

dbt と Dataform を比較して Dataform を利用することにしました
ChallengeWeekデータ基盤June 14, 2022
タクシーアプリ「GO」、法人向けサービス「GO BUSINESS」、タクシーデリバリーアプリ「GO Dine」の分析基盤を開発運用している伊田です。今回、dbt と Dataform を比較して Dataform を利用することにしましたので、導入経緯および Dataform の初期構築を紹介します。
※ 本記事の対象読者はELTツールを利用している方を対象にしています
これは MoT Engineer Challenge Week 2022 Spring の記事です。
はじめに
本記事では、まず、dbt および Dataform というツールについて簡単に説明させて頂き、次に現在データ分析チームが抱えている課題について取り上げます。その後、2つのツールについて検証した内容を紹介し、その結果、Dataform の導入に至った経緯を説明します。また、最後に Dataform の初期構築で工夫した点についても紹介させて頂きます。
ツール導入に至るまでに様々な記事を参考にさせて頂きました。最初に謝辞を述べさせて頂きますとともに、参考にしたサイトは本記事の最後に一覧として記載させて頂いています。
※ 検証および初期構築は千田と伊田で実施しました
※ 検証は Engineer Challenge Week を利用して実施しました
dbt / Dataform とは
dbt, Dataform という2つの製品は、ELTのうち、Transform をするためのツールです。つまり、分析基盤にデータが格納された後に、SQLを発行してデータの加工処理をするためのツールで、加えて null チェックや unique チェックなどのテスト、ドキュメンテーション、データリネージ、データパイプラインの実行・スケジューリング等の管理もすることができます。
dbt
- 公式サイト
- SaaS版とCLI版(OSS)があります
- SaaS版は3つのプランがあります
- Free: 個人の検証目的の場合は無料で使えます
- Team: チームで開発する場合は1人あたり $50 / Month 掛かります
- Enterprise: SSO や Custom SLAs など、より高度な機能が提供されます
Dataform
前提
- 弊社の分析基盤は GCP BigQuery です。よって、以降の検証は BigQuery に関してのものです
- BIツールは Looker を利用しています
- 以前から Cloud Composer (Airflow) を利用したワークフローが稼働しています
- データエンジニア、データアーキテクトとの人数対比で、データアナリストは約5倍程度在籍しています
課題
現在、分析チームには、データマートのリリース速度や品質に課題があります。
- データマートのリリース速度が遅い
- データエンジニアの人数が少ない
- エンジニアしかデータマートが作れない(Docker/Airflow の知識が必要)
- 品質が悪い
- テストをする仕組みがない(そこまで手が回っていない)
結果として、下記の事象が発生しています。
- 新規依頼から構築完了までに時間が掛かるので、アナリストが簡単に構築できる BigQuery スケジューリングクエリでデータマートを生成している
- 依存関係が定義できないので、巨大な SQL ができやすい
- Looker にデータマート代わりのビジネスロジックが入っている
- ダッシュボードの描画が遅く、Slack 配信時に負荷が掛かり失敗しやすい
- Looker の外側で、そのビジネスロジックが使えない
- 上流のデータが変わった時に気づけない(欠損やデータの期待値が違うなど)
- 利用者側からのアラートがあがって初めて気づくこともある
こうした課題への対応として諸々機能がそろっている dbt や Dataform の検討をしました
- データマートのリリース速度の改善
- 今すぐデータエンジニアやデータアーキテクトの人数を増やすことは難しいため、データアナリストでもデータマートが作れる状態にしたい
- データアナリストが触りやすいGUIツールを導入することが望ましい
- 品質の改善
- モニタリングをするために、テスト機能が必要になる
- テストをするために、テストがしやすい形にSQLを分割して書き直す必要がある
- 分割した結果、中間View/Tableが増えるため、依存関係を考慮したスケジューラーが必要になる
検証
検証内容
- 普及度: 将来性や困った時に解決しやすいか
- 利用コスト: 予算確保および横展開のしやすさ
- 学習コスト: ツール利用の敷居の低さ
- 機能比較: 課題に対して必要な機能がそろっているか
- 運用: 運用のしやすさ
検証結果
普及度
Google検索による結果が下記です
- dbt: 約 18,700,000 件
- dataform: 約 320,000 件
※ 2022/3/31 確認
利用コスト
- dbt:
- 1人あたり $50 / Month 最大40人まで
- 加えて、参照権限のみのユーザーが50人分付与される
- それ以上は Enterprise に移行する必要があると思われる
- Dataform: 無料
学習コスト
主観的なものとなりますが、基本的には SQL + dbt / Dataform のお作法に則る形であるので、データアナリストが触る部分としては、dbt も Dataform もそこまで学習コストは高くないと感じました。
一部コア部分の作り込みやCLI版については多少学習コストが必要だと思います。
機能比較
機能比較には、こちらのチュートリアルを参考に行いました。
※ 主要なものを取り上げており、すべての機能を網羅しているわけではありません
データモデル定義
- dbt: SQL と YAML で構成される。YAML にテスト、ドキュメントなどを記述する。Jinja やマクロを利用した柔軟な記述ができる。SQL に config を設定することで、個々の SQL の挙動を制御できる
- Dataform: SQLX として、SQL、テスト、ドキュメントを1ファイルに記述する。JavaScript を利用した柔軟な記述ができる。SQLX に config を設定することで、個々の SQL の挙動を制御できる
前処理、後処理
- dbt: pre-hook, post-hook を利用することで、クエリの前後に処理を挟むことができる
- Dataform: pre_operations, post_operations を利用することで、クエリの前後に処理を挟むことができる
データロード
- dbt: dbt プロジェクト内の csv ファイルをロードする。型などは csv ファイルから dbt が自動的に補完してくれる
- Dataform: 該当機能なし
ソース定義
- dbt:
- dbt の外側で作成されたテーブルについて、source を宣言することで SELECT文の中で参照できるようになる。SELECT文でテーブル名をベタ書きせずに、 {{ source('table_name') }} とするとデータリネージで表示されるようになる
- dbt source freshness コマンドでデータの鮮度チェックができる
- Dataform:
- Dataform の外側で作成されたテーブルについて、declaration を宣言することで SELECT文の中で参照できるようになる。SELECT文でテーブル名をベタ書きせずに、 {{ ref('table_name') }} とするとデータリネージで表示されるようになる
クエリの部品化
- dbt: ephemeral という機能を利用することで、SQL を部品化できる。さらに、Jinja や macro を利用して柔軟な書き方ができる
- Dataform: JavaScript を利用して、SQL を部品化できる
Viewの作成
- dbt: View を作成する。create or replace view が実行される
- Dataform: View を作成する。create or replace view が実行される
Tableの作成
- dbt: Table を作成する。create or replace table が実行される
- Dataform: Table を作成する。create or replace table が実行される
Tableの作成 incremental model
- dbt:
- Merge 文を実行することで増分・差分処理を実現する
- 初回実行時および、--full-refresh オプションをつけると create or replace table が実行される
unique_key の指定がない場合は Insert 処理
merge into dest
using (
select
.
.
.
from source
where
created_at > (select max(created_at) from dest)
) as source
on False
when not matched then insert
.
.
.unique_key の指定がある場合は Upsert 処理
merge into dest
using (
select
.
.
.
from source
where
created_at > (select max(created_at) from dest)
) as source
on dest.id = source.id
when matched then update set
.
.
.
when not matched then insert
.
.
.incremental_strategy で insert_overwrite を指定した場合は DELETE INSERT によるパーティション置換処理
-- 定義ファイル
-- 当日と前日分を取得する。柔軟にやる場合は macro を使う
{% set partitions_to_replace = [
'date(current_date)',
'date(date_sub(current_date, interval 1 day))'
] %}
{{
config(
materialized='incremental',
incremental_strategy = 'insert_overwrite',
unique_key='order_id',
partition_by={
'field': 'order_date',
'data_type': 'date'
},
partitions = partitions_to_replace
)
}}
select
id as order_id,
user_id as customer_id,
order_date,
status
from research_dbt.raw_orders
{% if is_incremental() %}
where order_date in ({{ partitions_to_replace | join(',') }})
{% endif %}merge into `myproject`.`research_dbt`.`stg_orders` as DBT_INTERNAL_DEST
using (
select
id as order_id,
user_id as customer_id,
order_date,
status
from research_dbt.raw_orders
where order_date in (date(current_date),date(date_sub(current_date, interval 1 day)))
) as DBT_INTERNAL_SOURCE
on FALSE
when not matched by source
and DBT_INTERNAL_DEST.order_date in (
date(current_date), date(date_sub(current_date, interval 1 day))
)
then delete
when not matched then insert
(`order_id`, `customer_id`, `order_date`, `status`)
values
(`order_id`, `customer_id`, `order_date`, `status`)- Dataform:
- Merge 文を実行することで増分・差分処理を実現する
- 初回実行時および、--full-refresh オプションをつけると create or replace table が実行される
uniqueKey の指定がない場合は Insert 処理
insert into dest
select ... from source
where created_at > (select max(created_at) from dest)unique_key の指定がある場合は Upsert 処理
merge dest T
using (
select
.
.
.
from source
where created_at > (select max(created_at) from dest)
) S
on T.id = S.id
when matched then update set
.
.
.
when not matched then
.
.
.updatePartitionFilter の指定がある場合は パーティションのプルーニングが行われる
-- 定義ファイル
-- 前日分以降を更新対象にする。柔軟にやる場合は pre_operations を使う
config {
type: "incremental",
uniqueKey: ["order_id"],
bigquery: {
partitionBy: "order_date",
updatePartitionFilter: "order_date > DATE(TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 DAY))"
}
}
select
id as order_id,
user_id as customer_id,
order_date,
status
from ${ref("raw_orders")}
where
order_date > DATE(TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 2 DAY))merge `myproject.research_dataform.stg_orders` T
using (
select
id as order_id,
user_id as customer_id,
order_date,
status
from `myproject.research_dbt.raw_orders`
where
order_date > DATE(TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 2 DAY))
) S
on T.order_id = S.order_id
and T.order_date > DATE(TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 2 DAY))
when matched then
update set `order_id` = S.order_id,`customer_id` = S.customer_id,`order_date` = S.order_date,`status` = S.status
when not matched then
insert (`order_id`,`customer_id`,`order_date`,`status`) values (`order_id`,`customer_id`,`order_date`,`status`)テスト
- dbt:
- unique: column_nameがユニークな値になっているか
- not_null: column_nameがnullを含んでいないか
- accepted_values: column_nameが決められた値になっているか
- relationships: テーブルのキーがテスト対象のテーブルのキーと結合できるか
- 任意のテストを書きたい場合はマクロを書くか、 dbt_utils にテスト用のマクロが用意されているので利用する
- Dataform:
- uniqueKey : column_nameがユニークな値になっているか
- nonNull : column_nameがnullを含んでいないか
- rowConditions: 各行の条件が true になることを期待する SQL 式を記述する
- 任意のアサーションを書きたい場合は assertion を宣言して、SELECT文の結果が0件となる SQL 式を記述する
ドキュメント、データリネージ
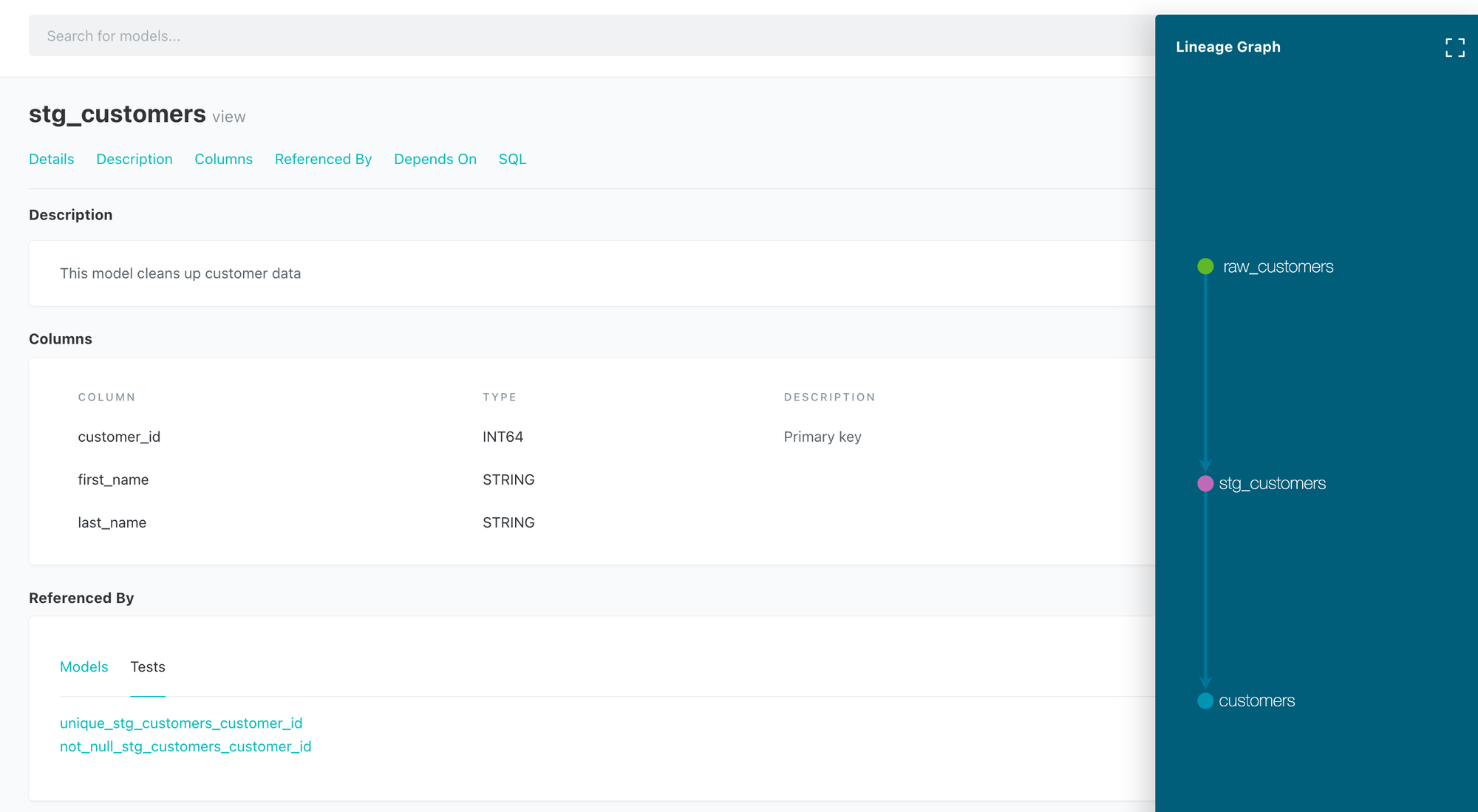
- dbt: テーブルのドキュメントを作成することができる
- SaaS版、CLI版ともにドキュメント、データリネージが確認できる
- テーブルの Description
- 各カラムの Description
- テスト内容 (自動的に参照先が作られる)
- SQL に source / ref 関数を使用することで依存関係が定義され、データリネージが可視化できる
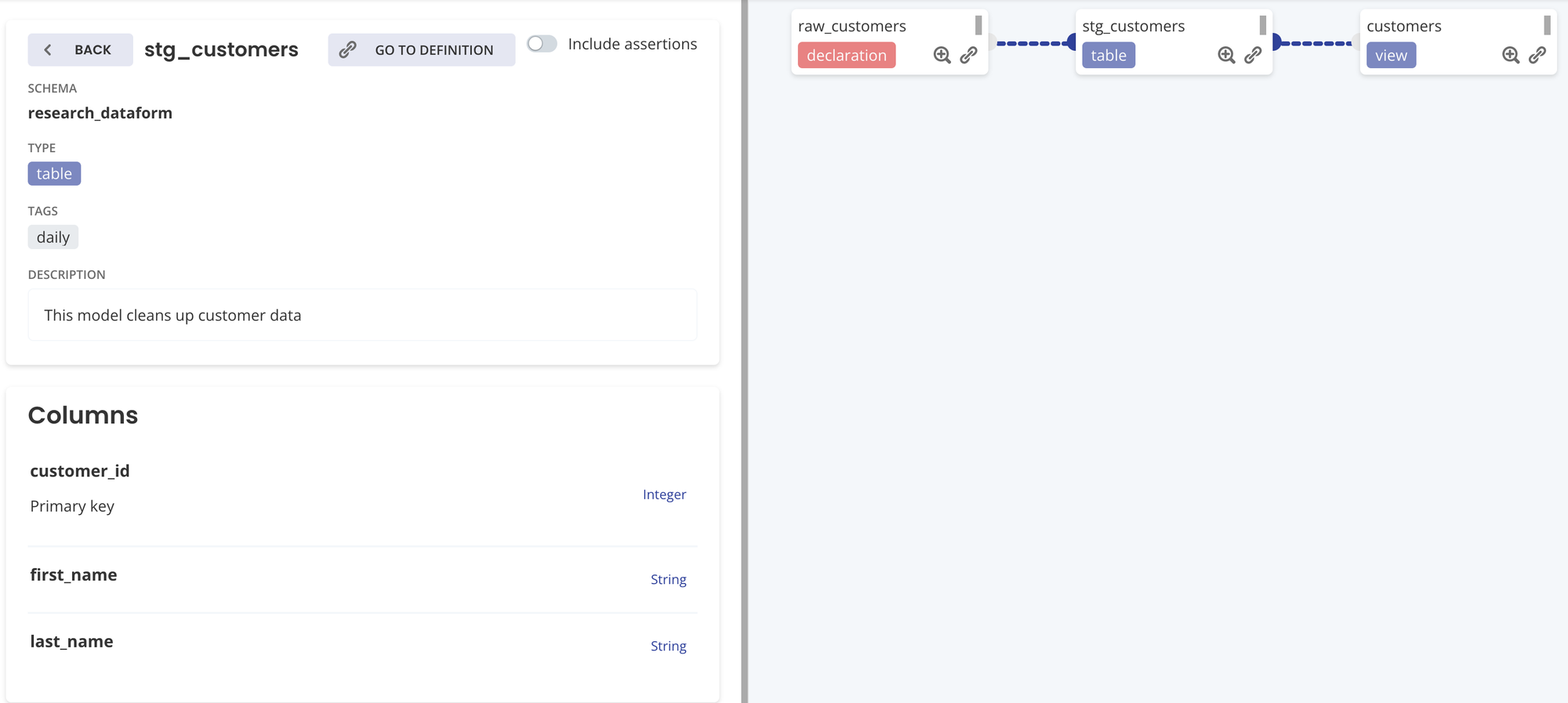
- Dataform: テーブルのドキュメントを作成することができる
- SaaS版のみドキュメント、データリネージが確認できる
- テーブルの Description
- 各カラムの Description
- テスト内容 (自動的に参照先が作られる)
- SQL に ref 関数を使用することで依存関係が定義され、データリネージが可視化できる
スナップショット
- dbt:
- 初回は全レコードのスナップショットを作成する
- 2回目以降は、strategy に従って対象レコードのみスナップショットを作成する
- strategy
- strategy='timestamp' の場合、unique_key, timestamp 列 を参照して変更があればスナップショットを取得する
- strategy='check_cols' の場合、unique_key をもとに、対象となるカラムに変更があればスナップショットを取得する
- 画像は id, user_id, order_date, status までが対象テーブルのスキーマで、以降は dbt が付与した情報

- Dataform:
- incremental model としてスナップショットを取得する
- updated_at を参照して、SELECT句に CURRENT_TIMESTAMP() を付与して差分バックアップを取っていくイメージ
ジョブ実行
- dbt: ref 関数を使用することで依存関係が定義され、ジョブ実行時に依存関係を考慮して順次実行してくれる。指定したタグに紐付いたモデルのみ実行等もできる
- Dataform: ref 関数を使用することで依存関係が定義され、ジョブ実行時に依存関係を考慮して順次実行してくれる。指定したタグに紐付いたモデルのみ実行等もできる
運用
スケジューラー
- dbt: SaaS版のみ。指定したタグに紐付いたモデルのみ実行等もできる
- Dataform: SaaS版のみ。指定したタグに紐付いたモデルのみ実行等もできる
リカバリ / backfill
- dbt: SaaS版、CLI版ともに変数を指定して実行できる
- Dataform: SaaS版は変数を指定して実行できない。CLI版は変数を指定して実行できる
Slack通知
- dbt: SaaS版はSlack通知の設定ができる
- Dataform: SaaS版はSlack通知の設定ができる
導入判断
結論
結論としては、Dataform を選択することにしました。不確定要素が多い中では、Dataform のほうがスモールスタートしやすいと判断しました。
理由
- 課題に対しては dbt / Dataform ともにクリア
- アナリストが自由にデータマートを作るためにGUIが必要である
- テスト機能が必要である
- 導入までのハードルは Dataform が低い
- アナリストを巻き込んだ枠組みがうまくいくか不確定であるため、そうした中で予算確保の調整やライセンス管理はやりたくないため、無料の Dataform の方が有利である
- Dataform は今後 GCP に統合されることからセキュリティ面で会社許諾を得やすい
- Google の担当者の方から「現在、Dataform (SasS版)を利用するためにサービスアカウントキーの発行が必要になりますが、今後は IAM に統合されます」という情報を確認しています
今後の展望として
結果が出て機能が物足りない場合は、dbt への移行も検討したいと思います。基本的な思想は同じなので移行は難しくなく、実績があれば予算も取りやすいと考えています。
今回は Dataform を選択しましたが、dbt と Dataform、この2つは素晴らしい製品だと思います。特に気に入っているのは ref 関数です。この関数があることでデータリネージとして可視化ができ、調査時に依存関係を簡単に把握することができます。また、ジョブ実行時も依存関係を考慮して自動的に順次実行してくれるのが嬉しいと感じています。
初期構築
ここからは Dataform 導入にあたり初期構築をどのようにしたか紹介したいと思います。
※ ここからはチュートリアル程度の知識がある前提で記述しています
SaaS版とCLI版の併用
下記の理由からSaaS版とCLI版を併用することにしました。
- データアナリスト:スケジューリングクエリや Looker に組み込まれているロジックを Dataform 側に寄せる。スケジューラーの機能もあることからデータアナリストはSaaS版で完結することができる
- データエンジニア、データアーキテクト:元々データ連携処理であったり、データマートの生成を Airflow 上で実行していることから、Dataform の処理を Airflow で設定した日付注入して実行したい。リカバリや backfill の時に変数指定ができるCLI版を使いたい
運用の流れとしては下記を想定しています。
- データアナリストがデータアーキテクトのサポートの元、SaaS版でデータマートを作成する
- 単発の場合はSaaS版で完結し、本格運用に乗る場合はデータエンジニアに運用を引き継いてAirflow から実行できるように整備する
GitHub連携
コードは GitHub と連携しています。
環境
本番環境と開発環境は、GCPプロジェクトでわけています(データセット配下は同じ構成)。
- 本番: prod-project
- 開発: dev-project
environments.json
デフォルトは開発環境に向くようにして、master にマージされて初めて本番環境に処理が向くようにしています。
{
"environments": [
{
"name": "development",
"configOverride": {},
"gitRef": "develop"
},
{
"name": "production",
"configOverride": {
"defaultDatabase": "prod-project"
},
"gitRef": "master"
}
]
}ディレクトリ構成
definitions 配下(SQL置き場)は ベストプラクティスに則ってディレクトリを切りました。
- reporting: データマート層
- staging: データウェアハウス層
- sources: データレイク層
- playground: Dataform の機能テスト用
また、SaaS版で生成された初期ファイルに加えて、CLI版の利用や各種スクリプトを tools 配下に切っています。
.
├── definitions
│ ├── playground
│ ├── reporting
│ ├── sources
│ └── staging
├── includes
│ └── date_config.js
├── dataform.json
├── dataform_prod.json
├── environments.json
├── package-lock.json
├── package.json
└── tools
├── cli
└── scriptsファイルの命名
テーブル名.sqlx としています。
例えば、データマートにテーブルを作る場合は下記となります。
- definitions
- reporting
- dataset_id
- table_name.sqlx
- dataset_id
- reporting
スキーマの指定、タグの指定
- Dataform ではスキーマを省略して書くことができますが、BigQueryでは、別データセット同一テーブル名が存在する場合があるので、Dataform が解釈できるようにスキーマを必ず指定します。スキーマの指定は config と ref 関数で指定します。
- データパイプラインをスケジューリングして動かすために、一緒に処理が動く単位で同一のタグ付けをします (SaaS版で動かす場合でも、Airflow で動かす場合でもタグ付けします)。
dataset_id.table_name の場合
config {
type: "incremental",
tags: ["dataform_test_dag_v1"],
schema: "dataset_id",
uniqueKey: ["id"],
bigquery: {
partitionBy: "DATE(ts)",
updatePartitionFilter: "ts >= raw_start_ts"
}
}
SELECT
.
.
.
FROM ${ref("ref_dataset_id", "ref_table_name")}動的な日付指定
SaaS版、CLI版ともに動的な日付を指定できるような JavaScript を作成しました。
まず、dataform.json に下記の通り変数を定義しています。
- targetStartTs: 対象期間いつから
- targetEndTs: 対象期間いつまで
- shouldOverrideVars: この変数が true のときに、targetStartTs、targetEndTs の変数を使って上書きする
dataform.json
{
"warehouse": "bigquery",
"defaultSchema": "dataform",
"assertionSchema": "dataform_assertions",
"defaultDatabase": "dev-project",
"vars": {
"shouldOverrideVars": "false",
"targetStartTs": "2022-04-01 09:00:00+9",
"targetEndTs": "2022-04-01 10:00:00+9"
}
}includes/date_config.js
最終的に生成する日付は4つです。
- start_ts: 対象期間いつから
- end_ts: 対象期間いつまで
- raw_start_ts: start_ts からマージンを取ったタイムスタンプ
- raw_end_ts: end_ts からマージンを取ったタイムスタンプ
日付を4つ定義しているのは、処理対象のテーブルにはストリーミングインサートで取り込み時間パーティション分割テーブルに挿入されたデータがあり、そのようなテーブルに対しては、_PARTITIONTIME に raw_start_ts と raw_end_ts を使って一時フィルタリングを行い、最終的に created_at のような実際に処理対象としたいタイムスタンプに start_ts と end_ts を使って絞り込むためです。
SaaS版で実行する時はshouldOverrideVars は必ず false です。
CLI版で実行するときは、shouldOverrideVarsはtrue を指定して、targetStartTs と targetEndTs に任意の期間を指定します。
date_config.js
function getStartTs(unit, start_ago) {
if (`${dataform.projectConfig.vars.shouldOverrideVars}` == "true") {
return `TIMESTAMP('${dataform.projectConfig.vars.targetStartTs}')`;
} else {
return `TIMESTAMP_TRUNC(TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL ${start_ago} ${unit}), HOUR)`;
}
}
function getEndTs(unit, end_ago) {
if (`${dataform.projectConfig.vars.shouldOverrideVars}` == "true") {
return `TIMESTAMP('${dataform.projectConfig.vars.targetEndTs}')`;
} else {
return `TIMESTAMP_TRUNC(TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL ${end_ago} ${unit}), HOUR)`;
}
}
function getRawStartTs(unit, start_ago, start_margin) {
return `TIMESTAMP_SUB(${getStartTs(unit, start_ago)}, INTERVAL ${start_margin} ${unit})`
}
function getRawEndTs(unit, end_ago, end_margin) {
return `TIMESTAMP_ADD(${getEndTs(unit, end_ago)}, INTERVAL ${end_margin} ${unit})`
}
/*
BigQuery Scripting
*/
function createTemporaryFunctionGetHourUnitTs(start_ago=1, end_ago=0, start_margin=0, end_margin=0) {
return `"""
create temporary function getHourUnitTs(ts STRING) AS (
CASE ts
WHEN 'raw_start_ts' THEN ${getRawStartTs('HOUR', start_ago, start_margin)}
WHEN 'raw_end_ts' THEN ${getRawEndTs('HOUR', end_ago, end_margin)}
WHEN 'start_ts' THEN ${getStartTs('HOUR', start_ago)}
WHEN 'end_ts' THEN ${getEndTs('HOUR', end_ago)}
END
);
"""`
}
function createTemporaryFunctionGetDayUnitTs(start_ago=1, end_ago=0, start_margin=0, end_margin=0) {
return `"""
create temporary function getDayUnitTs(ts STRING) AS (
CASE ts
WHEN 'raw_start_ts' THEN ${getRawStartTs('DAY', start_ago, start_margin)}
WHEN 'raw_end_ts' THEN ${getRawEndTs('DAY', end_ago, end_margin)}
WHEN 'start_ts' THEN ${getStartTs('DAY', start_ago)}
WHEN 'end_ts' THEN ${getEndTs('DAY', end_ago)}
END
);
"""`
}
module.exports = {
createTemporaryFunctionGetHourUnitTs,
createTemporaryFunctionGetDayUnitTs
};使い方としては下記です。
createTemporaryFunctionGetHourUnitTs
引数(=デフォルト値)
- start_ago=1
- start_ts がスケジュール実行時間の何時間前か
- end_ago=0
- end_ts がスケジュール実行時間の何時間前か
- start_margin=0
- raw_start_ts が start_ts の何時間前か
- end_margin=0
- raw_end_ts が end_ts の何時間後か
pre_operations 内で、EXECUTE IMMEDIATE FORMAT を実行することで、create temporary function を実行し、日付を取得できるようにしています。
-- createTemporaryFunctionGetHourUnitTs
pre_operations {
EXECUTE IMMEDIATE FORMAT(${date_config.createTemporaryFunctionGetHourUnitTs(
/* start_ago = */ 1,
/* end_ago = */ 0,
/* start_margin = */ 24,
/* end_margin = */ 24)});
}
SELECT
.
.
.
FROM $ref("dataset_id", "table_name")
WHERE
_PARTIONTIME >= getHourUnitTs('raw_start_ts')
AND _PARTIONTIME < getHourUnitTs('raw_end_ts')
AND created_at >= getHourUnitTs('start_ts')
AND created_at < getHourUnitTs('end_ts')2022/5/2 10:10 (JST) に実行した場合、
- start_ts: 2022-05-02 00:00:00 UTC
- end_ts: 2022-05-02 01:00:00 UTC
- raw_start_ts: 2022-05-01 00:00:00 UTC
- raw_end_ts: 2022-05-03 01:00:00 UTC
となります。
その他ツール類
ここからは Dataform 導入にあたり整備したツール類を紹介します。
Docker関連
tools/cli 配下は下記のようになっています。
tools/cli
├── Dockerfile
├── README.md
├── compiled
├── compiled_json_analyzer.js
├── deploy.sh
├── df-credentials.json
├── df-credentials_prod.json
├── docker-compose.yaml
├── docker-compose_prod.yaml
└── settings.json2種類あるファイルは、本番環境と開発環境用で無印が開発環境用です。docker image は本番用と開発用で切り分けています。
Dockerfile
_env=”_prod” が渡されると本番用です。
FROM node:17-buster-slim
ARG _env=""
# 基本的に依存するものはないのでコンテナ内で使う可能性があるものを追記する
RUN apt-get update \
&& apt-get dist-upgrade -y \
&& apt-get install -y --no-install-recommends \
vim \
jq \
&& apt-get clean \
&& rm -rf \
/var/lib/apt/lists/* \
/tmp/* \
/var/tmp/*
WORKDIR /usr/app/dataform
RUN npm i -g @dataform/cli@1.21.1
# dataform cli 使用時の設定
COPY tools/cli/settings.json /root/.dataform/
# OAuth 認証のため接続先のプロジェクトのみが記載されている
COPY tools/cli/df-credentials${_env}.json /usr/app/dataform/.df-credentials.json
# 資材
COPY definitions /usr/app/dataform/definitions
COPY includes /usr/app/dataform/includes
COPY dataform${_env}.json /usr/app/dataform/dataform.json
COPY package.json /usr/app/dataform/
RUN dataform install .
ENTRYPOINT tail -f /dev/nullsetting.json
dataform init で生成されるファイルです。
{
"allowAnonymousAnalytics": true,
"anonymousUserId": "your-anonymous-user-id"
}df-credentials.json
同じく、dataform init で生成されるファイルです。
{
"projectId": "dev-project",
"location": "US"
}docker-compose.yaml
version: "3"
services:
dataform:
# image: your-image-path
build:
context: ../../
dockerfile: tools/cli/Dockerfile
args:
_env: ""
container_name: dev
volumes:
- ~/.config/gcloud:/root/.config/gcloud
- ../../definitions:/usr/app/dataform/definitions
- ../../includes:/usr/app/dataform/includes
# - ./compiled:/usr/app/dataform/compiled
# - ./compiled_json_analyzer.js:/usr/app/dataform/compiled_json_analyzer.jsこの docker image を Airflow の GKEPodOperator で呼び出して Dataform を実行しています。
実行コマンドは下記です。
- actions を指定すると、対象のテーブルと対象テーブルの assertion が実行されます。
- vars を指定すると、変数を指定できます。この例では、対象期間いつから、いつまでを指定しています。
- Airflow から日付を取得して変数として注入し、かつ上述の date_config.js と組み合わせることで任意の期間のデータを生成することができます。
dataform run \
--actions destination \
--vars=shouldOverrideVars=true,targetStartTs='YYYY-MM-DD hh:mi:ss+9',targetEndTs='YYYY-MM-DD hh:mi:ss+9'Airflow 用コード変換ツール
dbt のこちらの記事を参考に、Airflow の1タスク = Dataform の1テーブル生成処理としたかったのでツールを作りました。ただし、Airflow 上で DAG の解析に負荷を掛けることをしたくないため、Airflow 上で動的に作るのではなく、タスクの依存関係を考慮した Airflow 用のコードを出力するツールを用意しました。
dbt の manifest.json に相当するデータは下記のコマンドから出力できます。
dataform compile --json > manifest.jsonクエリ生成ツール
Dataform でコンパイルされたクエリをファイルとして生成したくて compiled_json_analyzer.js というツールを用意しました(dbt はコンパイル時にクエリが出力されます)。
docker コンテナ内で下記のコマンドを打つと、json ファイルを解析して SQL ファイルに変換してくれます。
dataform compile --json | node compiled_json_analyzer.jsdeclaration 用コード生成ツール
既存のテーブルを Dataform の declaration として取り込みたいので、BigQuery のデータセットを指定すると、データセット配下のテーブルを declaration ファイルとして出力するツールを用意しました。
おわりに
本記事では、dbt と Dataform を比較検討し、Dataform の導入に至った背景を説明しました。また、Dataform の初期構築のアイデアも紹介させて頂きました。
今後は Dataform を分析チーム内に浸透させ、当初の課題だったデータアナリストが気軽にデータパイプラインを作れない状況を減らし、野良スケジューリングクエリを Dataform に移行させることや、ビジネスロジックを Looker に作り込まないように是正をしていきたいと考えています。加えて、分析基盤のデータの品質向上に注力できる状態を作っていきたいと考えています。
この比較記事が皆様のご参考になれば幸いです。
参考
- dbtとDataformを比較し、dbtを使うことにした
- dbt Cloudで始めるデータパイプライン構築のdbt入門
- Airflowの処理の一部をdbtに移行しようとして断念した話
- タイミーのデータ基盤品質。これまでとこれから。(問題3: ETLパイプラインにおける加工処理の負債)
- データエンジニア界隈で話題のdbt(data build tool)のまとめ
- dbtを触ってみた感想
- [dbt] 作成するデータモデルに関するドキュメントを生成する
- Building a Scalable Analytics Architecture With Airflow and dbt
- Dataform を導入してみた話
- Data Engineering Study #13 - ELT・データモデリングツール特集回
We're Hiring!
📢
Mobility Technologies ではともに働くエンジニアを募集しています。
興味のある方は 採用ページ も見ていただけると嬉しいです。
データエンジニアは こちら から
Twitter @mot_techtalk のフォローもよろしくお願いします!