

Kubeflow Pipelines on Amazon EKSのワークフロー環境
K8sAWSMLOpsDecember 06, 2021
DRIVE CHARTのAIシステムの開発・運用では、EKS上に構築したKubeflow Pipelinesをワークフロー環境として利用しています。本投稿では、このプラットフォームの活用や構成、構築やスケールの過程で遭遇した問題とその解決についてご紹介します。
この記事はMobility Technologies Advent Calendar 2021の5日目です。
DRIVE CHARTにおけるKubeflow Pipelinesの活用
交通事故削減支援を行う次世代AIドラレコサービス『DRIVE CHART』では、AIシステムだけで約30人のデータサイエンティスト・MLエンジニア・エッジデバイスエンジニア・MLOpsエンジニアが開発・運用に従事しています。
こうしたメンバの開発・運用業務改善のため、Amazon EKS + Kubeflow Pipelinesのワークフロー環境を昨年秋に構築し、約1年間運用してきました。
もともとは実験環境という位置づけでスタートしましたが、WebUIの使い勝手の良さやパイプライン実装の容易さが手伝って、その後もユースケースは拡大し、現在では以下に挙げるような広い範囲のタスクを処理する環境として用いられています。
- エッジアプリケーションとサーバサイドアプリケーションを一貫させた評価実験パイプライン
- 詳しくはこちらの発表 https://techcon.dena.com/2021/session/23/ をご覧ください
- PyTorchモデルからエッジデプロイ用モデルへの変換・ベンチマーク
- アノテーション用の動画ファイルの収集・編集
- 任意のコンテナイメージを用いた並列処理
上記のワークロードに対応するパイプライン (= ワークフローのテンプレート) を、MLOpsエンジニアが予め実装・デプロイしています。ユーザは、画面からパイプラインを選択し、パラメータを入力することでワークフローを作成・実行し、DBやS3に出力された結果を確認する、という使い方をしています。
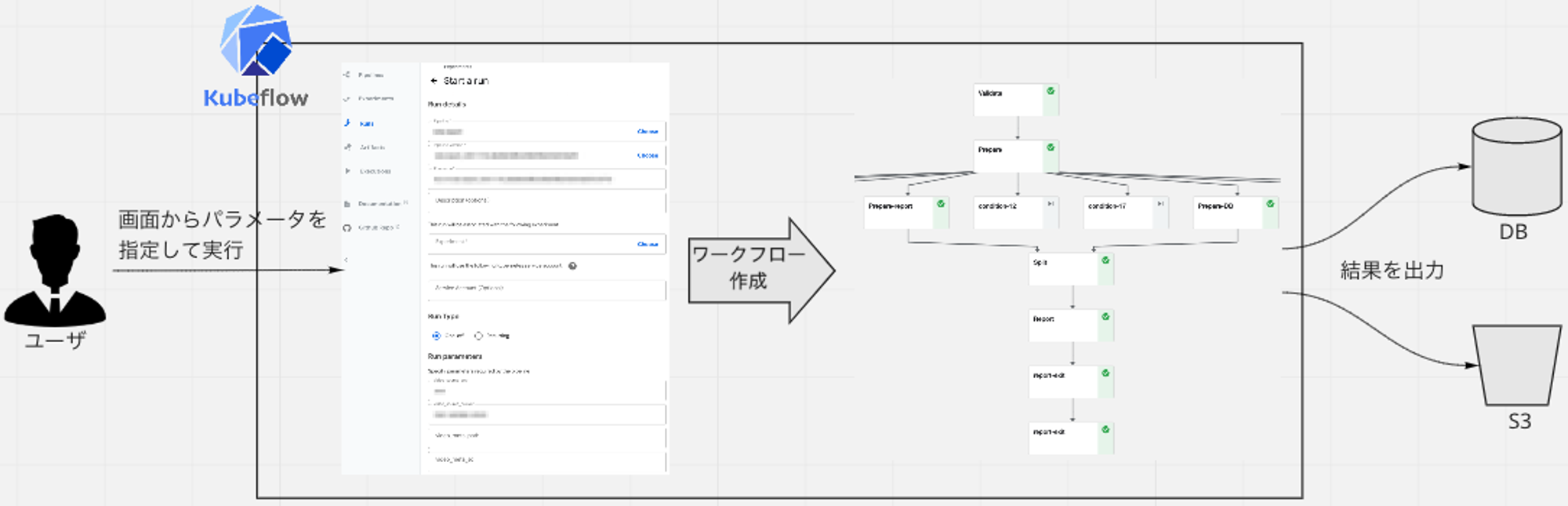
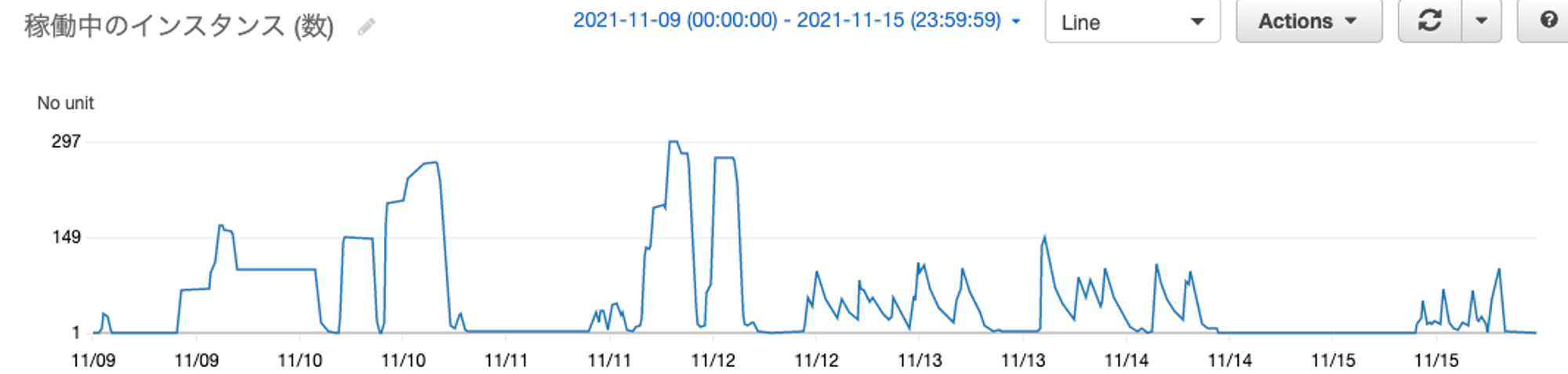
ある1週間の利用状況を、ワークフロー用のノードグループ (後述) のインスタンス数を軸として見てみますと、以下のような特徴があります。通常のWebサービスなどの環境と大きく傾向が異なっている点は注目です。
- 平日、特に営業時間中に最もよく利用され、多いときで最大300インスタンス (Pod数で約1,500) までスケールアウトする
- 利用されないときは、ほぼ0までスケールインする
ワークフロー環境のシステム構成
ワークフロー環境をメインに、システム構成概要を図示します。
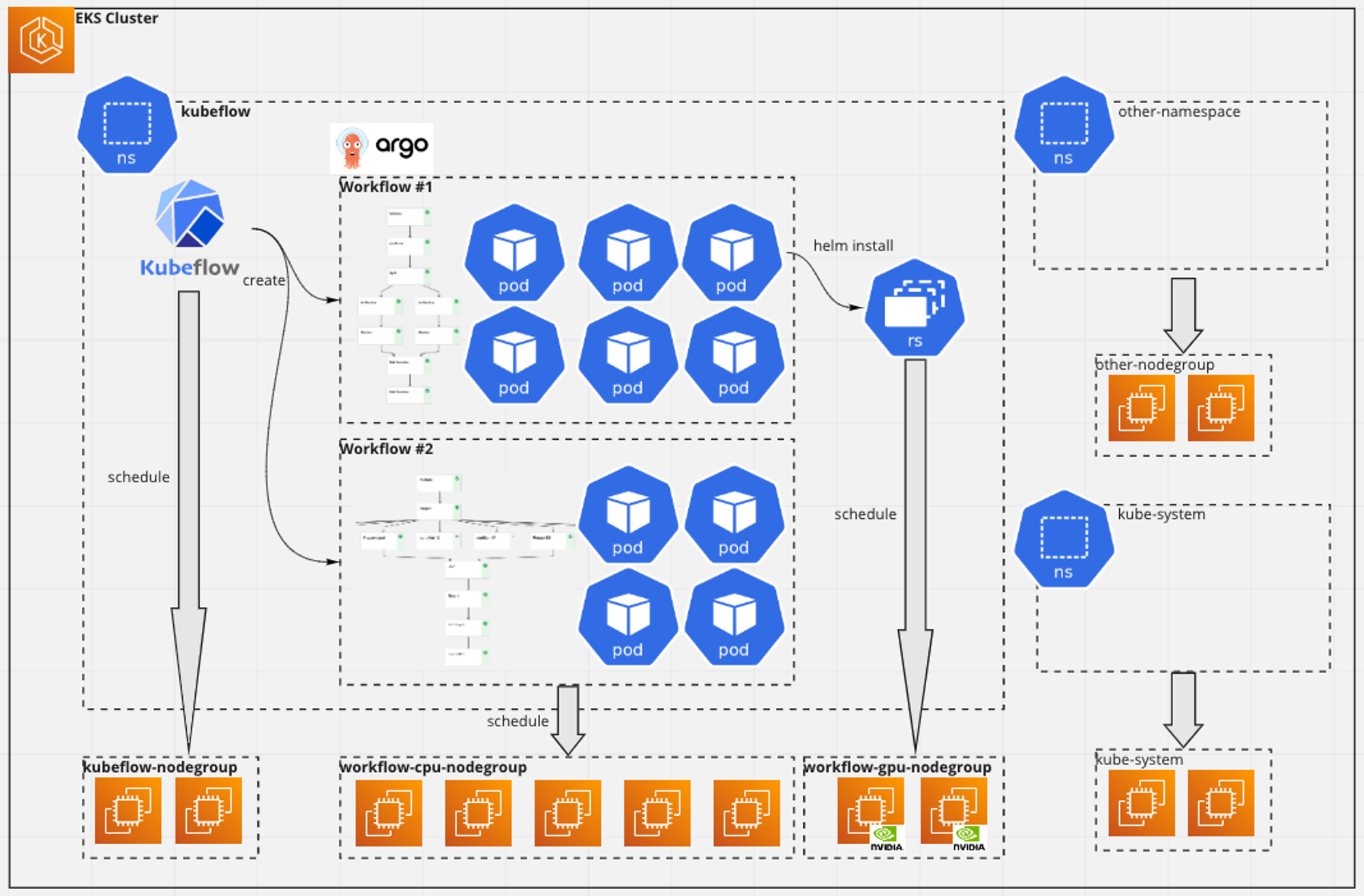
構成上のポイントは以下です。ノードグループを細かく分けている点が、通常のWebサービス環境などと比較して、大きく異なるかと思います。
- 単一のEKSクラスタ
- ワークフロー環境の他にも、他プロジェクトにデータ連携する定期ジョブやAIメンバが利用するWebアプリケーションなどが実行されています
- ワークフロー環境用のnamespaceを切って (kubeflow) 、他のアプリケーションと独立させている
- Kubeflow PipelinesやそのバックボーンとなるArgo Workflow、および、ユーザが実行するワークフローアプリケーションは、kubeflow内に集約
- ノードグループはワークフローサーバ用 (Kubeflow PipelinesやArgo Workflow) 、ワークフローアプリケーション用、その他アプリケーション用で分離
- 全てマネージドノードグループ
- ワークフローアプリケーションが利用するノードグループは、さらにCPUとGPUの2種類に分けられる
- ワークフローアプリケーションからは、さらに別のアプリケーションをHelmでインストールすることもあります (後述)
ノードグループ
ワークフローアプリケーション用のノードグループを分離しているのは、主に以下の理由です。
- スケーリングが激しく、スポットインスタンスを100%利用することで、コンピューティングコストを削減するため
- ワークフローでは 行儀の悪い カジュアルなアプリケーションが実行される可能性があり、他のアプリケーションの実行に悪影響を与えないため
- データサイエンティストやMLエンジニアの方が実装した実験用のプログラムやコンテナ (場合によっては書き捨てになるもの) が実行される
- ワークフローテンプレートでResource RequestsやResource Limitsなどは設定しているが、例えば巨大なファイルをephemeral storageにダウンロードするなどは自由に行われます
インスタンスタイプ
前述の通り、ワークフローアプリケーションが利用するノードグループにはCPUとGPUの2種類があります。ワークフローアプリケーションからはnodeSelectorを指定することで、スケジュールするノードグループを切り替えています。
CPUノードグループのインスタンスには、主にc5.xlargeとc5.2xlargeを使っています (2021年11月現在) 。
- 多くのワークロードは大きなメモリが要らず、c系のCPU1コアに対してメモリ2GBというのがバランスが良かった
- xlarge以上を使っているのは、インスタンスに割り当て可能なIPアドレス数を十分確保するため
- 例えばc5.largeですと、1インスタンスで収容可能なPod数が30に制限されます (参考)
- 全く使われない時間帯も発生するため、さらに巨大なインスタンスを確保するのもコストオーバヘッドが大きい (最小1インスタンスは稼働しているため)
GPUノードグループのインスタンスは、g4dn.xlargeとp2.xlargeを使っています。現在のユースケースでは、学習は行っておらず、専ら推論用です。そのため、インスタンスレベルのスケールアウトが可能で、GPU 1枚のインスタンスで十分というのが採用の理由です。なお、GPU AMIのインスタンスに NVIDIA device plugin for Kubernetes をDaemonSetで展開することで提供しています。
ログとメトリクス
クラスタ上のアプリケーションログやメトリクスは各ノードからAmazon Cloudwatch Logsへ送信・集約しています。
アプリケーションログは fluentd-cloudwatch をDaemonSetで全ノードに展開し、JSONで構造化して送っています。ワークフローの実行IDによってCloudwatch Logsのログストリームを分けて出力することで、ユーザが確認しやすいようにしています。必要に応じてPod名などもキーに追加しています。
また、メトリクスは cloudwatch-agent を同じくDaemonSetで全ノードに展開しています。Cloudwatch Container Insightsを使ってメトリクスの可視化をしています。
タスクの並列化
ワークフロー内でのPod間並列処理には、2つの方法で実現しています。主としてライフサイクル管理が不要な前者を使っていますが、必要に応じてHelmに切り出しています。
- withParamを使って、ワークフロー内で複数Podを実行する (後述)
- 実装が簡易で、予め処理量がわかっているケースに有効
- ワークフローから ReplicaSet + HPA (Horizontal Pod Autoscaler) を実行する
- 予め処理量が不明で、かつ、多くのCPU・メモリリソースやGPUを必要とするケースに
- Helmパッケージにまとめて、ワークフロー内でinstallとdeleteを行う
- Workflowオブジェクトと生成関係を持たないため、exitHandlerなどできちんと削除する必要がある
構築やスケールの過程で起きた問題とその解決
Kubernetesは未経験のメンバーだけであったため、構築フェーズでたくさんの躓きがありました。また運用を開始して、ユーザとユースケースがスケールしていく中でも様々な問題に遭遇しました。
だんだん遅くなる
βテストを開始からしばらくして "Kubeflowの画面表示が遅い" といったクレームを受けました。kubectlコマンドのレスポンスも極めて遅く、何らかの問題が起きていることは明らかでした。
EKSでコントロールプレーンのログ出力を有効化 (デフォルトでは無効) し、kube-apiserverのログを確認したところ、etcdへのアクセスが極めて遅いことがわかりました。調べると、ワークフロー上で作成していたJobとConfigMapのオブジェクトが大量に残存 (50,000+) していることがわかりました。さらにワークフロー中に、この大量のオブジェクトに対してkubectl list相当の処理を並列化したクライアントから行っており、全体のパフォーマンスに影響を与えてました。
以下の対策を実施しました。
- ワークフロー内でワークフローの管理から外れるk8sオブジェクトは、極力作らない
- ワークフロー内で作成したk8sオブジェクトは、ワークフロー内で削除する
- 途中で停止されるケースでも削除漏れが無いようにするため、exitHandlerで回収する
- どうしても残存するケースが発生しうるため、掃除のための定期ジョブを実行する (後述)
- ワークフロー内でlistアクセスを避ける
並行するワークフローが増えると名前解決に失敗する
βテスト中に、多数のワークフローを同時に動かすと各Podでしばしば名前解決に失敗する事象が、アプリケーションログから発覚しました。
負荷試験を実施したところ、ワークフローのPod数が300を超えたあたりでCoreDNSのPodが落ちる事象を確認しました。
CoreDNSのレプリカ数を増やす (デフォルトは2) とともに、ワークフローから実行される全Podに $.spec.dnsConfig を設定することで対策しました。デフォルトでは ndots: 5 (/etc/resolv.conf) が設定されており、FQDNではない場合は余計な検索が発生してCoreDNSを高負荷にするためです (参考) 。
dnsConfig:
options:
- {name: ndots, value: '1'}リトライ時にwithParam以降のタスクが実行されない
先述の通り、ワークフロー中のタスクをPod単位で並列処理する場合、手軽さ故にWorkflowのwithParamを使うことが多いです。withParamに配列で記述されたJSON文字列を渡すと、後続で配列の要素数だけPodが実行されます。
ところがKubeflow Pipelines上でリトライすると、JSON文字列を作るタスクの出力がキャッシュされている場合、実行できないケースがありました。以下のようなエラーが出力されます。
This step is in Error state with this message: withParam value could not be parsed as a JSON list: {{tasks.split.outputs.parameters.split-Output}}
そのため、withParamの入力となるタスクはキャッシュを無効化しています (参考) 。
def some_pipeline():
task_never_use_cache = some_op()
task_never_use_cache.execution_options.caching_strategy.max_cache_staleness = "P0D"ワークフローのPodが立て続けに落ちる
順調に稼働してたワークフローのPodが、ある時を境に突如終了を繰り返す、という事象が頻発しました。
今回の事象は、スポットインスタンスのプリエンプションを契機に起こっていました。スポットのプリエンプションでは、実行される2分前にインスタンスメタデータを通じて停止予定通知が飛んできます。アプリケーション内でこの通知を受信したら、プロセスを終了させるようにしていたのですが、停止予定になったノードに対してもスケジュール可能 (cordonされていない) なので、結局同じノードにスケジュールされて、またPodを終了させて... を繰り返していました。
このため、問題が発覚した当初は、プロセスを終了させずにインスタンスが停止するまで待機させるワークアラウンドを実装してました。
現在は AWS Node Termination Handler (DaemonSetとしてノードに展開され、インスタンスメタデータを監視し、終了予定通知を受け取ったらインスタンスの退役 (cordon) と再配置 (drain) を自動的に行う) をクラスタへ導入することによって回避しました。加えて、Capacity rebalancingを有効にしているので、プリエンプション時に新たなインスタンスを予めノードグループに追加されるため、一時的なノード不足にも陥りにくくなっています。
ノードグループのオートスケーリングが遅い
たくさんのPod (100+) で並列処理するワークフローを実行したときに、ノードグループのオートスケーリングが遅い、という問題が浮上してきました。Podのeventを確認すると、Pendingのままスケジュールされないという状態が数十分以上継続することがありました。
複数のノードグループを使い分けるため、各PodはnodeSelector ($.spec.nodeSelector) で指定していたのですが、cluster-autoscalerではnodeAffinity内で指定されたノードグループ ($.spec.affinity.nodeAffinity.requiredDuringSchedulingIgnoredDuringExecution) を尊重するため、うまくオートスケールできていなかったのが原因でした。
また安定性とは別の観点で、ノードの利用効率改善のために同じワークフローのPodは同じNodeにアサインされやすくなるように $.spec.affinity.podAffinity を設定しています。こうすることで、ワークフロー完了時にPodがすべて終了するので、インスタンスがスケールインしやすくなります。
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: eks.amazonaws.com/nodegroup
operator: In
values: [workflow-cpu-nodegroup]
podAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- podAffinityTerm:
labelSelector:
matchExpressions:
- key: workflow_run_id
operator: In
values: ['{{workflow.uid}}']
topologyKey: kubernetes.io/hostname
weight: 3だんだん遅くなる Part 2
リリースからしばらく使い続けていると、また遅いという不満が挙がってきました。
今度は完了したWorkflowオブジェクトとそれに紐づくPodオブジェクトが残存していたために、kube-apiserverのレスポンスを遅延させていました。
Workflowの有効期限 $.spec.ttlSecondsAfterFinished (Argo Workflow 3以降は $.spec.ttlStrategy.secondsAfterCompletion) に短い時間を設定することで回避しています。
ttlSecondsAfterFinished: 300上記のように設定していても、何かの契機でWorkflowオブジェクトが残存し、argocliでも削除できない (kubectl deleteでのみ削除できる) ケースが観測されています。
原因特定には至っていないのですが、ワークアラウンドとして、こういった残留オブジェクトを定期的に削除する運用アプリケーションをCronJobで実行しています。こういった運用ジョブはTerraform管理化に置いています。
まとめ
DRIVE CHARTで構築・運用しているワークフロー環境について、スマートドライビング事業部AI基盤グループ・大西がご紹介しました。
DRIVE CHARTのAI開発だけではなく、Mobility TechnologiesではプロダクションでもガッチリKubernetesを利用しているサービスがほとんどです。ご興味がありましたら、ぜひカジュアル面談にいらしてください!
We're Hiring!
📢
Mobility Technologies ではともに働くエンジニアを募集しています。
興味のある方は 採用ページ も見ていただけると嬉しいです。
Twitter @mot_techtalk のフォローもよろしくお願いします!