

ラベルなしデータを用いた Dense Tracking の研究動向
AIDeep Learningはじめまして、AI技術開発部の加藤(@nk35jk)です。
本記事では、コンピュータビジョン分野において近年注目されつつある研究トピックである、ラベルの与えられていない動画データを用いて画素レベルでの物体追跡(dense tracking)を学習する研究の動向を紹介します。
下の図は dense tracking 手法の評価に主に用いられる video object segmentation というタスクでの手法毎の評価値を示したものになります。それぞれのプロットは教師なし学習を用いた dense tracking 手法の評価値と論文公開日を表しており、破線はベースライン手法および教師あり学習を用いた最先端手法の評価値を表しています。
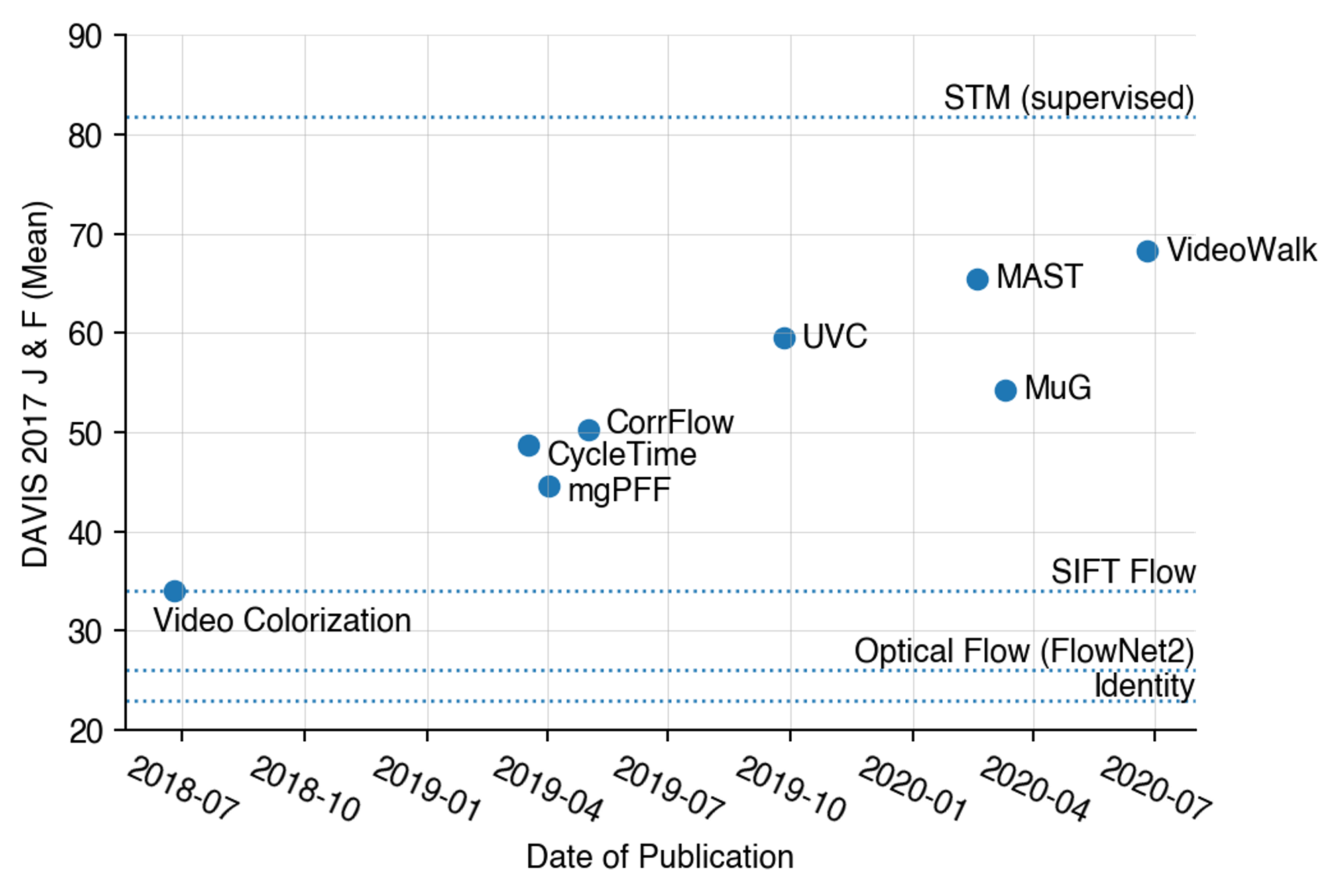
教師なし手法の性能推移
この図から、2018年に教師なし学習による dense tracking 手法である Video Colorization [1] が発表されて以来、教師なし手法の性能がここ2年程で急速に伸びていることが分かります。このペースで研究が進展すれば、表現学習において一部観測されつつあるように[2]、いずれ教師なし手法が教師あり手法の性能を上回る日も近いかもしれません。
ラベルなし動画を用いた dense tracking の学習は、データから自動的に作成可能な教師情報を機械学習モデルの学習に用いる自己教師あり学習の一種としても注目されており、コンピュータビジョン分野の世界最大規模の学会の一つである ECCV 2020 で開催された自己教師あり学習に関するワークショップ Self Supervised Learning: What is Next? における DeepMind の Andrew Zisserman 氏の講演 Beyond Self-Supervised Representation Learning において、自己教師あり学習の応用タスクの一つとして取り上げられています。
ここからは本研究分野について、タスクの概要、関連するデータセット、評価指標、ベースライン手法を紹介した後、主要な研究事例を紹介していきます。
本内容は Mobility Technologies と DeNA が合同で行っている技術共有会で講演した資料を記事化したものになります。スライドを本記事と合わせて参考にしていただければ幸いです。
タスクについて
概要
Dense tracking は映像中の物体を画素レベルで密に追跡するタスクです。
タスクの名称は論文毎であまり統一されておらず、dense tracking の他に、learning correspondence や correspondence matching など、correspondence という言葉を用いて表現されることも多いです。
このタスクはオプティカルフローと似ていますが、オプティカルフローが主に連続するフレームの輝度の一貫性と空間的平滑性を仮定した手法により求められる、物体の動きを表すベクトル場であるのに対して、dense tracking は必ずしも連続していない任意のフレーム間における画素同士の意味的な対応付けを行うタスクとなっています。
応用先として、動画の1フレーム目にマスクで指定された物体をその後のフレームに渡って追跡し続ける video object segmentation (VOS) 、テクスチャを追跡する texture tracking、人物関節点の追跡を行う pose tracking などが挙げられます。

(左)video object segmentation(中央)texture tracking(右)pose tracking (
これらの中でも、定量評価はVOSを用いて行われることが一般的です。
通常、VOSを遂行するモデルを学習するためには、動画の各フレームに物体領域のラベルが付与されたデータセットが必要になります。しかし、このようなラベルの作成には大きな労力が必要であるという問題があります。
そのような中で登場したのがラベルなしデータを用いた dense tracking 手法です。それらにより、人手でアノテーションしたラベルを用いずに dense tracking を遂行するモデルを学習できるようになりました。
Dense tracking の定量評価はVOSで行うことが一般的であるため、ここからは教師なし学習を用いたVOSに焦点を当てて話を進めていきます。
補足となりますが、VOSと類似する追跡タスクとして visual object tracking (VOT) または visual tracking が存在します。1フレーム目が物体領域のマスクで与えられるVOSに対して、こちらは1フレーム目で矩形で指定された物体をその後のフレームに渡って矩形ベースで追跡し続けるタスクとなっています。
データセット
ラベルなし動画を用いた dense tracking の学習および評価に用いられるデータセットを紹介します。
学習用データセット
モデルの学習には主に以下のデータセットが用いられます。元のデータセットにラベルが付与されていたとしても、それらは一切用いず生の映像データのみを用いてモデルを学習します。
Kinetics [3](30万動画、計800時間)
人物が様々な行動を取る様子を収録した主に行動認識に用いられるデータセット
VLOG [4](11万動画、計344時間)
YouTubeにアップロードされたVLOG動画から成るデータセット
OxUvA [5](366動画、計14時間)
単一物体追跡用データセット。長時間に渡る追跡のベンチマークを目的としているため、個々の動画の収録時間が長いのが特徴
YouTube-VOS [6](4519動画、計5.58時間)
YouTube動画から成るVOS用データセット
評価用データセット
VOSでの評価には主に以下のデータセットが用いられます。1フレーム目の領域を元に、その後の物体領域を特定し続けます。
- DAVIS-2017 [7](150動画)
- YouTube-VOS
評価指標
VOSは1フレーム目にマスクで指定された物体の領域をその後のフレームに渡って特定し続けるタスクです。
評価指標には以下のものが一般的に用いられます[8]。
Region similarity
推定領域と正解領域の重なり率(intersection over union)
Contour accuracy
推定領域と正解領域の輪郭点を画像上の距離に基づき2部マッチングした後、割り当ての真偽に基づき求められる適合率 と再現率 の調和平均
Region similarity と contour accuracy の平均値
VOS手法の大別
VOS手法は detection/segmentation-based approach と propagation-based approach の2種類に大別されます。
Detection/segmentation-based approach では全てのフレームに対して物体検出や領域分割を行うことで追跡結果を得ます。しかし、この方法では後述するように、学習データに含まれていない物体クラスがテストデータに含まれている場合、あまり良い性能が得られないという問題があります。そこで、学習データに含まれていない物体クラスに対応するために、テストデータの1フレーム目の領域ラベルを用いた fine-tuning を必要とする手法が多く、計算コストが大きいという課題があります。
一方、propagation-based approach では問題をマスクの伝播問題として扱います。オプティカルフローや距離学習を用いて隣接フレームの画素を対応付け、領域を時系列的に伝播させていきます。しかし、オプティカルフローを求める手法の多くは物体の輝度が時系列的に変化しないこと、また隣接画素の動きが滑らかであることを仮定したものが多く、このような手法で得られたオプティカルフローを用いると物体の色や形状の急激な変化に対応できないという問題があります。また、距離学習を用いる場合、距離関数の学習に用いられる学習データに含まれる物体クラス数には限りがあるため、detection/segmentation based-approach と同様、学習データに含まれない物体クラスへの頑健性に欠けるという問題が生じます。
教師なしのベースライン手法
教師ラベルを必要としない最もシンプルなベースライン手法として、恒等写像とオプティカルフローが挙げられます。
恒等写像は1フレーム目の領域にその後も物体が存在し続けると仮定したベースラインです。
一方、オプティカルフローでは前述のようにフローを用いて前フレームの領域を後フレームに伝播させていきます。オプティカルフローを求める手法として、ニューラルネットワークを用いたオプティカルフロー計算手法であるFlowNet2(人工データセットで学習)、SIFT特徴量に基づくオプティカルフロー計算手法である SIFT Flow がよく比較対象として用いられます。
教師あり手法の問題点
VOSの教師あり手法には大きく2つの問題点があります。
1つ目は、学習データに含まれていないクラスに対する頑健性に欠けることです。特に detection/segmentation-based approach の場合、モデルの学習に用いていないクラスの物体に対する推論の際、先に述べたテストデータでの fine-tuning を行ったとしても性能が落ちてしまう傾向にあります。
2つ目は、大規模な教師データの作成が困難であることです。先ほども述べましたが、VOSの教師データを作成するためには、動画の全てのフレームにおける物体領域を画素レベルでアノテーションする必要があり、多大な人的労力が必要となります。
例として、COCOデータセットのインスタンスセグメンテーションのアノテーションには1インスタンスあたり約79秒の時間を要したようです[9]。それを踏まえ、1画像に1インスタンスが存在すると仮定して YouTube-VOS データセット(計622,693フレーム)へのアノテーションにかかる時間を見積もると、約571人日となります。途方もない労力がかかることがわかると思います。
これらのような問題を解決する手段として、教師なし手法が注目されています。
まず、教師なし手法はデータさえ手に入れば人手のアノテーション無しにモデルを学習できるため、アノテーションコストの問題を解決することができます。
さらに、大量のデータを活用した学習が教師あり手法と比べ容易であるため、汎化性能の高い手法の実現可能性が存在します。実際、教師なし手法の性能は教師あり手法に匹敵しつつあるとともに、後に紹介する MAST という教師なし手法は学習データに含まれていないクラスに対する汎化性能において、ほとんどの教師あり手法を上回ることが確認されています。
論文紹介
ここからは個別の研究事例を、できる限り研究の流れがわかるよう紹介していきます。なお、使用している図表は紹介論文から引用したものとなります。
Video Colorization (Vondrick+, ECCV'18) [1]
ラベルの付与されていない動画データを用いた学習により dense tracking が可能になることを示した、本分野の起点となるような研究です。前フレームの色を用いて後フレームの色を復元する proxy タスク(自己教師あり学習に用いられるタスク)でモデルを学習することで画素間の類似度指標を獲得しています。
アイディアのベースになる考え方として、物体の色が時系列的な一貫性を持っていることを利用しています。下図の例から、同一物体の同部分の色は時間が経過しても概ね一貫していることが分かるかと思います。

Kineticsデータセットの近接フレームペアの元画像(上段)、 Lab色空間におけるabチャネル(中段)、量子化してから色を変更した画像(下段)
これを踏まえ、現在フレーム(input frame)の画素の色を、過去のフレーム(reference frame)から参照することで予測するタスクでモデルを学習します。その際、フレームをグレースケール化することで、単に同じ色の画素を参照する局所最適解に陥ることを防いでいます。それにより、物体の色が時系列的に変化しないと仮定すると、意味的に対応する画素から色を参照することで正しい色を復元することが可能となります。その結果、フレーム間の画素の対応付けが可能となります。
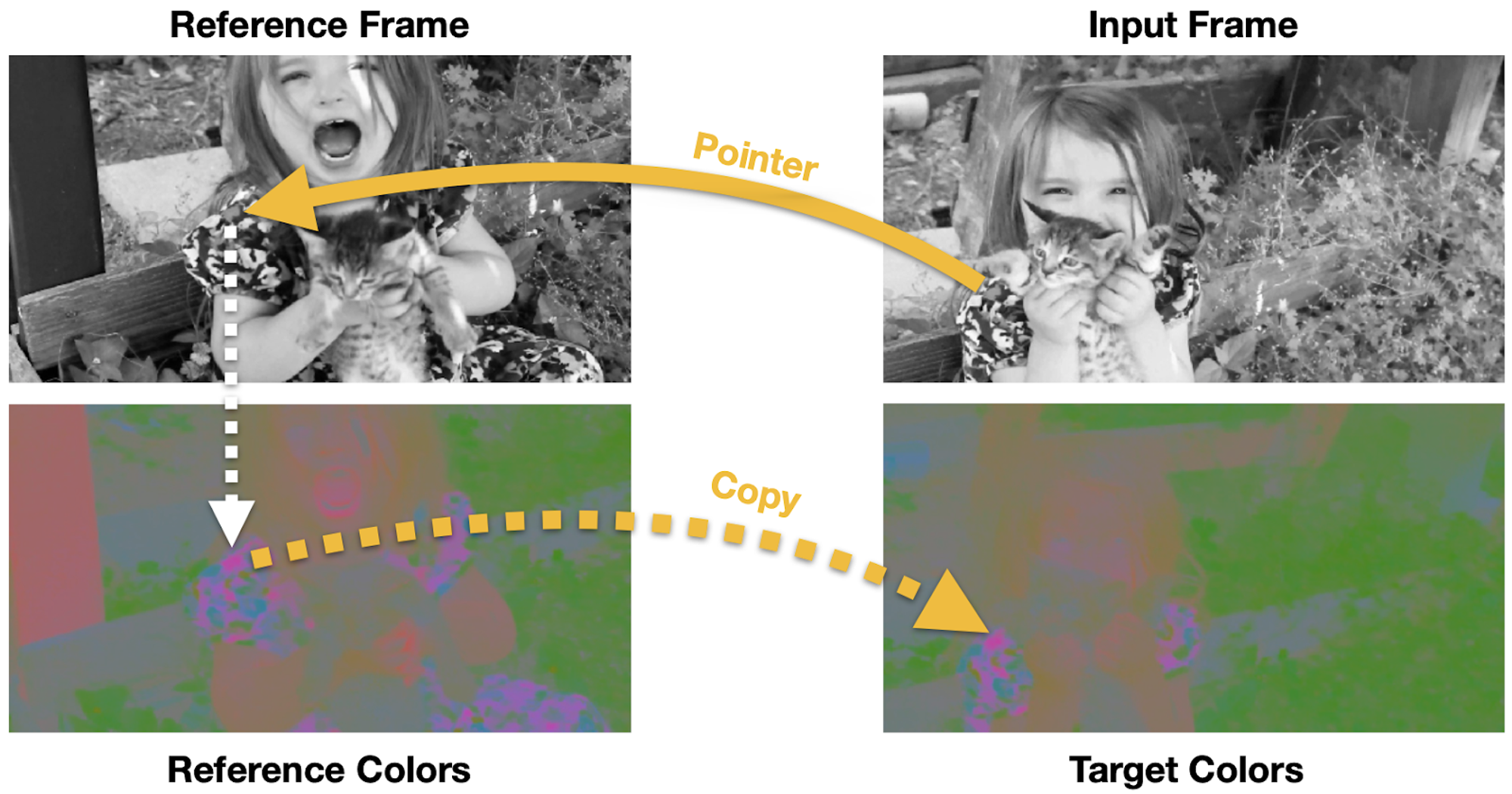
アプローチ
モデルはグレースケール画像を入力に画素毎の埋め込みベクトルを出力します。このとき、reference frame の画素 と target frame の画素 の類似度値 を、次式のように埋め込みベクトル 同士の内積を reference frame 全体に関するソフトマックス関数で正規化することで求めます。
色の予測結果は次式のように、類似度行列 を用いた reference frame の色 の重み和により得られます。
このように、色の復元はアテンションと類似した機構により行われます。
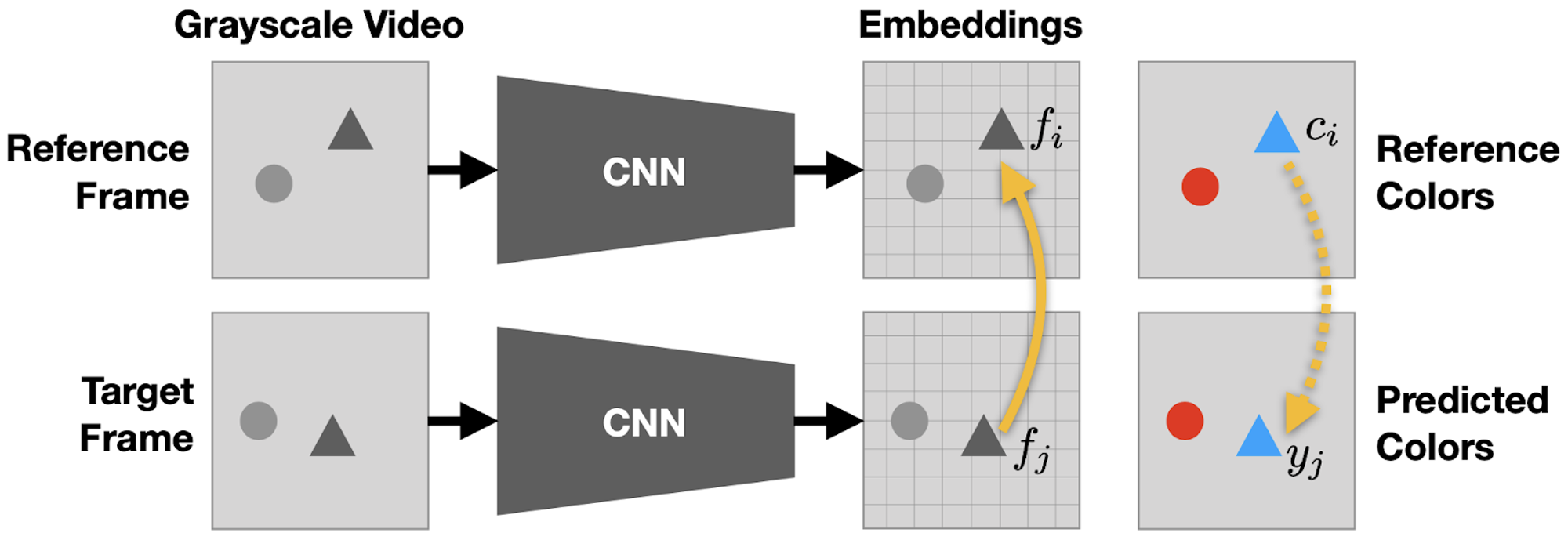
モデル構成
学習時は、色空間を離散的なクラス( クラス)に量子化して得られる確率分布を参照の対象とし、正解の分布(one-hot ベクトル)と予測分布に対する cross entropy ロスを適用します。回帰ではなく分類のアプローチをとっているのは、色の復元というタスクが複数の解を持つ問題であるためであると著者らは主張しています(しかし、後述する研究ではこの考えに異論が唱えられています)。
にリサイズした連続する4フレームをモデルの入力とし、最初の3フレームを reference frame、最後の1フレームを target frame として用います。モデル構造は 3D convolution を5層付加した ResNet-18 を使用し(本記事で紹介する研究の中で 3D convolution を使用しているのはこの研究のみ)、各フレームの埋め込みベクトル()を出力します。学習には Kinetics データセットを用いています。また、参照および予測する色は Lab 色空間の ab チャネルとしています。
推論時は類似度行列を用いて、色の分布ではなくクラスの予測確率(第1フレームでは one-hot ベクトル)を伝播させていきます。
実験では、VOSにおいてラベルの恒等写像やオプティカルフローを上回る性能が得られることを確認しました。

DAVIS-2017 データセットでの評価結果
推論結果例は以下のようになっています。

推論結果例(
本手法の課題点として、推論時に入力の色情報を利用できないことが性能のボトルネックになりうることが挙げられます。また、video colorization は色の一貫性を仮定したアプローチであるため、色の急激な変化に弱いという欠点があります。
本手法を改善する研究が後に多く発表されることとなります。
TimeCycle (Wang+, CVPR’19) [10]
この研究は、動画データにおける cycle-consistency を利用することでラベルなし動画を用いた追跡の学習を可能としました。Cycle-consistency とは、一連のデータを輪状に結びつけるように存在する一貫性のことで、この一貫性を利用した損失関数の設計により画像変換や映像の同期などのタスクを教師なしで学習する研究が存在します[11][12]。本研究では、映像中の物体を時系列的に逆方向に物体を追跡してから、同じフレームだけ順方向に追跡すると、追跡の始点と終点が一致するはずであるという cycle-consistency を利用し、始点と終点が一致するような教師をモデルに与えます。

物体追跡に関する cycle-consistency
本手法では、モデルの学習時はパッチを用いて追跡を行いますが、推論時は領域に基づいた追跡が可能です。
学習の枠組みは下図のようになっています。ResNet-50 から成るエンコーダー は、入力画像に対応する特徴マップを出力します。追跡処理 では、追跡物体のパッチ画像の特徴マップと次フレーム全体の特徴マップを入力に次フレームにおける物体の位置を特定します。この追跡処理を時系列に逆方向および順方向に同じフレームだけ行った後、追跡の始点と終点が一致するように損失を付与します。
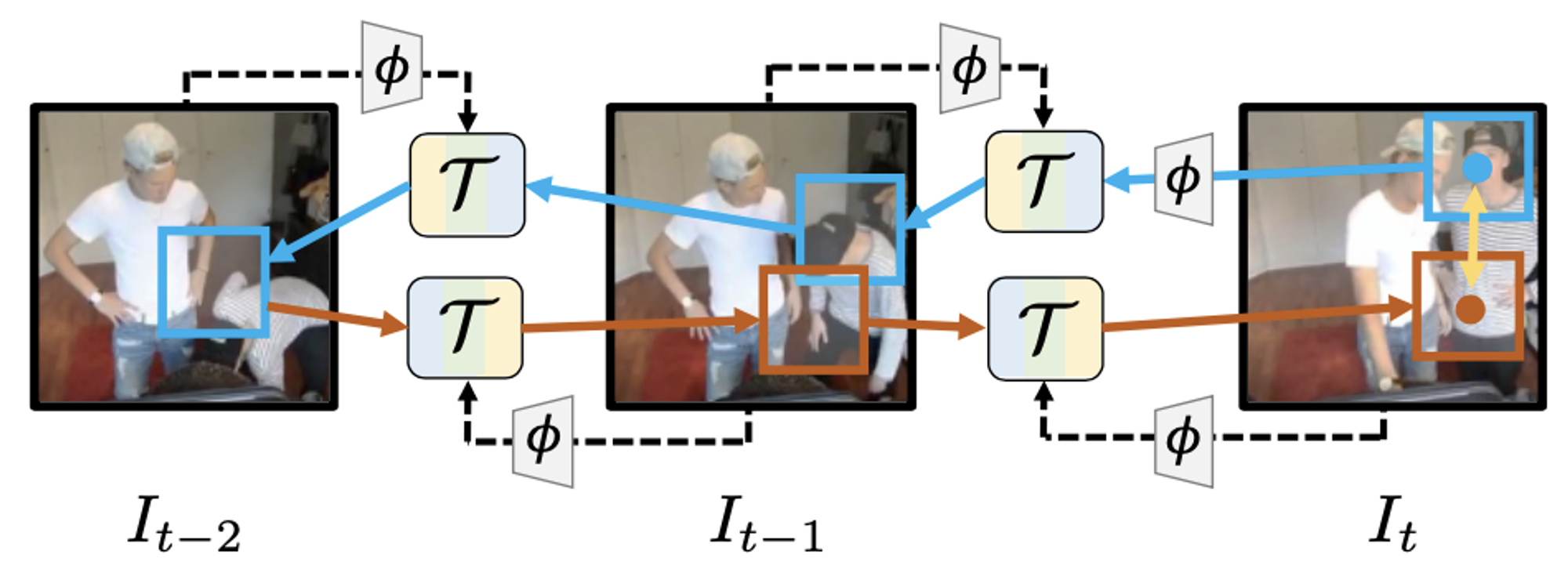
学習の枠組み
追跡処理 の詳細は下図のようになっています。まず、入力された特徴マップのペアに対して、Video Colorization と同様の類似度行列を算出します。その後、畳み込み層2層、全結合層1層の軽量なネットワークでパッチの 方向の移動量と回転を推定します。そして、推定されたパラメータに基づき特徴マップをバイリニアサンプリングすることで、追跡後の物体の特徴マップを算出します。
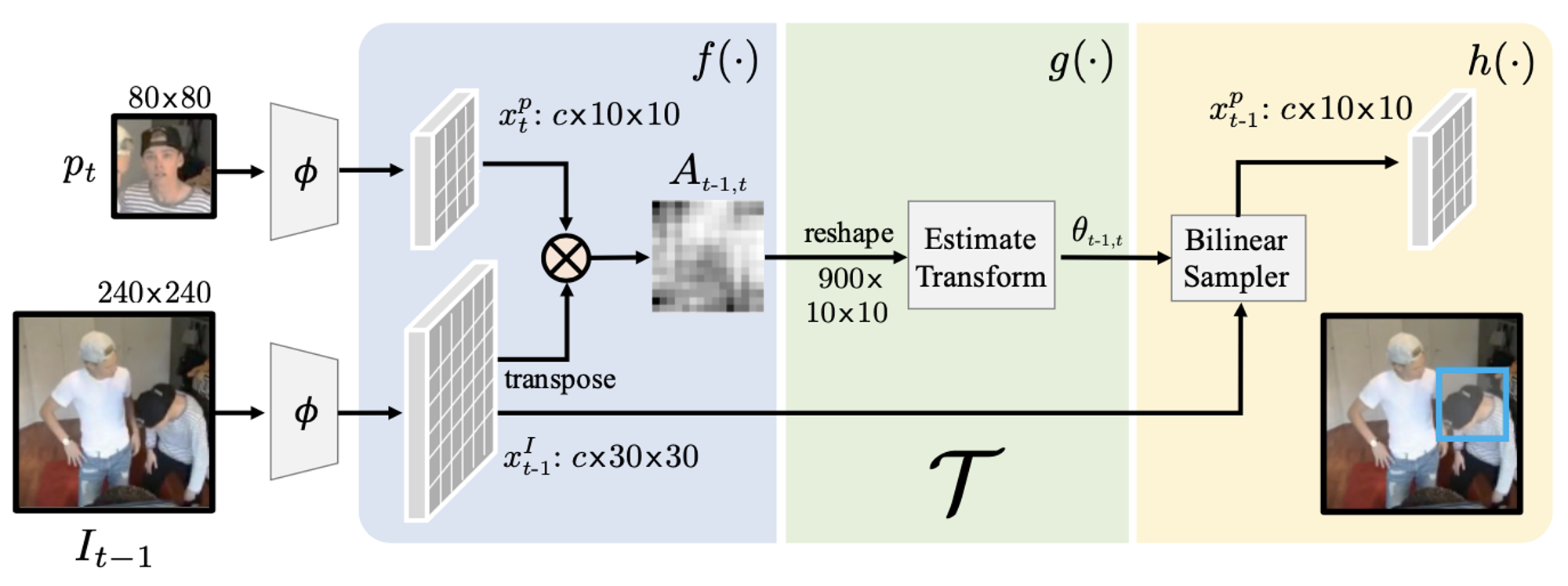
追跡処理
モデルの学習には以下3種類の損失関数を使用します。
- 追跡開始時と終了時のバイリニアサンプリンググリッドに対するMSE(下図左のように追跡フレーム数を変化させて形成される複数の cycle を使用)
- フレームをスキップした cycle(下図右)に対する同様の損失関数 → 遮蔽に頑健化
- 追跡開始時と終了時のパッチの特徴マップ間の負の内積 → 特徴マップの距離を明示的に近づける
学習にはVLOGデータセットを用いており、cycle を作成するのに用いる過去フレームは最大 としています。
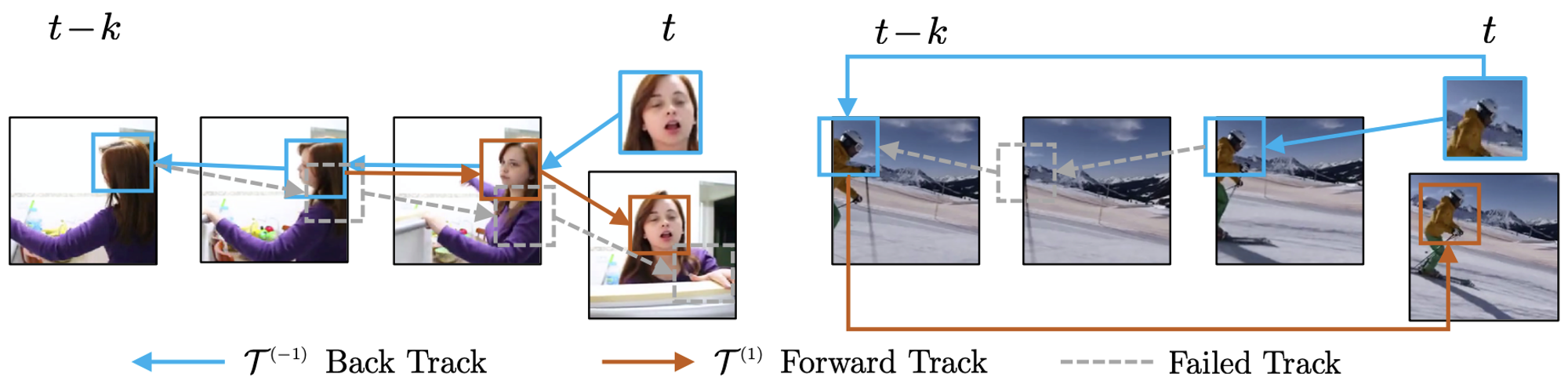
Cycle の種類
推論時は Video Colorization と同様に、特徴マップ間の類似度行列を用いてクラスの予測確率を伝播させることで追跡を実施します。その際、直近4フレームおよび第1フレームから予測確率を伝播させ、それらを平均することで最終的な予測確率を求めています。
実験では、VOSにおいて Video Colorization を上回る性能を達成しました(リポジトリでは、パッチサイズを から へと大きくすることで 46.4、 50.0 の評価値が得られることが報告されています)。
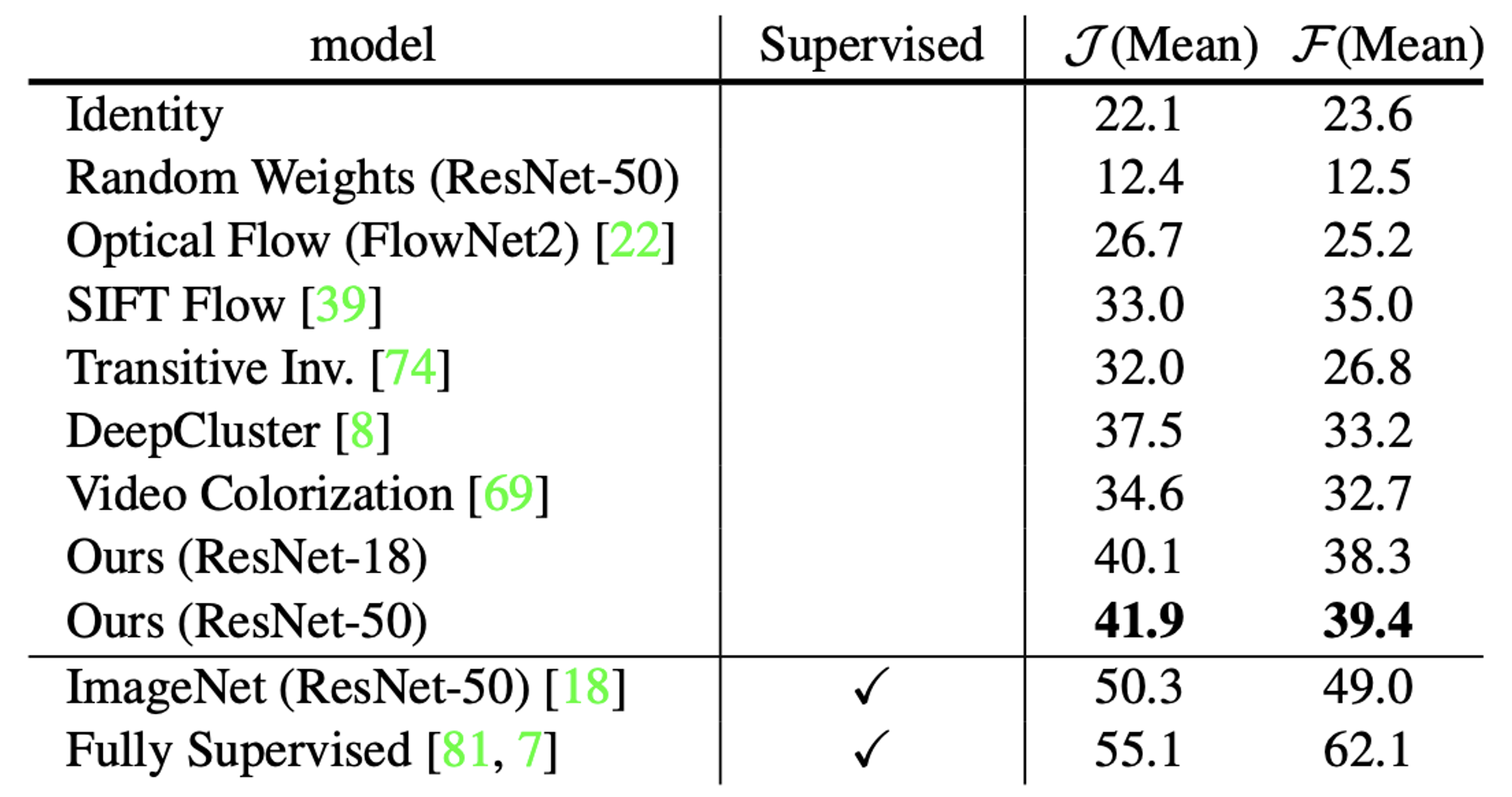
DAVIS-2017 データセットでの評価結果
課題点として、パッチ内に複数の物体が存在するとき追跡対象が不明確になり、学習のノイズとなってしまうことを著者らは述べています。
この研究の後、Vondrick らにより提案された video colorization、本研究で用いられた cycle-consistency learning の2つのアプローチが本分野のメインストリームとして研究が進展していきます。
Unsupervised deep tracking (Wang+, CVPR’19) [13]
この研究では自己教師あり学習を用いた visual tracking 手法が提案されており、CycleTime と同様に cycle-consistency learning が用いられています。CycleTime との違いとしては、タスクが矩形ベースの追跡であること、また相関フィルタを用いた追跡の枠組みを用いていることが挙げられます。具体的には、相関フィルタの response map に対して cycle-consitency loss(L2ロス)を適用することでモデルを学習しています。
本研究は CycleTime の翌日 arXiv に投稿されているとともに、CycleTime と同じく CVPR’19 に採録されています(第一著者の姓も同じ)。同時期に類似したアプローチの研究が発表されたことは、cycle-consistency learning が自己教師あり学習の手段として注目されていることを示しているように思われます。
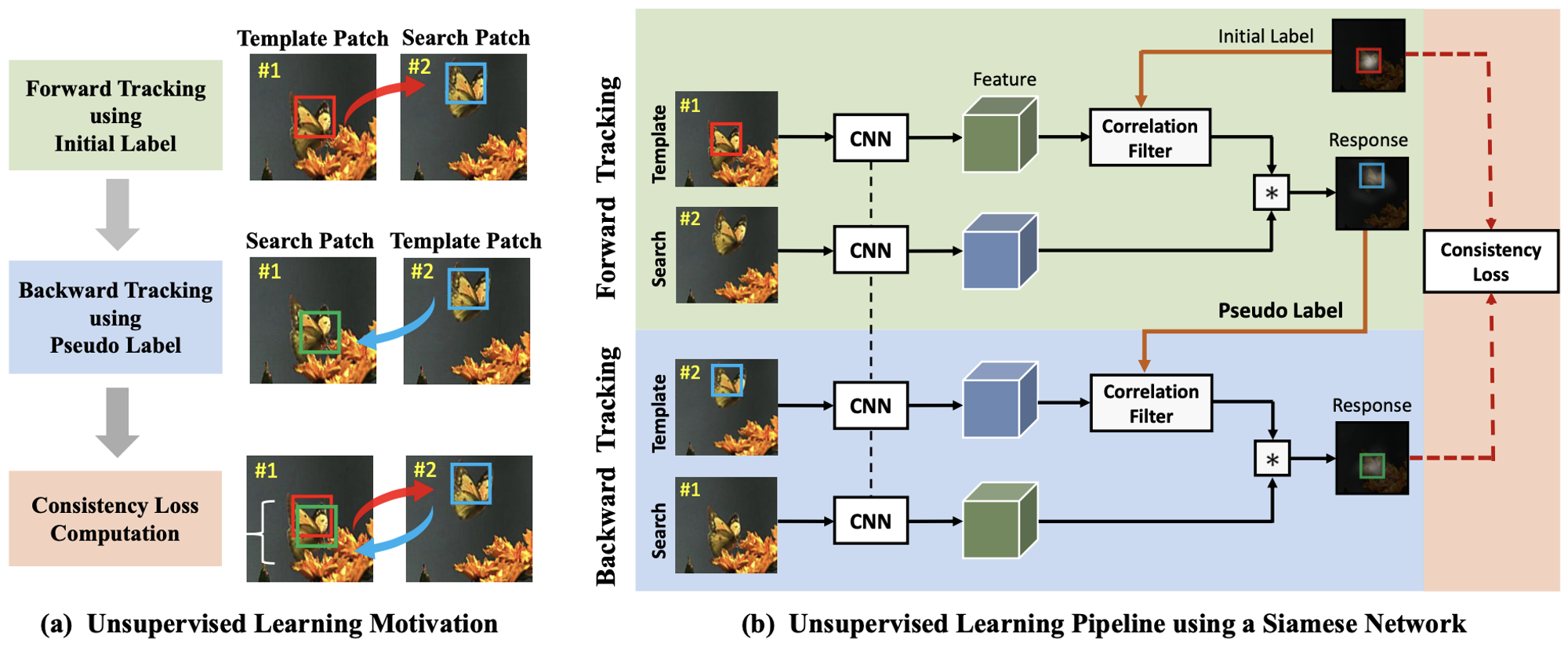
アプローチの概要図
Multigrid Predictive Filter Flow (mgPFF) (Kong+, 2019) [14]
この研究では、近接フレームを用いたフレームの再構成を通して filter flow を教師なしで学習する Multigrid Predictive Filter Flow (mgPFF) を提案しています。Filter flow は2つのフレームが与えられたとき、一方のフレームの各画素を、もう一方のフレームの近傍画素の重み和で表現することで画像の変換をモデル化したものとなっており、オプティカルフローや畳み込み、非線形モーフィング、ブラー除去などを包含した概念となっています。例として、filter flow の重心計算によりオプティカルフローを得ることができます。
手法の概要は下図のようになります。近接する2フレームそれぞれをモデルに入力し、対応する特徴マップを得ます。次に、それらをチャネル方向に結合したものを後段のモデルに入力することで、filter flow を出力します。ここで、filter flow は各行がベクトル化された入力画像に独立に作用して出力画素値を決定する行列です。この filter flow の各行と入力画像の重み和を求めていくことでフレームを再構成します。このとき、フィルタのカーネルサイズを調節して出力画素近傍の入力画素のみを考慮することで、計算量の爆発を防いでいます。
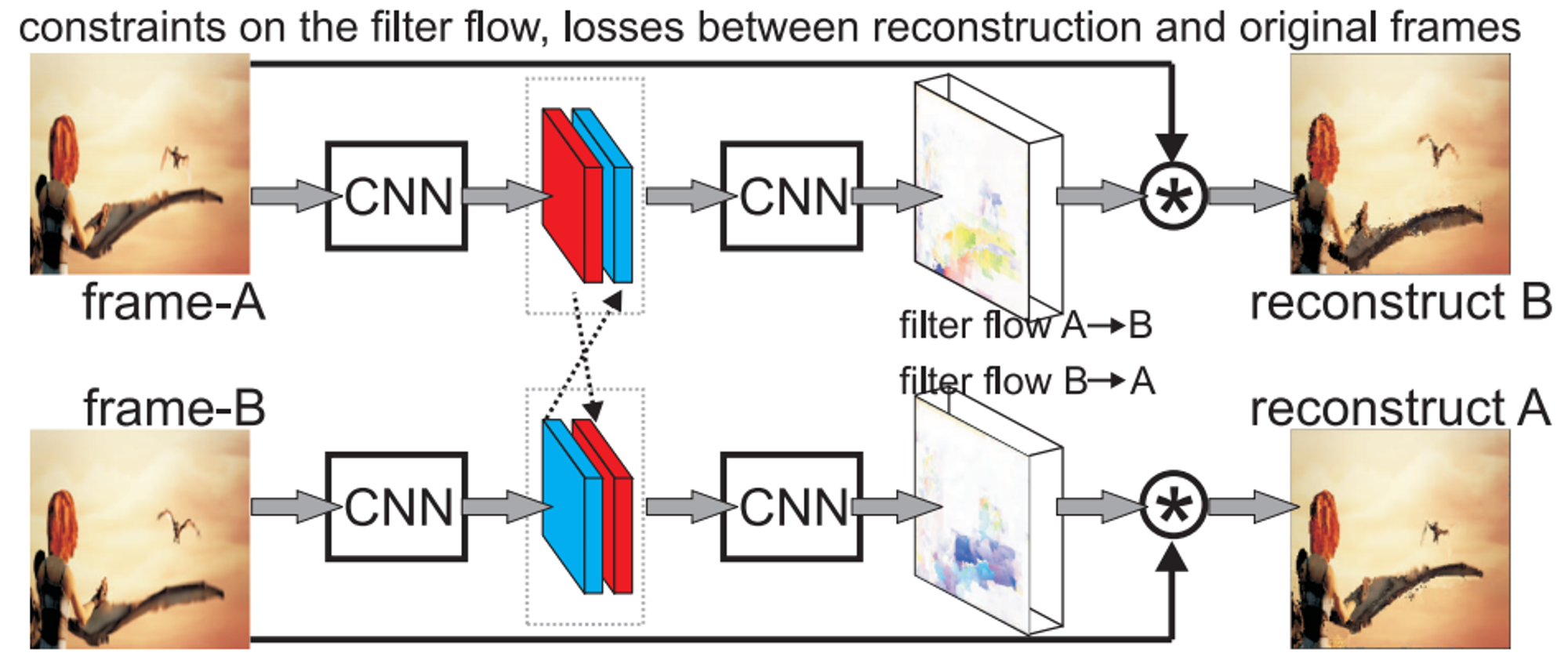
手法の枠組み
本研究ではさらに、下図のように複数解像度のフレームから coarse-to-fine に filter flow を推定し、それらを積算により統合することで最終的な filter flow を求めることを提案しています。これにより、小さなカーネルサイズのフィルタ(実験では を使用)で大きな移動量を表現することができるため、計算コストを削減することができます。
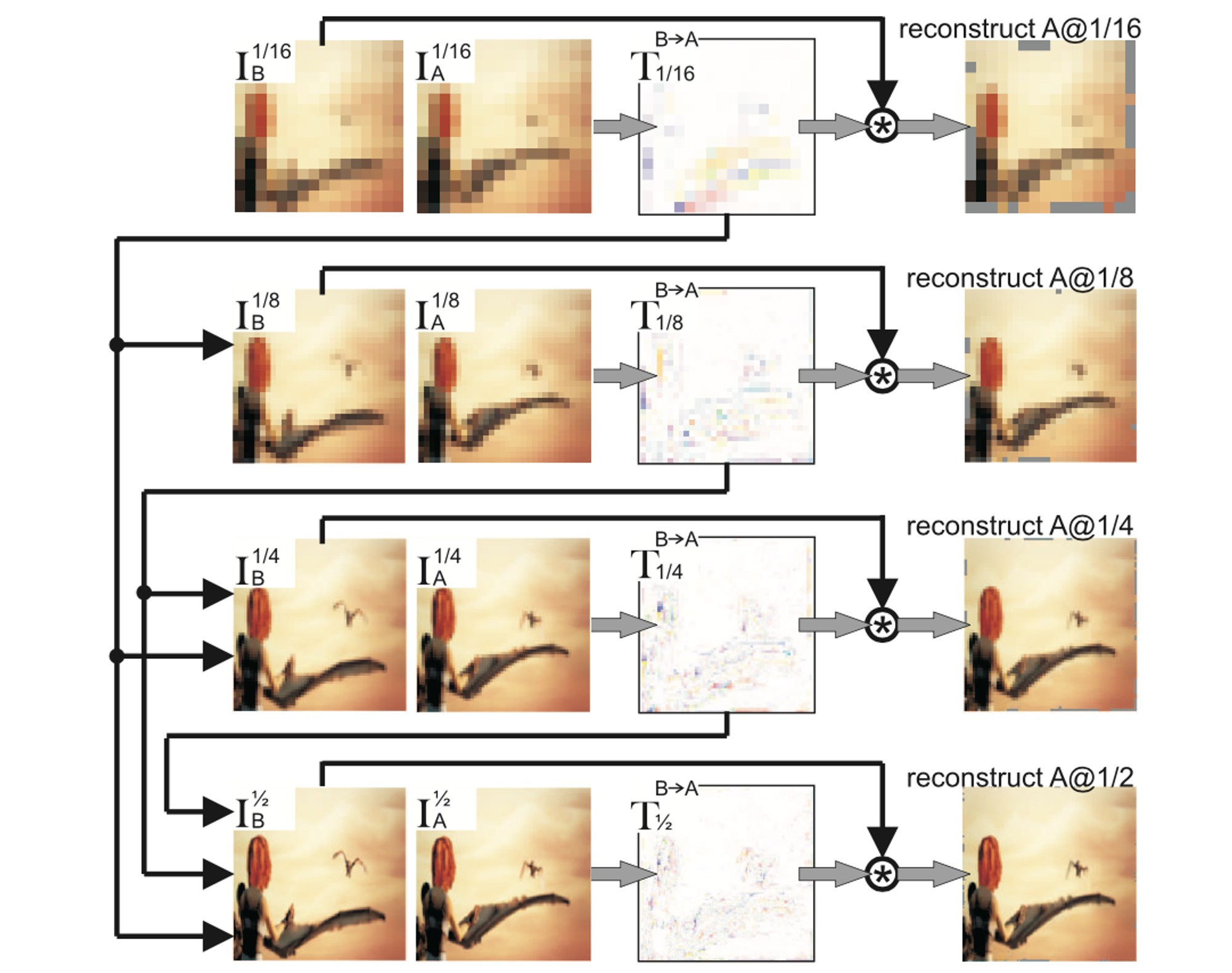
Coarse-to-fine に filter flow を推定
損失関数には以下4種類のものを使用します。
- 再構成損失:charbonnier function (この損失関数を使用する理由は明記されていませんが、charbonnier function は0付近における勾配の変化が連続的な、smooth L1 loss に似た形状の関数です)
- 順方向、逆方向のオプティカルフローに対する charbonnier function
- Smoothness constraints:オプティカルフローの勾配のL1ノルム
- Sparsity constraints:オプティカルフローのL1ノルム
再構成損失以外は filter flow を通して得られるオプティカルフローに対して付加されますが、オプティカルフローを直接推定するよりも、filter flow という中間表現を介すことにより学習が容易になると著者らは述べています。
VOSの推論時は直近3フレームおよび第1フレームからクラスの予測確率を filter flow に基づき伝播させることで領域の追跡を実施します。
実験では Sintel Movie、DAVIS-2017 の学習データ、JHMDB (split1) を統合した、他の教師なし手法と比べて小規模なデータセットでモデルを学習し、CycleTime と同程度の性能が得られることを確認しました。データセットの規模自体は確かに小さいですが、評価データと画像の外観が似ていると思われる DAVIS-2017 の学習データを用いてモデルを学習しているため、学習に用いるデータセットの条件を揃えたときの評価値が気になります。
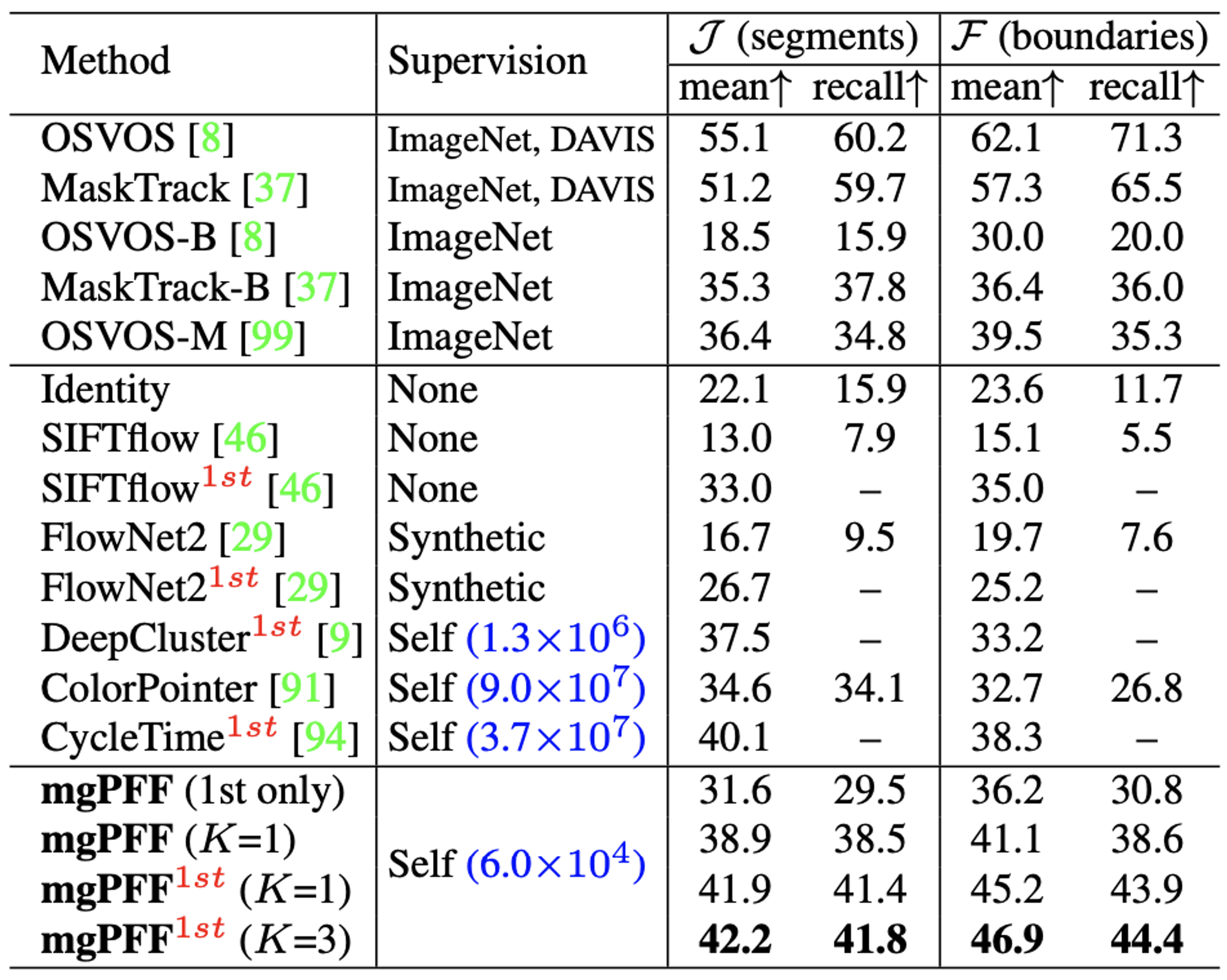
DAVIS-2017 データセットでの評価結果
CorrFlow (Lai+, BMVC’19) [15]
この研究では Video Colorization をベースに手法の改善を図っています。Vondrick らの手法からの差分として colour dropout、restricted attention、scheduled sampling、cycle-consistency の4つの工夫を施しています。
Colour dropout
Vondrick らの Video Colorization では、入力フレームをグレースケール化することで色情報を損失させ、単に同じ色を参照する瑣末な解に陥ることを防いでいましたが、推論時もグレースケール画像を用いる必要があるため、入力の情報を一部損失させた状態で推論を行う必要がありました。そこで本研究では、学習時に入力の各チャネルの値をランダムに0にして情報を損失させる colour dropout を提案しています。色情報をランダムに損失させることで同じ色を参照する局所解に陥ることを防ぎつつ、全ての色を用いた学習もされているため、推論時に全てのカラーチャネルを入力することができます。
Restricted attention
Video Colorization では reference frame 全体を参照画素としていましたが、本手法では target 画素近傍のみを参照することで類似度行列の計算コスト削減を図っています。さらに、参照する領域を絞ることで間違った物体への対応付けが減り、性能自体が向上することが実験で確認されています。
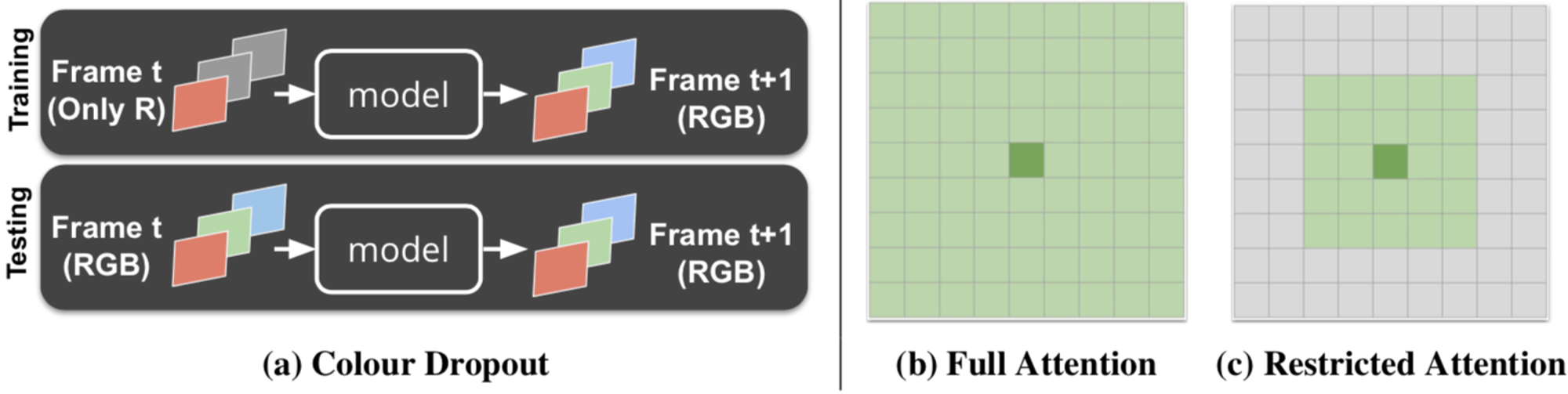
Scheduled Sampling
Sequence-to-sequence モデルで使われる scheduled sampling は、 学習の際、正解ラベルをモデルの推定結果に置き換えることで、モデルの頑健性を高めるカリキュラム学習です。本研究では、一定確率で正解色ではなく前フレームにおけるモデルの推定色を用いて次フレームの色を予測します。この確率を学習が進むにつれて高めていくことで、徐々にタスクを難しくしていき、モデルの頑健化を図っています。
Cycle consistency
主な損失関数として、Vondrickらと同様に、量子化されたLab色空間の色復元結果に対する cross entropy ロスをかけますが、それに加え、色の予測を時系列的に順方向に行ってから逆方向に行ったときの色復元結果に対する同様の損失関数を使用してモデルを学習します。追跡結果ではなく、色の復元結果に対して損失関数を適用する点で、TimeCycle とはアプローチの異なる cycle-consistency learning となっています(本手法ではあくまで video colorization の補助として cycle-consistency loss を適用しています)。
実験結果
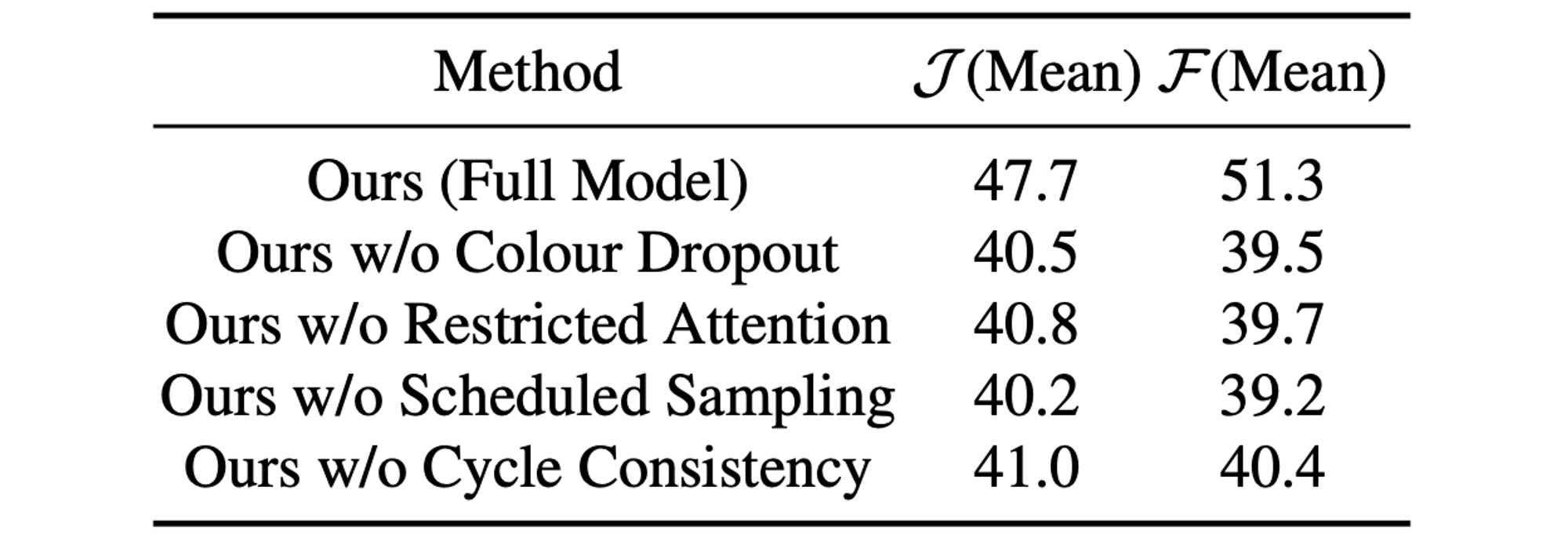
本研究における4つの改善点に関する ablation study を行い、いずれの手法もモデルの性能向上に大きく寄与していることを示しました。表中の Ours w/o Colour Dropout は入力をグレースケールにした場合となっています(全てのカラーチャネルを入力した場合は学習が上手くいかなかったのかもしれません)。
Ablation study 結果
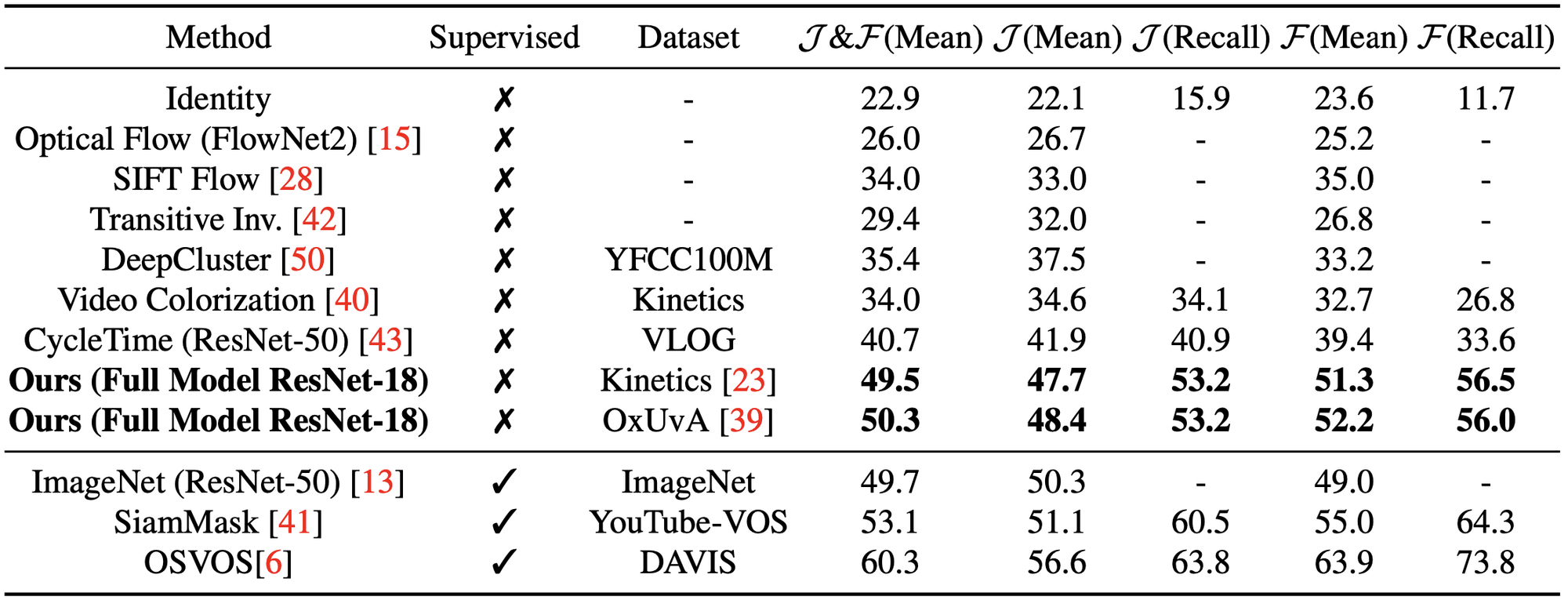
また、本手法は既存の教師なし手法を上回る性能を達成しています。入力画像サイズは Video Colorization と同じ ですが、特徴マップのサイズは と縦横の長さが Video Colorization の倍となっていることも本手法の性能向上に寄与しているものと思われます。
学習に用いるデータセットはデータ数は多いが評価データとドメインの乖離がある Kinetics よりも、データ数は少なくともドメインの近い OxUvA を用いた方が性能が高くなることが確認されました。
他手法との比較結果
UVC (Li+, NeurIPS’19) [16]
物体追跡のアプローチにおいて、パッチに基づく対応付けは物体の大まかな位置を特定するのに有効である一方で画素レベルでの対応付けができず、また画素レベルでの対応付けでは外観の似た他物体への誤った対応付けが起きやすいという問題があります。
そこで本手法では、可変サイズのパッチを用いて大まかな物体位置を特定してから、パッチ内で画素レベルの対応付けをすることで、頑健性の高い画素レベルでの追跡を図っています。
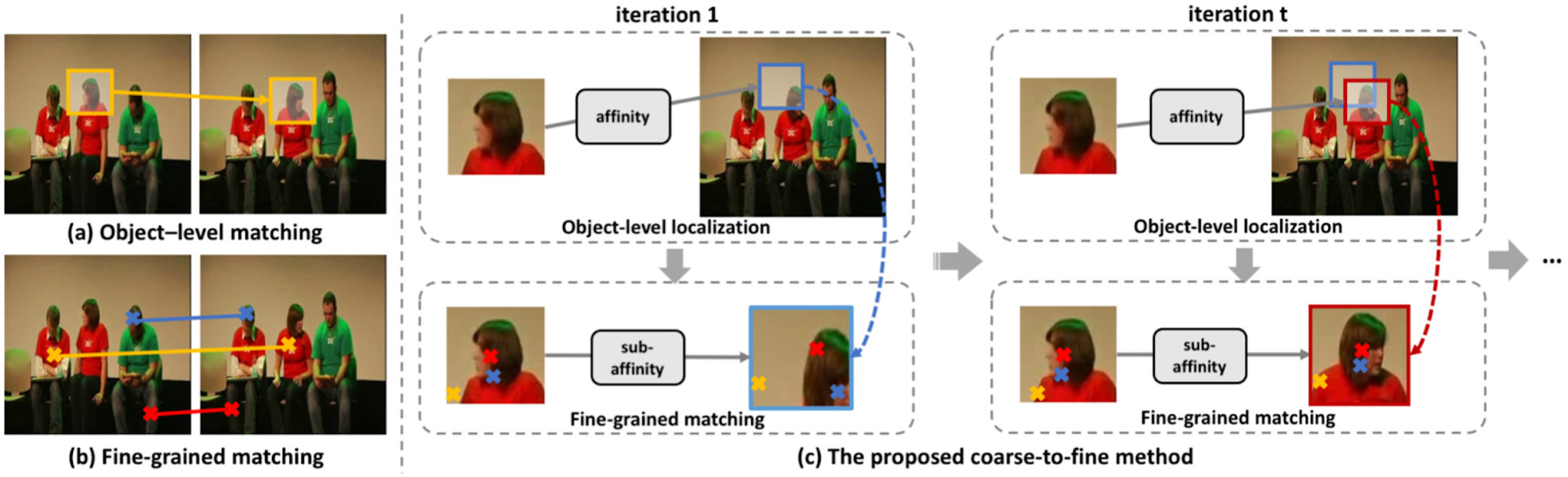
アプローチの大別
本手法はグレースケール化したフレームの colorization がベースとなっています。
モデルの入力は追跡対象のパッチおよび追跡を行う次のフレームです。まず、これらの特徴マップ間の類似度行列を Video Colorization と同様に算出します。
Region localization module
次に、パッチ内のある画素と次フレームの類似度の重心座標をその画素の移動先座標とみなし、パッチ内の全ての画素の移動先座標の平均を移動先矩形の中心座標、移動先座標と矩形中心の差の平均を矩形サイズとして追跡先の矩形を推定します。
Fine-grained matching module
その後、推定された矩形に対応する類似度行列をサンプリングし、色を復元します。このとき、直接色を参照するのではなく、Lab色空間のフレームを用いて学習されたオートエンコーダーの特徴ベクトルを参照しそれをデコードすることで色を復元します。オートエンコーダーは色情報とともに空間的なコンテクストをエンコードしているため、これを用いることで大きくエラーを削減できると述べられています(ただし ablation study はされていません)。
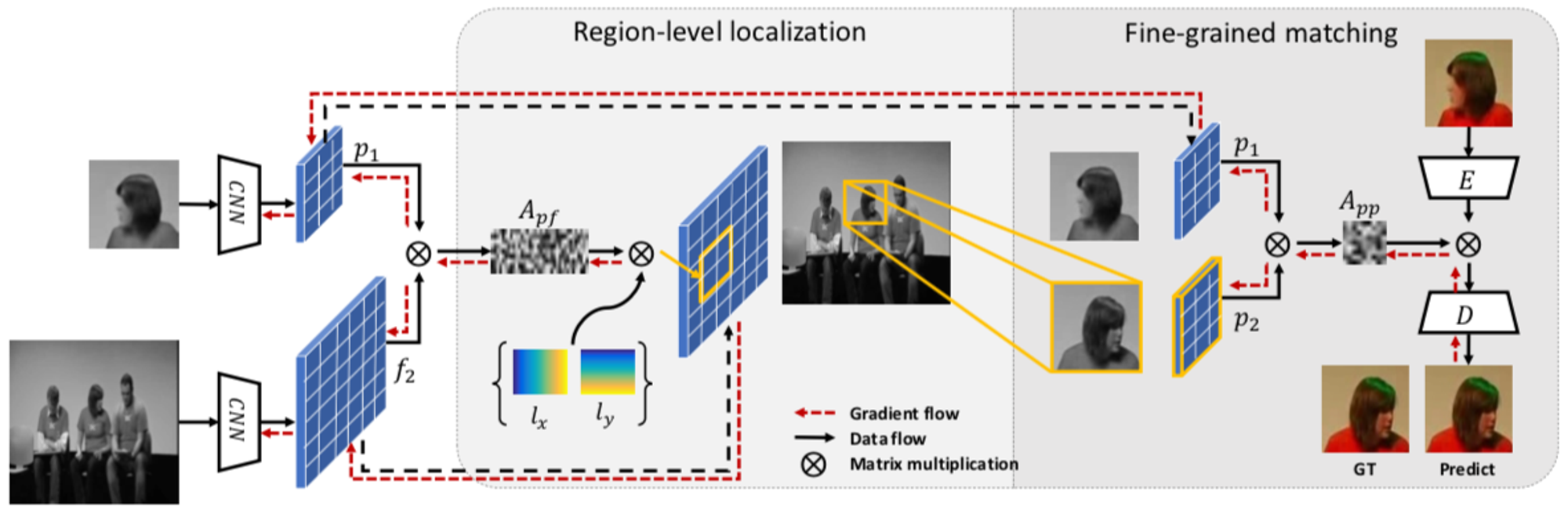
手法の概要
以下3つの損失関数を用いてモデルを学習します。
- 色の再構成損失(L1ロス)
- Concentration loss:パッチ内の画素の移動先座標が推定された矩形の中心に近づくようMSEを付加
- Orthogonal loss:順方向に追跡してから逆方向に追跡したときの移動量および特徴マップに対する cycle-consistency loss(両者ともMSE)
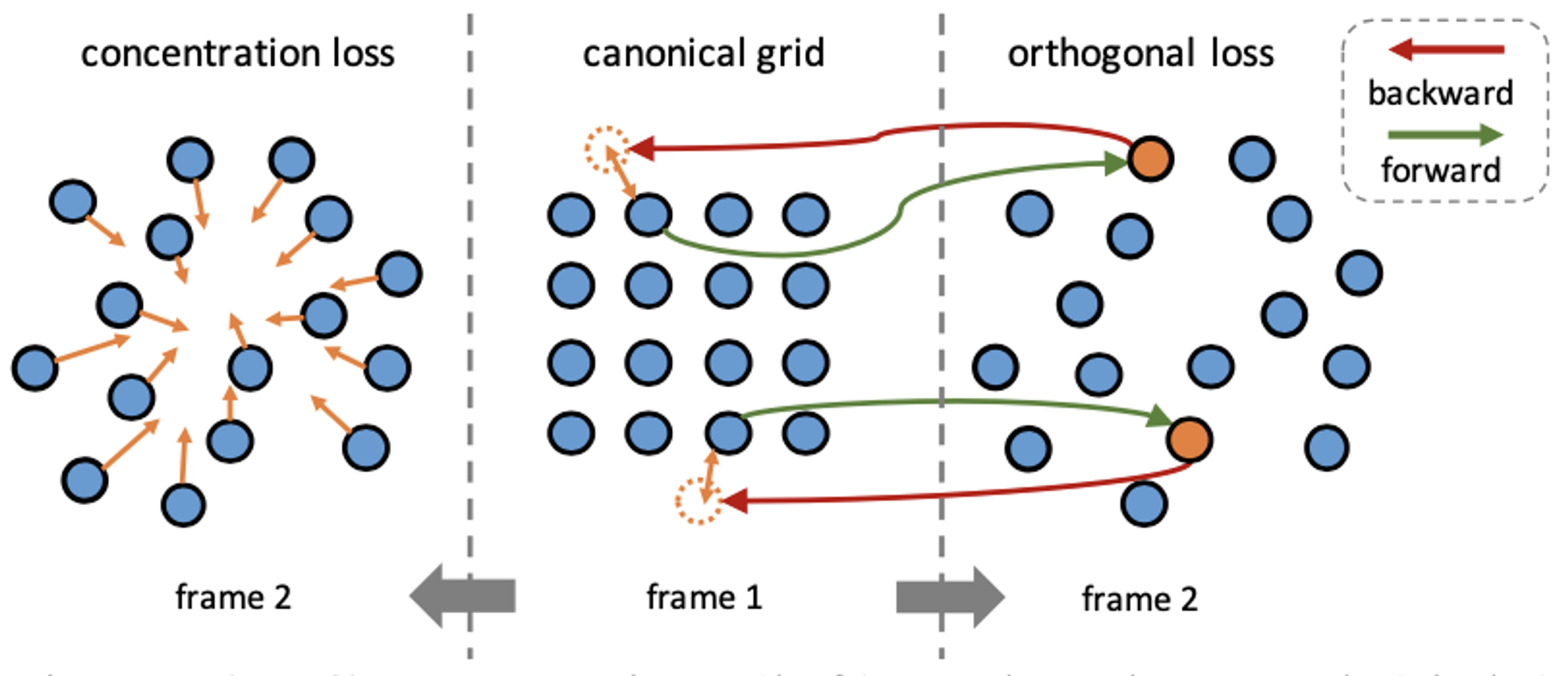
Concentration loss および orthogonal loss
実験では、既存の教師なし手法とともに、比較対象とした教師あり手法をも上回る性能を確認しています。
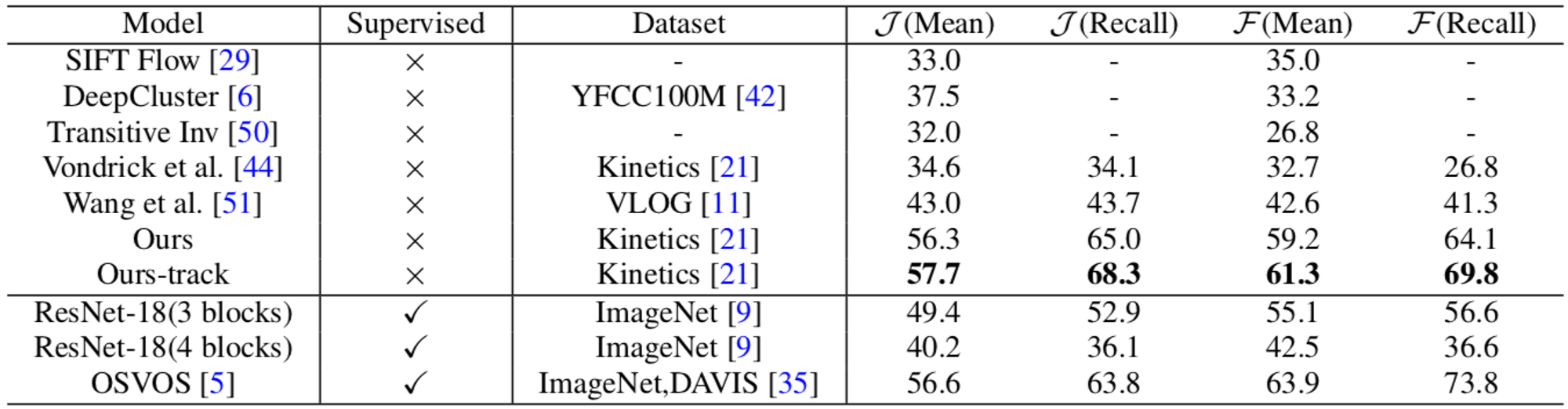
他手法との比較結果(Ours は推論時に localization module を用いていない場合)
Ablation study 結果は下表のようになっており、cencentration loss の性能への寄与が特に大きいことがわかります。推論時に localization module を用いていない場合の性能低下がそれほど大きくないことからも、学習の際に concentration loss を用いて画素の移動が空間的にある程度一貫するよう制約をかけていることが本手法の性能に寄与しているのではないかと思われます。

Ablation study 結果(L:localization module、O:orthogonal loss、C:concentration loss)
定性的な ablation study 結果は下図のようになっており、localization module を取り除くと他物体への誤った対応付けが見られ、concentration loss を取り除くと背景領域への誤った対応付けが発生するとともに移動量の空間的な一貫性が損なわれ、orthogonal loss を取り除いた場合も対応付けの局所構造が崩れてしまっていることが確認できます。
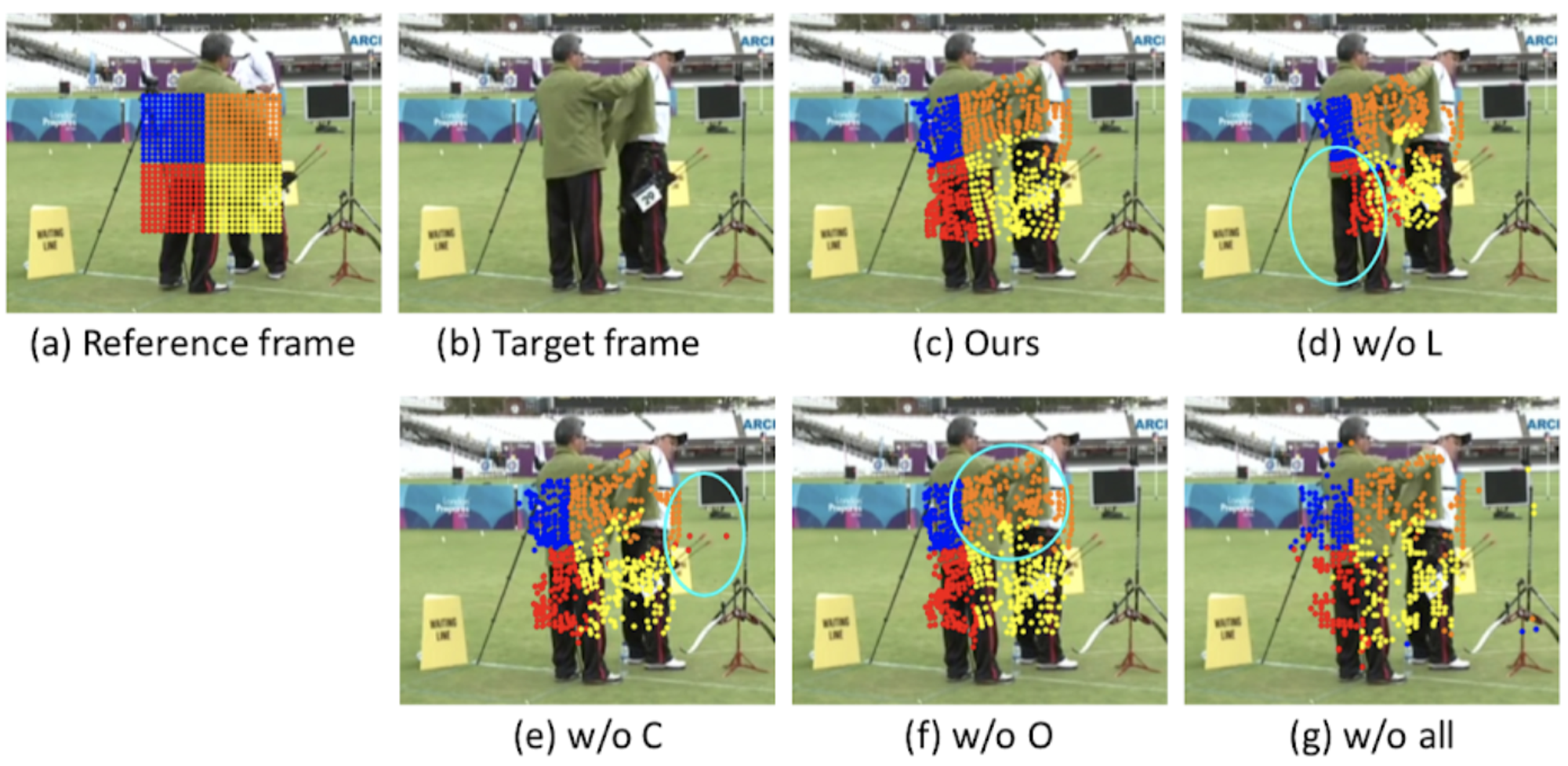
各種コンポーネントを取り除いたときの推論結果例
矩形および領域の推定結果は下図のようになっており、両者ともに適切に推定できています。
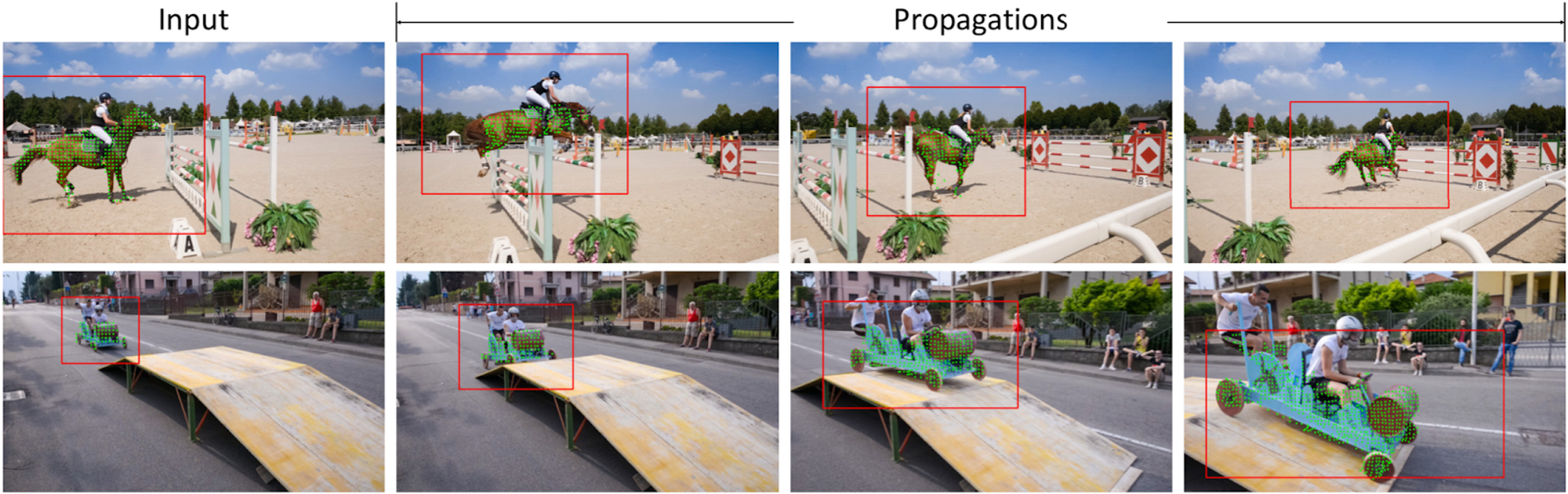
推論結果例
Memory-Augmented Self-Supervised Tracker (MAST) (Lai+, CVPR’20) [17]
こちらは CorrFlow と同じ著者らが、彼らの手法をアップデートした研究となります。Video colorization における学習の枠組みを再考するとともに、過去の複数フレームの情報を効率的に活用するモデルを提案しています。
Video colorization における学習の枠組みの再考
下図は DAVIS データセットにおけるRGB色空間とLab色空間におけるチャネル間の相関をプロットしたものになりますが、RGB色空間はチャネル間に強い相関関係があることがわかります。そのため、RGB色空間を video colorization に用いると、あるチャネルの値からその他のチャネルの値をある程度予測できてしまうため、間接的に同一色を参照する瑣末な解に陥りやすくなると著者らは指摘しています。そして、先行研究では素朴に使われていたチャネル間の相関が小さいLab色空間を使用するのが適切であると述べています。
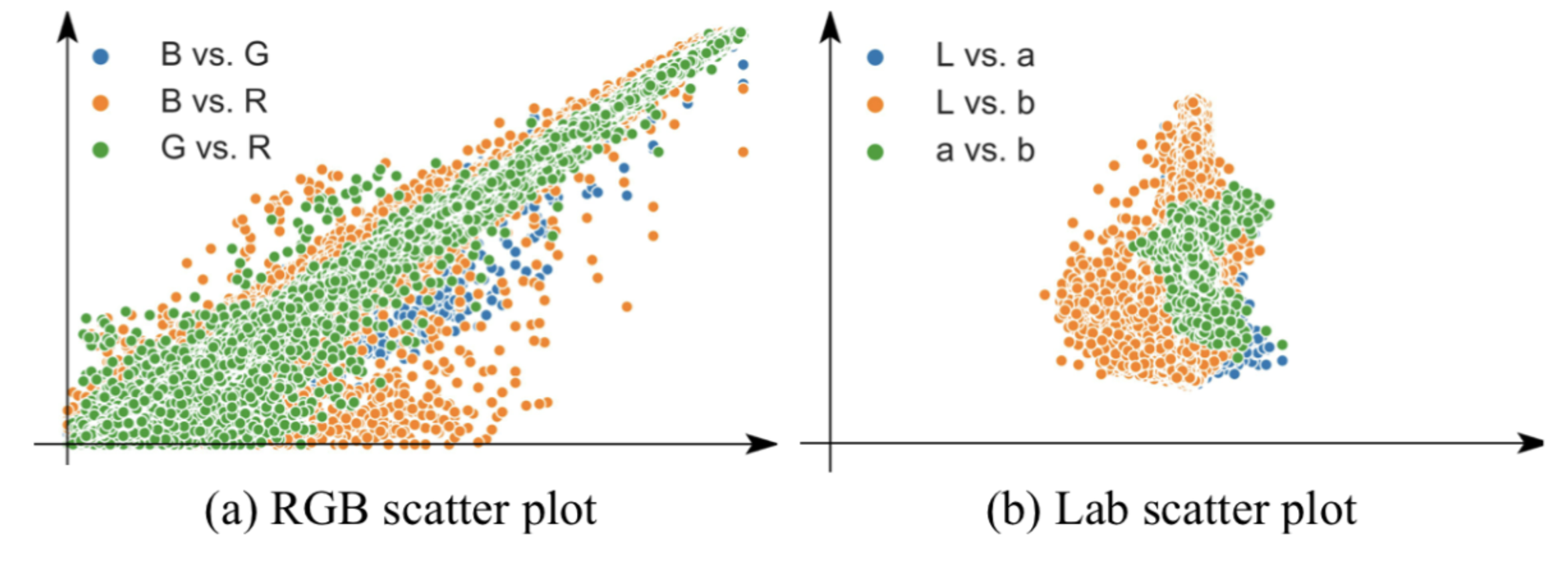
RGB色空間とLab色空間のチャネル間の相関
グレースケール画像からの色復元のタスクは複数の解が存在する問題であるため、Video Colrization ではタスクを量子化された色の分類問題として扱っていました。しかし、画素の色を直接推定する必要がある単一画像の場合とは異なり、物体追跡における色復元では reference frame から色を参照できること、また色を量子化することで情報が損失してしまうことを指摘し、回帰問題としてタスクを定式化した方がよいと主張しています。具体的には、復元された色と正解色に対する Huber Loss を用いてモデルを学習します。
モデルの枠組み
Reference frame として用いる過去複数フレーム(memory と呼称)から一括して類似度行列を求め、全てのフレームにおける類似度の重み和により色を参照します。
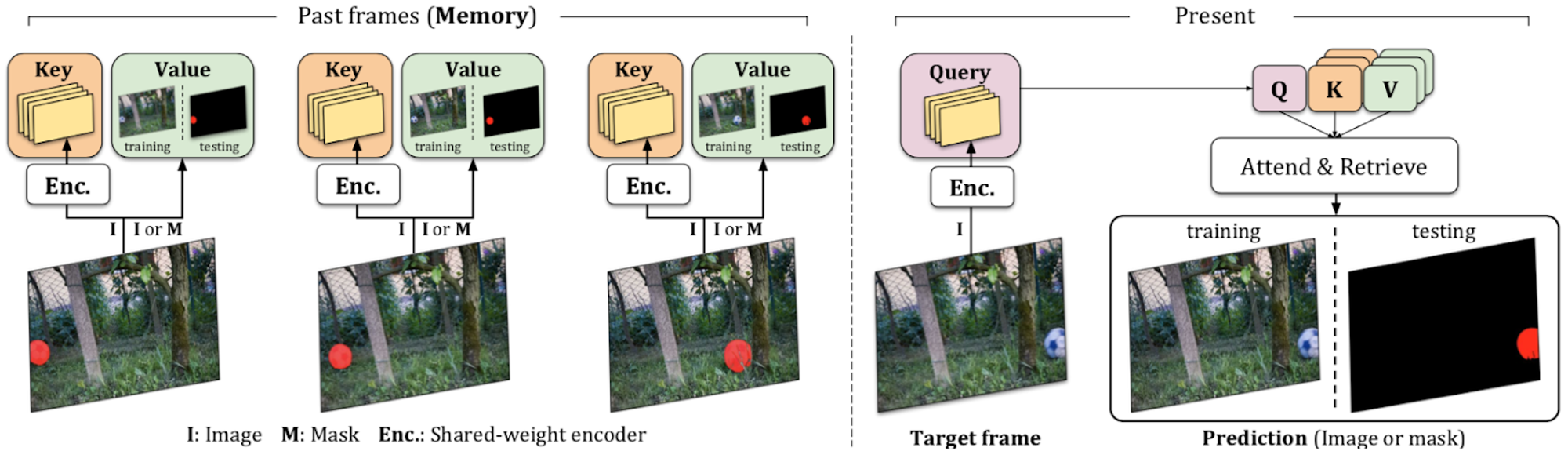
MASTの構成
しかし、高解像度な特徴マップを用いる場合、全てのフレームおよび画素の類似度値を求めるのは計算コストおよびメモリ消費量の観点から現実的ではありません(CorrFlowでは要素数10億以上の類似度行列を求めていました)。そこで、reference frame の target 画素近傍を Region of Interest (RoI) として、RoI 内のみの類似度行列を算出します。しかし、target frame と時間的に離れたフレームでは、追跡対象が RoI から出てしまう場合が存在します。そのため、reference frame から時間的に離れたフレームほど空間的な間引きを大きくした画素集合に対する類似度値(response map)を求めます。この response map の重心を RoI の中心とし、bilinear sampling で RoI の特徴マップをフレーム全体の特徴マップからサンプリングし、それを用いて最終的な類似度行列を算出します。これにより、少ないメモリ消費で物体が存在するであろう画素周辺の類似度行列を求めることができます。
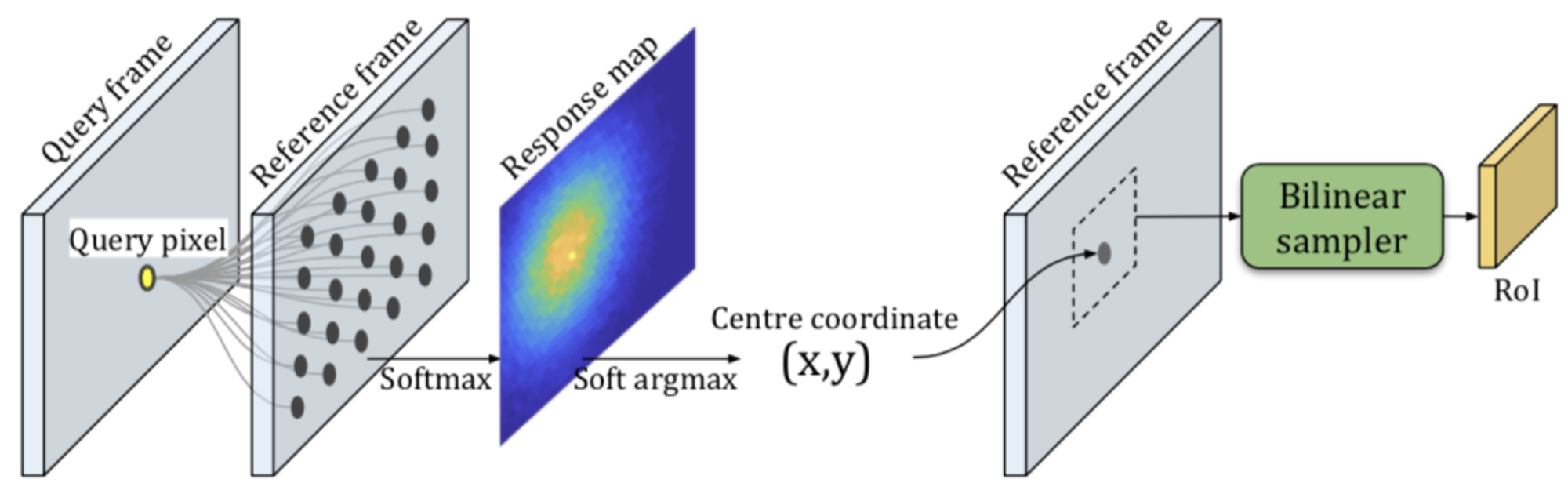
RoI localization
Reference frame には動画の1フレーム目と6フレーム目(long term memory)、また現在フレームを として 、、 フレーム(short term memory)を使用します。また、学習の効率を高めるため、1フレームのみを reference frame としてモデルを学習してから全 reference frame を用いてモデルを fine-tuning しています。
実験結果
既存の最先端の教師なし手法である UVC を 6.0ポイント上回るとともに、多くの教師あり手法を上回る性能を達成しています。
メモリ消費量の削減により、高解像度な埋め込みベクトル()を用いて多くのフレームを参照できるようになったこと、また RoI を動的に決定できることが既存手法と比べた性能向上に寄与しているものと考えられます。
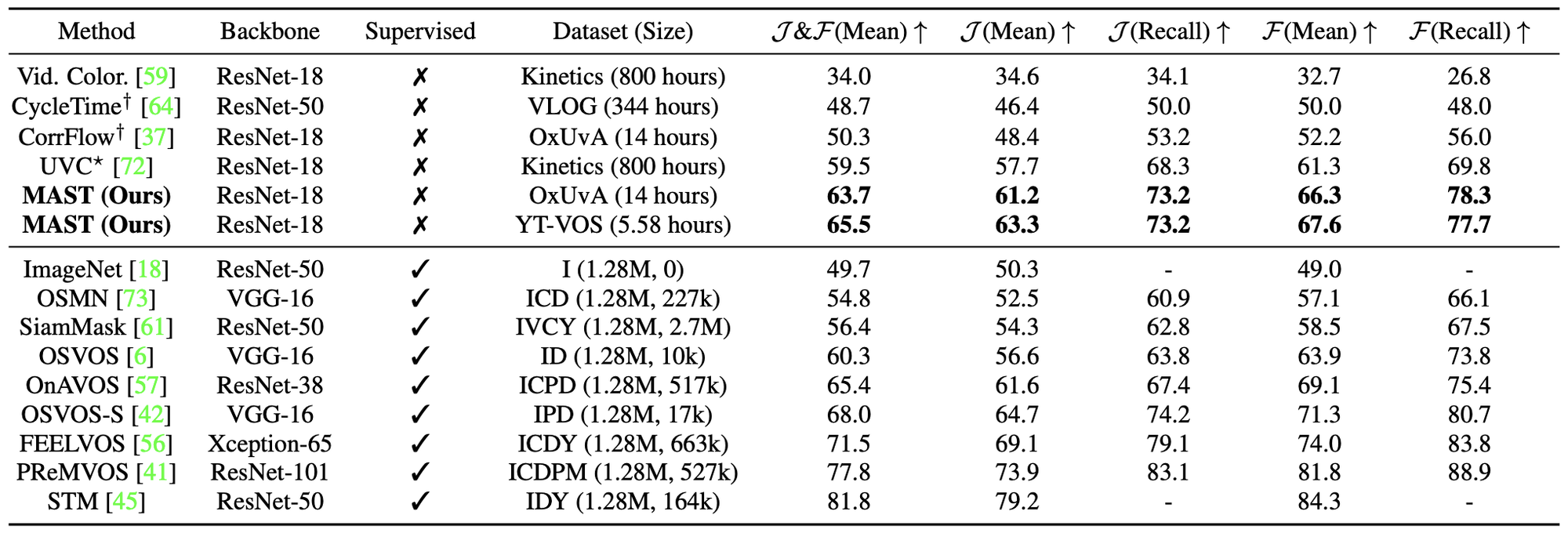
他手法との比較結果
また、多くの比較実験を通して以下のような実験結果を得ています。
- Lab画像を使用することが有効
- 回帰問題としてタスクを解くことが有効
- Long term memory の使用が有効
- Hardなラベルの伝播が有効
- 学習データセットによる大きな性能は見られない
- Reference frame は5フレームが最も高性能
さらに、YouTube-VOS データセットでは、学習データセットに含まれている物体クラス(seen)と含まれていない物体クラス(unseen)それぞれに対する性能およびそれらの差(generalization gap)を評価し、教師ありの最先端手法を含めた全ての比較手法の中で、提案手法の MAST が unseen クラスに対しては2番目の性能、generalization gap は最も低いことを示しました。また、教師なし手法は教師あり手法に比べ generalization gap が低い傾向にあり、教師なし手法の汎化性能の高さを示す結果が得られました。
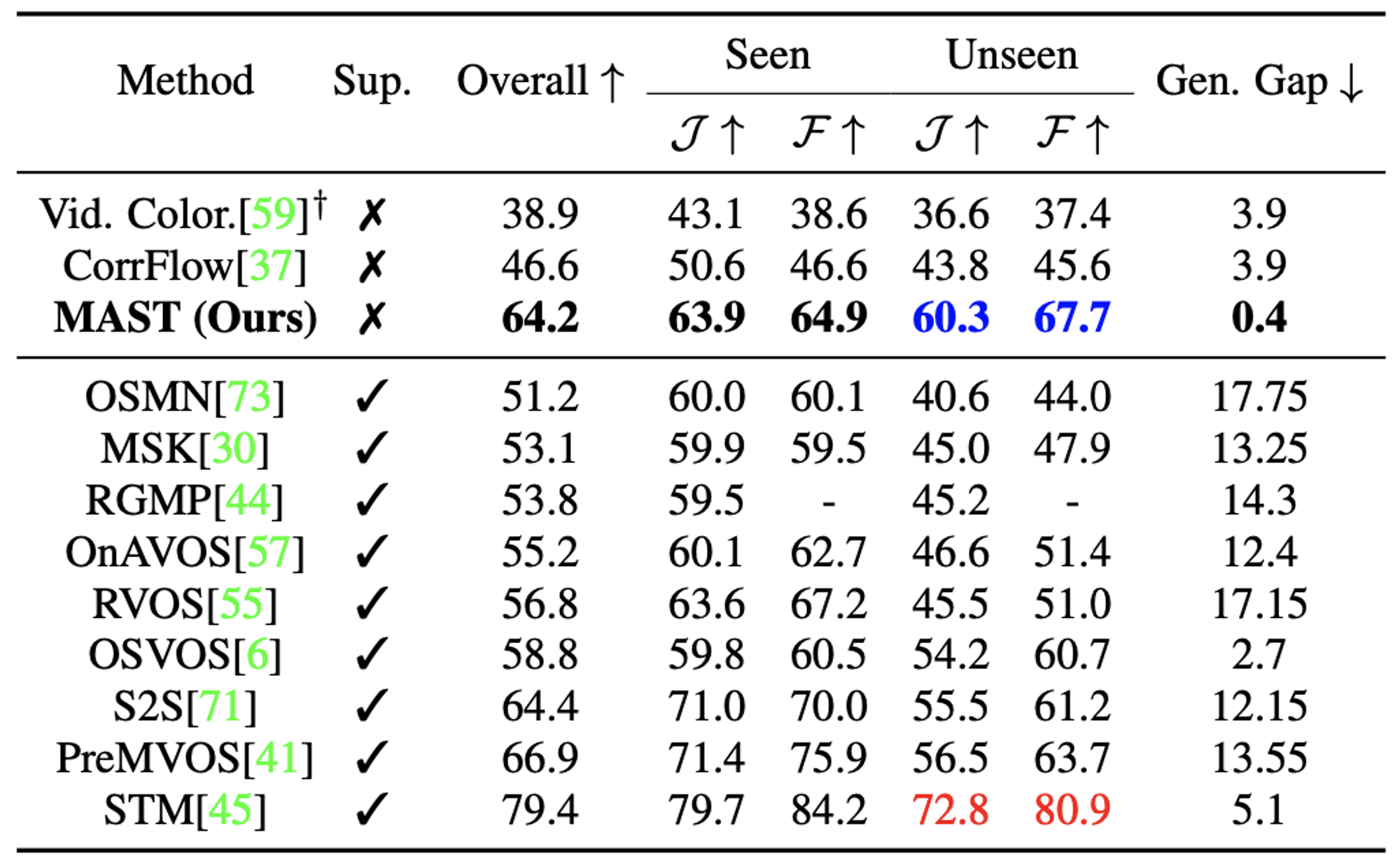
Youtube-VOS データセットでの汎化性能の評価結果
Multi-granularity VOS (MuG) (Lu+, CVPR’20) [18]
この研究は既存の手法とは異なるアプローチでモデルを学習することで、1フレーム目における領域が与えられた物体をその後のフレームにおいて追跡するVOS(論文では One-shot VOS と呼称)だけでなく、テスト時にラベルを用いずに主要な物体クラスやインスタンスを領域分割して追跡結果を得る Zero-shot VOS を可能としていることが特徴的です。
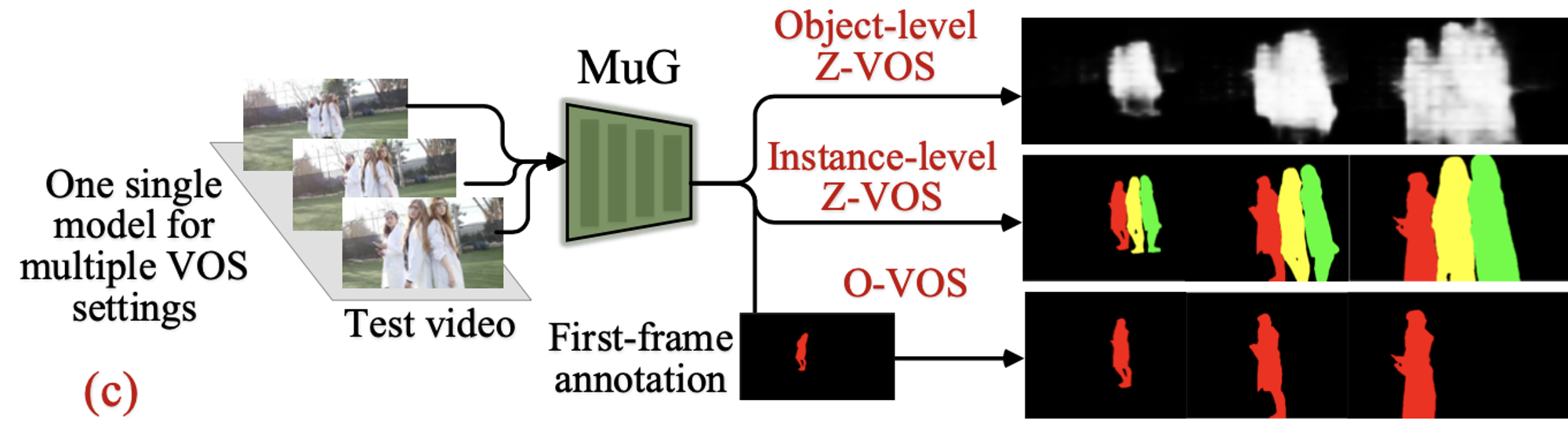
MuG の概要図
入力フレームに対応する特徴マップを出力するモデルを、以下の4つの粒度の教師信号を与えることで学習します。
Frame granularity analysis
フレーム毎に、教師なしで学習された saliency model [19]で推定された saliency map または 画像レベルのラベルで学習されたモデルの class activation maps (CAM) から、前景、背景を表す2値のマップを作成して教師ラベルとし、画素毎に cross entropy ロスを適用します。
Short-term granularity analysis
Wang らと同様、相関フィルタを用いて時系列的に順方向および逆方向へ追跡を行い、追跡の始点と終点の response map に対して cycle-consistency loss(L2ロス)を適用します。
Long-term granularity analysis
同じ動画からランダムにサンプリングした2つのフレームの幾何学的関係(並進、回転、スケール)を推定した後、対応画素の特徴ベクトルを近づけるよう損失関数を適用します。
Video granularity analysis
映像レベルに集約した特徴量が、同一動画ペアなら近く、異なる動画ペアなら遠くなるような埋め込み学習を行います。
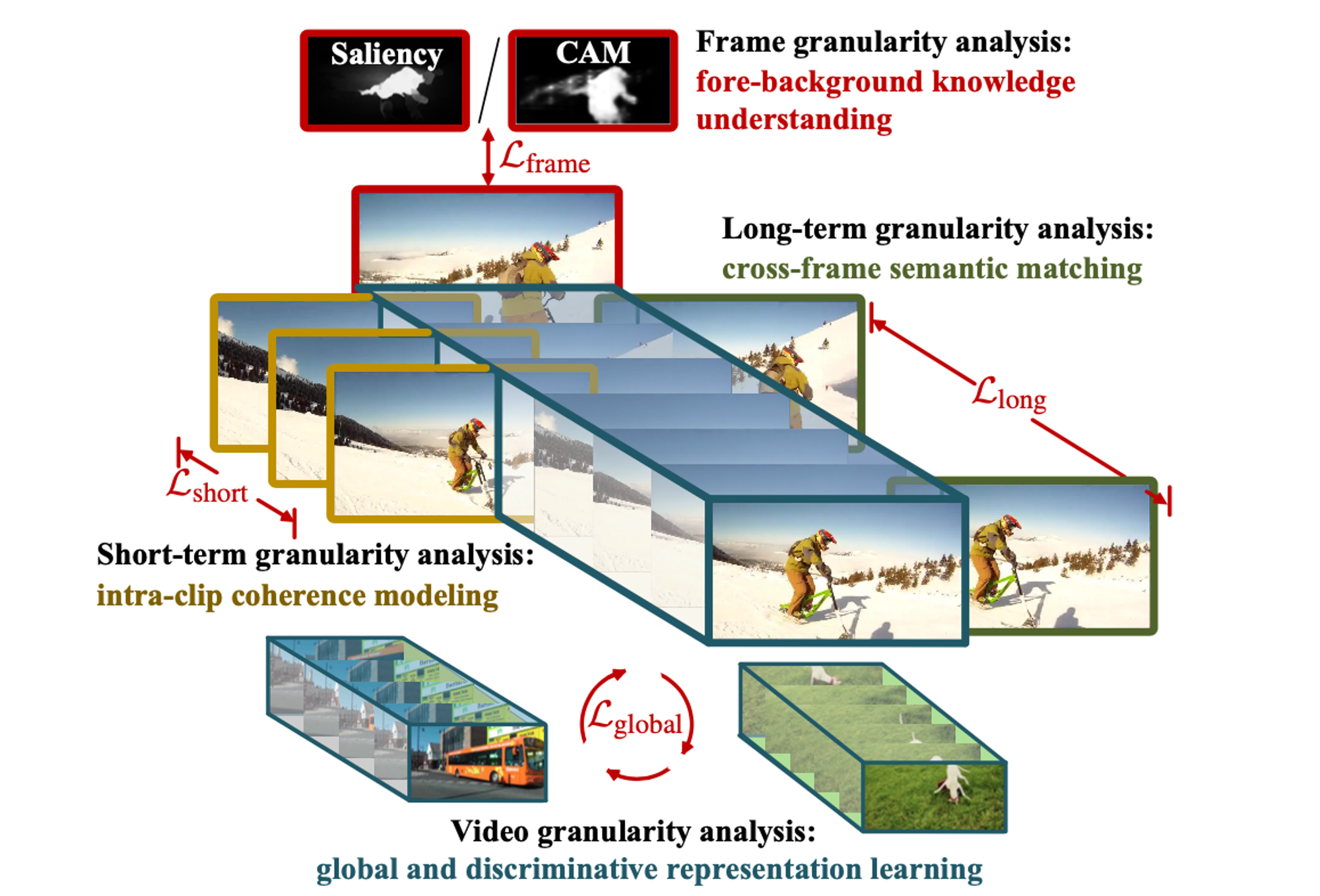
教師信号の種類
各VOS設定における推論時の処理は次のようになります。
- Object-level zero-shot VOS:フレーム毎に前景、背景の2値分類を行う
- Instance-level zero-shot VOS:Mask R-CNN や GrabCut などでインスタンスの候補領域を取得し、前景、背景の2値分類結果を用いて余分な候補領域を除外した後、IoUとオプティカルフローを用いて異なるフレームのインスタンス同士を対応づける
- One-shot VOS:前フレームから特徴ベクトルの類似度に基づきラベルを伝播させる
実験では、One-shot VOS において CorrFlow をやや上回る評価値が報告されています。

DAVIS-2017 データセットでの One-shot VOS の評価結果
VideoWalk (Jabri+, 2020) [20]
この研究では画素の対応付けを、画像中のパッチをノードとしたグラフにおける経路探索問題として定式化しています。その際、埋め込みベクトルの類似度に基づき隣接フレームのノード間の遷移確率を求め、それらを用いて時系列的に離れたノード間の遷移確率を算出して画素同士の対応関係を特定します。モデルの学習には cycle-consistency loss を用いています。
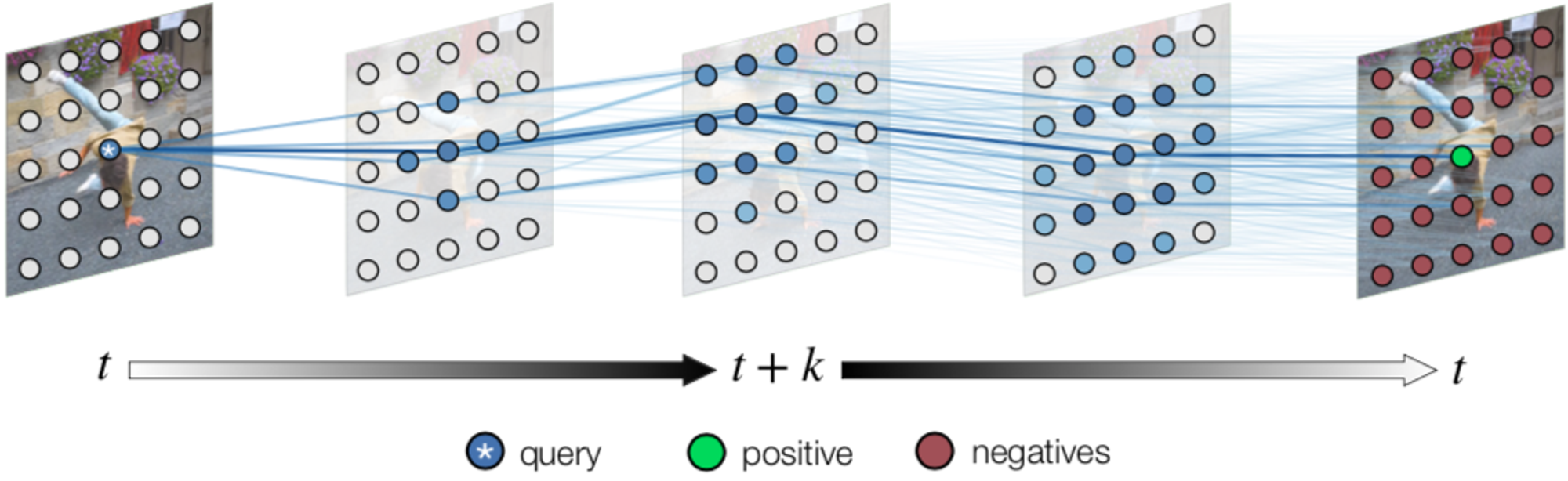
手法の概要
フレーム内のパッチ()をノードとするグラフによって映像を表現します。隣接フレームのノード間にエッジが定義され、フレーム のパッチ とフレーム のパッチ の類似度が次式で定義されます。
ここで、 はフレーム のノード集合、 は埋め込みベクトルペアの内積演算、 はソフトマックス関数の鋭敏さを決定する温度パラメータです。既存研究における画素をパッチに置き換えて類似度行列を算出しています。
そして、隣接フレームのノード間の類似度をノード間の遷移確率とみなし、遷移確率を時系列的に積算していくことで、時系列的に離れたノード間の遷移確率を算出します。
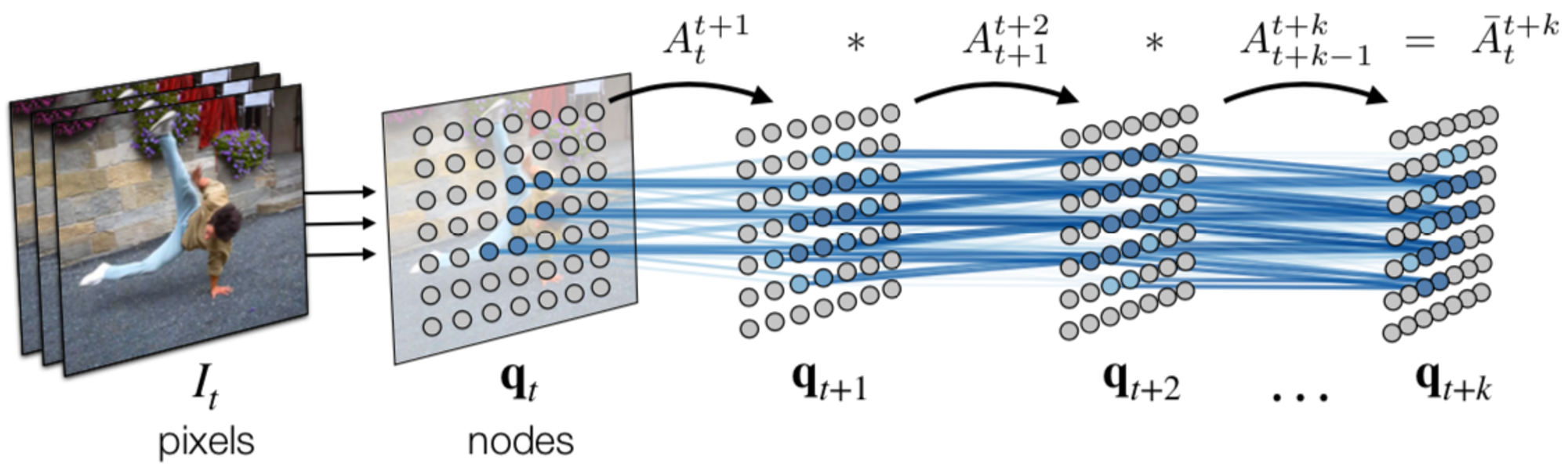
遷移確率の計算
モデルの学習時は下図のように → → と時系列的に折り返す形のシーケンスを用いてグラフを構築し、起点のノードと遷移後のノードが一致するよう cycle-consistency loss(ここでは cross entropy ロス)を適用します。
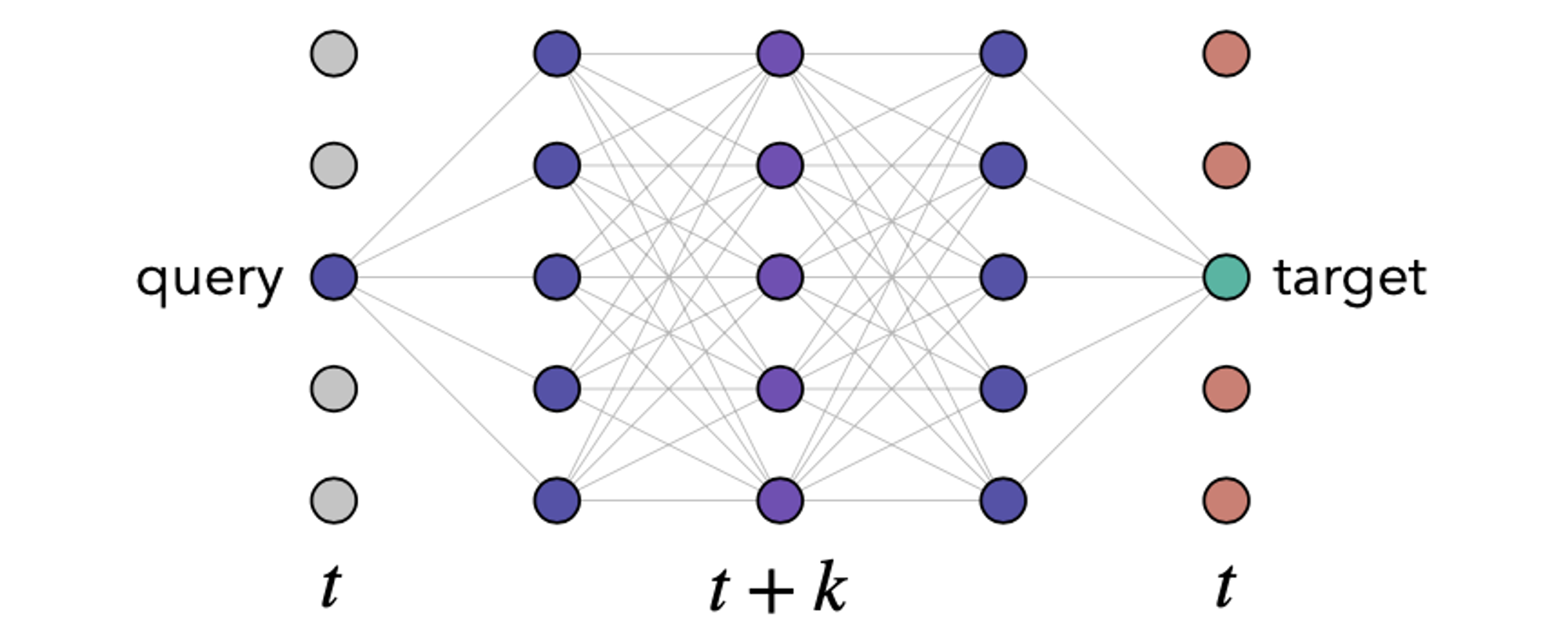
また、その他の提案として、エッジの遷移確率をランダムで0にする edge dropout を学習時に適用することで、他の経路を辿った遷移をモデルに課し、ノイズへの頑健化を図っています。
実験により、既存の教師なし手法を大きく上回る性能が得られることを確認しました。
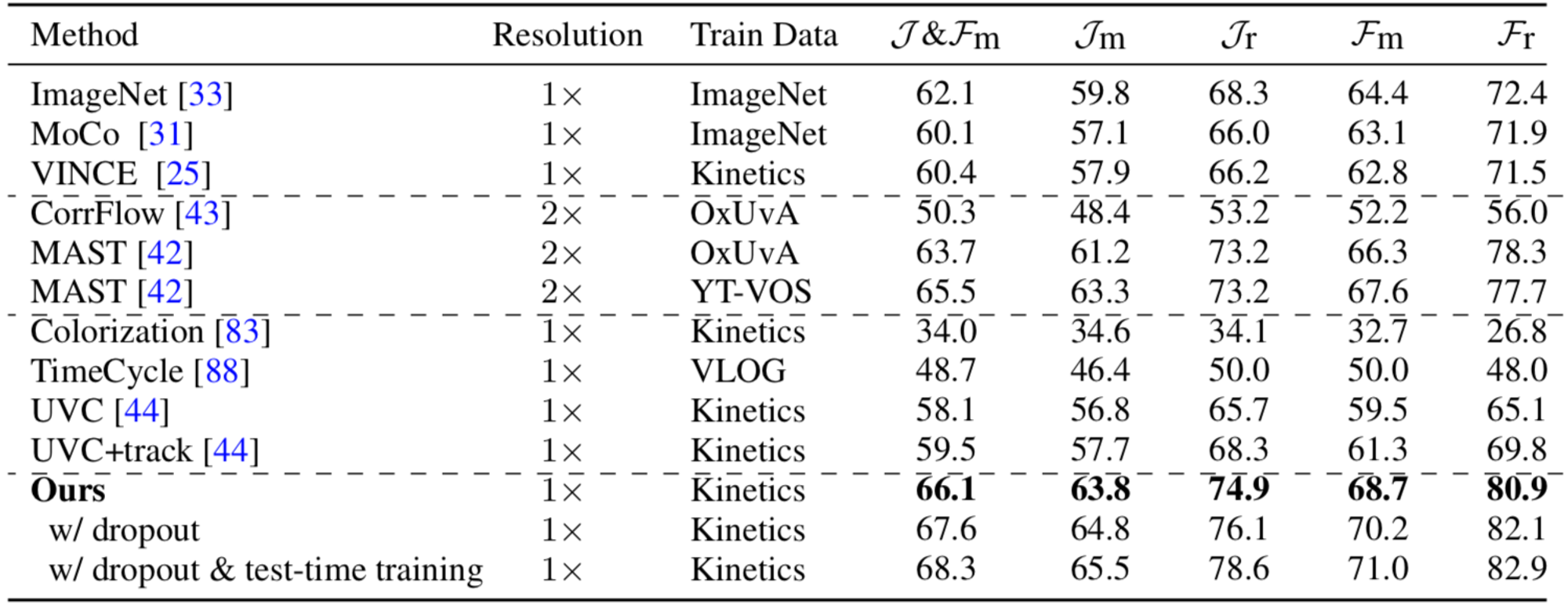
DAVIS-2017 データセットでの評価結果
以下の動画から、既存の教師なし手法と比べてより正確なVOSが可能となっていることがわかります。
まとめ
Dense tracking を教師なしで学習する方法として、以下のようなアプローチがあることを紹介しました。
- Video colorization
- Cycle-consistency learning
- フレームの再構成
- Saliency model や class activation map の利用
中でも video colorization と cycle-consitency learning が主要なアプローチとなっており、様々な観点での手法の改善が行われています。教師ありの最先端手法との性能差も徐々に小さくなってきており、今後の教師なし手法のさらなる発展を期待したいです。
おわりに
本記事では、ラベルなしデータを用いた画素レベルの追跡の学習に関する研究の動向を紹介しました。本記事が少しでも多くの方の理解の一助になりましたら幸いです。
また、弊社ではコンピュータビジョン技術を活用したサービス開発や研究開発に携わるエンジニアを募集しています。少しでも興味がありましたらぜひご連絡ください。
株式会社Mobility Technologies 求人一覧
参考文献
[1] C. Vondrick, A. Shrivastava, A. Fathi, S. Guadarrama, K. Murphy, “Tracking emerges by colorizing videos,” In ECCV, 2018.
[2] K. He, H. Fan, Y. Wu, S. Xie, R. Girshick, “Momentum contrast for unsupervised visual representation learning,” In CVPR, 2020.
[3] W. Kay, J. Carreira, K. Simonyan, B. Zhang, C. Hillier, S. Vijayanarasimhan, F. Viola, T. Green, T. Back, P. Natsev, M. Suleyman, A. Zisserman, “The kinetics human action video dataset” In arXiv:1705.06950, 2017.
[4] D. F. Fouhey, W. Kuo, A. A. Efros, and J. Malik, “From lifestyle vlogs to everyday interactions,” In CVPR, 2018.
[5] J. Valmadre, L. Bertinetto, J. F. Henriques, Tao R., A. Vedaldi, A. Smeulders, P. H. S. Torr, and E. Gavves, “Long-term tracking in the wild: A benchmark,” In ECCV, 2018.
[6] N. Xu, L. Yang, Y. Fan, D. Yue, Y. Liang, J. Yang, and T. Huang, “Youtube-vos: A large-scale video object segmentation benchmark,” In arXiv:1809.03327, 2018.
[7] J. Pont-Tuset, F. Perazzi, S. Caelles, P. Arbeláez, A. Sorkine-Hornung, and L. Van Gool, “The 2017 davis challenge on video object segmentation,” In arXiv:1704.00675, 2017.
[8] F. Perazzi, J. Pont-Tuset, B. McWilliams, L. V. Gool, M. Gross, A. Sorkine-Hornung, “A benchmark dataset and evaluation methodology for video object segmentation,” In CVPR, 2016.
[9] T. Lin, M. Maire, S. J. Belongie, J. Hays, P. Perona, D. Ra- manan, P. Dollár, and C. L. Zitnick, “Microsoft coco: Common objects in context,” In ECCV, 2014.
[10] X. Wang, A. Jabri, A. A. Efro, “Learning correspondence from the cycle- consistency of time,” In CVPR, 2019.
[11] J. Y. Zhu, T. Park, P. Isola, A. A. Efros, “Unpaired image-to-image translation using cycle-consistent adversarial networks,” In ICCV, 2017.
[12] D. Dwibedi, Y. Aytar, J. Tompson, P. Sermanet, A. Zisserman, “Temporal cycle-consistency learning,” In CVPR, 2019.
[13] N. Wang, Y. Song, C. Ma, W. Zhou, W. Liu, H. Li, “Unsupervised deep tracking,” In CVPR, 2019.
[14] S. Kong, C. Fowlkes, “Multigrid predictive filter flow for unsupervised learning on videos,” In arXiv:1904.01693, 2019.
[15] Z. Lai, W. Xie, “Self-supervised learning for video correspondence flow,” In BMVC, 2019.
[16] X. Li, S. Liu, S. D. Mello, X. Wang, J. Kautz, M.-H. Yang, “Joint-task self-supervised learning for temporal correspondence,” In NeurIPS, 2019.
[17] Z. Lai, E. Lu, W. Xie, “Mast: A memory-augmented self-supervised tracker” In CVPR, 2020.
[18] X. Lu, W. Wang, J. Shen, Y-W. Tai, D. Crandall, S. C. H. Hoi, “Learning video object segmentation from unlabeled videos,” In CVPR, 2020.
[19] C. Yang, L. Zhang, H. Lu, X. Ruan, M. H. Yang, “Saliency detection via graph-based manifold ranking,” In CVPR, 2013.
[20] A. Jabri, A. Owens, A. A. Efros, “Space-time correspondence as a contrastive random walk,” In arXiv:2006.14613, 2020.