

GCP のコスト分析をするためのデータ整備
GCPデータ基盤December 14, 2022
タクシーアプリ「GO」、法人向けサービス「GO BUSINESS」、タクシーデリバリーアプリ「GO Dine」の分析基盤を開発運用している伊田です。本記事では GCP のコスト分析をするために実施したデータ整備について紹介します。
この記事は、Mobility Technologies Advent Calendar 14日目の記事です。
はじめに
本記事では、まず、チームの役割、そして GCP のコスト削減を実施するにあたり抱えていた課題について説明し、次にどのようなアプローチを検討して、実際に整備したデータパイプラインについて紹介します。
チームの役割
僕が所属しているチームでは、プロダクトが日々生成するデータを GCP BigQuery に収集するパイプラインを開発、運用しています。構築したデータ基盤はデータ分析や機械学習モデルの学習、推論に利用されており、さらにデータインフラという側面から MLOps としてのインフラ機能も提供しています。
詳細は MoT Tech Talk 「タクシーアプリ『GO』大規模トラフィックを捌く分析データ基盤の全容に迫る!」を参照頂ければと思います。
また、チームとしてのミッションの一つに、データインフラのコスト最適化があり、チームはインフラのコスト削減にも取り組んでいます。
※ MoT では、AWS、GCP、Azure のクラウドを利用していますが、チームが管理するのは主に GCP のため、この記事では GCP のコスト削減に焦点をあてます
課題
コスト削減をするにあたりコスト構造を分析していますが、下記のような課題がありました。
- 改善サイクルが遅かった
- 集計が自動化されておらず、月次で集計および振り返りを実施していた
- 効果測定ができていなかった
- 集計の粒度が荒く、コスト削減施策によるコスト減と、プロダクトの成長に伴うコスト増が混ざって、施策の効果測定が正しくできていなかった
アプローチ
上記の課題に対処するため以下のアプローチを取りました。
- データ収集を自動化し、改善サイクルを月次から週次に引き上げる
- コスト構造を細分化して、コスト増とコスト減の関係を明らかにして、正しく効果測定ができるようにする
これらを達成するためにデータ整備を実施することにしました。
データ整備
請求データ
GCP の請求データは BigQuery にエクスポートできます。ただし、チームの権限ではこの操作ができないため、SRE チームに対応して頂きました。詳細は「インフラコストをBigQueryで集約管理」を参照ください。
GCP の請求データの構造は こちら のドキュメントを参照ください。
この請求データからコスト構造を分解すると、
プロジェクトごと → 製品ごと → 製品詳細
と分解できます。よって、この請求データからコスト構造の概観を把握することができ、定点チェックに活用することができます。
ただ、製品詳細レベルだと足りない場合があります。
例えば、請求データから BigQuery のコスト構造を分解すると
- Analysis (スキャンコスト)
- Storage (Active / Long Term)
- Streaming Insert
の粒度となりますが、下記の問題点がありました。
- Analysis
- ユーザーごとのクエリ料金がわからない
- Storage
- テーブルごとの Storage 料金がわからない
- Streaming Insert
- テーブルごとの Streaming Insert 料金がわからない
他にも GCS のバケットごとの料金や PubSub の topic ごとの料金などが、この請求データからは把握できないようでした。代替となるデータを探したところ、BigQuery については INFORMATION SCHEMA、他の製品については Cloud Monitoring の API を叩けば必要なデータを収集することができそうでした。
※ 特にコストが掛かっている BigQuery, Pub/Sub, Dataflow, GCE, GCS について、ドリルダウンができるようにデータを整備しました
BigQuery INFORMATION SCHEMA
今回データ収集に使う INFORMATION SCHEMA は下記となります。
- Analysis
- Storage
- Streaming Insert
データ収集にあたり要件としては下記の通りです。
- INFORMATION SCHEMA は過去180日間分しか保持しないため、実テーブル化しておきデータの連続性をトラックできるようにします
- チームが管理するプロジェクトは複数ありますが、プロジェクトレベルの権限しか保持していません。プロジェクトを横串で参照できるようにするため、各プロジェクトの INFORMATION SCHEMA からデータを集約する必要があります
- INFORMATION SCHEMA はリージョンごとにテーブルがわかれています。リージョンを横串で参照できるようにするため、各リージョンのデータを集約する必要があります
リージョンまたぎ問題
現在、使用しているリージョンは US リージョンと asia-northeast1 リージョンの2つです。この2つのリージョンにある INFORMATION SCHEMA を US リージョンにあるテーブルに集約します。
ただし、 BigQuery は制約上、複数リージョンにまたがったクエリを発行することができません。
指定したロケーションがリクエスト内のデータセットのロケーションと一致しない場合、BigQuery はエラーを返します。
リクエストに関連するすべてのデータセット(読み取り / 書き込みを含む)の場所は、
推定されるジョブまたは指定されたジョブのロケーションと一致する必要があります。https://cloud.google.com/bigquery/docs/locations?hl=ja#specify_locations より引用
これはつまり US リージョンと asia-northeast1 リージョンにあるテーブル同士を JOIN したり、asia-northeast1 のデータを US リージョンのテーブルに書き込むということができないということです。
いくつか方法を検討したところ下記の手順で集約することにしました。
手順概略
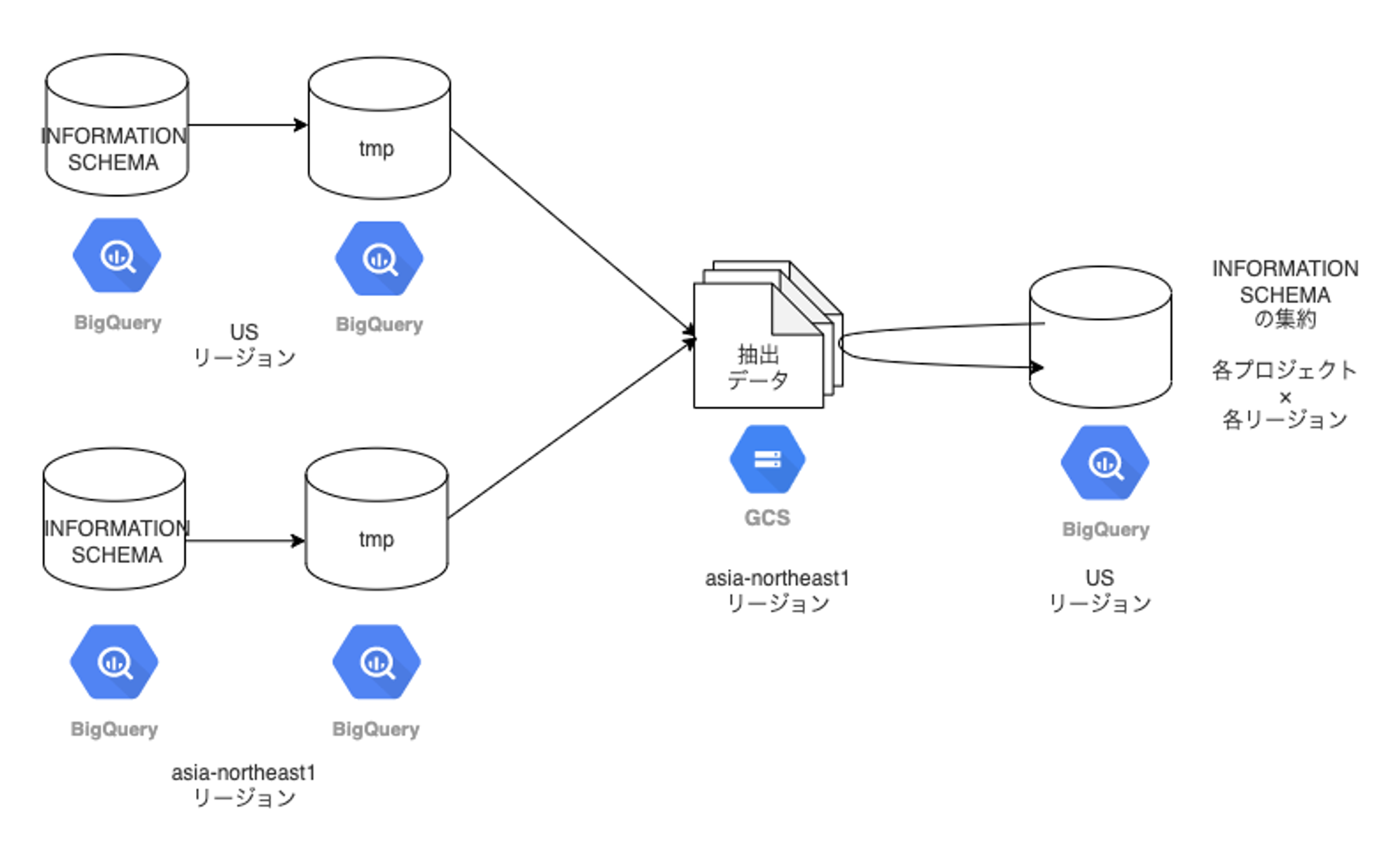
手順詳細
- INFORMATION SCHEMA を tmp テーブルに書き込む
- INFORMATION SCHEMA から直接 GCS に書き出せないようなので、CREATE TEMP TABLE AS 構文を使用して一度 tmp テーブルを経由する
- tmp テーブルを GCS にエクスポートする
- EXPORT DATA 構文を使用する
- GCS からテーブルに書き込む
- LOAD DATA 構文を使用する
※ この方式によって、BigQuery にクエリを投げるだけで済みます
GCS について
GCS へのエクスポートに関しては BigQuery の制限と同じく、同一ロケーションにしかエクスポートできません。ただし、例外としてデータセットが US リージョンにある場合は任意のロケーションにあるGCS にデータをエクスポートできます。
例外: データセットが US マルチリージョンにある場合、任意のロケーションにある
Cloud Storage バケットにデータをエクスポートできます。https://cloud.google.com/bigquery/docs/exporting-data?hl=ja#data-locations より引用
同様にロード時もデータセットが US リージョンにある場合は任意のロケーションの GCS からデータをロードできます。
例外: データセットが「US」マルチリージョンにある場合は、任意のロケーションの
Cloud Storage バケットからデータを読み込むことができます。https://cloud.google.com/bigquery/docs/batch-loading-data#data-locations より引用
これを利用して GCS (asia-northeast1) を1つ用意しました。
セッション
手順詳細の 1, 2, 3 を同一セッションで実施した場合、ロケーションの問題で 3 のロード処理がエラーになります。
- asia-northeast1 にある INFORMATION SCHEMA をもとに tmp テーブルを作成する
- このクエリによって、セッションロケーションが asia-northeast1 に固定される
- BigQuery (asia-northeast1) → GCS (asia-northeast1) に書き出し
- GCS (asia-northeast1) → BigQuery (US) に読み込み
- セッションロケーションが asia-northeast1 なので、データセットが US にあるテーブルに読み込みができない
よって、1, 2 の処理と 3 の処理を別セッションで実行して、INFORMATION SCHEMA のリージョンまたぎ問題を解決しました。
Cloud Monitoring
Cloud Monitoring API を利用しての収集は、Cloud Monitoring のグラフで描画される元となるデータを取りに行くイメージです。取得したデータを同じく BigQuery に書き込みしています。
取得できる指標は こちら
取得している指標の一例としては pubsub.googleapis.com/topic/message_sizes のメトリクスで、topic ごとのデータ量を収集しています。
元々は「Cloud Monitoringのメトリックを簡単にBigQueryにloadできるcloud_monitoring_metrics_fetchを作りました」を参考にさせて頂き、Python 実装を行いました。
データ整備の効果
請求データのエクスポートおよび BigQuery の INFORMATION SCHEMA、Cloud Monitoring API を利用して、データ収集を自動化し、コスト構造を細分化できるようになったことで下記の効果が得られました。
- 改善サイクルのスパンを短くできた
- コストの増減が正しく把握できるようになった
これらを正しく運用することでデータインフラのコスト最適化を図りたいと思います。
余談
先日 ZOZO さんの Tech Blog で「BigQueryのストレージ料金プランを変更して、年間数千万円を節約する」 という記事が公開されたのですが、調査したところ弊社でも新料金プランを使うことでストレージ料金を節約できることがわかりました。
勝手ながらこの場で御礼申し上げます。
おわりに
本記事では、まず、GCP のコスト削減にあたり抱えていた課題を説明しました。次に課題に対するアプローチおよび実施したデータ整備について紹介し、データインフラのコスト最適化を図るための土台が整ったことを説明させて頂きました。
この記事が皆様のご参考になれば幸いです。
We're Hiring!
📢
Mobility Technologies ではともに働くエンジニアを募集しています。
興味のある方は 採用ページ も見ていただけると嬉しいです。
Twitter @mot_techtalk のフォローもよろしくお願いします!