

Aurora PostgreSQLでテーブルパーティショニングを導入した話 【検討編】
SREDecember 09, 2022
技術戦略部 SREグループの古越です。
MoTで開発しているサービスの多くはAurora PostgreSQLを利用しています。一部サービスにはデータが蓄積し、肥大化していくテーブルの管理が課題になっています。今回は開発者からの要望で新規サービスの幾つかにパーティショニングを導入する事になりました。SREグループでパーティショニング導入までに検証したことを検討編と実践編という2つの記事で紹介できればと思います。
検討編では事前検証として行った事のまとめとして、導入検討の段階で注意するべきポイントを紹介いたします。実践編では導入するために行った具体的な施策について紹介してきます。
背景
肥大化するテーブル管理の課題
PostgreSQLに限らずDB一般に言えることですが、ログや履歴が含まれるテーブルはサービス成熟とともに徐々にデータが蓄積していきます。蓄積しすぎて肥大化すると簡単なクエリの応答が遅くなったり、削除が難しくなったり、INDEX付与の時間や容量が課題になるなど様々な難点が出てきます。
具体例を交えて言うと、タクシーアプリGOの決済履歴を格納するテーブルが肥大化してしまい、管理が難しいという状況になっていました。
具体例: 決済履歴テーブルの特徴
- 直近数ヶ月程度のデータは参照頻度が高い
- それ以上の過去データは参照頻度低い
- 1億レコード以上の蓄積
このテーブルの管理のため特定時刻のレコードを検索したり、古いデータを削除するという作業が必要でした。しかし肥大化したことでクエリ応答に時間がかかりDB負荷も高まってしまうという事になり、気軽に実行できなくなっていました。
テーブルを実際に運用していたのは決済基盤の開発グループでしたが、SREグループに依頼があり「このような課題の解決策として、新しいサービスでパーティショニングを導入できないか?」 という相談を受けました。そこでSREグループで開発用の足回り整備やAurora PostgreSQLへ導入するまでの事前検証などを行う事になりました。
私自身そこまでPostgreSQLについて詳しく無い所から開始したため、調べた事と行った事の総括という所も含めて紹介できればと思います。
基礎の解説
話を進める前に、パーティショニングの基本的なところをおさらいとして触れていきます。
PostgreSQLのテーブルパーティショニング
PostgreSQLでは大きなテーブル管理の課題解決策としてテーブルパーティショニングが標準機能として用意されています。パーティショニングについての概要はこれから触れていきますが、初めて知る人には富士通さんの記事がお勧めです。
テーブルパーティショニングは
- 論理的に大きなテーブルとして振る舞う親テーブル
- 物理的にデータを格納する子テーブル(パーティション)
の2種類のテーブルを作ることで実現されます。
作った後は親テーブルにSQLクエリを投げると子テーブルにルーティングされる動きとイメージすればだいたい合っています。
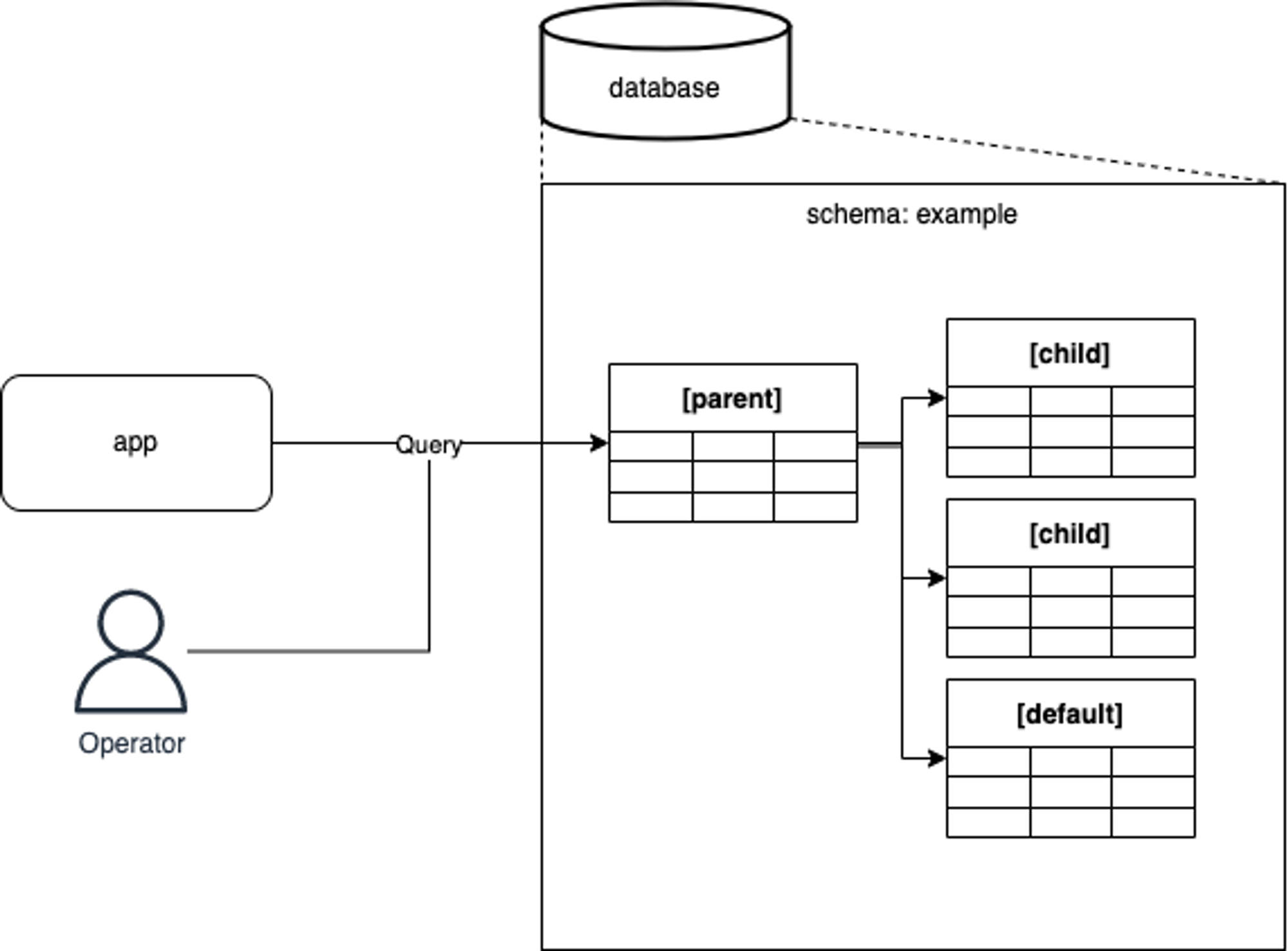
パーティショニング 利用イメージ
データの実体が扱いやすい単位で子テーブルに自動格納されるため、管理上の恩恵が幾つか有ります。例えば履歴を格納するテーブルを1ヶ月単位でパーティション分割したとすると以下のメリットが得られます。
- nヶ月前のデータを丸ごと廃棄 or 別のスキーマに移動 という作業が数秒で可能になる
- nヶ月前の過去データをWHEREで検索する場合、分母が減ってクエリパフォーマンスが向上
運用中のリスク軽減やコスト削減という所に役立ちます。
パーティショニングの種類
パーティションと一口に言っても分割方式によって種類があります。データの特徴に合わせて適切なパーティションを選択する必要があるので、種類と特徴については理解しておくと良いと思います。
PostgreSQL15時点で3種類の分割方法が用意されています
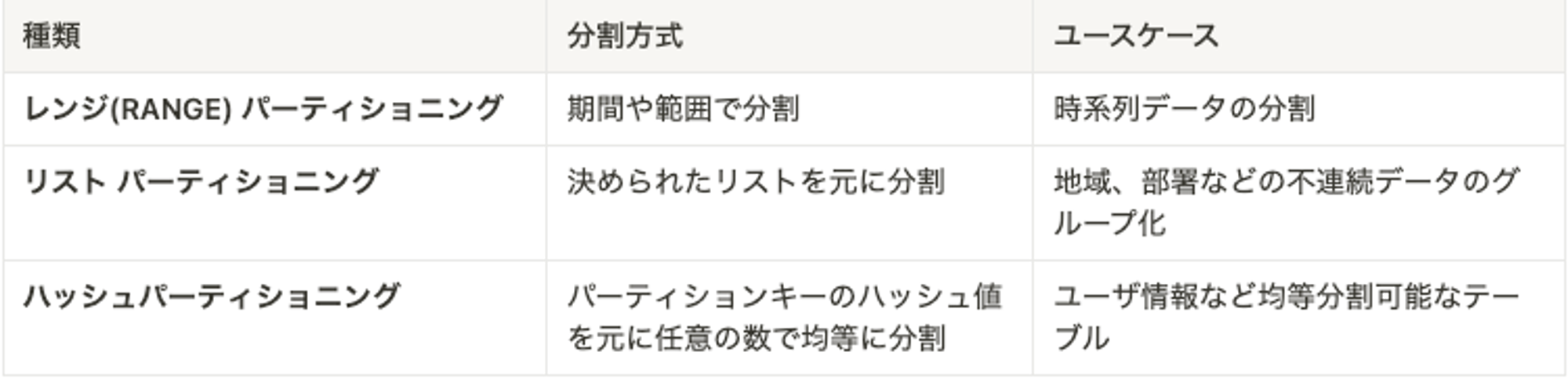
今回は履歴を格納するテーブルが課題になっていたため、レンジパーティショニングを前提として導入検証などを行っています。
パーティショニング 具体的な設定例と特徴
パーティショニングを構成する親子テーブルはそれぞれ以下のようなDDLで定義できます。
取引履歴を格納するようなテーブルをサンプルとして見ていきましょう。
/* Create Parent Table */
CREATE TABLE payment_transactions
(
id bigint NOT NULL GENERATED ALWAYS AS IDENTITY,
uuid uuid NOT NULL,
created_at timestamp DEFAULT CURRENT_TIMESTAMP NOT NULL,
-- 他カラム省略
PRIMARY KEY (id, created_at),
UNIQUE (uuid, created_at)
) PARTITION BY RANGE (created_at) WITHOUT OIDS;
/* Create Partition */
CREATE TABLE payment_transactions_p2022_11 PARTITION OF payment_transactions
FOR VALUES FROM ('2022-11-01'::timestamp) TO ('2022-12-01'::timestamp);
CREATE TABLE payment_transactions_p2022_12 PARTITION OF payment_transactions
FOR VALUES FROM ('2022-12-01'::timestamp) TO ('2023-01-01'::timestamp);
/* Create Default Partition */
CREATE TABLE payment_transactions_default PARTITION OF payment_transactions
DEFAULT;親テーブルの特徴
- 子テーブルへのルーティング、テーブル構造を子に継承するなどの役割を持つ論理的テーブル
- データの実体は親テーブルに格納されない
- PARTITION BY で子テーブルに分配する方式とパーティションキーを指定
- RANGEパーティションの場合、timestamp型で細かく指定する事も可能
- PRIMARY KEY, UNIQUE制約を付ける場合はパーティションキーを含む複合キーとして指定する必要あり
子テーブル(パーティション)の特徴
- 実体を格納するテーブル
- カラム、INDEXなどテーブル構造は親から継承する
- RANGEパーティションなら FROM ≦ x < TO で範囲を指定
- 親テーブルにINSERTしたとき配置先のパーティションが無い場合はエラーになる
- 予め作成する必要あり
- defaultパーティションを作る事でパーティションが存在しないエラーと取りこぼしを防げる
- 一度defaultパーティションに格納された後に新規パーティションを追加する時には注意
ドキュメントにも記載がありますが、通常テーブルを後でパーティションテーブルに変更したり、逆にパーティションテーブルを通常テーブルに戻すということは出来ません。パーティションキーを途中変更したい場合もテーブルを改める必要があります。
SQLクエリ上でも PARTITION BY でパーティションを設定出来るのは CREATE TABLE だけに制限されており、ALTER TABLE で後から変更することは出来ません。後から変更可能なのはパーティションのアタッチ、デタッチという程度です。
パーティションを後から変更するのは難しい作業が必要になるため、入念に設計する必要が有ります。簡単な解説としては以上です。
パーティショニングの要注意点
事前検証していく中で見つかった要注意点について解説していきます。
RANGEパーティションの運用課題
基本的にデータを格納する前に十分なパーティションを追加しておくのが好ましいです。時系列のRANGEパーティションを設定する場合は、時間経過とともにパーティションの追加削除といったメンテナンス作業を継続的に行う必要があります。
- パーティションテーブルの格納先が無くなる期日から数ヶ月前に次のパーティションを追加
- 年1回でまとめて13ヶ月先のパーティションを追加する
というような運用をしていく必要があります。運用段階ではパーティション追加削除の自動化や省力化が課題になります。
パーティションの追加削除を自動化する方法として pg_partmanという拡張機能を用いる方法が有り、今回採用する事にしています。具体的には次回のブログで解説いたします。
defaultパーティションテーブルの注意点
例にも記載しましたが、PostgreSQL 11以後に追加された機能でdefaultパーティションという取りこぼしを防ぐ一時的なテーブルを作る事ができます。defaultという名前になっていますが、RANGEパーティションの場合はテンポラリ領域に近い一時的な置き場所とイメージしたほうが良いです。
注意すべき挙動として、「defaultパーティションに格納したレコードと一致する条件で新しいパーティションを作ろうとするとエラーになる」という動きが有ります。
参考 https://www.enterprisedb.com/blog/default-partition-adopting-odds
具体的に例を上げると、サンプルに書いたパーティションテーブルを放置したとすると以下のようなシナリオが考えられます。
- (運用が放置され) 2023-01-01以後のデータ格納先パーティションが無い状態に
- 2023-01-01以後にデータが記録された場合、defaultパーティションテーブルに格納される
- 後日作業漏れに気づいて2023-01-01~2023-02-01のパーティションを追加しようとするが、エラーでパーティションが作れなくなる
直接的な害は少ないですが、リカバリとしてdefaultパーティションから別のパーティションを作って再配置する作業が必要になります。再配置に必要なデータ量が多いとLockが長めに掛かったりDB負荷が高まったりするため運用上好ましくありません。
このような状態を放っておくとdefaultパーティションしか利用してない状態になり、分離することに意味のあるパーティショニングのメリットが失われます。
取りこぼしを防ぐためにdefaultパーティションを作っておくのが安全ではあるのですが、可能な限りdefaultパーティションにデータが蓄積しないように運用設計する必要があります。
パーティション化したテーブルの変更、INDEX付与
パーティションテーブルにカラムを追加する場合は親テーブルにカラムを追加すれば子テーブルに継承されるため問題はありません。しかし、INDEX付与はLockのかかり方に注意が必要です。
INDEX付与時のLockについて
通常PostgreSQLでINDEX付与する際はテーブルに対してShareLockがかかります。ShareLockはINSERT/UPDATE/DELETEなどの書き込みクエリと競合するLockであるため、INDEX付与完了までは書き込みクエリがLock待ちで滞留します。
このLock待ちを回避するために CREAET INDEXに CONCURRENTLY というオプションが用意されています。オプションを付けるとLockのレベルが落ちますので、書き込みを滞留させることなくINDEX付与することが可能になります。
しかし、PostgreSQL15時点ではパーティション化したテーブルにCONCURRENTLYオプション有りでINDEX付与することが出来ません。
実際に親テーブルに対して実行すると以下のようなエラーが出力されます。
> CREATE INDEX CONCURRENTLY payment_transactions_id_idx ON payment_transactions(id);
ERROR: cannot create index on partitioned table "payment_transactions" concurrentlyこのような制約があるため、親テーブルに対してはそのままCREATE INDEXを実行する必要が有ります。しかし、そのまま実行するとINDEX付与中は親子テーブルの全てにShareLockがかかるという挙動になってしまいます。
INDEX付与のLock時間を短縮する策
CREATE INDEX CONCURRENTLYの未サポート部分については公式ドキュメント上に回避策が提示されており、2段階のINDEX付与作業をすることでShareLockの時間を短縮することが出来ます。
Lock時間短縮手順
- すべての子テーブル(パーティション)に CONCURRENTLYオプション有りでINDEXを付与
- 最後に親テーブルに CONCURRENTLY無しでINDEX付与
クエリの実例としては以下のようになります。
-- 1. add index child
CREATE INDEX CONCURRENTLY payment_transactions_p2022_11_id_idx ON payment_transactions_p2022_11(id);
CREATE INDEX CONCURRENTLY payment_transactions_p2022_12_id_idx ON payment_transactions_p2022_12(id);
CREATE INDEX CONCURRENTLY payment_transactions_default_id_idx ON payment_transactions_default(id);
-- 2. add index parent
CREATE INDEX payment_transactions_id_idx ON payment_transactions(id);はじめに実行する子テーブルに対するINDEX付与は少し時間がかかりますが、CONCURRENTLYオプションが有効なためLock影響はほぼ有りません。
2つめの親テーブルにINDEX付与する箇所は、子テーブルに対するINDEX付与が終わっていれば一瞬で完了します。
INDEX付与検証
導入前に上記作業の検証を行っています。
- 全体で1億レコードを格納したパーティション化したテーブルを用意
- 約0.5秒間隔でロック状態を出力するスクリプトを実行
この状態で2段階のINDEX付与を行いましたが、結果は親子テーブルともにShareLockを観測することなく終わるというものでした。
ShareLockは発生していたかもしれませんが、0.5秒未満の軽微なものに抑えられていたようです。
本番環境で行うINDEX付与には上記のような2ステップの手順で行うように運用設計をするのが良いかと思います。INDEX周りの情報も公式ドキュメントに記載されていますので、本番影響を気にする場合は一読することをお勧めします。
参考: https://www.postgresql.org/docs/current/sql-createindex.html
論理レプリケーションの連携
パーティション化したテーブルでは実体が子テーブルに格納されます。何もせず論理レプリケーションと組み合わせると、子テーブルに対する書き込みイベントが延々と発行されます。
MoTの幾つかのサービスでは Debezium connector for PostgreSQLとGCP PubSubを使い、CDC方式で分析基盤へデータを転送しています。デフォルトのまま連携させるとDebeziumから伝わるCDCイベントは子テーブルに対する書き込みイベントになってしまいます。オリジナルDBと同じような見え方にするためには分析基盤側でテーブルを集約させるなどの別の仕組みが必要になることが予見されました。
回避策を探したところ、以下のようにpublicationに publish_via_partition_root というオプションを付ける事が有効ということが分かりました。
CREATE PUBLICATION pub FOR ALL TABLES WITH (publish_via_partition_root = true);このオプションを入れるとパーティションの子テーブルではなく親テーブルに対するイベントとして論理レプリケーションのイベントが発行されます。
上記のように作成したpublicationをDebeziumが参照するよう設定したところ分析基盤側の不要な作業を回避することが出来ました。
今回はDebeziumに関する部分でしか検証していませんが、一般的な論理レプリケーションにも活きる重要なポイントになるかと思います。
参考:
- https://www.postgresql.org/docs/15/sql-createpublication.html
- https://amitlan.com/2020/05/14/partition-logical-replication.html
パーティショニングの向き不向き
ここまで読んだ方には言うまでも無いかも知れませんが、すべてのテーブルに導入するのはお勧めしません。
例えば
- データ量が少ない
- 依存関係の多いマスターデータを格納する
というようなテーブルはパーティショニングによるメリットがほぼ有りません。
複雑になるデメリットが勝るので、避けたほうが良いでしょう。
感覚値になりますが、数年で1億レコード規模のテーブルに成長する見込みであればパーティショニングを検討すると良いかと思います。
まとめ
パーティショニングを導入する時のポイント
これから導入を検討する方向けに、検討フェーズで確認するべきポイントをまとめます。
- パーティショニングの必要性をよく検討する
- パーティショニングon/offの切り替えは出来ず、新しいテーブルを作って移行する必要有り
- サイズが小さい場合はパーティショニングは採用しない方が好ましい
- パーティション化したテーブルの変更は注意する
- パーティションキーは変更出来ない
- INDEX付与は広めのロックが掛かる 回避策があるため運用手順を整備する
- パーティションの定期的な追加、削除といった管理作業のアプローチを検討する
- pg_partmanの利用を推奨
- DDL管理ツールとの相性を確認する
- defaultパーティションの管理、モニタリング方法を考える
- データ連携、論理レプリケーションとの組み合わせを確認する
後からの変更が辛いポイントが多いため、十分に事前検証することをお勧めします。
導入時点のAurora PostgreSQL最新安定版は14でしたので本記事は14を前提としていますが、パーティショニングに関してはPostgreSQL 15に大きな変更はありません。15でも同様と考えて良さそうです。
導入するために実施、検証したこと
基礎知識と注意点を諸々述べて来ましたが、導入する前には以下を重点的に検証していました。
- パーティション管理の自動化のため pg_partmanを導入する
- local開発環境でpg_partmanを利用可能にする
- Aurora PostgreSQLパラメーターのチューニング
- パーティションの一部をS3にエクスポートする
この内容については次のブログで紹介しようと思います。
次回: Aurora PostgreSQLでテーブルパーティショニングを導入した話 【実践編】
We're Hiring!
📢
Mobility Technologies ではともに働くエンジニアを募集しています。
興味のある方は 採用ページ も見ていただけると嬉しいです。
Twitter @mot_techtalk のフォローもよろしくお願いします!