

事業の要はデータ活用!タクシーITビジネスを支えるJapanTaxiの分析基盤とは?
行灯Laboデータ基盤March 01, 2018
💁🏻
※本記事は Mobility Technologies の前身である JapanTaxi 時代に公開していたもので、記事中での会社やサービスに関する記述は公開当時のものです。

まずはじめに、データ分析チームの仕事ですが、大きく以下の3つになります。特に業務内容自体に変わったものはないかと思います。
- 統計や機械学習などを使って、サービス・機能の新規創出やアプリの向上に貢献する
- 主にマーケティングや開発、セールスチームをデータを活用して支援する
- 分析などデータ活用のための分析基盤を構築、運用し、社内向けに提供する
私自身は、一番最後のデータ分析基盤関係をメインで担当しており、必要に応じて2つ目のデータ抽出や分析を行っております。
現在、分析チームは3人おり、ある程度役割を分けながら活動しています。
今回は、すべてのデータ分析活動を支える、一番最後のデータ処理基盤について、以下の内容をご説明して紹介したいと思います。何か皆様の業務のご参考になることなどあれば、嬉しく思います。
- 扱うデータについて
- データ処理基板の構成について
- 主要技術の選択ポイントについて
- 今後やっていきたいこと
1. 扱うデータについて
まずは、主にどういったデータを扱うかをご紹介したいと思います。
最も主要なデータは、弊社が提供している「全国タクシー」アプリのデータです。
特に、タクシーの配車依頼の注文レコードを主に扱います。注文には、ユーザ情報や時間、乗車/降車指定位置、指定されたタクシー会社、配車できたか否か、など様々な情報が入っています。あとは、「JapanTaxi Wallet」という決済サービスを提供しており、このサービスの利用状況もデータとして存在します。
その他、ユーザー様の登録情報やタクシー会社の登録情報、アプリを起動したログやFirebaseでロギングしたイベント情報、などなど様々な情報があります。
さらにさらに、アプリ以外の情報としては、弊社の母体である日本交通の乗車データも分析に活用しています。東京都内に走っている約4000台のタクシーの位置情報、乗車履歴などです。
これらのデータは、24時間365日常に発生しており数年前からデータベースなどに蓄積され活用されてきました。
2. データ処理基板の構成について
以前は、各サービスのレプリカ用のDBなどでデータの活用が随時行われてきましたが、今後のサービス拡充を想定し、コスト・パフォーマンス、スケーラビリティ、セキュリティなどの観点から専用のデータ処理基盤を構築する事になりました。
現在は、下記のような構成で分析基盤を構築し、運用しています。実際はもう少し複雑ですが、主要な構成要素だけ書いております。
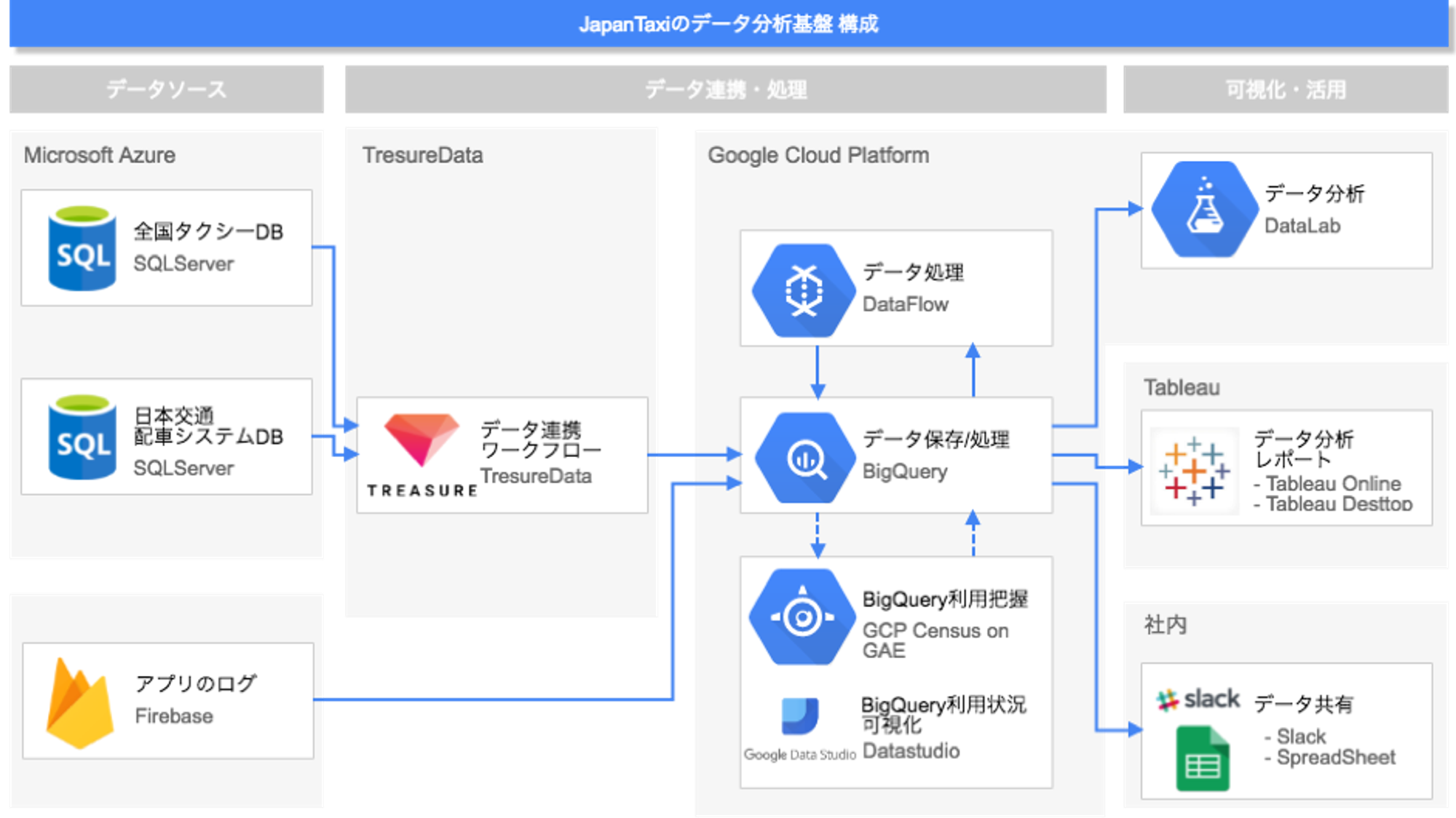
JapanTaxiのデータ分析基盤の構成図
それぞれの役割について、ポイントを掻い摘んでご紹介します。
データソースとデータ連携・保存
まず、データソースですが、主にAzure上のSQLServerとFirebaseとなります。
そして、データを溜め込んでいるのは、図のちょうど真ん中あたりにあるGoogle Cloud Platform(以降、GCP)上のBigQueryです。Firebaseは、それ自体の機能としてポチッとやるだけでデータをBigQueryにインポートできるため楽にデータ連携できています。SQLServerに関しては、TreasureDataのDataConnectorを使って一旦TreasureData上にデータを持ってきてからBigQueryに送っています。
データ処理と運用
BigQueryに持ってきたデータは、BigQuery上でデータの整形や分析用のテーブルなどを作成する処理をSQLでおこなっています。これらの処理はバッチ処理としておこなっており、処理の制御はTreasureDataのTreasure Workflowを使っています。
また、一部はGCPのサービスであるDataflowを使って整形などの処理をしています。
BigQueryの利用状況を把握するため、Google App Engine上でGCP CensusというOcado社が開発しているOSSも利用しています。これによりBigQueryのテーブルの数やサイズ、件数などを把握しています。
データ分析
そして、BigQueryから幾つかの分析やデータ抽出のツールを使ってデータの活用をしています。
機械学習などの処理をしたい場合は、DataLab等を使っています。実は、ここは各々の分析者が使いたい環境を使っています。EC2などに自分の環境を作っているメンバーもいます。BIツールとしては、基本的なデータの分析にTableau Desktop、KPIのなどの数値集計のためにTableau Onlineを使っています。
さらに、データ分析チーム以外のメンバーがデータにアクセスする手段として、Tableau Onlineで作ったレポートをSlackで共有したり、SpreadSeetからBigQueryのデータを抽出できるようにしています。
3. データ処理基盤の構成について
次に、なぜこういう構成にしたかという点で、主要技術の選択ポイントをお伝えしたいと思います。
まず、基本的な考え方として、運用に極力コストがかからないかつ人的な依存を発生させない方式にしたかったという思いがありました。ですので、基本的にサーバレスなクラウドサービスのマネージドサービスを中心に構成しています。
たとえば、Hadoopはビッグデータ分析用途で利用されるソフトウェアとして有名です。開発も非常に活発で様々な機能が利用できますが、経験上運用に非常に高いスキルとコストが求められると考えています。
先述の通り3人という少ない人数のデータ分析チームで基盤を運用していくためには、なるべく運用が楽なものを選びたいと思いました。
BigQueryについて
そこで、データ処理の要である部分にはBigQueryを採用しました。
メンバーが利用経験があったという理由もありますが、とにかく処理の速度が早いのが決定的です。クエリを打ってしばらく返ってこないようだと、ついついネットサーフィンしてしまいます。
また、今後の利用者数の増加を見積もってもコストパフォーマンスの観点からクエリを同時実行し易いということも有りました。クエリが同時実行しづらい環境だと、他人のクエリとのリソース競合に悩まされます。そして、通常ある程度の同時実行性を保とうとすると相応のキャパシティを平常時から持っておく必要があり、定常的にコストがかかってしまいます。
TreasureDataについて
TreasureDataを採用した理由は、データ連携の運用を楽にしたいという一点です。
通常TreasureDataサービスは大規模なデータの処理も十分に行えます。しかし、データ処理の中心は先述の通りBigQueryに担わせています。ただ、当然なんらかの方法でBigQueryにデータを連携する必要があります。
通常、データを連携するには、主にデータをエクスポート/インポートするツールとそれを実行制御する機能が必要になります。
実は、以前これをDigDagとEmblukというOSSツールで仮想マシン上に構築して運用していました。ただ、この先これを要求に応じてスケールさせたり、エラーや不具合の対応を自前でやるのはコストが掛かると想定しました。そこでこの機能をTreasureDataサービスのDataConnectorとTreasure Workflowで実現しようとなりました。
実際、スケールを気にすることなく、またなにか起きてもTreasuData社のスピーディかつ丁寧なサポートで負担なく運用できています。
社内の共有について
データ分析チームでは、Tableauなどのツールを使って日々データにアクセスしています。(ちなみに、Tableau Desktop + BigQueryは非常に快適な環境です。これに慣れると他が辛くなるくらいではないかと思います。)
加えて、社内でも様々な人がデータにアクセスしたいと考えています。経営層もそうですし、マーケティングのメンバーあるいはセールスのメンバー、はたまた開発チームなどです。それぞれの役割ごとに見るデータと見方が変わってきます。それは主に業務内容とエンジニアリングスキルに依存すると考えています。
例えば、セールスチームは、SQLを利用できる人が少ないので、データをそのまま扱えるサイズに集計して落とし、スプレッドシートで手軽にデータにアクセスできるようにしています。表計算ソフトはある意味最強です、利用の学習コストがほぼいりませんから。
その他、経営層を中心として全社で見ているKPIなどの数値は、Tableau OnlineでレポートにしてPushMetricsというサービスを利用してSlackに日々流しています。Slackは、社内の標準コミュニケーションツールなのでここで直接数値が見れることが重要だったりします。これにより数字的に何か(いいこと悪いこと両方ですが)あったときにすぐに議論に入れます。
以上簡単ですが、各種技術・サービスの採用理由をご説明しました。
4. 今後やっていきたいこと
最後に、今後データ分析の基盤をどうしていきたいかについて少し書かせていただければと思います。
約2ヶ月ほどこの基盤を運用してきました。ある程度データに通じた分析チームや一部の開発メンバーなどが使う分にはそこそこ十分だと思います。そして今後は、社内の他のメンバーがより自律的にデータにアクセスしたり、それを使って分析したりできることが、私は望ましいと考えています。
その理由は、例えば、どこの会社でもよくあることだと思いますが、他のチームで発生した問題等の分析や他チームの活動で利用するデータの抽出の依頼がデータ分析チームに来ることがあります。
分析や抽出処理自体が何かしら難易度が高かったり、意図しない結果を招きそうなデータセットしかない(例えば、生データに近いものだったり)場合、データ分析チームで行う必要があると思いますが、その反面そのアウトプットを待つ必要があるため依頼元である他チームのスピード感が失われることにもなります。
また、JapanTaxiに入社して約半年経ちましたが、データを使ったファクトで意思決定していないのではないか、という場面が何度かありました。ファクトに基づくことは大事だと理解していてもそれをすぐに明らかにできなければ、タイムアップとなりとにかく物事を決めざるを得ない現実もあります。そしてまた、社内の多くのメンバーがデータを見て判断や意思決定、あるいはお客様への提案をしたい、あるいはすべきという意気込みや思いを感じてきました。
ですので、誰もがデータを扱える環境は、JapanTaxiにとって相当重要だと強く思って日々仕事をしています。
そのためには、データについての仕様をドキュメントにする必要もあるでしょうし、ある程度目的に沿った扱い易いデータセットを用意しておくことも大事だと思います。また、分析ツールなどを使えるように社内のトレーニングや製品の選定なども必要だと考えています。
今、少しずつそれらに向けて着手しています。
また、そのあたりの取り組みや結果は、ブログで共有したいと思います。
開発部 データ分析チーム 饗庭
💁🏻
※本記事は Mobility Technologies の前身である JapanTaxi 時代に公開していたもので、記事中での会社やサービスに関する記述は公開当時のものです。
Mobility Technologies では共に日本のモビリティを進化させていくエンジニアを募集しています。話を聞いてみたいという方は、是非 募集ページ からご相談ください!