

Kaggle のデータ分析コンペ TReNDS Neuroimaging で『3位 / 1,047チーム』を獲得しました :)
KaggleAIDeep LearningNews初めまして。MoTのAI技術開発部アルゴリズム第一グループの島越 [1]です。本ブログでは、私が最近ソロで3位入賞を達成したKaggleのコンペティション「TReNDS Neuroimaging」で行った取り組みについて紹介したいと思います。また、今回使用したコードについては、github上でも公開しているのでよろしければそちらもご覧ください。
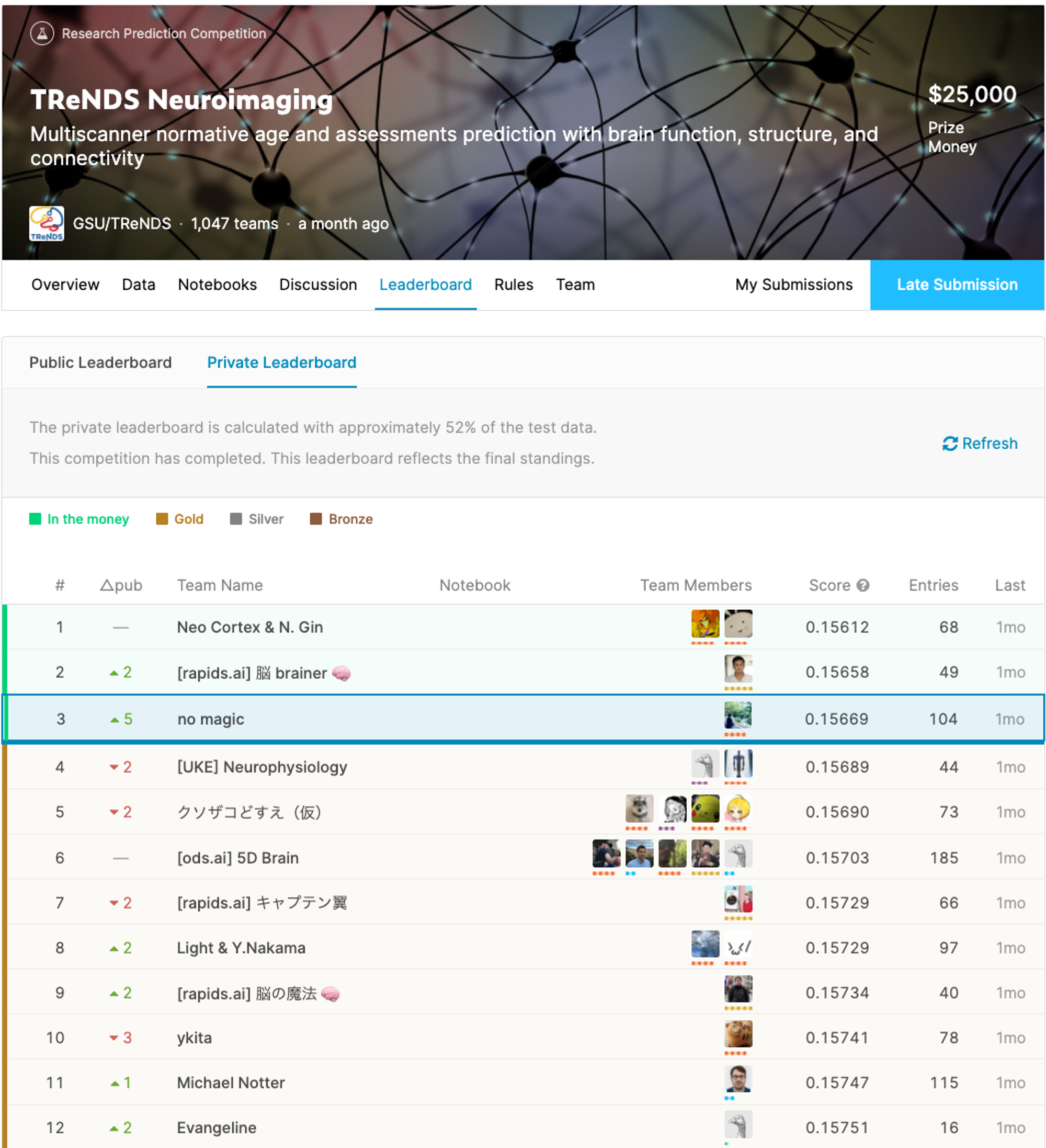
図1:最終順位発表後におけるTReNDS NeuroImagingのLeader Board
Kaggleについて
Kaggle (カグル)とはGoogleを母体とするKaggle社が運営する世界最大のデータ分析プラットフォームです。Kaggle社は、一般の企業や研究期間などから課題を募り、課題作成の支援やプラットフォームの提供を行います。そうしてKaggleのウェブサイト上で公開された課題に対して世界中のデータサイエンティストが挑み、日々精度を競っています。
Kaggleでは年間を通して複数のコンペが開催されており、私はそのうちの一つである「TReNDS Neuroimaging」に参加しました。
コンペの概要
タスクについて
今回私が参加した「TReNDS Neuroimaging」はジョージア州立大学/ジョージア工科大学/エモリー大学の3つのアカデミアによる組織である Center for Translational Research in Neuroimaging and Data Science (TReNDS)が開催したコンペティションです。
人間の脳の研究は、科学者にとって最も複雑な研究分野の一つと言われています。「TReNDS Neuroimaging」はそのような人間の脳に関するコンペティションで、脳のfMRI (functional MRI)データと前もって出題者が脳データから抽出したテーブル特徴量が提供されました。これらのデータを元に年齢と4つの匿名化された評価値[2]を予測することが、今回のコンペティションの目的となります。この4つの評価値はdomainによって分かれており、コンペ内では[domain1_var1, domain1_var2, domain2_var1, domain2_var2]と呼ばれていました。
評価指標
評価指標は、以下の式で表されるWeighted Normalized Mean Absolute Errorsが用いられました。
ここで、 はtargetの種類(年齢など)、 はサンプルindex、 は正解、 は予測値を表しています。各targetに対する重みは年齢が重要視され、[age, domain1_var1, domain1_var2, domain2_var1, domain2_var2] に対して、[0.3, 0.175, 0.175, 0.175, 0.175]のように主催者側から設定されていました。この評価指標に対して、いかに値を低くできるかが今回のコンペの競争ポイントとなります。
データについて
Kaggleでは答えが与えられているデータを訓練データ、答えが与えられていないデータをテストデータと呼びます。このテストデータに関しては、さらにPublicデータとPrivateデータというものに分割され、PublicデータについてはKaggleのページ上で予測をsubmitすることで精度を確認できますが、Privateデータに関してはコンペが終了するまで確認することができません。このPrivateデータの精度によって最終順位が決定されるため、参加者は訓練データとPublicの精度のフィードバックを利用してPrivateのスコアを上げることに注力します。よくある失敗としては、Publicデータのサンプル数が少ない時や、PublicとPrivateのデータの分布が異なる時に、Publicデータの精度を信頼しすぎてしまうことです。このコンペでは、訓練データとテストデータに5877件ずつ与えられ、PublicとPrivateでデータが半分に分割されていました。
このコンペで提供されたデータの特徴としては、以下のようなものが挙げられます。
まず、一つ目に関して説明します。通常脳のfMRIデータは3次元のvoxelデータで提供されますが、今回は、データ提供者によって注目したい脳の部位ごとにvoxelデータが53成分に分離されていました。そのため、一人の脳データが53x48x56x45という巨大なデータになっていました。今回扱う脳データより入力として小さい画像認識でも、汎化的な性能を出すためには数十万の画像を必要とすることが多いことから考えると、今回訓練データとして与えられた5877件というデータがいかに少ないかということが分かると思います。一般的に、高次元のデータを十分に説明できるモデルを構築するためには、パラメータ数の多いモデルを用意する必要がありますが、今回の場合だとパラメータ数の多いモデルを使ってしまうと訓練データに過学習してしまう可能性があったので、そのことに留意する必要がありました。
次に二つ目に関してです。今回のコンペでは、テストデータの中にのみ違う機器を使って計測したfMRIデータ (Site 2データ)がいくつか混在しているということが明言されており、機器の違いに精度が左右されないモデルを作成することが求められていました。また、そのようなSite 2データについて一部の510件だけ公開されており、それをどう用いるかもこのコンペの工夫点の一つだったのではないかと思います。コンペ終了後に提供された資料によると (図2)、テストデータ全体5877件のうち、2037件がSite 2のデータだったようです。更に、公開されていたSite 2データは全てPublicデータに含まれており、公開されているSite 2データにのみ対策を行っていたチームはPublicデータに過学習してしまうという問題もあったようです。
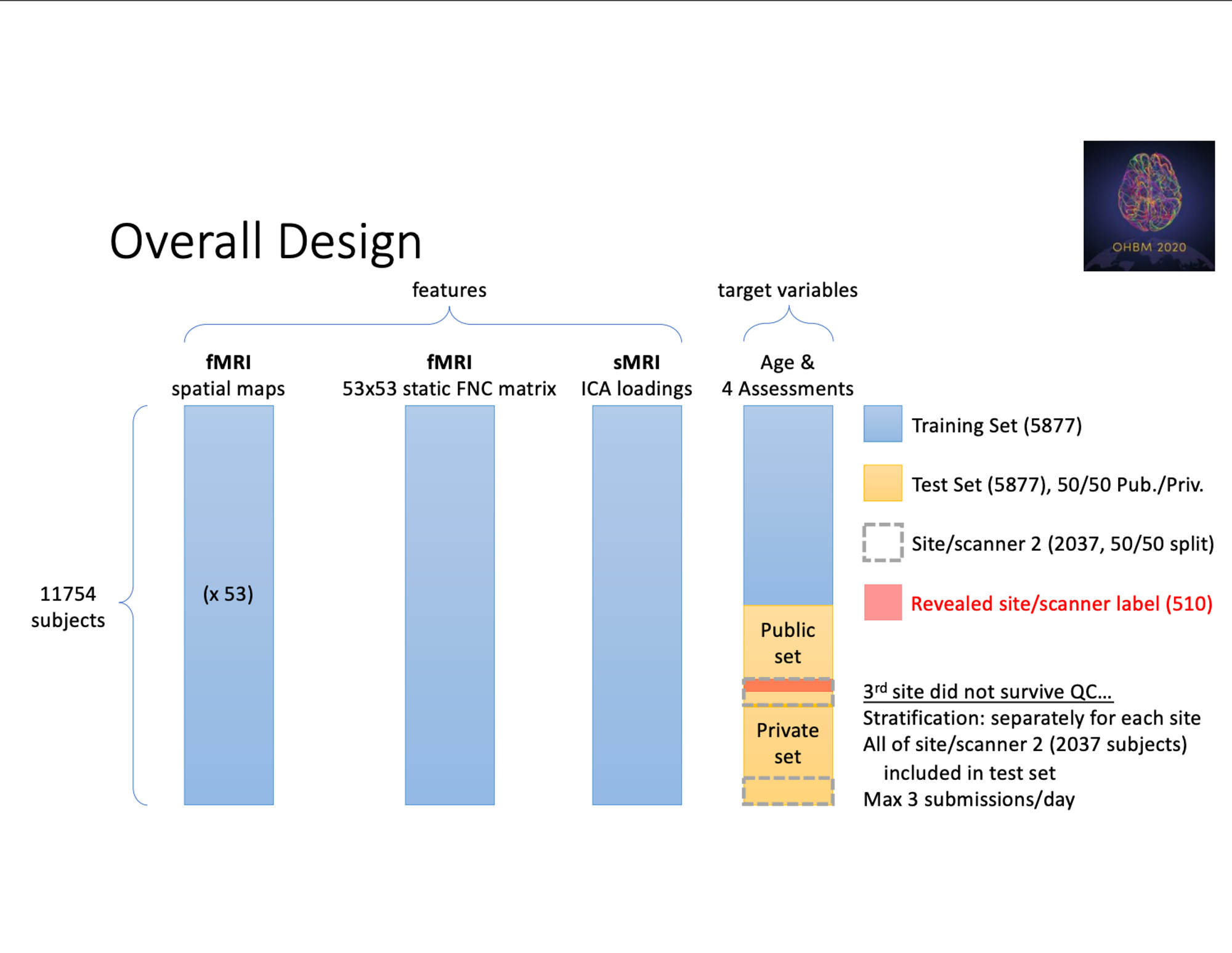
図2:
最後に三つ目に関してですが、年齢について匿名化のためのround処理が入ってると明言されていました。実際にデータを見てみると確かに図3の様に丸められており、この処理がテストデータには入ってないとすると、過度に訓練データにfitするのは危険な匂いがします。結果から言ってしまうと、この対策はあまり必要なかった様ですが、コンペ中は隣り合う値の間の値に一定の確率で変換させるなどして、過学習を防ごうとしていました。
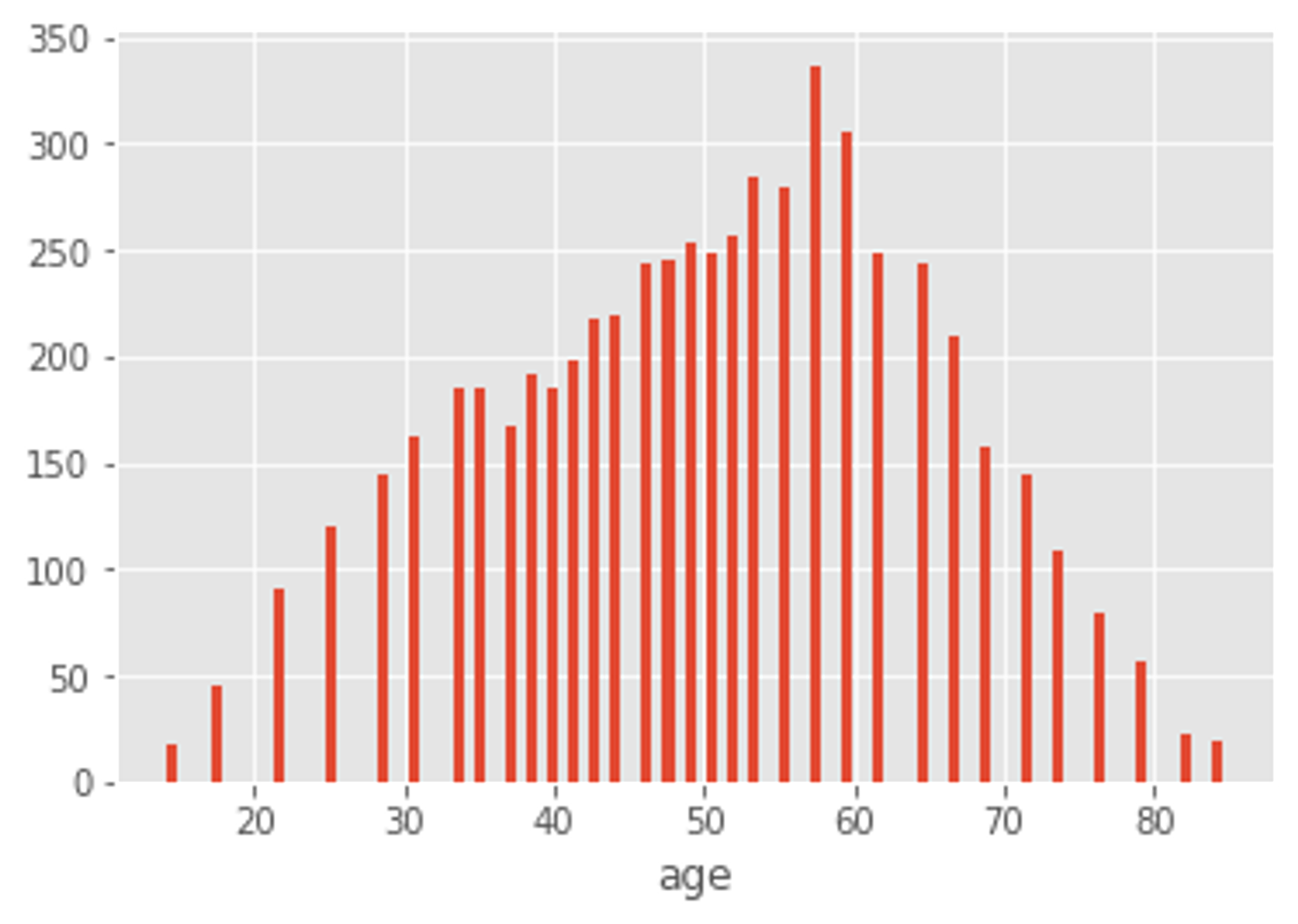
図3:訓練データにおける年齢のヒストグラム
島越の解法 (3rd place)
ここからは、上述したコンペティションで私が3位入賞した解法の概要について紹介します。
概要
まず、最終的なモデルとして図4のようなモデルを作成しました。私の解法のポイントとしては、以下の三つになります。
- Stacking
- モデルの構造による多様性
- Stackingの手前でのNoisyな予測値の除去
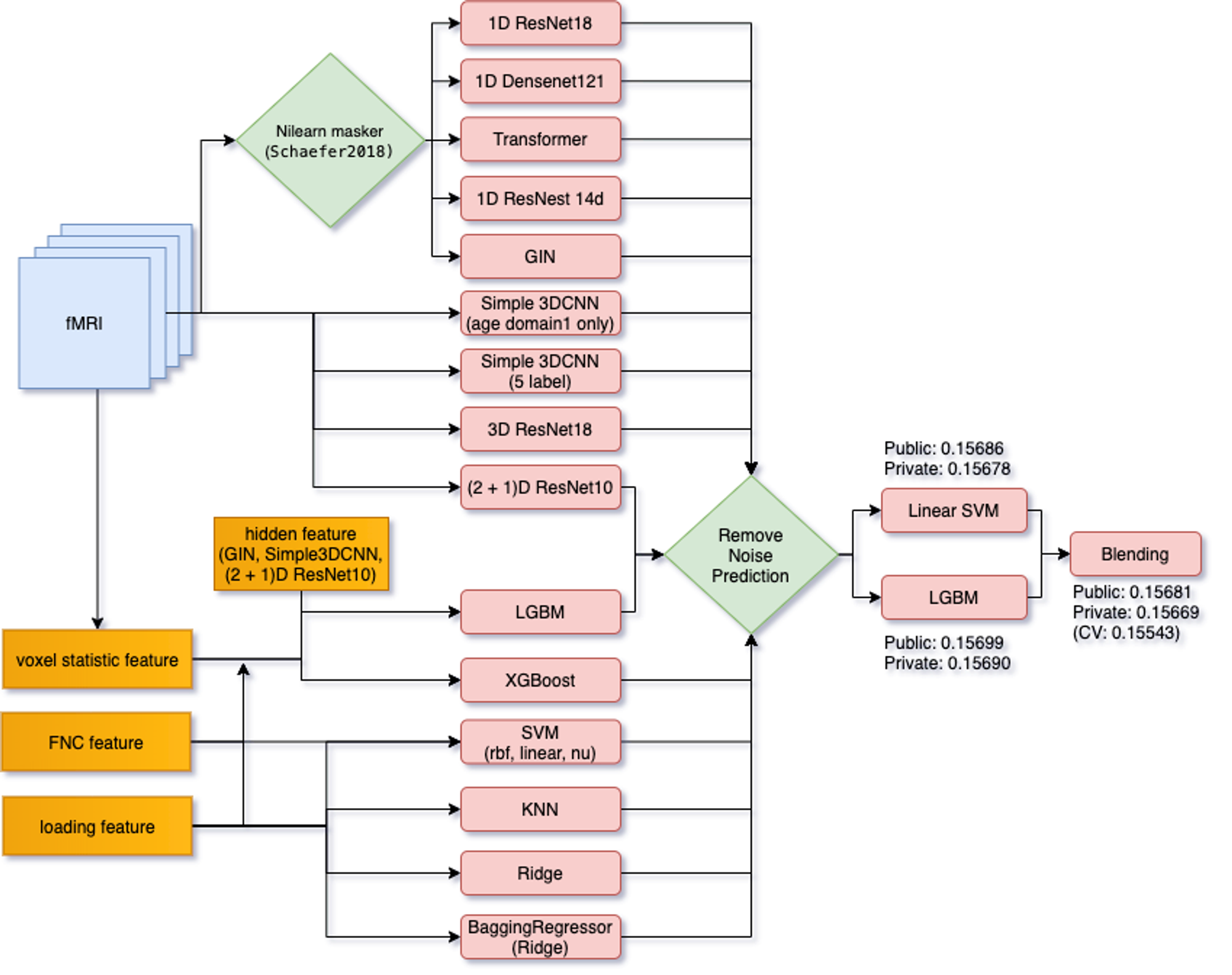
図4:Solutionの概略図
コンペ中の取り組み方
図5に私のコンペ期間中におけるスコアの推移を示しています。
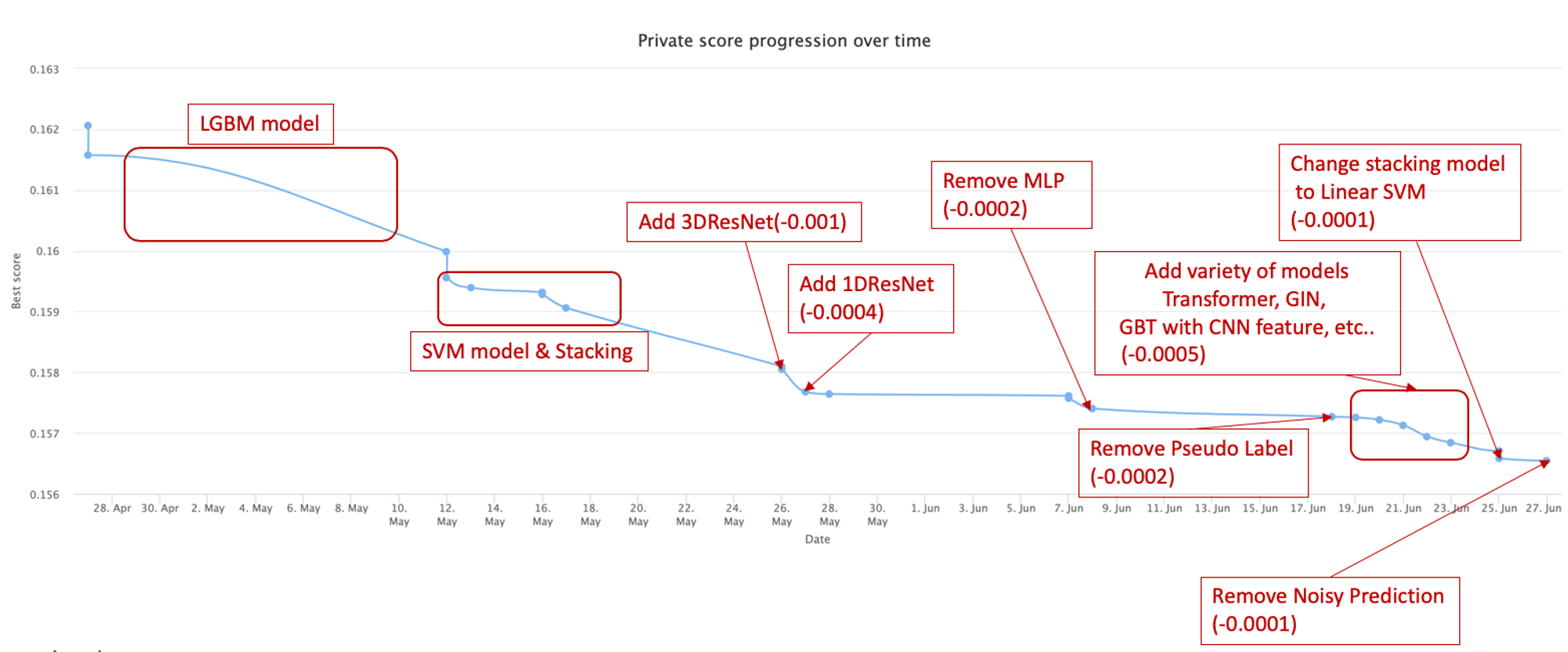
図5:コンペ中のリーダーボードの推移 (
序盤
コンペ参加初日の私の思考は次の様な感じでした。
上の思考に従い、とりあえずLightGBMモデルを作成しました。今回のデータの場合、「データ数が少ない」ということと「過学習しやすい」という問題があり、性質的に過学習しやすいLightGBMだと手元のCVのスコアは下がるが、Publicは悪化するという現象が発生していました。次に、Pseudo Labelingを試しましたが、特にPublicは改善しませんでした。更に、上で説明したようなSite 2の問題があったので、LightGBMでAdversarial Validationを行ったところ、IC_20という特徴量が図6に示すように訓練データとテストデータで大きく分布が異なることが分かりました。この特徴量が、特徴量重要度として上位に来てしまうと、訓練データとテストデータで異なる振る舞いをしてしまうことから、平均値の差分だけ訓練データにおけるIC_20の値をShiftさせるという戦略を取りました。これをすることで、CVとPublicの値が追従する様になったので必要な操作だった様です。他には、IC_20を特徴量から削除するという戦略も試しましたが、大きな違いはありませんでした。
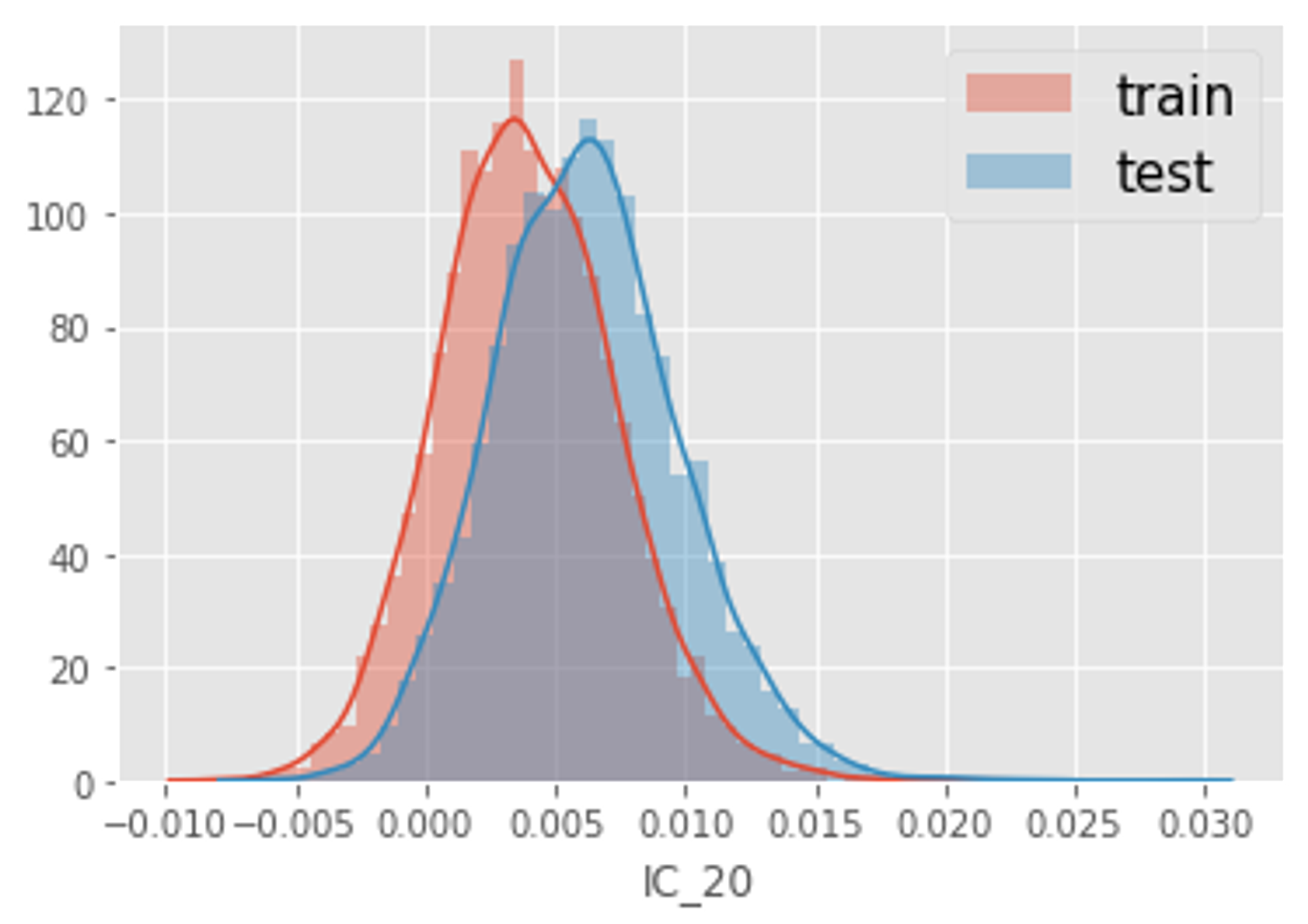
図6:
その後、テーブル特徴量に対してrbfカーネルのSupport Vector Machine (SVM)を用いて高スコアを出しているNotebookが公開され、Simpleなモデルが効果的ということが分かりました。データ数が少ないということとSimpleなモデルが有効という点から、細かい精度が勝負の肝になってきそうだなと思い、この辺りでStackingの使用を検討しました。このタイミングでSimpleなモデルであるSVMやRidgeなどとMLPやLightGBMを用いてStackingを行ったところ、この時点でのTop10くらいに入ったと思います。
中盤
序盤はテーブル特徴量だけしか使っていなかったのですが、それだけだと使える情報量にどうしても限りがあるので、fMRIデータの使い方を考え始めます。まず単純に考えられるのが、3D CNNの利用です。しかし、3D CNNは2D CNNよりもパラメータが多い分、データ数が多く必要になるという動画認識分野での知見[3]があったため、最初は厳しいのではないかと思っていました。そうは思いつつも、とりあえず最初にResNet-18のModuleを3Dに置き換えたモデルとテーブル特徴量を用いた図7の様なモデルを作成しました。このモデルをStackingに加えることで若干改善はしましたが、劇的な改善とまではいきませんでした。
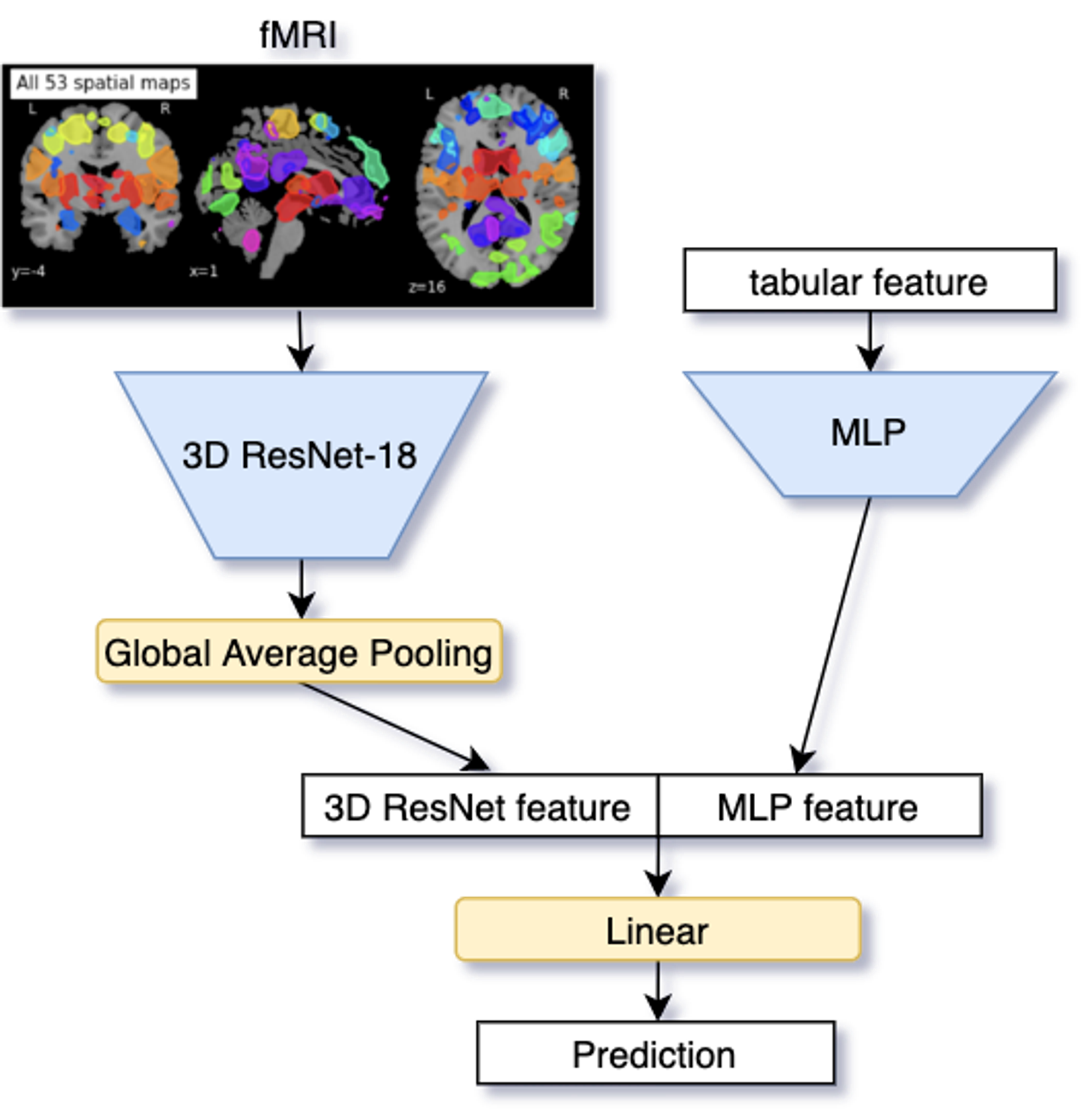
図7:fMRIデータとテーブル特徴量を組み合わせたモデル
そこで、図7のモデルでは、テーブル特徴量を用いることで、fMRIの情報を実際のところあまり使えていないのではいかという仮説に基づき、fMRIのデータのみを用いた3D ResNetを作成しました。その予測結果をStackingに組み込んだところPublicが劇的に改善し、当時の2位くらいに躍り出たと思います。これは、テーブル特徴量を用いない方が純粋にfMRIのみから予測をするため、テーブル特徴量だけでは捉えきれない情報をStackingに加えることができたからだと考えられます。
ここで、更にNilearnというライブラリのMaskerと呼ばれるものを用いることで、fMRIデータの中でも重要な部分のみを抜き出し、それに対してモデル作成を行いました。これは、[4]の論文でも用いられており、53x48x56x45の4次元データを図8のような2次元の53x400までサイズを減らすことができます。空間的な情報は失われてしまいますが、サイズが小さくなったことにより過学習しにくくなることと、異なるデータの扱い方をしてモデルを作成することによってモデルの多様性を出すことができると考え、このMaskerを採用しました。このデータに対してもSimpleな1D ResNet18を作成し、予測値をStackingに加えたところ当時の1位になり、完全に調子に乗ります(笑)
https://twitter.com/nt_4o54/status/1265425296888459264?s=20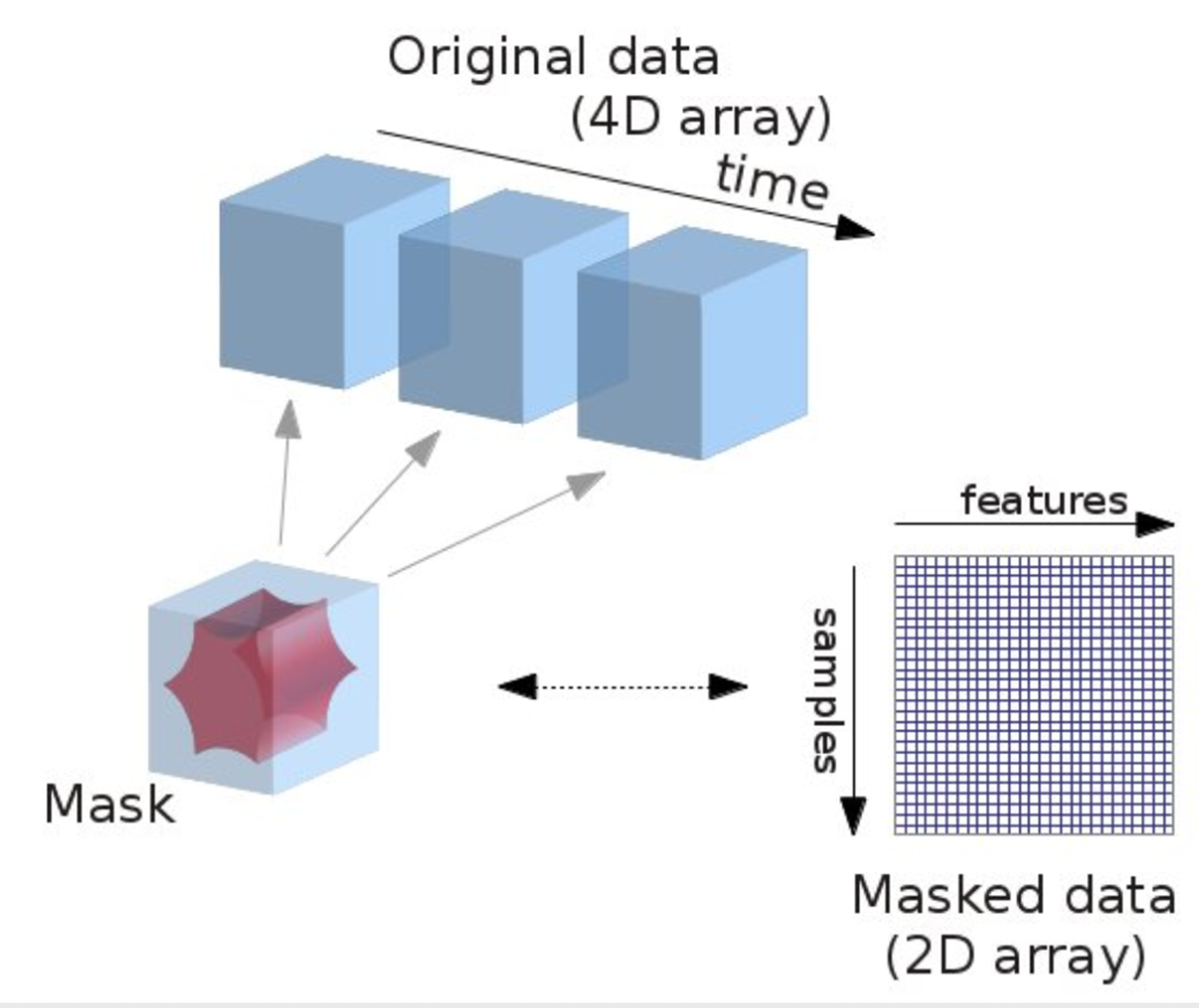
図8:Makerを用いてfMRIから重要な部分を抜き出す概念図 (
終盤
残り2weekくらいまでリーダーボードはほとんど動きがなかったのですが、終盤に差し掛かり上位が入れ替わり始めました。Stackingが有効というタスクの仕様上、終盤に熾烈な上位争いが行われることは想定できましたが、この辺りで私も焦り出しました。残り2weekの私の動き方としては、次のような考え方でした。
まず一つ目に関して、まず考えたのがResNetだけでなく違うアーキテクチャのモデルを用いてモデルを作成することです。しかし、SeNetやResNext, DenseNetなどResNetよりもパラメータが多いモデルは過学習する傾向が大きく、Stackingにも有効ではありませんでした。これが、パラメータの多さによるものではないかと当たりをつけ、よりパラメータの少ないモデルを構築しました。それが3D CNNを3層積み重ねてGlobal Average PoolingしたSimpleなモデルや、(2 + 1) D CNN [5]を用いて構築したResNet-10です。これらのモデルは3D-ResNet18より汎化性能が高く、モデルの多様性に貢献することができました。更に、age, domain1_var1, domain1_var2はある程度予測しやすく、domain2_var*は予測しにくいということがわかっていたため、予測しやすい3つのtargetのみで予測したモデルなども作成していました。
また、上述した53個の成分に分かれているfMRIの各成分同士の相関を考慮したモデルを作成するために、Maskerを適用したデータに対して、TransformerモデルとGraph Isomorphism Network (GIN)を構築しました。ここで用いたGINは、[4]の論文を参考に、図9のモデルを回帰タスクに変更し層数を3に減らしたものです。ここでは、各成分同士に単純にエッジを生やしてしまうと学習が不安定になってしまうことから、与えられたテーブル特徴量を用いてエッジを枝刈りするなどの細かい工夫も行っています。更に、Maskerをかけたものに対してDenseNetやResNestなどのアーキテクチャを用いてモデルも作成しましたが、これらがやはりパラメータが多いためか、後述するノイズ除去で大部分が削られることになりました。
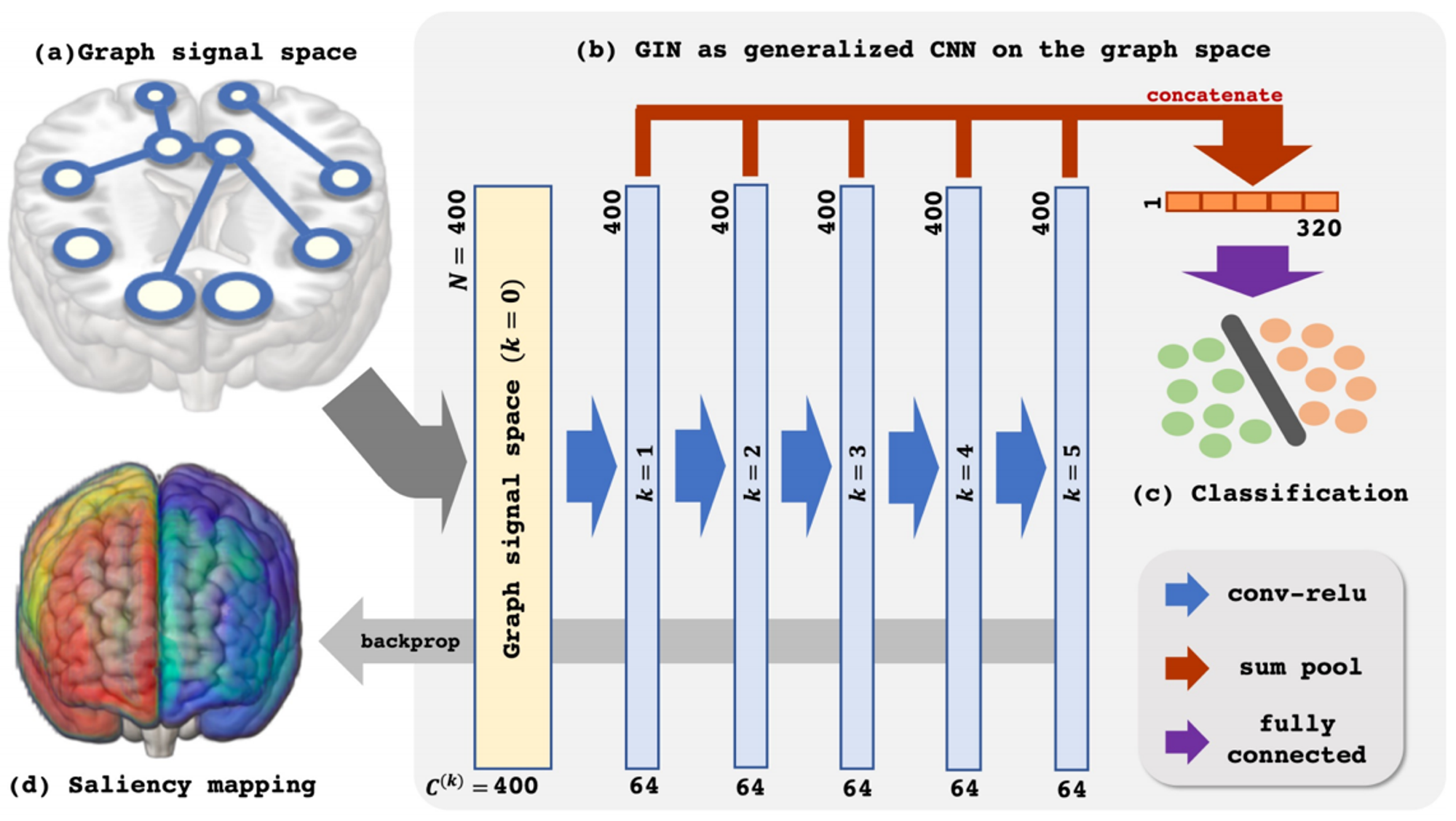
図9:[4]の論文で用いられているGINの概略図
テーブル特徴量を用いたモデルに関してもいくつかの追加を行いました。まず、特徴量としてfMRIの情報入れたかったので、fMRIの各成分に関する統計量を計算しました。それらと上述したCNNモデルの中間特徴量をLightGBMとXGBoostに入力し訓練させた後、特徴量重要度で上位1024個の特徴量を選択し、再訓練しました。この1024はいくつか試しながら、Publicを見ながら選択したものです。また、今回のデータはBoostingだと過学習しやすいため、葉の数を2にするなど細かいパラメータ調整も行いました。
次に、二つ目に関してです。今回のコンペに限っていえばPublicとPrivateが 1: 1で分割されているため、ある程度Publicが信用できると考えていました。そのため、手元のモデルとPublicを見ながら「MLPを入れると何故か悪化するな」とか「Pseudo Labeling入れるとやっぱり良くないな」など、なるべくCVとPublicが相関するようにモデルを選択していきました。その結果、徐々にではありますがPublicは改善していき、細かい作業の大切さを思い知りました。
残り3日
ここまで、Publicを信用してきた私ですが、この辺りで「本当にPublicを信用していいんだろうか」と疑心暗鬼に陥ってきます。というのもSite 2の問題があり、もしPublicよりPrivateの方がSite 2の数が多かったりすると、途端にPublicが信用できなくなるからです。ここで、Site 2がどれくらいあるかというのを一部公開されているSite 2の情報で求めようとしましたが、うまく分類器を構築することができませんでした。。(コンペ終了後のDiscussionでは上手く分類器を作れている人はいたので、ここは深掘りが足らない部分でした)そこで、公開されているSite 2の部分の予測を0にするとPublicのスコアが0.854くらいになると教えてくれるDiscussionがあったので、それを利用してPublicにどれだけ公開されているSite 2のデータが含まれているか確認できないか考えました。手元の訓練データに対して半分だけSamplingすることで擬似的にPublicデータを作成し、そのうち510件だけ予測をゼロにして評価指標を複数回計算したところ丁度0.85くらいになったので、公開されているSite 2は全てPublicに含まれていることが分かりました。そのため、公開されているSite 2に対して過剰に対策しすぎるとPublicにoverfitしてしまうなと思い、どちらかというとテストデータ全体に対しての対策を行おうと決めました。
そこで行った対策として、愚直にStackingに使っている各モデルの予測値が訓練データとテストデータで乖離していないかを一件一件確認し、乖離しているものは一つずつ取り除いていくというものです。例えば、図10のように一部のモデルでは訓練データとテストデータで予測値の分布が大きく異なっていることが分かると思います。このようなものでStackingしてしまうと、訓練データでの予測とテストデータでの予測で異なる挙動を示してしまうことがあるので、赤枠で囲っているような予測値は取り除きました。この結果Publicのスコアとしては下がってしまうのですが、Privateではスコアが向上していたので、Publicに過学習していないStableなモデルになったのではないかと思います。
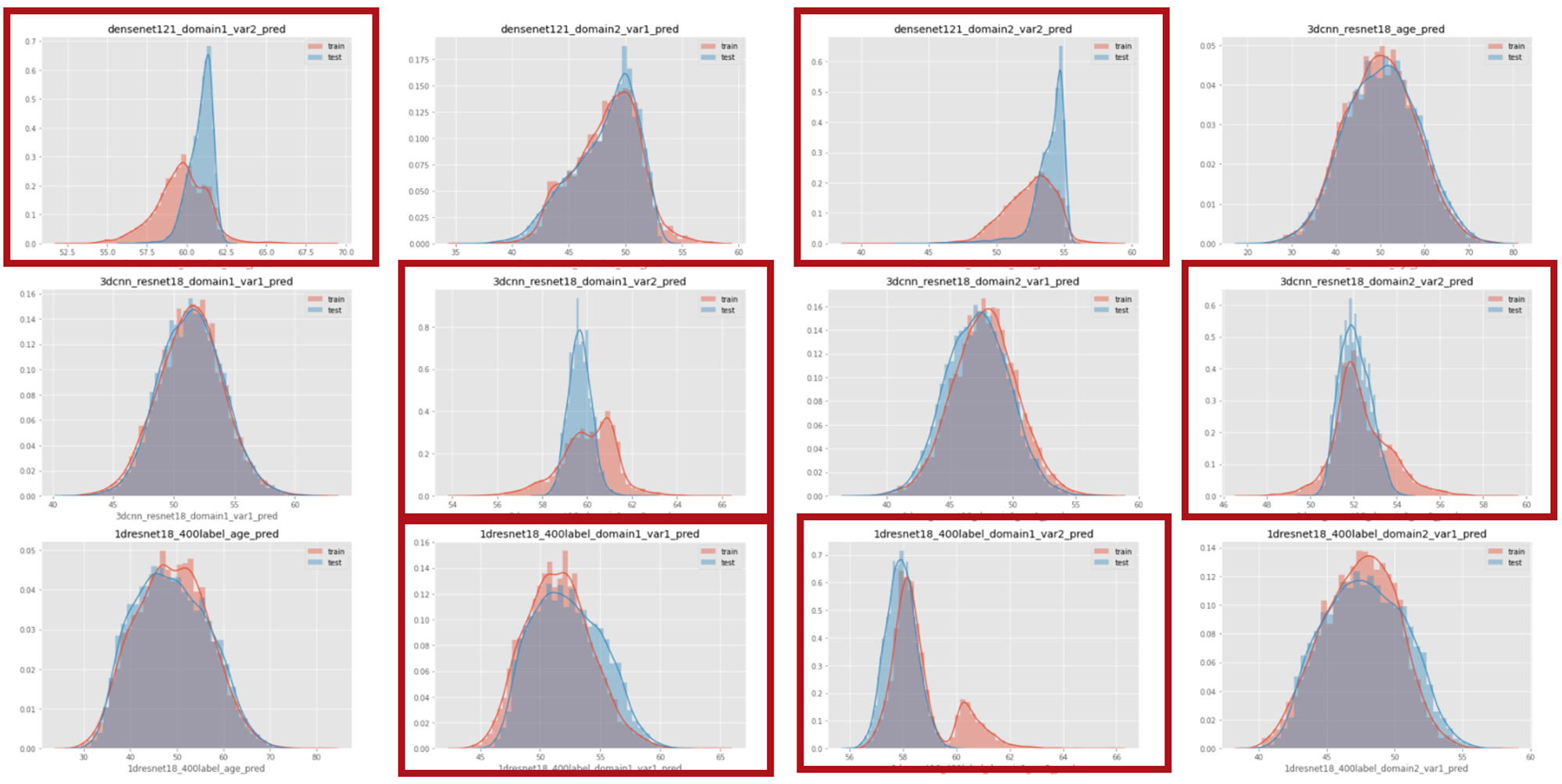
図10:TrainとTestで予測値の分布が大きく解離してしまっている例
上記の対策を行った後は、LightGBMで行っていたStackingをLinear-SVMに変えたり、それらをBlendingしたりと細かい調整を行っていました。細かい話で言うと、以下のようなことも行いました。
他にもRidge Stackingや2nd level Stackingも試しましたが、それらは有効ではありませんでした。
最終的には、Publicで一番良かったものと上記のノイズ対策をしたものの二つを提出したところ、ノイズ対策をしたものが3位のSubmissionとなりました!対策をしていなかったものだと、Privateで5位のスコアだったので上記の対策のおかげで賞金圏に入れたのだと思います。
今回のコンペのポイント
ここでは、他の上位者の解法を元に、私の思う今回のコンペのポイントについて二点述べようと思います。
まず一つ目は、「どのようにしてfMRIデータから特徴を抽出するか」です。今回のコンペでは、テーブル特徴のみでは上位に入ることは難しく、いかに高次元のfMRIデータを扱うというのが肝だったと思います。図11に示したように、上位陣の手法としては、私のようにNeural Networkを用いてStackingをしている手法が主流で、AutoEncoderで特徴量抽出しているチームもありました。一位は、昔ながらのPCAで特徴量を抽出していて、今回のような医療データで少数しかデータが存在しない時にはまだまだ有効な手法なんだと思い知らされました。
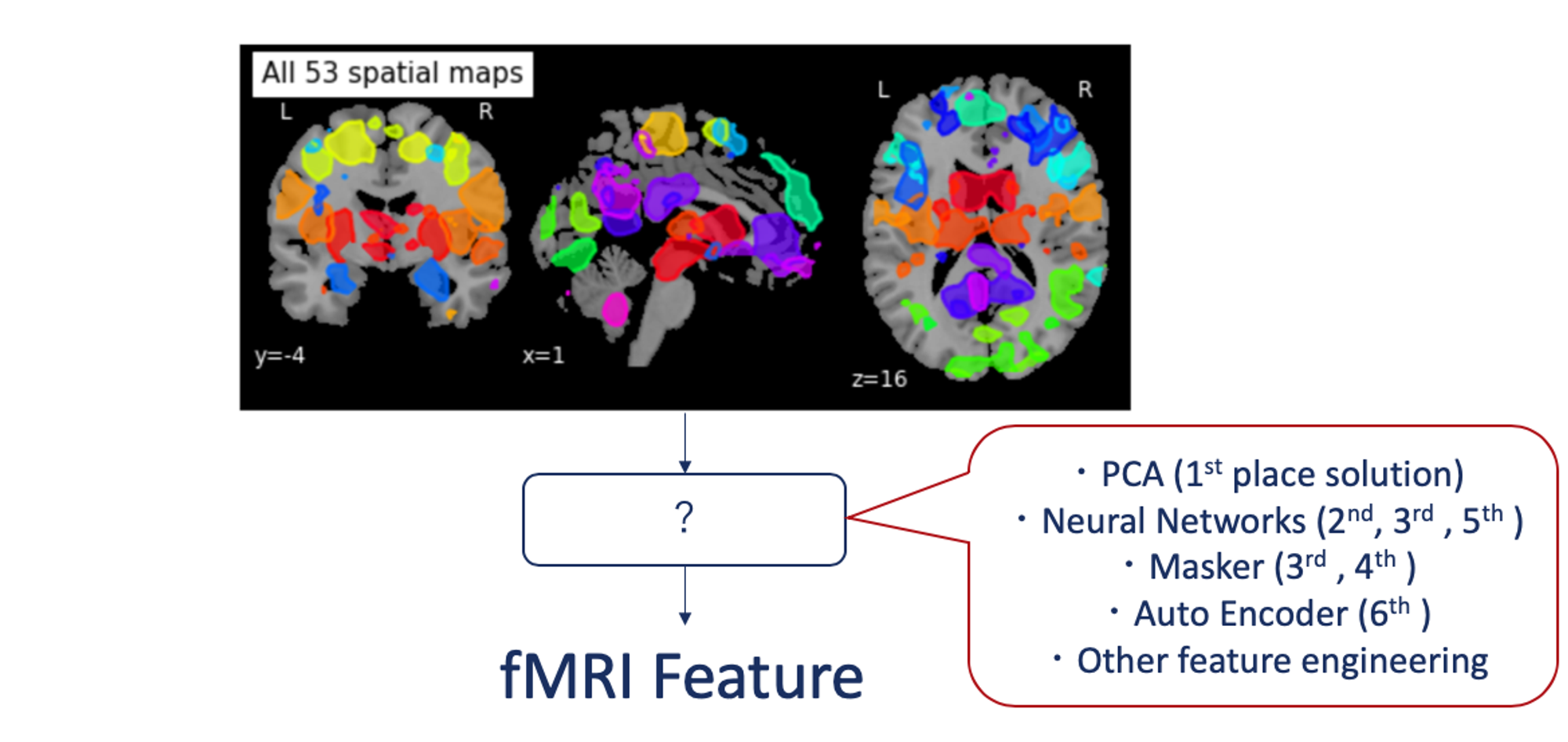
図11: 上位陣におけるfMRIからの特徴量抽出の方法
次に二つ目ですが、「どのようにして多様性を出すか」です。私の場合は、違うアーキテクチャのモデルを扱うことで、モデルの多様性を出していました。2ndの解法では、ResNetなどにinputする際のfMRIのエリアを変えることで多様性を出していたり、1stや4thの解法では、モデルに入力する特徴量のsubsetを色々変えることで多様性を出していたようです。
このように各者様々な手法で、fMRIから特徴量を抽出し、更にそれらを利用して多様性のあるモデルを多く作っていました。これらが主に勝敗を分けたポイントなのだと思います。その他Site 2の対策なども多少はやはり効いていたようですが、大きなポイントではなかったのではないかと思っています。ageの丸め対策も上位陣何もしていなさそうなので、あまり関係なかったようですね。
結局Kaggleで何が得られるのか?
ここまで、今回私が参加したコンペについて詳細を述べてきましたが、よく話題に上がる「結局これが実務においてどのような役に立つのか」ということについても少しだけ述べようと思います。
Kaggleを通して私が実感している実務への貢献は、以下のようなものです。
私自身、MaaS領域を扱っている会社のメンバーなので、実務で脳データを扱う機会などはもちろんありません。しかし、普段機械学習やデータ分析のプロジェクトを行うのに必要な自走力であったり、データに対する勘所はKaggleによって養われていることを実感しています。今回のコンペだけでもここには書き切れないくらい頭を抱えてデータと向き合っていて、例えば、「何故CVとPublicが相関しないのか」という一点だけでも、とても悩まされます。このような悩みは実務でもよく対面する問題でもあり、コンペを通してそのような経験を積み重ねることで、実務でも役立つ能力を培うことができます。また、上位に入るためには、自分で論文などから情報を取りに行ったり、自分で仮説検証のサイクルを繰り返すという作業が必須になってきます。このようなことを繰り返していると、自然と実務に必要な自走力や仮説思考が身に付きます。実際、弊社にもKaggle Masterが多数在籍していますが、全員自走力が非常に高く驚かされる毎日です。
また、今回のような多数のモデルを構築してStackingを行うようなモデルだと実用的じゃないといった話もよくあり、自分もKaggleでStackingのsolutionを見る度そう思っていました。しかし、実際に多数のモデルを構築するには、一つ一つのモデルに対しての理解が必要であり、それらをどう組み合わせるかということについても考えることがたくさんあります。確かに複数のモデルを用いたStackingを実務で用いるには、要件などとの兼ね合いもあり難しいものがありますが、一つ一つのモデルの扱いを学べる上に、それらを無駄にせず最終出力に組み込むので、非常にエコな手法なのではないかと思います(笑) 更に、色々なモデルのコード資産が蓄えられ、それらを実務で転用できるのもいい点ですね。
更に、仮説検証を正しく行うためには、自分のやりたいことを正しく実装できている必要があります。恐らく多くの人が自分のコードにバグを埋め込んでしまった経験があると思いますが、それをしてしまうと実験の結果が正しいものではなくなってしまうので、それらをなるべく減らすことが大事です。特に、今回のような多数のモデルを扱う際にはバグを埋め込みやすく、実験を上手く管理できるようにコードを書く必要がありました。私もKaggle始めたての頃は全く整理されていないコードを書いていて、実験の再現をするのも大変だったみたいなことがあり、その頃の成績は全く奮っていませんでした。なので、自分なりでもいいのでちゃんと管理できるコードを書くということはとても大切だと思います。もちろん、これも実務で非常に重要な能力です。
このように色々と書き連ねましたが、Kaggleをすることによって上記のような能力が得られているという実感が私自身あります。もちろん、実務に必要な能力は上に挙げたものだけではないので、このようなことがKaggleができる人には(ある程度)担保されているよということを分かっていただければと思います。
まとめ
今回のコンペでは、Stackingの有効性に序盤で気づけたことによって、モデルの多様性を出すことに注力する時間を多く取れたのが勝因でした。今回のコンペだけでも、実務に活かせる能力を身につけれたという実感があるので、引き続きKaggleに積極的に参加していこうと思っています。今回念願のソロゴールドを獲得することができたので、MoT初のGrand Masterになることを目指して精進していきます!
最後になりましたが、Mobility Technologies では Data Scientist / Data Analyst を募集しています。大規模多様なデータを扱い、プロダクトに大きなインパクトを与えられるだけでなく、確かな技術力を持ったメンバーとともに切磋琢磨できるポジションなので、ご興味のある方は是非ご応募を検討していただけると幸いです!
採用ページはこちら >>> https://hrmos.co/pages/mo-t/jobs
注釈
[1] 株式会社ディー・エヌ・エーよりMoTに出向中
[2] コンペ終了後にこの評価値は、行動や生活様式に関連する複数の評価値を正規分布に変換した後に、それぞれのドメインで線形に重み付けした値だと明かされました
[3] Carreira et. al, “Quo vadis, action recognition? a new model and the kinetics dataset”, CVPR 2017.
[4] Kim, B.H. et. al, “Understanding Graph Isomorphism Network for rs-fMRI Functional Connectivity Analysis”, Front. Neurosci. 2020.
[5] Tran et al, “A closer look at spatiotemporal convolutions for action recognition”, CVPR 2018.