

物体検出のエラー分析ツールTIDE
AIDeep LearningコンピュータビジョンDecember 18, 2021
この記事はMobility Technologies Advent Calendar 2021の18日目です。
こんにちは、AI技術開発AI研究開発第二グループの劉です。私はドラレコ映像から標識などの物体を見つける物体検出技術を開発しているのですが、その精度を改善していくためにはまず検出エラーを細かく分析することが重要です。本記事では、物体検出のエラー分析に関する論文である”TIDE: A General Toolbox for Identifying Object Detection Errors”を解説すると共に、その著者らが公開しているツールを実際に使ってみた結果をご紹介をしたいと思います。
はじめに
本記事では、以下の論文を取り上げます。コンピュータビジョンで最も有名な国際学会の一つであるECCV(European Conference on Computer Vision)で2020年に発表された論文です。なお特に断りのない限り本記事における図は論文から引用したものとなります。
Daniel Bolya, Sean Foley, James Hays, and Judy Hoffman, “TIDE: A General Toolbox for Identifying Object Detection Errors,” ECCV 2020. [pdf] [GitHub]
物体検出では、検出精度の評価にmAP(mean Average Precision)という指標がよく使われます。mAPについての解説は本記事では割愛しますが、例えばこちらの記事が詳しいです。mAPは物体検出モデルの精度を一つの数値で表現できるため使いやすくはあるのですが、それだけでは物体検出における様々なエラータイプのそれぞれがどのように精度全体に影響しているかを知ることはできません。
本論文では、物体検出のエラー分析においては以下の要求が満たされるべきであり、またこれらを満たすツールとしてTIDEを提案しています。
- エラータイプをコンパクトにまとめることができ、一目で手法間の比較ができる
- あるエラータイプが検出精度に与える影響を他のエラータイプの影響と分離できる
- 分析のために新たなアノテーションを行う必要がない
- 評価データセットの一部ではなく全体を使うことができる
- 解釈性が高く更なる詳細分析に役立つ
物体検出におけるエラータイプ
まず、物体検出におけるエラータイプを定義します。本論文では、図1に示すような6種類を定義しています。
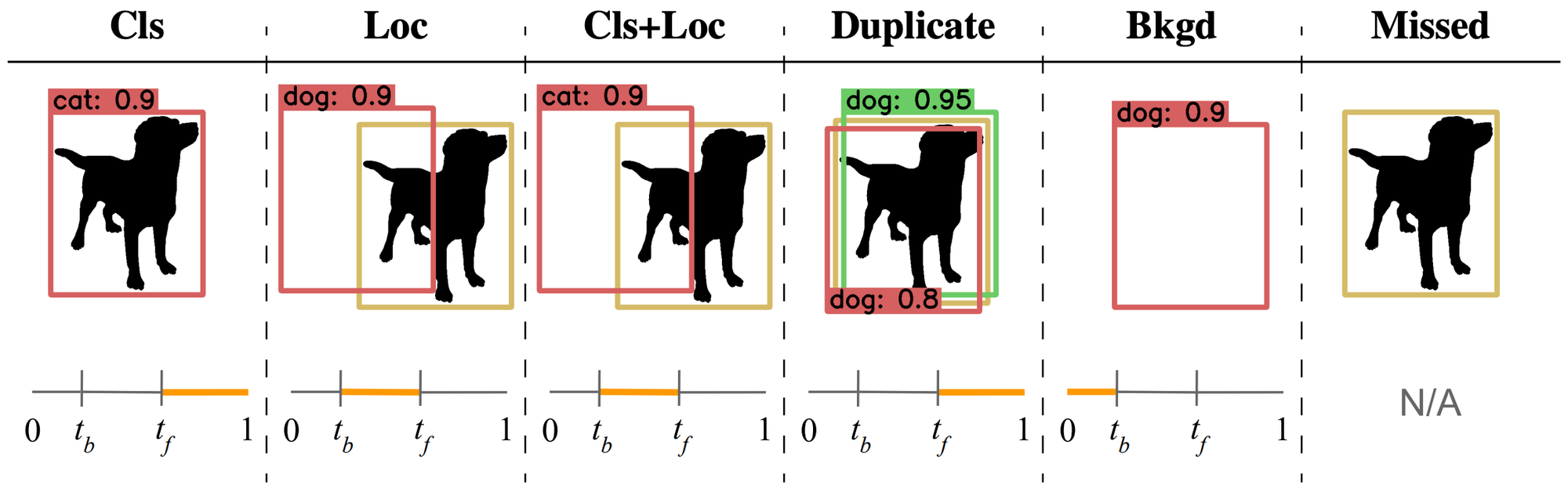
図1 物体検出におけるエラータイプ(赤:false positive、黄:真値、緑:true positive)
図1における各エラーの定義は以下の通りです。なお、図1の各エラーの下側にある0〜1のバーは検出結果と真値とのIoU(Intersection over Union)を表しており、IoUがオレンジで示された値の範囲に入っていることを意味します。IoUが閾値以上となる場合はその物体を検出したとみなし、未満となる場合は背景を誤って検出したとみなします。
- Cls:物体の位置は正しいが、クラス分類が誤っている
- Loc:クラス分類は正しいが、物体の位置がずれている
- Cls+Loc:クラス分類を誤っており、物体の位置もずれている
- Duplicate:一つの真値を複数回検出している
- Bkgd:背景を誤って検出している
- Missed:検出漏れ
各エラータイプの寄与率
図1に示したエラータイプ間の比較として、単純にそれらの個数をカウントするのは不十分です。なぜなら、スコアの低いfalse positiveはスコアの高いものに比べて精度全体に与える影響が小さいからです。知りたいのは、あるタイプのエラーが検出モデルの精度をどれだけ低下させているかであり、これはつまり、もし検出モデルの改善によりそのエラータイプの発生をゼロにできた場合にどれだけmAPが向上するかを調べる、ということになります。
これを実現するため、”オラクル”を使ってエラーとなった検出結果を正解に修正することを考えます。あるエラータイプに該当するエラーを修正するオラクルをとし、オラクルを適用した後に再計算したAPをとすると、と元のAPとの差分を求めることでオラクルが精度全体に与える影響(エラータイプの寄与率)を知ることができます。オラクルがからまでn個あったとすると、それら全てを適用したは100となります()。
ここで、他ツールとTIDEとの最も大きな違いとして、TIDEは各エラータイプの寄与率をエラータイプごとに独立して求めているという点が挙げられます。他ツールでは、あるタイプのエラーを修正したあと、修正済みのエラーはそのままとした状態で次のタイプのエラーを修正し、また次のエラータイプを修正し、ということを繰り返していきます。その結果として全てのタイプのエラーを修正した後のAPは100となりますが、修正していくエラータイプの順番によって寄与率が変わってしまうという欠点があります。
例えば図2は、物体検出のデータセットとして著名なCOCOデータセットが提供しているCOCO Analysis Toolkitによるエラー分析結果です。これは各エラータイプを修正していくことでどのようにPR曲線がAP100に近づいていくかを示したものであり、各エラータイプの寄与率が色分けして示されています(面積が大きいエラータイプほど寄与率が大きい)。図2(a)がツールによるデフォルトの分析結果であるのに対し、修正していくエラータイプの順番を入れ替えたのが図2(b)です。両者で明らかにエラータイプごとの寄与率が変わってしまっていることがわかります。こうした事態を避けるため、TIDEでは各エラータイプの寄与率をそれぞれ独立に計算しています。
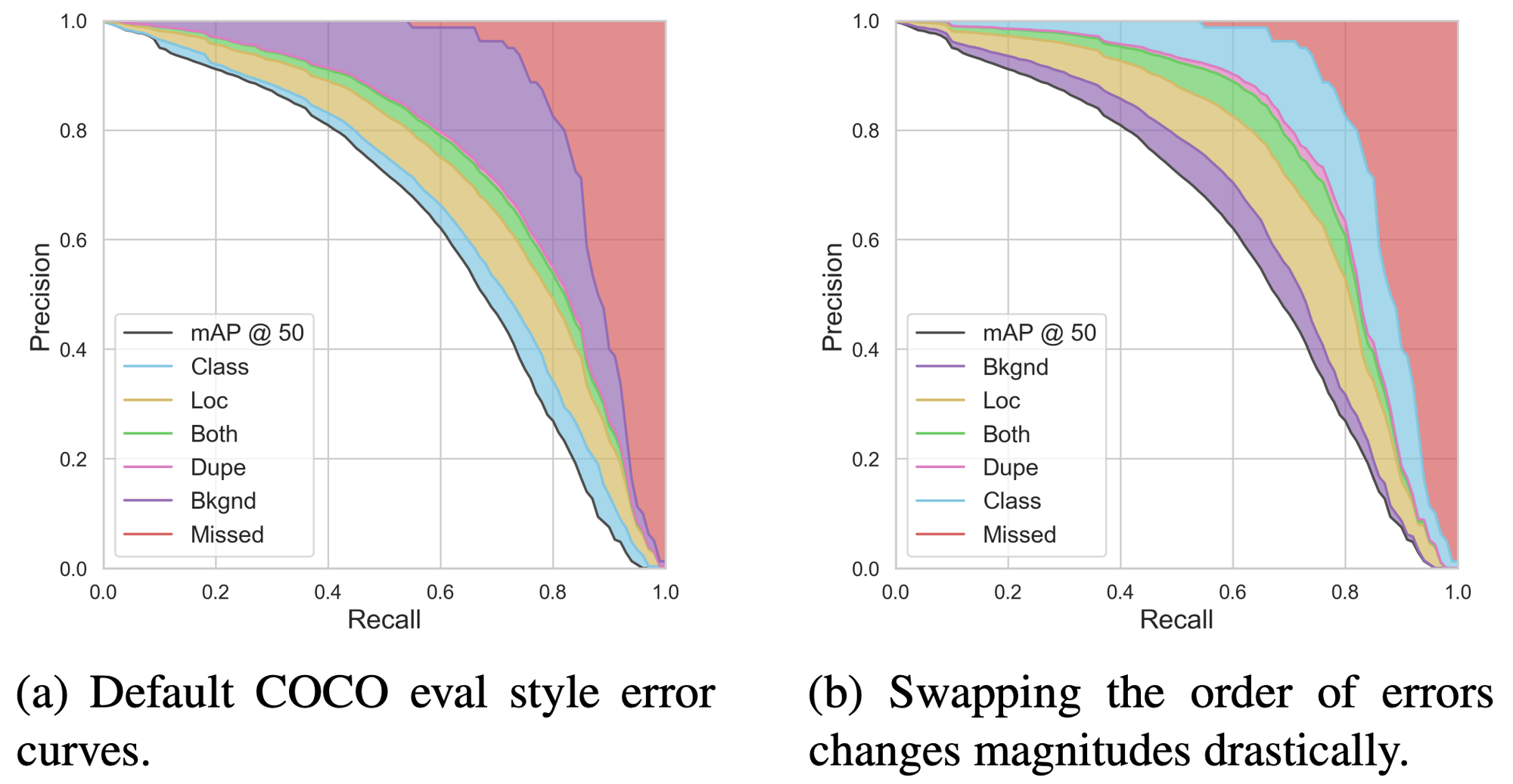
図2 既存のエラー分析ツールにおける課題
TIDEによる分析結果
実際にTIDEを使って物体検出モデルの比較を行った例を図3に示します。対象としたデータセットはCOCO、また比較した物体検出モデルはMask R-CNN、HTC、TridentNet、RetinaNet、FCOS、YOLOACT++です。TIDEを実行すると、各エラータイプの相対的な寄与率が円グラフで可視化され、また絶対的な寄与率が棒グラフで可視化されます。また図4は寄与率の絶対値をエラータイプごとに並べたものです。
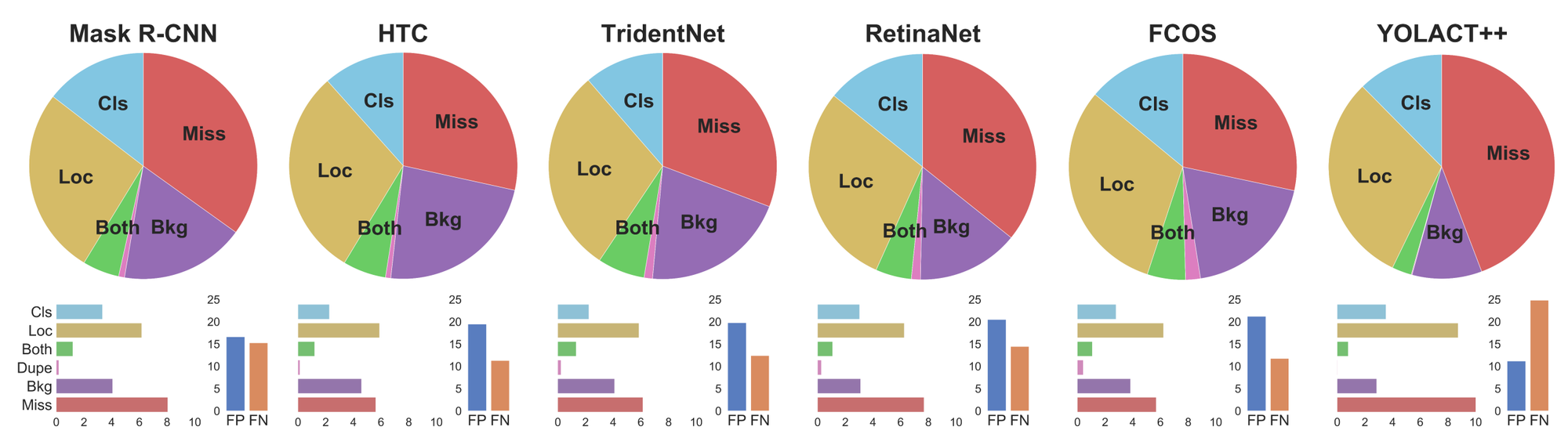
図3 物体検出モデル間の比較
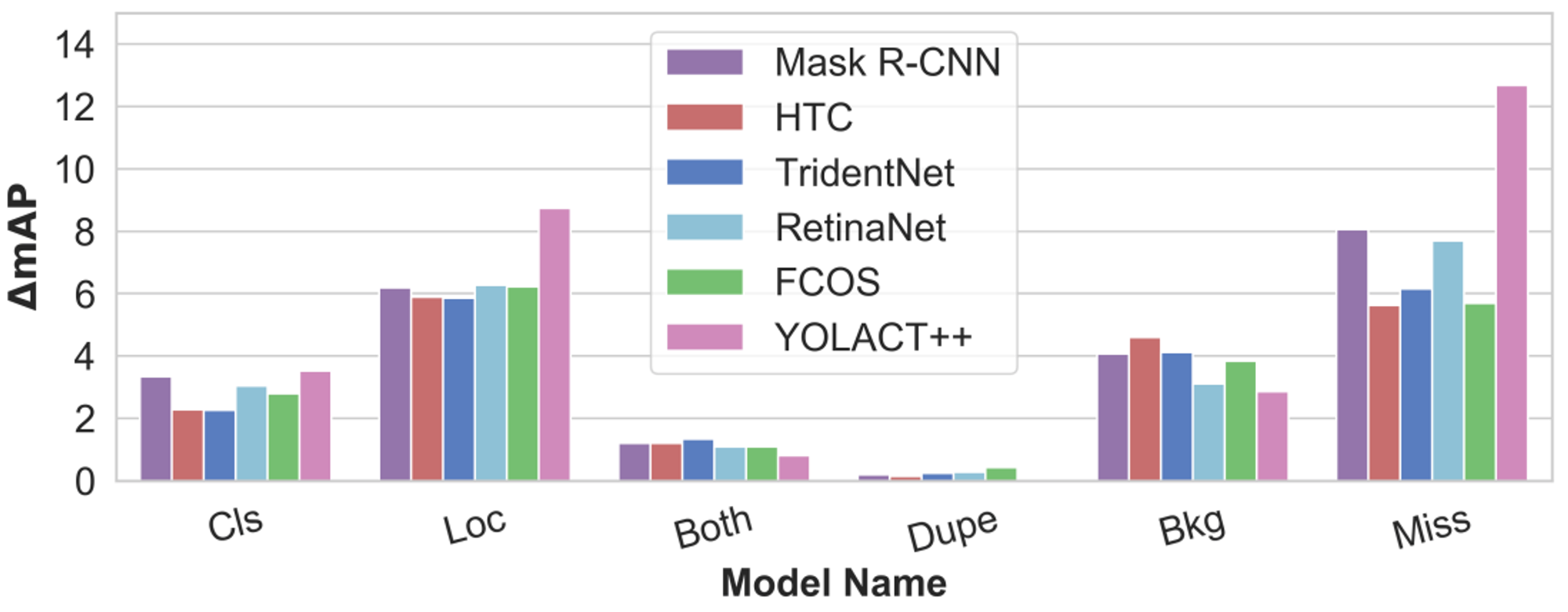
図4 各エラーの絶対値の比較(論文から引用した図ですが、横軸のキャプションが誤っているようです。本来はError Typeだと思います)
全てのモデルの詳細な比較は割愛しますが、例えばMask R-CNNとHTCの違いを見てみましょう。HTCは、Mask R-CNNに対してカスケード機構による繰り返し処理で予測結果を改善し、また背景と間違えやすいような物体の検出精度を向上させる工夫を入れています。TIDEによる分析結果を見ると、確かにHTCはMask R-CNNに比べて分類(Cls)や位置(Loc)エラーが小さく、また検出漏れ(Miss)も少なくなっています。一方で、背景を誤って物体として検出してしまう(Bkg)ことが増えています。つまり、背景と間違えやすいような物体の検出精度を改善したことで検出漏れは減ったものの、同時に背景からの誤検出が増えてしまったと考えられます。このようにTIDEを使えば、各モデルにおける工夫が本当に精度改善に寄与しているかを簡単に確認することができます。
また、物体検出モデルを固定することでデータセット間の比較をすることもできます。図5は、Mask R-CNNによる物体検出結果をPASCAL、COCO、LVIS、Cityscapesデータセットで比較したものです。これを見ると、例えばCOCOと同じデータに対してクラス数を増やしてアノテーションを付与しているLVISは、COCOと比べて圧倒的に分類エラー(Cls)の寄与率が大きく、分類が困難なデータセットであることがわかります。
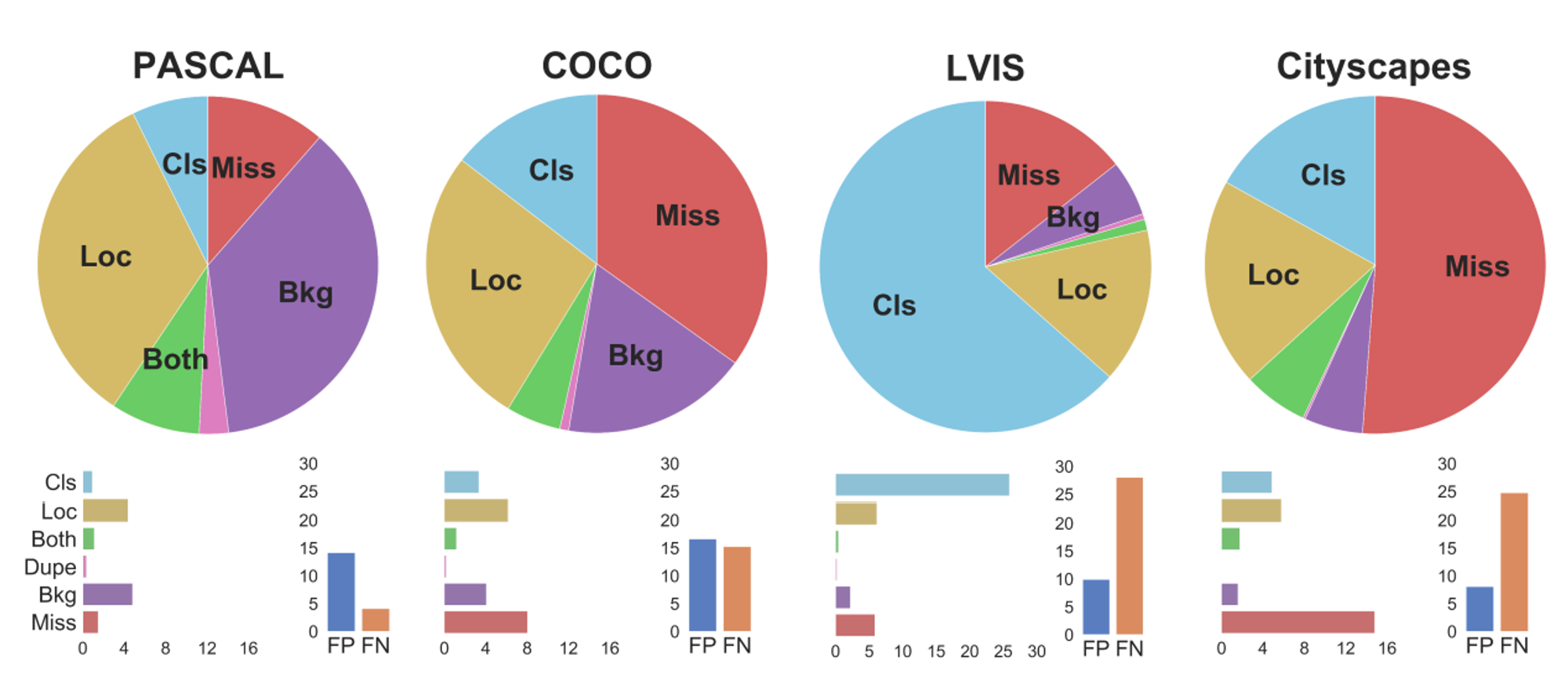
図5 物体検出データセット間の比較
実際に使ってみる
では実際に私が業務で開発しているドラレコ映像から標識を検出する物体検出モデルをTIDEで分析してみたいと思います。インストールや使用方法についてはTIDEのリポジトリのREADMEに従えば問題ありません。
インストール
インストールはpipでポンです。
pip3 install tidecv使用方法
分析時には、分析対象となる評価データセットの真値および同データセットにおける物体検出モデルの推論結果をCOCOフォーマットで用意し、それぞれのパスを指定するだけです。
from tidecv import TIDE, datasets
tide = TIDE()
tide.evaluate(
dataset.COCO('path/to/your/groundtruth/file'),
dataset.COCOResult('path/to/your/results/file'),
mode=TIDE.BOX
)
tide.summarize() # コンソールに分析結果のサマリをテーブルで表示
tide.plot() # サマリの図を表示(フォルダを指定した場合はそのフォルダに図を保存)結果
まず、標識の検出から分類までをend-to-endで行う物体検出モデルのエラーを分析した結果を図6(a)に示します。分類エラー(Cls)の寄与率が最も高くなっていますが、これは私たちのプロジェクトでは100種類以上の標識を区別して検出しており、中には非常に似通った標識もあるため正しく分類することが難しいケースが多いことが原因と考えられます。
そこで、分類精度を高める1つの工夫として、検出と分類を1つのモデルで行うのではなく、2つのモデルに分けることを検討してみました。つまり、最初の検出器で全ての標識を区別せず1クラスとして検出し、検出されたバウンディングボックスを切り出して分類器に入力することでどのクラスの標識なのかを判定する2段構成のモデルです。分類器を独立して設計、学習することで、より分類精度の高いモデルが得られる可能性があります。このモデルの分析結果を図6(b)に示します。これを見ると、最初のモデルに比べて分類エラー(Cls)の寄与率が小さくなっており、2段目の分類器の効果が出ていることがわかります。一方で、背景領域を誤って物体として検出するエラー(Bkg)やFPの寄与率が大きくなっていますが、これは最初の検出器が"標識らしきもの"を網羅的に検出できるようになった結果、本来標識でないものを誤って検出してしまうケースが増えたためと考えられます。
このように、TIDEを使ってエラー分析を行うことでmAPのみを使った評価に比べてはるかに多くの情報を得ることができ、モデルの弱点やアルゴリズムの工夫による改善効果をわかりやすく把握することができるようになります。
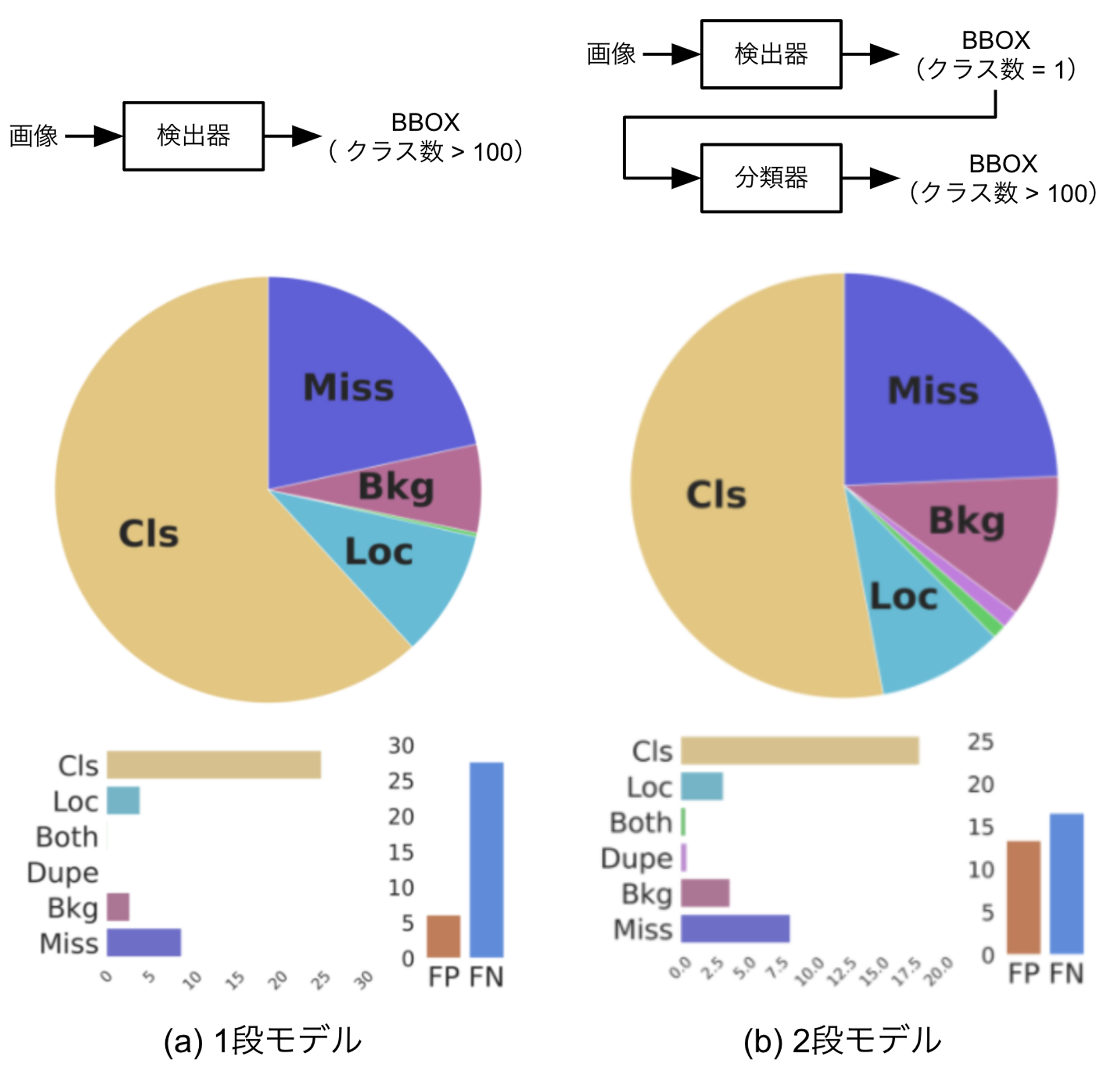
図6 開発中の標識検出モデルの分析結果
まとめ
本記事では、物体検出のエラー分析ツールを提案した論文である”TIDE: A General Toolbox for Identifying Object Detection Errors”を取り上げ、その内容と実際にツールを使ってみた結果についてご紹介しました。記事にあるように、TIDEを使うことで簡単に物体検出モデルの弱点把握やモデル間の比較ができますので、物体検出モデルの精度改善に取り組まれている(苦しめられている?)方にはぜひ使ってみることをお勧めいたします。
We're Hiring!
📢
Mobility Technologies ではともに働くエンジニアを募集しています。
興味のある方は 採用ページ も見ていただけると嬉しいです。
Twitter @mot_techtalk のフォローもよろしくお願いします!