

MIRU2023参加レポート
AIコンピュータビジョン学会イベント論文August 09, 2023
AI技術開発部でコンピュータビジョン技術の研究開発を行っている鈴木です。GO株式会社は、2023年7月25日(火)から7月28日(金)の4日間浜松で開催された「MIRU2023(第26回画像の認識・理解シンポジウム)」のゴールドスポンサーを務め、企業ブースの出展及び研究発表を行いました。本多・宮澤・森本と共に参加してきましたので当日の様子やGOからの発表内容を紹介していきます。

会場となったアクトシティ浜松
MIRUとは
MIRUはコンピュータビジョンに関する国内最大規模の会議です。多くの研究者・技術者・学生が集まり、研究発表や討論などが行われます。

オーラル発表や特別講演が行われた大ホール
開催方式は昨年に引き続き対面+一部オンラインでも参加が可能なハイブリッド形式でした。参加者数は1513名と過去最高の規模だったとのことです。今年は展示ホールでのケータリング付きの交流会も開催され、参加者同士のコミュニケーションが活発に行われていました。お話させていただいたみなさまありがとうございました。

軽食やお酒の提供もあり盛り上がった交流会
企業展示
GOの企業ブースではコンピュータビジョンがコア技術として使われているAIドラレコを使った交通事故削減支援サービス『DRIVE CHART』と地図情報メンテナンスを効率化することを目的とした「道路情報の自動差分抽出プロジェクト」の紹介を行いました。こちらからのサービス紹介だけでなく、技術的なディスカッションを行うこともでき大変有意義な場となりました。

企業ブースの様子
今年4月に株式会社Mobility TechnologiesからGO株式会社に社名変更したことで、昨年と異なり多くの方に認知いただいているGOのロゴを出しての出展にもなりました。タクシーアプリの『GO』を使っている、知っているという声とともに足を止めてくださる方も多くありがたかったです。
研究発表
企業ブースのほか、インタラクティブセッション(ポスター発表)で2件の研究発表も行いました。それぞれ簡単に内容を紹介します。
画像特徴量の類似度を用いた道路標識の変化検知
著者:鈴木達哉, 劉国慶, 宮澤一之, 内田祐介
過去の画像と現在の画像を比較することで地図情報メンテナンスが必要な道路標識の変化を見つける仕組みを提案しました。道路標識の変化を見つける上では物体検出によるクラス分類やOCRといった画像認識により画像から抽出した情報を地図と比較することが考えられますが、あらゆる図柄・数値の標識に対して高い認識精度を実現することは困難です。この問題の解決策として、詳細な変化内容は分からずとも変化しているかどうかを顔認証で使われているような画像比較技術によって検知するという方法を考えました。
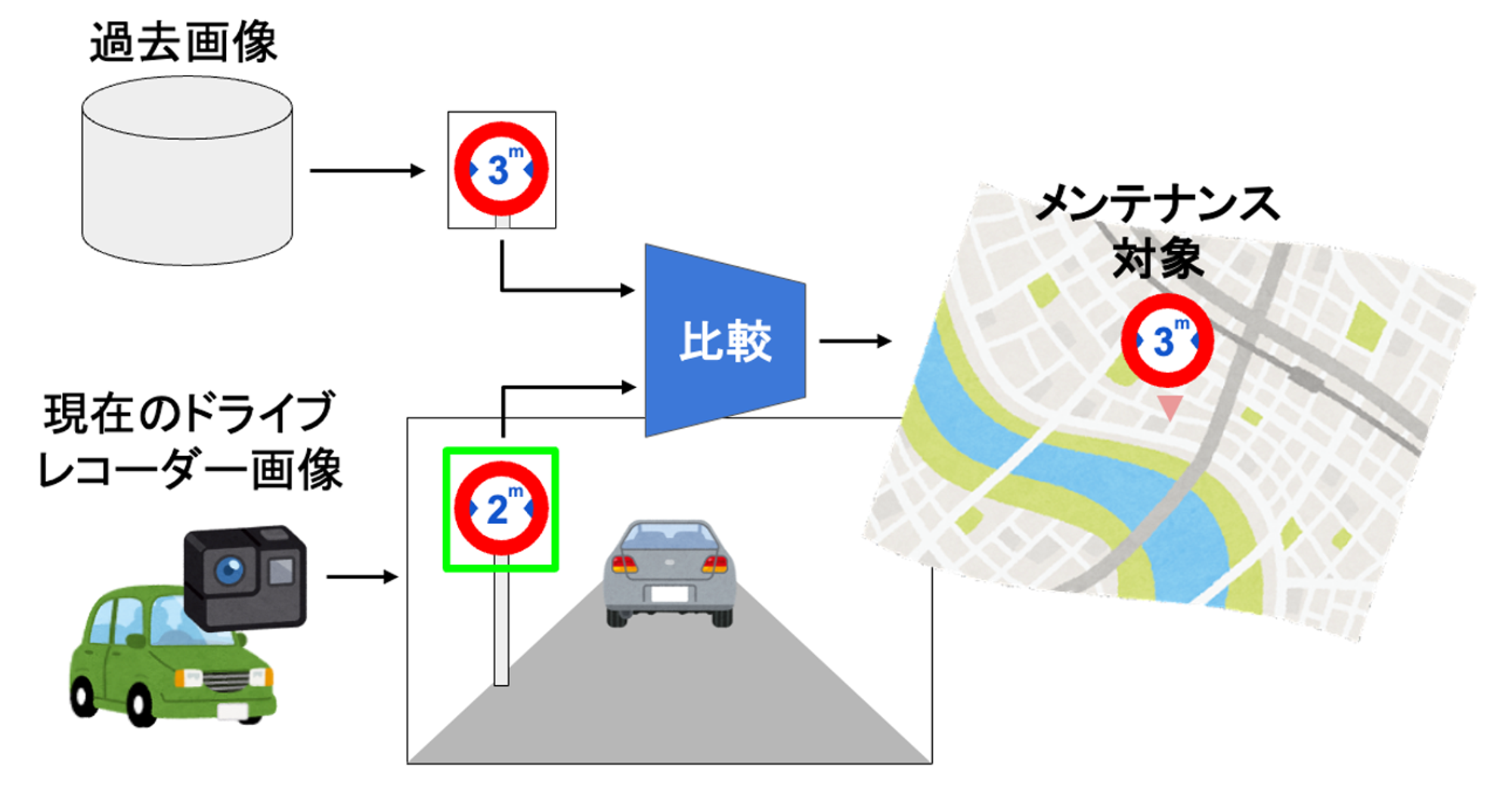
提案手法によるメンテナンス箇所特定の流れ
提案した仕組みの検証として自分たちで用意した学習・評価データセットにより実験を行い、顔認証で使われているArcFace等の手法により学習データには含まれない数値の標識の変化有無を8割以上の正解率で検知できることが確認できました。この研究成果は「道路情報の自動差分抽出プロジェクト」の中で活用していきます。
CLRerNet:LaneIoUによりレーン信頼度スコア学習を改善したレーン検出手法
著者:本多浩大, 内田祐介
レーン検出は画像中から道路の区画線を検出するタスクです。我々は今回、レーン検出の代表的ベンチマークCULaneにて、最高精度 (state-of-the-art, SOTA) 81.12%を達成しました (参考:papers with code)。arXiv論文や実装も公開しております。
最近のレーン検出では、既定水平線上のx座標の集合として表現する手法が高性能を達成しています。推論時に100以上のレーン候補から数本を選ぶために、それぞれのレーンに信頼度スコアが推論されます。事前実験により、信頼度スコアを正解との重なり度(Intersection Over Union, IoU)と正確に一致させることが重要であることを見出しました。
我々は、レーンがどのような角度・形状であっても正確にIoUを計算できるLaneIoUを新たに定義し、学習対象アサイン関数や損失関数として用いることで、従来の精度を上回りSOTAを実現しました。
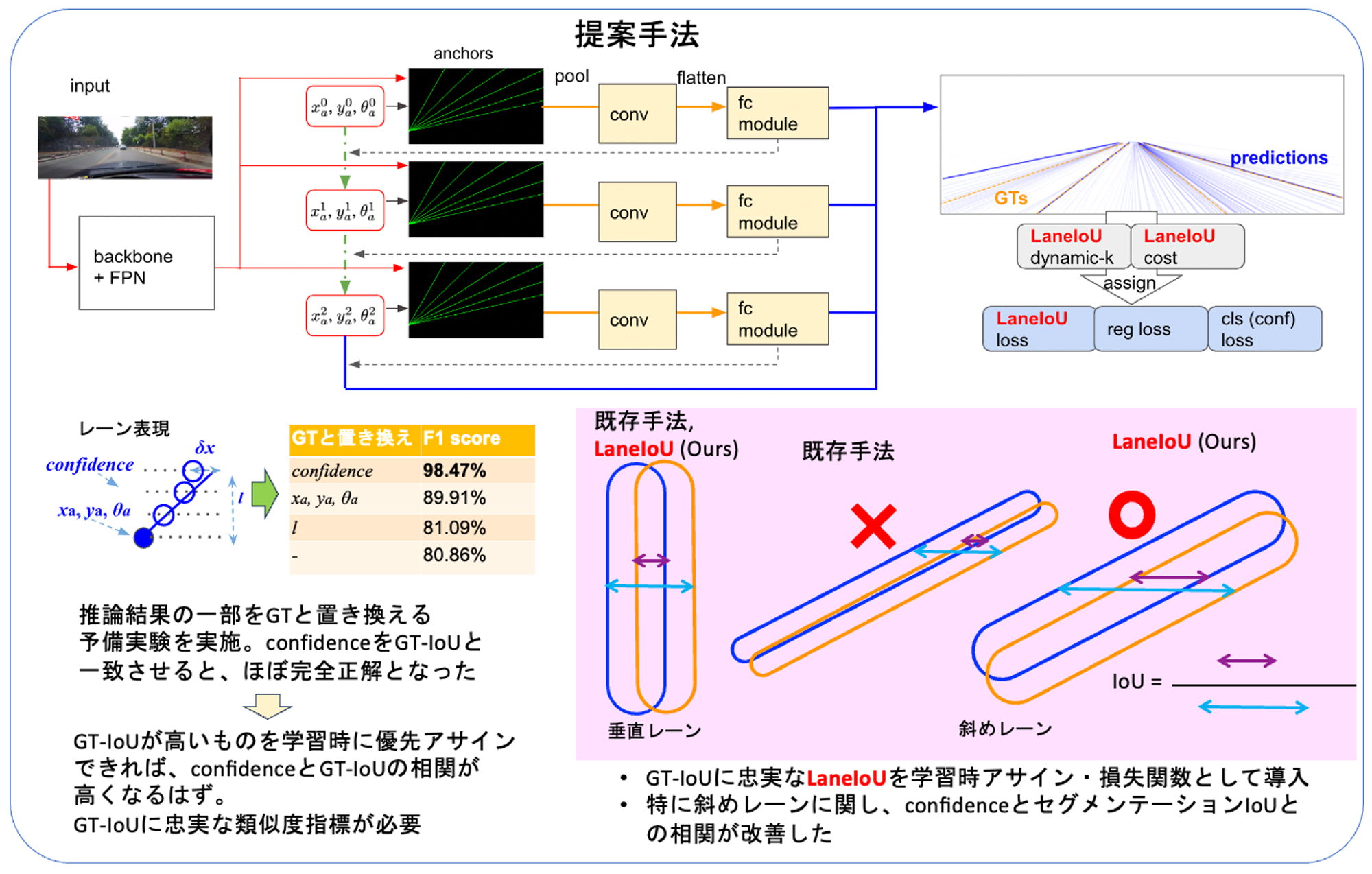
レーン検出でSOTAを達成したCLRerNetの手法図 (MIRU発表ポスターより抜粋)
気になった発表
MIRU2023ではオーラル・ポスター発表あわせて400件以上の発表が行われました。私たちが聴講した中で気になった発表の一部をここで紹介します。
StableSeg: Stable Diffusionによるゼロショット領域分割
本部 勇真, 山口 廉斗, 柳井 啓司 (電気通信大学)
MIRU優秀賞を受賞された論文です。セマンティックセグメンテーションの分野は大幅に性能が向上しているものの、大規模事前学習モデルがセグメンテーションに特化していないため多くの研究でアノテーションデータを用いた追加学習を必要とする問題があります。この研究ではStable Diffusionを使用し追加学習することなくセグメンテーションを可能にする手法を提案し,コスト削減の実現とその有用性を示しています。具体的には、追加学習が一切不要なゼロショット領域分割を実現する StableSegの提案に加え、疑似マスクを生成してセグメンテーションモデルを学習する StableSeg++も提案しています。個人の所感として、アノテーションコストは時間的費用的にも避けられないのが現状です。このような研究を起点にアノテーションをより良くしていく仕組みを作っていきたいです。
物体検出の半教師有りおよび弱教師有りドメイン汎化
古田諒佑, 佐藤洋一 (東大)
推論するデータのドメイン(この論文では画風や車載カメラの天候・時間帯)が学習時と異なると精度が大きく低下する課題に対しての研究です。従来、複数ドメインのラベル付きデータを用意することで未知のドメインにも汎化する方法が提案されていますが、物体検出の場合はアノテーションコストが高いためデータの用意が困難です。そこで、この研究では複数ドメインのデータを用意するが1つ以外のドメインにはラベルを付けない半教師ありドメイン汎化、1つ以外のドメインにはバウンディングボックスはなしで画像単位のラベルだけを付ける弱教師ありドメイン汎化というタスクを提案しています。このタスクに対して、1つのネットワークの出力を疑似ラベルとしてもう1つのネットワークを学習するStudent-Teacher学習を採用した手法を使うことで、比較手法を上回る性能が発揮されることを確認しています。
GOでは、車載カメラ映像に対する物体検出を行っており、様々な状況への汎化は重要な課題です。データ用意のコストを下げながら汎化可能な本研究は興味深い提案でした。
Explainability Enhancement Module for End-to-End Driving Models by Focusing on the Important Objects
Chenkai ZHANG, Daisuke DEGUCHI, Hiroshi MURASE (名古屋大学)
自動運転 (AD) パイプラインは、1) 複数のタスク (認識、予測、計画) に対応する個別モデルの組み合わせ、2) 入力データ シーケンスに対する行動・計画を出力するfully end-to-endモデルに大別されます。end-to-endモデルはシンプルですがブラックボックス的な性質があるため、モデルの動作と障害モデルを理解するにはexplainability(説明可能性)が鍵となります。この論文はこの問題に対し、物体のbounding boxをlabeとして活用、オブジェクトらしさのヒート マップを学習する ”objectifi-cation”ブランチと、説明可能性を高めることを目的とした”refinement”ブランチを提案し、本来のタスクである行動予測の精度向上を実現しています。
GOでは、交通事故リスク予測のための認識モデルを開発しており、モデルの説明可能性はやはり重要です。また、ブラックボックス モデルに複数のラベルを導入するとパフォーマンスが向上するという結果は良い知見となりました。
LanesPose: 骨格推定によるレーン検出
玄元奏 (立命館大), 飯田啄巳, 小西嘉典 (SenseTime Japan)
車載カメラ画像からのレーン検出は運転支援や自動運転における重要なタスクであり多くの従来研究がありますが、本論文ではOpenPoseなどの人体の骨格推定手法に着想を得たオリジナリティの高い手法を提案しています。特に、レーンを1つずつ独立に扱うのではなく、複数のレーンをまとめて1つの骨格として捉えることでレーン間の関係性を考慮できるようにしています。これにより、例えばあるレーンがオクルージョンなどにより隠されている場合でも、見えている他のレーンの情報を利用して隠されたレーンを検出することができます。本論文では、まず各レーンをキーポイントの集合として表し、レーンの形状に応じてそれぞれのキーポイントの重みを変化させています。そして、レーン内およびレーン間のキーポイント同士の距離に基づいてそれらの接続関係を定義し、OpenPifPafと呼ばれるOpenPoseを発展させた人体の骨格推定手法を使ってレーン検出を行なっています。GOからの研究発表にもあるようにGOでもレーン検出を開発していますが、複数のレーン間の関係性を考慮することでロバスト化を図った本手法は特に悪条件での性能低下が問題となる実応用において大変有効ではないかと感じました。
特徴の変換に基づく選択的忘却
後藤優太 (東京理科大), 柴田剛志, 木村昭悟 (NTT), 入江豪 (東京理科大)
MIRUにおける最優秀論文賞である長尾賞を受賞された論文です。一度学習したモデルに対してさらに新たなクラスを追加して学習していく継続学習においては、すでに学習したクラスは精度を低下させずに「記憶」できるようにするのが一般的ですが、本論文では選択的に「忘却」もできるようにしています。著者らはすでに入力画像に対して特殊なコードを埋め込むことで特徴空間上の凝集性を変化させ、記憶と忘却の制御を実現する手法を2021年に提案していますが、本論文では入力画像ではなくそこから得られる特徴に対してコードを埋め込むことで大幅に精度を改善しています。入力画像の値の範囲は既知ですが、特徴の場合は未知となるため、特徴へのコードの埋め込みにおいては両者のスケールの不整合が問題となります。本論文では、新たな正規化層としてStandMixを提案し、バッチ正規化の中で行われる標準正規化の直後にコード埋め込みを行うことでこの問題を解決しています。例えばプライバシー配慮や漏洩防止等の観点から一度学習した内容を「忘却」したいケースは多くあると考えられ、コンピュータビジョンの社会実装という観点からも大変興味深いテーマであると感じました。
さいごに
昨年のレポートでは次回は研究の発表もできるよう取り組んでいきますと書いていたのですが、宣言通りGOからの研究発表が実現でき充実したMIRUへの参加となりました。ポスター発表・企業ブースともに多くの方と議論することができ学会という場の価値を強く実感できた1週間でした。ここで得た知見・経験をプロダクト開発に活かしていきます。次回MIRU2024は熊本での開催です。来年またみなさまにお会いできること楽しみにしております。

名物のうなぎを楽しむこともできました
We're Hiring!
📢
GO株式会社ではともに働くエンジニアを募集しています。
興味のある方は 採用ページ も見ていただけると嬉しいです。
Twitter @goinc_techtalk のフォローもよろしくお願いします!