

SREグループの定例ミーティングでやっていること
SREチーム開発December 05, 2022
こんにちは、SREグループの水戸 (@y_310)です。MoTのSREグループでは毎週1時間の定例ミーティングを実施しています。今回はこのミーティングの目的や内容についてご紹介します。
ミーティングの目的
SREグループでは毎朝30分のスタンドアップミーティング (リモート)を実施しており日々のタスク確認はこの中で行っています。そのため週次の定例ミーティングでは進捗確認は一切やっていません。では、何のためにミーティングを行っているかというと大きく2つの目的があります。
- 運用しているサービスの定点観測によるヘルスチェック
- まとまった時間を取って検討したい課題の議論や直近で導入した新しい仕組みの共有の場
この記事では特に1つ目のサービスの定点観測によるヘルスチェックついて詳しくご紹介したいと思います。
サービスの定点観測
サービスの定点観測とは具体的には何のことでしょうか?SREグループでは数十のマイクロサービスを運用しており、日常的なアラート対応などを日々行っています。ただサービスというのは様々な要因によって徐々に性能が劣化していったりいつの間にかエラーが増えていたりといったことが起こります。そのためアラートへの都度対応だけでは気づきにくい中長期的な変化に気づくためにサービスの基本的なメトリクスとアラートの件数を週次で確認しています。
定点観測するメトリクス
ではどんなメトリクスを観測するのが良いでしょうか?この定点観測においては個別のサービスの細かい問題を洗い出すのではなく全体として傾向の変化が無いかを見ることが目的です。そのため、SLIを見るのが都合が良いと考えています。
SREグループでは運用している全てのサービスに対して共通の指標をSLIとして定義し可視化しています。理想的にはサービス毎にそのサービスの特性を表現できる指標を選ぶべきとは思いますが計測や自動化のしやすさを重視して今のところサービスによらず共通の指標を使用しています。
具体的にはSRE本のThe Four Golden Signalsを参考にした以下の3つの指標をSLIとしています。
- Latency: レスポンスタイム
- Traffic: RPS
- Errors: エラー率
なお、Saturationについては問題があった場合に他の指標で観測できる可能性が高いことから現状は含めていません。(もちろん通常のアラート設定などはしており、無視しているわけではありません)
The Four Golden Signalsをベースにしたメトリクス監視については以前New Relic User Groupで発表した以下の資料も合わせてご覧ください。
https://speakerdeck.com/y310/maikurosabisuhuan-jing-niokerujian-shi-falsexiao-lu-hua
3つのSLIを定点観測するにあたって、既に運用しているサービスが数十に渡ることからこれをすべて見るだけでもミーティングの時間では終わらない量になってしまうため、実際にはサービス単位ではなくKubernetesのネームスペース単位で集計した値を観測しています。
メトリクスの観測方法
観測値は毎週GoogleスプレッドシートのApps ScriptによってNew RelicのAPI経由で取得され、シート上で可視化されます (これはNew Relicのメトリクス保存期間を超えて長期のトレンドを把握するために古いデータを保存し続ける目的で行っています) 。SREグループではネームスペース毎に主担当を決めているため、各ネームスペースの主担当者がメトリクスレポートを定例ミーティング資料にコピーして所感を記入し、メトリクスに異常値が見受けられる場合は簡単な原因調査を行って何が起きているかを把握します。
定例ミーティング内でネームスペースごとに各担当者が状況を報告し、異常があるものは議論した上で改善タスクチケットを作成したり、開発チームに状況をフィードバックするといったアクションを行います。
例としてこちらはとあるネームスペースのメトリクスレポートです。
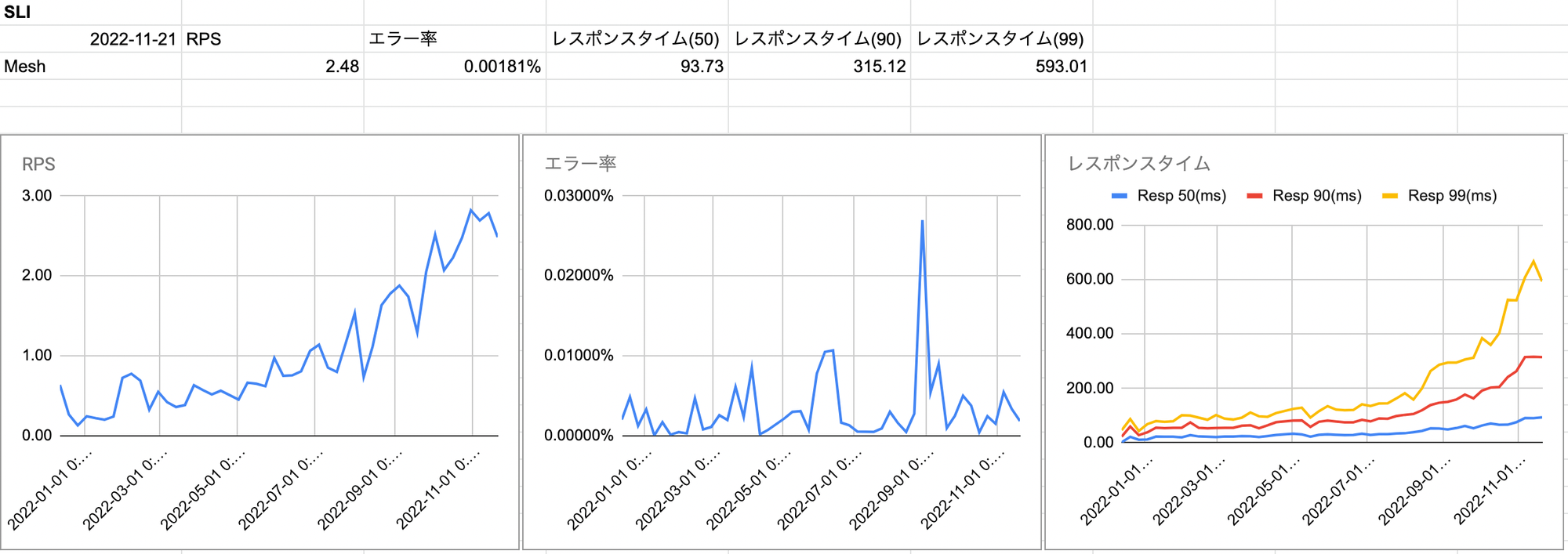
RPSが着々と増えておりサービスの利用が進んでいることが分かります。もし突然大きく増えたり減ったりした場合には何か想定外のことが起きていることを疑って原因を調査します。
エラー率については増減はあるものの傾向として大きな変化はないことから安定していると考えられます。
レスポンスタイムについてはRPSに比例して指数的に遅くなっていってることが分かります。まだサービスに深刻な影響があるレベルではなかったため9月頃までは様子を見ていましたが上昇が止まらないため先日詳細を調査したところ、リクエスト数の多いAPIの中でレスポンスの遅い外部APIを叩いている部分があることを発見し開発チームにフィードバックしました。
こういった形でサービスのヘルスチェックを行い問題の早期発見につなげています。
定点観測するアラート
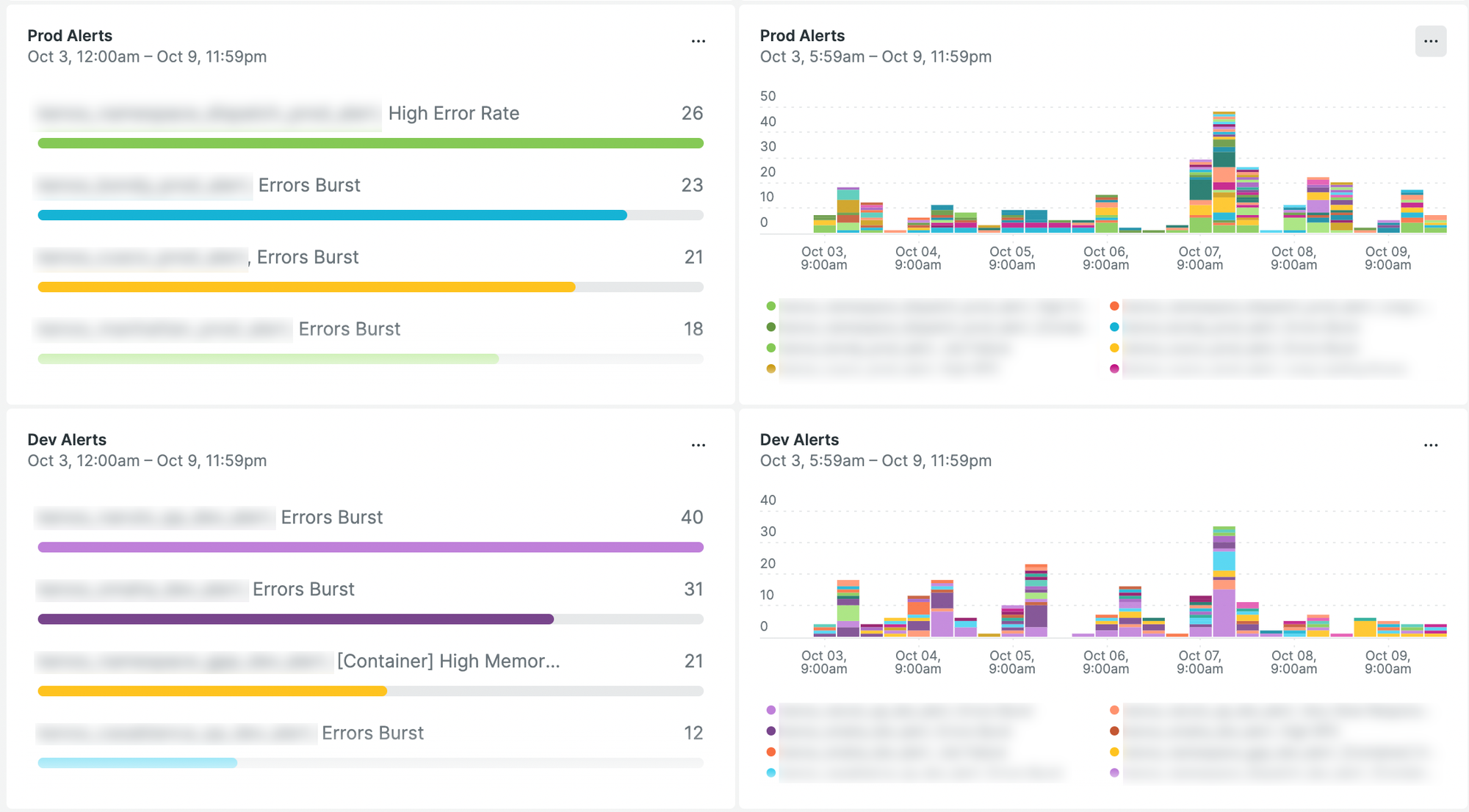
アラートについては直近一週間の傾向のみを一覧できるダッシュボードをNew Relic上に作成しており、そこから発生傾向のグラフと発生件数の多いアラートのリストを定例ミーティング資料にコピーします。その後発生件数の多いアラートについて個別に原因調査を行いコメントを記入します。
またアラートの多くは閾値調整の不足によって発生しているため、その場で閾値も調整して今後不要なアラートが発生しづらいように対応します。
ehこちらが実際のアラートダッシュボードです。ここから本番環境と開発環境それぞれで発生件数の多かったアラートをピックアップし分析します。本番環境の10/7頃にアラートが多く発生していることが分かりますが、この時は外部APIに障害が発生しておりそれの影響を受けて複数の関連サービスでもエラーが多発していました。
また開発環境でも特定のアラートが頻発していましたが、こちらは実装の問題によりデータベースの接続数上限にあたってエラーになっているものでした。本番環境では開発環境に比べてDBの接続数上限値が大幅に高いため発生していませんでしたが潜在的な問題を発見することに繋がりました。
ミーティングの効果
定例ミーティングをサービスヘルスチェックの場とすることで、個人の注意力に依存せずに仕組みとして継続的にサービスを監視することができるようになりました。
毎週サービスの稼働状況について確認することで徐々に悪化するパフォーマンスに早期に気づくことができ障害が起こる前に改善アクションを取ることができたり、アラートを定期的に整備することで不要なアラートが鳴り続ける状況を抑止することができています。
またチーム全員が全てのサービスのメトリクスを継続して見続けることでサービスの通常状態の傾向の肌感を掴むことができ、異常が起きたときの変化に気づきやすい体制になりました。
まとめ
SREグループでは運用するシステムの標準化、共通基盤化を常に推進していますが、技術面の標準化だけでなく運用面でも標準化を進めることで効率的に多数のサービスを運用できる体制の構築を日々進めています。定例ミーティングは何となく進捗確認などをするだけで終わってしまいがちだったりしますが、現状把握のための定点観測の場とするのも一つの有意義な使い方ではないかと思います。
We're Hiring!
📢
Mobility Technologies ではともに働くエンジニアを募集しています。
興味のある方は 採用ページ も見ていただけると嬉しいです。
Twitter @mot_techtalk のフォローもよろしくお願いします!