

分析基盤を Cloud Composer & trocco 構成に刷新しました
行灯Laboデータ基盤October 10, 2019
💁🏻
※本記事は Mobility Technologies の前身である JapanTaxi 時代に公開していたもので、記事中での会社やサービスに関する記述は公開当時のものです。

2019年7月に分析基盤を Cloud Composer & trocco の構成に刷新しましたのでご紹介させて頂きます。
従来の構成や経緯につきましてはこちらの記事を参照ください。
分析基盤構成
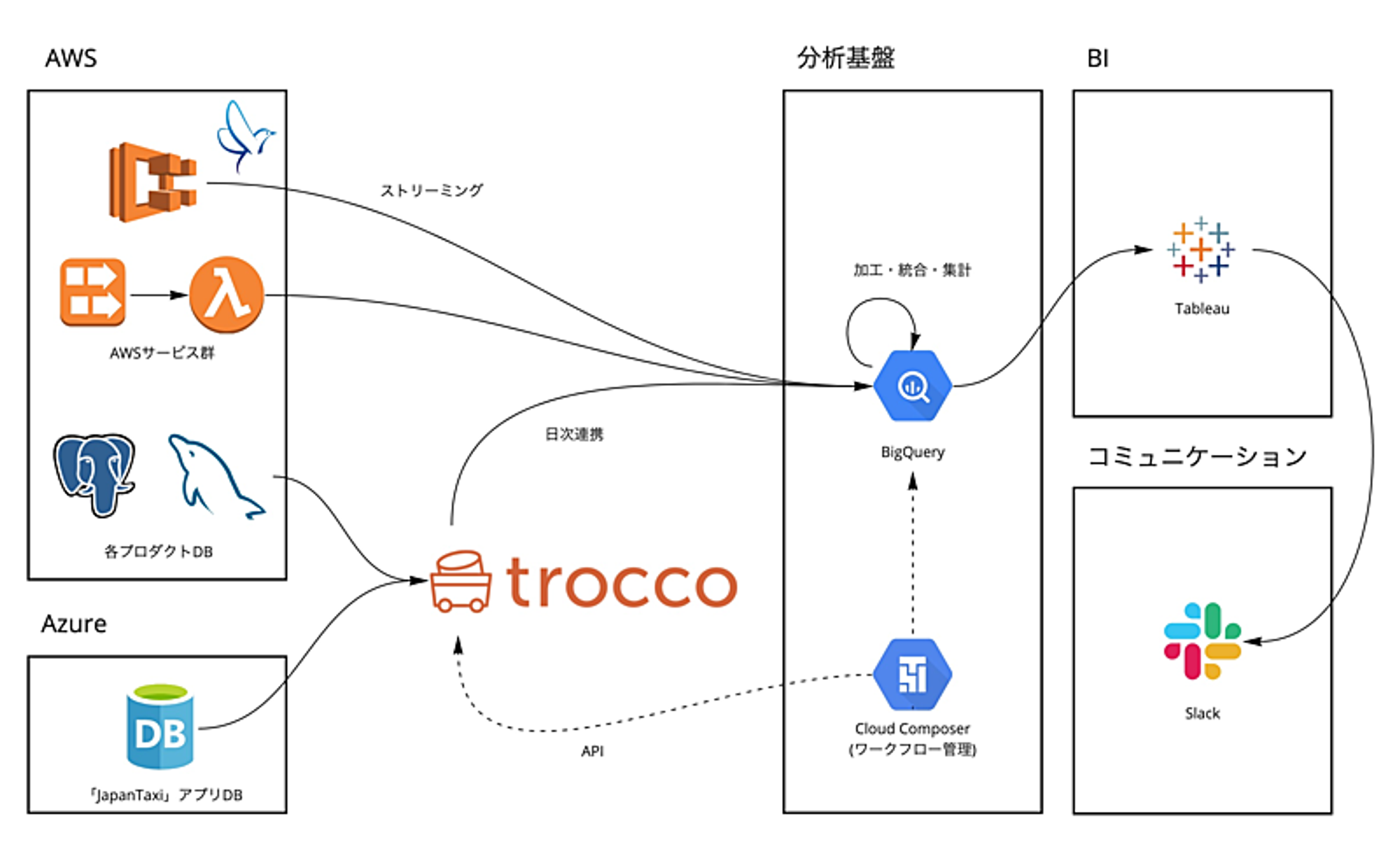
だいぶ簡略化していますが、現在の分析基盤の構成です。GCPのCloud Composerが分析基盤のワークフローを管理、trocco(https://trocco.io/)がクラウド間データ連携を担っています。
尚、データ連携はストリーミング方式と日次連携でデータを組み上げるバッチ処理方式があります。
※troccoは 株式会社primeNumber 様 (https://primenumber.co.jp) のプロダクトです
※troccoはバッチ処理に使用しています
保有するデータについて
保有するデータについて、メインは先日800万DLを突破した弊社「JapanTaxi」アプリに関するデータです。 ただ、それだけにとどまらずタクシードライバー様を支援するJapanTaxi DRIVER’S、JapanTaxi タブレットの決済情報、タクシー車両の位置情報など多岐にわたるデータを保有しています。
なぜリプレイスしたのか
プロダクトが成長するにつれて徐々にデータ量が増大し、パフォーマンスの低下が発生しました。また、このままデータ量が増え続けるとインフラのコスト増も想定されたため2018年12月ごろからリプレイスの検討を始めました。
※実際にリプレイスをするまで一時的なコスト増へと繋がりました
主な課題を整理すると下記の通りになります。
- 処理時間の推移が可視化できない(いつからパフォーマンスが劣化し始めたのか)
- ワークフローの依存関係が把握しづらい
- 情報が二重に蓄積されることに起因するいくつかの弊害
ただし、パフォーマンス低下について一つ一つ精査したところ、主要因はインデックスがきちんと張られていなかったことによるものと判明しました。こちらはSREチームと連携し、地道にチューニングを実施して改善しました。
Cloud Composerの採用理由
※本記事とは別にCloud Composerについて記事を執筆する予定です
- マネージドサービス
- 処理時間の推移が可視化できる
- ワークフローの依存関係が明確になる
- 環境を複数用意できる
- 個別にファイルをデプロイできる
- 開発言語がPython
troccoの採用理由
弊社はマルチクラウド環境であるため、どうにかデータをGCP BigQueryに連携する必要がありました。分析基盤の中心にGCP BigQueryを据えているため同じGCPのサービスであるCloud Composerの採用は上記の理由もあり自然な流れでした。
そうした中でEmbulkのマネージドサービスがあれば……という時にtroccoというサービスを見つけました(なければ自前で運用しなければなりませんでした)。
troccoの採用理由は下記の通りです。
- SaaS
- Embulkで動いている
- ジョブ実行のためのAPIが用意されている
- データソースからBigQueryに直接データ連携できる
- 設定が簡単(ただしGUIベース)
- 特に元のDBで動作するSQLをそのまま移植するだけでよい
troccoはデータ連携に特化したサービスでCloud Composerと相性が良いです。
本番運用を開始して3ヶ月が経ち良かったこと
プロジェクト開始当初の主な課題が解消されました。
- 処理時間の推移が可視化できるようになった
- ワークフローの依存関係が明確になった
- 情報の二重蓄積が解消された
もう少し掘り下げますと
- インフラのコストを抑えることができた
- 二重連携の時間ロスが解消された
- 二重開発が解消された
- 開発環境を用意することができた(今まで本番環境しかなかった)
- 本番運用が始まってから目立った障害が発生していない
- Cloud Composerの工夫とtroccoのわかりやすさにより開発コストおよび教育コストが下がった
なども良かった点です。
今までの運用課題を踏まえてリプレイスしたこともあり、障害対応の頻度が下がりました。これは単純に他のタスクに稼働を割り当てられるようになり良かったと思います。
また、教育コストが下がったことでデータアナリストでもパイプラインを整備しやすくなりました(自分でデータを集計加工できるようになった)。これにより少人数のBIチームを機能させることにも繋がっています。
最後にtroccoについてもう少しご紹介
接続情報
troccoは様々なデータソースと連携できます。各データソースと連携するために接続情報を入力します。※管理者以外参照できません
Cloud ComposerからtroccoのAPIを実行する際はtroccoのAPIトークンをCloud Composer側に持つだけ良く、各接続情報はtroccoで一元管理されます。

※接続先は今後も増えていくそうです
メインで使用しているのはSQLServerですが、他にもAppStoreと連携できたことにより今までCloud Functionsで取得していた処理が葬られました。
接続設定
設定例としてSQLServerからBigQueryに連携する処理をご紹介します。
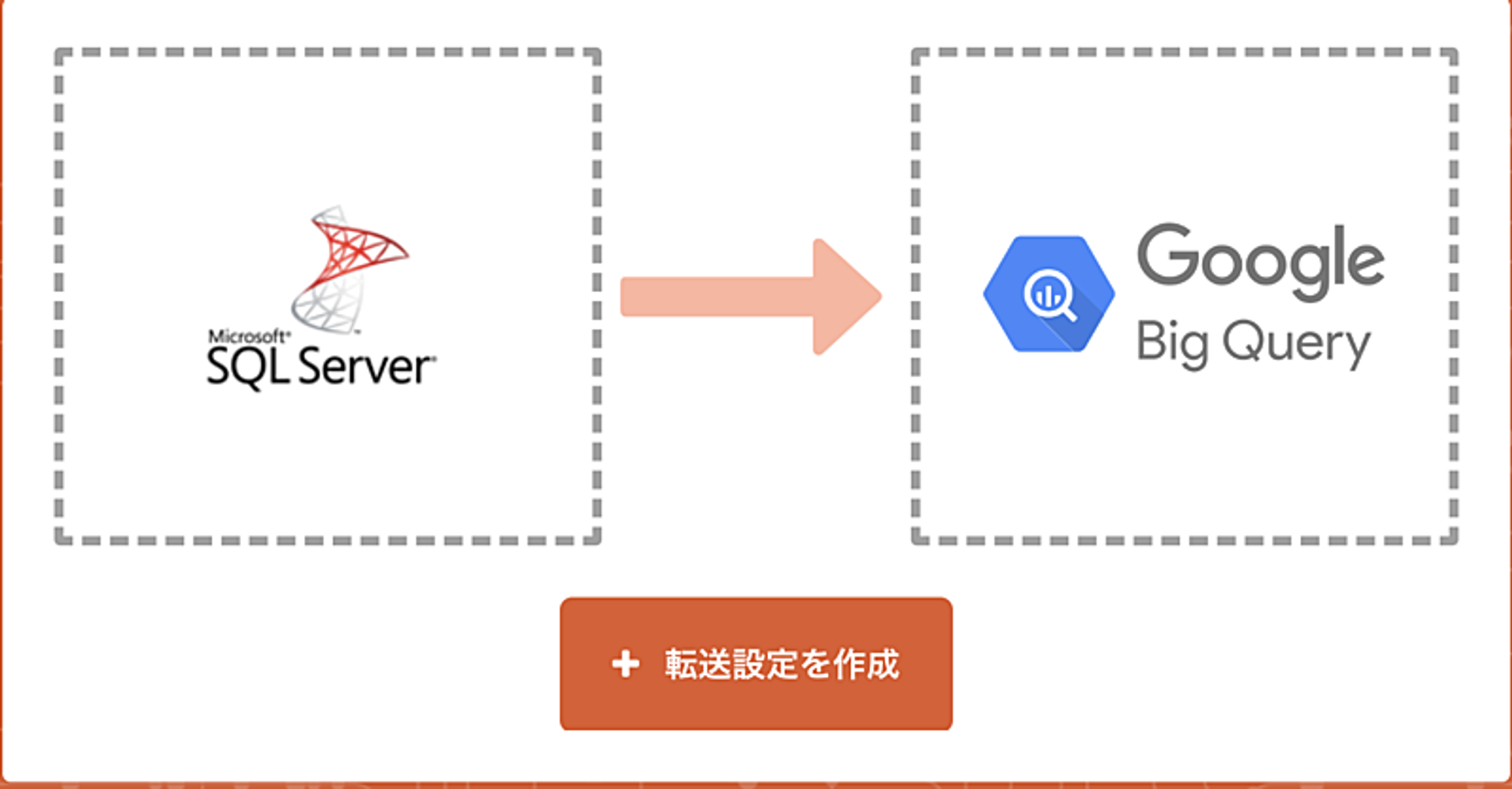
転送元
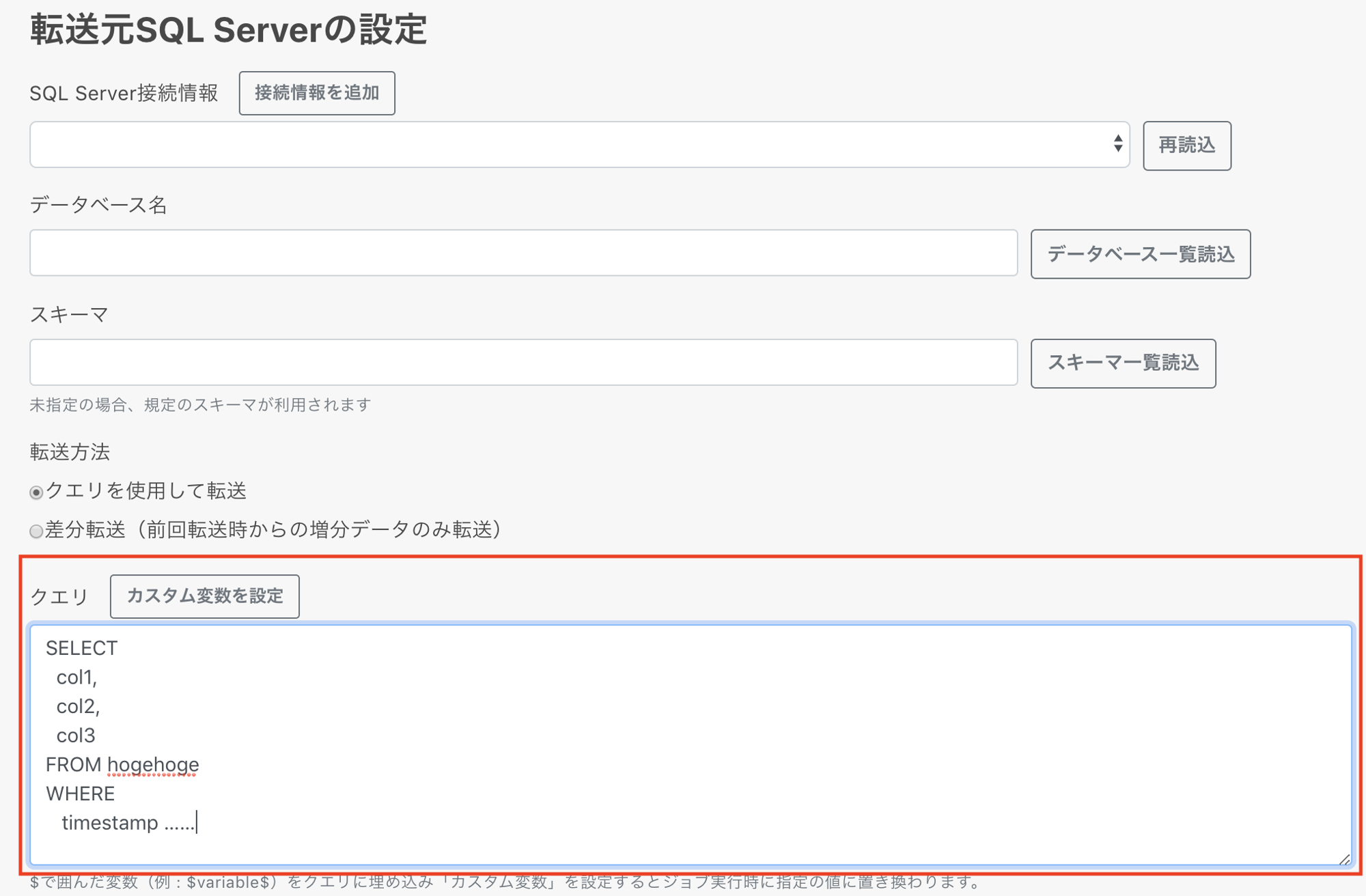
転送元のDBで動作するSQLを移植すればOKなので簡単です。
転送先
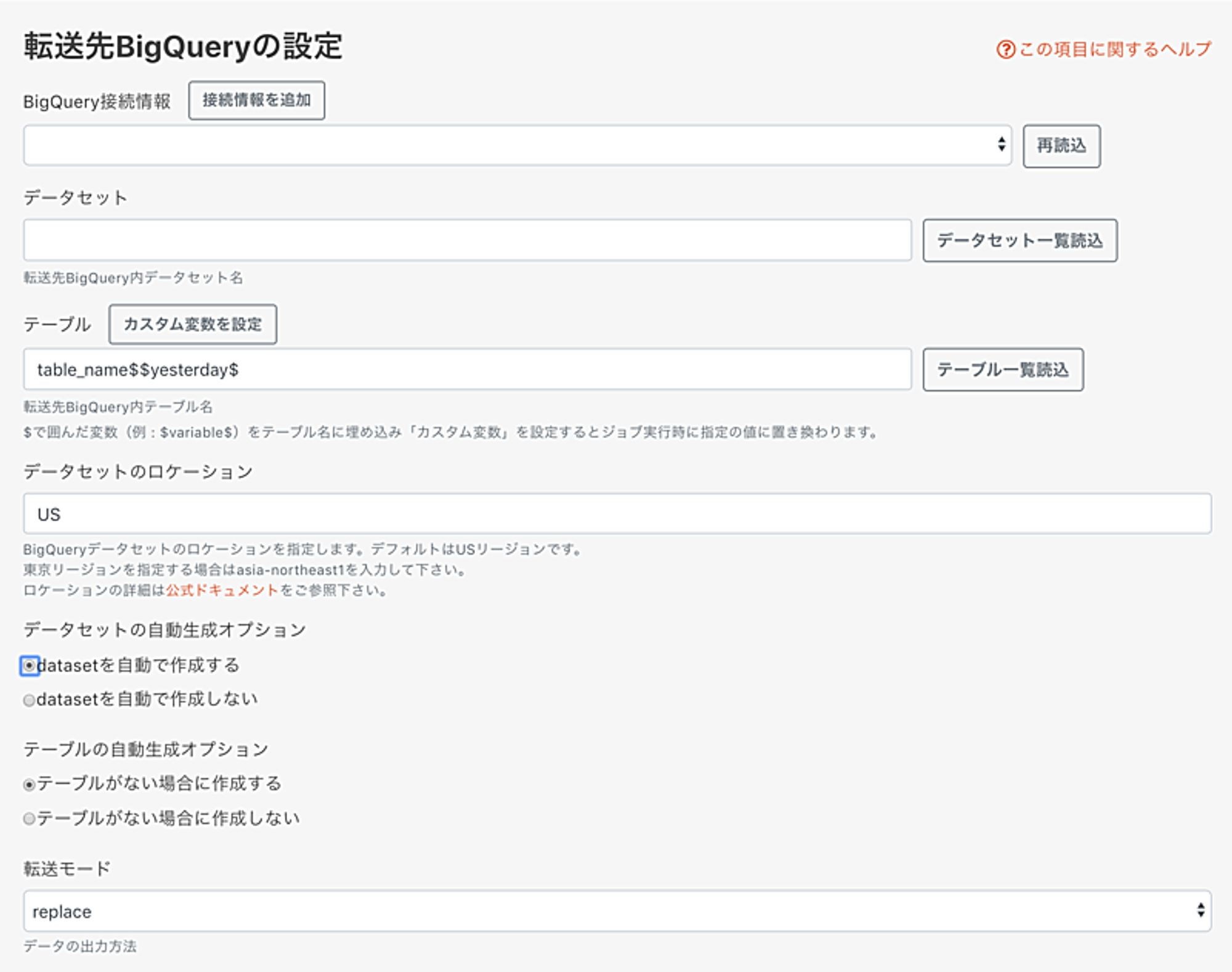
日付のカスタム変数&replaceオプションを設定することで特定の日付パーティションにWRITE_TRUNCATEで転送できます。
※日次処理では昨日のデータを取得し、そのデータを昨日日付のパーティションに格納したい場合があるので冪等性が担保される処理が必要となる
詳細設定

trocco自体にもリトライ機構があります。
また、Cloud ComposerからAPI起動しているので使用していませんが、troccoにはスケジュール起動できる機能も備わっています。
設定完了
設定が完了すると転送元、転送先の設定内容が表示されます。
ちなみに複製ボタンを使うとジョブ自体がまるまる複製されます。複製されたジョブをもとに、クエリと転送先のテーブル設定を書き換えれば同じ転送元からのジョブを簡単に増やしていけます。
設定ファイル(JSONのエクスポート)
ただ、GUI上不安となるのは誤操作です。意図せず変更して保存してしまった場合はなかなか気づくことができません。そのため設定完了後に設定ファイルをJSONでエクスポートできるようになっています。
最後に
troccoは今後も機能アップデートを予定しているそうなのでより便利に使えることを楽しみにしています。
💁🏻
※本記事は Mobility Technologies の前身である JapanTaxi 時代に公開していたもので、記事中での会社やサービスに関する記述は公開当時のものです。
Mobility Technologies では共に日本のモビリティを進化させていくエンジニアを募集しています。話を聞いてみたいという方は、是非 募集ページ からご相談ください!