

Cloud SQLからDatastoreにデータの保存先を変更した際のハマりどころと解決策
ServerSideGCPNovember 19, 2021
プッシュ通知関連のデータを制御するテーブルは1億レコードにも及ぶのですが、この巨大なテーブルによってDBのパフォーマンスが悪化する問題が発生していました。それらをどのように改善したのかについて解説します。
はじめに
バックエンドグループの青松です。タクシー配車アプリGOのサーバーサイドの開発を担当しています。
GOアプリは累計500万ダウンロードを突破し、日々ユーザー数や配車数も増加しています。それに加えて、様々な新規機能の開発や大規模なプロモーションも実施されています。
となると、特定のテーブルにおいてはレコード数が極端に増え、テーブルスキーマの変更に長時間を要したり、スキーマ変更時や大量にインサートするバッチ処理においてレプリケーション遅延の発生やDBのCPU負荷が上昇するといったリスクが発生したりすることがあります。
プッシュ通知関連のデータを制御するテーブルは、その主な例の一つでした。
このテーブルは1億レコードに及ぶほどのデータ量で、「プッシュ通知の送信」という用途から使用頻度も機能改修もそこそこ多いです。
チーム内にはこのテーブルをどうにか改善したいという思いがあり、Cloud SQLからDatastoreに移行するのはどうかという案が出ていました。
GOアプリにおけるプッシュ通知の流れ
もう少し、プッシュ通知関連テーブルの用途とライフサイクルについて話しておきます。
実際にPush通知を送信する際のオペレーションは以下のようになります。
1. まずは管理サイトからプッシュ通知の登録を行います。このときに登録するデータにはプッシュ通知を送信するユーザーのIDのリストや、同時に付与するクーポンなどのオプショナルな情報などが含まれます。
2. 定期的に実行されるcron処理で、上記の元データをUserID毎に生成されるプッシュ通知用のデータに分解します。ここで大量にデータをインサートすることになります。
3. また別のcron処理でCloud TasksにTaskが追加され、プッシュ通知が配信されたり、同時に登録されたクーポンなどをユーザーに付与したりといった処理が実行されます。
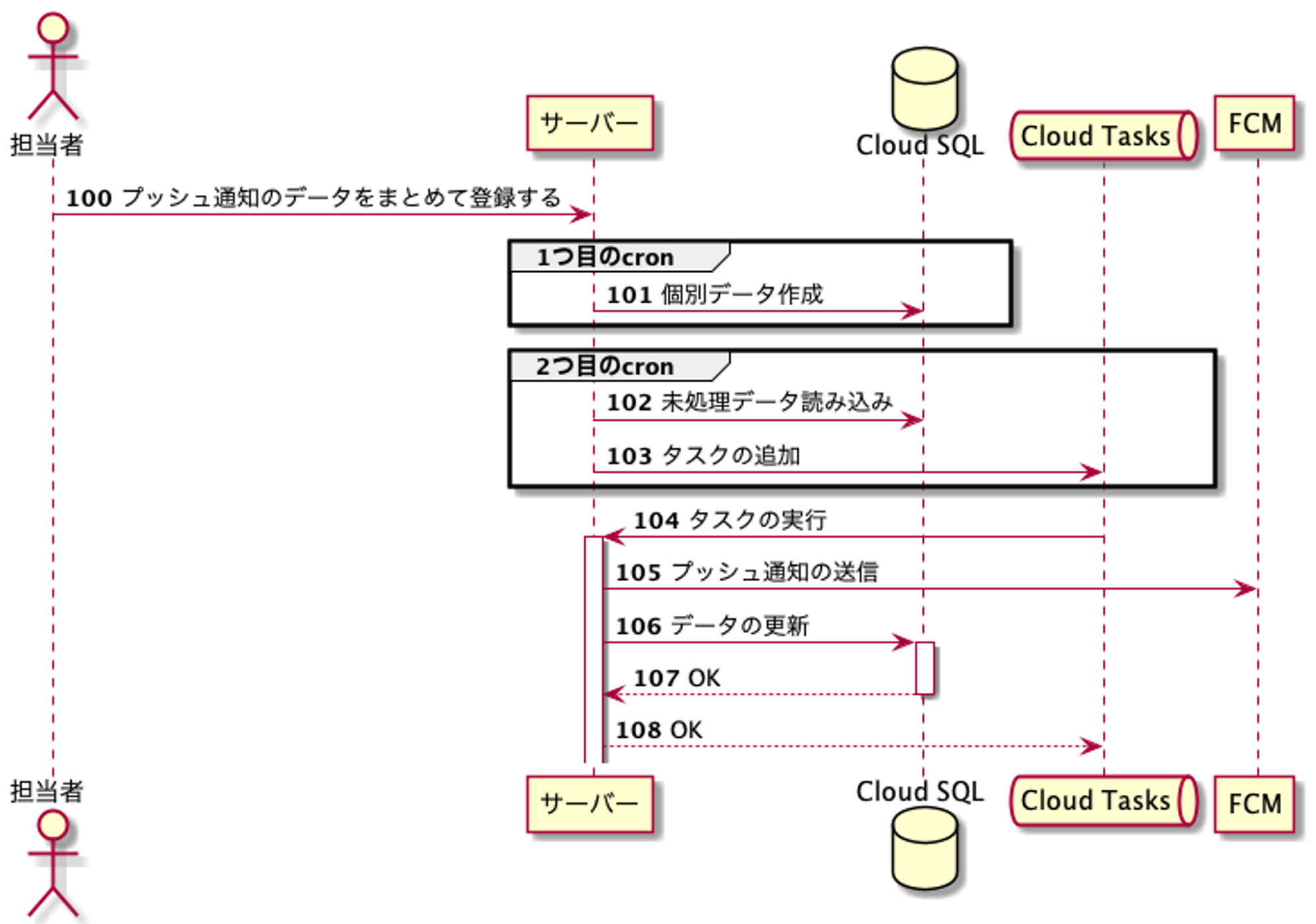
また、プッシュ通知には小〜中規模の配信と大規模の配信があります。
小〜中規模の配信とは、1件〜数万件 or 数十万件ほどのプッシュ通知の配信で、高頻度でこのような配信は実施され、クーポンなど他テーブルを参照する必要のある追加情報が伴うこともあります。
大規模の配信とは数百万件規模のプッシュ通知の配信で、頻度は高くなく、クーポンなどのほかテーブルを参照する必要のある追加情報が伴うことはありません。
DBの負荷が上がる問題については、主に大規模の配信において発生していたため、クーポンなどのデータをCloud SQLに残したままプッシュ通知のデータをDatastoreに移行しても、DBの負荷は減少するだろうという算段がありました。
巨大なテーブルが抱える問題点
大きなレコード数を持つテーブルがどのような問題を引き起こすのかについて、実際に起こった事象を見ていきます。
レプリケーション遅延
GOでは、マスターDBの負荷を軽減するために読み込み専用のリードレプリカが複数台走っています。
バッチ処理で大量にレコードが生成されるときや新規でカラムを追加するスキーマの適用時には、レプリケーション遅延が頻発していました。
これは、リードレプリカの性能がマスターDBの性能よりも悪いという状況から、SQLの実行速度に差が出てしまうという要因もありましたが、バッチ処理などで大きなトランザクションを処理する際には性能は関係なく遅延が発生してしまいます。
レプリケーション遅延はマスターDBとのデータの不整合を引き起こすためバグの原因になる可能性があり、できるだけ回避したい問題となります。
DBのCPU負荷の上昇
GOアプリの機能であるタクシーの配車という性質上、特定の時間帯にリクエストが増えたり、荒天の際にはリクエスト数が急増するという傾向があります。
そのようなタイミングでアプリケーションに何かバグが発生した場合、急激にDBに負荷がかかるという事象が起こり得ます。
cronによるバッチ処理やTaskQueueからのAPI呼び出しは、そのような状況下でも問答無用に大量のデータをインサートし続けるため、DBの負荷はより上昇します。
結果、APIサーバーのインスタンス数は上限まで張り付き、アプリからはレスポンスが返ってこなくなるという、最悪の事態が発生します。
cronによるバッチ処理を例に取ると、バッチ処理の実行中のDB書き込みオペレーション数は、バッチ処理が行われていないときの書き込みオペレーション数の約1.5倍ほどの量にまで昇っていました
拡張性に対する懸念
新規にカラムを追加するスキーマの適用の時間がかかってしまうことやレプリケーション遅延の危険性が常に付きまとう状況は、新規機能開発やリファクタ作業の際に安定性の観点からも精神的にも健全とは言えません。
「カラム追加しないといけない」から「カラム追加するだけで出来る」とポジティブに考えられるようになることは日々の業務において何気に重要なことです。
Cloud SQLとDatastore
GCPにはBigtableやDatastoreなどのNoSQLデータベースが用意されていますが、Cloud SQLからの移行に適しているものとしては、トランザクション機能が一番充実しているDatastoreがまず上がります。
では大規模なデータの保存先をDatastoreに変更するにはどのような制約があるのでしょうか、そしてどのようなメリットがあるでしょうか。
まずはCloud SQLとDatastoreについてざっくりとした比較をします。
(注意) 本文中にあるDatastoreは旧世代のDatastoreを指しており、DatastoreモードのFirestoreではありません。
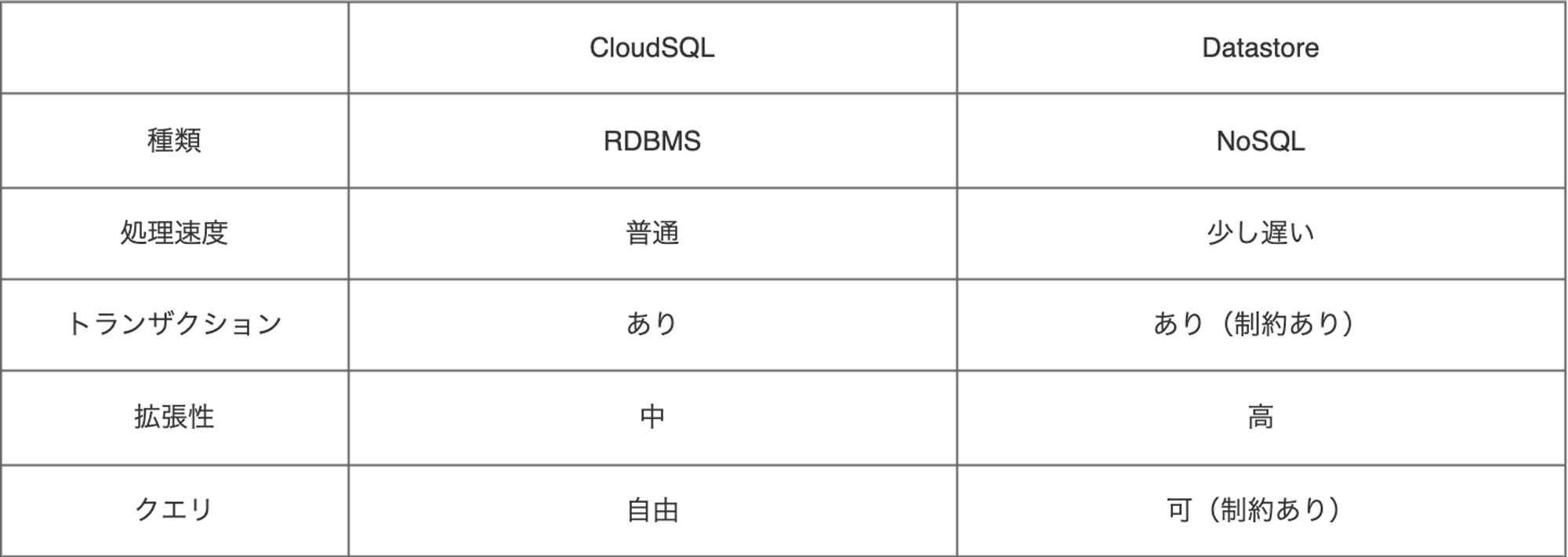
ポイントはいくつかあります。
処理速度
まず、NoSQLと聞いて、RDBMSよりも処理が高速になることを予想しましたが、Datastoreの場合は単純なKVSではないために、そこまで速いわけではないです。
Cloud SQLのスペックやデータの内容にもよると思いますが、今回のリファクタ作業においては処理速度は悪化しました。
具体的には、32vCPUで動いているCloud SQLをDatastoreに変更した場合、トランザクションを貼って1つのレコードを更新する処理の速度は40%程度にまで落ちています。
そのため、可能な箇所においては並行処理を行うように実装を変更する必要がありました。
また、ある条件を満たすエンティティ数をカウントするなど結果セットのサイズが大きくなるクエリは、100万エンティティほどあれば数十秒かかることもあります。(Cloud SQLであれば数百ミリ秒で終わります。)
トランザクション
Cloud SQLでは超巨大なトランザクションを走らせることに制限はありませんでしたが、Datastoreの場合は異なります。(制約 : https://cloud.google.com/datastore/docs/concepts/limits)
エンティティを新規に作成する場合にはトランザクション内で同時に500件までしかエンティティを作成できません。
またDatastoreモードのFirestoreを使用していない場合には、トランザクション内で25件のエンティティまでしか既存のエンティティを参照できないという制約も加わります。
これまでバッチ処理で一つのトランザクションで一気にインサートしていた実装箇所は、トランザクションを小分けにする必要がありました。
トランザクションを細かい単位に分けすぎると、トランザクションを貼る処理に時間がかかりすぎるため、ある程度大きな単位にバッチ処理を分割する必要がありました。
処理単位を分割したために、実行途中でサーバーが落ちた場合を考慮する必要が出てきます。
今回のケースでは、どのUserIDまでデータの登録が完了したのかをメモしておき、途中で止まっているバッチ処理は再開できる仕組みを追加開発する必要がありました。
クエリ
Datastoreでは複合indexは事前に登録しておいたものしか使用できず、登録していないindexでエンティティのフィルタや並べ替えを実行することはできません。
また、日時情報などのカーディナリティの低いカラムにインデックスを貼ると、ホットスポットが発生しインデックスの意味をなさずに特定のクエリがとても遅くなることもあります。
ユニーク制約
Cloud SQLでは特定のカラムにユニークインデックスを貼ることができましたが、Datastoreではそのような機能はありません。
ユニーク性を担保したい場合は愚直にデータの有無を確認してからデータの追加を行う等の工夫が必要になります。
負荷分散
Datastoreの制約を並べてきましたが、重い処理をDatastoreに移せるのはメインのDBの負荷を軽減させる目的で有効です。特に、
- 一時的で大量のデータ
- あまり他のテーブルと密結合していないデータ(もしくは冗長化してもよいもの)
という性質のデータはDatastore移行に向いていると思います。
また、Datastoreは分散アーキテクチャを使用した高いスケーラビリティを売りにしており、データ数が増えた際にも高いパフォーマンスを維持できます。
ただし、他のテーブルと密結合しているデータの場合は、2相コミットのような複雑な処理が必要になるので注意が必要です。
2相コミット
プッシュ通知の話に戻すと、クーポンの付与などを同時に行うパターンがあるため、これまではCloud SQLのみのトランザクションで済んでいたところを、Datastoreも同時にトランザクションを貼る必要が出ました。
こういった複数データベースを跨ぐトランザクション処理を実現する際には、2相コミットと呼ばれる手法が取られます。
2相コミットを実現するための仕組みとしては、XA Transactionというものがあり、これはプロトコルレベルで2相コミットを実現します。
つまり各々のトランザクションで、Commitの前にPrepareというオペレーションを行うことで、Commitの準備ができているどうかを事前に検知できます。
MySQLではXA Transactionに対応しているのを確認しましたが、Datastoreに関してはこのXA Transactionに関する記述はネット上で発見されていなかったために、対応していないのではないかと推測します。
そこで今回は2つのトランザクションに対しては愚直に順番にコミットを行うことにしました。
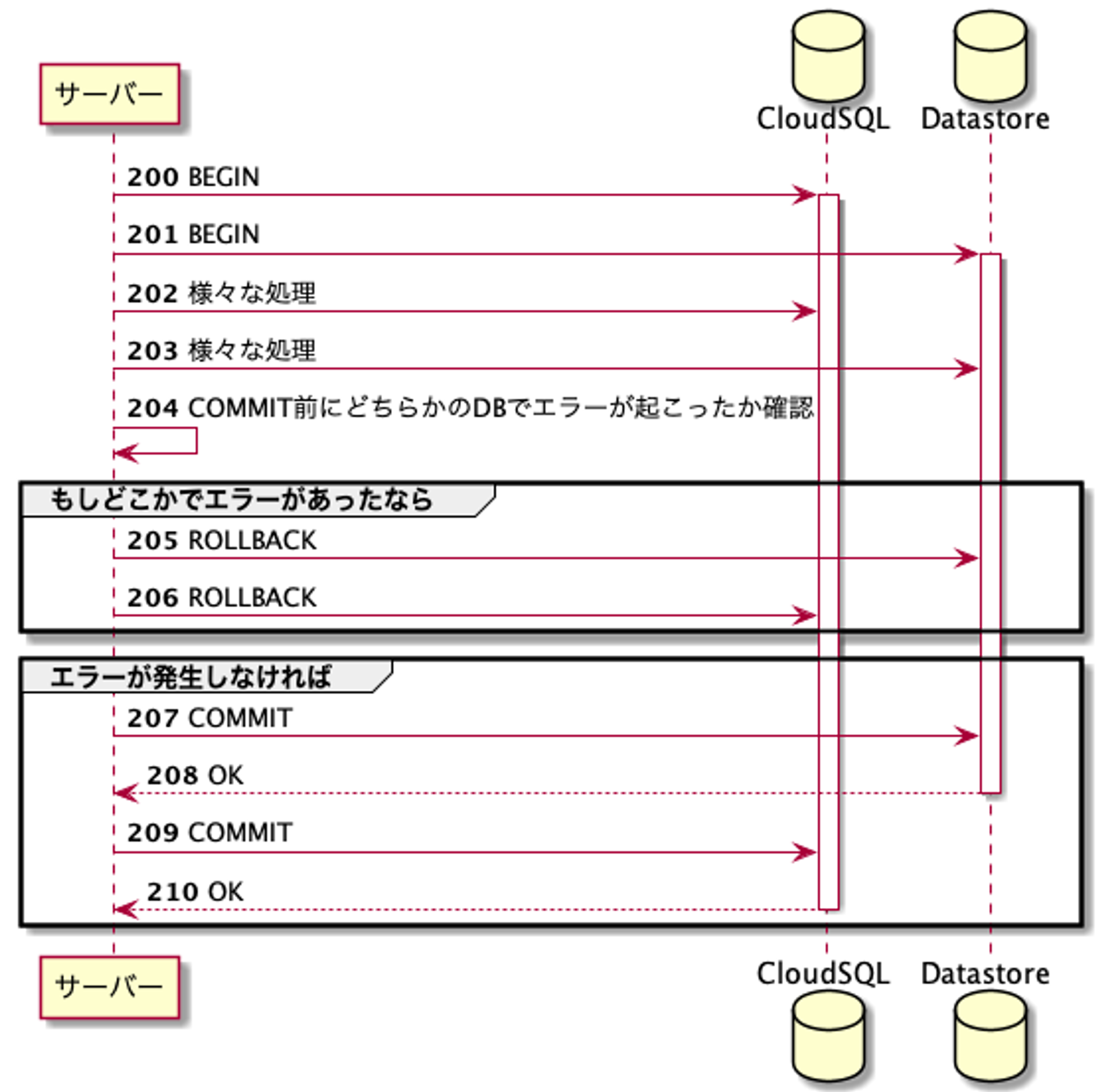
こうすると、1つ目のコミットが失敗した場合には2つ目のトランザクションをロールバックすることができますが、1つ目のコミットが成功して2つ目のコミットが失敗した場合には1つ目のトランザクションをロールバックすることはできません。
今回はこのパターンについては許容する実装になっており、もしもデータ不整合が起きてしまった場合には運用でカバーするようになっています。
ただし、そもそももしXATransactionのようなプロトコルでPrepareというオペレーションを実行することができたとしても、PrepareとCommitのわずかな時間の間にDB障害が起きたとしたら、データ不整合は起こりうるはずです。(参考 : https://www.ogis-ri.co.jp/otc/hiroba/technical/DTP/step2/index.html)
となると、完全に複数のデータベース間でトランザクションの結果を同期するのは難しく、どこかで失敗時のリカバリ処理が必要になるはずです。
今回は別々のゴルーチンでトランザクション処理を行いました。(Go言語で実装しています。)
204番の時点において双方でしっかりとトランザクション内のDB操作をすべて終えている必要があるので、チャネルを使用してタイミングを同期しながらエラーの伝達を行いました。
解決した問題と新たな課題
Datastoreを使用するようになったことで、データ構造の拡張性に対する懸念はなくなりました。
レプリケーション遅延も今の所起きていませんし、CPU負荷に対する不安は軽減した気がします。
上記が今回の改善で良かった点です。
逆に一番問題となったケースは、処理速度の問題でした。DBのCPUのスペックで殴っていた処理はDatastoreに移行したことで遅延するようになり、それに伴って、元のパフォーマンスが出せるように並行処理を行うなどの改善が必要になりました。
トランザクションにおける制約などもあるため、CloundSQLのまま頑張るという選択肢もあると思います。
例えば、ログ用のデータをBigQueryなどに移した後は、定期的に古いデータを削除するなどすれば、ある程度は問題となっていた課題は解決したかもしれません。
または日付やID単位などでシャーディングをすればパフォーマンスが改善するかもしれません。
プロジェクト終盤で、違うやり方で改善することもできたかもと気付くことはよくあります。このあたりは、後戻り出来るうちに色々と試行錯誤するのが良いと思います。
おわりに
今回の移行プロジェクトにおいては設計や実装をそのまま使い回すというシンプルな話では終わらず、当初想定していたよりもより多くの制約を乗り越えながら開発を行い実運用ができるまでに至りました。
Cloud SQLからのDatastore移行という同じような状況に陥り知見が必要になった際や、もう少し一般的にRDBMSからNoSQLに移行する際にも抽象的な観点レベルであってもなにか参考になる点があれば幸いです。
We're Hiring!
📢
Mobility Technologies ではともに働くエンジニアを募集しています。
興味のある方は 採用ページ も見ていただけると嬉しいです。
Twitter @mot_techtalk のフォローもよろしくお願いします!