

GIS処理を超超高速化した話
ServerSideAlgorithm地図December 12, 2021
この記事は Mobility Technologies Advent Calendar 2021 の12日目です。
MoTでサービス展開しているタクシーアプリ『GO』では、地理情報を元にした様々な処理を行っているのですが、その中でも、タクシー車輌やお客様が特定範囲内に位置しているかどうかの判定処理は様々な処理の中で実行されるものとなります。
この記事では、この高頻度で実行される処理の高速化をどのように実現しているのかについてご紹介します。
はじめに
MoTの取締役 兼 開発本部本部長をやっている惠良です。部門のマネジメントをしながら、自らもタクシーアプリ『GO』のプロダクト開発や運営に深く関わっています。この記事で紹介する内容は、2019年に開催された『Mobility:dev』というイベントで登壇した際に紹介した内容をベースに、さらなる高速化を実施した点について紹介するものです。
さて、今回紹介するタクシーアプリ『GO』で行っている「タクシー車輌やお客様が特定範囲内に位置しているかどうかの判定」処理は、GIS(Geographic Information System)ではPoint-In-Polygonなどと呼ばれるのですが、なぜこの処理が必要なのか最初に説明します。
タクシーには営業可能なエリアとして営業区域というものが道路運送法で定められていて、アプリからの注文を受け付ける際にもこの営業区域を意識しなければなりません。営業区域に関する営業ルールはざっくりまとめると以下のようになります。
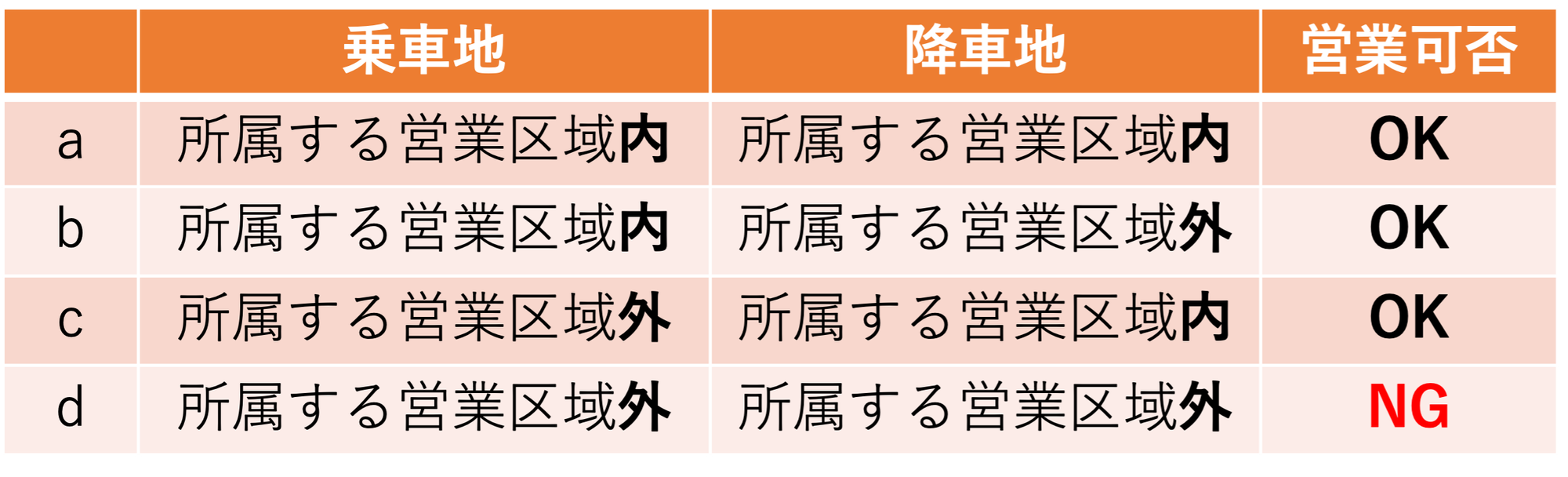
上記のような営業ルールが存在するため、各タクシー車輌の所属する営業区域とお客様が乗車ないし降車しようとしている場所とのマッチングを行う必要があります。
Point-In-Polygon処理の負荷軽減と枝刈り
GISにおけるPoint−In-Polygon処理は、基本的に緯度経度を座標とした二次元座標系における判定処理になりますが、こういったGIS処理は意外といろんなところで需要があるため、RDBMSなどでも対応されていたりします。
タクシーアプリ『GO』では、実行頻度の高いPoint-In-Polygon処理をRDBMSの機能を利用するのではなく、自前で開発したサーバー上で計算しています。計算処理の最適化とスケーラビリティを担保するための手段としてこのような構成のシステムにしているのですが、この構成に至るまでの経緯についてもMobility:devで説明していますので、詳細は割愛させて頂きます。
では、実際にPoint-In-Polygon処理がどういった判定を行っているのかイメージしていただくために、東京都内の営業区域である特別区・武三交通圏のポリゴンを以下に示します。
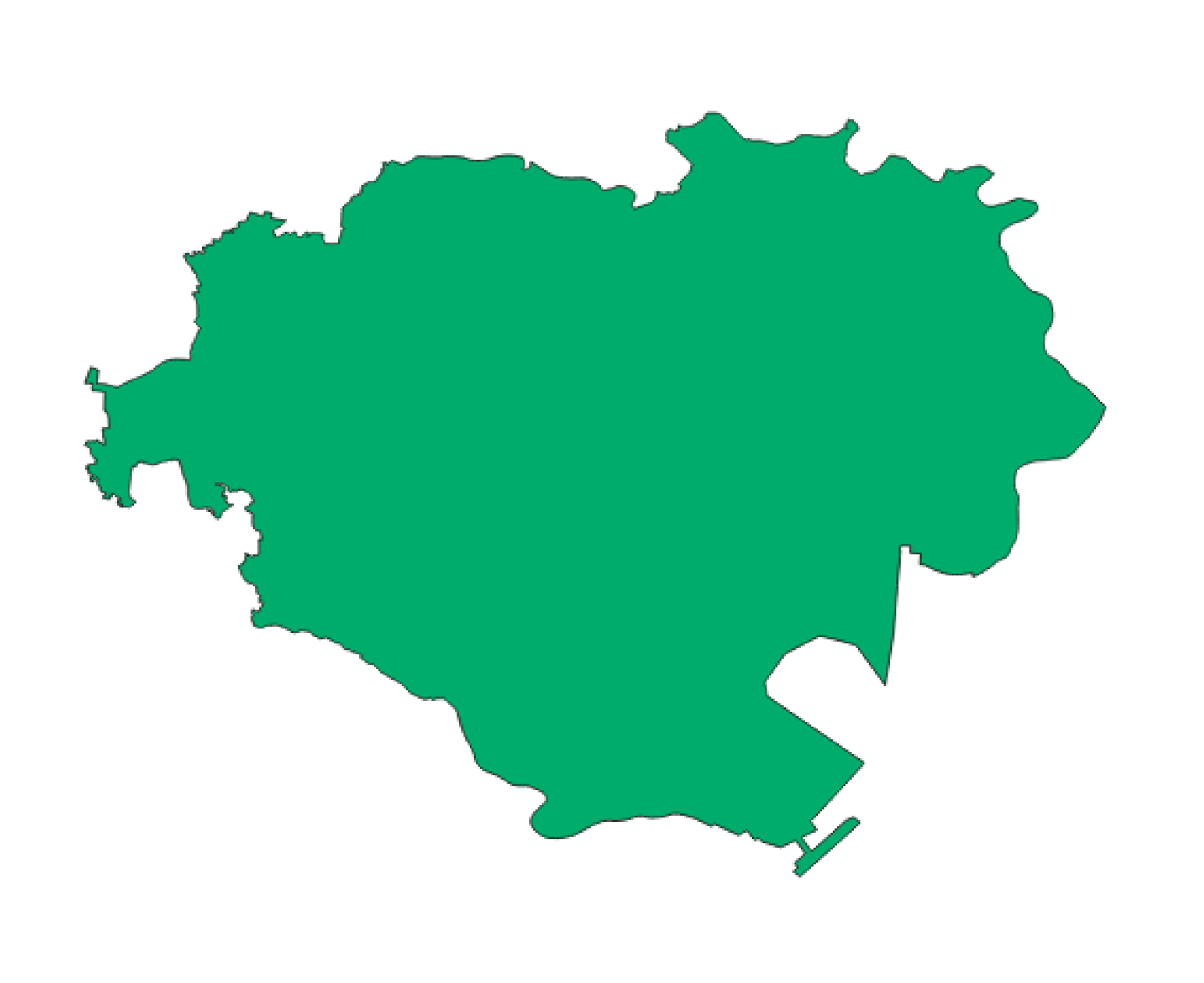
上の図を見ると、相当複雑な形状になっていることが理解できると思いますが、このポリゴンデータは3888頂点もあります。この複雑な形状の中に、任意の座標が含まれているかどうかを判定するためには、相当複雑かつ多くの計算が必要なことは容易に想像できると思います(実際のPoint-In-Polygonの計算アルゴリズムについては相当複雑かつここでは重要ではないため割愛します)。
前述の『Mobility:dev』でのプレゼンでは、この複雑なポリゴンを対象にしたPoint-In-Polygon処理を効率良く枝刈りして計算負荷を下げるというものですが、考え方を以下で簡単に説明します。
まず、以下のようにポリゴンを細かいエリアに分割するとします。
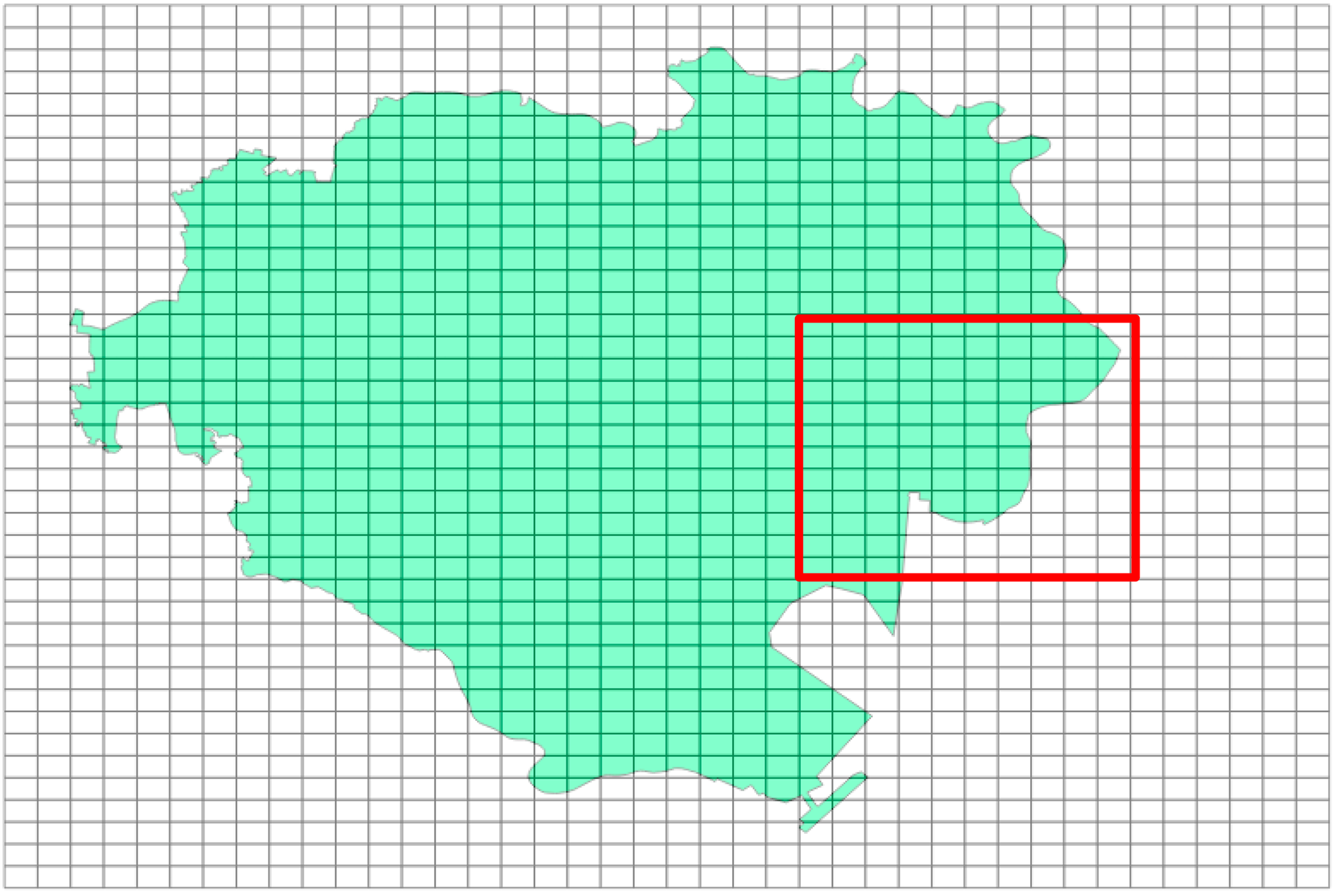
この分割されたポリゴンの一部(上記赤枠)に注目します。

この注目した範囲のエリアには、以下の3つのパターンのエリアが存在します。
- エリア内であればどこでも必ずポリゴン上に位置する(ポリゴンと交差する)
- エリア内であればどこでも必ずポリゴン上に位置しない(ポリゴンと交差しない)
- エリア内の場所によってはポリゴン上に位置する(ポリゴンと交差するかもしれない)
これを図にすると以下のようになります。
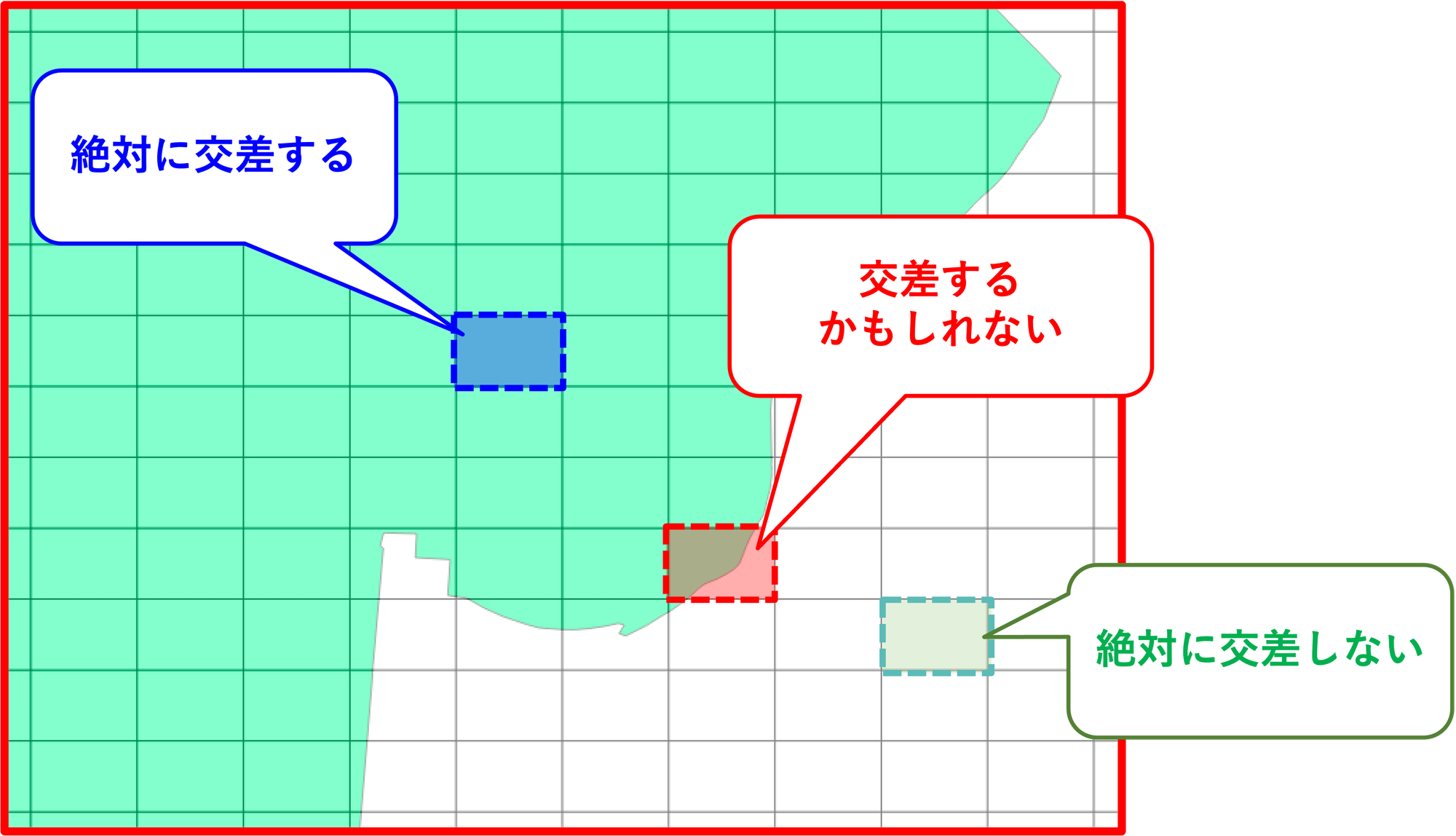
この3パターンのエリアのうち、ポリゴンと交差するかもしれないものだけ、Point-In-Polygonの処理を実施することで計算量の大幅な削減を実現できます。また、ポリゴンそのものもエリアの範囲で切り出したものとすることができるため、頂点数を大幅に削減できます。その結果、Point-In-Polygonの処理そのものも軽量化されます。
エリア分割単位
『Mobility:dev』で発表した内容では、他にも細かな工夫を行っていますが、基本コンセプトはエリア分割による枝刈りで、この当時はこのエリア分割の単位として地域メッシュを利用していました。
地域メッシュ
地域メッシュとは、統計に利用するために、緯度・経度に基づいて地域を隙間なく網の目(メッシュ)の区域に分けたもので、メッシュを識別するためのコードを地域メッシュコードと言います。
地域メッシュの詳細な説明をすると長くなりますので、総務省統計局のWebページに任せますが、地域メッシュのメリットは地域メッシュコードによる階層構造のわかり易さです。
地域メッシュコードは、シンプルな数字文字列として表現されるため、ヒューマンリーダブルで文字列処理にも相性が良いと言えます。一方で、特定の緯度・経度に対応する地域メッシュコードの算出には少なくない演算が必要になります(複雑ではありませんが、単純に計算量が多くなる)。
例えば、緯度経度を8分の1地域メッシュコードに変換する処理をGo言語で記述すると以下のようになります。
func genJISMesh(latitude, longitude float64) string {
hi1 := math.Floor(latitude * 1.5)
lo1 := math.Floor(longitude - 100.0)
lat1 := latitude - hi1/1.5
lon1 := longitude - 100 - lo1
hi2 := math.Floor(lat1 * 12.0)
lo2 := math.Floor(lon1 * 8.0)
lat2 := lat1 - hi2/12.0
lon2 := lon1 - lo2/8.0
hi3 := math.Floor(lat2 * 120.0)
lo3 := math.Floor(lon2 * 80.0)
lat3 := lat2 - hi3/120.0
lon3 := lon2 - lo3/80.0
hi4 := math.Floor(lat3 * 240.0)
lo4 := math.Floor(lon3 * 160.0)
lat4 := lat3 - hi4/240.0
lon4 := lon3 - lo4/160.0
hi5 := math.Floor(lat4 * 480.0)
lo5 := math.Floor(lon4 * 320.0)
lat5 := lat4 - hi5/480.0
lon5 := lon4 - lo5/320.0
hi6 := math.Floor(lat5 * 960.0)
lo6 := math.Floor(lon5 * 640.0)
mesh1 := hi1*100.0 + lo1
mesh2 := mesh1*100.0 + hi2*10.0 + lo2
mesh3 := mesh2*100.0 + hi3*10.0 + lo3
mesh4 := mesh3*10.0 + hi4*2.0 + lo4 + 1
mesh5 := mesh4*10.0 + hi5*2.0 + lo5 + 1
mesh6 := mesh5*10.0 + hi6*2.0 + lo6 + 1
return fmt.Sprintf("%011d", uint64(mesh6))
}見てわかる通り、計算量が多いですね。そして、個人的に気になるのが、最後に文字列化している処理です。地域メッシュコードがそもそも数字文字列なので、fmt.Sprintf()関数を使って文字列化しているのですが、この手の文字列変換処理は大抵処理負荷が高くなります。仮に、文字列ではなく uint64 などの符号なし整数で表現したとしても、地域メッシュコードを求めるまでの計算量はかなり多いと言えます。
あるタクシー車輌が位置する緯度経度の地域メッシュコードを算出するためには、上のような計算を行うことになるわけです。処理負荷が高くなると書きましたが、絶対的な計算量としてはそれほどでもないのですが、地域メッシュコードを算出する処理の実行回数が多くなると無視できなくなります。
より最適なエリア分割のために、Z階数曲線を表現するために利用されるモートン符号などと呼ばれる表現手法を活用しました。あまり馴染みのない言葉だとは思いますが、実はゲーム開発ではよく使われるもので、2次元空間だけでなく3次元空間を量子化して表現する際に利用したりします。
分割した空間を特定するためのキーとしてモートン符号を用いることで、地域メッシュコードを使うよりも効率的な処理に置き換えることができました。この空間分割キーをモートンキー(MortonKey)と表記し、以下詳細を説明します。
MortonKey
MortonKeyの考え方は、Go Conference 2021 Autumn で私が発表したセッションで説明した四分木(Quadtree)のノードIDそのものです。MortonKeyは仕組み的に2次元でも3次元でも対応可能で、量子化された複数の値を1つの数値として表現出来ます。
地域メッシュもMortonKeyと同様に緯度経度の座標値を量子化して特定範囲(メッシュ)毎にグルーピングする方法ですが、その表現方法がヒューマンリーダブルな形になっているというだけです。GeoHashやQuadKeyなども同様の考え方で表現方法が違うだけです。
基本的な考え方は同じでも最後の表現方法の違いによってMortonKeyは計算量を大幅に削減することができるという特徴があります。
例えば、Go言語でMortonKeyを表現すると以下のようになります。
// MortonKey
type MortonKey struct {
Key uint64
}
func part1by1(n uint64) uint64 {
// 32bit値が入ったuint64のビット配列を以下ののように1bit置きの配置に変換します
// n = --------------------------------nnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnn
// n = ----------------nnnnnnnnnnnnnnnn----------------nnnnnnnnnnnnnnnn
// n = --------nnnnnnnn--------nnnnnnnn--------nnnnnnnn--------nnnnnnnn
// n = ----nnnn----nnnn----nnnn----nnnn----nnnn----nnnn----nnnn----nnnn
// n = --nn--nn--nn--nn--nn--nn--nn--nn--nn--nn--nn--nn--nn--nn--nn--nn
// n = -n-n-n-n-n-n-n-n-n-n-n-n-n-n-n-n-n-n-n-n-n-n-n-n-n-n-n-n-n-n-n-n
n = (n ^ (n << 16)) & 0x0000ffff0000ffff
n = (n ^ (n << 8)) & 0x00ff00ff00ff00ff
n = (n ^ (n << 4)) & 0x0f0f0f0f0f0f0f0f
n = (n ^ (n << 2)) & 0x3333333333333333
n = (n ^ (n << 1)) & 0x5555555555555555
return n
}
func NewMortonKey(x, y float64, quantizeBit uint8) MortonKey {
quantizeMax := float64(uint64(1) << quantizeBit)
quantizeCoef := float64(quantizeMax / 360.0)
quantizedX := uint64((x + 180.0) * quantizeCoef)
quantizedY := uint64((y + 90.0) * quantizeCoef)
key := (part1by1(quantizedY) << 1) | part1by1(quantizedX)
// quantizeBitは最大でも28というルールの下、Keyの上位8bitにquantizeBitの値を仕込む
return MortonKey{
Key: (uint64(quantizeBit) << 56) | key,
}
}上記のGo言語のコードを見ると一見計算量が多そうに思いますが、コンピュータにとって計算負荷の高い掛け算、割り算の回数が圧倒的に少なく、反対にコンピュータが高速に処理できるビット演算を多用していることがわかります。
このMortonKeyを使うことで節約できる計算量は微々たるものですが、MortonKeyの量子化ビット数を調整するだけでエリア分割単位を地域メッシュより細かくできるので、営業区域ポリゴンのPoint-In-Polygon処理などでは全体としての性能をかなり向上することが出来ます(もちろん、メモリ使用量とのトレードオフですが)。
実際の性能
以下に、Goのベンチマークを取った結果を示します。
goos: darwin
goarch: amd64
cpu: Intel(R) Core(TM) i9-9980HK CPU @ 2.40GHz
BenchmarkCollider-16 1827198 620.7 ns/op 0 B/op 0 allocs/op
BenchmarkMKCollider-16 4031845 296.3 ns/op 0 B/op 0 allocs/op
BenchmarkMortonKeyGen-16 144343474 7.856 ns/op 0 B/op 0 allocs/op
BenchmarkGetMeshcode6-16 29602747 35.07 ns/op 0 B/op 0 allocs/op
BenchmarkGetMeshcode6Str-16 6872527 173.2 ns/op 24 B/op 2 allocs/op各ベンチマークの説明をすると以下の通りです。
・BenchmarkCollider-16・・・8分の1地域メッシュで分割したPoint-In-Polygon処理 ・BenchmarkMKCollider-16・・・MortonKeyの量子化ビットを最大19ビットで分割したPoint-In-Polygon処理 ・BenchmarkMortonKeyGen-16・・・MortonKeyの生成処理 ・BenchmarkGetMeshcode6-16・・・8分の1地域メッシュコードの生成処理(uint64) ・BenchmarkGetMeshcode6Str-16・・・8分の1地域メッシュコードの生成処理(文字列)
ベンチマークの数字を見るとわかりますが、Point-In-Polygon処理で2倍以上高速化しています。このPoint-In−Polygonは特別区・武三交通圏のポリゴンを使っているためかなり複雑なポリゴンデータではありますが、もともとの地域メッシュでの分割方式でもかなり高速に動作するものですが、そこから更に高速化しています。計算量の観点では、タクシーの注文処理に関するGIS処理ではこのPoint-In-Polygon処理が大半なので、全体性能としてもかなり向上できたことになります。
参考までに、MortonKey生成と地域メッシュコード生成処理だけのベンチマークも記載していますが、計算量が明確に違うことがわかると思います(単体の処理時間は微々たるものですが)。
まとめ
今回ご紹介した手法を活用すると、計算負荷の主要部分の性能を2倍にすることが出来ました。タクシーアプリ『GO』では、Point-In-Polygonの計算を数万rps程度処理しています。効率の良いアルゴリズムを選択することはインフラコストを抑制するためにも重要なので、適宜こういった取り組みは続けていきたいと思います。
※記事中の特別区・武三交通圏のポリゴンデータは、政府統計の総合窓口(e-Stat)(https://www.e-stat.go.jp/)のデータを使用して作成しています
We're Hiring!
📢
Mobility Technologies ではともに働くエンジニアを募集しています。
興味のある方は 採用ページ も見ていただけると嬉しいです。
Twitter @mot_techtalk のフォローもよろしくお願いします!