

Grafana Lokiでログを検索 | オブザーバビリティ基盤第2話
SRENovember 17, 2023
こんにちは、SREグループのカンタンです!
LGTM!オブザーバビリティ基盤第1話という記事ではログとメトリックスとトレース情報を扱えるGrafanaをベースとした新しいオブザーバビリティ基盤の話をしました。今回はログにフォーカスし、ログの収集と検索を行うGrafana Lokiについて詳細に説明したいと思います。
Grafana Loki
Grafana Lokiはログを検索するためツールです。他のログ検索の仕組みと比べて、ログの内容自体をインデックスしないのが主な特徴になります。ログを投入する際にログ内容に加えてラベルとして渡すアプリケーション名、コンテナ名、Pod名などログ発生元の特定情報のみがインデックスされます。検索の際にラベルを検索フィルタとして指定することでインデックスを参考に該当するログレコードがストレージから取得されます。
ログの書き込みは以下のような非常にシンプルな流れになります。ログ内容がLokiのメモリ内にチャンクとして蓄積されつつラベルに該当するチャンクIDがインデックスされます。チャンクが非同期で定期的に永続ストレージにアップロードされます。
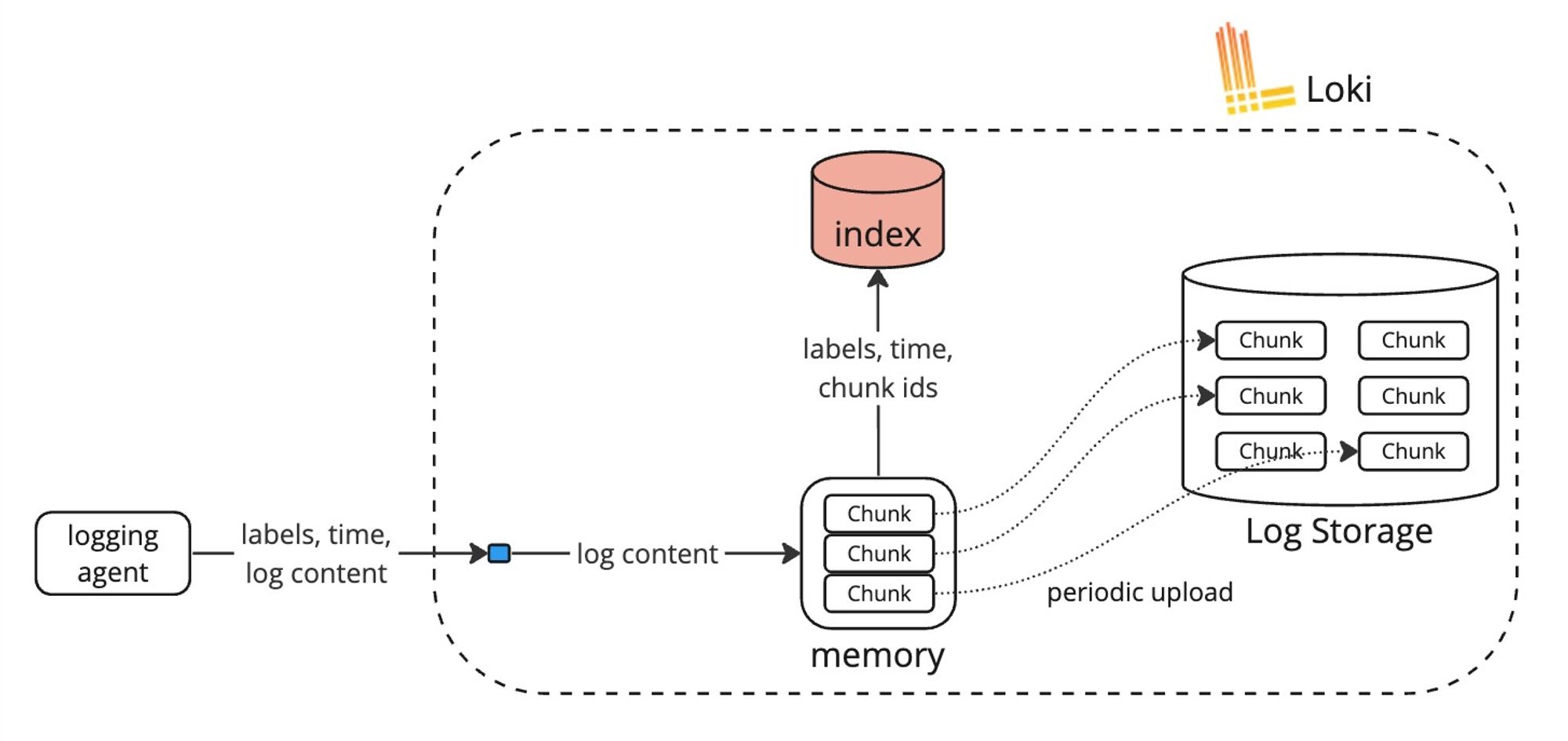
検索フローがざっくり以下のようになっています。ラベル、時間と細かいフィルタでログを検索すると、インデックスからラベルと時間に該当するチャンクIDが抽出され、チャンクがストレージから取得されます。その他の細かいフィルタはオンメモリで行われます。
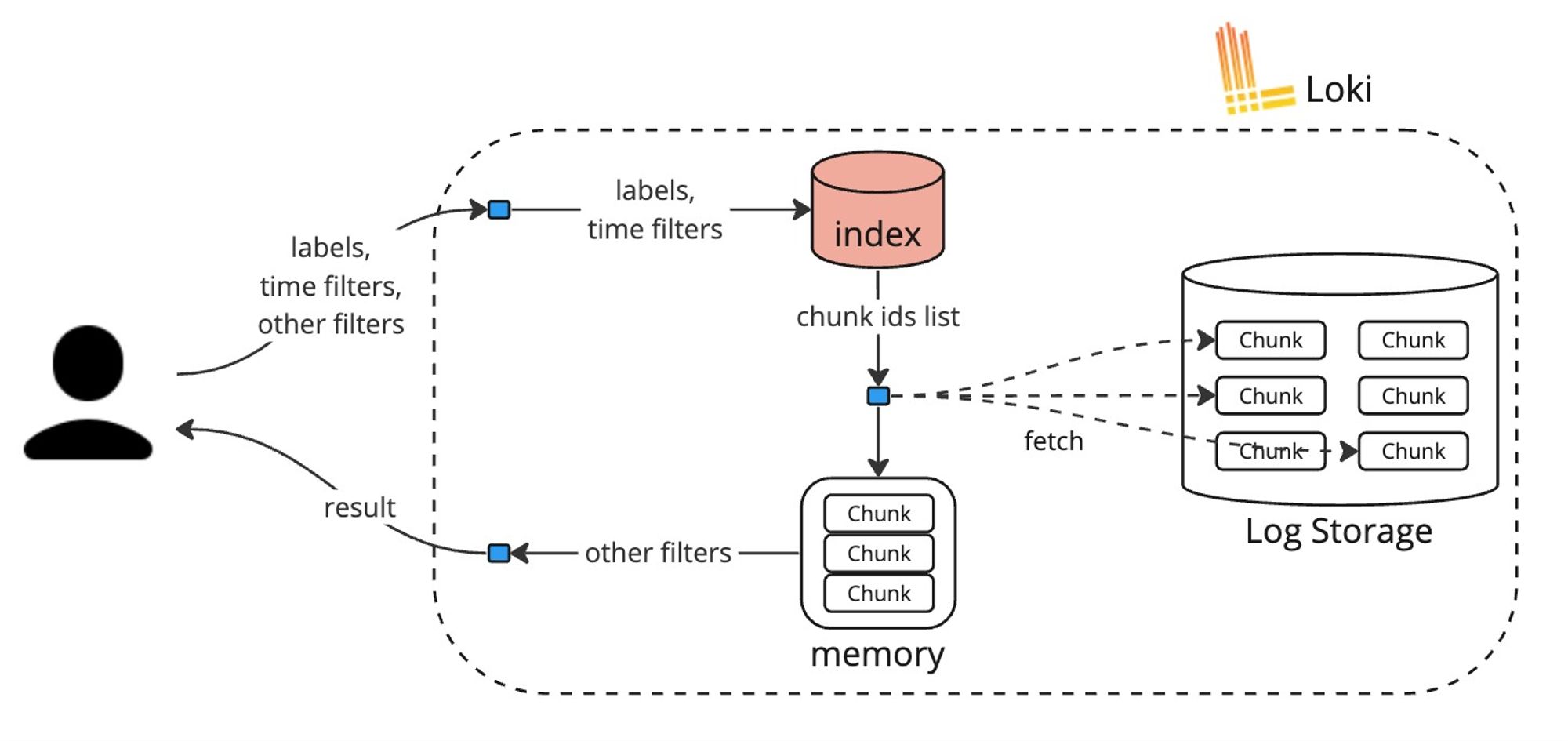
ラベルしかインデックスしない関係で、検索の際に大量のデータがストレージから取得され、検索条件にマッチしないログをオンメモリで除外する必要があります。完全にブルートフォースなやり方で、CPUとメモリリソースがかなり必要です。
Elasticsearch/OpenSearchのようにログ内容をインデックスするプロダクトと比べると非常に非効率で不思議なやり方に見えるでしょうが良く考えるととても適切です。問い合わせ対応、トラブルシューティング、分析、コンプライアンス遵守など様々な理由でログを残す必要があるためログのデータ量は圧倒的に多いです。ラベルだけをインデックスすることでログの書き込みに必要なコンピュートとストレージのコストがとにかく安くなります。また、書き込むログの量が多い割に検索するログの量はとても少ないです。特殊なアプリケーション以外、書き込んだログの大半が一回も検索されないと言っても過言ではないです。そう考えると、ログの検索がコンピュートインテンシブでコストがかかっても全体的にとても安いアプローチになります。
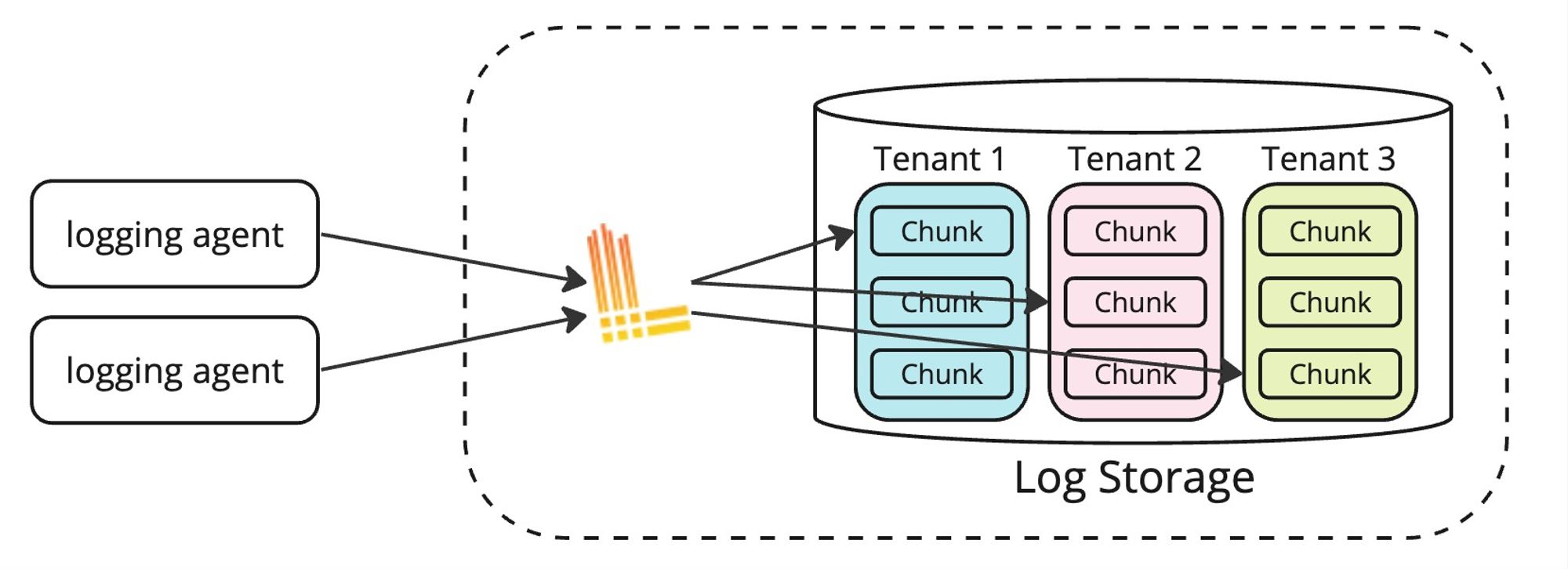
また、Grafana Lokiは永続ストレージとしてS3やGCSなどオブジェクトストレージを採用しているためストレージのコストが比較的安いです。Lokiはマルチテナントのため、チャンクがテナントごとにフォルダ分けされていて、テナントごとの保持期間設定と権限管理が可能です。
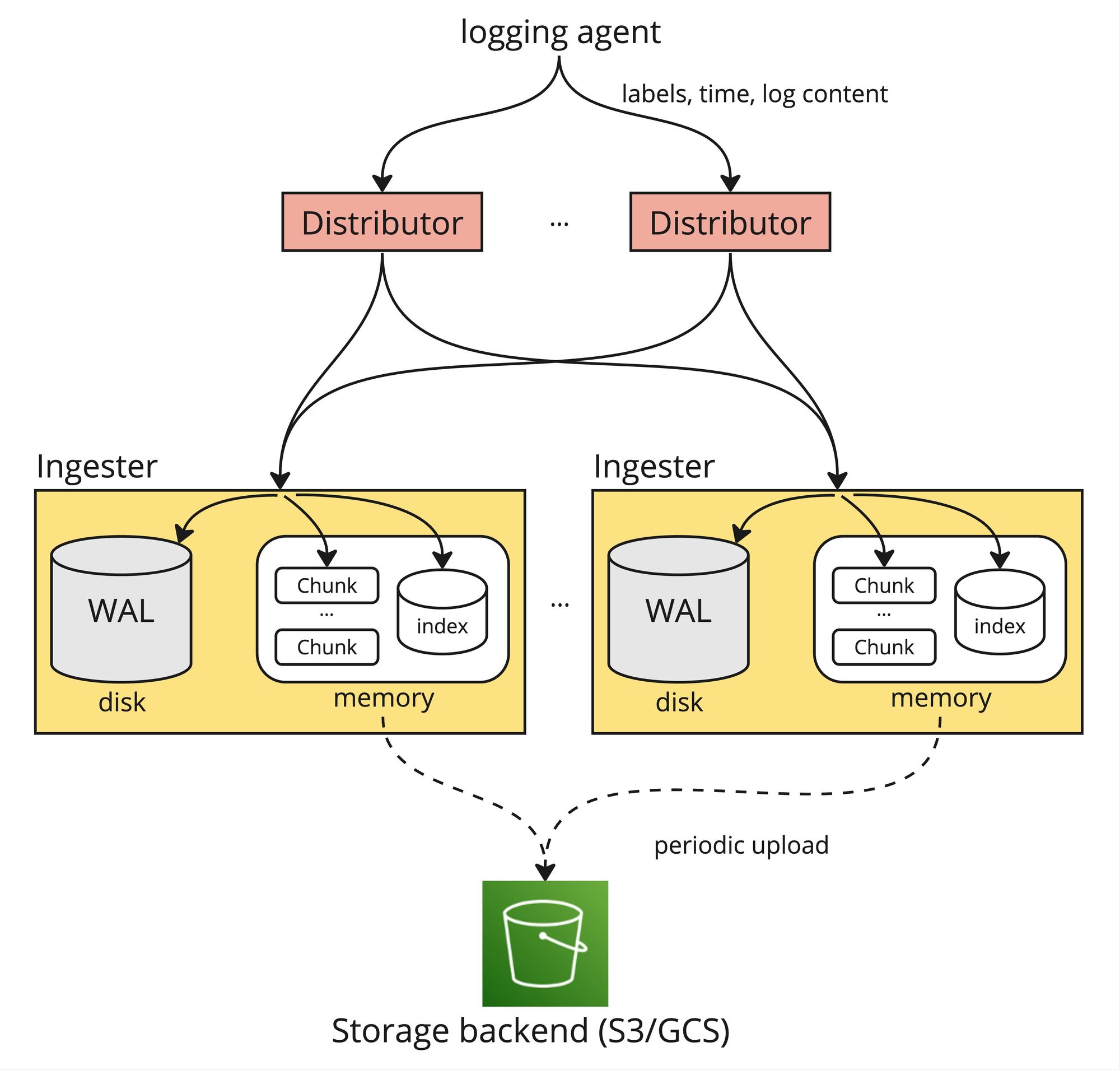
アーキテクチャ:書き込みフロー
裏ではGrafana Lokiは複数のコンポーネントに分かれていて、ログの書き込みに関連するコンポーネントはDistributorとIngesterになります。
ログを投入する際、PromtailやFluent BitなどLoggingエージェントがログ内容とラベルをDistributorに送ります。Distributorはレートリミットなどバリデーションを行いログをIngesterに送信します。ログ内容がIngesterのメモリ内にチャンクとして蓄積され、ラベルがインデックスされます。チャンクとインデックスデータが非同期で定期的に永続ストレージにアップロードされます。
ただし、この方法だけでは永続ストレージにアップロードされるまでログデータがIngesterのメモリにしか存在しないため、Ingesterのクラッシュでデータの欠損が発生してしまいます。Lokiではそれを防ぐためにWrite-Ahead Logging (WAL) の仕組みが設けられています。ログを受ける際、データをメモリに入れると同時に、同一サーバのディスクにも保存しています。Ingesterがクラッシュした際、ディスクの内容を読み込んでデータをメモリ内に復元してから起動することでログデータの欠損を防いでいます。
アーキテクチャ:読み込みフロー
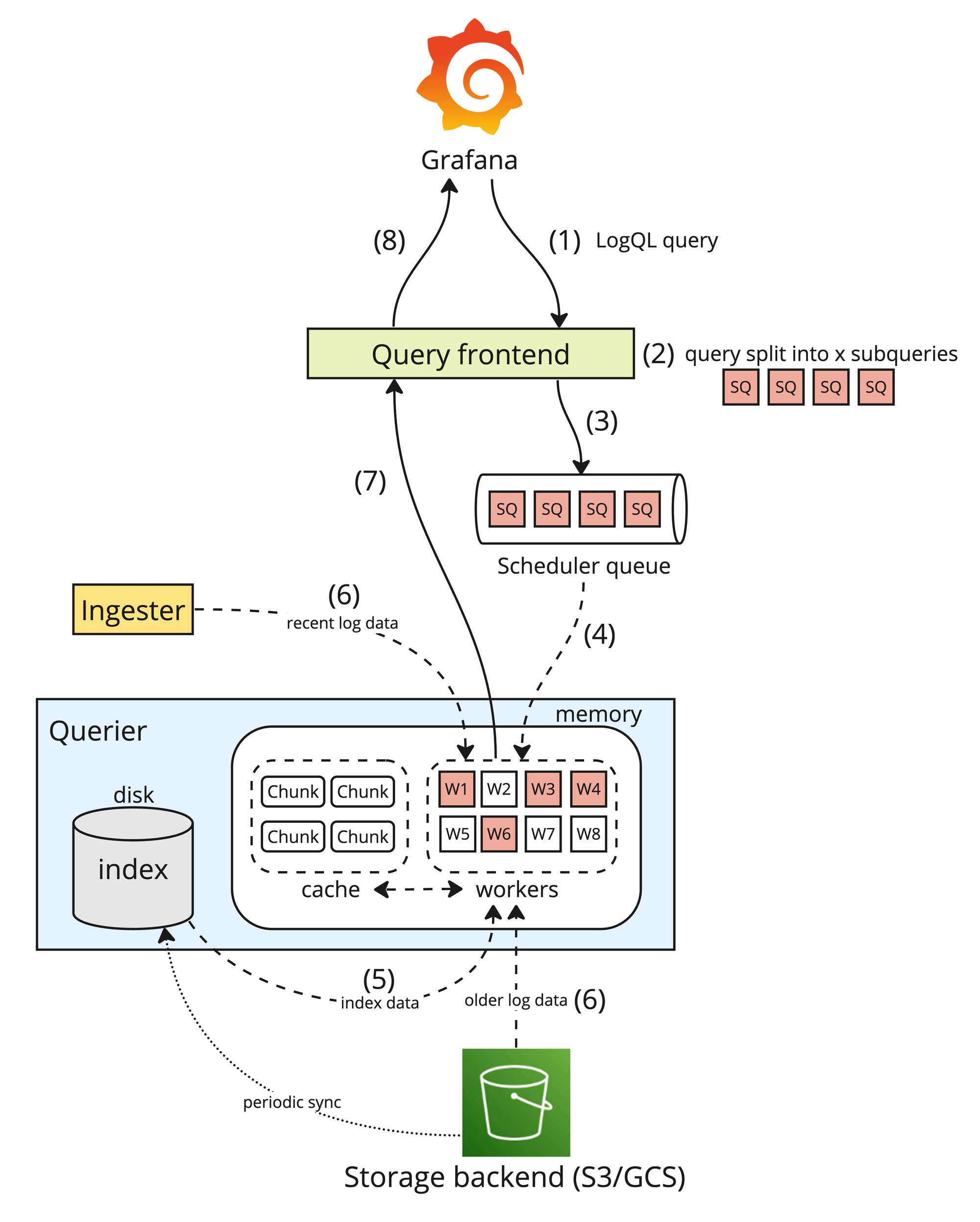
ログの読み込みに関わるコンポーネントはQuery frontend, Scheduler queue, QuerierとIngesterになります。
ログを検索する際、LogQLというクエリ言語で書かれたクエリがGrafanaのGUIやLokiのAPIから実行されます。ログ検索の流れは以下のようになります。
- Grafanaで入力したLogQLクエリがLokiのQuery frontendに送信される
- Query frontendがクエリを複数のサブクエリに分ける(分け方は割愛するが時間やラベルが活かされている)
- サブクエリがScheduler queueにキューされる
- Querierで動いているワーカがScheduler queueからサブクエリを取得し処理する
- サブクエリに指定されているラベルに該当するチャンクを抽出するためインデックスを参照する
- 直近のデータをIngesterからAPIコールで取得し、それ以前のログデータをストレージから取得する
- サブクエリの条件に合わせて、取得したログデータを更に絞り込み加工しQuery frontendに返す
- Query frontendがそれぞれのサブクエリの結果を集計しクエリ全体の結果を返す
書き込みフローの説明にあったように、永続ストレージにまだないIngesterのメモリにしか存在しないログデータがあるためQuerierは永続ストレージだけではなくIngesterからもデータを取得しています。
ラベルしかインデックスされていないため、一つのクエリを処理するには大量のチャンクデータを取得し処理する必要があるため検索のパフォーマンスが気になるところです。ただしクエリを複数のサブクエリに細かく分けることで複数のQuerierで並列処理ができパフォーマンスが意外と出ています。Querierの数とQuerierあたりのCPUとメモリリソースを調整することで非常に早い検索を実現できます。コストとのトレードオフがありますが、求める検索スピードを柔軟にコントロールできます。
サンプル
以上に説明した仕組みを利用してGrafana Lokiが提供している非常に便利な機能をいくつか紹介したいと思います。
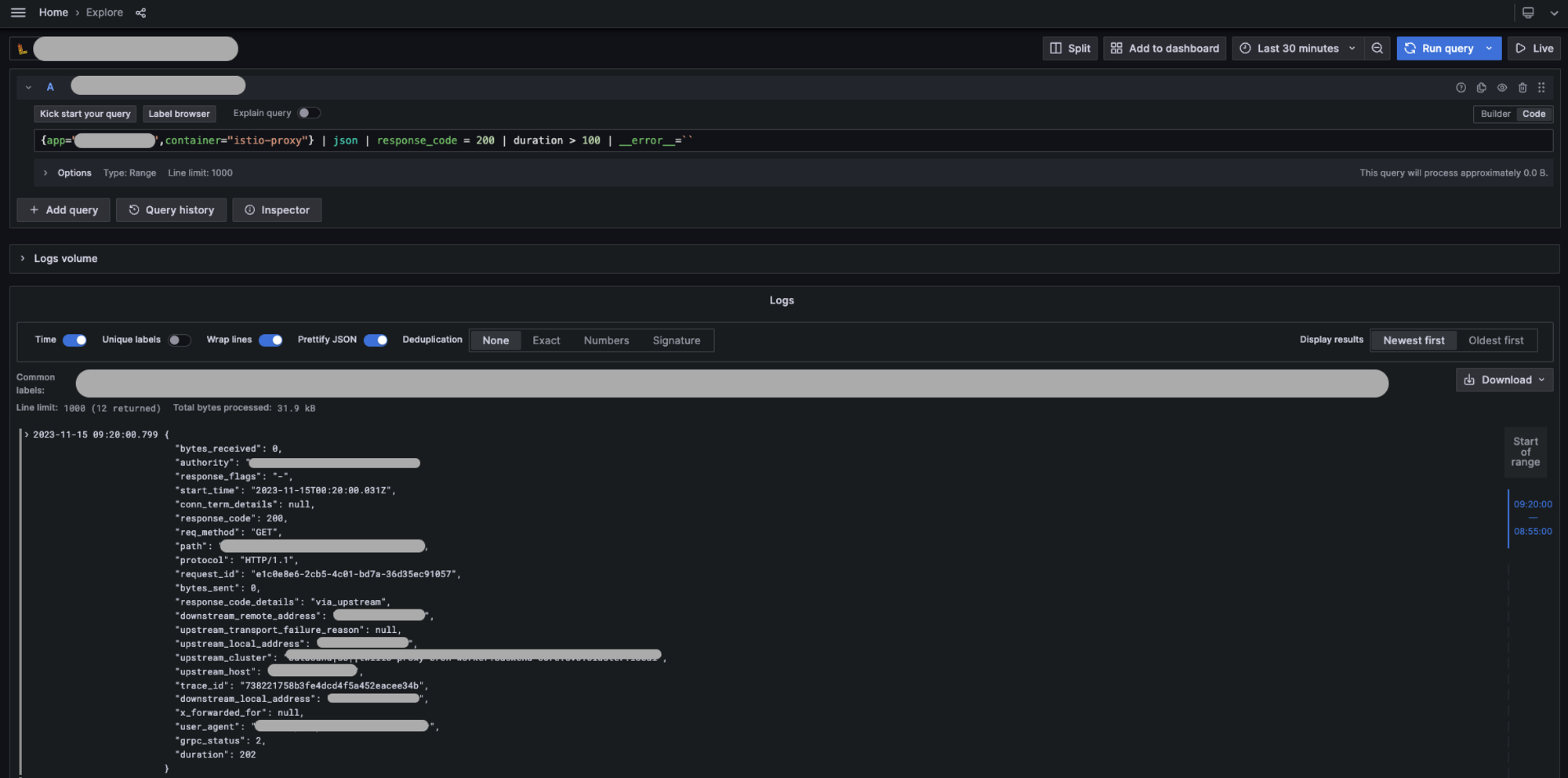
まずはログ検索ができます。例えば以下のLogQLクエリではmyappアプリケーションの istio-proxy コンテナのログから、ステータスコードが200かつレスポンスタイムが100ms以上のログを検索します。
{app="myapp",container="istio-proxy"}
| json
| response_code = 200
| duration > 100
| __error__=``今回はjsonのログでしたがLokiは複数のフォーマットを理解していますし多数の関数を提供してくれているため様々なログデータに対応できます。
ログ内容からグラフも作れます。アプリケーション側で事前にメトリックスを用意しなくても様々な情報を可視化できるため問い合わせ対応や障害対応の際に非常に便利です。例えば以下のLogQLクエリで istio-proxy コンテナのログからパスごとのRPSを可視化できます。
sum by(path) (
rate(
{app="myapp", container="istio-proxy"}
|= `inbound`
[1m])
)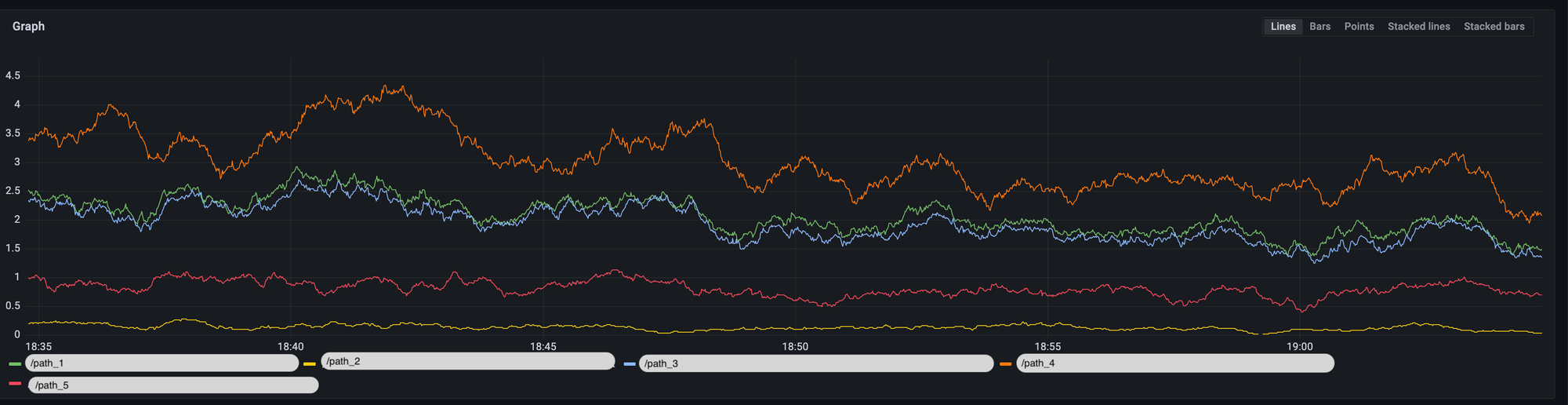
グラフからアラートを設定したりダッシュボードを作ったりすることも可能で本格的なオブサービリティ機能が提供されています!
GO Inc.の使い方
LGTM!オブザーバビリティ基盤第1話で説明したようにGO Inc.ではGrafanaを自前のKubernetesクラスタで運用しています。これから全体の構成と独自の取り組みを紹介したいと思います。
アーキテクチャ
タクシーアプリ『GO』のサービスがAWS EKSとGCP GKEを両方利用していることもあって、GrafanaとLokiを専用のKubernetesクラスタで運用しています。
サービスのEKSとGKEの各ノードに動いているPromtailがコンテナのログを収集しGrafana Lokiに送信しています。EKSの場合はVPC Peeringを利用し内部通信としてInternal ALB経由で送信していますがGKEの場合は外部通信としてExternal ALB経由で送信しています。オブザーバビリティクラスタにGrafana Loki、Loki OAuth Gateway、GrafanaとGrafana Gatewayが動いていて、Grafana Lokiの永続ストレージとしてS3を利用しています。Loki OAuth GatewayとGrafana Gatewayについては LGTM!オブザーバビリティ基盤第1話に詳細に説明しているためそちらにご参考ください。全体のアーキテクチャ図は以下になります。
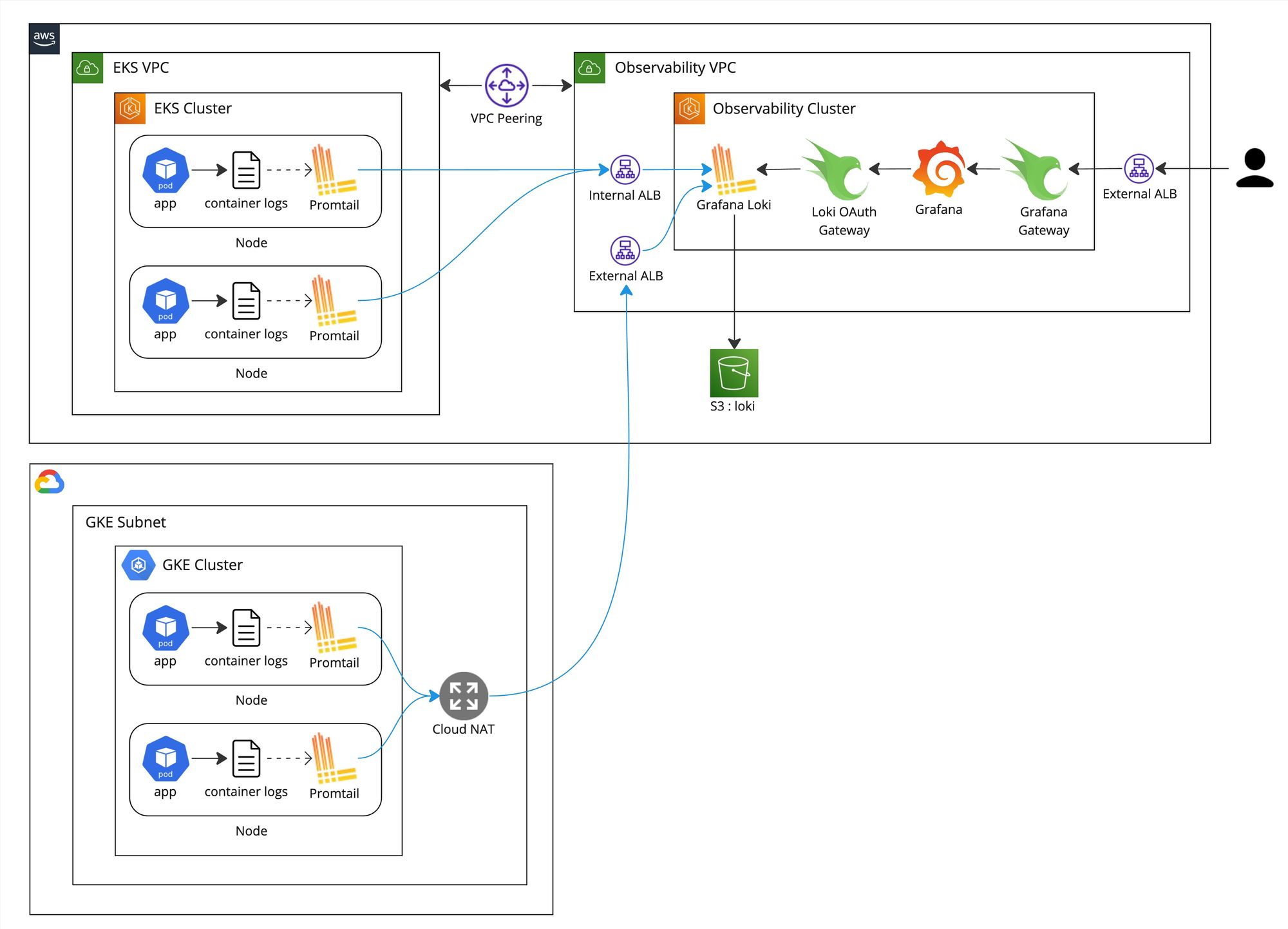
Grafanaが提供しているLokiのHelmチャートを利用しLokiをSimple Scalable Deploymentモードとしてインストールしています。オブザーバビリティクラスタの構成は以下のようになっています。
- GrafanaのサービスとLokiのサービスをそれぞれGrafanaとLokiネームスペースに分けて管理している
- LokiをSimple Scalable Deploymentモードで運用しているため、LokiのPodが書き込み用のwrite Podと読み込み用のread Podに分かれている
- write Pod専用のノードプールとread Pod専用のノードプールを設けている
- その他Pod用のgenericノードプールを設けている
- ログ書き込みの際にwrite Podへのロードバランシングを行うためHelmチャートに含まれているNginxベースのGatewayを利用している
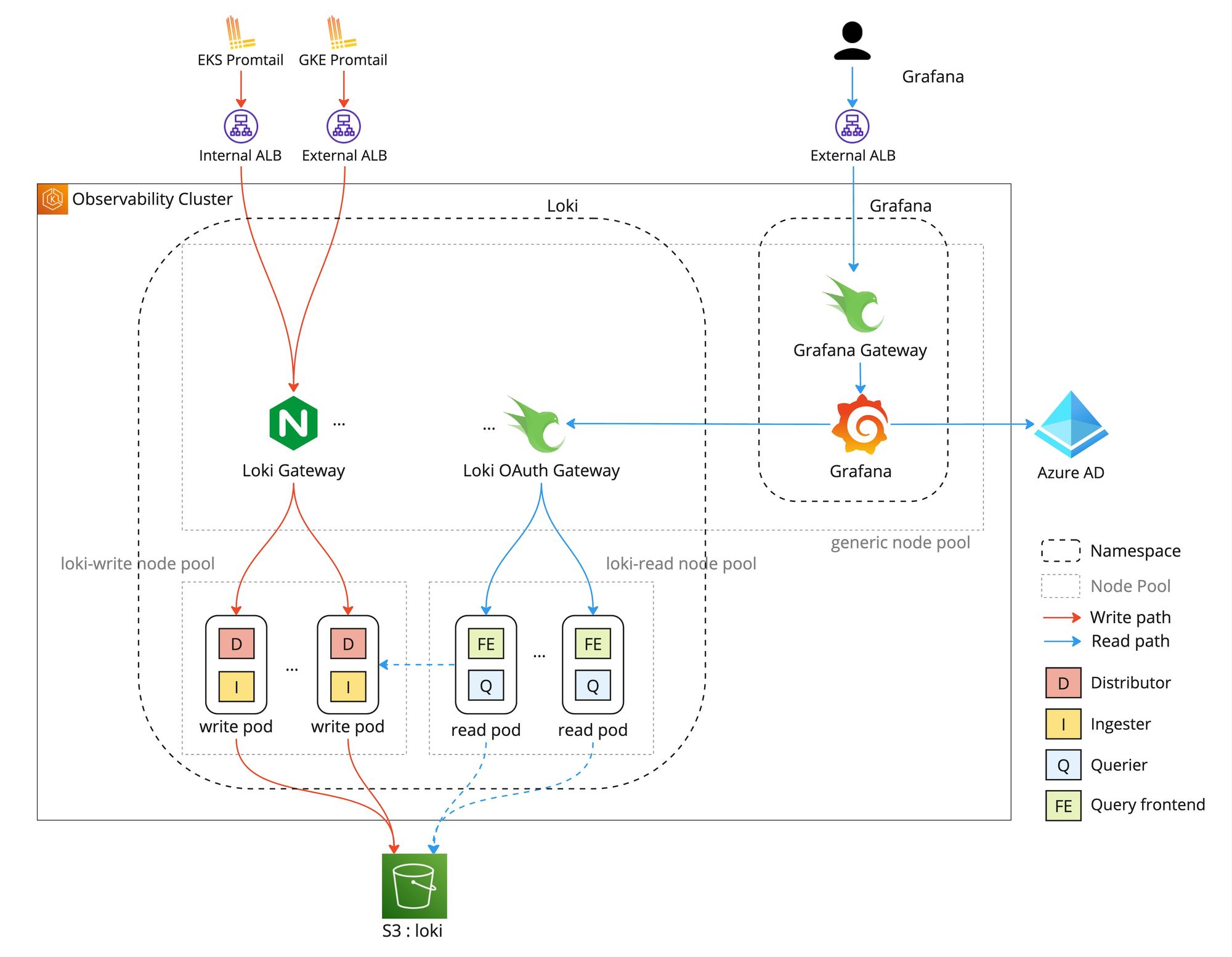
write専用とread専用のノードプールを設けている理由がいくつかあります。
- Lokiのワークロードが非常に個性的でリソースの利用パターンがかなり異なっている。チャンクを常にメモリ内に持っているwrite PodはCPUよりもメモリを必要としている。ログの検索がコンピュートインテンシブのためread PodはCPUもメモリも必要としている。write Podとread Podに適するマシンタイプが異なるためノードプールを分けている。
- ログを検索する際にメモリがバースト的に必要になりread Podが動いているノードに影響する可能性がある。ログの書き込みに影響しないようにノードプールを分けている。
- Kubernetesのバージョンアップデートなどメンテナンス作業する際にノードプールが分かれていた方が作業のタイミングを細かくコントロールでき、書き込みと読み込みに同時に影響を与えることを防げる。
設定
これからGO Inc.で利用している設定のサンプルを共有したいと思います。
ログをLokiに送る際、ログ内容と一緒に渡すラベルの決め方がとても大事なポイントになります。様々な検索パターンを考慮できるよう、GO Inc.ではログが発生したPodの次の属性をラベルにしています。
- namespace : Podが動いているネームスペース
- pod : Pod名
- container : ログを出力したコンテナ名
- node : Podが動いているノード名
- app : Podのアプリケーション名 (Kubernetesの app.kubernetes.io/name ラベル)
- component : Podのコンポーネント名 (Kubernetesの app.kubernetes.io/componentラベル)
- instance : Podのインスタンス名 (Kubernetesの app.kubernetes.io/instance ラベル)
- version : アプリケーションのバージョン (Kubernetesの app.kubernetes.io/version ラベル)
また、ログデータの持ち主になるテナントをネームスペースにすることでKubernetesと同様にネームスペース単位の権限管理が可能になります。
ログとラベルをLokiに送信するPromtailをGrafanaが提供しているHelmチャートでインストールしています。Promtailの設定が以下のようになります。
promtail:
config:
snippets:
pipelineStages:
- cri: {}
- tenant:
source: namespace
- labeldrop:
- stream
- filename
extraRelabelConfigs:
- source_labels:
- __meta_kubernetes_pod_label_app_kubernetes_io_version
- __meta_kubernetes_pod_label_version
regex: ^;*([^;]+)(;.*)?$
action: replace
target_label: version
- source_labels:
- node_name
action: replace
target_label: node
- action: labelkeep
regex: ^(__path__|namespace|app|component|instance|version|container|node|pod)$Loki自体は多数の設定があってニーズに応じてチューニングすべきかと思いますが、参考までにGO Inc.で利用している設定のサンプルを共有します。一番重要な設定を以下にまとめます。
- chunk_encoding: snappy : 圧縮方式としてsnappyを利用する。デフォルトのgzipと比べてファイルサイズが大きくなってしまうが圧縮と伸張速度がかなり早くなり検索スピードが向上する。
- replication_factor: 1 : デフォルトの 3 だとDistributorが同じログデータを3つのIngesterに送信することでIngesterの冗長化を実現している。1 にすることで、Distributorが同じログデータを一つのIngesterにしか送信しないためIngesterがクラッシュしたり再起動したりする際にそのログデータに一時的にアクセスできなくなる。ただしIngesterが起動したらデータにアクセスできるようになるためデータの欠損自体は発生しないこととクラッシュや再起動が頻繁に起きないため 1 にしている。書き込みのコンピュートコストを3分の1ぐらいにできるのが一つのメリット。
- wal.flush_on_shutdown: true : Ingesterの停止の際にWALのデータを永続ストレージに必ずアップロードすることで、write Podを簡単に削除できるようになりメンテナンス作業が楽になる。
loki:
loki:
storage:
type: s3
bucketNames:
chunks: my-loki-bucket
ruler: my-loki-bucket
admin: my-loki-bucket
s3:
region: ap-northeast-1
server:
grpc_server_max_recv_msg_size: 104857600 # 100MB
grpc_server_max_send_msg_size: 104857600 # 100MB
commonConfig:
replication_factor: 1
storage_config:
disable_broad_index_queries: true
ingester:
chunk_encoding: snappy
wal:
flush_on_shutdown: true
limits_config:
# write
max_global_streams_per_user: 20000
ingestion_rate_mb: 20
ingestion_burst_size_mb: 30
per_stream_rate_limit: 10MB
per_stream_rate_limit_burst: 15MB
cardinality_limit: 500000
# read
split_queries_by_interval: 15m
max_query_parallelism: 128
max_query_series: 1000
# retention
retention_period: 91d
# misc
enforce_metric_name: false
querier:
max_concurrent: 16
query_scheduler:
max_outstanding_requests_per_tenant: 2048
frontend:
compress_responses: true
log_queries_longer_than: 20s
compactor:
retention_enabled: true
delete_request_cancel_period: 1h
gateway:
replicas: 2
basicAuth:
enabled: true
autoscaling:
enabled: true
read:
legacyReadTarget: true
extraArgs:
- -log-config-reverse-order
autoscaling:
enabled: false
persistence:
size: "50Gi"
# force pods to run on loki-read node pool
tolerations:
- key: "node/pool"
operator: "Equal"
value: "loki-read"
effect: "NoSchedule"
affinity: |
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: "node/pool"
operator: "In"
values:
- "loki-read"
write:
extraArgs:
- -log-config-reverse-order
autoscaling:
enabled: false
persistence:
size: "50Gi"
# force pods to run on loki-write node pool
tolerations:
- key: "node/pool"
operator: "Equal"
value: "loki-write"
effect: "NoSchedule"
affinity: |
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: "node/pool"
operator: "In"
values:
- "loki-write"
monitoring:
rules:
enabled: false
selfMonitoring:
enabled: false
grafanaAgent:
installOperator: false
lokiCanary:
enabled: false
test:
enabled: falseコスト削減対策
自前のKubernetesクラスタで運用することで以下のようなコスト削減対策が簡単に取れます。
- Lokiのノードプールが分かれているためAWSのリザーブドインスタンスの導入が比較的に楽で30%以上のコスト削減を簡単に実現できる。
- 週末や夜中などログを検索しない時間にread Podの数を自動的に減らすことで読み込みコストをかなり安くできる。GO Inc.ではLokiのread Podのオートスケールをまだ導入していないがCronJobで夜中と週末にread Podを自動的に減らすことで読み込みコストを簡単に半分ぐらいに削減できた。
- サービスのEKSクラスタとオブザーバビリティEKSクラスタの間にVPC Peeringを設定することでNATゲートウェイのコストとデータ転送料のコストを大きく減らせた。
- S3のストレージクラスとライフサイクルを活かすことでストレージのコスト削減も可能。
終わりに
Grafana Lokiはログ内容をインデックスしない新鮮で面白いログ検索ツールです!ログの書き込みをとにかく安く抑えつつ、検索スピードを柔軟にコントールできる仕組みになります。S3やGCSなどオブジェクトストレージを採用することでログの保存料金も比較的安いです。
Grafana Cloudなどクラウド版のサービスを利用すればGrafana Lokiの自前運用の手間と人的コストがからないのですが、その分データ量に応じた課金モデルで高額になります。GO Inc.ではLokiを自前で運用してみて半年以上経っていますが運用とメンテナンスの手間が大きくないことがわかり、しばらく自前運用で頑張りたいと思います!
メトリックスを扱うGrafana Mimirとトレース情報を扱うGrafana Tempoも利用していて、別記事で詳細に説明したいと思いますので是非読んでみてください!
We're Hiring!
📢
GO株式会社ではともに働くエンジニアを募集しています。
興味のある方は 採用ページ も見ていただけると嬉しいです。
Twitter @goinc_techtalk のフォローもよろしくお願いします!