける現在の量子化の対応状況を俯瞰しました。量子化自体はモデルの軽量化や高速化が必須なエッジコンピューティングではメジャーになってきましたが、スタンダートなオペレーター以外は使えないなど、ライブラリ側での対応はまだ不完全な場合も多いです。これから充実していくであろう量子化への対応に向けて、理解の一助になれば幸いです。
また、Mobility Technologiesではチームメンバを募集しています。興味の在る方はぜひご連絡ください。
エッジAIエンジニア | 株式会社Mobility Technologies