

6.サーバーサイドの開発裏話 | GraphQLを本番投入して実感したメリットと課題
行灯LaboGraphQLServerSideDecember 26, 2018
💁🏻
※本記事は Mobility Technologies の前身である JapanTaxi 時代に公開していたもので、記事中での会社やサービスに関する記述は公開当時のものです。

今年9月のリニューアルで、JapanTaxiアプリ向けのAPIにGraphQLを導入しました。この記事では実際にGraphQL導入したことで感じたメリットと課題を書いていきたいと思います。
現在のJapanTaxiアプリにおけるGraphQLの導入状況
今回は数年間開発を続けてきたアプリのリニューアルプロジェクトということで、既存部分を使いまわしている部分も多々あり全てのAPIを一斉に置き換えるのは難しい状況でした。そのためリリース時点ではアプリの変更に合わせて改修が必要になった参照系のAPIにのみGraphQLを導入しました。 リリース後は順次RESTからGraphQLに切り替えを進めており、一部では更新系でもGraphQLを使い始めています。 Railsでgraphql-rubyを使って実装する場合、以下のように1つのコントローラからGraphQLのスキーマクラスを呼び出すだけのため、既存APIと容易に共存させることができます
class GraphqlController < ApplicationController
# POST /graphql
def execute
context = {
current_user: current_user
}
result = GraphqlSchema.execute(params[:query], variables: params[:variables], context: context)
render json: result
end
endGraphQL導入によって実感した価値
リクエスト数の削減
GraphQLのメリットとしてまず挙げられるのはhttpリクエスト数の削減です。GraphQLクエリによって複数のフィールドをまとめて取得することができるためRESTでは複数のAPIで定義されていたリソースを1リクエストで取得できるようになりました。 サーバサイドの汎用的なAPIを作ることで開発コストを下げたいというニーズとクライアントサイドの少ないリクエストで画面に必要な情報をすべて取得したいというニーズを両立できるようになりました。
テストの書きやすさ
前述の通りgraphql-rubyにおけるGraphQLの実装はすべてスキーマクラスとそれにつながる各種Typeクラスで完結します。 実際Railsはgraphql-ruby gemの依存関係に含まれておらず、Relay Connection関連の機能を使うときだけページネーションクエリを発行するためにActiveRecord等のORマッパを使用しています。そのためGraphQLのテストは実質このスキーマクラスをテストすれば良いことになります。JapanTaxiでは現状以下の方針でテストを書いています。
- request specでコントローラの実装を含んだ結合テストを記述 (ここは認証やcontextの準備などの共通部分のテストのため最初に一通りのテストを書いたら以後は基本的に変更はない)
- model specでスキーマクラスに対してクエリを流しレスポンスをチェックする単体テストを記述
- model specでスキーマから呼び出されるビジネスロジックの単体テストを記述 (ここはGraphQLとは直接関係しない)
つまり実質スキーマに変更があった場合は2番目のスキーマクラスに対する単体テストだけを書くという形になります。そのためテスト実行時間も早く、依存も少ないためテストも書きやすくなっています。 実際のテストでは以下のようにすべてのフィールドを列挙したクエリ文字列を流して結果が完全に一致するというケースを書きます。(条件分岐等がある型では追加でそのフィールドだけを確認するテストケースを追加します)
RSpec.describe Types::UserType do
example 'Userの情報を返す' do
user = create(:user)
query = <<-QUERY
query UserQuery($id: ID!) {
user(id: $id) {
id
name
}
}
QUERY
context = { current_user: user }
variables = { id: user.id }
result = Schema.execute(query: query, context: context, variables: variables)
expect(result.to_h.with_indifferent_access).to match(
data: {
user: {
id: user.id,
name: user.name,
}
}
)
end
endドキュメントの維持コストが低い
APIドキュメントの品質を維持することは常に悩みの種ですが、GraphQLではスキーマ自体にドキュメントを記述することができ、それをAPI経由で出力する仕組みが標準で備わっています。この情報を使うことで標準添付されているGraphiqlでAPI Exploreとドキュメントをはじめから利用することができます。またgraphdocなどを使うことで静的なhtmlとして出力することもできます。 これらのツールに加えて、graphql-rubyではスキーマ定義のDSLの中で直接ドキュメントを書けるため実装中にソースコードとドキュメント用ファイルを行き来する必要もなくコード上のコメントを書くのと同じレベルの心理的障壁でドキュメントを維持することができます。 また標準でdeprecation_reasonというオプションで特定のフィールドをdeprecated扱いにすることができます。これはAPIとしては引き続き参照可能ですが、Graphiql上ではクリックしないと見えない領域に隠されるようになります。廃止の理由や代替手段も合わせて記載できるため新規開発で誤って使ってしまうリスクを容易に下げることができます。
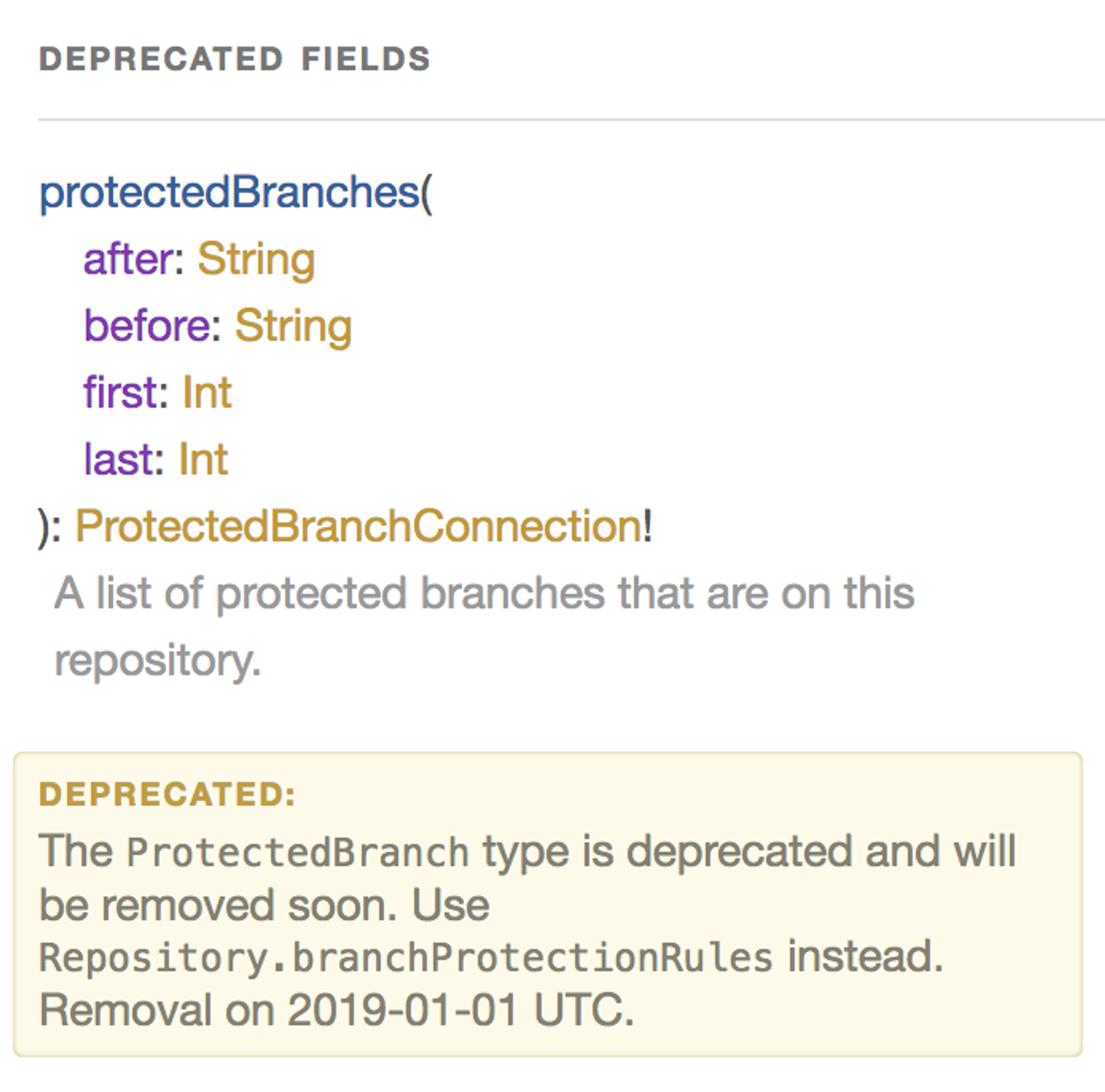
廃止されたフィールドの例 (GitHub)
GraphQL APIの開発開始から約半年経過した現在でも特に負担に感じることなくドキュメントを最新状態に維持できているためこの効果は大きかったと感じます。
再利用性の高さによる実装コストの削減
GraphQLで新しいAPIを追加する場合、Query型のフィールドとして、取得したい情報(レスポンスの型)と入力値を定義し、resolverとして実際にその情報を取得するための処理を書くという流れになります。
class Types::QueryType < Types::BaseObject
# フィールドの定義
field :user, Types::UserType, 'ユーザ情報', null: true do
argument :id, ID, 'ユーザID', required: true
end
# Resolverの実装 (クエリでフィールドが参照されると実行される)
def user(id:)
User.find_by(id: id)
end
end
# Resolverの評価結果(Userのインスタンス)が渡され、クエリに応じて各フィールドが評価される
class Types::UserType < Types::BaseObject
field :id, ID, 'ユーザID', null: false
field :name, String, 'ユーザ名', null: false
# ...
end導入当初は新しいAPIを作るたびに新しい型定義が必要になり、ユーザや注文といった複雑になりがちな型では実装コストが高く感じることもありましたが、徐々に実装済の型を別の条件で取得するようなAPIの実装が増えてくるとレスポンスに関しては既存実装をそのまま使えるため、データ取得部分の実装を書くだけでよく実装を進めるほど実装コストが下がっていくようになりました。 RESTで実装する場合も一見流れは同様ですが、ネストしたリソースをまとめて返したいという要件が発生した場合に状況が変わってきます。例えばブログサービスを考えた時に/postsではpostのデータだけで良いが、/posts/:idではリクエスト数を減らす目的でレスポンスにuserやcommentsも含めたいといった場合に、両者のレスポンス定義を共通化してしまうと/postsのレスポンスに不要なデータが大量に含まれてしまいます。この場合レスポンス定義をAPIごとに分けるか内部で条件分岐するなどの対応が必要になり再利用性が大きく下がってしまいます。 GraphQLではクエリによって必要なフィールドをクライアントが選択できるためパフォーマンスを気にすることなくネストしたフィールドを追加できます。
型定義による品質の向上
GraphQLでは戻り値の型を常に定義する必要があり、実行時に型と食い違うレスポンスを返そうとするとサーバサイドエラーになります。またgraphql-rubyではnullabilityも必ず明示的に指定する必要があります。 Rubyは動的型付け言語なこともあり意識していないとAPIレスポンスでもIntで返すべき値をStringで返してしまったり無頓着にnullを返してしまったりしがちです。これらの問題が型によって原理的に発生しなくなるため、前述のドキュメントと合わせてクライアント側で過剰に防衛的な実装をする必要が無くなりました。
GraphQL導入によって見えてきた課題
ここまではGraphQL導入によって得られたメリットでした。ここからは実際に本番環境で使うことで見えてきた課題です。
QueryTypeの肥大化
QueryTypeはすべての入り口になる型です。そのためフィールド定義とその実装が全て1つのクラスに入ることになりすぐに肥大化が始まります。ビジネスロジックの大半を別のモデルクラス等に追い出すことである程度の秩序は保てていますが現状これ以上の効果的な解決策がわからない状況です。
Enumの追加が非互換変更になり得る
これはGraphQL固有の問題というわけではありませんがEnum型の値を後から追加するとそれは非互換変更になる可能性があります。仮にクライアントサイドが既存のEnum値だけを想定した実装をしてしまっていると追加した値を返した際にクラッシュする可能性もあります。予めあらゆるEnum型は将来的に追加があり得ると想定してクライアントサイドで未知の値が来ても問題のない実装をしてもらうのが良いと思います。例えばApolloクライアントではUnknownという値を自動的に定義する形で対応されているようです。
パスを前提としたキャッシュやルーティング、モニタリングができない
現状大きな問題になっているわけではありませんが、GraphQLでは通常全てのリクエストが POST /graphqlというエンドポイントに送られるため、パスごとのキャッシュや性能のモニタリング、リバースプロキシでのルーティングが難しくなります。 モニタリングについてはgraphql-rubyだとtracing という仕組みを使ってフィールド単位の処理時間をモニタリングツールに送ることができるので今の所事足りていますが、New Relic等のモニタリングツール側に公式サポートがある事例はまだ見かけません。 またキャッシュやルーティングについても、GraphQLの処理の中で個別に実装する分には簡単に対応できますがRESTのように前段にhttpプロキシを置くような方式は現状だと難しいです。
まとめ
GraphQLを本番導入することで実感したメリットと課題についてまとめました。参照系の実装はほぼ終わりこれから更新系の実装に入っていくため、そこでまた新たな知見を共有できればと思います。
今回の記事はサーバサイド視点でのGraphQLについてまとめましたが、Androidチームがクライアント視点からGraphQLを使用した感想についてもまとめているのでこちらも合わせてご覧ください。特別連載|5. JapanTaxiアプリAndroidの開発裏話
また今回使用したgraphql-rubyの詳細を知りたい方は、以前コードリーディングをした際の記事をご覧ください。 https://lab.mo-t.com/blog/andonlabo-graphql-ruby
リブランディング連載一覧
- 1. JapanTaxiのアプリリニューアルプロジェクト VPoE 吉田
- 2. ネーミングについて マーケター 中川
- 3. アプリデザインについて デザイナー 室津
- 4. iOSの開発裏話 iOSエンジニア 今入
- 5. Androidの開発裏話 Androidエンジニア 祖父江
- 6. サーバサイドの開発裏話 サーバサイドエンジニア 水戸
- 7. SREの開発裏話 SREエンジニア
- 8. アプリを世に広めるために マーケター
💁🏻
※本記事は Mobility Technologies の前身である JapanTaxi 時代に公開していたもので、記事中での会社やサービスに関する記述は公開当時のものです。
Mobility Technologies では共に日本のモビリティを進化させていくエンジニアを募集しています。話を聞いてみたいという方は、是非 募集ページ からご相談ください!