

ドラレコ動画の物体検出モデルをデータの量や質に着目し改善するData-Centric AIな取り組み
AIコンピュータビジョンJanuary 05, 2023
AI技術開発部の鈴木達哉です。Mobility Technologies (MoT)ではドライブレコーダーから取得できる情報を元に道路上の物体を検出し、地図と比較することで現地と地図の差分を見つけ、地図を更新する『道路情報の自動差分抽出プロジェクト』を株式会社ゼンリンと共同で進めています。本記事ではドラレコ動画から道路標識を認識するAIの精度改善を機械学習モデルではなくデータの量と質に着目し実現した事例を紹介します。
はじめに
本記事は、2022年4月6日に開催された「MoT TechTalk #11 深掘りコンピュータビジョン!研究開発から社会実装まで」での発表「データの量や質を改善するData-Centric AIな取り組み」を発展させたものです。発表の動画・資料を公開していますので、そちらもあわせてご覧ください。
本プロジェクトにおいては、様々な種類の道路標識をドラレコ動画から検出する必要があります。当初所有していたデータセットで学習したプロトタイプモデルでは学習データの少ない珍しい道路標識は精度が低いという課題がありました。例えば道路上で頻出の「最高速度」と珍しい「高さ制限」の検出精度をAverage Precisionで比較すると、それぞれ0.78、0.48と大きな乖離があり、表1に示すようにやはり学習枚数が精度に直結していることがわかります。実際のプロジェクトではより多くの標識を扱っていますが、本記事ではこの2つを例に話を進めていきます。
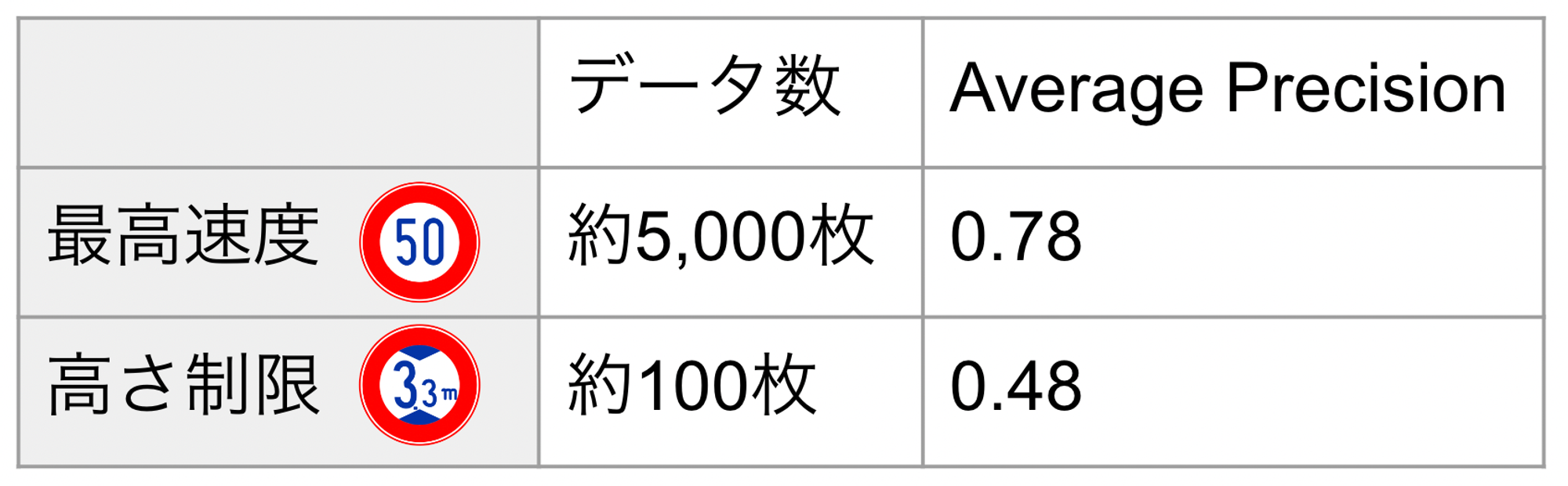
表1:各標識の学習データ数とAverage Precision
Model-Centric AI vs. Data-Centric AI
課題の解決には2つのアプローチが考えられました。Model-Centric AIかData-Centirc AIかです。従来AI開発で注目されてきた領域はModel-Centric AIで、データを固定して機械学習モデルを改良していくアプローチをとります。着目点はどのようなモデルを使うかや、どのような学習を行うかです。
一方、近年注目されつつあるのがData-Centric AIです。Model-Centric AIとは逆に、機械学習モデルを固定して、データを改良していくアプローチをとります。着目点はどのようにデータを収集し量を増やすかや、どのようにデータの質を高めるかです。これらは従来から経験的に重要視されてきたことですが、2021年にAndrew Ng先生が提唱したことで体系化が進んでいます。Data-Centri AIについて詳しくはData-centric AI Resource Hubをご覧ください。
今回は後者のData-Centric AIなアプローチで精度改善をすることにしました。利用していた物体検出モデルは、十分な量のデータで学習すれば高い精度が得られることが公開データセットによるベンチマークで報告されていたためです。また、累計4万台を超える車両に搭載されている『DRIVE CHART』を通して大量のドラレコ動画を収集可能であるというのも理由のひとつです。
ここからはデータの量と質、それぞれに対しての改善のアプローチを紹介していきます。
どのようにデータの量を増やすか
一般的には学習データが多い方が精度が高くなりますが、必要な枚数を効率的に用意する方法を考える必要があります。必要な枚数は、例えば著名な物体検出モデルのYOLOv4では1クラスあたり2000枚以上の画像での学習が推奨されていますのでこれを基準に考えます。
当初所有していたデータセットでは珍しい「高さ制限」クラスは約100枚の画像がありました。これを2000枚に増やすには、追加でこれまでの19倍の動画収集工数とアノテーション工数がかかると予想できます。例えばアノテーションには他のクラスも含めこれまでに数人月かけてきていましたので、必要数集めるには数十人月が必要ということになりかなりのコストです。
地図とGPSを使ってデータを効率的に集める
当初のデータセットはランダムにサンプリングしたドラレコ動画にアノテーションして作成したものでした(図1上)。この方法だと標識ごとの設置数の大小がデータ数にそのまま反映されることになり、珍しい標識のデータがなかなか集まりません。
そこで、本プロジェクトのパートナーであるゼンリンから提供された標識の位置データと、ドライブレコーダのGPS情報を組み合わせることで、データを増やしたい標識が写ったドラレコ動画のフレームを特定する仕組みを作成しました(図1下)。対象標識が写っている確率が高いフレームのみをアノテーション作業に回すため、目標とする枚数を集めるために見なければならないフレームの枚数が大幅に減りアノテーション工数を削減することができます。
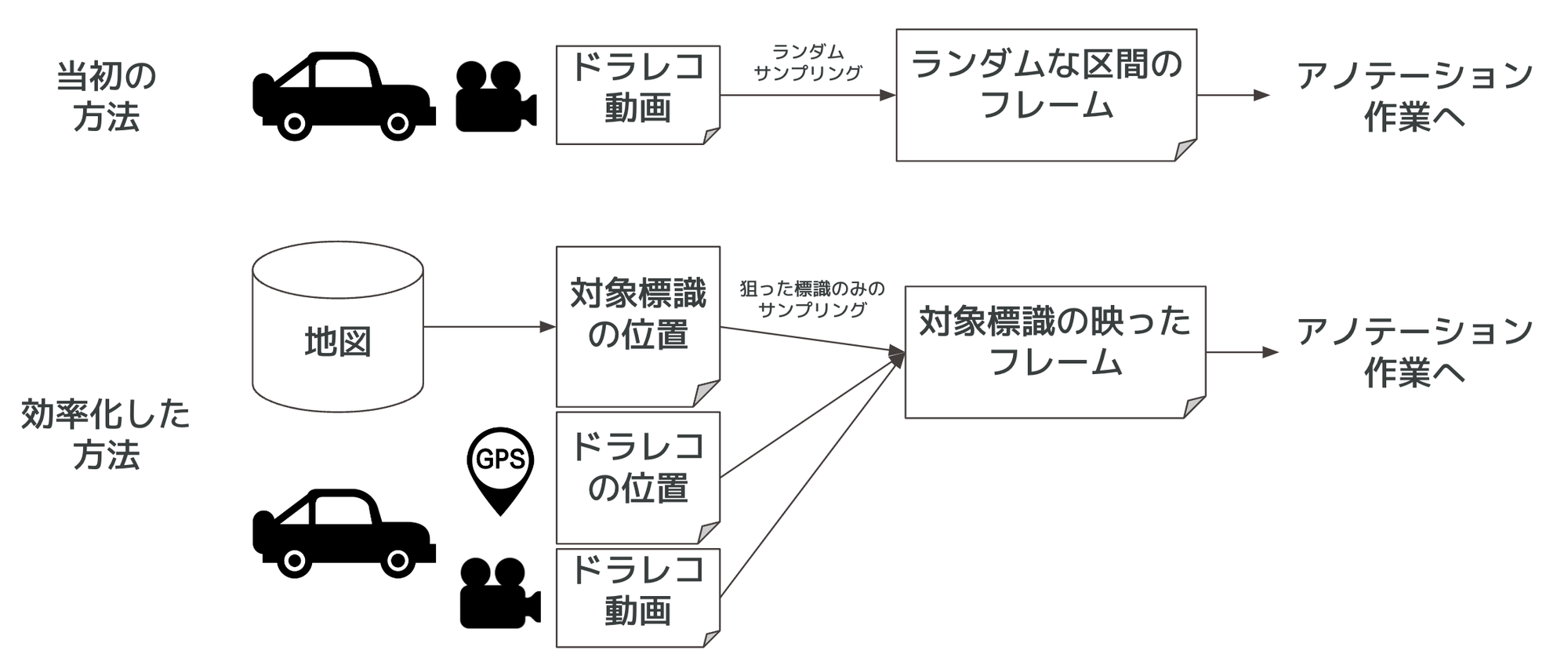
図1:データセット作成の当初の方法と効率化した方法
この仕組みを利用した結果、目標の2000枚をランダムサンプリングの1/10以下の工数で収集できました。そしてこの増えたデータをモデルの学習に使用したことで、「高さ制限」クラスのAverage Precisionは0.48から0.97に大幅に改善できました。約0.5の向上と、モデルや学習方法の改良では実現しにくい成果です。また、必要数が集まるまでの工数が読みやすくなり、クラスを追加する対応の検討もしやすいというメリットも分かりました。
このように画像以外の情報も活用することでデータの量を効率的に増やすことができ、それによってモデルの精度向上を実現することができました。
どのようにデータの質を高めるか
Data-Centric AIでデータの量と併せて重視されるのが質の観点です。既存のデータセットのアノテーションを見ていくと、標識のクラスを誤ってアノテーションしているケースが多いことが分かりました。図2は「最高速度」を「重量制限」の標識と見間違えている例です。標識は種類が多い上に似た図柄のものが多いため、このよううな見間違いが一定数発生していました。

図2:似た標識の見間違い例。実際のアノテーションツール上の画像
図3は、「最高速度」を「最低速度」と間違えていますが、「最低速度」はこのような市街地で一般的な標識ではないため、見間違いというよりもアノテーションツール上で選択を間違えたという例になります。ツール上で「最高速度」と「最低速度」のボタンが並んでいるためにこういった間違いも発生していました。

図3:ツール上の選択ミスと思われる例。実際のアノテーションツール上の画像
アノテーションの間違いを修正する
この問題への対応として、単純ではありますがアノテーションをチェックし間違いを修正するという作業を行いました。前述の「地図とGPSを使ってデータを効率的に集める」の取り組みで集めたデータを修正したところ、修正前後で検出精度(Average Precision)は「高さ制限」が0.95から0.98、「最高速度」が0.80から0.83に改善できました。どちらも0.03ポイントと量を増やした際の変化と比べれば僅かではありますが精度を向上させることができました。
アノテーションチェックによってクラスの修正を行った枚数を調べると「高さ制限」も「最高速度」も3%前後の画像が修正されており、それが精度向上に繋がりました。
アノテーション誤りの再発防止
アノテーションのチェックにより過去のデータの質は改善できましたが、このようなダブルチェックは工数の負担が大きいです。チェック作業で見つかった間違いが今後起きないような工夫をしていく再発防止策も重要になってきます。
そういった対策はまだ途上ですが、MoTではアノテーション作業やツールを内製しているため工夫を行いやすい環境が整っています。AIエンジニアがアノテーションチームと随時連携をとることでルールやツールを改善し、アノテーションの間違いを減らしていくことができます。
また今回は紹介しませんでしたが、アノテーションルールが曖昧なためにアノテーターによって結果が揺れてしまうといった問題も起こることがあります。そこへの対策もデータの質の改善として取り組む必要があります。
まとめ
珍しい標識は学習データが集めづらいために十分な検出精度が出ないという課題に対して、モデルではなくデータの改善を行うことで精度向上を実現するというData-Centricな取り組みを紹介しました。しかし我々はもちろん、モデルに着目したModel-Centricなアプローチを軽視しているわけではありません。モデル開発に関しては既に広く知られているように様々な観点がありますが、それらを高いレベルで行った上で、データに着目するのも忘れてはいけないということです。AIの開発においてはモデルとデータはどちらも重要な要素です。今後もMoTのAI技術開発部ではModel-CentricとData-Centricの両面のアプローチでAIの社会実装における様々な課題の解決に取り組んでいきます。
We're Hiring!
📢
Mobility Technologies ではともに働くエンジニアを募集しています。
興味のある方は 採用ページ も見ていただけると嬉しいです。
Twitter @goinc_techtalk のフォローもよろしくお願いします!