

CloudWatch LogsのログをBigQueryで分析できるようにする
AWSGCPBigQueryApril 23, 2021
次世代事業本部 データビジネス部 KUUグループ の田中です。
今回はシステムのログを分析をしやすくするためにAWSのCloudWatch LogsのログをGCPのBigQueryに転送する仕組みを構築し、BigQuery上で分析できるようにした話です。
はじめに
株式会社ゼンリンと共同開発中の本プロジェクト(ニュースリリース)では、複数のモジュールに分割して開発したアプリケーションをAWS上にサーバレスで構築し、システム全体がスケーラブルかつ機能ごとの拡張性が高くなるように設計・開発を進めています。
全体像は弊社の渡部が登壇したDeNA TechConn 2021の「ドライブレコーダの動画を使った道路情報の自動差分抽出」をご覧いただくと、より具体的にイメージしやすいかと思います。
BigQuery上でログを分析したい
システムは現在開発中ですが実データを用いた検証や短期運用が始まっており、各アプリケーションのログ出力も今後増えることが予想されています。
ログ詳細を見るだけであればCloudWatch Logsでも良いのですが、複数アプリケーションを横断した結果の確認や、大量にジョブを実行した際のエラー件数把握、エラーステータスやメッセージでの絞り込み、処理時間の算出などをおこなう目的でBigQueryを使うことにしました。
社内ではGCPベースのサービスが主流でもあり、DWH(データウェアハウス)としてBigQueryが選択されているケースは多いです。
今回選定した基準は「MoTの社内標準である」が主な理由ですが、類似サービスと比較してチーム内で話した理由としては以下が挙げられます。
- Redshiftはクラスタの運用が必要になるのと、インスタンス課金のためクエリ実行が高頻度でなければクエリ課金のBigQueryやAthenaの方がコストパフォーマンスが高い
- AthenaはBigQueryと比較して社内での利用実績が少ないのと、WebコンソールのUIが使いづらい印象がある
どうやってBigQueryへ転送するか
本プロジェクトでは、ログ出力元のアプリケーションがAWS LambdaもしくはAWS Batchになるケースが多いため、今回はCloudWatch LogsをソースとしてGCPのBigQueryに出力する形で検討を進めました。
まずはなるべくマネージドにして人手をかけず運用できることに主眼を置いた際の選択肢が、以下の2つです。
案1
👉
CloudWatch Logs → Subscription Filter → Amazon Kinesis Data Firehose → S3 → BigQuery Data Transfer Service → BigQuery
- 取り込み処理は最小で15分単位
- 汎用フォーマットでのログ出力ファイル(JSON)がS3に残る
案2
👉
CloudWatch Logs → Subscription Filter → Amazon Kinesis Data Streams → Lambda → BigQuery streaming insert → BigQuery
- 取り込みはほぼリアルタイム
- 汎用フォーマットでのログ出力ファイル(JSON)は残らない
各サービスの詳細は割愛しますが、今回はリアルタイム性は求めておらず、将来的にAWS内でS3に出力されたログ出力ファイルを再利用する可能性もあることから「案1」を選択しました。
AWS → GCPのシステム構成
案1を実現する構成を図に示したものが以下です。
ログ出力の翌日にBigQueryで見れるようにData Transfer Serviceのジョブを日次起動させています。
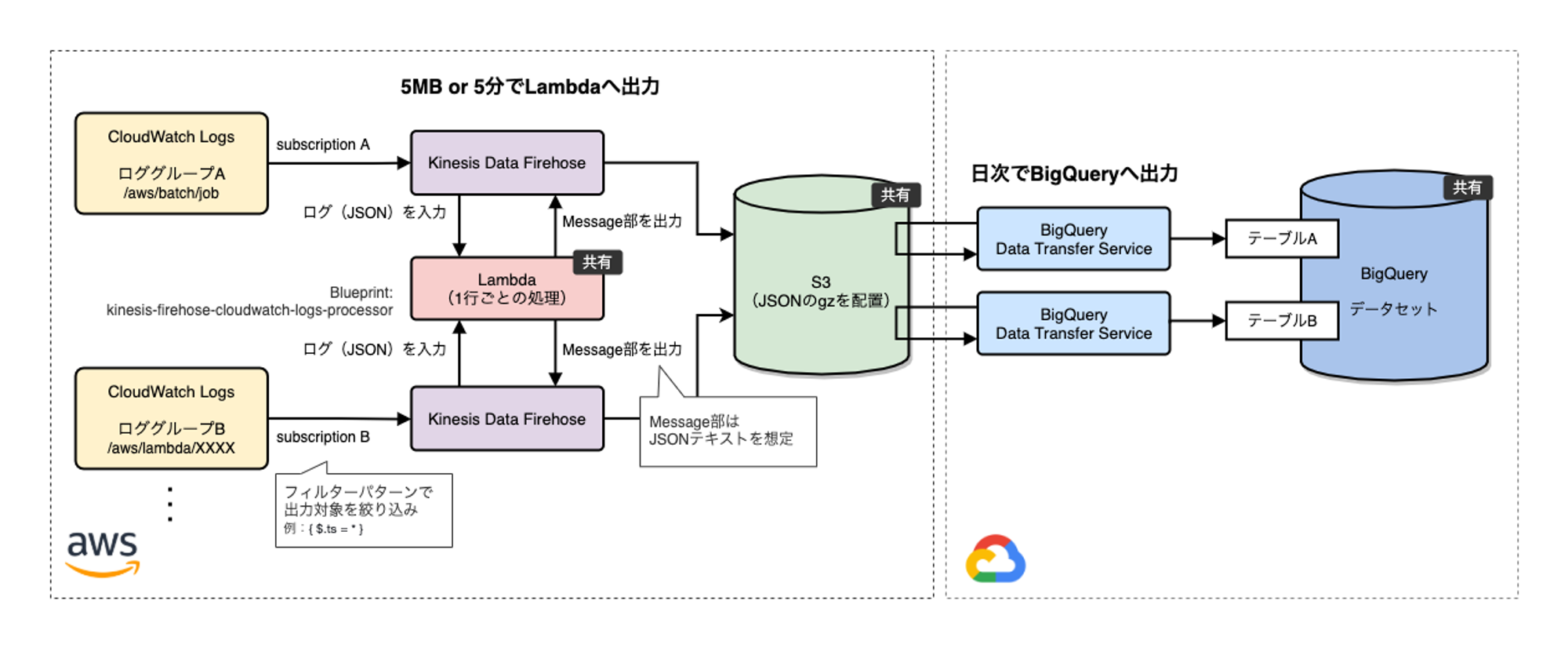
ロググループはA・B・・・と増えていく想定で、所定のフォーマットでCloudWatch Logsにログを出力できるアプリケーションであれば、どんなアプリケーションであっても対応可能にしています。入力となるロググループ1つが最終出力のBigQueryテーブル1つと対応します。
図で「共有」となっている箇所は、システム全体で共有の枠組みにすることで再利用しやすく利用者側が楽できる形で設計しました。
AWS側での作業(Subscription Filter、Kinesis Data Firehose)
各アプリケーションのCloudWatch Logsへのログ出力は改行区切りのJSONテキストを想定しています。
{
"ts":"2021-03-26T19:24:07.476+09:00",
"msg":"[app] trigger SQS message"
"level":"INFO"
"caller":"xxxxx/app.go:26",
}
{ ... }
{ ... }ロググループのSubscription Filterを使ってFirehoseでS3に送りますが、その際CloudWatch Logs出力のMessage部のJSONテキスト(アプリケーションが出力したログ部分)だけを抽出するためにLambdaを挟んでいます。
極力マネージドにするため、LambdaのBluePrintとして提供されている kinesis-firehose-cloudwatch-logs-processor を利用しました。
今回の場合1カラムを抽出したいだけなので、現在はできませんがFirehose設定等でLambdaを挟まずできるようになればもっと手軽な仕組みになると思っています。
一方で、BigQueryに入れる前にデータを加工したい場合にはこのLambdaで自由にゴニョゴニョすることができる利点もあります(後述の「ハマったポイント2」で少しだけいじることになったので、結果的には活用してます)。
GCP側での作業(BigQuery Data Transfer Service)
ここまでで、JSONテキストの羅列が各ロググループごとにS3に蓄積される状態になりました。
Lambdaを通すとCloudWatchLogsのログ(gzip)は展開されてしまいますが、AWS → GCPへのデータ転送は容量に応じて金額が上がるため、Firehoseの転送設定(S3 compression)にて改めてgzipで出力されるようにしておきます。
BigQueryはgzipのままで取り込みしてくれます。
あとは、BigQueryへの転送ですがここはData Transfer Serviceが設定した起動タイミングに従って、S3にデータを取りに来るようなイメージです。
BigQueryには予めログのJSONと対応したテーブル定義を用意しておきます。
[
{
"description": "出力日時",
"name": "ts",
"type": "timestamp",
"mode": "REQUIRED"
},
{
"description": "ログメッセージ",
"name": "msg",
"type": "string",
"mode": "REQUIRED"
},
{
"description": "ログレベル",
"name": "level",
"type": "string",
"mode": "REQUIRED"
},
{
"description": "呼び出し元",
"name": "caller",
"type": "string",
"mode": "NULLABLE"
}
]Data Transferの設定を定義すれば、CloudWatch LogsのログがBigQueryに取り込まれて分析可能になります。
BigQueryではスキャン料に応じて利用料がかかるため、最低限コスト抑止のためtimestamp型のtsカラムを必須としテーブル作成時に設定することで、日単位のログがパーティショニングされるようにしました。
これにより、日毎に検索すればスキャン量を抑えることができます。参照カラムの絞り込みや除外も有効です。
運用準備
今回このシステムはAWS側はCDK、GCP側は、構築時以外は触らない可能性が高いことから、初回設定やテーブル定義更新の際にMakefileからコマンドを叩く形で仕組み化しました。
CDKについてはボリュームが大きくなるため本記事では割愛しますが、GCP側の登録や更新は以下のような形でmakeコマンド化しています。
# BigQuery テーブル作成
.PHONY: create-bq-table
create-bq-table:
@echo create bq table... env=$(ENV) table=$(TABLE)
@cd $(BQ_DIR); $(BQ_CMD) mk -t \
--time_partitioning_type=DAY \
--time_partitioning_field=ts \
${BQ_DATASET}:${BQ_SCHEMA}.$(TABLE) \
./schema/$(TABLE).json
# S3 → BigQuery データ転送作成
.PHONY: create-bq-transfer
create-bq-transfer:
@echo create bq transfer... env=$(ENV) filter=$(FILTER) table=$(TABLE)
@cd $(BQ_DIR); $(BQ_CMD) mk --transfer_config \
--data_source=amazon_s3 \
--display_name="$(FILTER)" \
--project_id=XXXXX \
--target_dataset=XXXXX \
--schedule="every day XX:00" \
--params='{\
"destination_table_name_template":"$(TABLE)",\
"data_path":"s3://$(BUCKET)/$(FILTER)/XXXXX*",\
"access_key_id":"$(AWS_ACCESS_KEY)",\
"secret_access_key":"$AWS_SECRET_KEY)",\
"file_format":"JSON",\
"ignore_unknown_values":"true"\
}'
# BigQuery テーブル更新(カラム追加)
.PHONY: update-bq-table
update-bq-table:
@echo update bq table... env=$(ENV) table=$(TABLE)
@cd $(BQ_DIR); $(BQ_CMD) update \
${BQ_DATASET}:${BQ_SCHEMA}.$(TABLE) \
./schema/$(TABLE).jsonMakefileハマったポイント1(カラムのフォーマットエラー)
設計通りS3出力までは進んでいたのですが、bq loadであれば入るデータがData Transferを通すと不正扱いで入らない問題に直面し、くじけそうになりました。
Error while reading data, error message: JSON table encountered too many errors, giving up. Rows: 1; errors: 1. Please look into the errors[] collection for more details.; JobID: ...原因を調べていくと、timestampの形式で、 ISO 8601の基本形式である"2006-01-02T15:04:05.000+0900" だと取り込みエラー
"2006-01-02T15:04:05.000+09:00" だと取り込みOKという状況で、エラーメッセージからもなかなか気づけずフォーマットを変えて出力を試していたところ原因にたどり着き、解消しています。
こちらは2021年3月現在ではエラーとなりましたが、bq loadと挙動に差異がある状況なのでいずれGCP側で修正されるかもしれません。
ハマったポイント2(AWS Batchのログ出力が取り込めない)
仕組みを構築し、Lambdaから出力されたログは無事に取り込めたのですが、AWS Batchから出力されたログはBigQueryへの取り込みでエラーが発生しました。
すでにLambdaログでは仕組みが動いていたので、多少穏やかな気持ちで解決に臨めました。
エラー自体は「ハマったポイント1」と同じで、これだけだと詳細はわからず。
Error while reading data, error message: JSON table encountered too many errors, giving up. Rows: 1; errors: 1. Please look into the errors[] collection for more details.; JobID: ...調べていくと、Firehoseから出力されたS3のgzファイルの中身が改行なしのJSON羅列になっていることが原因とわかりました。
{ts: "2006-01-02T15:04:05.000+0900", msg: "...", ...}{ts: "2006-01-02T15:04:05.000+0900", msg: "...", ...}{ts: "2006-01-02T15:04:05.000+0900", msg: "...", ...}...BigQueryの取り込みは改行区切りJSONを期待しており、JSONテキスト毎の改行がないためフォーマットエラーになります。
LambdaのログはLoggerによりもともとメッセージ部分の末尾に改行が入っていたのですが、AWS Batchの出力では改行が入っておらず、また明示的に改行を入れても出力時には取り除かれてしまう状況でした(ここは深堀りはしていない)。
対策として、Firehoseの中間Lambdaでのgzファイル出力時に必ず改行区切りになるように調整して解決しています。
:
function transformLogEvent(logEvent) {
return Promise.resolve(`${logEvent.message.trim()}\n`);
}
:おわりに
今回はシステムの端っこの話をさせてもらいましたが、Mobility Technologiesではゼロからの技術検証やまだ世の中にないシステム開発にも日々チャレンジしています。 そのため、メインとなるアプリケーション開発だけでなく今回のような運用のための開発においても、フェイズや状況を見極めて自分たちで最適解を模索することが求められる刺激と学びの機会が多い現場です。
「移動で人を幸せに。」していくためにテクノロジーでモビリティ課題を解決することに興味をお持ちの方は、社内メンバーの様子がわかる公式noteや採用ページもぜひご覧ください。
👪 公式noteはこちら >>> https://now.mo-t.com/
🚪 採用ページはこちら >>> https://hrmos.co/pages/mo-t/jobs