

Kaggleコンペ「RSNA STR Pulmonary Embolism Detection」で9位を獲得しました
KaggleAIDeep LearningNewsはじめに
2020 年 10 月に終了した Kaggle のコンペ 「RSNA STR Pulmonary Embolism Detection」で MoT のメンバー 佐藤*、島越*で構成されるチームで、784 チーム中9位となり、金メダルを獲得しました! 本記事では、このコンペの概要と我々のソリューションを紹介したいと思います。なお、本記事は佐藤、島越の共著となります。また使用したコードはgithub 上でも公開しているのでぜひご覧ください。
コンペ概要
タスク概要
今回参加したコンペティション「RSNA STR Pulmonary Embolism Detection」はRSNA(北米放射線学会)が開催したコンペティションです。これまでにもRSNAは2回コンペティションを開催してきたのですが、今回は胸部CT画像から肺塞栓症(Pulmonary Embolism、PE)という病気を予測するコンペティションでした。
肺塞栓症は肺の血栓にができて血管が閉塞する病気です。生命を脅かす可能性のある病気であり、全米では年間6万人から10万人の方が肺塞栓症により亡くなっています。肺塞栓症の診断は造影剤を用いたCT肺血管造影検査が一般的です。医師は得られた数百枚の連なったCT画像から診断を行います。肺塞栓症の確認は時間がかかるため、機械学習による高速で正確な予測ができることで、患者にとって適切かつ迅速な診療ができるようになる可能性があります。
このコンペティションでは約900GB もの胸部CT画像データが提供され、参加者はこのデータから肺塞栓症という病気を発症しているか、またそれが急性なのかどうかなどの症状を予測することが求められます。
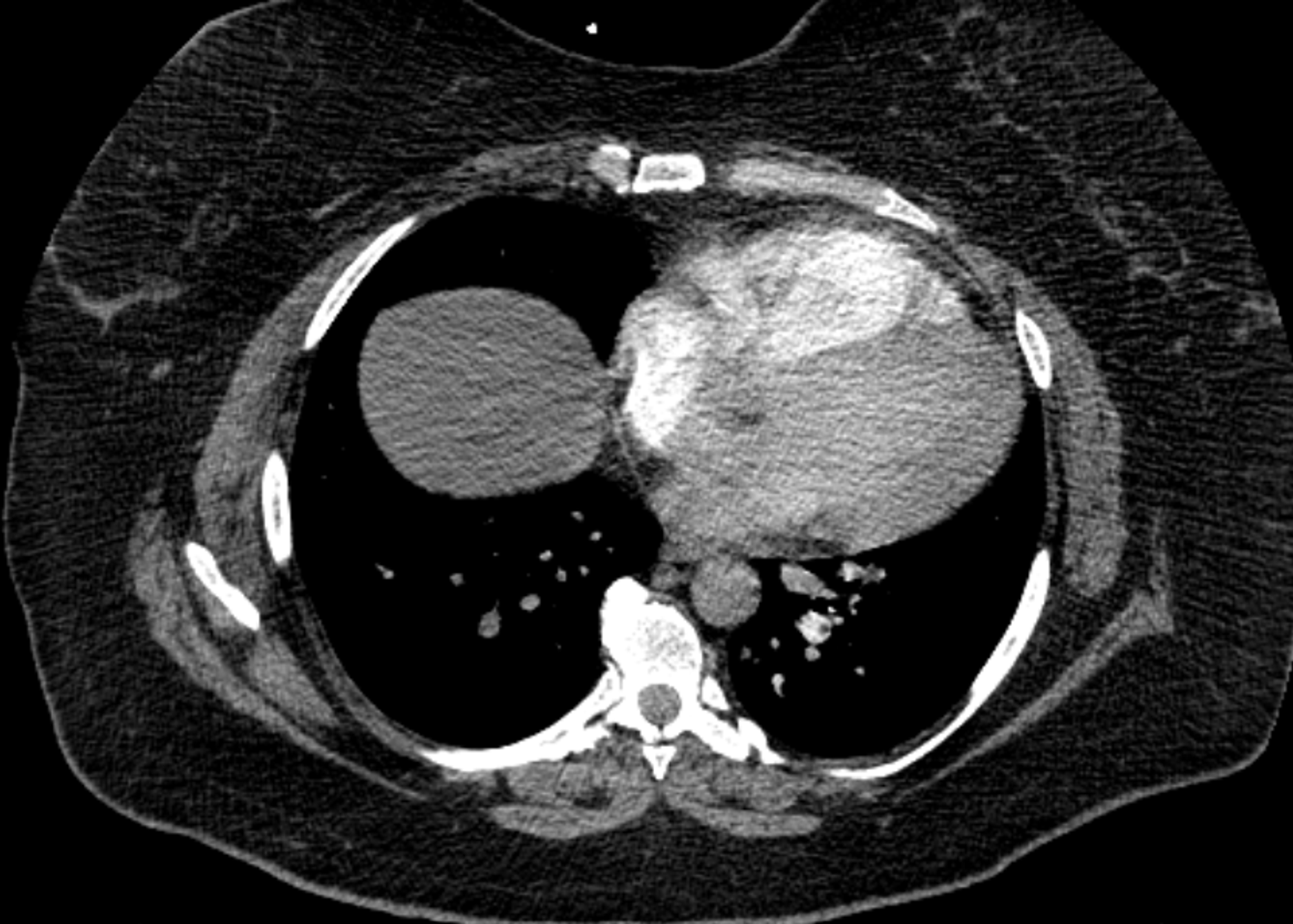
図1:胸部CT画像の一例(
評価指標
今回の教師データは、画像毎にそれぞれ肺塞栓症であるかどうかのimage-level のラベルと患者ごとに肺塞栓症の症状などを記述した9種類のexam-level のラベルに大きく分けられます。基本的にはimage-level とexam-level のweighted log-loss なのですが、これらのラベルには下図のような論理的な階層構造がありその論理関係を満たさなければならないという制約がありました。例えばimage-level で少なくとも1 つの画像で肺塞栓症が検出された場合はexam-level でRV/LV Ratio ≥ 1 とRV/LV Ratio < 1 が両方とも0.5 を超えてしまうような予測は許容されません。(RV/LV Ratio は心臓の右心房・左心房の比を表し、どちらかしか一方が大きい以外はありえないため)
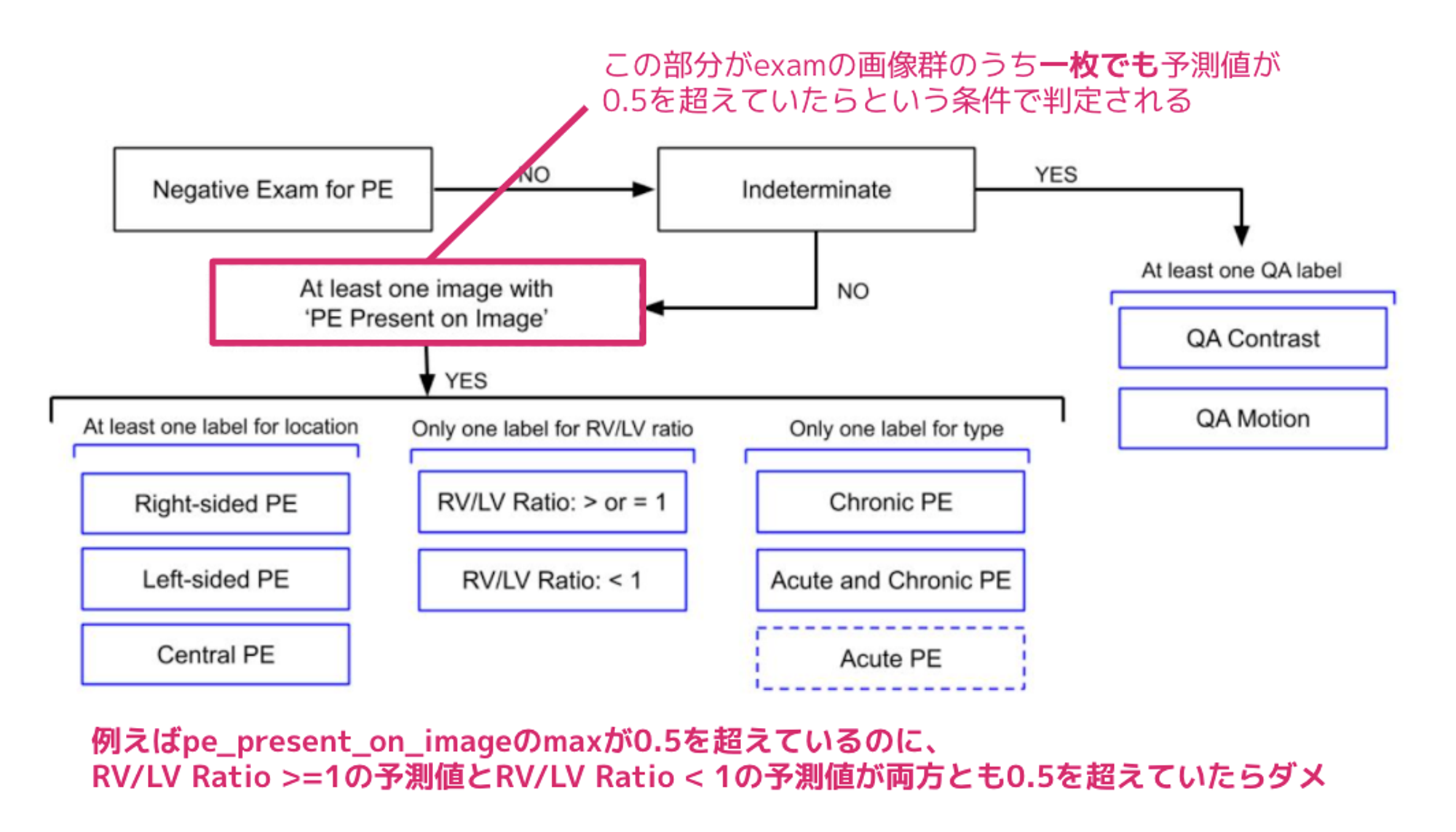
図2:ラベルの階層構造(
本コンペの特徴
Kaggle のデータは以下の3つに分類されます。
- Train:正解が公開されており学習に用いるデータ(7279 exam)
- Public:正解は非公開だがデータだけは公開されており開催期間中にKaggle のページで精度だけが確認できるテストデータ(650 exam)
- Private:データも非公開であり最終的な順位はこのテストデータの精度で決定される(1517 exam)
このコンペティションはCode Competition と呼ばれるもので、参加者は予測を提出する際にKaggle Notebook 上で推論する必要があります。推論時間はGPU1枚の環境で9時間以内と制限されておりこの時間制限の厳しさもこのコンペティションの特徴でした。私達は推論時間を短縮するためにprivate だけを推論することにしました。これにより推論時間が約25% 削減することができました。
私達の解法(9th place)
下図が私達の解法の概要図です。image-level の学習を行うStage 1 と、Stage 1 で得られた特徴量を系列データとして扱うStage 2 に大きく分けられます。
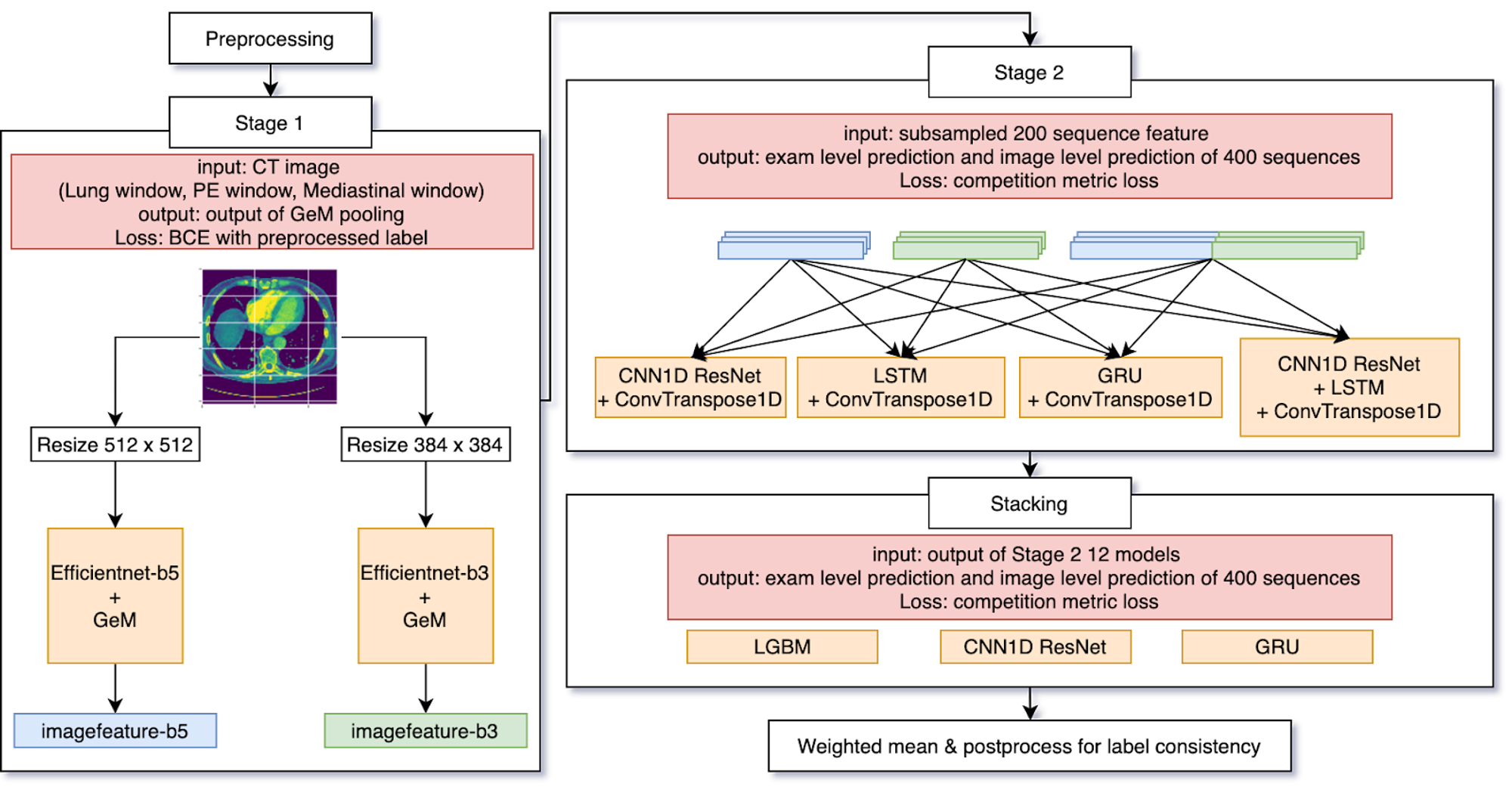
図3:解法の概要図
Stage 1
入力画像
胸部CT画像を学習するために、CTデータをまず画像データに変換します。CTデータは-1000から3000の値をそれぞれピクセルに持ちます。放射線科医は可視化する際にwindowing と呼ばれる処理を行うのが一般的です。異なる種類の組織を見るために適切なwindowing をするのですが、その時のパラメータとしてwidth とlevel があり、以下の式でwindow が計算されます。
def window(img, WL=50, WW=350):
upper, lower = WL + WW // 2, WL - WW // 2
X = np.clip(img.copy(), lower, upper)
X = X - np.min(X)
X = X / np.max(X)
X = (X * 255.0).astype('uint8')
return Xwidth とlevel には以下の3種類を用いて3-channel な画像データに変換しました。
- LUNG : level=-600, width=1500
- PE : level=100, width=700
- MEDIASTINAL : level=40, width=400
多くの参加者はこの形式の画像を用いたようです。こうした情報は全てこちらのDiscussion から得ました。このDiscussion は2018年のRSNAコンペティションの優勝者であり研修医でもあるlan pan さんが書いてくださっています。こうした取っ掛かりやすさをコミュニティで共有しあっているのもKaggle の良さだと思います。
前処理
今回のような画像枚数が多いコンペの場合だと一回の実験に時間がかかってしまうので、手戻りが発生しないようにデータをまず丁寧に眺めました。その過程で、図4のように訓練データの中にはCT画像の位置が371番目以降にpositiveラベルがついていないことが分かりました。これは、ある程度の枚数以降になると肺が写りこんでいないものだと推察されます。そこで、私達のチームでは371に少しバッファを設けて400番目以降の画像は訓練に用いないこととしました。また、推論の際も400番目以降はモデルを通さず、negativeと予測することで推論時間を減少させることができました。
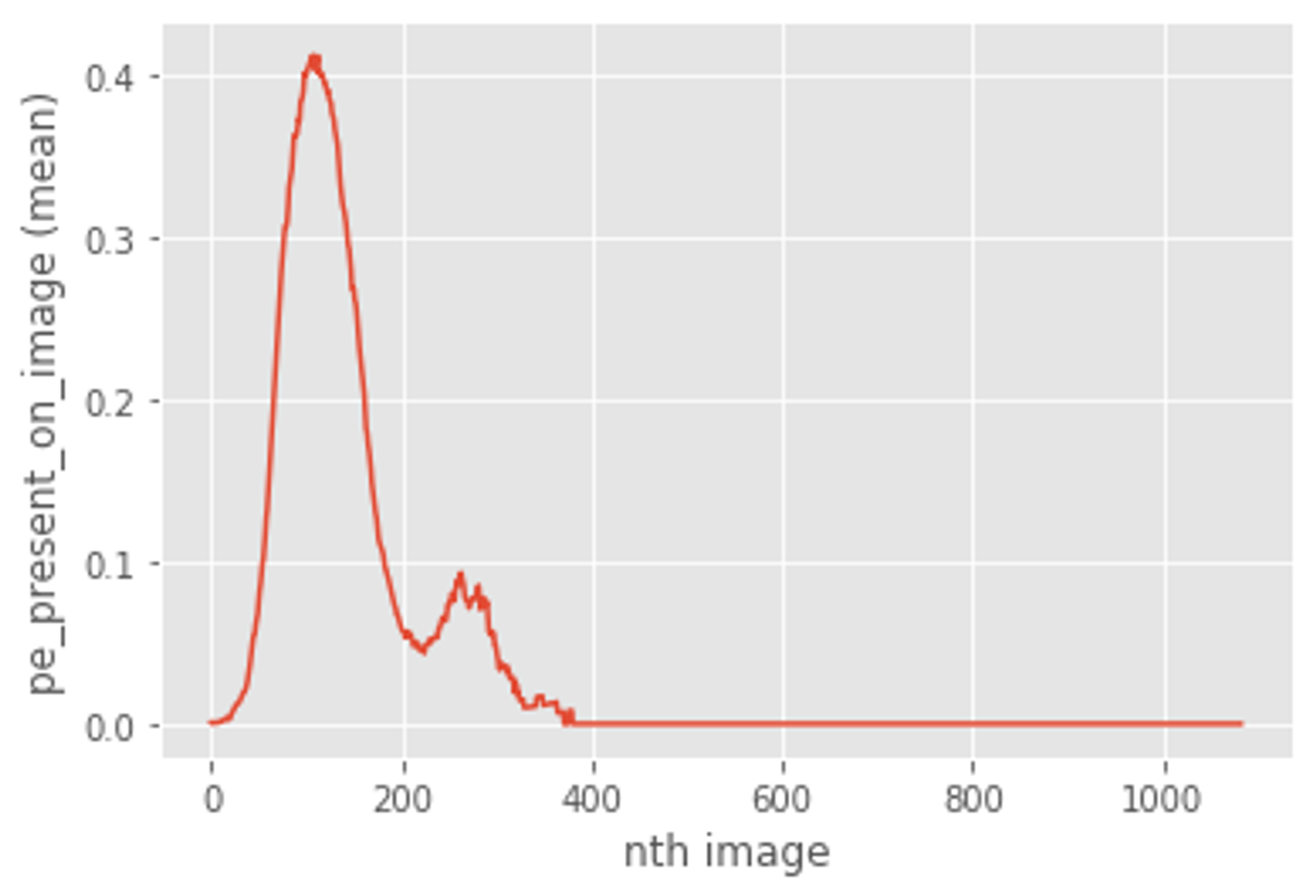
図4:訓練データにおけるCT画像の位置とpositiveラベルの関係
また、Stage 1のような画像単位で学習する際にexam-levelのラベルの付け方を図5のように変更しました。exam-levelのラベルは、negative_exam_for_pe という肺塞栓症でないと診断されたラベル以外は、positiveな画像が一枚でもあった時に付与されるラベルでした。そのため、画像単位でnegativeになっている場所はexam-levelにおいてもnegativeとしました。
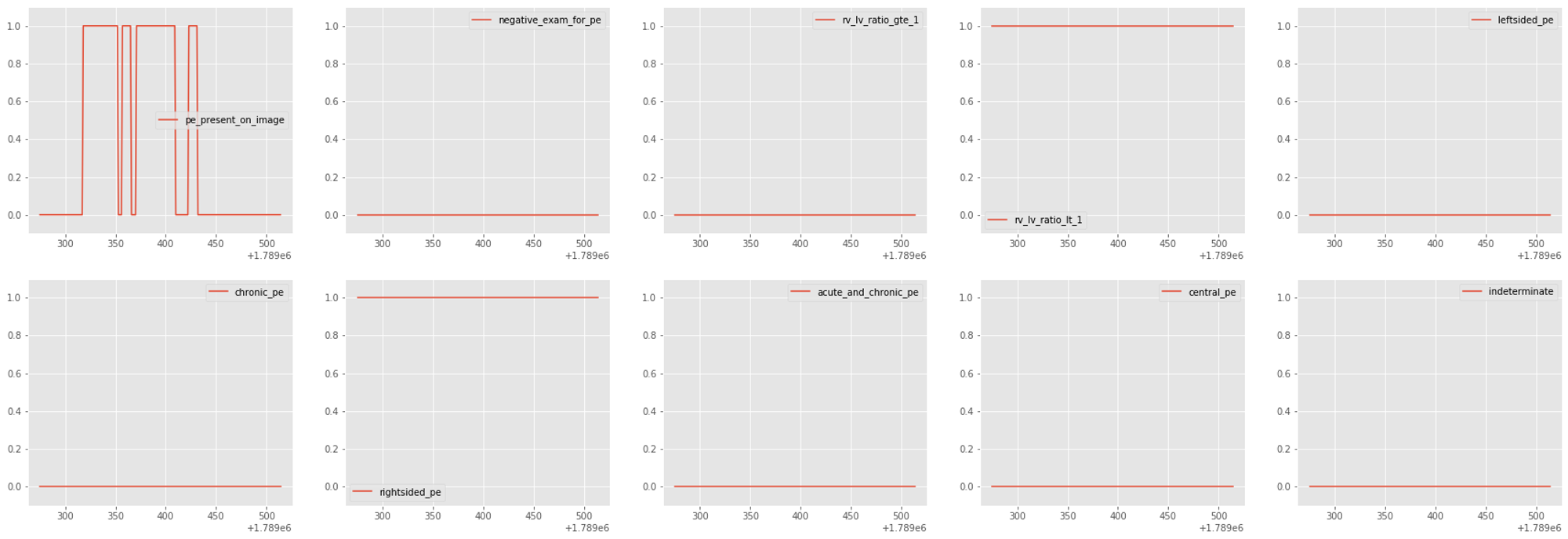
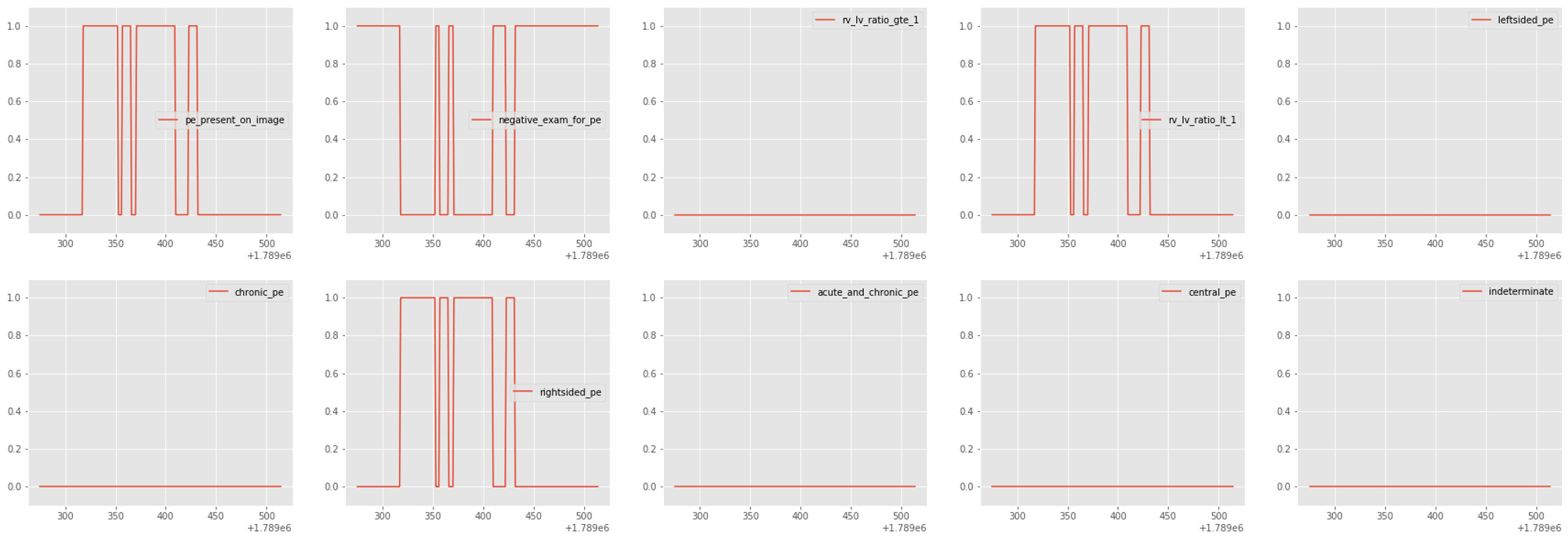
図5:ラベルの変更例
モデル
入力画像のサイズを256, 384, 512 と試した結果、大きい画像にするほど顕著に精度が上がることがわかりました。しかし推論時間の制約のため大きな画像サイズを扱うのには限界があります。そこである程度の多様性も確保するために、今回は以下の2つのモデルを作ることにしました。この二つのモデルに対して上記で加工したラベルを用いてbinary cross entropyで学習させたのがStage 1のモデルとなります。
- image size = 512, backbone = EfficientNet-b5
- image size = 384, backbone = EfficientNet-b3
Stage 2
入力データ
Stage 1 で得られた学習済みモデルを用いて学習データからPooling 層の特徴量を抽出します。CT画像は人体の上から下に連なって撮影されその断面を画像として抜き出しているため、系列データとして考えることができます。そこで図6のように得られた特徴量をソートして系列データとして扱い、RNNや1D-CNNなどの系列データに用いるモデルを使用しました。
また推論時間の短縮のために、入力する画像を1つ飛ばしにすることで推論時間を半分にすることにしました。この飛ばされた入力に対してConvTranspose1D を適用し、元の長さを復元するモデルを組むことで、精度を落とさずに推論時間を半分にすることができました。
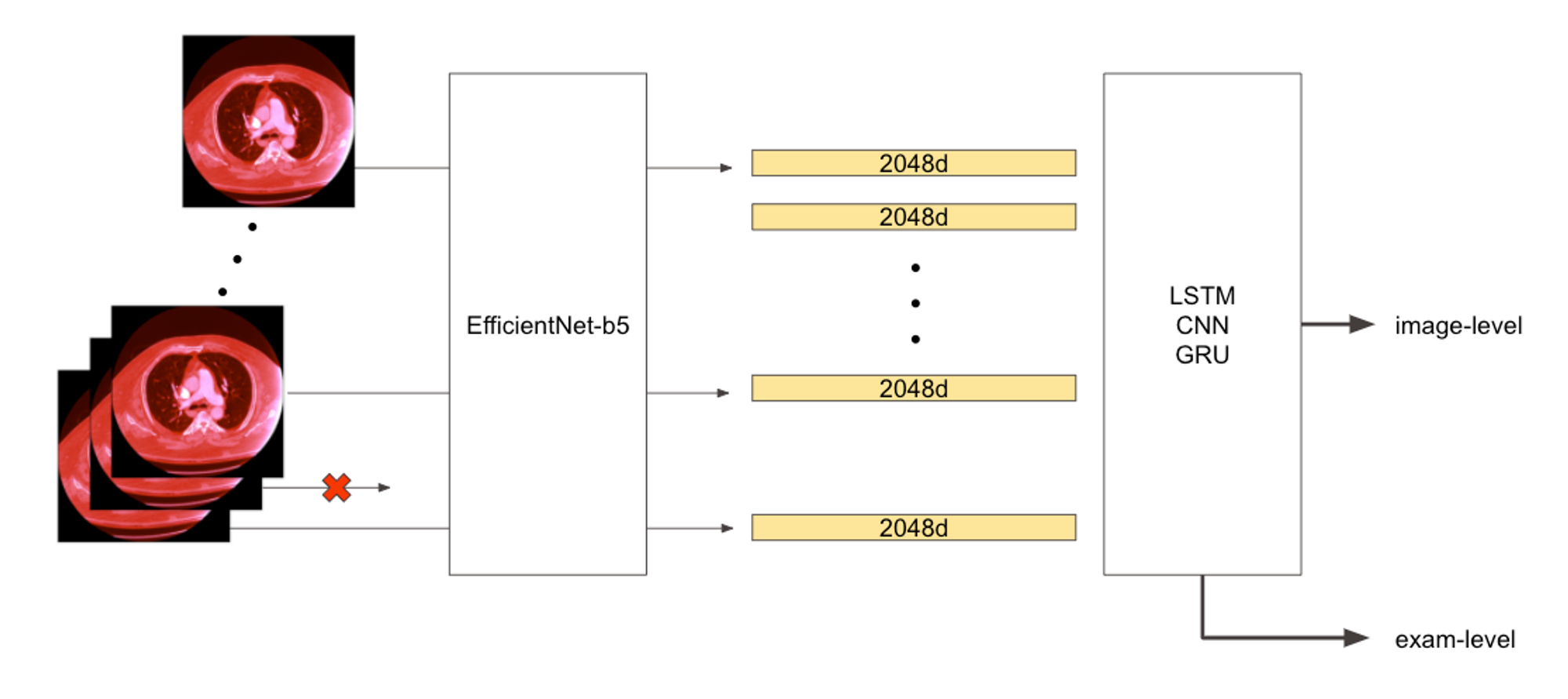
図6:Stage 2 のモデルの概要図
モデル
Kaggle において、多様性のあるモデルの予測値のアンサンブルによって精度が上がることはしばしばあります。このコンペティションでもその傾向が予想されましたが、推論時間の制約があるためモデル数を増やすのにも限界があります。Stage 1 の推論時間は特に重くこれ以上増やすことが困難なため、私達はStage 2 のモデルに多様性を出すことにしました。最終日までこの部分を増やし最終的に4種類のモデルを作り、また入力として512-b5、384-b3、更に512-b5と384-b3を結合したものの3種類を組み合わせて合計12 個のモデルを作成しました(図3右上)。また、image-levelのラベルはimage毎についているためRNNなどの出力をそのまま用いることができますが、exam-levelは系列に対して一つのラベルがついているので、中間層をGlobal Average Poolingしたものに線形層を通したものを出力として用いています。
これらのモデルを今回のコンペの評価指標をPytorchのLossとして実装したものを用いて学習させたものがStage 2のモデルとなっています。
Stacking
2nd Stageの出力を更にStackingすることで、最終的にscoreを伸ばしました。2nd stageの出力をそのまま重み付き平均することも考えられますが、12モデルの10ラベルの出力に対する最適な重みを見つけることは難しく、私の場合はコンペにもよりますがアンサンブルしたいモデルが5、6個になってきたあたりからStackingの使用を考え始めます。今回の場合は、系列データということもあったので1DCNNとGRUをStage 2と同じような形で用い、LightGBMでのStackingも行いました。少しだけ工夫をした点としては、今回だとimage-levelのLossに関してはFalse Positiveがいくらあっても影響しないものだったので、LightGBMでimage-levelのラベルを学習する際は、positiveなexamだけを訓練データとして用いました。
最後に、これら3つのモデルを重み付き平均することで最終的な予測値としました。
Postprocess
忘れてはいけないのが図2で説明した制約条件で、10位以内のチームはこの制約を満たしていなければ失格という厳しい問題がありました。単純に考えれば、RV/LV Ratio ≥ 1 とRV/LV Ratio < 1 のようなラベルの場合、片方しか0.5を超えてはいけないという制約を満たすためにSoftmaxをかけることなどが考えられますが、そのようなことをするとスコアが著しく低下してしまいました。また、image-levelの予測値が一枚でも0.5を超えてしまうとpositiveと判定されてしまうため、False Positiveが多いとスコアを下げる要因となってしまいます。
そこで、私たちは次のような手順でヒューリスティックなpostprocessを行いました。
- image-levelの予測である pe_present_on_image とexam-levelの予測であるnegative_exam_for_pe を比べて、1 - negative_exam_for_pe よりpe_present_on_image の方が大きかった場合、pe_present_on_image の値を1 - negative_exam_for_pe に置き換える。
- 制約条件を満たすまでsigmoid → logit → logit += (定数) → sigmoid の処理を繰り返す。
まず1つ目に関してですが、これは自分たちのモデルだとpe_present_on_imageの値が大きく出てしまいがちで、それによりFalse Positivesが多くなってしまっていた点へのアプローチです。図7のように左側の変換前だとnegativeなexamで0.5を超えてるものが多数存在しており、これがpostprocess時にスコアを下げる要因となっていました。logitに戻してから定数を引くことで、全体的に分布を左に寄らせるといったアプローチも考えられますが、色々と試した結果上記1. のアプローチが一番うまくいきました。右が変換後の画像ですが、左側よりうまく分離できていることが分かると思います。
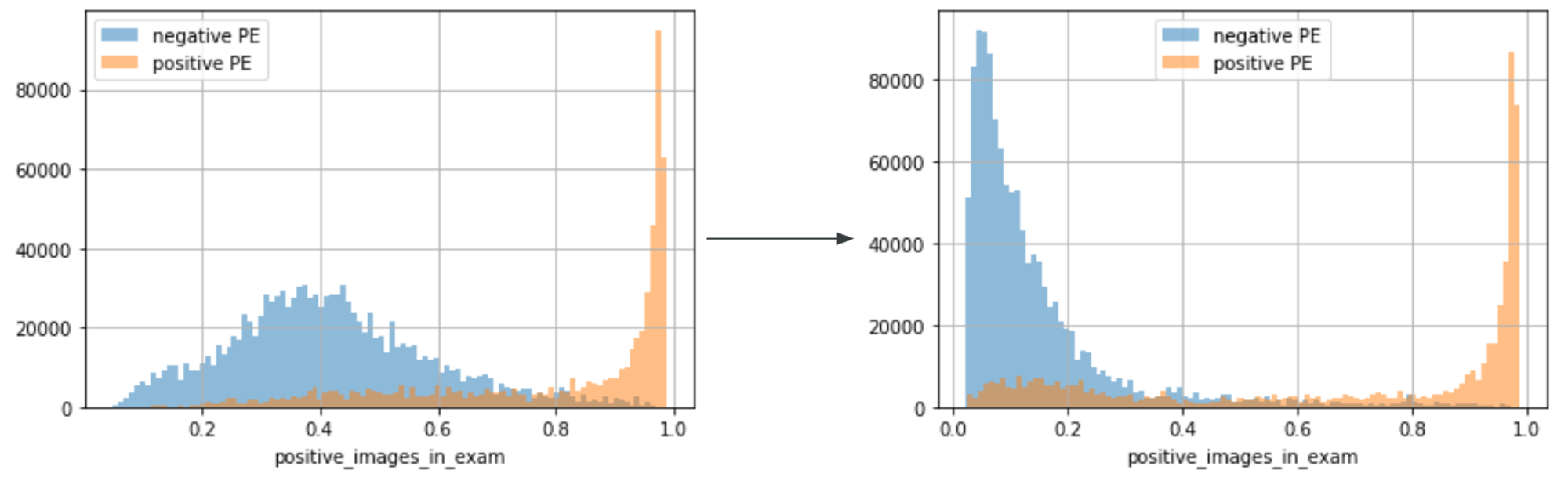
図7:
最後の2つ目に関しては、例えば、RV/LV Ratio ≥ 1 のラベルが0.7、RV/LV Ratio < 1が0.55のような予測値の場合に、より0.5に近い0.55の値を0.4999となるような値となるまで小さくするという処理です。
これらの処理によって、CVでの悪化を0.1919 -> 0.1925程度に抑える事ができ、Public、Private共に0.001程度の悪化で留めました。
今回のコンペティションのポイント
上位チームのほとんどは同じように2ステージで学習するモデルを作成し、ヒューリスティックなpostprocess でラベルの階層構造を解決していました。似た解法の中で、以下のポイントが重要であったと思います。
画像の大きさ
私達のチームでは画像の大きさを256から384、512と大きくするごとに精度が上がりました。多くのチームも512 の画像サイズにしていたようです。このことは高解像度な画像から得られる細かい要素が重要であることを示唆しています。1位のチームは画像サイズを更に640に上げることで精度が上がることを発見していました。しかし大きな画像サイズにすることでより計算時間がかかってしまうので、640サイズの画像から肺の部分だけ画像を切り出す予測モデルを作ることで解決しています(Discussion より引用)。私達のチームも画像サイズが大きい事が効くことは分かっていたので、「何故大きい画像が効くのか」という部分をもっと深掘りできていれば、肺の部分を切り出す事が重要であることに気づけていたのかなと思いました。
推論時間
推論時間の関係で、前回のRSNA コンペティションに比べて軽量なモデルを用いているチームが多かったようです。特にEfficientNetは推論も軽量なため、用いているチームが多いように感じられました。1位のチームはデータの品質が高く、また量が多いためにcross validation せずに学習していたので推論時間に余裕があったようです。今回のコンペの様な画像枚数が多くある程度CVとPublicのスコアに相関が取れる様なコンペの場合だと、5-foldせずにholdoutで高速に実験を回すチームも多い印象です。
まとめ
今回チーム参加することでStage 1 は佐藤、Stage 2 以降は島越が主に取り組むことでかなり効率よく進めることができました。また最初はEnd-to-End での学習も思案しており、最終的には使わなかったもののそうした様々なアプローチを分担して進められるのもメリットだと思います。
最後になりましたが、Mobility Technologies では Data Scientist / Data Analyst を募集しています。大規模多様なデータを扱い、プロダクトに大きなインパクトを与えられるだけでなく、確かな技術力を持ったメンバーとともに切磋琢磨できるポジションなので、ご興味のある方は是非ご応募を検討していただけると幸いです!
採用ページはこちら >>> https://hrmos.co/pages/mo-t/jobs
*株式会社ディー・エヌ・エーよりMoTに出向中