

ドラレコ映像を使った地図メンテナンスを支えるコンピュータビジョン技術
Deep LearningAIコンピュータビジョンこんにちは、AI技術開発部AI研究開発第二グループの宮澤(@kzykmyzw)です。私は、地図のメンテナンスのためにドラレコ映像から道路の変化情報を自動抽出するプロジェクトに携わっています(プレスリリース)。このプロジェクトでは、ドラレコ映像に写った道路標識や信号機などを検出してそれらの位置を特定し、地図と比較することで変化を見つけます。この記事では、このプロジェクトのコアとなるコンピュータビジョン技術について、映像から検出した物体を地図と比べるためにどんな処理を行なっているかをご紹介します。
はじめに
3月3日に開催されたDeNA TechCon 2021にて、MoTの渡部(@fetarodc)から「ドライブレコーダの動画を使った道路情報の自動差分抽出」というタイトルで発表がありました。詳細につきましては以下のスライドや講演の録画をご覧ください。なおこちらの講演はTechCon 2021にご参加いただいた方からの満足度が非常に高く、Best Talk Awardで2位を獲得しています!
簡単に言うとこのプロジェクトでは、タクシーやトラックに取り付けたドラレコの映像を収集し、それらから画像認識技術を使って検出した物体を既存の地図と比較することで地図が古くなっている箇所を自動で見つけることを目的としています。こうした情報は地図のメンテナンスに使うことができ、地図の鮮度向上やメンテナンスコストの削減につながります。なお、ドラレコ映像から検出している物体の例としては、道路標識や信号機、道路上のペイント(区画線や路面標示)などが挙げられます。
上記の講演は、こうしたサービスを実現するために私たちが開発しているシステム全体の説明やエンジニアリング上の工夫にフォーカスを当てています。そこでこの記事では、システムの中で動いているコンピュータビジョン技術について、特に映像から検出した物体を地図と比べるためにどんな処理を行なっているかをご紹介します。
検出した物体の3次元座標を求める
ディープラーニングに代表される機械学習技術の発展により、画像から特定の物体を検出する技術は飛躍的に進歩しました。このプロジェクトでもディープラーニングを活用することで、ドラレコ映像から地図のメンテナンス対象となっている標識や信号機を高精度に検出することができています。
しかし、単にドラレコ映像から物体を検出するだけでは、地図との比較によってその物体が地図上にあるかないかを判断することはできません。なぜなら、あくまでもドラレコ映像から検出した物体は2次元の画像中の座標を持っているにすぎず、そのままでは地図で使われている3次元の地理座標系(緯度・経度・標高)とは比べられないからです。そこでまず、画像から検出した物体の2次元座標を、撮影したドラレコを基準とした相対的な3次元座標に変換します。
図1の左のようなケースを考えてみましょう。ここでは、1つのカメラで撮影した画像に速度標識が写っており、それを画像認識で正しく検出できているとします。このとき、図に示すカメラ中心と、検出した速度標識の画像中の2次元座標とを結んだ直線(図中のグレーの破線)上に速度標識は存在します。しかし、このままでは直線上のどこに速度標識が存在するかまではわからないため、例えばカメラ中心を原点とした3次元空間において速度標識の3次元座標を一意に定めることはできません。
ここで、図1右のように、同じ速度標識を写すもう1つのカメラが存在すると考えてみます。すると、それぞれのカメラから速度標識を通る直線を引くことができ、2本の直線の交点として速度標識の3次元座標が求められます。この原理を三角測量と呼びます。
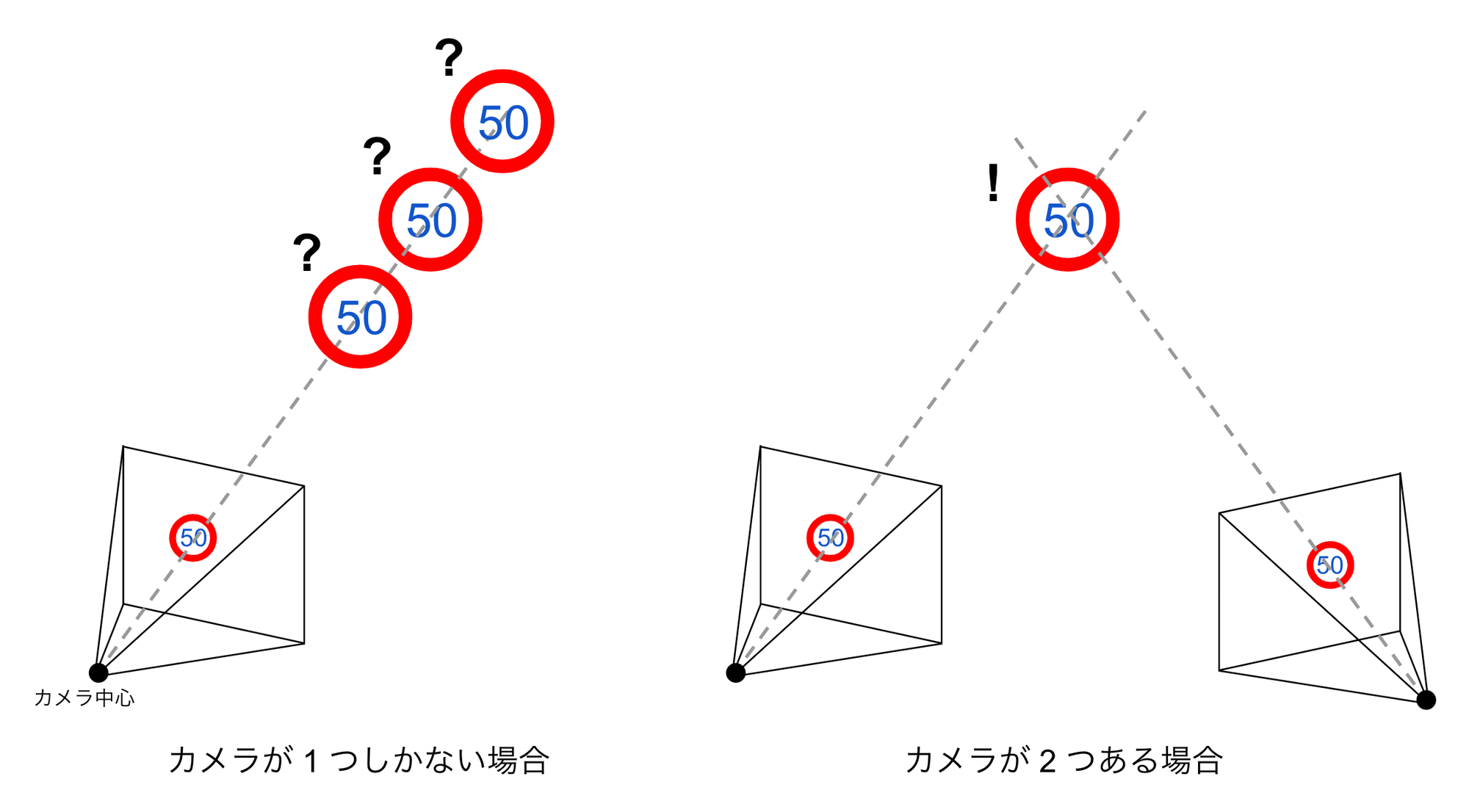
図1: カメラで検出した物体の3次元座標の推定
一般にはこのように位置が異なる2つ以上のカメラで対象物体が撮影されていれば、その3次元座標が求められます。私たちが扱うのはドラレコ映像ですが、ドラレコを搭載した車両が移動しているとすれば、映像内の各フレームでカメラの位置は異なります。つまり、例えばある1つの標識が一定時間ドラレコ映像に写っていれば、映像に含まれるフレームはその標識を様々な位置から写した画像の集まりであると考えることができ、各フレームで標識を検出して追跡することで三角測量により標識の3次元座標を知ることができます。この様子を図2に示します。
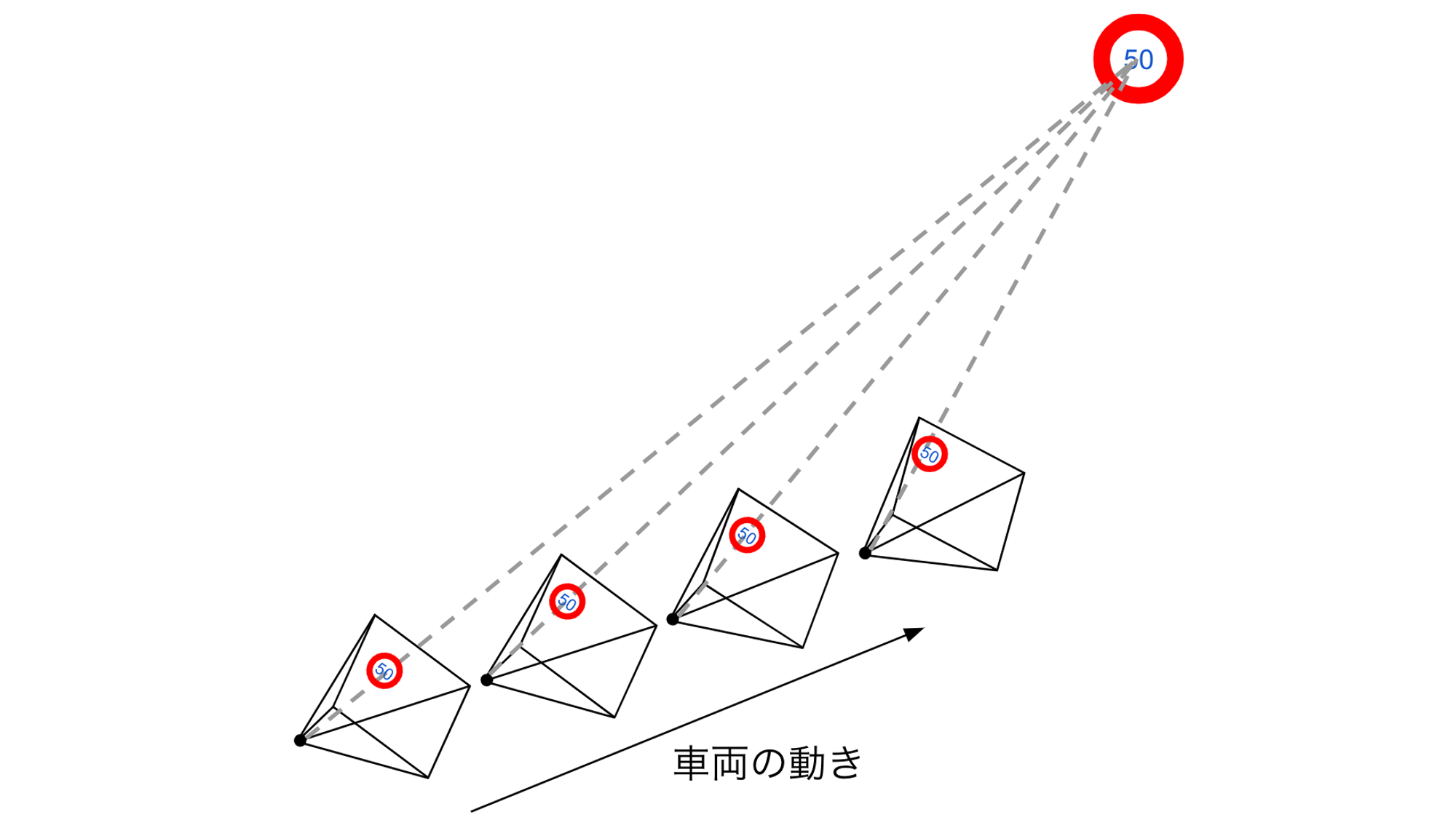
図2: ドラレコ映像からの三角測量
ここで、ある重要な情報が必要となります。それは各フレームを撮影した際のカメラの相対的な位置と姿勢です。図1右のようにカメラが2つあれば物体の3次元座標を求められると言いましたが、このとき例えば左のカメラを基準とし、相対的に右のカメラがどの位置にどのような姿勢で存在するかをあらかじめ知っておく必要があります。これをドラレコ映像の場合で考えると、映像の各フレームが撮影された際のドラレコの位置姿勢を知っておく必要があるということです。
このような問題は、何らかのセンサを搭載した移動体が未知の環境で動き回る際に、周囲環境の3次元マップを構築しながらその中を自分がどのように移動しているかを推定する問題に一般化できます。これはSLAM(Simultaneous Localization and Mapping)と呼ばれ、最近ではお掃除ロボットなどにも搭載されている技術です。今回の場合だと、何らかのセンサ=ドラレコ、移動体=ドラレコを搭載した車両、ということになります。なお特にカメラの映像だけを使ったSLAMはVisual SLAMと呼ばれます。
Visual SLAMの原理は複雑ですが、代表的な手法を簡単に説明すると図3左のように各フレームで例えばビルや標識の角など見た目が特徴的な点(特徴点)を検出し、それをフレーム間で時間方向に追跡していくことで図3右のように各フレームを撮影したカメラの位置姿勢を推定します。カメラから遠い位置にある特徴点はフレーム間であまり移動しないのに対し、カメラから近い位置にある特徴点は大きく移動します。こうした情報を使って、周囲がどのような環境で、またその中をどのようにカメラが移動しているかを求めます。
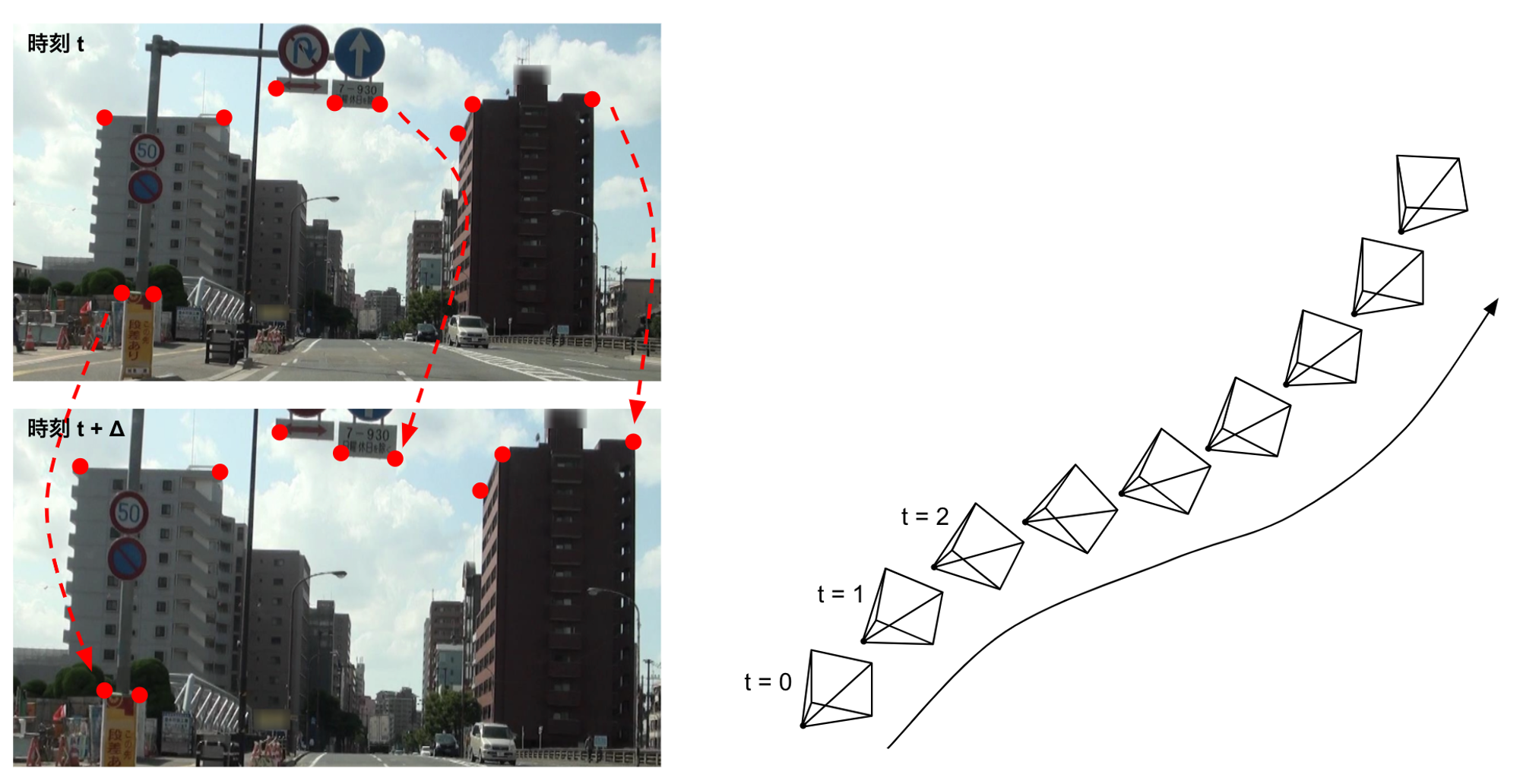
図3: 特徴点の追跡によるカメラ位置姿勢の推定
Visual SLAMの著名なOSSとしては、ORB-SLAM2やLSD-SLAMがあります。また、Visual SLAMではなくSfM(Structure from Motion)と呼ばれる技術でも同等のことが実現できます。SfMのOSSではCOLMAPなどが有名です。Visual SLAMもSfMも複数の画像からカメラの位置姿勢や周囲環境の3次元マップを求めるのは同じですが、SfMでは全ての画像を同時に利用し、あまり計算コストを気にせずに精度を優先するのに対し、Visual SLAMは動画など画像が逐次的に入力されてくるケースにおけるリアルタイム性を重視しています。このプロジェクトでは将来的に全国の地図がターゲットとなり、単位処理あたりの計算コストを下げることが重要であったため、私たちはVisual SLAMを採用しました。一般にVisual SLAMの精度はSfMに劣るとされますが、私たちは自前のデータで両者を比較し、私たちのユースケースでは大きな精度差がないことを確認しています。
以上を整理すると、私たちのアプローチではまずドラレコ映像から物体を検出すると共にVisual SLAMで各フレームでのカメラの位置姿勢を推定し、それぞれの結果から三角測量の原理で物体の3次元座標を求めます。ここで言う3次元座標というのは、地図で使われる地理座標系とは関係なく、あくまでもカメラを基準とした相対的なものであり絶対的な大きさは不定です。例えば入力映像の1番最初のフレームを撮影したときのカメラ位置を原点とし、次のフレームを撮影したカメラまでの距離をある適当な大きさに決めたような座標系です。したがってここで求めた物体の3次元座標はまだ地図と比べることはできません。
物体の3次元座標を地理座標に変換する
画像から求めた物体の3次元座標を緯度・経度・標高といった地理座標に変換するには、なんらかの基準が必要です。この基準として、私たちはドラレコに搭載されたセンサから得られるGPS情報を使っています。ドラレコにはGPSによる位置情報が一定の時間間隔で記録されているため、Visual SLAMで求めた一連のカメラ位置(便宜上カメラ軌跡と呼びます)とGPS軌跡とをマッチングすることで座標変換のためのパラメータを求めることができます。ここで、2つの座標系の間の変換は相似変換で記述できるので、求めるパラメータは回転、並進、拡大縮小ということになります。これらのパラメータは、2つの軌跡を構成する点列の間の対応関係がわかっていれば最小二乗法で推定することができます。このイメージを図4に示します。なお、映像の各フレームとGPS情報は非同期で取得されているため、両者のタイムスタンプに基づいて後処理で対応関係を求めています(図4の破線)。
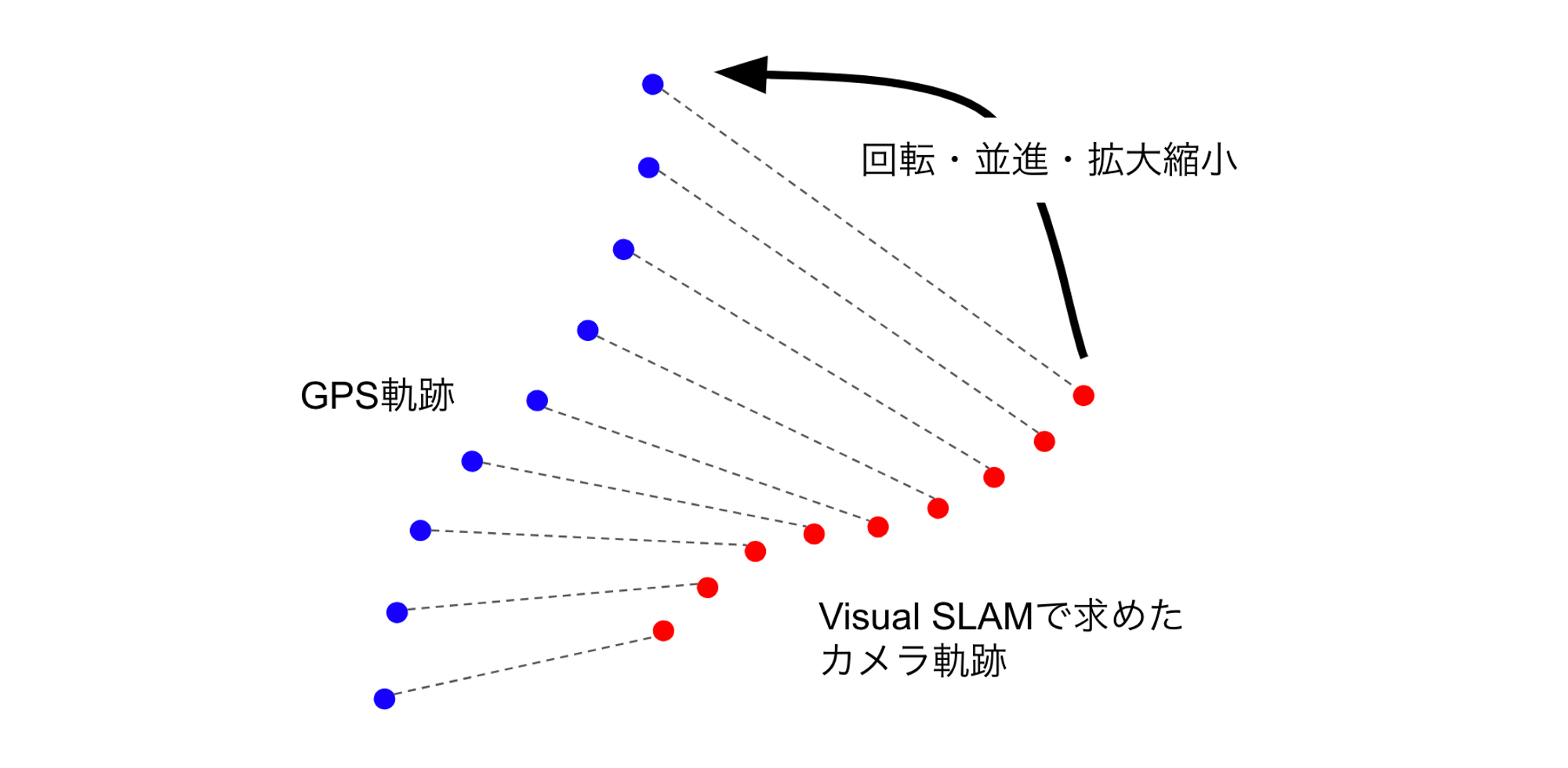
図4: GPS情報を使った座標系変換パラメータの推定
このようにして推定した座標変換パラメータを使い、カメラを基準とした座標系で求めた物体の3次元座標を地理座標に変換します。こうすることで、ドラレコ映像から検出した物体の緯度・経度・標高を知ることができ、やっと地図と比べることが可能になります。
地図と比べる
これまでに説明した方法でドラレコ映像から求めた物体の座標を地図と比較した結果の例を図5に示します。図中のオレンジのラインがVisual SLAMで求めたカメラ軌跡、赤い☆がドラレコから推定した物体(信号機)の座標です。あらかじめ地図に登録されているそれらの位置は黄色の◇でプロットしていますが、☆と◇の位置が概ね一致していることがおわかりいただけるかと思います。当然ながら誤差があるため両者は完全に一致することはなく、この例ですと2〜4mほど離れているケースが多いです。つまり、☆と◇の最近傍同士をペアにしたときにその間の距離が4mを大きく超えるような箇所や、そもそもペアが見つからないような箇所では地図が古くなっている可能性が高いと判断することができます。
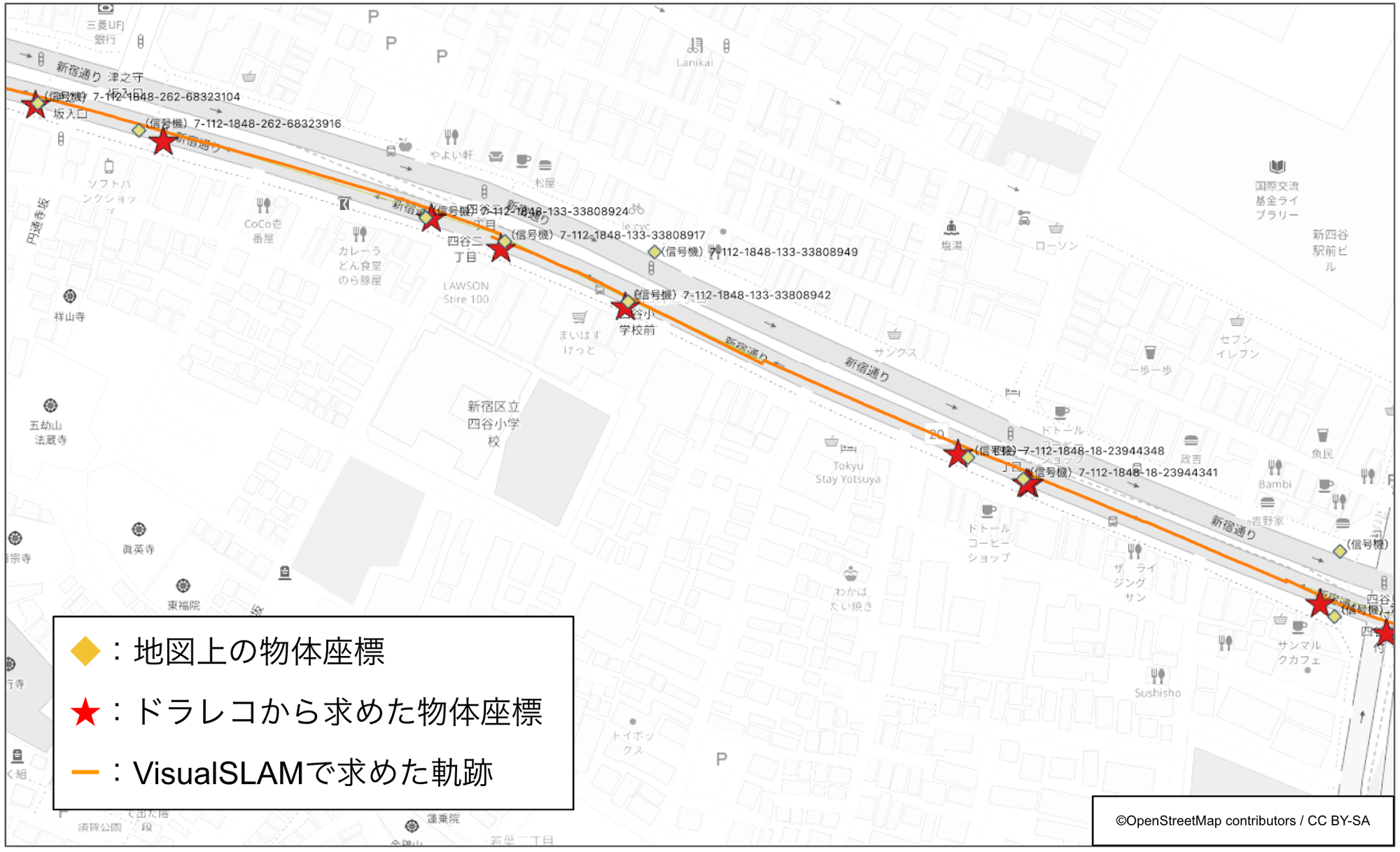
図5: ドラレコから求めた物体と地図上の物体との比較
なお実際にはさらに大きな誤差が入ることも多いです。その要因としては物体検出の誤差、Visual SLAMや三角測量の誤差、GPSの誤差、地図自体の誤差など様々なものがあり、これら全てをゼロにするのは不可能です。したがってある程度の誤差が存在することを前提としてドラレコから求めた物体と地図上の物体の座標を比較していく必要があり、まだ私たちも色々な方法を試行錯誤している段階です。特に、このプロジェクトの特徴として、必ずしも1回の走行だけで判定を確定させる必要はないため、同じ道路を複数回走行した結果を統合することで判定の信頼性を高められるという点が挙げられます。例えば複数回走行のそれぞれで判定した結果の多数決を取るのがもっとも単純な方法ですが、こちらも色々な方法を検討しているところです。
見えてきた課題と工夫
冒頭でご紹介したTechConでの講演でも述べられているように、このプロジェクトで実現を目指すサービスの全体像はほぼ完成しており、現在は大量のドラレコ映像を実際に入力して課題の洗い出しを行なっています。その過程で、特にVisual SLAMについて様々な課題が見えてきました。最も大きな課題は、周囲環境の影響による処理の不安定性です。図2に示したように、Visual SLAMでは映像中の特徴点を追跡していくことでカメラの位置姿勢を推定するため、なんらかの理由により途中で追跡が途切れてしまうとそこからなかなか復帰できなかったり、あるいは時間方向に逐次的に推定していく過程で誤差が蓄積し、最終的に処理が破綻したりするようなことがあります。
そこで私たちは、入力されたドラレコ映像をそのまま処理するのではなく、一旦短い映像の集まりに分割したうえでそれぞれに対して独立にVisual SLAMを適用するなどの工夫をしています。こうすることで例えば5分の映像の冒頭で特徴点追跡に失敗し、その後復帰できないことで5分全てが無駄になるような事態を避けることができ、また誤差の蓄積も小さく抑えることができます。その他、計算リソースに余裕がある場合は分割した映像単位で並列に処理すれば全体の処理時間も削減できます。
またVisual SLAMの原理的に、周囲に動くものがたくさんあると正しい推定ができないという課題があります。Visual SLAMでは基本的に静的なシーンの中をカメラが移動していくことを前提としているため、カメラ以外に動くものが存在すると誤差要因となります。もちろんある程度は許容できるように工夫していますが、それでも例えば自車両の付近が完全に他車両に囲まれてしまっているようなケースでは処理が不安定となります。
こうした課題の解決策としては、あらかじめ映像中から自車両以外の移動物体(他車両など)を検出し、その領域をVisual SLAMにおける特徴点追跡から除外することが考えられます。ここではディープラーニングを使った画像認識技術の1つであるセマンティックセグメンテーションが効果を発揮します。セマンティックセグメンテーションとは、画像から特定の物体の領域(輪郭)を抽出するための技術であり、例えば図6に示すように左の入力画像から右のような車両領域だけを抽出してマスクした画像を作り出すことができます。このようにマスクされた領域からはVisual SLAMのための特徴点検出を行わないようにすることで、周囲の移動物体からの影響を軽減することができます。

図6: セマンティックセグメンテーションによる車両領域の抽出
その他、例えば周囲をテクスチャのない壁に囲まれた道路や逆に周囲に何もない道路など、Visual SLAMに必要な特徴点がほとんど得られないシーンも大きな問題となっています。こうしたシーンでは特徴点に頼ったVisual SLAMは機能しないため、異なる方式のVisual SLAMやそもそもVIsual SLAMを使わないアプローチも検討する必要があると考えています。
おわりに
このブログでは、私たちが取り組んでいるドラレコ映像から道路の変化情報を自動抽出するプロジェクトにおいて、コアとなっているコンピュータビジョン技術の一部をご紹介しました。本プロジェクトはまだまだ発展途上であり、最後に述べた課題の他にも、コンピュータビジョン技術の社会実装にはたくさんの壁が立ちはだかっています。こうした壁を一緒に越えていってくれる仲間を募集中ですので、ご興味ある方は採用ページからお気軽にご連絡いただければと思います。また本プロジェクトの難しさや面白さについてエンジニアが語った記事も公開されておりますので、ぜひそちらも併せてご覧ください。