

Kaggle のデータ分析コンペ Tweet Sentiment Extraction で『5位 / 2,227チーム』を獲得しました :)
AIKaggleNews❌ 未対応のtype(table_of_contents)が見つかりました
記念すべき MoT (Mobility Technologies) の技術ブログ第一号記事です :)
MoT はタクシーアプリなどの事業統合により、2020 年 4 月から新体制でスタートしたモビリティ DX カンパニーです。「移動で人を幸せに。」をミッションに、タクシーアプリ『JapanTaxi』、『MOV』の運営の他、タクシー車内での広告や決済、タクシー需給予測による乗務員の営業サポート、ドライブレコーダーや交通事故削減支援システム『DRIVE CHART』、自動運転社会やスマートシティの実現を見据えたビッグデータ解析などの R&D 事業と、幅広く事業を展開しています。
本ブログではそんな MoT の強みの一つ、『技術』にフォーカスして様々なお話をさせて頂きます!第一回の本記事では、データ分析コンペティション Kaggle において MoT メンバーが奮闘し、上位成績を収めた際の話を共有させて頂きます!!
はじめに
2020 年 6 月に終了した Kaggle のコンペ Tweet Sentiment Extraction で MoT のメンバー 田口*、藤川*、山川*、松井*並びに社外のチームメンバー tkm2261 さんで構成されるチームで、2,227 チーム中 5 位となり、金メダルを獲得しました!
本記事では、このコンペの概要と我々のソリューションを紹介したいと思います。なお、本記事は田口、藤川、山川、および松井の共著となります。
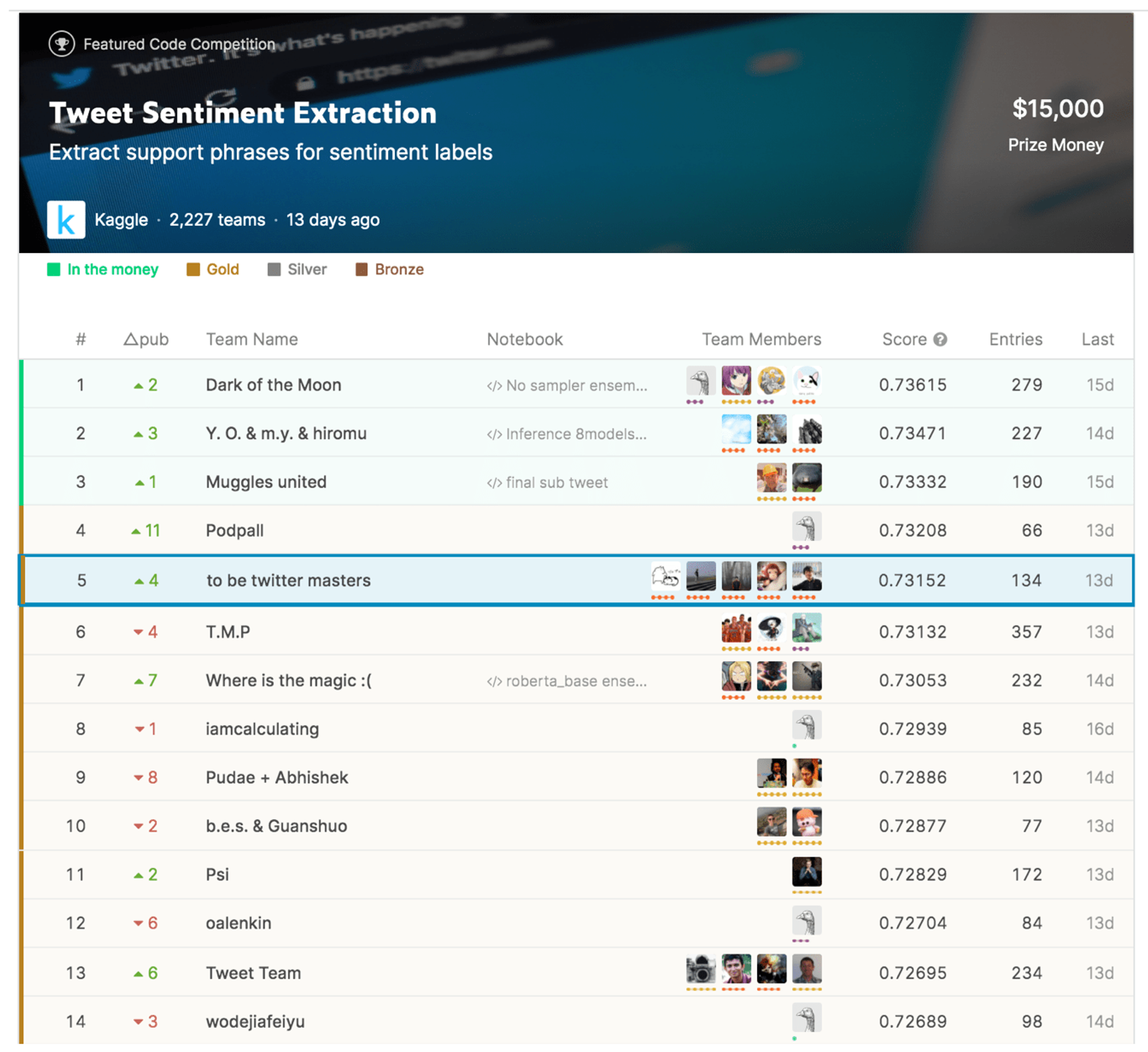
図: Tweet Sentiment ExtractionのLeader Board 出典:
1. コンペ概要
1.1 タスク概要
インプットデータとして tweet の文章 [text] と、その文章に対する感情 [sentiment](positive, negative, neutral の 3 種)が与えられます。これをインプットとして、文章がその感情を反映している部分を抽出します。例えば、”Sooo SAD I will miss you here in San Diego!!!” という文章に対して ”negative” という感情が付与されており、この文章が negative という感情持つとアノテーターが考えた根拠部分 [selected_text] が ”Sooo SAD” であると示されています。
学習データとしては 27,481 レコード与えられており、テストデータには Public データセットとして 3,434 レコード、参加者が見ることのできない Private データセットが 8,245 レコードあります。学習データに対して Public データセットの数が少なく、 我々のチームでは shake の危険性をいつも感じていました。(学習データ 27,481 レコードから 5 fold の CV セットを作ると 1 つの fold が 6,870 レコードなので、Public データセットは 1 fold にも満たない)
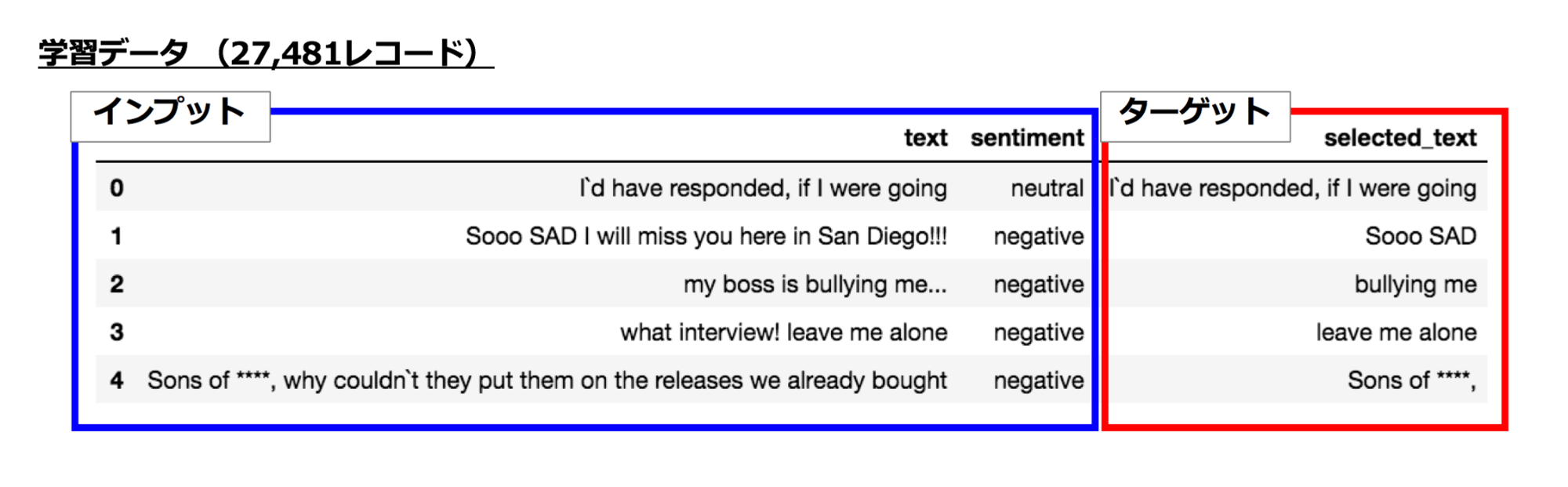
図:学習データの例

図:テストデータの例
1.2 評価指標
評価指標は word-level Jaccard score が用いられています。公式の evaluation ページに記載の下記コードを見て頂ければわかりやすいかと思います。
def jaccard(str1, str2):
a = set(str1.lower().split())
b = set(str2.lower().split())
c = a.intersection(b)
return float(len(c)) / (len(a) + len(b) - len(c))基本的には空白文字で区切ってできた単語 1 つ 1 つを set を用いて重複を除き、selected_text のみに出現する単語数、予測した単語群 [predicted] にのみ出現する単語数、両者に共通する単語数、から

を計算すると 1 レコード分の Jaccard score が算出できます。各レコードごとにこの jaccard を計算し、全レコード数で平均したものが今回のコンペの評価指標となります。

図:Jaccard scoreを計算する一例
この word-level Jaccard score を計算をするための単語の抜き出しに罠があり、magic と呼ばれるものにつながっていくのですが、それは後述の magic のパートでご紹介します。
2. ベースラインモデル
ベースラインモデルとしては RoBERTa を用います。RoBERTa にインプットできるよう学習データに前処理を行います。RoBERTa の出力を今回のタスクにフィットさせるよう Head 部分を付加します。この Head には MLP モデルが用いられたり、CNN モデルが用いられていたり工夫の余地がある部分です。
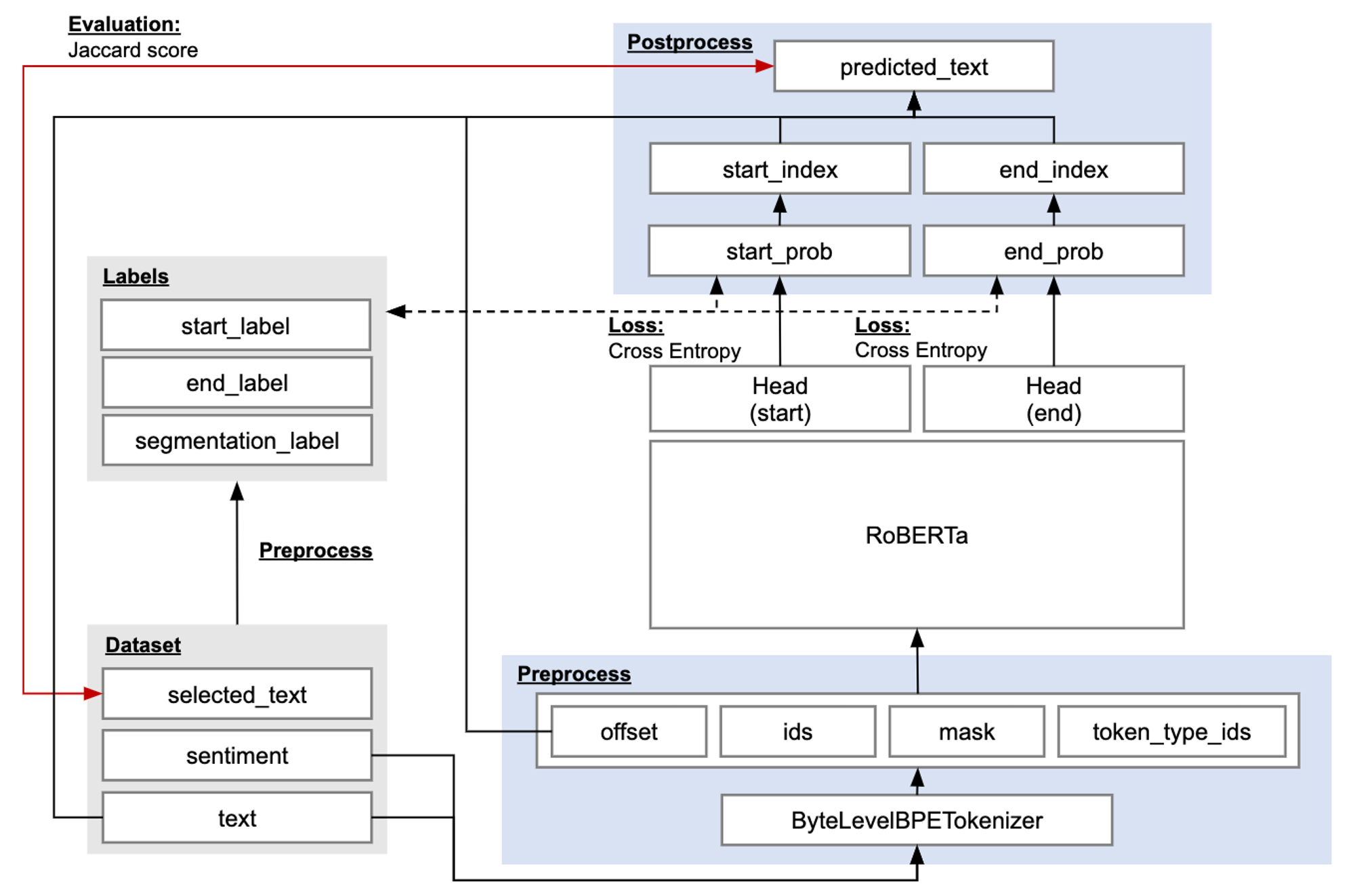
図:ベースラインモデル全体像
2.1 前処理
文章の tokenize には ByteLevelBPETokenizer(※ BPE: Byte Pair Encoding)を使っています。この tokenizer は単語をサブワードに分割して tokenize します。サブワードを用いることで未知語を減らす効果があります。この前処理で RoBERTa のインプットとして必要な ids, mask, token_type_ids を生成します。
各アイテムの用途は下記になります。
- ids : Tokenizer により tokenize された後のサブワードIDリスト
- mask : 注目したい token に 1 を立て、padding 部分を 0 を立てたリスト。学習に使いたい箇所を特定する。
- token_type_id : 2つの文章をインプットした時に、それらの文章を区別するための ID リスト。今回は text 全体を一文として扱うため、全て 0 をセット。
- offset : RoBERTa へのインプットでは利用しないが、モデルの出力結果から元の単語を復元するために利用する index リスト。
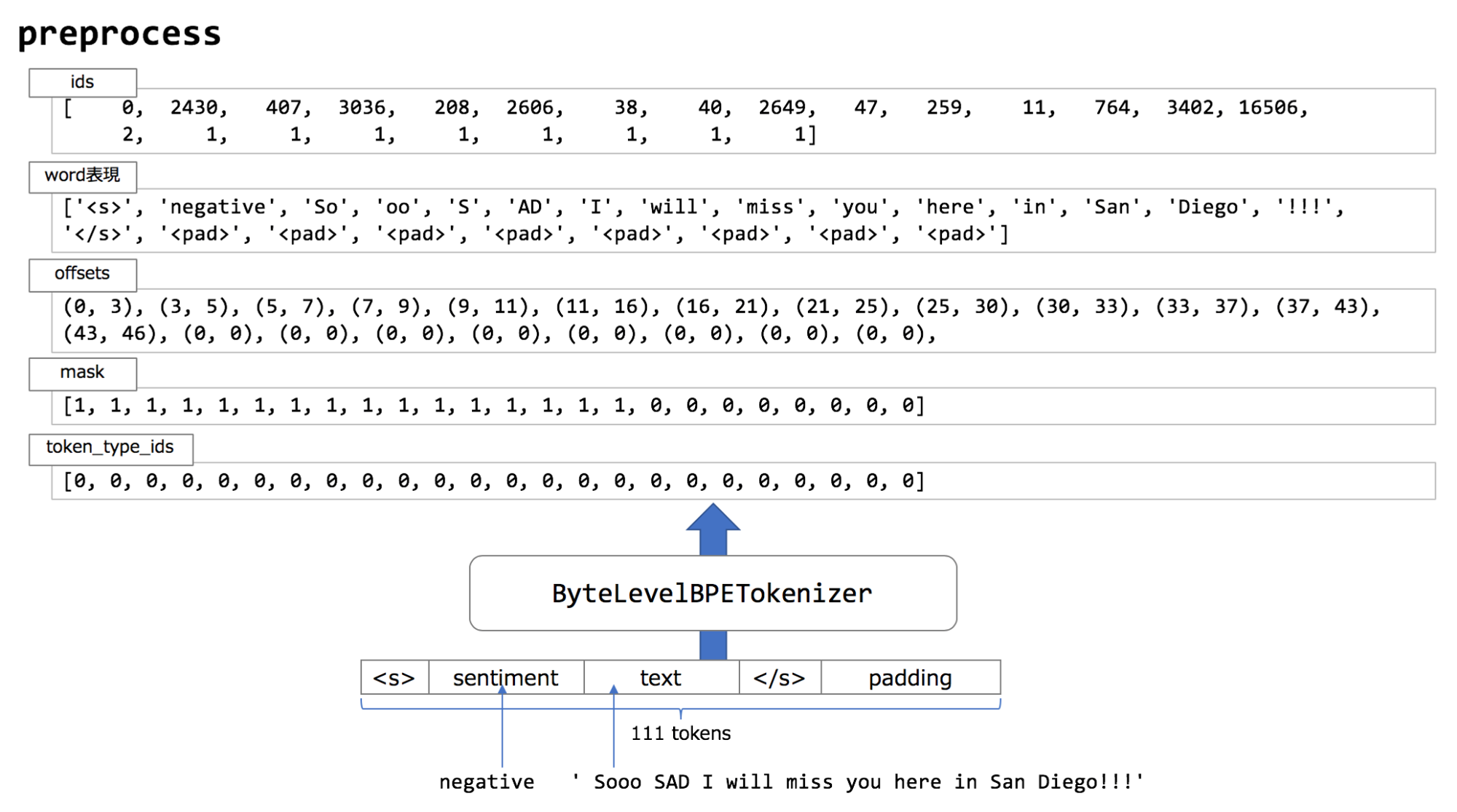
図:基本的な前処理の概要
2.2 後処理
テキストを抽出するために開始箇所(start_index)、終了箇所(end_index)を出力しますが、これを分類問題として解くため、どの token が抽出開始位置か、どの token が抽出終了位置か、の 2 つの多値分類問題として解きます。その際ベースラインモデルとしては Cross Entropy Loss でロスを算出します。得られた index と text を用いて予測文を抽出し、selected_text との Jaccard score を算出します。
3. 我々のチームのアプローチ
3.1 事前学習とモデル選択
今回のような NLP コンペ含め、NLP 界隈では近年 BERT (Bidirectional Encoder Representations from Transformers) [Devlin et al., 2018] から派生したモデルが非常に高い性能を発揮しています。この BERT の派生モデルには RoBERTa [Liu et al., 2019]、ALBERT [Lan et al., 2019]、XLNet [Yang et al., 2019] や ELECTRA [Clark et al., 2020] など様々なものがありますが、今回はコンペ初期の試行錯誤で最も性能の良かった RoBERTa をメインのモデルとして開発を進めました。
BERT の派生モデルの性能の良さの一因は、大量のデータで事前学習できている点です。あくまで経験則ですが、事前学習時のデータ・タスクと今行いたい学習のデータ・タスクの類似性が高いほど学習後のモデルの性能が良い傾向があります。今回のコンペでもこれは非常に重要で、通常の RoBERTa ではなく今回のタスクと同様 Start / End を求める手法で解ける SQuAD [Rajpurkar., 2016] と呼ばれるタスクで事前学習したものを使うことでより良い精度を獲得できました。事前学習した重みを再利用する場合でも Head は事前学習のものを流用できないことも多いのですが、SQuAD で事前学習したモデルはタスクの類似性から Head を変えることなく Start / End 方式で利用できるというメリットも有り、これも精度向上に大きく寄与したと思われます。
3.2 Magic
magic のタネ
Kaggle ではよく magic と表現をされますが、『何かに気付く』ことで飛躍的にスコアを伸ばせることがしばしばあります。このコンペも magic があるコンペで、金圏等上位チームは全て気付きを得ていました。
結論から述べると、このコンペにおける magic は『ラベルズレの補正』でした。下図がその一例を表したものです。negative な text である『is back home now gonna miss every one』に対する selected_text が『onna』となっていますが、これは『gonna』の一部であり、非常に不自然です。
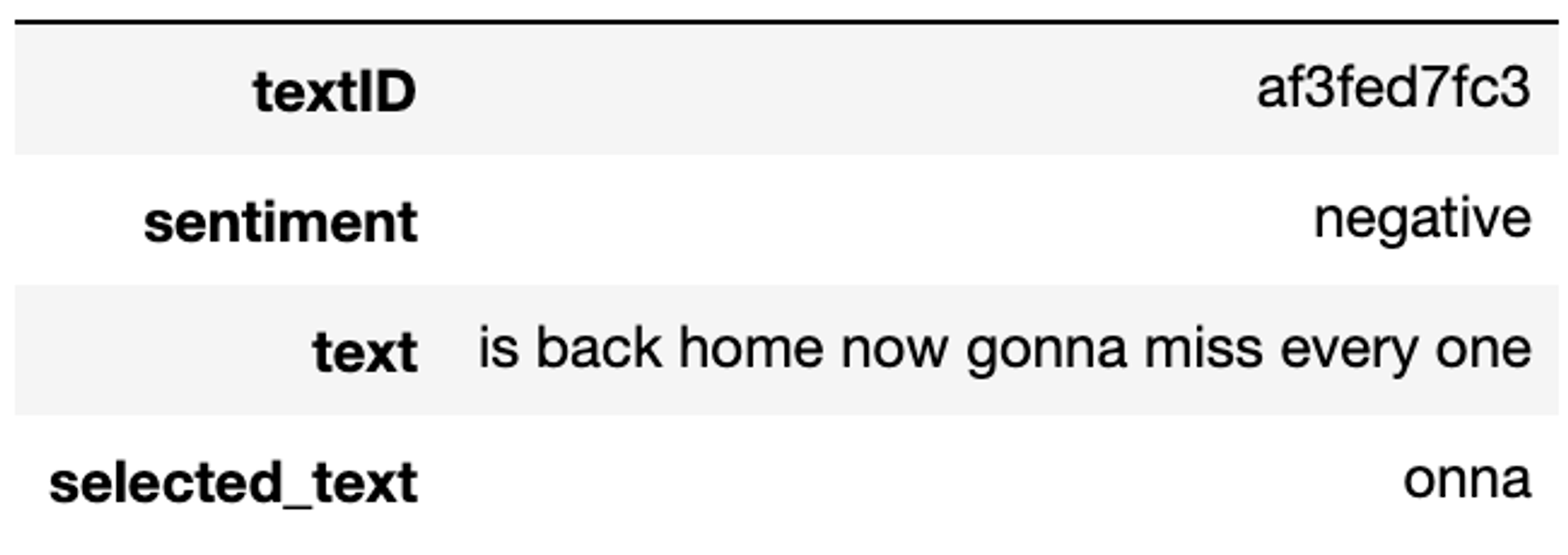
図:ラベルズレのあるデータの例
この一例だけであれば単なるアノテーションミスとも考えられますが、データをよく見ていくとこのような例が非常に多く観測されます。これに気付き、個々のデータを丁寧に見ていくと magic にたどりつくことができます。つまり、magic は『スペースによる文字インデックスのズレの補正』です。(※ この補正だけでラベルズレが完全になくなるわけではなかったため、結局最後まで分かりませんでしたが他にもインデックスズレの要因はあったようです。)
また、下図がラベルズレの正体を浮き彫りにした例です。text の 17 文字目から 22 文字目が全て連続してスペースになっていますが、この連続するスペースを 1 つに変換し selected_text 『onna』に当たる文字インデックスを変換後の space_fixed_text について参照すると『miss』という妥当なラベルを得ることができます。

図:ラベルずれの原因を表した例
公式の見解が無いのであくまで予想ですが、この現象が起きた原因は下記の 2 つだと思われます。なお、このコンペの主催は Kaggle であり、ラベルの作成も Kaggle が行ったようです。
- Kaggle のラベル作成依頼時に文字インデックスでやりとりしていた。
- Kaggle の依頼時には連続スペース数を 1 つに丸めるが、文字インデックス適用時には連続スペース数の丸めが行われなかった。
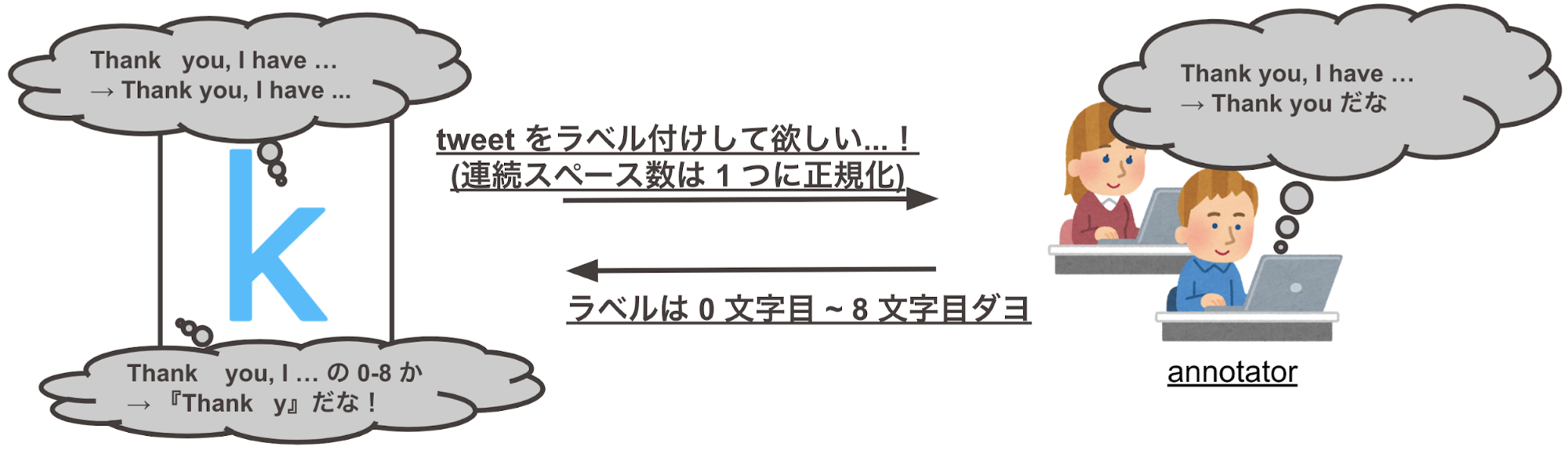
図:ラベルズレが起こるメカニズムを示した図
magic の開発
さて、『ラベルズレがある』ということに気付いても、それを実際に利用する方法を開発しなければ magic として利用することはできません。今回のケースでは以下のようにして利用することができます。4 でラベルズレを付与しているのは、リーダーボードのスコア計算に使われるラベルはラベルズレを含んでいるためです。
- pre-process により selected_text のラベルズレを修正
- 修正後のラベルを使ったモデルの学習
- 学習後のモデルによる予測
- post-process により予測結果にラベルズレを付与
この内、pre-process と post-process をどのように開発するかが magic のスコアへの寄与を左右します。
我々のチームでは、pre-process post-process の開発を共通の仕様で効率よく開発するため、下記の処理を行う Kaggle notebook を初期に開発・共有し使っていました。
- pre-process により selected_text のラベルズレを修正
- 1 の結果に post-process をかける (モデルが 100% ラベル通りの予測をしたと仮定している)
- 2 の結果と、pre-process をかけていない selected_text の jaccard score を計算
- 3 の結果が良ければ 1, 2 の pre-process, post-process を使って submit
- 1, 2 の pre-process, post-process を再開発し、1 に戻る
この共通指標で評価を行う Kaggle notebook の発明は今回我々が上位に入る上で最も重要な要素の一つでした。今後 Kaggle でチーム戦を行う際の戦い方の参考にして頂ければと思います。
3.3 マルチタスク学習
本タスクに対する一つの代表的なアプローチは2章で示した通り、文中の全トークンの中からselected_text の開始 / 終了に位置するトークンを選択する、Classification のアプローチでした。このアプローチには以下のような課題が考えられます。
- 1トークンだけ左右に外した ”惜しい” 誤りと、大きく区間を外した “検討違いな” 誤りが同等に扱われてしまう
- Cross Entropy Loss と本コンペティションの評価指標である Jaccard スコアが必ずしも連動しない
特に 1. については前節で言及したラベルノイズ(Start/End 位置が数文字ズレる)との相性が悪く、学習の安定性を阻害する要因となる可能性があります。
本タスクに対する別のアプローチとして、文中の全トークンを selected_text 区間内 / 外の2クラスに分類する Segmentation アプローチが挙げられます。ロス関数に Lovasz-hinge loss [Yu+, 2015] を用いてこの Segmentation のアプローチを選択することで、本コンペティションの評価指標である Jaccard スコアを直接最適化することが可能になります。(厳密には単語単位と Tokenizer で分割されたトークン単位という違いがありますが、相関が強いことが期待されます。)このアプローチは、先で上げた2つの課題に対して以下のような改善が期待されます。
- selected_text の区間境界以外に対しても評価を行うため、境界に対してのみ評価を行うClassification のアプローチと比較してラベルノイズの影響が小さいのではないか
- Jaccard スコアを最適化する指標であるため、Loss の最小化が本コンペティションの評価指標の最大化と連動するのではないか
一方で、このアプローチは Classification のアプローチと比較して以下に例を挙げるようなチューニングが必要で、単純にはスコアが出にくいという課題がありました。
- 閾値のチューニングが必要
- 同じ文中に区間が推定されなかった時 / 二箇所以上の区間が推定された場合の対応を考える必要がある
そこで以下の図で示すように、Classification のアプローチで最終的な推定結果を得るという枠組みは維持しながら、Segmentation タスクをマルチタスク学習で解くことによって、汎化させることができないかと考えました。このアプローチは効果的で、ベースモデルを CV で 0.002 程度(0.724→0.726)改善にすることができました。
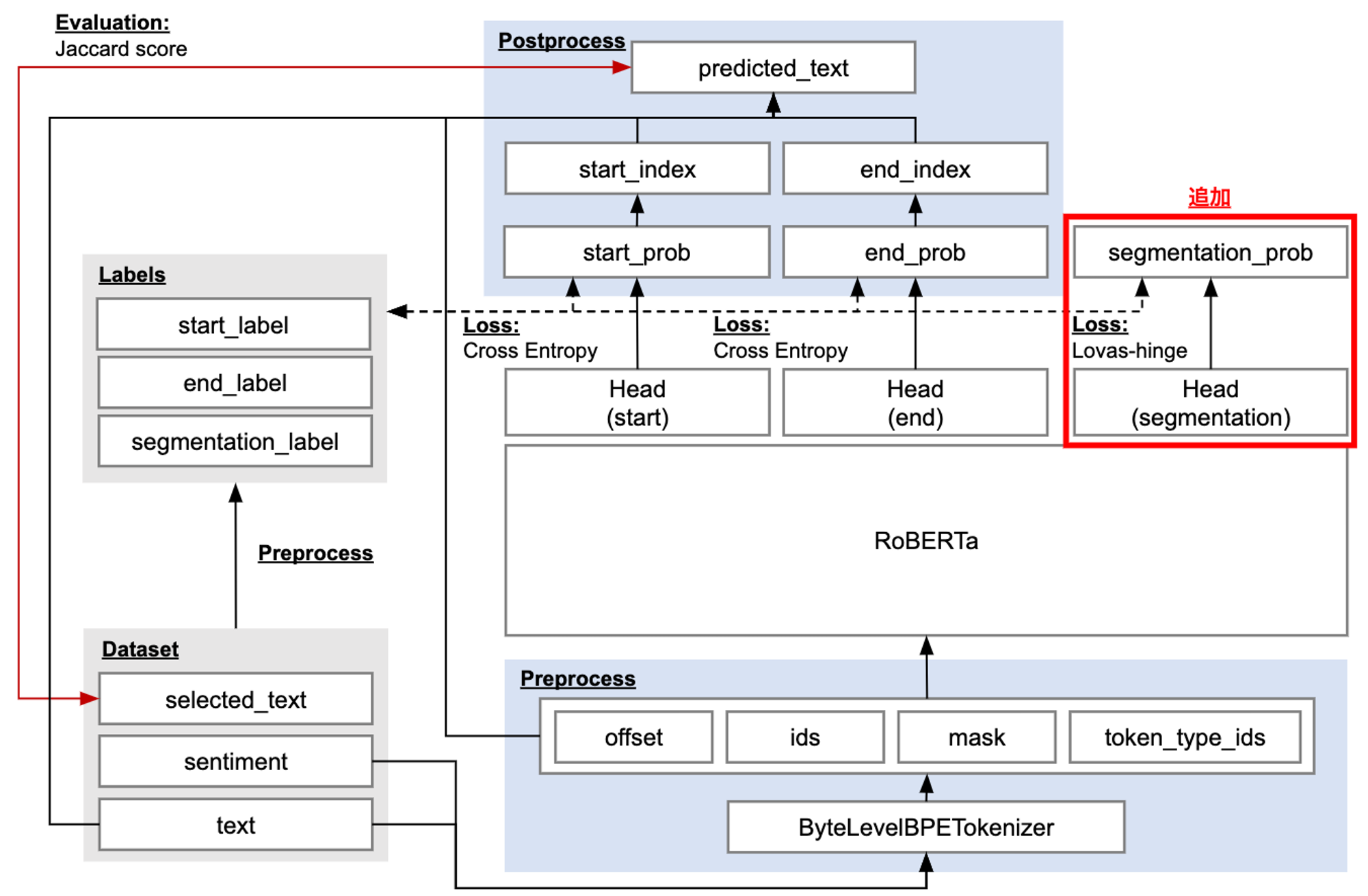
図:マルチタスク学習のネットワーク
3.4 Cumax 関数の利用
マルチタスク学習のアプローチにより、先に挙げた課題を一定程度解決できたものの、最終的に推定結果を得る 2 つの Head は Jaccard スコアを最適化できていない、という課題は残っていました。そこで、Cumax関数 [Shen+, 2019] を使い、Start / End の位置を表す 2 つの確率分布を区間内 / 外を表す確率分布へと変換し、Lovasz-hinge ロスを直接最適化することを検討しました。具体的な手順を以下に示します。
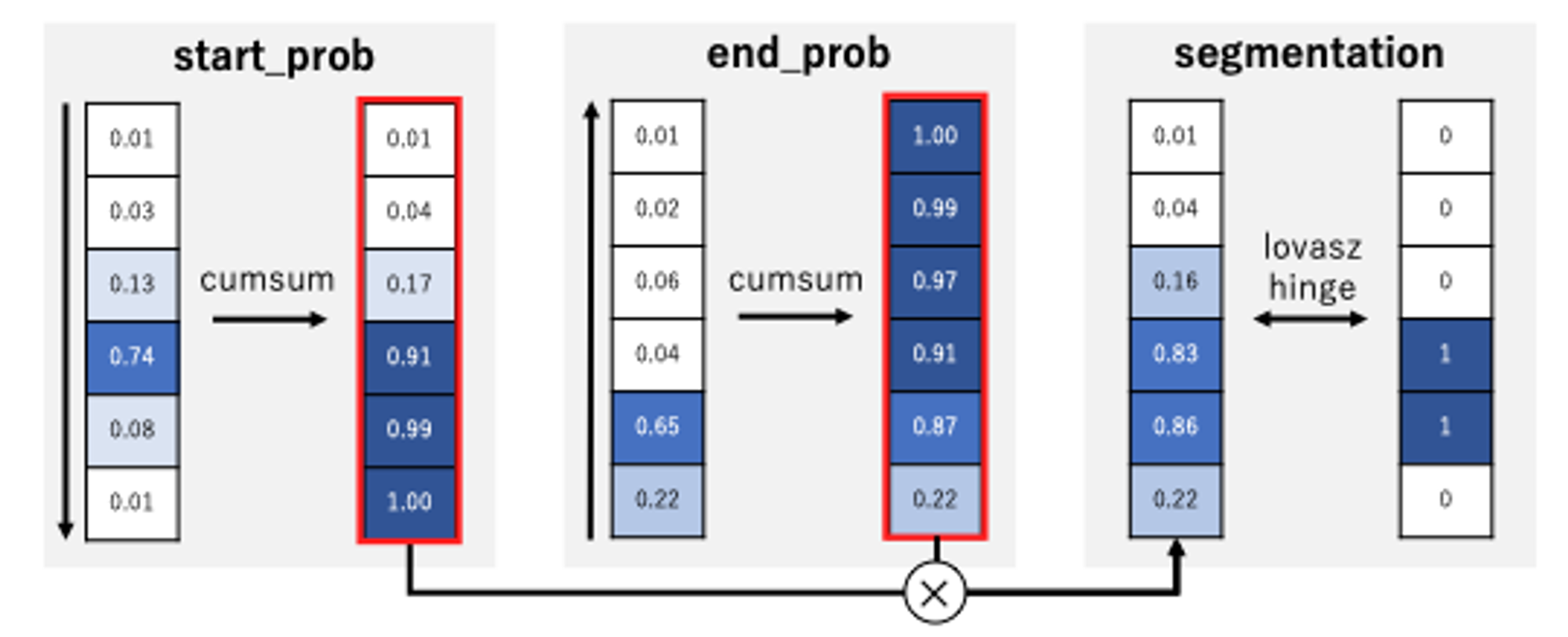
図:cumax 関数
まず、Start / End の位置を表す 2 つの確率分布として、上図で示した start_prob, end_prob を用います。これらは、学習が進むと区間の開始 / 終了位置にピークを持つ分布になっていくことが見込まれます。これらに対し、start_prob は前方から、end_prob は後方からそれぞれ累積和(cumsum)を計算します。最後に、この累積和同士の積を取ると segmentation の出力が得られます。このロス関数を利用することで、マルチタスク学習のみを実施していた時と比較してCVで0.001程度(0.726→0.727)改善することができました。
3.5 アンサンブル学習
アンサンブル学習とは
複数のモデルの予測値を「組み合わせて」用いることにより最終的な予測精度を向上させる手法を「アンサンブル学習」と呼びます。この手法により予測精度が向上することが多いため、Kaggle のコンペなどでは終盤の追い込みによく使用されます。
アンサンブル学習の代表的な手法には以下のようなものがあります。
- averaging:各モデルの出力の重み付き(または単純)平均をとり、その値を予測値とする。
- stacking:各モデルの出力を入力とするモデルを作成し、そのモデルの出力値を予測値とする。
特に averaging は実装コストがほとんどかからないため、非常によく使われます。他にもBagging/Boosting などがあります。
我々のチームのアンサンブル手法
実験の手数を増やすこと、加えてモデルの多様性を担保することを目的として、序盤から各メンバーが独立して実験を繰り返していたため、このコンペにおいては最終局面で各メンバーの出力値を重み付け平均する戦略を取りました。各モデルの出力を使用して再度別のモデルを作成する stacking も選択肢としてはありえましたが、実装/実験コストの高さから今回は見送りました。
似たような予測を行うモデルでアンサンブルを行っても、それほど恩恵は大きくありません。したがって個々のモデルの性能は保ちつつ、各メンバーそれぞれ異なる学習方法 / architecture によって多様性を担保することが求められます。今回は各自
などを変えながら、各々独立したモデルを作成していました。
モデルアンサンブルの実装
各モデルの validation data に対する予測値を持ち寄り、重み付け平均の結果最も validation の結果が良くなるような重みの組み合わせを探索しました。探索には Optuna を用いました。古くからhyperopt などの組み合わせ最適化ライブラリがありましたが、Optuna は探索結果の精度・探索効率・実装の手軽さという観点で非常に使いやすいと感じています。今回は
- 各メンバーがそれぞれのモデルを重み付き平均した後、
- さらにそれらの結果を重み付き平均する
という2段階の最適化プロセスを経て最終的な出力を得ました。図にすると下記のようになります。
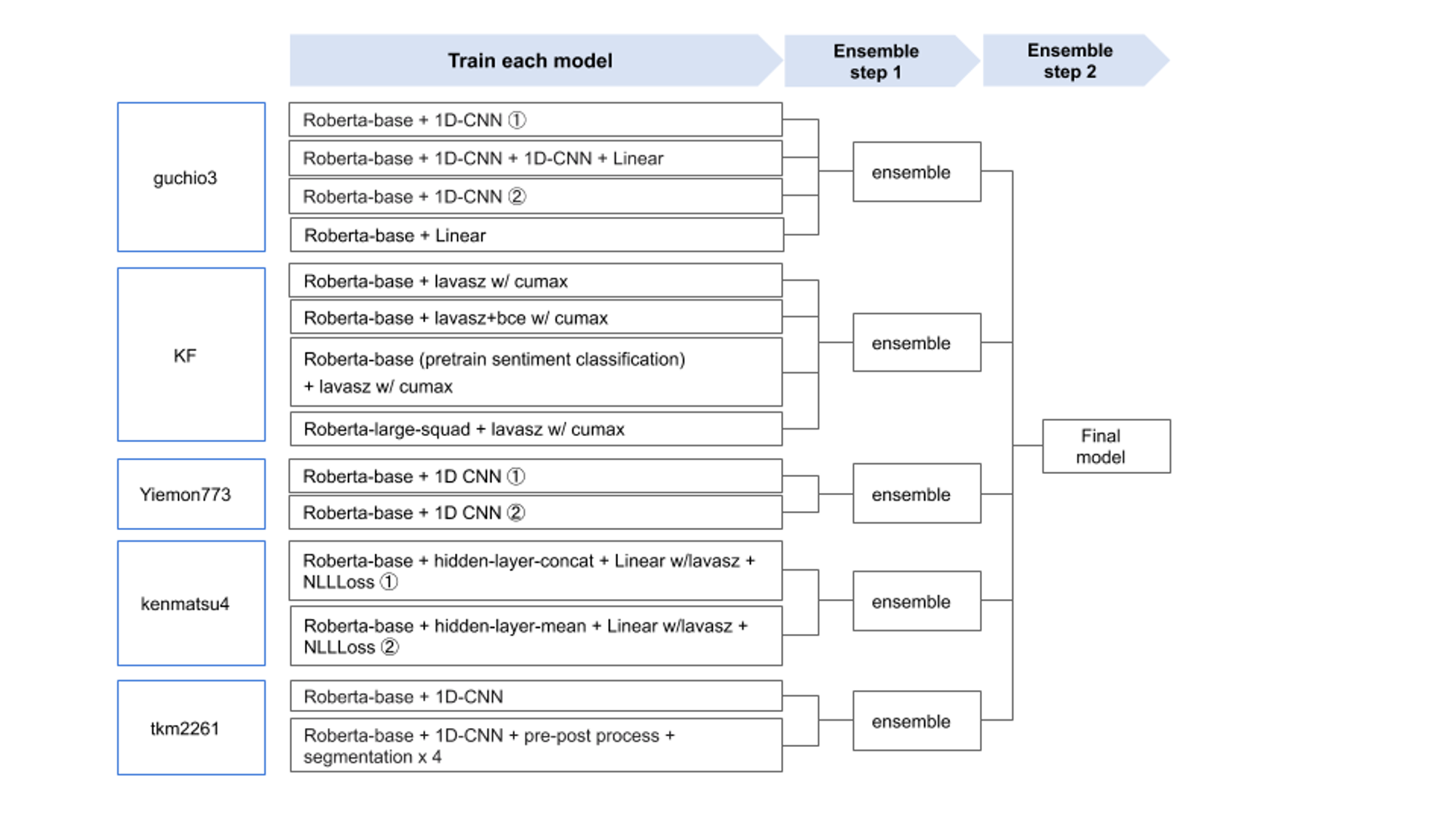
図:我々のチームのアンサンブル
あまりに探索アルゴリズムが優秀であるが故に、自身のモデル性能が低いと容赦なく重みが 0 になってしまいます。チーム戦においては、アンサンブルする場面が(自尊心の保護という意味では)一番緊張感が高まる瞬間とも言えるでしょう。重みが 0 になったときのメンバーからの気遣いの眼差しも、傷口に塩を丹念に塗り込まれている気分です。
Kaggle最終局面のリアル
前述の通り Kaggle においてアンサンブルは有効であるため、しばしばこの作業がコンペ最終盤にもつれ込みます。今回もご多分に漏れず、最終日にとても早起きしてギリギリまで重み調整を行いました。 朝5時、それまで1時間ほど待っていたモデル提出の失敗が判明し、やり直しすることになってしまったときの、メンバー二人ため息混じりの朝の静寂は今だに記憶に新しいです。しかしながら、実はこの提出こそが Public/Private でのほぼベストであり、結果的に粘ってよかったと実感しています。 「諦めたらそこで試合終了ですよ」という恩師の言葉を思い出したのでした。
4. まとめ
チームでのコンペティション参加にも色々な取り組み方がありますが、我々のチームでは各実験/改善タスクをうまく切り出しながら効率的にPDCAを回せたことが今回の結果に繋がりました。特に、日頃から業務や勉強会で各々の強みを理解しており、タスクの担当割り振りや実験計画も非常にスムーズに行うことができたことも非常に印象的でした。
最後になりましたが、Mobility Technologies では Data Scientist / Data Analyst を募集しています。大規模多様なデータを扱い、プロダクトに大きなインパクトを与えられるだけでなく、確かな技術力を持ったメンバーとともに切磋琢磨できるポジションなので、ご興味のある方は是非ご応募を検討していただけると幸いです!
採用ページはこちら >>> https://hrmos.co/pages/mo-t/jobs
5. 参考文献
- Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." In NAACL-HLT, 2019.
- Liu, Yinhan, et al. "Roberta: A robustly optimized bert pretraining approach." arXiv preprint arXiv:1907.11692, 2019.
- Lan, Zhenzhong, et al. "Albert: A lite bert for self-supervised learning of language representations." In ICLR, 2020.
- Yang, Zhilin, et al. "Xlnet: Generalized autoregressive pretraining for language understanding." In NeurIPS, 2019.
- Clark, Kevin, et al. "Electra: Pre-training text encoders as discriminators rather than generators." In ICLR, 2020.
- Rajpurkar, Pranav, et al. "Squad: 100,000+ questions for machine comprehension of text." In EMNLP, 2016.
- Yu, Jiaqian, and Matthew Blaschko. "Learning submodular losses with the Lovász hinge." In ICML. 2015.
- Shen, Yikang, et al. "Ordered neurons: Integrating tree structures into recurrent neural networks." In ICLR, 2019.
*株式会社ディー・エヌ・エーよりMoTに出向中