

物体検出フレームワーク IceVisionの紹介
AIDeep Learningコンピュータビジョンこんにちは、AI技術開発部AI研究開発第二グループの佐々木です。 本記事では、物体検出アルゴリズムを効率的に開発できるフレームワークIceVisionを紹介します。
はじめに
IceVisionは既存の有名物体検出リポジトリを統合して使えるようにしたPyTorch-Lightning/fastaiベースのフレームワークです。
IceVisionは以下のような作業をスピーディーに行いたい方にオススメです
・実務での物体検出アルゴリズム開発における最新手法ベンチマーク ・Kaggle等の物体検出コンペにおけるベース手法の選定 ・論文執筆における既存手法とのベンチマーク
課題意識
物体検出は画像認識で最も有名なタスクの一つですが、ホットな研究領域であることから最新手法やその実装の移り変わりは激しく、ディープラーニングのフレームワークが整備された現在も、以下のような場面では多くの時間を取られることがあります。
課題(1) リポジトリの選定、実装
物体検出は画像分類等と比べアルゴリズムが複雑なため実装が煩雑になりがちで、実装によっては論文同等の性能が出ない、学習が遅い、リポジトリとして使いにくいといったことがあります。このためリポジトリは時間を掛けて選定したり、適切なリポジトリがない場合等はスクラッチでアルゴリズムを実装したりする必要があります。
課題(2) 複数手法の横断的な利用
物体検出には、アノテーションのフォーマットが複数存在しているため、選定したリポジトリが採用しているフォーマットと、自分が学習したいデータのフォーマットとが異なる場合、両者を繋ぎ合わせる作業が発生し、特に複数手法間でのベンチマークを行うためいくつかのリポジトリを横断的に使う場合それなりの時間を取られます。
物体検出フレームワーク
前述の課題に対応できるものとして、2018~2019年頃、MMDetectionやDetectron2等の物体検出フレームワークと呼ばれるものが登場しました。これらは、複数の物体検出アルゴリズムを纏めて使えるようにしたもので、実装の完成度が高く、論文同等の性能で幅広いアルゴリズムを使え、チューニングもしやすくコードベースとして優れているため、広く使われています。
他方これらの物体検出フレームワークで前述した課題を全て解消できるかというと答えはNoで、物体検出コンペでもよく使われるような一部の手法(EfficientDetやYOLOv5といったSoTAの手法)がMMDetection等には含まれていないため、現実的には個別の再現実装リポジトリの利用を視野に入れる必要がありました。
IceVisionはこの辺りの課題を解決してくれます。
IceVisionの特徴

MMDetection等が、完成度の高い再現実装集というような方向性であるのに対し、IceVisionは、再現実装は行わず既存のリポジトリをそのまま取り込んで統合しています。
既存リポジトリのモデル実装をimportする形で利用し、取り込んだリポジトリを統合できるようにデータローダ部分を独自仕様で実装しています。このためユーザはIceVisionのAPIを利用すれば、IceVisionに取り込まれた複数のリポジトリを統一的に扱うことができます。。
実際に取り込まれているリポジトリは、MMDetectionの各種実装、PyTorch標準のtorchvision、Ross Wightmanさんが再現実装を行ったEfficientDet等です。直近ではYOLOv5を新たに取り込もうとしているようです(FraPochetti/mantisshrimp )。
IceVisionの構成を概念図としてまとめると以下のようなイメージです。
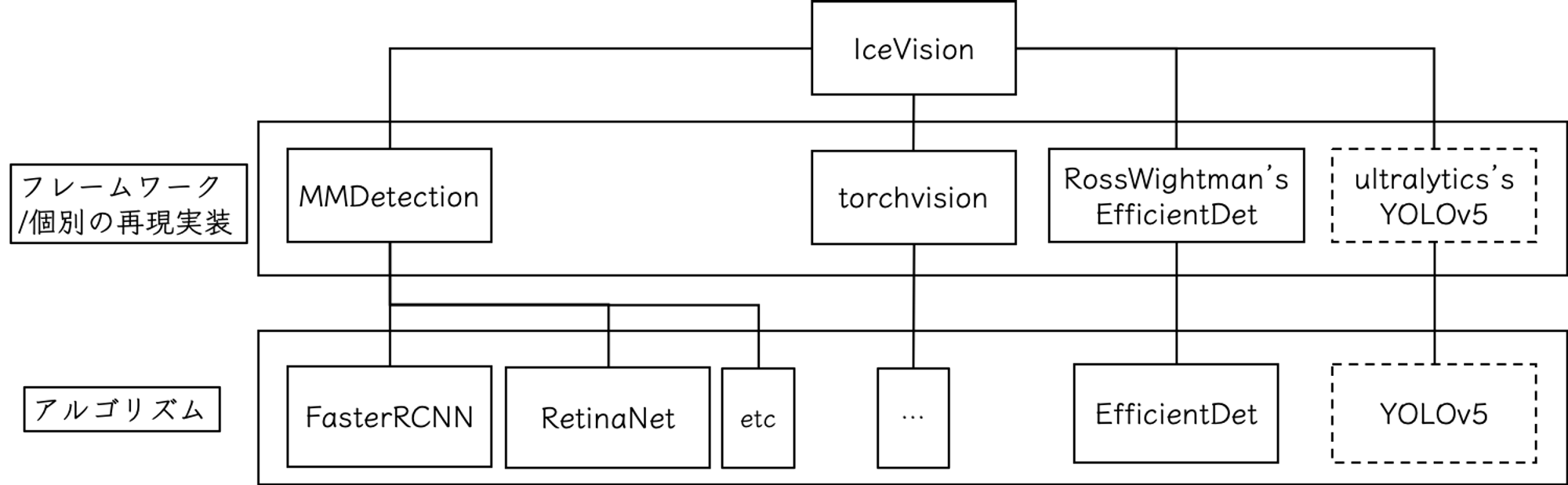
IceVisionのメリット/デメリット
幅広いアルゴリズムを統一されたI/Fで使えるIceVisionですが、不得手なこともあります。
IceVisionは、共通I/Fで抽象化できないリポジトリ固有部分のチューニングが面倒です。各手法のネットワークアーキテクチャや損失関数、固有パラメータを修正する場合はimportされているライブラリのコードを直接書き換えることになります。
このため、ベースアルゴリズムの選定には力を発揮しますが、踏み込んだ検討には不向きです。
ちなみにIceVisionで簡単に触れるハイパーパラメータは、アルゴリズム共通部分では概ね以下の範囲です。基本的にはpytorch-lightning等で簡単に触れる範囲と同じです。(この他、EfficientDetの場合はBackboneのサイズを選べたりします。)
- Epoch数
- 各種Optimizerの選択とそれらの設定
- Learning Rate
- dropout rate
- データ拡張
- FP16 or 32
IceVisionを触ってみよう
ここまでの内容でIceVisionには興味を持って頂けたでしょうか。筆者はこれまでいくつか物体検出フレームワークや個別のリポジトリを触ってきましたが、IceVisionはそれらと比較して簡単に動かせます。
それでは実際にセットアップおよび学習と推論までを進めてみましょう。
IceVisionのセットアップ
pipでインストールできます
pip install icevision[all] icedata
ちなみに、本チュートリアルの動作は以下のバージョンで確認しています。
pip install icevision[all]==0.5.2 icedata==0.2.0
IceVisionの使い方(標準データセット)
公式のチュートリアルのコードを一部修正したものを使い、上記pipでインストールされたicedataに含まれるPetsデータセットを使って画像から犬と猫を検出する例をご紹介します。https://airctic.com/examples/efficientdet_pets_exp/
IceVision特有の部分以外は適宜割愛しています。詳細は公式チュートリアルをご参照ください
データの読み込み
# Loading Data
data_dir = icedata.pets.load_data()
icedataと呼ばれるIceVisionが整備しているデータセットリポジトリの中からpetsを指定し、data_dirという変数にpetsデータセットを代入します。
読み込んだデータを学習に使うためのパーサーの設定
# Parser
class_map = icedata.pets.class_map()
parser = icedata.pets.parser(data_dir, class_map)
train_records, valid_records = parser.parse()
show_records(train_records[:3], ncols=3, class_map=class_map)
class_mapという変数はデータセットのアノテーションのクラスを代入したものです。class_mapと一つ前のブロックで作ったdata_dirを引数としてparserというインスタンスを作成します。
標準データセットの場合はclass_mapとparserを上記コードのようにicedataを使って作成しますがカスタムデータの場合はicedataを使わずに別途定義します。
parser作成後はparse()というメソッドで学習用と評価用にそれぞれtrain_records, valid_recordsを作ります。show_records()は可視化用メソッドで、以下のようにbboxとクラスが可視化されます。

入力サイズ等やデータ拡張に関する設定
# Datasets
presize = 512
size = 384
train_tfms = tfms.A.Adapter([*tfms.A.aug_tfms(size=size, presize=presize), tfms.A.Normalize()])
valid_tfms = tfms.A.Adapter([*tfms.A.resize_and_pad(size), tfms.A.Normalize()])
train_ds = Dataset(train_records, train_tfms)
valid_ds = Dataset(valid_records, valid_tfms)
samples = [train_ds[0] for _ in range(3)]
show_samples(samples, ncols=3, class_map=class_map, denormalize_fn=denormalize_imagenet)
presize = 512は変換対象画像のリスケール後のサイズを表しており、size = 384は実際にモデルに与える入力サイズです。データ拡張時は画像を一旦presizeの大きさに揃えたあと、最終的にsizeで指定した大きさにリサイズしています。train_tfmsとvalid_tfmsはtfms.A.Adapterを使って変換の設定を指定しています。valid_tfmsはデータ拡張なしにしている点には注意してください。
train_dsとvalid_dsはtrain_records, valid_recordsをtrain_tfmsとvalid_tfmsの設定でpytorchのDatasetクラスに変換したものです。show_samples()は可視化用のメソッドで、以下に示すようにさきほどの画像がAugmentationされたものが出てきます。

データローダの設定
# DataLoaders
train_dl = efficientdet.train_dl(train_ds, batch_size=16, num_workers=4, shuffle=True)
valid_dl = efficientdet.valid_dl(valid_ds, batch_size=16, num_workers=4, shuffle=False)
batch, samples = first(train_dl)
show_samples(samples[:6], class_map=class_map, ncols=3, denormalize_fn=denormalize_imagenet)
model = efficientdet.model(model_name="tf_efficientdet_lite0", num_classes=len(class_map), img_size=size)
metrics = [COCOMetric(metric_type=COCOMetricType.bbox)]
# Train using pytorch-lightning
class LightModel(efficientdet.lightning.ModelAdapter):
def configure_optimizers(self):
return Adam(self.parameters(), lr=1e-3)
light_model = LightModel(model, metrics=metrics)
trainer = pl.Trainer(max_epochs=10, gpus=1)
trainer.fit(light_model, train_dl, valid_dl)
train_dlとvalid_dlはtrain_dsとvalid_dsを引数としてpytorchのDataloaderクラスを返す関数です。
efficientdet.modelはEfficientDetのモデルを読み込んでいます。model_name="tf_efficientdet_lite0"を変えれば、EfficientDetのBackboneサイズを変えられます。 ちなみにtf_efficientdet_lite0はEfficientDetの中では最も軽量なBackboneになります。metricsは、物体検出のデファクトな指標であるCOCOMetricを指定しています。
class LightModel(efficientdet.lightning.ModelAdapter):ではtrainer.fitを動かすためLightModelClassを作り、その中でoptimizerを定義しています。定義後、作っておいたmodelとmetricsをLightModelクラスに与えてモデルを生成します。Trainerにエポック数とgpuを指定し、trainer.fitにlight_modelとtrain_dl、valid_dlを与えたら学習スタートです。ちなみにTrainerやtrainer.fitの詳細はpytorch-lightningの公式サイト等を参照ください。
推論
# Inference
infer_dl = efficientdet.infer_dl(valid_ds, batch_size=8)
samples, preds = efficientdet.predict_dl(model, infer_dl)
# Show samples
imgs = [sample["img"] for sample in samples]
show_preds(samples=imgs[:6],preds=preds[:6],class_map=class_map,denormalize_fn=denormalize_imagenet,show=True,ncols=3,)
infer_dlは、データとbatch_size を引数としてpytorchのDataloaderクラスを返すIceVisionの関数です。predict_dlは、直前に定義したinfer_dlと学習済みのモデルを引数として推論結果を返すIceVisionの関数です。show_predsは可視化用のメソッドです。学習後の推論結果を可視化すると以下のような画像が得られます。(可愛いワンチャンのbboxを検出できていますね。)

IceVisionの使い方(カスタムデータセット)
以下の公式チュートリアルのコードを抜粋したものを説明しています。https://airctic.com/custom_parser/
Notes: IceVisionは現在も開発が進んでおりリポジトリやチュートリアルの変わり続けていますこのため、将来的に本記事の内容は公式サイトと整合性を取れなくなる可能性があります。本記事ではicevisionは0.7.0rc1、icedataは0.3.0.devを想定しています。
以下、公式チュートリアルのcolabを編集してそのまま動くようにしたcolabです。
https://colab.research.google.com/drive/1PZXP9L6AZ02iMGl9NeAEADsphmQLuqfd?usp=sharing
インストール
(2021/03/24時点での公式チュートリアルと整合の取れたバージョンでインストール)
pip install --upgrade pip
pip install icevision[all]==0.7.0rc1
pip install git+https://github.com/airctic/icedata.git
データの取得
チュートリアル用のデータを取得します
data_url = "[<https://github.com/airctic/chess_sample/archive/master.zip>](<https://github.com/airctic/chess_sample/archive/master.zip>)"
data_dir = icedata.load_data(data_url, 'chess_sample') / 'chess_sample-master'
フォーマットの確認
カスタムデータセットの場合、以下のようなcsvを作ります。今回はダウンロードしたファイルの中にannotations.csvというものが含まれています。
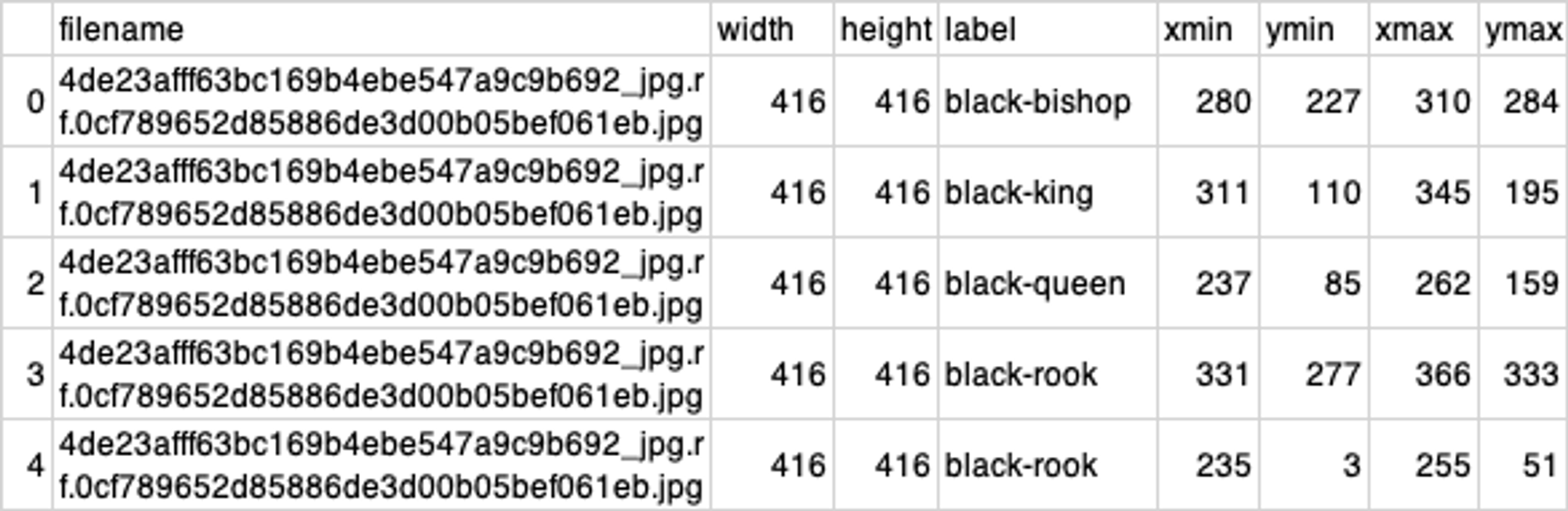
各軸はそれぞれ以下のような情報を示しています。
- filename: 入力画像の名前
- width : 入力画像の幅 (pix)
- height : 入力画像の高さ (pix)
- label : class名
- xmin, ymin, width, height: それぞれ、bboxにおけるx/y軸の最小値/最大値 (pix)
読み込み
前述のannotations.csvを以下のように読み込みます。
df = pd.read_csv(data_dir / "annotations.csv")
df.head()
カスタムパーサーの定義
IceVisionのメソッドObjectDetectionRecordを呼び出し、テンプレートレコードを作成します。
template_record = ObjectDetectionRecord()
次にtemplate_recordを引数としてIceVisionのメソッドgenerate_templateを呼び出します。
Parser.generate_template(template_record)
カスタムパーサーを定義します。
class ChessParser(Parser):
def __init__(self, template_record, data_dir):
super().__init__(template_record=template_record)
self.data_dir = data_dir
self.df = pd.read_csv(data_dir / "annotations.csv")
self.class_map = ClassMap(list(self.df['label'].unique()))
def __iter__(self) -> Any:
for o in self.df.itertuples():
yield o
def __len__(self) -> int:
return len(self.df)
def record_id(self, o) -> Hashable:
return o.filename
def parse_fields(self, o, record, is_new):
if is_new:
record.set_filepath(self.data_dir / 'images' / o.filename)
record.set_img_size(ImgSize(width=o.width, height=o.height))
record.detection.set_class_map(self.class_map)
record.detection.add_bboxes([BBox.from_xyxy(o.xmin, o.ymin, o.xmax, o.ymax)])
record.detection.add_labels([o.label])
- __init__: 画像ファイルへのパス data_dir 、アノテーションファイルへのパスdf 、クラス一覧class_map を取得します。ClassMapは学習対象となるデータセット中のクラス名を全て定義したものです。
- __iter__: pandasのdf.itertu。ples メソッドを呼び出しdf の全行を反復処理します。
- __len__: 反復処理するアイテム数を返します。
- recordid: 前述したcsvの filename をレコードのidとして返します。
- parse_fields: レコードのid以外の各属性を収集します。
カスタムパーサーの利用
定義したパーサーは以下のように使います。
parser = ChessParser(template_record, data_dir)
標準データセットのチュートリアル時と同じようtrain_recordsとvalid_recordsを作ります。
train_records, valid_records = parser.parse()
標準データセットチュートリアルと同じようにレコードを可視化すると以下のようになります。
show_record(train_records[0], display_label=False, figsize=(14, 10))
train_records[0]

あとは標準データセットの時と同じようにparserを使えば学習を行うことができます。
まとめ
IceVisionは、既存の物体検出リポジトリを統合するラッパーのような新しいタイプのフレームワークで最新の物体検出アルゴリズムをスムーズに動かせる便利なものです。
SoTAな物体検出アルゴリズムの比較を簡単に行えるため、初期検討を効率よく進めたいシーンで重宝するかと思います。
物体検出に関する実験コストを最小化しておきたい方は、一度触ってみてはいかがでしょうか。
最後になりましたが、MoT では、AI 技術の実応用に向けてCVエンジニアを募集中です。現在募集中のポジションはこちらの通りですので、少しでもご興味ある方はぜひご連絡をいただければと思います。
採用ページはこちら >>> https://hrmos.co/pages/mo-t/jobs