

タクシー走行の模倣学習に関する研究論文が「The Web Conference 2021」に採択されました
AI学会論文NewsAI技術開発部アルゴリズムグループの織田です。 この度、自身が取り組んでいた研究「Equilibrium Inverse Reinforcement Learning for Ride-hailing Vehicle Network」がWeb・データマイニングに関する国際会議「The Web Conference 2021」にて論文採択されましたので、内容を紹介したいと思います。
研究の背景
当社は配車サービス「GO」を提供しており、ユーザーの要求に応じて適切な車両を割り当てることで、ユーザーとタクシーのマッチングと車両運行の最適化を目指しています。一方で、タクシー乗務員は空車時には、これまでの経験に基づいて各々が自由に乗客を求めて走行するため、未来の状態には不確実性が伴います。したがって、リアリスティックなタクシーの走行経路をシミュレートすることができれば、マッチングアルゴリズムの改善や施策意思決定に役立つでしょう。また、今後MaaSや自動運転を社会実装していく上でも、より詳細で信頼性の高いシミュレーション技術は非常に重要になっていくと考えています。
チャレンジ
タクシーの走行経路を模倣するためにはいくつかの課題があります。一般的に道路ネットワークのようなスパースな道路グラフ構造は計算量が多くなる傾向があるため、抽象化して粗いメッシュで表現されることが多いですが、道路レベルの行動を模擬するには道路ネットワークの効果的なモデリングが重要になります。例えばグラフニューラルネットワークのような手法を道路ネットワークのような大きなグラフに適応するのは、複雑さや計算コストなどの観点から現実的な困難が伴います。また、タクシー市場のシミュレーションは、車両数が数百台から数千台と比較的多く、非常に多くのエージェント間の相互作用を考慮する必要があります。さらに、学習データ分布に含まれない状態(オリンピック期間中のような特異的な需要が首都圏に発生した場合など)を模倣する反実仮想シミュレーションを行いたい場合には、環境ダイナミクスの変化に対してのロバスト性も不可欠です。
提案手法
そこで本研究では、タクシーなどのライドヘイリングサービスにおける道路ネットワーク上のドライバーの行動モデリングとマルチエージェントの報酬学習のアプローチを提案しました。
報酬関数はタスクの最も簡潔でロバストで転移可能な表現であると考えられているため、エキスパートの行動から報酬関数を推定する方法(逆強化学習と呼ばれる)は反実仮想シミュレーションのようなユースケースにおいて特に有用だと思います。マルチエージェントの設定では、一般に、各々のエージェントが自らの報酬を最大化するように行動することで均衡状態が実現します。本研究では現実のタクシー市場が「探客ゲーム」の均衡状態になっていると考え、現実の状態を再現するような均衡状態における方策(報酬関数)を推定するという問題設定となっています。
まず、報酬関数が仮に与えられた場合の均衡状態の方策と交通流(状態行動分布)を推定する問題を考えます。以下の3ステップを繰り返すことで、最終的に均衡状態における方策及び交通流を算出することができます。
- ベルマン方程式を繰り返し適応して状態価値Vと状態行動価値Qを交互に更新していくアルゴリズムである価値反復法により、方策を推定
- 初期状態分布(乗客の降車位置によって決まる車両の初期位置分布)からスタートし、決められた方策にしたがって状態確率を伝播させ、状態行動分布を推定
- 状態行動分布をもとに各行動における乗車確率と初期状態分布を更新
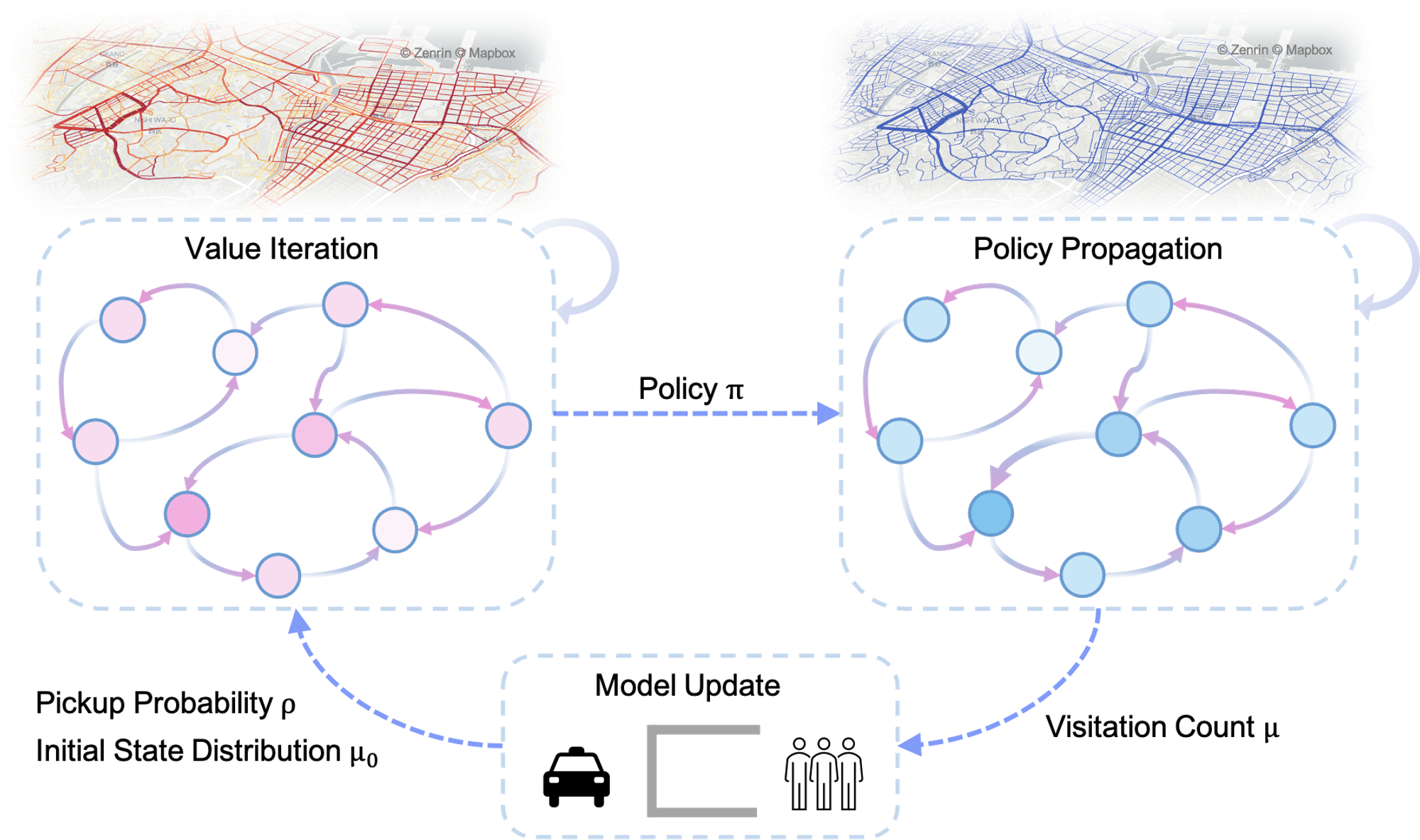
このようにして算出した均衡状態における状態行動分布がエキスパートの状態行動分布に近づくように報酬を更新していきます。ただし、あるエージェントからみると報酬関数をアップデート => そのエージェントを含む全てのエージェントの方策が変化 => 均衡状態における交通流が変化 => 乗車確率が変化、つまりダイナミクス(マルコフ決定過程における遷移確率)が変化することになります。提案手法では、このようなダイナミクスが変化するような場合における報酬学習の問題を定式化し、乗車確率が十分小さい状況ではMaxEnt IRL同様に勾配がエキスパートの状態行動分布と学習方策の状態行動分布の差に比例することを示しました。
実験結果
実験では横浜の繁華街エリアの軌跡データを用いて、評価を行っています。学習データとは大きく異なる分布を持つ2020年4月(COVID-19による緊急事態宣言の影響でタクシー需要が激減した時期)を含む期間をテストデータとして用いました。また、テスト時のみ人工的に横浜市西区の需要を喪失させた場合や、学習データにノイズがあった場合など複数の条件で評価を行うことで提案手法のロバスト性(学習データにない状況をシミュレートできる能力)を検証しています。
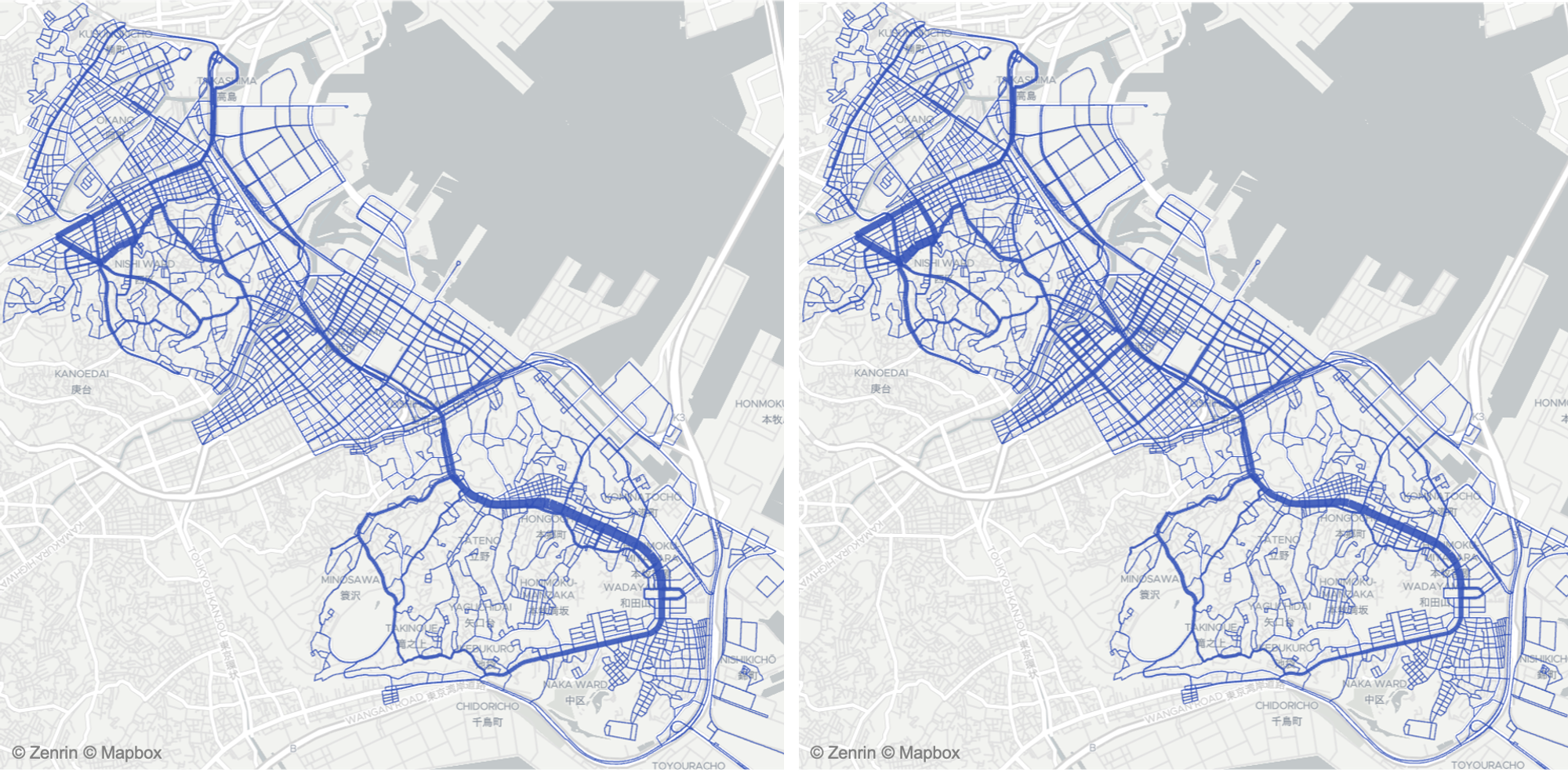
左:エキスパートの状態分布、右:提案手法で学習した方策による状態分布
学習した報酬を用いて全ての状態の方策を更新するのに要する時間は、ネットワークサイズの多項式となり、エージェントの数には依存しません。ハードウェア環境にもよりますが、今回実験で用いたような道路ネットワークの問題規模(ノード数2万弱)であれば、シングルCPUでも数秒で計算が可能となっています。
おわりに
この投稿では自身が取り組んでいた研究「Equilibrium Inverse Reinforcement Learning for Ride-hailing Vehicle Network」の紹介をさせていただきました。本論文は、2021年4月にオンラインで開催される「The Web Conference 2021」で発表する予定です。
最後になりましたが、MoT では、GO事業をはじめとするAI技術の社会実装や最新のモビリティ技術の研究を共に行ってくれるデータサイエンティストを募集中です。少しでもご興味ある方はぜひご連絡をいただければと思います。