

ドライブレコーダ映像からの走行レーン番号認識
AIDeep Learningコンピュータビジョンこんにちは、Mobility Technologies (以下 MoT) の AI 技術開発部 AI 研究開発第二グループのパエです。MoT では、タクシー配車以外にも、MaaS 発展のための次世代サービス実現に向けて研究開発を行なっています。本記事では、そうした取り組みの一つとして我々が開発中のドライブレコーダ映像から自車両が走行するレーンの番号を認識する技術について紹介します。
はじめに
ドライブレコーダというと事故が起きた際の映像記録などが主な用途として思い浮かびますが、それ以外にも多くの応用が可能です。実際に MoT でも、車内外を写したドライブレコーダの映像などを元に AI によって危険運転状況を可視化し、ドライバーの運転特性を把握して交通事故削減につなげる「DRIVE CHART」というサービスを商用車向けに展開しています。また、地図情報のメンテナンスに活用するため、ドライブレコーダ映像から道路変化情報を自動抽出する技術の開発も進めています [1]。
AIにより画像や映像を解析する技術分野はコンピュータビジョン (CV) と呼ばれますが、今や CV は MaaS と関連の深い ADAS や自動運転に必須の技術となっており、中でも道路上の白線の検出は古くから活発な技術開発が進められてきました。その主な目的は自車両が現在走行中のレーンから逸脱しないようにコントロールすることですが、自車両がその道路の何レーン目を走行しているのかという情報も地図上での自己位置推定などの観点で重要になります。本記事では、自車両が走行するレーンが道路の左端から数えて何番目なのかをドライブレコーダ映像から認識するタスクを「走行レーン番号認識」と呼ぶこととします。
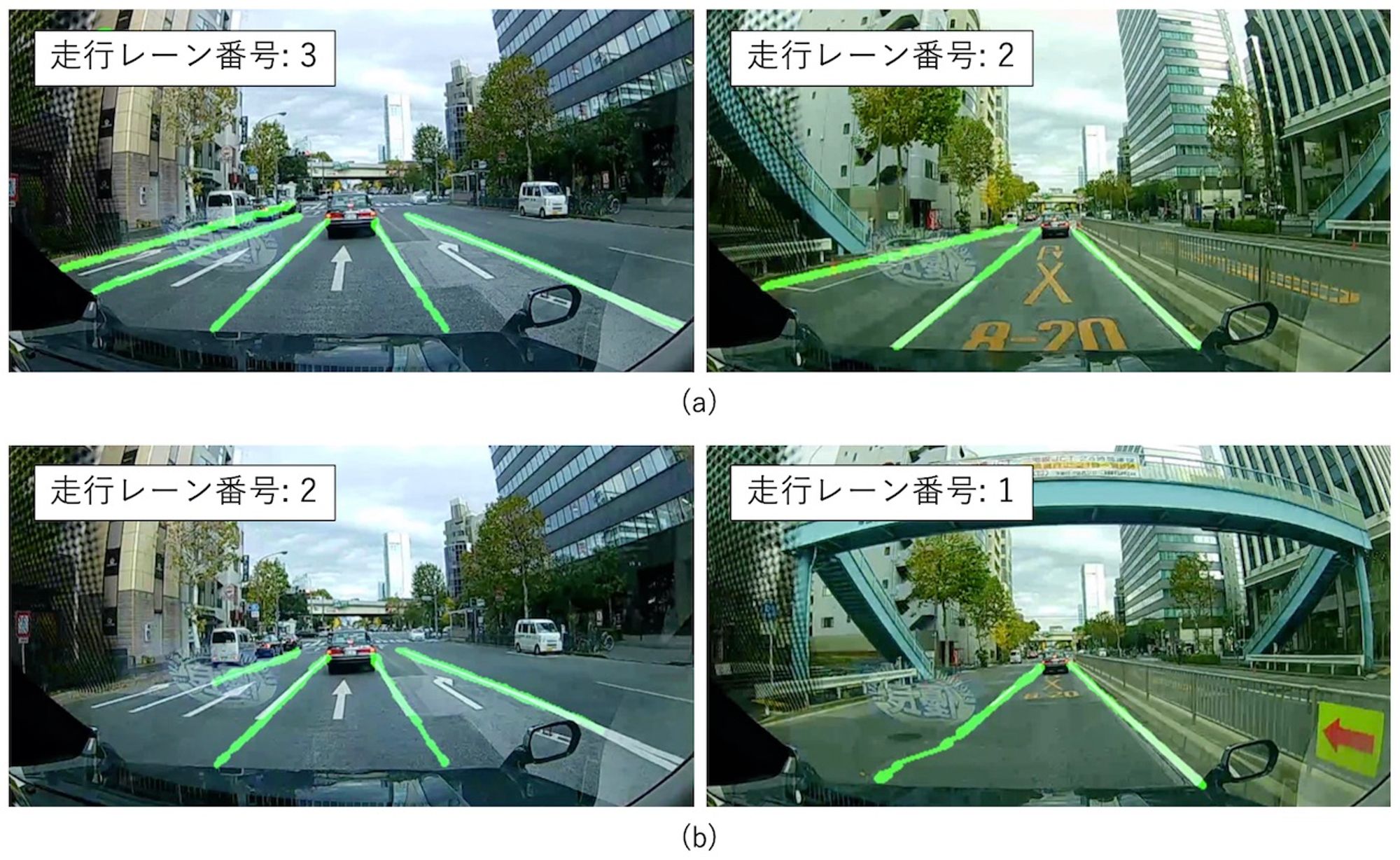
図 1 検出した白線のカウントによる走行レーン番号認識
白線検出ができるのであれば、単にその本数を数えれば走行レーン番号認識もできてしまうように思えますが、一般に画像認識にはエラーがつきものであり、特に走行レーンの隣やその隣の白線まで完璧に検出することは困難です。図 1 では検出された白線を緑で示していますが、同図 (a) では全ての白線を正しく検出できているため走行レーン番号認識にも成功しています。一方で同図 (b) では左端の白線が検出できておらず、結果として走行レーン番号も誤っています。このように、検出した白線の本数を直接的に数えるだけでは白線検出の精度に大きな影響を受けてしまうため、我々はよりロバストな走行レーン番号認識の実現に向けた検討を実施しています。本記事では、走行レーン番号を認識するモジュールへ入力するデータの違いによりどのように認識精度が変化するかを調査した結果について紹介します。
検討した入力データのバリエーション
今回の検討では、認識モジュールへ入力するデータのタイプを変えて図 2 に示す 4 つのモデルを検討しました。それぞれについて説明します。
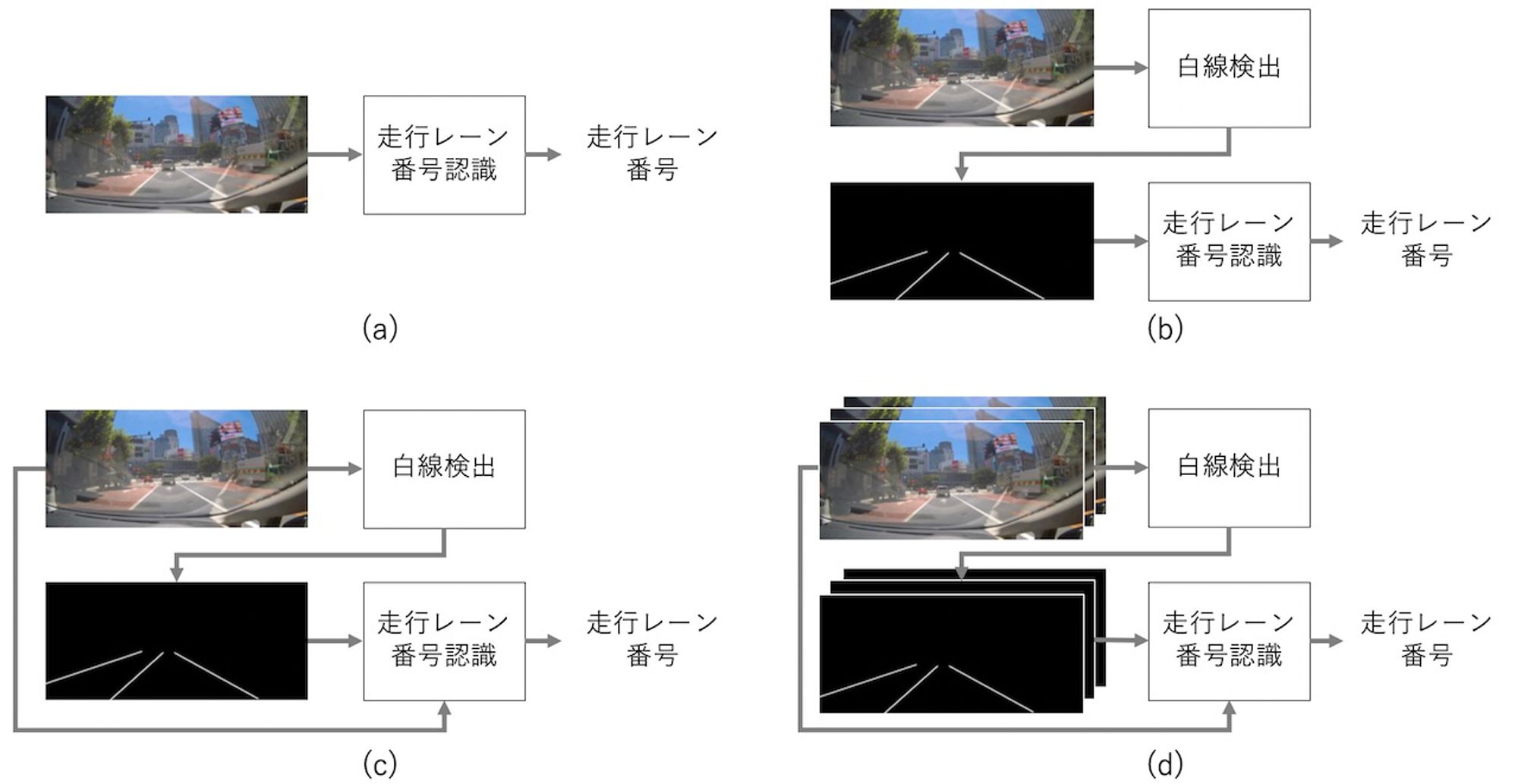
図 2 検討した入力データのバリエーション
画像のみ
まず、図 2 (a) は画像のみを入力とする最もシンプルなモデルであり、ドライブレコーダ映像の各フレームを入力として受け取って走行レーン番号を出力します。画像からの走行レーン番号認識には、機械学習を使った画像認識におけるデファクトスタンダードである畳み込みニューラルネットワーク (CNN) を利用し、画像のクラス分類問題に帰着させています。今回利用した CNN のアーキテクチャについては後述します。
白線検出結果のみ
図 2 (b) は白線検出の結果を直接的に数えるモデルです。白線検出の結果を見ると、自車両の位置を境に左側にある白線は正の傾きを持ち、右側にある白線は負の傾きを持つことがわかります。したがって、検出された白線の中から正の傾きを持つものをカウントすることで自車両の走行レーン番号を知ることができます。つまり、このモデルでは白線検出の結果があれば CNN のような機械学習手法を使わずに単純な画像処理のみで走行レーン番号を認識できますが、前述したように白線検出の結果に精度が大きく左右されるという課題があります。
画像 + 白線検出結果
図 2 (c) は (a) と (b) を組み合わせたモデルで、ドライブレコーダ映像の各フレームと、そこから白線を検出することで得られたバイナリマップを結合したものを入力データとします。ここで、バイナリマップとは、例えば白線に相当する画素が 1、それ以外の画素が 0 であるような 2 次元マップです。走行レーン番号認識には (a) と同様 CNN を用います。
画像 + 時系列白線検出結果
図 2 (d) は (c) を時間方向に拡張したものです。ドライブレコーダ映像は時間方向に連続した複数のフレームで構成されているため、例えば時刻 のフレームにおける走行レーン番号を認識するのに時刻 や のフレームも使うことができます (ただし未来や過去のフレームをどの程度利用できるかはアプリケーションに依存します)。 何枚のフレームを使うべきかは自明ではありませんが、今回は単純に 、、 の 3 枚のフレームを用いています。具体的には、時刻 、、 の 3 枚のフレームのそれぞれに対する白線検出結果 (バイナリマップ) と、時刻 のフレーム (合計 4 枚) を結合して入力データとします。ここでも走行レーン番号認識には CNN を用います。
走行レーン番号認識と白線検出モデル
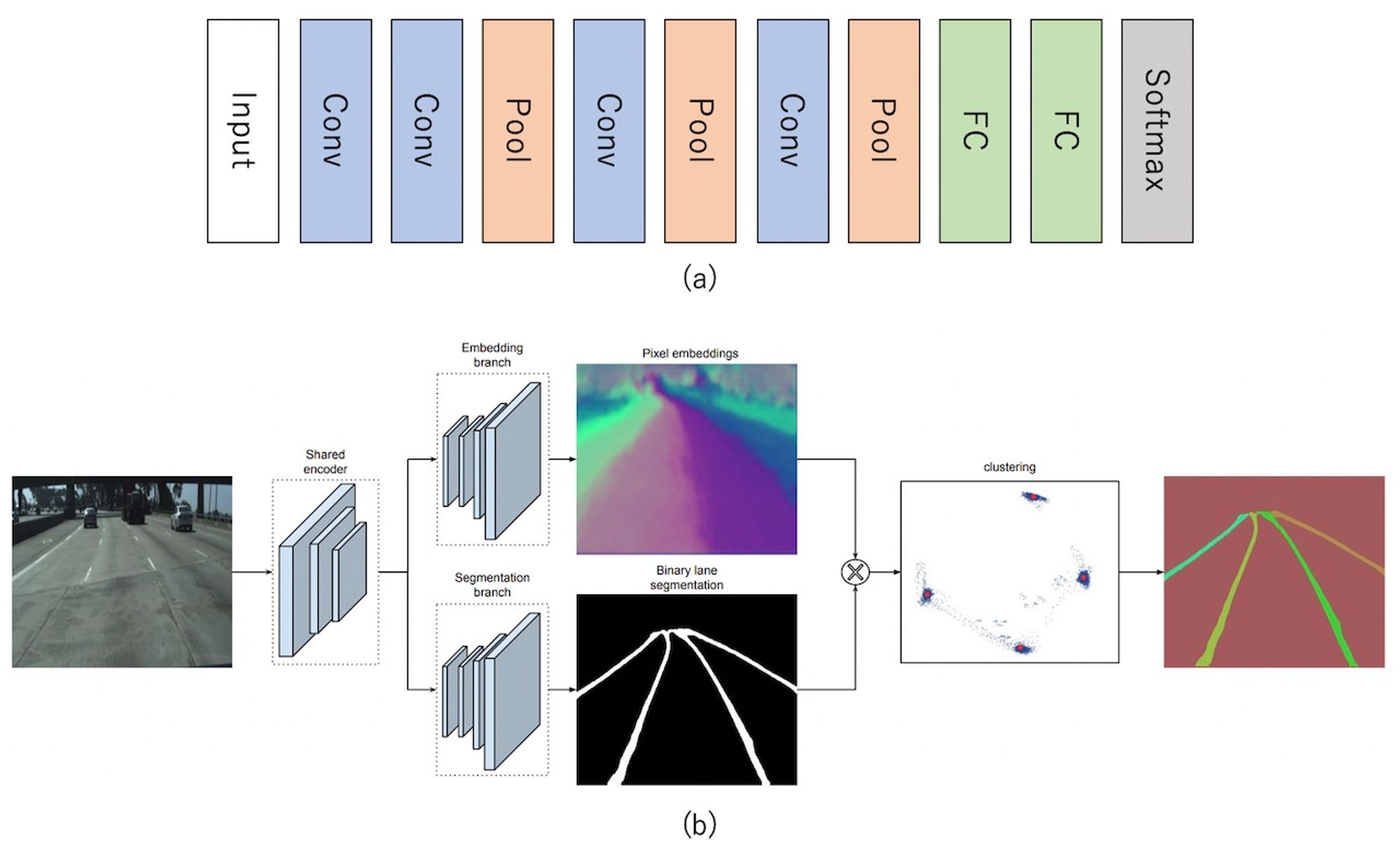
図 3 走行レーン番号認識モデルと白線検出モデル
図 2 で利用した走行レーン番号認識と白線検出のモデルは図 3 の通りです。今回の検討における目的はあくまでも図 2 に示したバリエーションの性能差を調べることであるため、走行レーン番号認識のためのモデルは図 3 (a) に示すシンプルなアーキテクチャを持つ CNN で構成しました。
白線検出については、LaneNet [2] と呼ばれる既存手法を用いました。こちらは 2018 年にルーベン・カトリック大学の研究チームが提案したインスタンスセグメンテーションに近いアプローチで、一枚の入力画像から CNN を用いて白線に相当する画素を表す 2 次元マップを出力します。図 3 (b) は LaneNet のアーキテクチャ図を論文より引用したものですが、入力画像から CNN により低解像度な特徴マップを抽出し、そこから再び CNN を使って画像と同じ解像度のマップを生成しています。
認識精度評価
図 2 に示した 4 つのモデルの認識精度を評価する実験を行いました。実験にあたっては独自に収集したドライブレコーダの映像から 7000 フレームを利用し、各フレームに対し走行レーン番号のアノテーションを実施しました。アノテーションでは、フレームを目視で確認し、そのフレームにおける自車両が走行しているレーンが左から数えて (i) 1 番目、(ii) 2 番目、(iii) 3 番目、(iv) 4 番目以降、(v) 判定不能、のいずれであるかをラベル付けしました。したがって、図 3 (a) に示した CNN モデルは、5 クラスの画像分類問題を解くように学習しています。なお、我々のデータではクラスごとのサンプル数が不均衡であったため、これを緩和するようにロスに対してクラス数に応じた重みを設定しています。
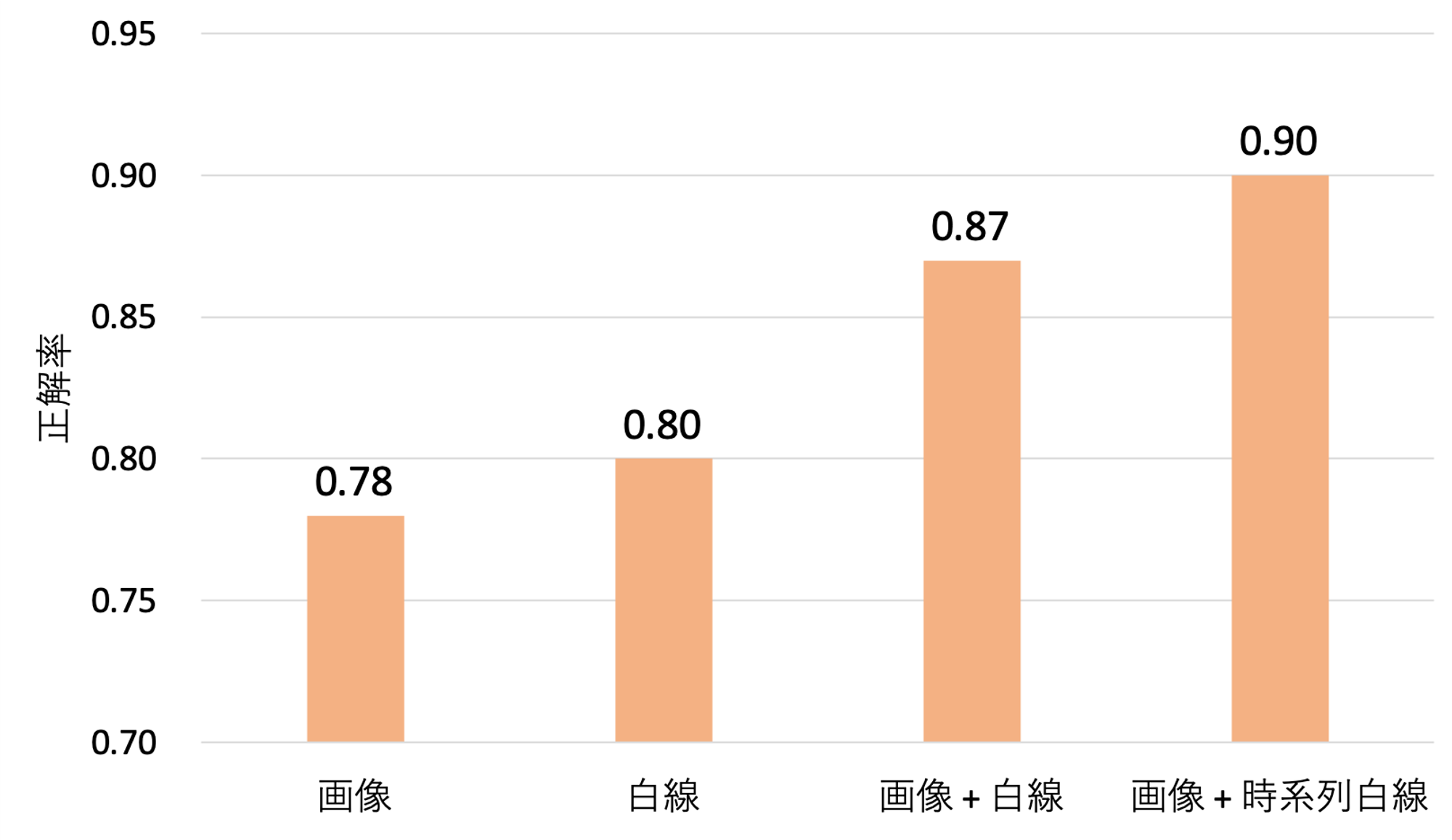
図 4 認識精度評価結果

図 5 認識結果例
実験結果を図 4 に示します。こちらは、全データのうち 80% で学習し、残り 20% を使って評価した結果です。横軸が図 2 に示した 4 つのモデル、縦軸が正しくレーン番号を認識できた割合です。この結果を見ると、画像または白線検出結果の一方だけを用いる場合に比べて両者を組み合わせることで大幅に認識精度が改善していることがわかります。
図 5 は認識結果の例ですが、同図 (a) に示す入力画像を見ると自車両の走行レーンは左から数えて 3 番目であり、画像と白線検出結果の両方を使った図 2 (c) のモデルでは正しく走行レーン番号の認識ができていました。一方で、同図 (b) は同じ画像に対する白線検出結果ですが、図中に黄色の破線で示しているように最も左側の白線の検出に失敗しています。したがって検出された白線を数える図 2 (b) のモデルでは走行レーン番号を 2 と誤認識しますが、画像を併せて利用することでよりロバストな認識が可能となっていることがわかります。
また図 4 の結果からは白線検出の結果を時系列で複数利用することも効果的であり、90% という非常に高い認識精度が達成できていることがわかります。これは、あるフレームで白線検出に失敗したとしても、時間方向に隣接するフレームでは検出に成功するケースがあるため、複数のフレームにおける白線検出の結果を統合して利用することでさらなるロバスト化ができるためと考えられます。
おわりに
本記事では、ドライブレコーダの映像から自車両が走行しているレーンの番号を認識するという課題に対する MoT の取り組みをご紹介しました。少し変わった課題のようにも思えますが、地図上での走行位置の特定やナビゲーションの高度化という観点で重要になります。また、白線検出の結果を数えるだけでは白線検出の精度に大きな影響を受けるという問題があるため、よりロバストな走行レーン番号認識の実現に向けた検討を実施しています。
今回は主に入力データの観点からデータの形式と認識精度との関係を調査し、画像と白線検出結果の両方をフュージョンして用いることで大きな精度向上が得られることを確認しました。今後も引き続き検討を進め、入力モダリティをさらに増やすことや認識モデルの高度化などにトライしていきたいと考えています。なお、本記事に関連した内容は論文 [3]、[4] としてもまとめています ([4] については 10 月に発表予定)。
最後になりましたが、MoT では、AI 技術の実応用に向けてエンジニアを募集中です。現在募集中のポジションはこちらの通りですので、少しでもご興味ある方はぜひご連絡をいただければと思います。
参考文献
[1] MoT プレスリリース, 2020 年 4 月 22 日.
[2] D. Neven, B. D. Brabandere, S. Georgoulis, M. Proesmans, and L. V. Gool, "Towards end-to-end lane detection: an instance segmentation approach," IV2018.
[3] P. Chetprayoon and F. Takahashi, "Prediction of lane number by combining results from lane detection," JSAI2020.
[4] P. Chetprayoon, F. Takahashi, and Y. Uchida, "Prediction of lane number using results from lane detection," GCCE2020.