

BigQuery Remote Functions (Preview) をデータパイプラインに組み込んでみました
BigQueryApril 21, 2022
タクシーアプリ「GO」、法人向けサービス「GO BUSINESS」、タクシーデリバリーアプリ「GO Dine」の分析基盤を開発運用している伊田です。BigQuery Remote Functions (Preview) を利用することのメリットや、導入にあたり工夫した点を紹介します。
※ 本記事の対象読者は BigQuery を利用してパイプラインを作成している方を対象にしています
はじめに
本記事では、BigQuery Remote Functions について取り上げ、どのようなメリットがあるのか説明し、実装方法を解説します。次に Preview のプロダクトをパイプラインに導入するにあたり工夫した点を紹介させて頂きます。
※ 本記事では、Cloud Functions とは何かというような解説はしていません
BigQuery Remote Functions とは
BigQuery から Cloud Functions を呼び出して、加工した結果を再び BigQuery に戻すことで SQL だけでは実現できない変換をすることができます。
ただし、いくつか制限事項があり、引数、戻り値としてARRAY ,STRUCT ,INTERVAL ,GEOGRAPHY,JSON 型が使えないようです。
公式のドキュメントは こちら です。現在、Preview 中のため利用するには 登録フォーム から申請する必要があります。
料金は BigQuery + Cloud Functions を使用したのと同じだけ掛かります。
BigQuery Remote Functions を使うメリット
メリットは別途 Worker を用意する必要がない点です。
例えば、バッチ処理として GKE 上の Worker で BigQuery からデータを取り出して加工することを考えます。
GKE 上の Worker で処理する場合
処理するときの考慮事項として、
- BigQueryからデータを読み込む。読み込んだデータが Worker のメモリに乗らない可能性がある
- それを回避するためにページングしながら読み込む必要がある
- 途中エラーになったときを考慮して、いきなり出力先に書き込まずに一度テンポラリテーブルに書き込む必要がある
- backfill などで並列実行されることを考慮するとテンポラリテーブルを動的に作る必要がある
が考えられるので、下記の処理とします。
- テンポラリテーブルを動的に作成する
- BigQueryの対象テーブルからページングしながら読み込む
- y = f(x) のような加工処理を行う
- テンポラリテーブルに書き込む (読み込みが完了するまで2〜4)
- テンポラリテーブルから出力先テーブルにマージする
- テンポラリテーブルを削除する
もしくはある Worker が司令塔となり、子 Worker にメモリが乗り切る分だけ処理を分散させる方式も考えられますが、だいぶ大掛かりになってしまいます。
(ということを BigQuery Remote Functions がやってくれます)
BigQuery Remote Functions で処理する場合
- BigQuery で、Remote Functions を呼び出すクエリを実行する
- Cloud Functions 上で y = f(x) のような加工処理を行う
- (BigQuery がよしなに Cloud Functions にデータを分割してリクエストしてくれる)
- BigQuery が出力先にデータを書き込む
このように、BigQuery に実行させるクエリと Cloud Functions の実装を用意するだけなのでだいぶ構築が簡単になります。
構築
今回は、あるデータが暗号化された状態で BigQuery に連携されていて、そのデータを BigQuery Remote Functions を利用して SQL を実行するだけで復号を行います。
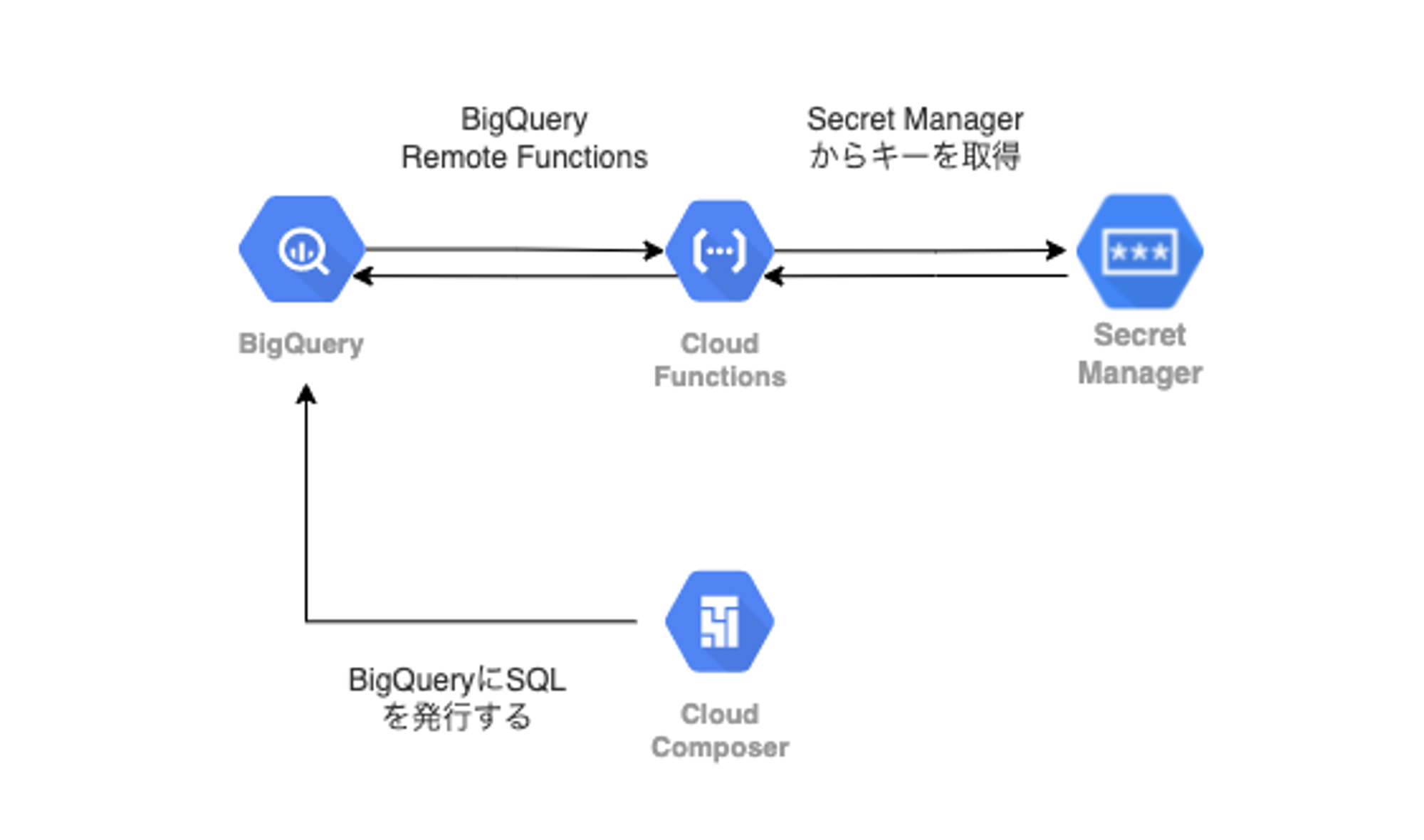
アーキテクチャ
アーキテクチャとしては下記です。
Cloud Composer から BigQuery に SQL を発行し、BigQuery Remote Functions によって Cloud Functions を呼び出します。呼び出された Cloud Functions は Secret Manager から暗号鍵を取得し、データを復号して BigQuery に値を返します。
リクエストとレスポンス
構築するにあたり、リクエストされたデータがどのように Cloud Functions に渡されて、どんなレスポンスを返せばよいのか確認します。
リクエストは例えば下記で、(公式の例がわかりづらいので一部改変しています)
{
"requestId": "124ab1c",
"caller": "//bigquery.googleapis.com/projects/myproject/jobs/myproject:US.bquxjob_5b4c112c_17961fafeaf",
"sessionUser": "test-user@test-company.com",
"userDefinedContext": {
"key1": "value1",
"key2": "v2"
},
"calls": [
[3, 2],
[1, 1]
]
}calls が実際に BigQuery で渡すデータです。
同じくレスポンスは、
{
"replies": [
1,
0
]
}という値を配列で返しています。つまり、
calls = [[3, 2], [0, 3]]
# f が Cloud Functions 内の処理で、 f(a, b) = a - b とすると
f([3, 2]) = 1
f([1, 1]) = 0
replies = [1, 0]ということです。
また、リクエストには、userDefinedContext というユーザ定義の値を設定することもできます。userDefinedContext は、同一エンドポイントで、context によって、Cloud Functions の内の挙動を変更するというような使い方ができます。
Cloud Functions の実装
では早速 Cloud Functions の実装を行います。
ディレクトリ構造
.
├── decrypter.py
├── main.py
├── requirements.txt
├── test_decrypter.py
└── test_main.py※ 本記事では、main.py のみ紹介します
main.py
import json
import os
import google.cloud.logging
import logging
from decrypter import Decrypter
client = google.cloud.logging.Client()
client.setup_logging()
logger = logging.getLogger()
def remote_decrypt(request):
try:
request_json = request.get_json()
calls = request_json['calls']
user_defined_context = request_json.get('userDefinedContext')
decrypter = Decrypter()
return_value = decrypter.decrypt(calls, user_defined_context)
return_json = json.dumps({"replies": return_value})
return return_json
except Exception as e:
return json.dumps({"errorMessage": f'{e}'}), 400このように main.py では受け取ったリクエスト値(calls)および、userDefinedContext を decrypter.py に渡して、結果を json にして BigQuery に返しています。
また、 Cloud Functions は Secret Manager と連携できるので、そういった処理も、 decrypter.py に記述しています。
デプロイ
Cloud Functions のデプロイは下記のコマンドでデプロイできます。
gcloud functions deploy remote_decrypt --runtime python38 --trigger-httpリモート関数
※ 公式ドキュメント +αの解説をしています
CLOUD_RESOURCE 接続を作成する
bq mk \
--connection \
--display_name='your-connection' \
--connection_type=CLOUD_RESOURCE \
--project_id=your-project \
--location=US \
your-connection
bq show --location=US --project_id=your-project --connection your-connectionCLOUD_RESOURCE 接続を作成するとサービスアカウントが作成されます。このサービスアカウントは後で使いますので、bq show コマンドで表示されたサービスアカウントを控えておきます。
リモート関数を作成する
CREATE FUNCTION `your-project`.your-dataset.remote_decrypt(target_column_name STRING) RETURNS STRING
REMOTE WITH CONNECTION `your-project.us.your-connection`
OPTIONS (endpoint = 'https://us-central1-your-project.cloudfunctions.net/remote_decrypt',
user_defined_context = [("key", "value")])権限
ここで処理の流れを確認すると
- BigQuery がリモート関数を呼び出す
- CLOUD_RESOURCE が仲介役となって Cloud Functions を呼び出す
- Cloud Functions が Secret Manager を呼び出して暗号鍵を取得し、復号処理を行う
よって、付与する権限は以下の通りです。
リモート関数の呼び出し
リモート関数を呼び出すには、BigQuery Connection User ロールが必要です。
CLOUD_RESOURCE から Cloud Functions の呼び出し
(再掲)
bq show --location=US --project_id=your-project --connection your-connectionCLOUD_RESOURCE 接続を作成するとサービスアカウントが作成されます。このサービスアカウントに Cloud Functions 起動元ロールを付与します。
Cloud Functions から Secret Manager の呼び出し
your-project@appspot.gserviceaccount.com が Cloud Functions のデフォルトサービスアカウントなので、このサービスアカウントにシークレットアクセサー権限を付与します。
尚、Cloud Functions はランタイムサービスアカウントとして、個別にサービスアカウントを設定できるので、権限分離をすることもできます。
チューニング
これで準備が整ったので BigQuery Remote Functions を実行してみます。......処理が20分ほど待っても返ってきません。というわけで、ここでは実施したチューニングについて紹介します。
前提条件
今回、BigQuery Remote Functions で加工するデータは1テーブル内の6カラムです。6カラム合計で、1日あたり 100〜200k のデータ量となります。
仮説
- 復号処理(Cloud Functions)で時間が掛かっている
- 1.1. Secret Manager へのアクセスで時間が掛かっている
- 1.2. 復号処理自体に時間が掛かっている
- BigQuery から Cloud Functions のやりとりで時間が掛かっている
チューニング その1
事前測定
ひとまずどこがボトルネックになっているか測定します。ログを仕込み1レコード分の処理を測定したところ、全体としては平均300〜500ms で、このうち Secret Manager へのアクセスに大部分の時間が掛かっていることがわかりました。
仮説1.2は否定され、仮説1.1に問題があることがわかりました。
改善
そこで Cloud Functions に Secret Manager をマウントするという方式があるようなので、今まで Secret Manager に API 実行していたのをマウントする方式に変更しました。
こちら の記事を参考にさせて頂きました。
測定
この改善により、1行のリクエストで実行時間は10〜50msになりました。
チューニング その2
改めて BigQuery Remote Functions を実行しますが、状況は改善しませんでした。ここで仮説2について検討します。
指標の確認
Cloud Functions の指標タブから状況を確認したところ、1リクエストあたりの平均実行時間が10〜50msとなっていることに気づきました(この実行時間からすると、1レコードしか処理していないと考えられた)。ログを改めて確認したところ、1リクエストあたり1レコードのリクエストとなっていて、かつインスタンス数も10〜20程度で推移していました。
どうやら BigQuery が Cloud Functions にうまくリクエストできていないようです。
改善
そこで CREATE FUNCTION の max_batching_rows というオプションを利用することにしました。このオプションは、HTTP リクエストの最大行数を指定できます。おそらく BigQuery は Cloud Functions に何レコードリクエストを投げられるかわからないので、安全に倒して1リクエスト1レコードとしているのだと思われました。
よって、max_batching_rows=10000 を指定して再作成しました。
CREATE FUNCTION `your-project`.your-dataset.remote_decrypt(target_column_name STRING) RETURNS STRING
REMOTE WITH CONNECTION `your-project.us.your-connection`
OPTIONS (endpoint = 'https://us-central1-your-project.cloudfunctions.net/remote_decrypt',
max_batching_rows = 10000,
user_defined_context = [("key", "value")])10,000 という数字は Cloud Functions のタイムアウトを鑑みて、指標を見ながら調整しました。1カラム分を試しに実行したところ、1リクエストの実行時間は約10〜15sとなりました(1リクエスト10,000レコードになった)。
チューニング その3
改めて BigQuery Remote Functions を実行しますが、状況は改善しませんでした。1カラムだとうまくいきますが、6カラムだとうまくいかないという謎の事象です(何らかのバグを踏んでいる感じがしました)。
改善
1カラムだとうまくいくので、SQLの組み方を以下のように変更しました。
修正前
merge target t
using (
select
id,
dataset_id.remote_decrypt(...) as col_1,
dataset_id.remote_decrypt(...) as col_2,
dataset_id.remote_decrypt(...) as col_3,
dataset_id.remote_decrypt(...) as col_4,
dataset_id.remote_decrypt(...) as col_5,
dataset_id.remote_decrypt(...) as col_6
from source
) s
.
.
.修正後
merge target t
using (
select
id,
dataset_id.remote_decrypt(...) as col_1
from source
) s
.
.
.merge target t
using (
select
id,
dataset_id.remote_decrypt(...) as col_2
from source
) s
.
.
.この要領で SQL を6つに分割しました。
この方式にしたところ、当初20分経ってもクエリが返ってこなかったのが、全体で5分程度で完了するようになりました。
※ この事象については Google の方にフィードバック済みです
運用
Preview のプロダクトをパイプラインに組み込むにあたり運用上の制約は下記でした。
- 対象テーブルはレコード数を速報KPIとしているが、復号カラム自体は速報KPIではない
よって、復号が失敗しても後続処理が流れるようにし、アラートをもとにリカバリを行う運用設計としました。
この制約を満たすように Airflow の DAG 上では、復号処理の後続で、DummyOperator を配置し、trigger_rule に all_done を設定して、復号処理が成功しても失敗しても後続処理が流れるようにしています。
ちなみに、このパイプラインを本番運用して2週間が経過していますが、今のところ復号処理が失敗したことはありません。
また、Cloud Functions, Secret Manager の料金について言及しますとテスト期間と本番期間を含めても100円も掛かっていません。
おわりに
本記事では、BigQuery Remote Functions について紹介しました。この機能があることで、SQL 単独では実現できない加工処理も Cloud Functions を実装するだけで完結させることができます。
GA になったときはもっと使い勝手が良くなっていることを期待しています。
We're Hiring!
📢
Mobility Technologies ではともに働くエンジニアを募集しています。
興味のある方は 採用ページ も見ていただけると嬉しいです。
Twitter @mot_techtalk のフォローもよろしくお願いします!