

PosgreSQLのFDWを使ってデータベース間で透過的にクエリする
RDBServerSideDecember 15, 2021
💡
次世代事業本部 データビジネス部 KUUグループの田中です。
今回は、PosgreSQLのFDWを活用して、外部データベースに存在するテーブルを透過的に扱えるようにし、同一データベース内でJOINやサブクエリ利用をできるようにした話です。
はじめに
株式会社ゼンリンと共同開発中の本プロジェクト(ニュースリリース)では、複数のモジュールに分割して開発したアプリケーションをAWS上にサーバレスで構築し、システム全体がスケーラブルかつ機能ごとの拡張性が高くなるように設計・開発を進めています。
全体像は弊社の渡部が登壇したDeNA TechConn 2021の「ドライブレコーダの動画を使った道路情報の自動差分抽出」をご覧いただくと、より具体的にイメージしやすいかと思います。
FDW(Foreign Data Wrapper)とは?
FDW(Foreign Data Wrapper)とはPostgresSQL上で利用できる外部データ参照機能のことです。 起点となるデータベースから、外部のRDBやKVSなどのデータソースを参照するできる仕組みで、データソースごとの接続モジュールを組み合わせて利用します。 PostgresSQLのデータベース間接続をおこなうには、バージョン9.3以降で提供されているpostgres_fdwを利用します。
dblinkとの違い
PostgresSQLのデータベース間接続をおこなう方法はFDW以外にも、古くから使えるdblinkと呼ばれる機能があります。
大きな違いとして、dblinkはモジュール関数を使って別データベースのテーブルに対するSQLを発行するのに対し、FDWは同一データベースに存在するテーブルと同じようにSQLを発行することができます。データベース接続方法についても、dblinkは接続のたびにモジュール関数実行が必要なのに対し、FDWはあらかじめ接続の設定をおこなっておけば都度の特別な操作は必要ありません。
なぜFDWを使うのか
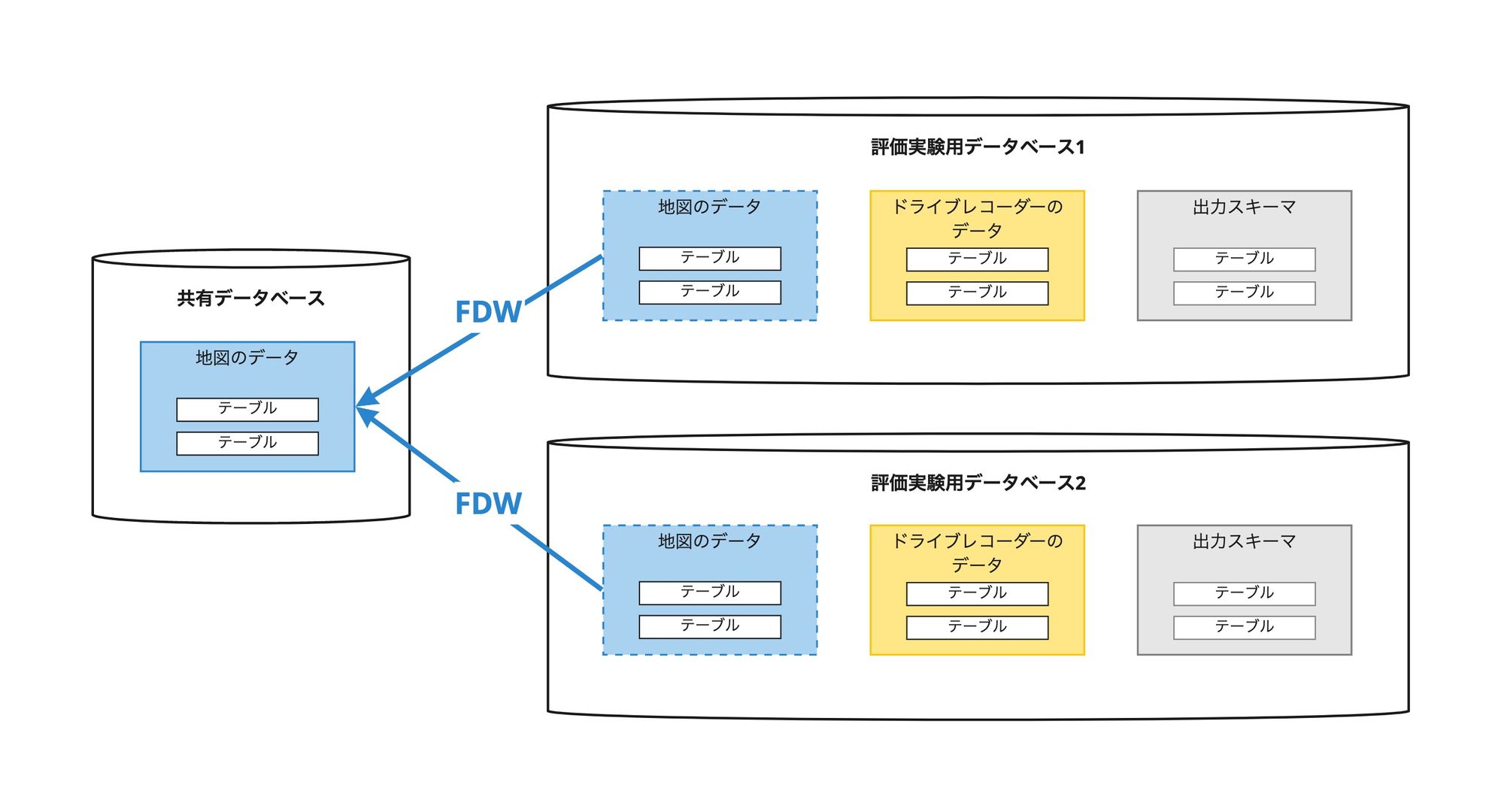
本プロジェクトでは定期的に性能測定とよばれるシステムの評価実験をおこなっており、評価対象ごとにデータベースを独立させて、処理の実行から結果の評価実験までを実施しています。
実施する中で以下のような課題が発生し、FDWを活用して対応をおこないました。
課題
- 評価実験の入力は、主に地図とドライブレコーダーのデータだが、評価実験ごとに地図のデータを格納したデータベースを作ると、データ容量が大きすぎて、取り扱いが難しく保管コストも高くなる
対応
- 共通データベースと、評価実験用データベースを準備
- 共通データベースには地図のデータを格納
- 評価実験用データベースにはドライブレコーダーのデータを格納
- 評価実験用データベースから共通データベースに対してFDWを設定し、共通データベースにある地図のデータが格納されたテーブルを、評価実験用データベースから透過的にクエリできるようにした
FDWの設定方法
ここからは、postgres_fdwを利用したFDWの設定方法を紹介します。
拡張機能の有効化
postgres_fdwを利用するにあたり、接続元データベース・接続先データベース双方でpostgresSQL上で拡張機能を有効化します。
CREATE EXTENSION postgres_fdw;接続先データベースの設定
postgres_fdwで接続先データベースにアクセスするための情報を、外部サーバに定義します。
CREATE SERVER ${外部サーバ名} FOREIGN DATA WRAPPER postgres_fdw
OPTIONS (
host '${接続先ホスト名}',
dbname '${接続先データベース名}',
port '${接続先データベースのポート番号}'
);接続先データベースのユーザー設定
接続元データベースのユーザーが、接続先データベースにログインする際に使用するユーザーを紐付けます。
CREATE USER MAPPING FOR ${接続元データベースのユーザー名} SERVER ${外部サーバ名}
OPTIONS (
user '${接続先データベースのユーザー名}',
password '${接続先データベースのユーザーパスワード}'
);外部テーブルの一括定義
接続先データベースのテーブルにアクセスするためには、接続元データベースのスキーマ※に各テーブルの外部テーブル定義を作成する必要があります。
ただ、テーブル単位で作成するのは大変ため、接続先のスキーマを指定することでスキーマ内の全テーブルの定義を自動で作成してくれるやり方を記載します。
IMPORT FOREIGN SCHEMA ${接続先データベースのスキーマ名}
FROM SERVER ${外部サーバ名}
INTO ${接続元データベースに配置するスキーマ名};これは新規にテーブルを作成する場合の方法ですが、テーブル定義を更新する場合にも応用可能であり、具体的には外部スキーマを一度削除した後に上記のコマンドで再度スキーマを作成することで、一括でテーブル定義を更新することが可能です。
※スキーマ・・・ここで言うスキーマとはデータ構造の意味ではありません。PostgreSQLのスキーマはテーブルをグルーピングした概念のことで、データベースには複数のスキーマが存在し、スキーマには複数のテーブルが存在します。
外部テーブル参照の確認
設定がうまくできていれば、接続元データベースのスキーマを経由して外部テーブルのデータを参照できます。
SELECT * FROM ${接続元データベースに配置したスキーマ名}.${テーブル名};FDWの注意点
実際に使ってみて気づいた注意点について紹介します。
デフォルトでは外部の統計情報が使われない
外部テーブルを参照するSQLを実行する際、デフォルトでは外部テーブルの統計情報が使用されません。
統計情報とは、テーブルのインデックス内容やサイズ、データの重複度合いや頻出度などを保持したもので、最適なSQLの実行計画を算出するために用いられます。
外部テーブルの統計情報を取得するコストも必要なため、小さなテーブルの場合はそのままのほうがパフォーマンスが良い可能性もありますが、データ量が多く正しい統計情報を使わないと検索効率が悪い場合は、外部サーバ定義の際にuse_remote_estimateをtrueにして、外部テーブルの統計情報が使われるようにします。
CREATE SERVER ${外部サーバ名} FOREIGN DATA WRAPPER postgres_fdw
OPTIONS (
host '${接続先ホスト名}',
dbname '${接続先データベース名}',
port '${接続先データベースのポート番号}',
use_remote_estimate 'true'
);デフォルトでは外部の拡張機能が使われない
外部テーブルを参照する際、デフォルトでは外部テーブルに適用されている拡張機能が使われません。
そのため拡張機能を利用している場合は、以下のように外部サーバのextensionsに対象の拡張機能を指定します。
CREATE SERVER ${作成する外部サーバ名} FOREIGN DATA WRAPPER postgres_fdw
OPTIONS (
host '${接続先ホスト名}',
dbname '${接続先データベース名}',
port '${接続先データベースのポート番号}',
extensions '${拡張機能名}'
);たとえばPostGISで、接続元から以下のようなモジュール関数を利用したクエリを実行したい場合、外部の拡張機能にpostgisを指定しておく必要があります。
SELECT
name,
ST_DISTANCE(
'SRID=4326;POINT(139.7649308 35.6812362)',
geom_column
) -- 東京駅からの距離(m)
FROM postgis_table;おわりに
今回使ってみるまでFDWを知らなかったのですが、同一データベース内のテーブルとして別データベースのテーブルを扱えるのは使い勝手がよく、覚えておいて損はない機能だと思いました。仕組みとパフォーマンス劣化への懸念は理解した上で、活用を検討いただければ幸いです。
なお、「FDW」か「FWD」かわからなくなることがありますが、Wapperなので最後はWと覚えておけば良さそうです。もしくは「PostgresSQL」とセットで検索すれば、Google先生が訂正してくれます。
We're Hiring!
📢
Mobility Technologies ではともに働くエンジニアを募集しています。
興味のある方は 採用ページ も見ていただけると嬉しいです。
Twitter @mot_techtalk のフォローもよろしくお願いします!