

分析基盤へのデータ同期を約40倍早くしてみた
データ基盤July 04, 2022
タクシーアプリ「GO」、法人向けサービス「GO BUSINESS」、タクシーデリバリーアプリ「GO Dine」の分析基盤を開発運用している伊田です。本番DBから分析基盤への連携処理を改善した事例を紹介します。※ 本記事の対象読者はETLツールを利用している方を対象にしています
はじめに
本記事では、タクシーアプリ「GO」の DB から分析基盤への同期処理を約7時間から約10分に改善した事例を紹介します。まず、既存の処理および改善前の状況を説明し、次に改善にあたり実施した分析、その分析をもとにチーム内で実施した議論を経て、最終的にどのような実装を行ったのか紹介させて頂きます。
同期処理について
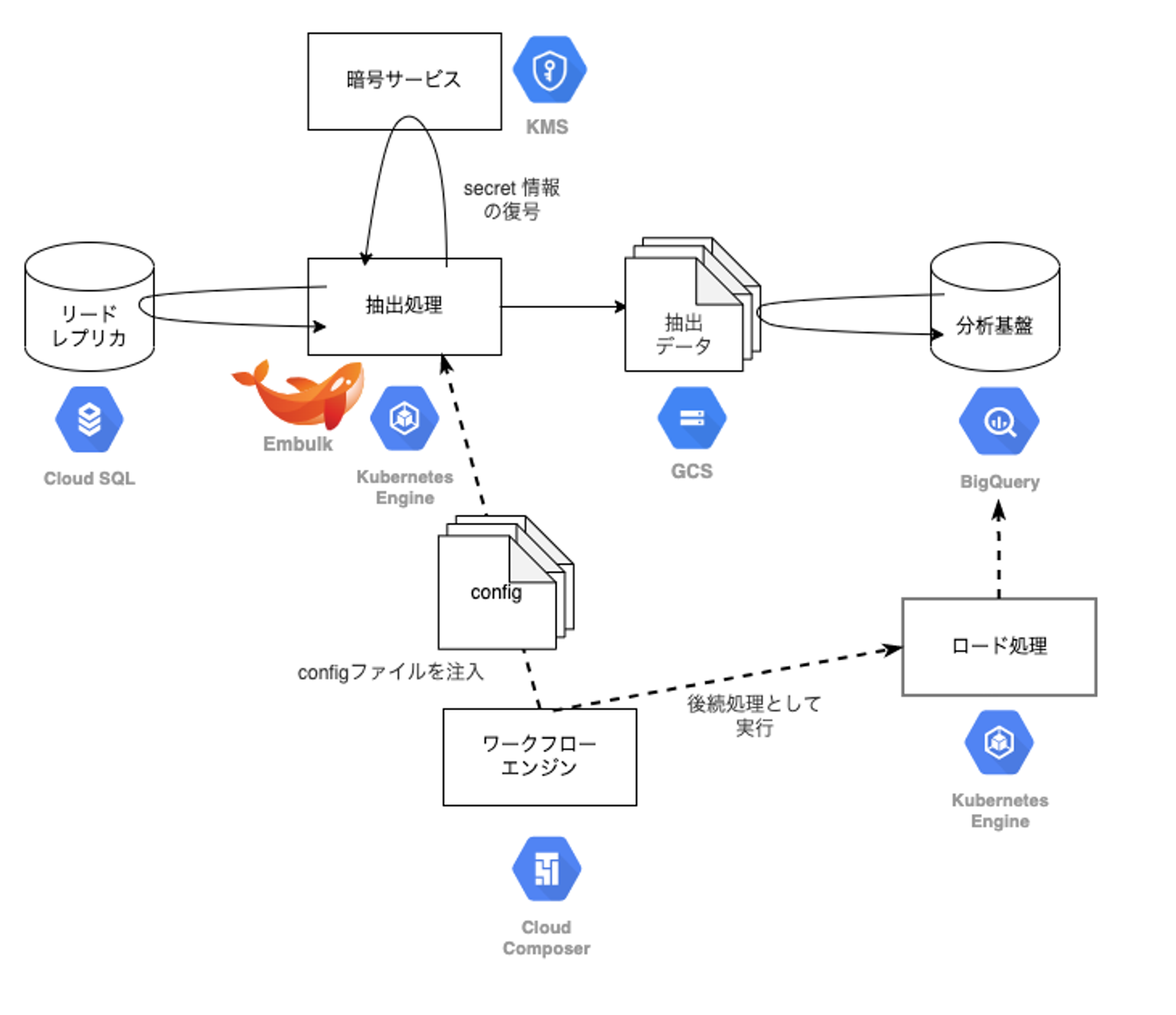
GO の DB は Cloud SQL 上で構築されており、分析基盤への同期処理は GKE 上で Embulk を起動し、リードレプリカに対してクエリを投げて一度 GCS に結果を格納します。その後、GCS から BigQuery にロードします。この処理が6時間毎(0時、6時、12時、18時)に実行され、毎回全件取得の洗い替えを実施しています。
改善前の状況
1回あたりの処理に約7時間掛かっており、特に0時台の処理が遅延すると、Looker(BIツール) で行っている Daily の集計処理の結果がおかしくなります。また、エラーが発生した場合、再実行にも時間が掛かるため、復旧するのは当日の夕方近くになりやすいです。こうしたエラーが月1〜2回程度の頻度で発生しており、同期処理の改善が求められていました。
改善目標
具体的にどの程度まで改善すれば良いかの指示はありませんでしたが、エラー時に頭から再実行しても次のジョブ起動時間に間に合うことが運用を安定させるための最低ラインと考えました。現状、6時間毎に実行しているので処理全体で3時間にすることを改善目標としました。
現状分析
改善するにあたりどこに手を付けるべきか検討するため、
- 現行の処理方式の確認
- 処理時間の内訳の確認
を行いました。
現行の処理方式の確認
改善を行うにあたり現行の処理方式の実装を確認しました。処理としては既に紹介したとおり、Cloud SQL から GKE 上で Embulk を起動して、全件取得を行い GCS に連携した後に、BigQuery にロード処理をして洗い替えをしています。細かく処理を見て行くと、Cloud Composer から config ファイルを注入して連携対象のテーブルのリストを渡したり、Cloud KMS を利用して暗号ファイルの復号を行い、復号した暗号鍵を用いて特定のカラムに対して復号およびハッシュ化処理をする等が確認できました。同期テーブル数は150テーブルで、4テーブルずつ並列に同期処理を実行していました。
処理時間の内訳の確認
- Cloud SQL → GCS : 約4〜5時間
- GCS → BigQuery : 約2時間
Cloud SQL → GCS 処理時間ワースト10
ほぼ黒塗りで申し訳ないのですが、下記のように処理時間ワースト10のテーブルについて、データサイズ、レコード数、処理時間の確認をしました。
現状のデータと中期経営計画の数値をもとに試算をすると、現状維持を選択すると遠くない未来に破綻することがわかりました。どう対応すべきかこの時点で判断はできませんが、少なくとも30分以上掛かっている処理をなんとかする必要がありました。また、アナリストにプライオリティの高いテーブルについてヒアリングを行い、30分以上掛かっているテーブルの中に日常的に利用するテーブルが存在していることがわかりました。
改善に向けての議論
これ以降の作業はある程度工数を投入する必要があるため、自分の考え、マネージャーの意向およびチームの意見をすり合わせるために議論を行いました。議論を行うにあたり、あらかじめ現状の分析と議論のポイント、対応案を資料にまとめ、事前に読んで頂いた上で議論をしました。議論のポイントとしては下記でした。
- 対処するテーブルのスコープ: 止血対応 or 全面刷新
- 連携方式: 全件更新 or 差分更新
- アーキテクチャ: 既存 or 新規
対処するテーブルのスコープ: 止血対応 or 全面刷新
まず、方針として止血対応として処理に時間が掛かっているテーブル(最大でも10テーブル)のみに対処するのか、全150テーブルに対処する全面刷新のスコープで行くのか議論しました。止血対応の場合、やり方によっては一時的に2つの連携方式が混在することになります。今回は素早い解決が求められていたことから、ひとまず止血対応を行い、その結果に応じて次にどうするか判断することにしました。
連携方式: 全件更新 or 差分更新
次に、中期経営計画の数値を根拠にプロダクトの成長によって、いずれ全件更新による連携が難しくなることから、今回の改善のスコープに最初から差分更新を盛り込むのかどうかを議論しました。前述の通り素早い解決が求められていたことから、ひとまず全件更新方式を維持することなりました。また、差分更新方式の問題点については下記の通り洗い出すことができました。
差分更新方式の考慮事項
前提: 連携処理に時間が掛かっていないテーブルは全件更新方式を維持
- 自動的にスキーマに追従できない問題がある
- 全件更新の場合、SELECT * FROM として全件洗い替えをすることでスキーマ変更を自動的に追従できる
- 差分更新の場合、例えば updated_at を指定して一定期間のデータを持ってくる都合上、 テーブルの洗い替えができず BigQuery 側のカラム追加、カラム名変更、カラム削除を行い、スキーマを追従する必要がある。もしくはスキーマ変更時の手動運用を許容する
- レコードが物理削除されていないか確認する必要がある
- updated_at が確実に更新されている必要がある
- updated_at に index が貼ってある必要がある
アーキテクチャ: 既存 or 新規
最後に、アーキテクチャを刷新するかどうかを議論しました。これについては、後述の対応案がある程度改善を見込めることから、一定工数が掛かるものの新規アーキテクチャの検討を進めることになりました。
対応案
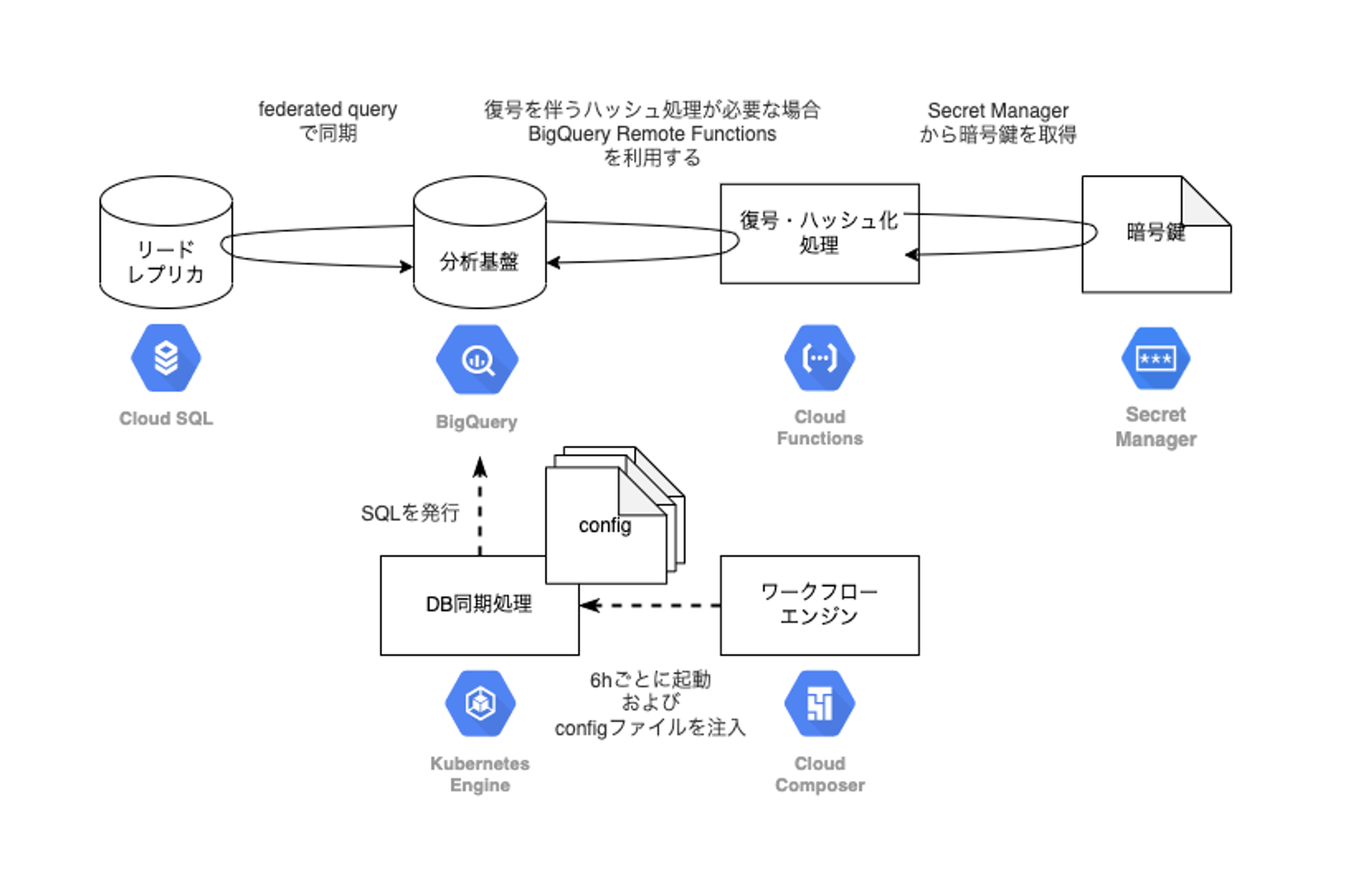
federated query による連携方式に切り替えることです。これは BigQuery から Cloud SQL に直接クエリを発行できる機能です。この機能を使うことで現行と新規のデータの流れはそれぞれ下記になります。
- 現行方式:Cloud SQL → GKE → GCS → BigQuery
- 新規方式:Cloud SQL → BigQuery
新規方式の場合、データの流れがCloud SQL → BigQuery となるので、現行方式に比べてデータの移動時間がある程度短くなると期待できます。特に、差分更新を適用することなく処理時間を改善できる可能性があります。
ただし、制限事項として下記があります。
- federated query の対象となる Cloud SQL はパブリック IP で接続できること
- federated query の接続設定は Cloud SQL と同じプロジェクトにしか作れないこと
- federated query の接続設定へのアクセス権限(roles/bigquery.connectionUser)があること
- Cloud SQL が Tokyo リージョンにある場合、BigQuery の連携先も Tokyo リージョンにあること
この制限事項の中で、今回、本番DBは Tokyo リージョンにあり、分析関連のデータセットは US リージョンにあるため、このリージョン違いの問題を解決する必要がありました。そこで以下の2案を検討しました。
案1 クロスリージョンレプリカを作成する
Cloud SQL のクロスリージョンレプリカ機能を使うと、マスターインスタンスとは別リージョンにインスタンスを立てられる機能です。この機能を使うことでリージョン違いの問題を解決することができます。BigQuery US マルチリージョンは us-central1 リージョンに近いとドキュメントに記載があるため、レプリカを us-central1 に作ると良さそうです。ただし、新規でインスタンスを立てるためコストが掛かります。
案2 既存のレプリカを利用する
既存のレプリカに対して、federated query の接続設定を行います。この場合、一度 Tokyo リージョンに書き込んでからデータセットコピーを使用して US リージョンにコピーします。
試しに既存のデータセットを US から Tokyo にデータセットコピーを行い、約30分掛かることを確認しています。
※ 既存のレプリカは元々別用途のレプリカで、分析基盤はあいのりして使用しており、既存のレプリカをクロスリージョンレプリカにすることはできませんでした
この場の議論では、どの程度の改善が出るか、またどの程度のコスト増が許容されるのか不透明だったため、本番DBを管理しているバックエンドチームに、コスト試算はしつつもひとまず案2で交渉することにしました。
新規アーキテクチャの初期実装
バックエンドチームとの交渉
この問題についての説明および、federated query の利用可否、利用が可能な場合の設定依頼、クロスリージョンレプリカを利用した場合のコスト試算を Slack 上(概略説明 + チーム内で使用した説明資料のURLを添付)で交渉を行いました。結果として、この問題について理解を頂き、実験的にクロスリージョンレプリカを立てることになりました。
また、並行して差分更新方式実現のためのコミュニケーションも行いました。
Q1. 処理に時間が掛かっている10テーブルのうち、物理削除を実施しているテーブルはあるか
A1. 一部のテーブルで物理削除を実施している
Q2. updated_at は確実に更新されているか
A2. ON UPDATE CURRENT_TIMESTAMP の設定があるため updated_at は必ず更新される
Q3. 差分更新を計画している10テーブルのうち、いくつかのテーブルで updated_at に index が貼ってない。クエリの実行計画を確認すると全件スキャンになるため index を貼って欲しい
A3. 対応する
このコミュニケーションによって、一部のテーブルで物理削除が実施されているとはいえ、差分更新方式の実現に目処が立ちました。
これらのバックエンドチームとのやりとりは一度も会議することなく非同期のコミュニケーションのみで完結できたのでリードタイム短縮に繋がりました。
実験
同期処理ワースト10のテーブルのうち仕様上移行ができなかった1テーブルを除いて federated query の実験を実施しました。
結果
30分程度で同期が完了しました。
考察
あまりに速度に差が出たので、どこで差がうまれているのか考察を行いました。既存の Embulk 方式と比較したところ下記の通りでした。
Embulk 方式
- CloudSQL(Tokyo) → GKE(US) → GCS(Tokyo) → BigQuery(US) と複数のアーキテクチャを経由している
- Tokyo と US リージョンを往復している
- GKE のマシンリソースを考慮して4テーブルずつ並列に同期処理をしている
federated query 方式
- CloudSQL(US) → BigQuery(US) とダイレクトに連携している
- クロスリージョンレプリカの時点で US リージョンにデータが存在している
- BigQuery にマシンリソースをおまかせできるので30テーブルずつ並列に同期処理をしている
GCS を Tokyo リージョンで作っているのは、当時はプロダクトの初期段階で Embulk 方式を実験的に実装し、データ量もそこまで大きくなく問題がなかったのではないかと推測しています。
実装
当初は止血対応として、ワースト10のテーブルを federated query 方式に移行する想定でしたが、思いの外に改善が見込めたので、全150テーブルのうち141テーブルを federated query 方式に移行することになりました。
9テーブルが移行できなかった理由は、復号およびハッシュ化処理を伴ったクエリが実行されているからです。federated query 上で復号する場合は、暗号鍵が BigQuery のログに流れてしまうことから一旦移行が見送られました。
テスト
新旧スキーマのチェック、データチェックを行いました。
スキーマに差分が出たので確認したところ、既存の実装では分析基盤用に型変換をしていました。federated query を使うと自動的に BigQuery の型にマッピングされるため(ドキュメントはこちら)、ほとんどは問題なかったのですが、差分が出たうちの1つとして、例えば TINYINT は BigQuery では INT64 に自動的に変換されます。このカラムは BOOLEAN としての使い方をしているため 既存の実装では分析基盤に連携する際に BOOLEAN に型変換をしており、新方式でもこれに追従しました。
リリース
リリースは実装の都度行い、四段階のリリースとなりました。
第一次リリース
Embulk 方式と federated query 方式が混在した状態です。このリリースによって、約7時間掛かっていた処理が約1時間になりました。
案件として立ち上がったのが4/8で、GW明けの5/9にリリースしたので約1ヶ月で対応することができました。この時点で同期処理の改善という目標はクリアしていますが、対応可能なときに一気に対応するべきと考えていたためマネージャーの了承を得てやりきることにしました。
※ ここまでが新規アーキテクチャの初期実装分です
第二次リリース
復号およびハッシュ化処理を伴ったクエリに対応しました。このリリースによって、処理時間が約30分になり方式が一本化されました。
復号およびハッシュ化の一連の実装は BigQuery Remote Functions を利用しています。いくつか案を出した上で、この方法は実装や暗号方式が変わったときのリスクがあると考えていたのですが、BigQuery にクエリを投げるだけで済むため方式を一本化できることや、元々プロダクトの実装にGo言語での復号処理が存在していたため、そのコードを利用することで比較的簡単に実装(仕様変更時も追従)できるという助言を元に、BigQuery Remote Functions での実装を行いました。以前、記事にして実装の勘所もわかっていたこともあり、特段ハマることなく実装でき、 BigQuery のログに 暗号鍵が流れてしまう問題を回避することができました。
結果として、この実装は方式が一本化されたことで運用も楽になり、今現在困っていることもないため、あの時の助言に助けられたと思っています。
第三次リリース
バックエンドチームから index 対応が完了したと連絡を受けて、データ量が大きいテーブルに対して差分更新方式をリリースしました。このリリースによって、処理時間が約20分になりました。
この差分更新方式のリリースにより、今までテーブルのデータ量に比例していた処理時間が updated_at の一定期間のデータの増分に比例するようになり、今後のプロダクトの成長によるデータ量の増大に耐えられるようになりました。
また、当初懸念していたスキーマが自動的に追従できない問題については、本番DB側のテーブルスキーマと BigQuery 側のテーブルスキーマを比較して、スキーマに差分がないときは差分更新処理、スキーマに差分があるときは全件更新処理とすることで自動的に追従するようにしました。BigQuery 側のスキーマ操作の実装難易度、手動運用などを検討した結果、そもそもスキーマ変更がほとんど起こらないことから、処理時間が時々悪化することは許容できると考えました。
第四次リリース
これまでのリリースで改善されなかった処理時間ワースト1のクエリを確認しチューニングを実施しました。また、レプリカのスペックを調整しコスト最適化を図りました。このリリースよって、処理時間が約10分になりました。
クエリチューニングとしては、GROUP BY を含む複雑なクエリをレプリカに投げており、こうした計算は BigQuery のほうが得意と考え、WITH句でテーブル全件を federated query で BigQuery に吸い出した後に、GROUP BY 等の計算を BigQuery 側に寄せました。
レプリカのコスト最適化は、スペックダウンで処理時間が伸びると考えていたのですが、差分更新対応で連携するデータ量が減った結果スペックダウン後のメモリでも十分だったのか、SSDへのディスク書き込みでも速度的に問題なかったのかは不明ですが、幸運なことに処理時間が伸びることはありませんでした(モニタリングしていると CPU が悲鳴をあげている)。
第四次リリースは6/9に行い、約2ヶ月に渡る改善対応を無事に終えることができました。
尚、チューニングのイメージは下記の通りです。
チューニング前
CREATE OR REPLACE TABLE ... AS
SELECT
.
.
.
FROM EXTERNAL_QUERY("connection_id",
"""
SELECT
.
.
.
FROM (
SELECT
.
.
.
FROM source_1
GROUP BY
column_name
) source_1
LEFT JOIN source_2
.
.
.
"""
);チューニング後
CREATE OR REPLACE TABLE ... AS
WITH
source_1 AS (
SELECT
.
.
.
FROM EXTERNAL_QUERY("connection_id",
"""
SELECT
.
.
.
FROM source_1
"""
)
),
source_2 AS (
SELECT
.
.
.
FROM EXTERNAL_QUERY("connection_id",
"""
SELECT
.
.
.
FROM source_2
"""
)
)
SELECT
.
.
.
FROM (
SELECT
.
.
.
FROM source_1
GROUP BY
column_name
) source_1
LEFT JOIN source_2
.
.
.新規アーキテクチャ図
最終的な新規アーキテクチャは下記となります。
おわりに
本記事では、本番DBから分析基盤への同期処理をどのように改善したか紹介させて頂きました。案件の立ち上がり当初は、手探り状態の中でデータを集めて分析し、どの方式が良いかチームで議論しました。改善にあたっては、別チームを巻き込んで実装を進め、最終的に劇的に処理時間を改善することができました。
この同期方式が皆様のご参考になれば幸いです。
We're Hiring!
📢
Mobility Technologies ではともに働くエンジニアを募集しています。
興味のある方は 採用ページ も見ていただけると嬉しいです。
データエンジニアは こちら から
Twitter @mot_techtalk のフォローもよろしくお願いします!