

Aurora PostgreSQLでテーブルパーティショニングを導入した話 【実践編】
SREDecember 09, 2022
技術戦略部 SREグループの古越です。
前回の記事でパーティショニングを導入する段階で注意するポイントについて主に触れてきました。今回は導入するために具体的に行った事や追加で導入する拡張機能の解説などを踏まえて紹介していきます。
前提知識と導入するまでの背景については前回の検討編を見て頂ければと思います。
Aurora PostgreSQLでテーブルパーティショニングを導入した話 【検討編】
実践したこと
前回のブログでも軽く触れましたが、導入する前には以下を重点的に検証し、実践しました。
- パーティション管理の自動化のため pg_partmanを導入する
- local開発環境でpg_partmanを利用可能にする
- Aurora PostgreSQLパラメーターのチューニング
- パーティションの一部をS3にエクスポートする
このあたりを具体的に解説していければと思います。
1. pg_partman の導入
前回の記事でも軽く触れましたが、時系列のRANGEパーティションを設定する場合は、時間経過とともにパーティションの追加削除といったメンテナンス作業を継続的に行う必要があります。
MoTの場合はDDL管理ツールとしてflywayを使っているケースが多いためflywayを例にして挙げます。flywayはDDLの変更をバージョン管理している都合上、過去のDDLを簡単に削除出来ません。
仮にflyway経由でパーティション追加/削除を行うとすると
- 開始時点からのDDLを保持
- パーティションを増減する場合、以下のようなDDLを追記
DROP TABLE payment_transactions_p2022_08;
CREATE TABLE payment_transactions_p2023_04 PARTITION OF payment_transactions
FOR VALUES FROM ('2023-04-01'::timestamp) TO ('2023-05-01'::timestamp);という運用になります。時間経過でDDLの記述が膨れ上がるため、DDLを調べ難くなる悪影響も考えられます。
定期的な実行方法にも課題が有り、パーティションテーブル毎に追加/削除する必要があるので、テーブル数が増えたり、特定テーブルでパーティションの分け方が異なるなどのケースが混ざると徐々に運用が厳しくなってくる事が予想出来ます。
そういった運用の省力化や自動化の助けになる拡張機能としてpg_partmanが有ります。
pg_partmanとは
パーティション管理を簡単にし、運用を自動化するための関数セットとパーティション管理用テーブルを提供するPostgreSQLの拡張機能です。Aurora PostgreSQLでも導入可能になっています。
Auroraでの利用方法については公式ドキュメントにも記載があるため、こちらを参考にすると良いと思います。 https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/PostgreSQL_Partitions.html
Auroraの場合、pg_partmanの導入は簡単で以下クエリだけで導入可能です。
CREATE EXTENSION pg_partman;dockerなどのコンテナで構成する場合はgithubからソースを取得し導入するなどの手が必要ですので後ほど説明します。有効化すると関数セットと設定用テーブル part_config などが配置されます。
partmanを使ってパーティションを作成する場合は以下のように書くことが出来ます。
/* Create Parent Table */
CREATE TABLE example.payment_transactions
(
id bigint NOT NULL GENERATED ALWAYS AS IDENTITY,
uuid uuid NOT NULL,
created_at timestamp DEFAULT CURRENT_TIMESTAMP NOT NULL,
PRIMARY KEY (id, created_at),
UNIQUE (uuid, created_at)
) PARTITION BY RANGE (created_at) WITHOUT OIDS;
/* Create Partition */
SELECT create_parent(
p_parent_table => 'example.payment_transactions',
p_control => 'created_at',
p_type => 'native',
p_interval=> 'monthly'
);親テーブルの書き方はそのままで、パーティション(子テーブル)を作成する部分はpg_partmanの関数を使う形になります。
RANGEパーティションの場合 FROM, TO で具体的な時間を指定してパーティションを追加する必要があり、flywayなどの宣言的なDDL管理ツールと相性が良く有りませんでした。pg_partmanを使えばどの時期でもあるべき姿を一文で記載できるので、宣言的なDDL管理ツールと相性が良くなります。
上記のDDLの結果として以下テーブル群が作成されます。
main=# \dt
List of relations
Schema | Name | Type | Owner
---------+---------------------------------------+-------------------+----------
example | payment_transactions | partitioned table | postgres
example | payment_transactions_default | table | postgres
example | payment_transactions_p2022_08 | table | postgres
example | payment_transactions_p2022_09 | table | postgres
example | payment_transactions_p2022_10 | table | postgres
example | payment_transactions_p2022_11 | table | postgres
example | payment_transactions_p2022_12 | table | postgres
example | payment_transactions_p2023_01 | table | postgres
example | payment_transactions_p2023_02 | table | postgres
example | payment_transactions_p2023_03 | table | postgres
example | payment_transactions_p2023_04 | table | postgres
public | custom_time_partitions | table | postgres
public | part_config | table | postgres
public | part_config_sub | table | postgres
public | template_example_payment_transactions | table | postgres
(15 rows)(2022年12月に作成したときの結果)
デフォルトでは作成したタイミングの前後4カ月分が作成されます。
パーティションの開始時期や事前作成するパーティションの数については create_parent関数の引数を設定することで微調整可能です。githubに関数のリファレンスが記述されていますので、細かくはリファレンスを参照してみてください。
https://github.com/pgpartman/pg_partman/blob/master/doc/pg_partman.md#creation-functions
なお、パーティション作成時にtemplate_ から始まるテーブルがpg_partmanを導入したスキーマに作成されますが、PostgreSQL 14以後は無視してしまって支障無いかと思います。(templateテーブルはPostgreSQL 13以前のバージョンでパーティショニングする時に使われるテーブルのようです。)
pg_partmanの仕事
具体的な使い方を先に述べましたが、pg_partmanがやる主な仕事の全体像が掴みにくいと思いますので軽く説明します。良く使う部分のみ抜粋すると、イメージとしては以下の通りです。
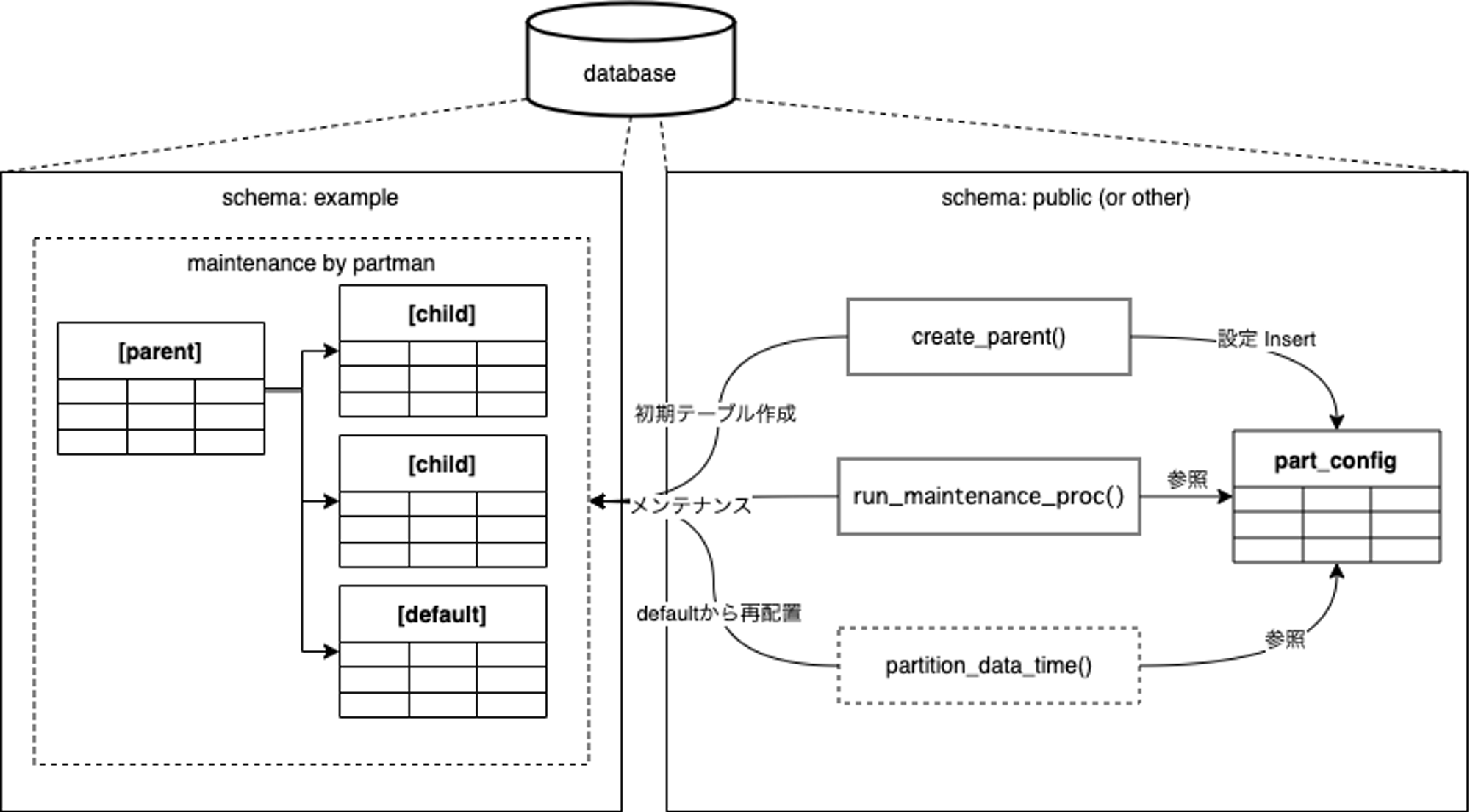
pg_partmanの仕事概要
part_config等のテーブルがpg_partmanの管理テーブルになっており、エクステンションを有効化した時に作られます。主に使う関数はpart_configに設定を格納したり、part_configの情報を参照しあるべき姿に収束させる動きをしてくれるものです。
エクステンションの導入時にpart_configテーブルを配置するスキーマを設定出来ますが、1つのDBに1つしか設定出来ないため、複数スキーマに渡ってパーティショニングを使う場合はpublicスキーマかpg_partman専用スキーマを別途作って導入する形になります。
RANGEパーティションの場合は主に3つの function/procedureを使う事になります
- create_parent() … 初期設定
- run_maintenance_proc() … 定期実行するメンテナンス用プロシージャ 冪等性有り
- partition_data_time() … defaultパーティションから別パーティションへの再配置を行う
create_parent() とpart_config管理
書き方は上述したとおりです。
実行すると親テーブルを元に複数のパーティションテーブルを作成し、同時にpart_configテーブルに管理情報が記録されます。この関数で与えたパーティション管理パラメーターを後で修正したいときはpart_configのレコードを直接編集すればOKです。
パーティションを自動削除するパラメーターもありますが、デフォルトでは無効化されています。細かくはドキュメントのpart_configの説明を参照すると良いと思います。
https://github.com/pgpartman/pg_partman/blob/master/doc/pg_partman.md#tables
run_maintenance_proc()
terraformのapplyコマンドと近い形の冪等性を持つプロシージャとして定義されています。
create_parentで初期設定を入れた後はこのプロシージャを定期的に投げるだけでpart_configに書かれた情報を元にパーティションの追加、削除を行ってくれるようになります。
実行クエリ
CALL run_maintenance_proc();パーティション化したテーブルが何個あっても、メンテナンスは上記1クエリを投げるだけで完了します。実行に時間は必要無く、特に問題なければ数秒で終わるプロシージャになっています。
Aurora PostgreSQLのドキュメントに pg_cronを使って定期的に実行するサンプルが記載されてるとおり、このクエリを定期的に実行するだけでパーティション管理を自動化する事が可能になります。
partition_data_time()
defaultパーティションに関するリカバリ作業に用いるのが主になると思います。細かくは後述します。
defaultパーティションに注意
defaultパーティションの扱いについては注意が必要という所は前回も述べていましたが、pg_partmanを扱う場合でも同様に注意が必要です。
run_maintenance_proc()を実行すると
- 新しいパーティションの作成
- 古いパーティションテーブルの移動 or 廃棄
というオペレーションがされますが、defaultパーティションに格納したレコードに一致する条件で新しいパーティションを作る場合はエラーになってしまいます。
実験として、次に作るパーティションに入るレコードをdefaultパーティションに入れた状態を作ります。
-- 検証のためパーティションを一旦削除
main=# drop table payment_transactions_p2023_04;
DROP TABLE
-- 検証のため、後で追加されるパーティションに格納される範囲のレコードを追加する
main=# INSERT INTO example.payment_transactions (uuid, created_at) SELECT gen_random_uuid(), '2023-04-01'::timestamp;
INSERT 0 1この状態で run_maintenance_procを実行すると冪等性のためp2023_04 を作成しようとしますが、defaultパーティションにp2023_04に入るべきレコードがあることで適切に処理出来ずエラーになります。
main=# CALL run_maintenance_proc();
ERROR: updated partition constraint for default partition "payment_transactions_default" would be violated by some row
CONTEXT: SQL statement "ALTER TABLE example.payment_transactions ATTACH PARTITION example.payment_transactions_p2023_04 FOR VALUES FROM ('2023-04-01 00:00:00+00') TO ('2023-05-01 00:00:00+00')"
PL/pgSQL function create_partition_time(text,timestamp with time zone[],boolean,text) line 243 at EXECUTE
PL/pgSQL function run_maintenance(text,boolean,boolean) line 273 at assignment
SQL statement "SELECT public.run_maintenance('example.payment_transactions', p_jobmon := 't')"
PL/pgSQL function run_maintenance_proc(integer,boolean,boolean) line 42 at EXECUTE
DETAIL:
HINT:
CONTEXT: PL/pgSQL function create_partition_time(text,timestamp with time zone[],boolean,text) line 486 at RAISE
PL/pgSQL function run_maintenance(text,boolean,boolean) line 273 at assignment
SQL statement "SELECT public.run_maintenance('example.payment_transactions', p_jobmon := 't')"
PL/pgSQL function run_maintenance_proc(integer,boolean,boolean) line 42 at EXECUTE
DETAIL:
HINT:
CONTEXT: PL/pgSQL function run_maintenance(text,boolean,boolean) line 402 at RAISE
SQL statement "SELECT public.run_maintenance('example.payment_transactions', p_jobmon := 't')"
PL/pgSQL function run_maintenance_proc(integer,boolean,boolean) line 42 at EXECUTEこのエラーはpartition_data_timeを実行することでリカバリすることが可能です。
main=# SELECT partition_data_time(p_parent_table=>'example.payment_transactions');
partition_data_time
---------------------
1
(1 row)これを実行するとdefaultパーティションに入っている問題のレコードを一時的に別のテーブルに移動し、パーティションを作成して再配置するというオペレーションを行ってくれます。
しかし対象のレコード数が多い場合には長時間のLockが獲得されることになるため、注意して行う必要が有ります。
pg_partmanには管理用に check_default()という関数も用意されており、defaultパーティションに格納されたパーティションとレコード数を洗い出す事が出来ます。
main=# SELECT check_default();
check_default
------------------------------------------
(example.payment_transactions_default,1)
(1 row)放置されてdefaultパーティションしか使っていない状態になると、後々リスキーな再配置作業が必要になるので、defaultパーティションのレコード数には注意してください。
run_maintenance_procの実行とモニタリング方法
検証始めた当初はpg_cronを使って run_maintenance_procを実行する想定だったのですが、defaultパーティションの蓄積には不安が残りました。
defaultパーティションのモニタリング方法としては上記SQLを実行する方法がありましたが、既存の監視システムに乗せるのに簡単な方法が無く、defaultパーティションのモニタリングは現在も課題としてあります。
暫定的な対処として以下の方式を採用しています
- kubernetes CronJobでrun_maintenance_proc実行を定義
- 1週間に1度run_maintenance_proc実行
- ジョブの実行失敗をアラート通知させる
パーティション管理に想定外の事があっても1週間に1度はエラーが通知されるため、管理に問題があっても気づくことが出来るというものになります。
2. local開発環境でpg_partmanを利用する
開発用にPostgreSQLコンテナを手元に持ってくるケースはよくあるかと思いますが、pg_partmanを導入しているコンテナは公式提供はされていません。
以下のようなDockerfileとSQLを手元に置いて docker buildすれば開発に利用出来ます。
Dockerfile
FROM postgres:14 AS build
ENV PG_PARTMAN_VERSION v4.6.0
RUN apt-get update && apt install -y wget build-essential postgresql-server-dev-$PG_MAJOR
# Install pg_partman (no_bgw)
RUN set -ex \
&& wget -O pg_partman.tar.gz "https://github.com/pgpartman/pg_partman/archive/$PG_PARTMAN_VERSION.tar.gz" \
&& mkdir -p /usr/src/pg_partman \
&& tar \
--extract \
--file pg_partman.tar.gz \
--directory /usr/src/pg_partman \
--strip-components 1 \
&& rm pg_partman.tar.gz \
&& cd /usr/src/pg_partman \
&& make && make NO_BGW=1 install \
&& cd / \
&& rm -rf /usr/src/pg_partman
FROM postgres:14
RUN apt-get update
# install pg_partman
COPY --from=build /usr/share/postgresql/$PG_MAJOR/extension/pg_partman* /usr/share/postgresql/$PG_MAJOR/extension/
# enable extention
COPY create_extention_pg_partman.sql /docker-entrypoint-initdb.d/create_extention_pg_partman.sqlcreate_extention_pg_partman.sql
CREATE EXTENSION IF NOT EXISTS pg_partman;基本的にはpostgresコンテナを継承しているので、環境変数も同じ用に利用出来ます。
以下のようなdocker-composeを記載すれば利用可能です。
docker-compose.yaml
version: '3'
services:
## ----------
## PostgreSQL
## ----------
postgres:
build:
context: .
environment:
POSTGRES_DB: main
POSTGRES_USER: postgres
POSTGRES_PASSWORD: postgres
POSTGRES_CREATE_SCHEMA: example
ports:
- "5432:5432"3. Aurora パラメーター設定
必須では有りませんが、クエリパフォーマンス向上を見込める設定が有るので、本番化する前には留意したほうが良さそうです。
Aurora PostgreSQLでも設定出来るパーティショニング関係のパラメーターは3つあります
- enable_partition_pruning
- enable_partitionwise_join
- enable_partitionwise_aggregate
enable_partition_pruning はAurora PostgreSQL 14の時点でデフォルト有効化されてますので割愛します。
複数のパーティションテーブル同士で結合したり集約する部分がある場合 enable_partitionwise_join, enable_partitionwise_aggregateを有効化するとパフォーマンス向上が見込めます。
具体的には富士通さんの記事が大変良くまとまっているので、一読すると良いかと思います。
4. パーティションの一部をS3にエクスポート
巨大なパーティションテーブルの管理自動化方法の一つとしてS3エクスポートする方法を確認しています。残念ながら導入時にはパーティション自動削除は設定せず、蓄積してから考えるという形になったためS3エクスポートについては実際に投入はしていません。例の一つとして紹介できればと思います。
pg_partmanでパーティション自動削除する場合、メンテナンス用プロシージャを通じて古いパーティションが削除されます。定期的にS3エクスポートするのであれば、メンテナンスプロシージャを動かす前にS3エクスポートするなど設定が必要になります。
pg_partmanの設定次第ですが、デフォルトでは4ヶ月前まで保持します。履歴を格納するテーブルでレコードの更新が無い前提で考えると、3ヶ月前のパーティションを定期的にS3エクスポートするようにすれば漏れ無くS3エクスポート出来ると考えられます。
準備
詳細は割愛しますが、以下を準備します
- エクスポート先のs3 bucket作成
- RDS用のIAM Role作成、S3 Upload可能なIAM Policy付与
- rdsクラスターに作成したIAM Roleを付与
- aws_s3 EXTENSION有効化
- CREATE EXTENSION IF NOT EXISTS aws_s3 CASCADE;
aws_s3については以下ドキュメントが参考になります。
https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/postgresql-s3-export.html
S3 エクスポート用プロシージャ作成
aws_s3 extensionそのまま使うと、少し長いクエリを書くことになるため、複数パーティションテーブルを管理しやすくするために以下のようなプロシージャを作成します。
/* procedure */
CREATE OR REPLACE PROCEDURE s3_export_csv(target_table text,s3_bucket text, s3_prefix text)
LANGUAGE plpgsql
AS $$
BEGIN
RAISE INFO 'target_table: %', target_table;
EXECUTE $exec$
SELECT * from aws_s3.query_export_to_s3(
'SELECT * FROM ' || $1,
aws_commons.create_s3_uri($2, concat($3,'/', $1, '.csv'), 'ap-northeast-1'),
options := 'FORMAT CSV, HEADER'
);
$exec$ USING target_table, s3_bucket, s3_prefix;
END;
$$;例えば3ヶ月前のパーティションをS3エクスポートする場合は以下のようにCALLすればOKです。
CALL s3_export_csv(
concat('payment_transactions_p',
to_char(now()-interval '3 month','YYYY_MM')),
'<s3 bucket name>',
'payment_transactions'
);pg_cronを使った定期実行
同じSQL文で毎月実行するなら、pg_cronを使って定期実行する方法も取れます。
pg_cronは以下のように設定することが可能です。
-- pg_cron有効化
CREATE EXTENSION pg_cron;
-- 設定
SELECT cron.schedule(
'payment_transactions_s3_export',
'@monthly',
$$
CALL s3_export_csv(
concat('payment_transactions_p',
to_char(now()-interval '3 month','YYYY_MM')),
'<s3 bucket name>',
'payment_transactions'
)
$$
);pg_cronについてはRDSのドキュメントに詳しく書かれているので、以下を参考にすると良さそうです。
https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/PostgreSQL_pg_cron.html
まとめ
前半でパーティション管理の課題を述べつつ検討するポイントについて触れてきました。
後半では前半で述べた課題の解決策など具体的に導入する時に活用出来る点について触れました。
PostgreSQLのパーティションの管理には留意点が多く有りますが、うまく利用することで巨大テーブルとうまく付き合うことが出来るかと思います。pg_partmanについては、パーティションを運用する上でかなり助かる拡張機能だと思います。パーティション管理は基本的にpg_partmanを利用する方針として良いと思います
巨大なDBの管理方法として何か参考になれば幸いです。
We're Hiring!
📢
Mobility Technologies ではともに働くエンジニアを募集しています。
興味のある方は 採用ページ も見ていただけると嬉しいです。
Twitter @mot_techtalk のフォローもよろしくお願いします!