

エッジデバイス向けAIアクセラレータの比較検証
ChallengeWeekAIAugust 01, 2022
交通事故削減支援サービス『DRIVE CHART』のドライブレコーダー上で動作するEdge AIライブラリの開発担当の廣安です。今回は我々のチームで行った、入手可能なAIアクセラレータをいくつか選考して評価するという取り組みについて紹介したいと思います。
これは MoT Engineer Challenge Week 2022 Spring の記事です。
はじめに
我々のチームでは、DRIVE CHARTのアプリケーション上でドラレコのカメラ画像を入力としてAI推論処理を行うためのライブラリを開発しています(こちらのブログ参照)。しかし開発を進めていく中で、そのハードウェア上で高速に推論処理を行うための知見についてはかなり溜まっている一方、AIアクセラレータ全般の最新ベンチマークが不十分であるという課題感がありました。
そこで今回Engineer Challenge Weekという機会を借りて、AIアクセラレータの市場調査や実機を使った評価に取り組んでみる事にしました。まずは市場にどのようなAIアクセラレータが出回っているかというところから調査を始め、その中からいくつか選定して購入しチームメンバーで手分けして実際に評価を行いました。この記事ではその評価内容についてご紹介したいと思います。
AIアクセラレータとは
本題に入るまえに、まずAIアクセラレータが何かについて説明します。AIアクセラレータとは、AI(主にニューラルネットワーク)のモデル推論処理を高速に行うためのハードウェアの事で、広義ではGPUやFPGAのようなデバイスも含まれますが、近年では推論用に設計された専用チップやAIアクセラレータベンダが提供するIPを実装したSoC(System on Chip)等が多く出回っており、そちらを指す事が多いです。広く知られている製品としては、Google CoralのEdgeTPU(USBタイプ)や、IntelのNeural Compute Stick2などがあります。
提供形態
AIアクセラレータの提供形態は例にあげたUSBスティックタイプの他にも以下のようなタイプのものが存在します。
- SoC内のNPU(Neural Processing Unit)やDSP(Digital Signal Processor)として配置(例:RenesasのRZ/V2L)
- PCIeやM.2の拡張ボードとして提供(例:HailoのHailo-8)
- 完全に独立したチップとしてUSB, SPI, I2Cのようなシリアル通信を介して使うタイプ(例:Google CoralのEdgeTPU Accelerator Module)
計算性能
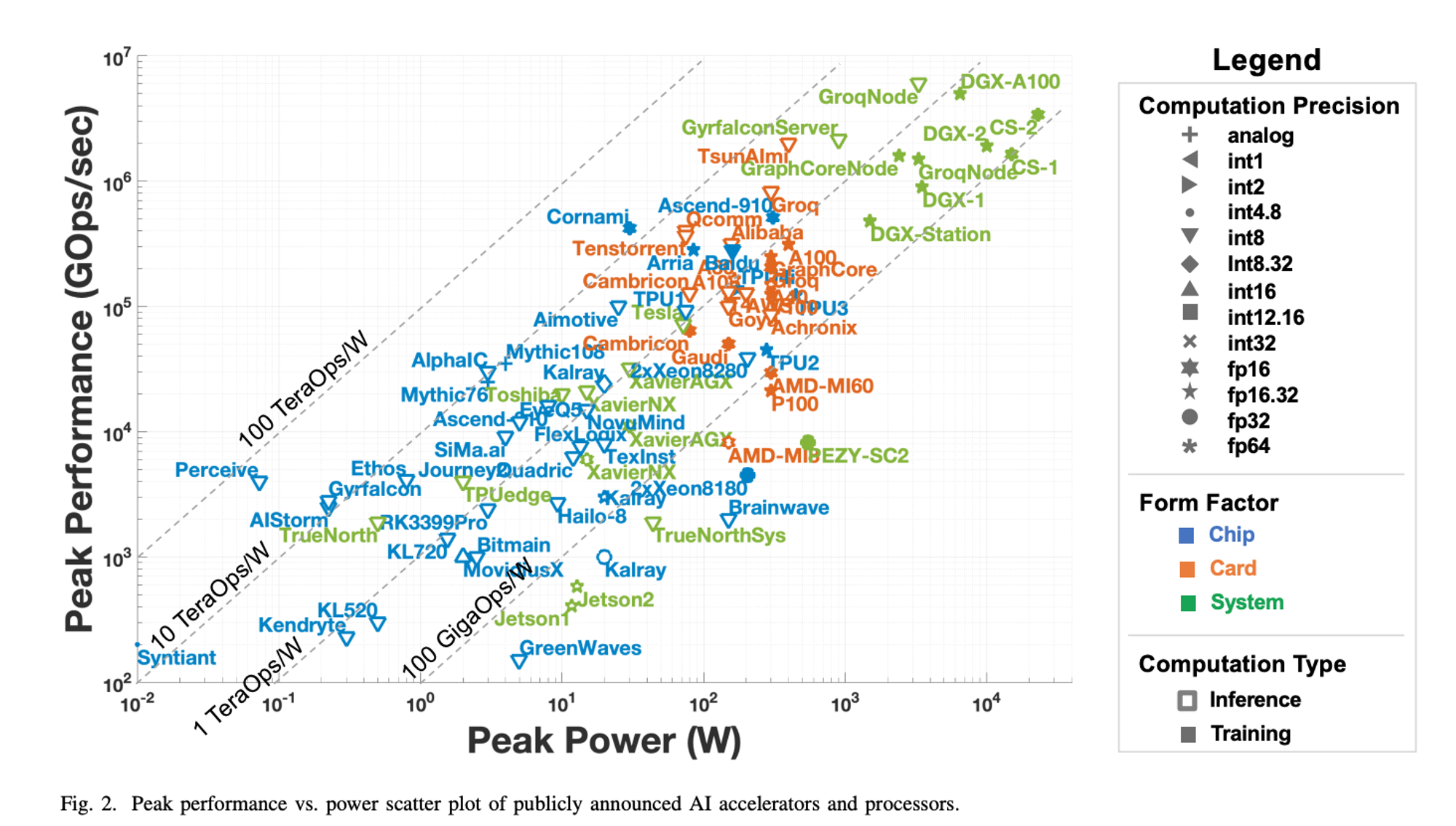
AIアクセラレータに必要とされる計算性能はターゲットによって異なります。以下はこのサーベイ論文[Albert Reuther et al.]から引用した各社のAIアクセラレータの消費電力と計算性能をプロットした図になります。これを見てわかるように、計算性能が大きくなるに従い消費電力も大きくなる傾向があります。また、物理的なサイズや排熱量も消費電力に比例して大きくなってくるため、エッジ向きのアクセラレータとしては図の左下の方にあるような、低消費電力でそれなりに計算性能が高いものが求められます。
実際にどの程度の計算性能が要求されるかは実行したいタスクやその規模などによって変わってきます。以下の図はArmとNXPのWebinarの資料からのキャプチャで、各ユースケースでどの程度の計算性能が必要になるかを入力データ(画像/オーディオ/その他の時系列データ)別で示しています。目安ではありますが、例えば複数の物体検出を行うようなタスクならば、2-3TOPS程度の計算性能が必要とされていますし、10ワード程度の音声認識を行うようなタスクであれば0.25-0.5TOPS程度の計算性能があれば良いとされています。
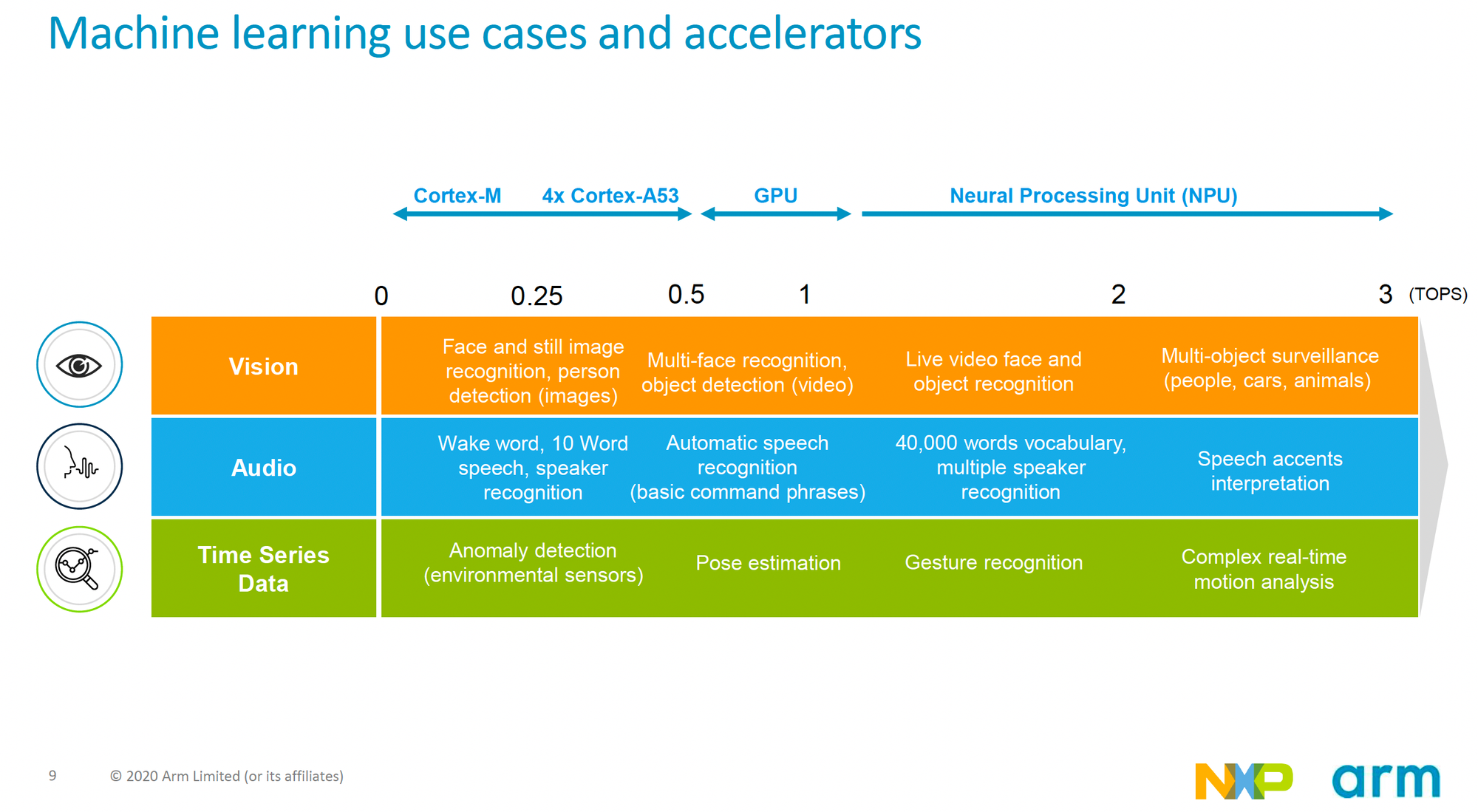
図では高いAI性能が求められないのであればNPUのようなAIアクセラレータが必要ない、というようにも見えてしまいますが、そのあたりは実際のシステムによっても変わってくると思います。例えばCPUやGPUが別のタスクで高優先度で使用されるようなシステムでは、AI処理が全体処理のネックになってくるような事が考えられるので、AI処理をオフロードするためのアクセラレータが必要になってくる事もあるでしょう。
対応フレームワーク
AIアクセラレータは専用のランタイムを持っており、そこにAIモデルを読み込ませて推論処理を行います。AIモデルを学習するフレームワークは多数ありますが、多くのメーカーはpytorchやtensorflowのようなメジャーなフレームワークのモデル読み込みや、ONNX(Open Neural Network Exchange)という広く使われているニューラルネットワークのモデル保存ファイルフォーマット形式の読み込みに対応しています。
また、ほとんどのAIアクセラレータのランタイムではpytorchやtensorflowで学習されたモデルを直接読み込むわけではなく、高速化のためにINT8やFP16で内部計算を行うよう量子化を行ったり、そのランタイム向けの変換を行う専用ツールを介して出力されたファイルを読み込むようになっています。量子化についてはチームメンバが書いたこちらのブログが詳しいのでご参照ください。
AIアクセラレータ評価
ここからは本題である各AIアクセラレータの選定や実機を使った評価について述べます。
評価対象の選定
Engineer Challenge Weekは期間が定められているので、評価対象を絞り込む必要がありました。そのため、事前調査の時間を取り、まずは市場にどのようなAIアクセラレータが存在するかの情報収集を行った上で、以下のような基準を設けて選定を行いました。
- 画像入力のAI推論を高速に実行できる性能がある(2TOPS以上)
- PytorchやONNXといったよく使われるAIモデルのフレームワークに対応している
- 比較的安価で入手しやすい
今回、評価対象として選んだAIアクセラレータは以下の通り(括弧内は担当メンバー)になります。
- Texas Instruments TDA4VM (廣安)
- NXP i.MX 8M Plus (廣安)
- Rockchip RK3399Pro (亀澤)
- Google EdgeTPU (郭)
以下のような点について評価を行い、それぞれの評価結果をまとめていきます
- どのようなハードウェアか
- どのようなAIフレームワークに対応しているか
- モデルの量子化やハードウェア上で実際にベンチマークを行うにはどのような手順が必要か
Texas Instruments TDA4VM
ハードウェア概要
TDA4VMは、8TOPSのAI演算性能のMMA(Matrix Multiply Accelerator)を内部に持つArmのCortex-AベースのSoCになります。ADAS/自動運転向けに作られたSoCであり、MMAの他にも積和演算以外のAIの演算処理を担うDSP「C7x」や画像処理向けのDSP「C66x」などを内蔵しています。
今回はSK-TDA4VMという評価ボードをTexas Instrumentsから購入して評価を行いました。
対応フレームワークと推論ランタイム
推論ランタイムとしてTVM、TFLite、ONNX Runtimeが用意されています。ONNX RuntimeにはExecution Provider、TFLiteにはDelegateというアクセラレータ上で演算処理を行うための拡張機能がありますが、それらを利用する事でTDA4VM上で高速にAI推論処理を行うような仕組みになっています。
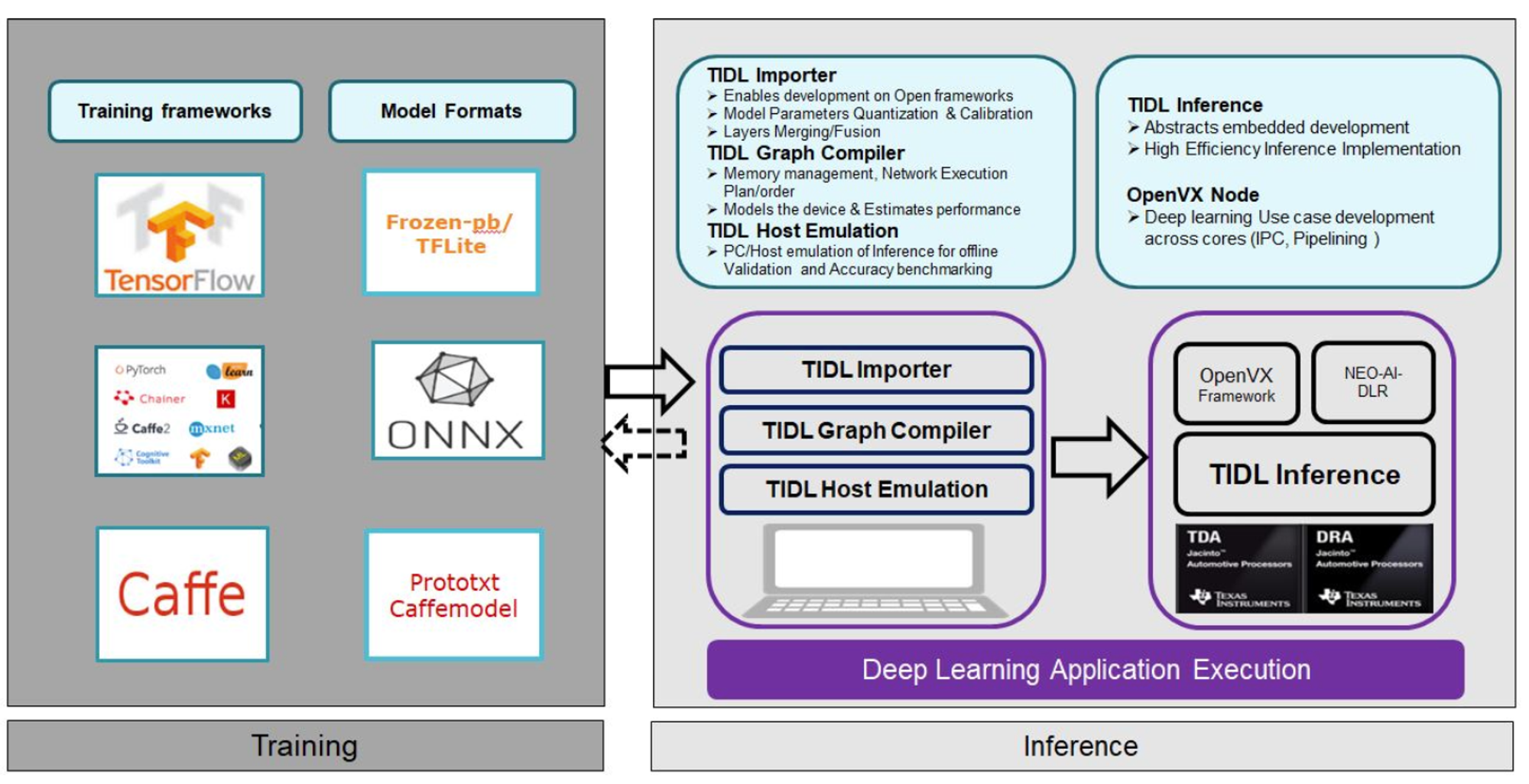
それぞれのランタイム上でモデルを読み込んで動作させるためには、学習済みのモデルを変換し専用のファイル形式にする必要があります。変換はTIDL(Texas Instruments Deep Learning ecosystem)というツールを介して行います。下図はTIDLのユーザガイドにあった概観図になりますが、TFLiteやONNXのフォーマット形式のモデルをホスト上で変換し、それを実デバイスにデプロイして推論を行うような仕組みになっています。
ランタイムのAPIを実装するための言語としてはPythonとC++が用意されています。
その他の特徴
TDA4VMにはAI向け以外に画像処理向けのDSPも搭載されていますが、そのDSPを使った処理はOpenVX APIを介して実行できるようになっています。また、そのOpenVX APIを使用したGStreamerのプラグインも用意されているため、映像を入力としたAI処理系のシステムを簡単に構成する事ができます。
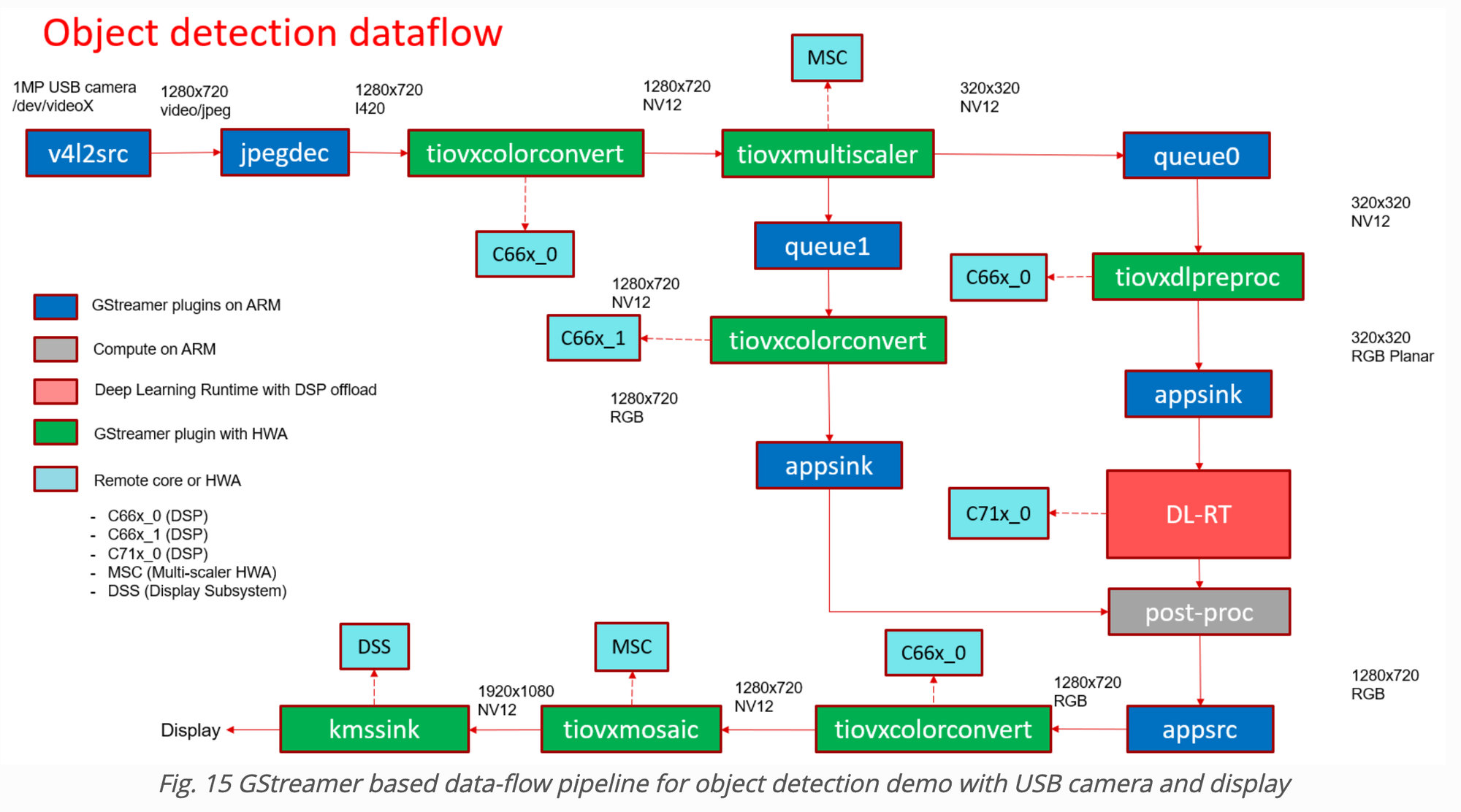
例えば、下記の図はSDKのマニュアルより抜粋した物体検出のデモプログラムの処理フローになります。緑色のボックスがOpenVXを使用したGStreamerプラグインであり、そのバックグラウンドで水色のボックスで示されるDSPが動作している事を示しています。このようにGStreamerを利用する事でカメラの映像入力から、AIモデルに入力するための画像前処理の実行、後処理後の結果のオーバレイとその映像出力に至るまでのパイプラインを簡単に構成する事が出来、かつ高速にアクセラレータ上で実行する事ができるというのもこのデバイスの良い点だと思います。
モデル変換とベンチマークの実施手順
変換は上述したようにTIDLを使って行います。リポジトリ上にDockerfileが用意されているので、まずはそれを使ってホスト上に変換を行うdocker環境を構築します。あとはここにカスタムモデル変換用のnotebook(custom-model-*.ipynb)があるので、それを参考に対象モデルの変換用スクリプトを作成し実行します。
今回TFLite, ONNXRuntime, TVMに向けてDRIVE CHARTで使われているモデル(ONNXフォーマットのファイル)の変換を試みましたが、TFLite, ONNXRuntimeについては実行時にエラーが出て対応できませんでした。そのため、ベンチマークはこちらのTVM向けの変換用サンプルnotebookを元に作成したモデルだけで実施しました。変換時には量子化ビット数(8bit or 16bit)や量子化パラメータのキャリブレーションを行うための入力画像パスといったいくつかのパラメータ指定が可能ですが、今回はベンチマークだけなのでキャリブレーションは使わず、量子化ビット数8として変換を行いました。
出力されたファイルを実デバイス上にデプロイし、ランタイムの読み込ませれば推論処理の実行が可能になります。パフォーマンス測定のサンプルnotebookもあるのでそちらを参考に実際に実装を行い測定を行いました。結果は最後のまとめに記載しています。
感想
以下にTDA4VMに関して良かった点を列挙します。
- 計算性能が高い
- 画像処理向けのDSPも内蔵しており、カメラ画像処理やAIの前処理などをオフロードする事も可能
- サンプルやドキュメントが充実している。サンプルコードもシンプルでわかりやすい
- モデル変換のエコシステムが使いやすい。サンプルもnotebookで用意されているので手軽に試行錯誤できる
- コードがすべてOSSとして公開されており、何かあった時の調査が容易
- 質問フォームから丁寧で迅速に回答を貰えるなどサポートも充実
ADAS向けという事で少し高めの価格設定ではありますが、総合的に良いチップだと思いました。
NXP i.MX 8M Plus
ハードウェア概要
NXP i.MX 8M Plusは2.3TOPSの性能を持つNPUを内蔵しているArmのCortex-AベースのSoCです。NXPは要求性能に応じてスケーラブルにプロセッサを選択できるようi.MXというプロセッサシリーズを提供しており、その内の一つになります。
AI性能だけでなくマルチメディア性能も強力で、H.264/H.265等のコーデックのDecode/Encode用のVPU(Video Processing Unit)や、オーディオ処理用のDSP等がSoC上に配置されているのが特徴です。
また、i.MXシリーズはVariscite、SolidRun、TechNexion等の多数のメーカがSoM(System on Module)を生産/販売しており、主に産業用で使われているようです。そのSoMを搭載した評価ボード等も多数あるのですが、今回は国内でも入手が容易だったBaslerのprB-iMX8MPというSBC(Single Board Computer)を購入し評価を行いました。このSBCにはVariscite製のSoMが搭載されています。
対応フレームワークと推論ランタイム
i.MXシリーズにはMLソフトウェア開発環境としてeIQというものが用意されてます。eIQにはホストPC側でモデル変換やベンチマーク検証を行うeIQ ToolkitというGUI/CLIツールや、実際のデバイス上で行うためのeIQ Inference Runtimeが含まれています。
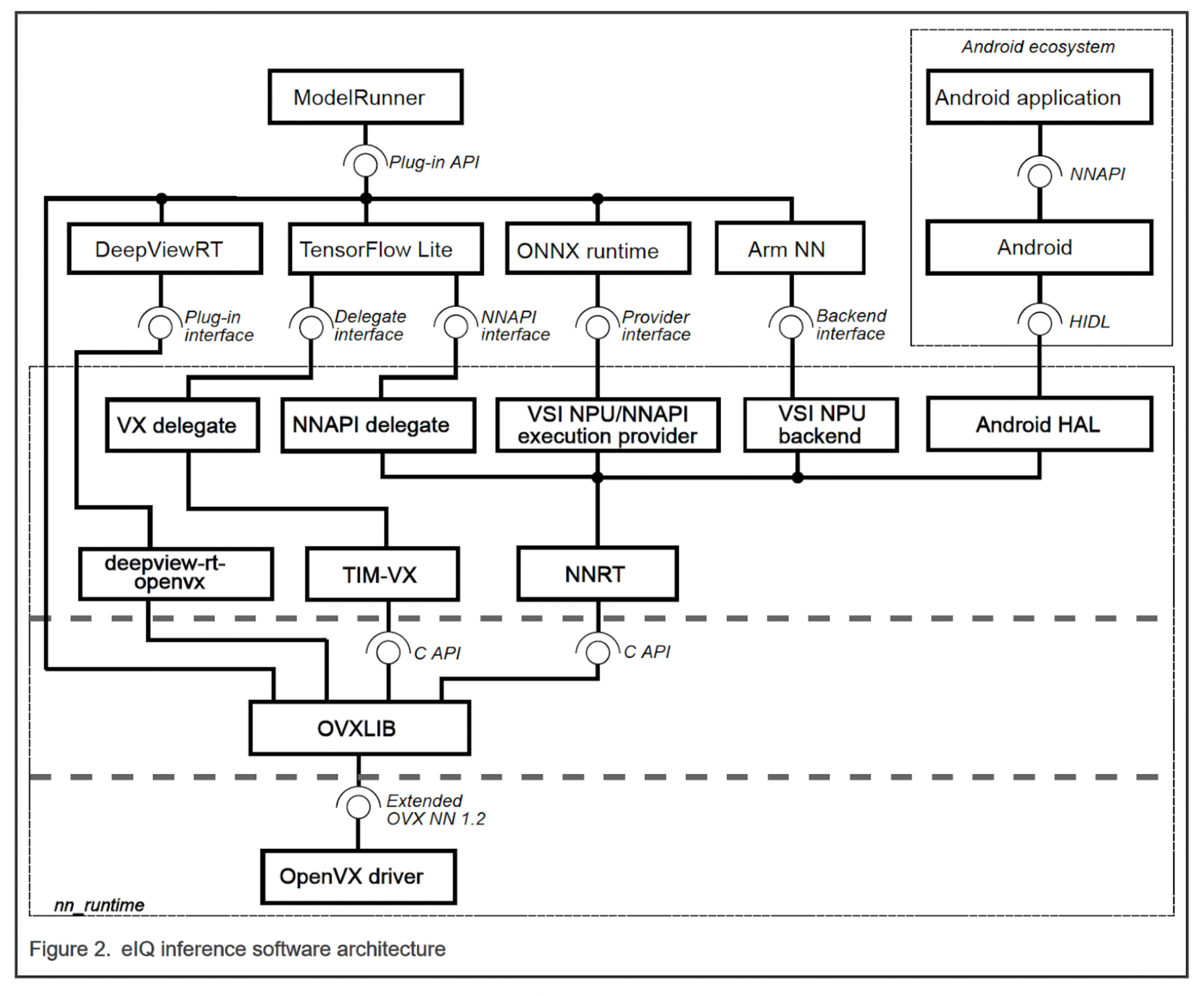
eIQ Inference RuntimeはNPUを使った推論を実行するためのランタイムとしてTensorflow Lite、ArmNN、ONNX Runtimeに対応しており、それに加えてDeepViewRTという独自ランタイムが用意されています。いずれもPython, C++のAPIから使用する事ができます。下図はi.MXシリーズのユーザガイドから引用したeIQ Inference Engineのアーキテクチャ図になりますが、どのランタイムについても最終的にはOpenVXドライバを介してNPUにアクセスし推論を行うような仕組みになっているようです。
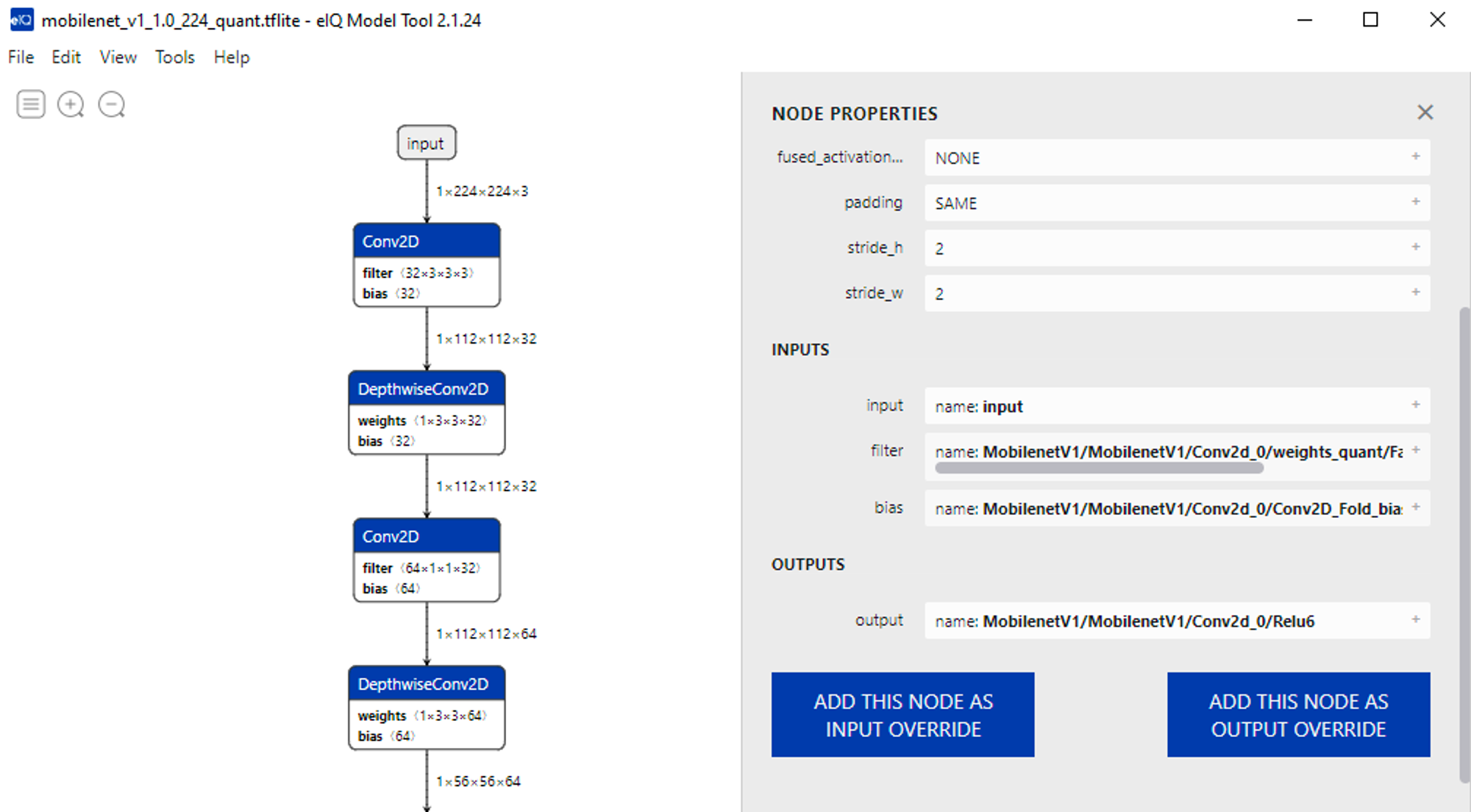
TDA4VM同様にランタイム上でモデルを読み込んで動作させるためには、ホストPC上で専用のツールを使ったモデル変換を行う必要があります。この操作にはeIQ Toolkitに含まれるeIQ PortalというGUIツールを使います。このツールを使う事により簡単な操作で学習済みモデルの読み込み、変換パラメータの設定、変換後のモデルの確認といった操作を行う事ができます。
下はユーザガイドからのキャプチャになります。このように読み込んだモデルと変換後のモデルを表示し内容をチェックする事が可能なので便利です。
また、今回は学習済みモデルのベンチマークが目的なので深くは触れませんが、eIQ PortalではTensorflowを使った学習もサポートしており、GUI上で学習の進捗確認や精度の検証といった事も行えるようになっています。
モデル変換とベンチマークの実施手順
モデル変換に使用するeIQ Toolkitは、ホストPCとしてWindowsあるいはUbuntu 20.04の環境に対応しており、インストールするとeIQ PortalというGUIツールが使えるようになります。実際にeIQPortalを使ってDRIVE CHARTで使われているモデルの変換を試しましたが、特定のモデルで未対応operatorがあったというエラーが出た事を除いてはスムーズに変換を行う事ができました。量子化についてもモデル変換時のダイアログ中に以下のような設定箇所があり、簡単に対応できます。
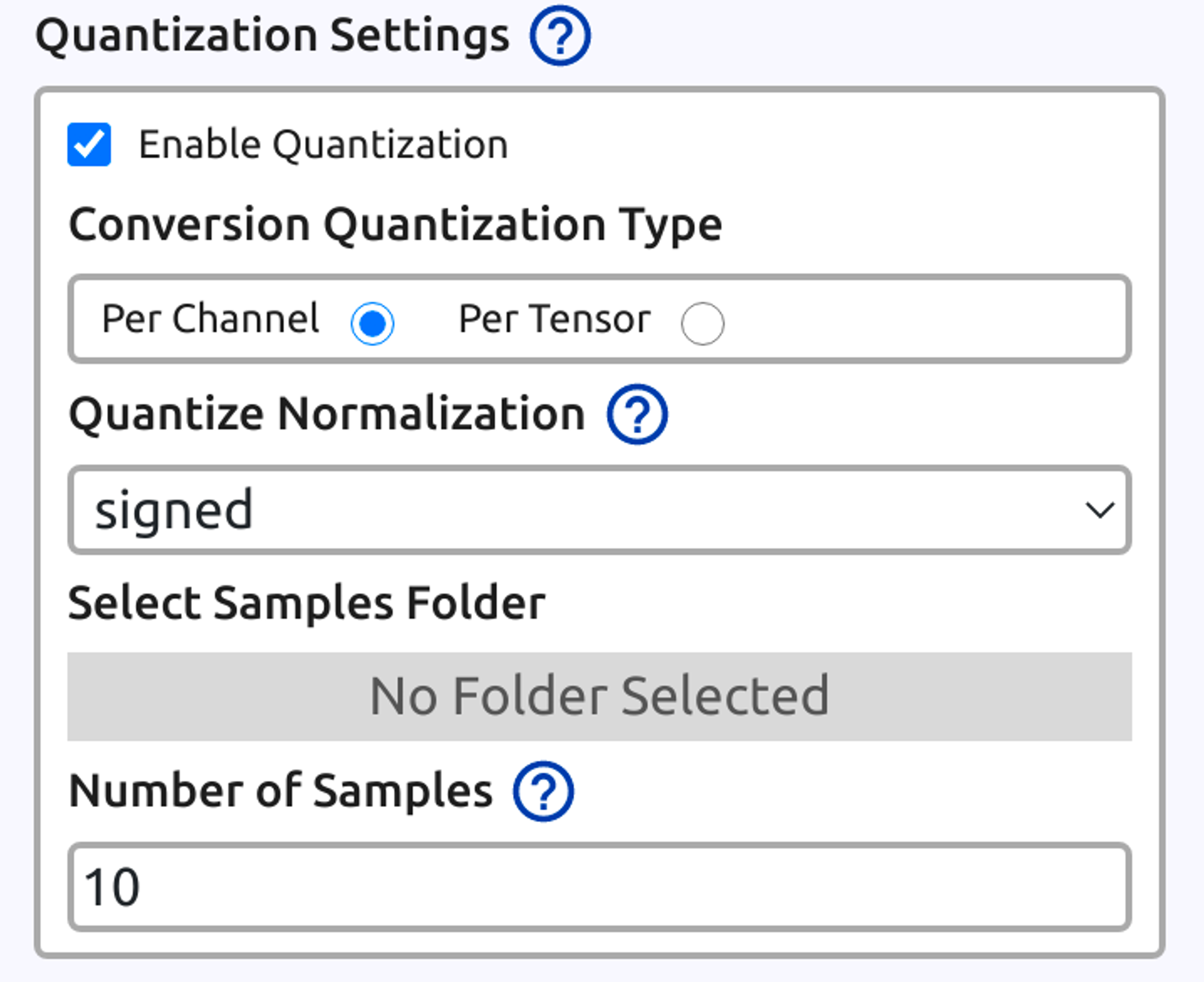
量子化変換タイプはPer ChannelとPer Tensorがあり、必要に応じて切り替える事ができます。また、量子化パラメータのキャリブレーション用の入力画像フォルダ、使用枚数、正規化タイプ(signed, unsigned)を設定する事が可能です。
ベンチマークに関しては、デバイス上でModelRunnerというCLIツールを起動しておく事でeIQ Portalが変換モデルの転送とベンチマークを実行して結果をプレビューする機能があるのでこれを使うのが簡単です。HTTP経由で通信を行うため、事前にeIQ Portal側でデバイスのIPアドレスを設定しておく必要があります。
ベンチマークが終わると上で示したようなモデルプレビュー画面上で、推論全体の処理時間だけでなく、各operatorにかかった時間も表示してくれます。ただ、ModelRunner側で設定できる推論プロセッサ選択でNPUを選んでベンチマークを行うと先頭付近のoperatorが処理時間の大半を占めてしまうなど不自然な結果になったので、operator毎のベンチマークはまだ完全にはサポートされていないのかもしれません。
今回はTFLite向けのモデル変換を試し、NPU推論モードでのベンチマークを実施してみましたが他の検証デバイスと比べて極端に遅いという結果になりました。変換後モデルを見るとすべてのConvolution operatorの前後にNHWCとNCHWの変換operatorが挟まるようになっていたので、このあたりの変換がうまくいってないのが原因かもしれません(TFLiteがNHWCを入力として処理を行うため変換していると思われる)。
ベンチマーク
実際のモデル変換を行った際の性能評価がうまくいかなかったため、代わりにvarisciteのブログ記事を参考にサンプルに付属しているMobileNetV1のモデルでのベンチマークを試したところ、2.8[msec]という結果になりました。4TOPSの性能を持つEdgeTPUのベンチマークでは2.4[msec]だったので、思ったより速いという印象でした。
感想
以下にi.MX 8M Plusの良いと思った点を列挙します。
- MobileNetV1でのベンチマーク結果を見た感じでは計算性能は高そう
- ドキュメントが充実。Python版しかみていないがサンプルコードもわかりやすい
- eIQ Toolskitを使う事でPC上からモデル変換やベンチマークを簡単に実行できる
- VPU使う事でビデオデコード/エンコード処理のオフロードも可能(CPU負荷の軽減)
- SoMタイプを使用して実際のハードウェアを作った場合、後から高性能なSoCが出てきた時の差し替えとかが簡単そう
- OSの選択幅が広い(今回はYoctoを使ったが、その他にAndroid, Debian, FreeRTOSに対応)
モデル変換周りなどにはまだ課題はありそうですが、AI以外のマルチメディア性能も高い事から使い所は色々ありそうだと思いました。
Rockchip RK3399Pro
ハードウェア概要
Rockchipは中国のRockchip社が設計するARMベースのSoCシリーズになります。その中でもRK3399Pro、 RK1808をはじめとしたいくつかのSoCには、Neural network Processing Unit (NPU) と呼ばれるニューラルネットワーク推論専用の演算コアが搭載されています。このNPUは公開スペック上ではINT8での演算性能が最大 3.0 TOPS と比較的高い性能が示されています。ただし、NPUはデータ型として、INT8 / UINT8 / INT16 にしか対応していないため、事前に量子化する必要があります。今回、RK3399Proが使われているTinker Edge Rというボードを使って調査、評価を行いました。
対応フレームワーク
Rockchip NPUでニューラルネットワークモデルを動作させるためには、対応フレームワークで学習されたモデル(もしくはそこから変換されたモデル)をRKNN toolkitというツールを用いて所定のフォーマット(RKNNフォーマット)へ変換する必要があります。RKNN toolkitにはPython APIとGUIがあり、それらを用いてモデル変換や量子化、RKNNフォーマットのモデルの実行を行うことができます。このRKNN toolkitが扱えるフレームワークは次の通りです。
- Caffe
- Darknet
- Keras
- MXNet
- ONNX
- PyTorch
- TensorFlow
- TensorFlow Lite
また、それぞれのフレームワーク内で対応しているオペレータについてはドキュメントに詳しい記述があります。対応するフレームワークは他のAIアクセラレータと比べて豊富で、動作させる上での制約としては緩い部類に入るのではないかと思います。
量子化
量子化にあたって様々なオプションがありますが、RKNNがサポートする量子化のオプションは以下のようになっています。
- データ型:INT8, UINT8, INT16
- テンソル(レイヤー)ごとの量子化(チャネルごとの量子化はサポート外)
RKNN toolkit自体にも量子化の機能はありますが、Pytorch, ONNX, Tensorflow (Lite) の場合、量子化(学習後量子化、もしくは量子化を考慮した学習)済みのモデルを読み込むこともできます。量子化済みのモデルを読み込む際にはパラメータのみの量子化(動的量子化、dynamic quantization)ではなく、パラメータと中間層を含めた量子化(静的量子化、static quantization)となっている必要があります。一方で、RKNN toolkitを用いて量子化する場合は量子化パラメータ(値域)を決めるためのキャリブレーションデータが必要になります。基本的には量子化パラメータはRKNN toolkitの実装する量子化アルゴリズム(MMSE もしくは KL divergence)よって自動的に計算されますが、RKNN toolkitがHybrid quantizationと呼んでいる方法で手動で設定することもできます。そのため、RKNN toolkitが実装していない量子化アルゴリズムを自分で実装して使うことも可能になっています。
推論ランタイム
Rockchip自体がARMベースのCPUを搭載したSoCのため、NPUを使うためにはそれに対応したOSが必要となります。具体的にドキュメントに記載があるのはLinux (Debian-based)と Androidになります。
NPUを利用するためのAPIとして次の言語が利用できます。
- Python (RKNN toolkit)
- C (RKNPUTools)
Python APIだと動作確認やモデルのベンチマーク、プロファイリングが簡単にできる反面、組み込みやパフォーマンス要件が厳しい環境だとPythonを使うことが難しいため C API を利用することになるのではないかと思います。
ベンチマーク
今回のベンチマークではPytorchで学習されたモデルをONNXにエクスポートし、そこからRKNN toolkitを使ってRKNNフォーマットに変換されたモデルを利用しました。また、RKNN toolkitに含まれているベンチマーク用のAPI RKNN.eval_perf() を用いて計測しました。結果は最後のまとめに記載しています。
感想
以下にRockchip NPUの良いと思った点を列挙します。
- 対応フレームワークが多い
- モデル変換から実行・ベンチマークまでのAPIが揃っている
- 量子化パラメータがカスタマイズできる
- Github上にドキュメント、サンプルが公開されている
Rockchip NPUはEdgeTPUなどに比べると認知度はまだ低く、採用事例もあまり聞いたことはなかったのですが、ベンチマーク結果も優良でポテンシャルは高いのではないかと思います。
Google Coral EdgeTPU
ハードウェア概要
EdgeTPUはGoogleによって開発されたエッジ端末用の推論デバイスで、TensorFlow Lite (TFLite)のバックエンドとして利用することができます。EdgeTPUはINT8の演算のみをサポートしているため事前に量子化する必要があります。様々なデバイスがリリースされており、例えば、Dev Board、USB Accelerator、Dev Board miniなどがあります。今回はDev Board を購入し評価を行いました。
対応フレームワークと推論ランタイム
EdgeTPUでニューラルネットワークモデルを動作させるためには、Tensorflow/Kerasで学習されたモデルをまずTFLiteの量子化モデルに変換して、そのあとedgetpu_compilerというツールを用いてEdgeTPU向けのフォーマットにコンパイルする必要があります。
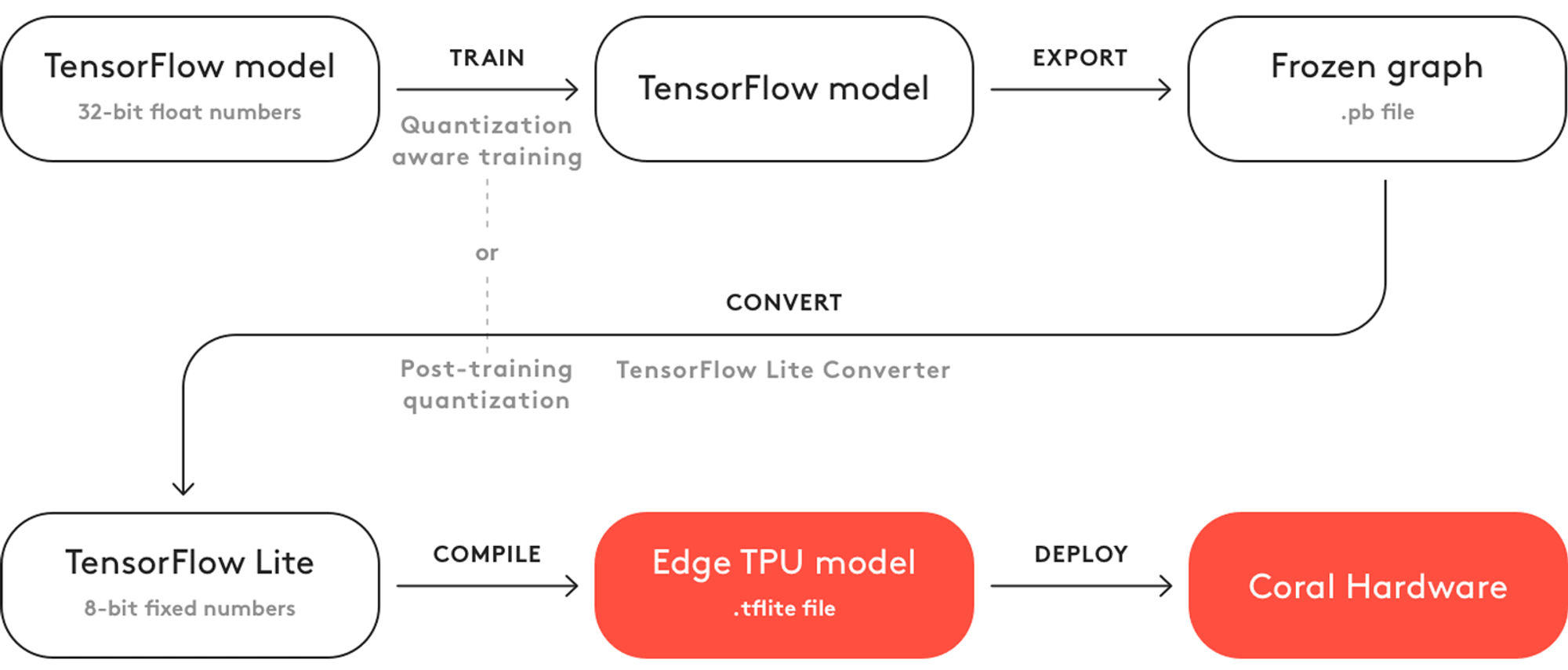
The basic workflow to create a model for the Edge TPU
また、Tensorflow/Kerasからの変換が容易ですが、他のフレームワーク(Pytorch、ONNXなど)からもTFLiteへの変換ができれば、そこからEdgeTPU向けにコンパイルする事も可能です。
推論ランタイム
TensorFlow Lite API(Python, C++)を利用することでEdgeTPU上で推論を行うことができます。また、TensorFlow APIやその他の高度な機能をラップする便利な関数を提供するCoral API (Python: PyCoral, C++: libcoral) を使うこともできます。これらは低水準なlibedgetpuを内部的に利用しています。非推奨ではありますが、libedgetpu自体のPython API も用意されています。
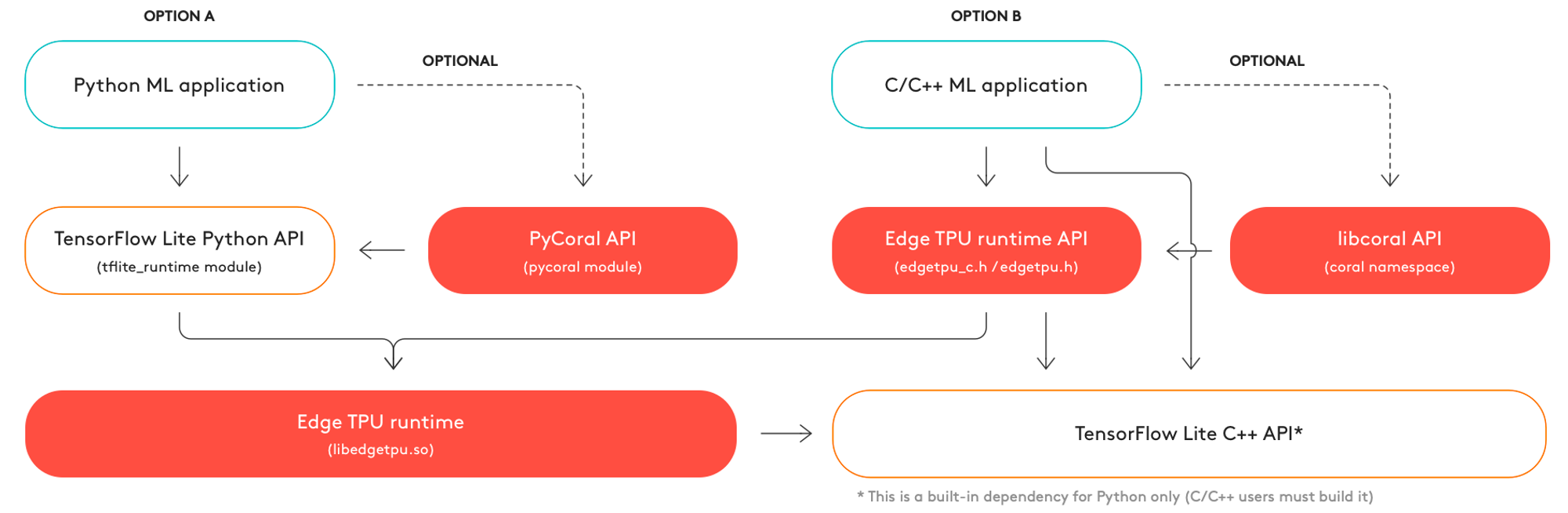
The three options for inferencing and the corresponding software dependencies
ベンチマーク
今回のベンチマークではTensorFlow Lite Python APIを用いてkerasモデルから量子化済みのtensorflow liteモデルに変換し、そこからEdgeTPU コンパイラコマンドラインを使ってEdgeTPUフォーマットに変換したモデルを利用しました。また、EdgeTPU の推論用のAPI interpreter.invoke() を用いて計測しました。結果は最後のまとめに記載しています。
感想
以下にEdge TPUの良いと思った点を列挙します。
- EdgeTPUの仕様が複雑ではなく、Python APIとC++ API両方も使える。
- モデル変換から実行・ベンチマークまでのAPIが揃っている。
- EdgeTPUに関するドキュメント、サンプルがGoogle社に公開されている、ネットで他の参考資料も多い。
EdgeTPUの認知度は高く、採用事例も多く、Keras、Tensorflowで学習済みモデルからの変換は簡単でした。一方、Pytorchなどのフレームワークで学習済みモデルからの変換は工夫が必要でした。
まとめ
最後にそれぞれのデバイスで実際にDRIVE CHARTで使われているモデルを使った時の推論時間をグラフにまとめてみました。なお、モデル変換が全般的にうまくいかなかったi.MX 8M Plusについては省略しています。
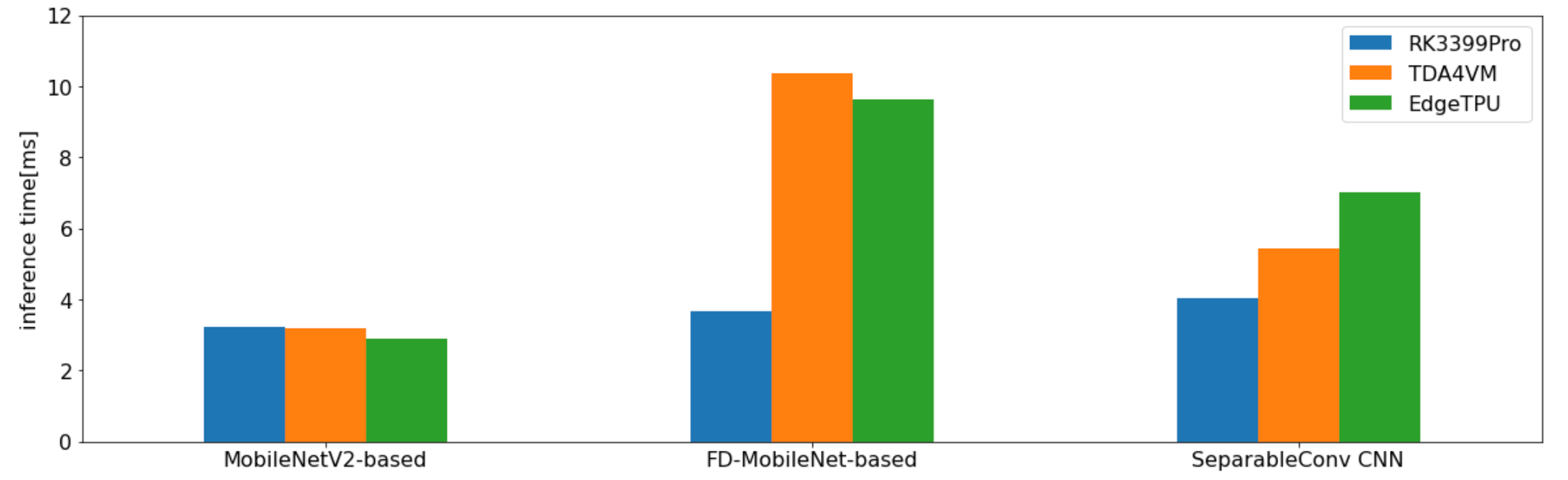
i.MX 8M Plusに限らず、今回のベンチマーク計測は各デバイス一週間という限られた期間内での調査の中で行ったということもあり、AIアクセラレータの性能をフルに活用できて得られた結果であるとは考えていません。
それに、実際のプロダクトで使うようなデバイスの選定ではこのようなベンチマークだけでなく、価格や消費電力、それにモデル変換ツールの使い勝手やAIの精度検証をPC環境でエミュレートする機能の有無なども考慮する必要があります。今後もう少し正確なベンチマーク測定を行った上で上記のような観点での比較評価も行い、今回の選定では対象から外したデバイス群も含め実際の選定をやっていきたいと考えています。
さいごに
今回、Engineer Challenge Week という弊社の新しい施策を利用して、AIアクセラレータの調査を行いました。前々から興味はあったものの、業務には直接結びつかないところでもあり、なかなか本格的な調査に手をつける事ができなかった分野だったのですが、この機会を利用して取り組む事ができました。
実際に調べるまで市場にどのようなアクセラレータがあるか、またそれらはどのような仕組みで動作しているか等々わからない事だらけである事に気付かされましたし、調べていく中でそういった知識の穴を埋めていく事ができ、チーム全体の技術レベルの向上にもつながったと感じています。
次回も機会があればさらに深堀りをしていくか、あるいは新しい技術にもチャレンジしていきたいと思います。
We're Hiring!
📢
Mobility Technologies ではともに働くエンジニアを募集しています。
興味のある方は 採用ページ も見ていただけると嬉しいです。私たちのチームでもエンジニアを募集しています。
Twitter @mot_techtalk のフォローもよろしくお願いします!