

PostgreSQLのTransaction ID Wraparound失敗でDB停止障害を起こしそうになった話
SRESQLDecember 15, 2023

こんにちは、SREグループの水戸 (@y_310)です。GO Inc.ではマイクロサービスごとに固有のDBを持っているため数十台のAurora PostgreSQLクラスタを運用しています。ある日たまたまAWSコンソールを眺めていたところそのうちの1つのクラスタでこんなメッセージが表示されていることに気づきました。
This instance is approaching transaction ID wraparound, which will cause lengthy downtime if not mitigated. Please refer to the RDS Postgres documentation for next steps.恥ずかしながらTransaction IDが何なのかも分かっていなかったのですが will cause length downtimeというメッセージから何かやばそうなことが起きていると気づき調査を開始しました。今回はTransaction IDが何なのか、このメッセージが何を意味しているのか、どうしてこんなことになったのか、といったお話を紹介したいと思います。
Transaction IDとは何か
まずTransaction IDはINSERTやUPDATEなどの更新トランザクションが発生するたびにそのトランザクションに付与される32bitの符号なし整数値です。ある実行中のトランザクションから見て自分のIDより古いトランザクションによって作られたレコードは参照可能で、自分より新しいIDのトランザクションで作られたレコードは見えないという制御をするために使われます。
32bitの最大値は約40億なのでその番号を超えてインクリメントされると0に戻り周回し続けます。そのため、30億より40億の方が大きいが、40億より10の方が大きいといった周回を考慮した大小判定をする必要があります。また10から見て40億は過去の値としてみれば小さいですし未来の値としてみれば大きいことになってしまい単純な比較では大小関係を定義できません。そこでTransaction IDはあるIDから見てマイナス側20億を過去、プラス側20億を未来と定義しています。それによって10から見て
- -20億+10〜9(実際には符号なし整数なので20億+10〜9)までは過去の値
- 11〜20億+10までは未来の値
という扱いになります。
実際のTransaction IDの大小関係の比較は以下の実装で行われており、これはid1とid2が周回上どの位置にあるかに関わらずid2がid1より大きいかどうかを判定する処理になっています。
// https://github.com/postgres/postgres/blob/a82ee7ef3aacc2073d3ef5f4b7e5067fa08ea76c/src/backend/access/transam/transam.c#L291-L292
// id1, id2はuint32, id1 < id2の場合true
diff = (int32) (id1 - id2);
return (diff < 0);この仕組みによって、過去側/未来側ともに20億を超えると反対側の領域に食い込んでしまうことから、同時に扱えるTransaction IDの数は最大で20億となります。
Transaction IDの枯渇を防ぐ仕組み
20億あるとはいえ大量に更新があるデータベースであれば容易に枯渇してしまう数字になります。もし何もせず20億トランザクションを処理しきってしまうと一番古いTransaction IDが突如として未来のIDとして扱われてしまいデータが不可視状態になる、つまり実質データが消失してしまった状態となります。これを防ぎ半永久的にトランザクションを発行し続けられるようにするための仕組みがFreezeです。
Freezeは一定以上古くなったレコードに対してFreeze状態であることを示すフラグを立てる操作です。FreezeされたレコードはどのTransaction IDと比較してもそれより古いと判定されるようになっているためIDがどれだけ周回してもデータが不可視になることはありません。またFreeze状態になったレコードが使っていたTransaction IDは再利用が可能になるためIDの枯渇が起こらなくなります。新しいレコードの場合まだ実行中のトランザクションがあるとそのトランザクションから見えてはいけないレコードがあるかもしれないためFreezeできませんが、ある程度以上古いレコードであればそういった問題が無くなるため一律でどのトランザクションからみても古いという扱いができるということです。
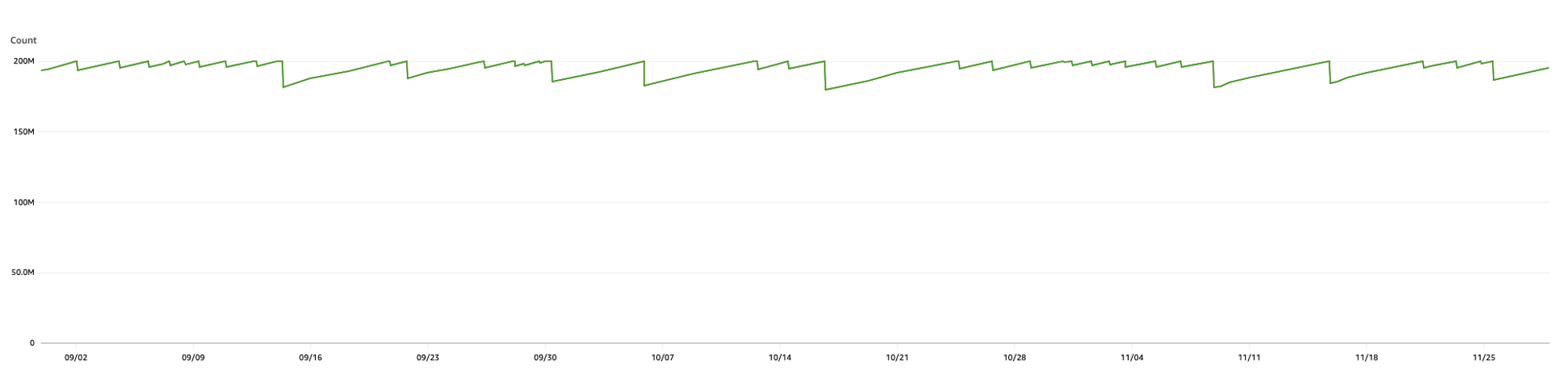
デフォルトでは一番古いTransaction IDと最新のTransaction IDの差が2億になるとautovacuumが実行され古いレコードがFreezeされます。こちらは書き込みが多いあるDBの実際のMaximumUsedTransactionIDsの値ですが2億に近づくとautovacuumが走り数値が下がっているのが分かります。
このようにこの仕組みが順調に動いていればTransaction IDが枯渇すること無くデータ消失も書き込みの停止も起きないのですが、今回はある見落としによってFreezeが動作しない状態になってしまいIDが枯渇しそうになってしまいました。
発生した事象と解決
Transaction IDとFreezeが何なのか把握できたところで冒頭の警告メッセージに戻ります。
This instance is approaching transaction ID wraparound, which will cause lengthy downtime if not mitigated改めてメッセージを読むとTransaction ID Wraparoundが近づいていて対応しない限り長時間のダウンタイムを引き起こすと書かれています。これはつまり20億トランザクションの上限に近づいてTransaction IDを使い切ってしまいそうだと言っていることが分かります。PostgreSQLは完全にIDを使い切る手前で書き込みを停止するため、実際には使い切るタイミングではなくその少し手前のタイミングが近づいていることを意味しています。
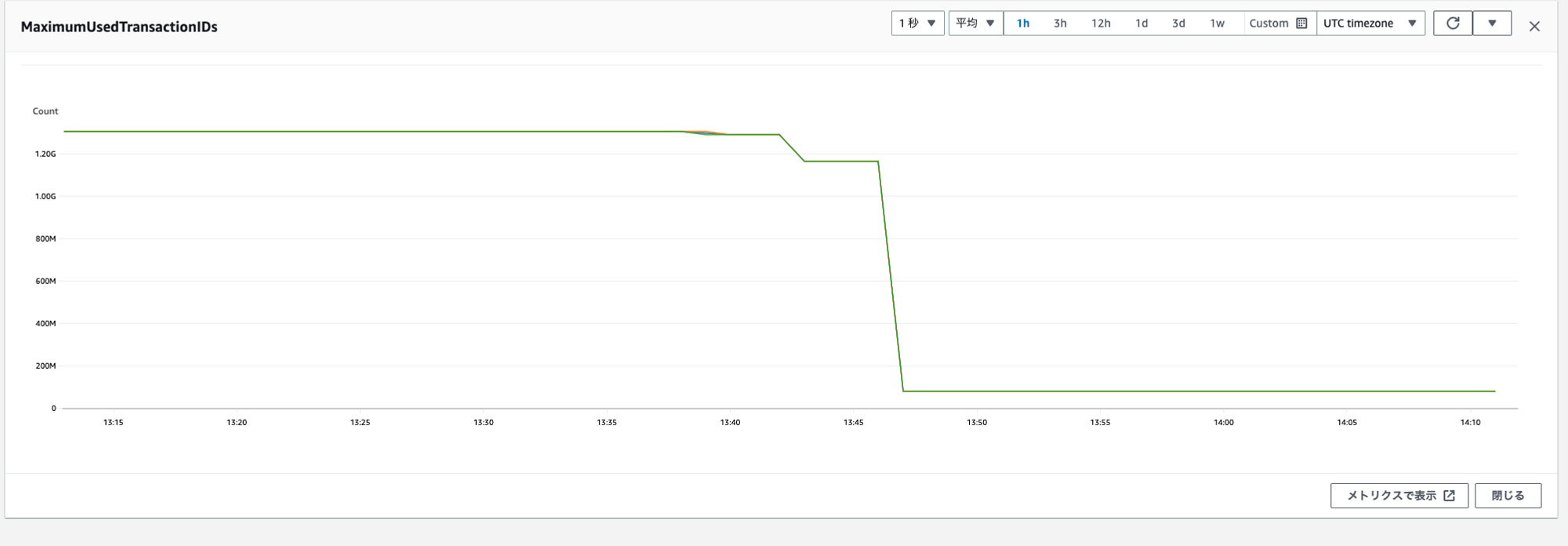
こちらが当時のMaximumUsedTransactionIDsの値ですが、ある時を境に急速に値が上昇し始め13億付近まで増加していることが分かります。

まだ20億まで猶予はあるものの明らかに危機が迫っていることが分かります。
本来autovacuumによってこの値は2億以下に保たれているはずですがなぜこのような事態になってしまったのでしょうか?
AWSサポートに問い合わせた結果、原因の候補として長時間実行されているトランザクションが無いかと古いreplication slotが残っていないかについて確認を求められました。そこで始めて削除していないreplication slotが存在していることに気づきました。このデータベースではデータをDWHに同期するためにdebezium serverを使ったCDCを行っており、その際にreplication slotが作成されていました。ただ、この同期を別の方法で実施することになりちょうどTransaction IDの消費が始まった3月頃にdebezium serverを停止していたのでした。当時はそれで作業が完了しているものと思い込んでいましたがreplication slotだけが残り、それがautovacuumの実行を阻害することでFreezeされないレコードが残り続けTransaction IDの枯渇に向かっていました。
replication slotはレプリケーションのクライアント(今回であればdebezium server)がどこまでレプリケーションを完了したかの状態を保持し、未完了のログが削除されてしまうことを防止するための仕組みです。そのため、レプリケーションしないままslotだけを残しているとvacuumが古いデータを削除できなくなりTransaction IDも開放されなくなってしまいます。
原因発覚後replication slotを削除すると自動的にvacuum analyzeが実行され、約40分間DBが高負荷状態になり、最終的に一気にFreezeが進みTransaction IDが開放されました。
まとめ
今回は不要になったreplication slotを放置していたことで危うくTransaction ID Wraparound失敗による深刻なサービスダウンを引き起こしてしまうところだった事例を紹介しました。本当に偶然警告に気づけたために未然に防ぐことができましたが非常にヒヤヒヤする事件でした。問題発覚後、その他のDBでも不要replication slotの点検やMaximumUsedTransactionIDsに対するアラート設定などを実施し今後は同じ問題を引き起こさないように再発防止を実施しました。
危ない事態ではありましたが、結果的にPostgreSQLのTransaction IDやautovacuumの仕組みの理解が深まり良い機会となりました。
参考文献
今回の記事は特に以下の情報を参考にさせていただきながら執筆しました。この記事ではTransaction IDやautovacuumの仕様についてごく浅い概要しか書けていませんが以下の資料では詳細かつ分かりやすくそれらの仕様や挙動が記載されていますのでぜひ参照されることをおすすめします。
- パフォーマンスチューニング9つの技 〜「基盤」について 〜
- Transaction IDの範囲についての図示がとてもわかり易く理解の助けになりました
- VACUUM Simulatorを使ってVACUUMをもっと理解しよう
- つい先日11/24に開催されたPostgreSQL Conference Japan 2023で発表されていた資料です。Transaction IDのことも含むVacuum処理全体の非常に詳細な情報が分かりやすくまとめられており貴重な資料でした
We're Hiring!
📢
GO株式会社ではともに働くエンジニアを募集しています。
興味のある方は 採用ページ も見ていただけると嬉しいです。
Twitter @goinc_techtalk のフォローもよろしくお願いします!