

S3からデータを消すためのプロセスとテクニック
AWSMLOpsAIDecember 16, 2023
15億を超えるオブジェクトを持つS3バケットからデータを消すためのプロセスとテクニックを、『DRIVE CHART』の運用で実際に行ったケースに沿ってご紹介します。
『DRIVE CHART』に携わるエンジニア・大西 (@ken_jimmy) です。
この投稿では、S3のデータの削除のプロセスとテクニックについて、 『DRIVE CHART』の運用で実際に行ったケースに沿ってご紹介します。
これは、GO Inc. Advent Calendar 2023の16日目の記事です。
『DRIVE CHART』
『DRIVE CHART』は、安全運転に関わる業務を総合サポートする法人向けの交通事故削減支援サービスです。ドライブレコーダーとAIを用いて、交通事故に繋がる可能性の高い危険シーンを自動検知して、運行管理者やドライバーへフィードバックすることで、普段から常に安全運転できるように行動変容を促すサービスとなっています。2019年6月のリリース以降、導入企業は着実に増え、現在では6万台を超える車両に搭載されています。
AWSコストの4割がS3
『DRIVE CHART』のインフラ環境として、Amazon Web Services (AWS) を利用しています。
ドライブレコーダーからアップロードされるセンサーや動画像などの各種データを、主にS3に保存しています。リリースから4年半が経過し、 『DRIVE CHART』のAWSのコストの中で、このS3のコストの4割を占める構造となっています。
過去にも定期的に削除する仕組みを入れたりして削減を図っていましたが、さらなるコストカットに取り組みました。
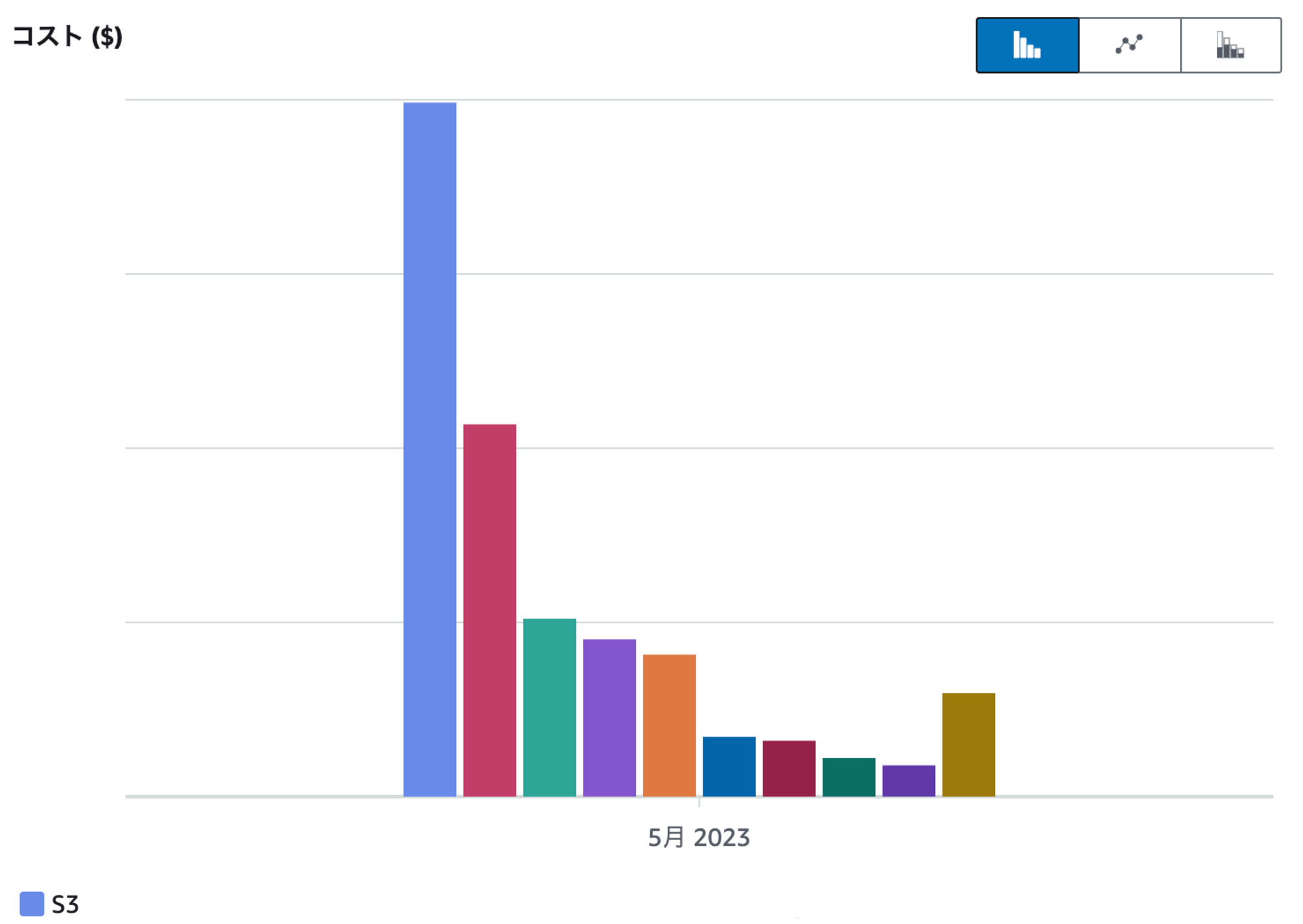
バケットタグ + Cost Explorerでどのバケットの何の操作にお金がかかってるのかを知る
S3のコンソール画面やCloudWatchからバケットのメトリクスを見ることで、どのバケットで保持しているオブジェクトが増えているのか、さらにそのバケットでストレージコストがどの程度かかっているのかを推測することはできます。
しかし、S3にかかる料金はストレージにかかるもの (USD/GB・月) 以外に、PUTやGETなどのアクセスなどにかかるもの (USD/requests) 、アウトバウンド通信にかかるもの (USD/GB) などがあります。そのため、効果的なコストカット施策を打つためには、どのバケットの・どの操作にお金がかかっているのかまで知る必要があります。
『DRIVE CHART』のAWSアカウントでは、Cost Explorerにて集計しやすいように、利用しているマネージドサービスには共通のキーを持つコスト配分タグを付与するようにしています。この共通のキーを我々は Service としています。S3のバケットごとにバケットタグを付与しており、値は s3_バケット名 としています。例えば、aaaバケットは {"Service":"s3_aaa"} 、bbbバケットは {"Service":"s3_bbb"} といった感じです。
以上の準備をしておけば、Cost Explorerにてこのタグをグループキーやフィルタにすることで、お金がかかっているS3バケットがどれか、さらにそのバケットに対する何の操作でお金がかかっているのかまでドリルダウンできます。
これら情報を用いた調査から、あるバケットの保存にかかるコスト (TimedStrage-BytesHrs) が年々増加しており、全体から見ても相当な額になっていることを突き止めました。
S3インベントリとAthenaで何のオブジェクトがどれくらいあるかを知る
次に、ではこのバケットに保存しているオブジェクトは何か、さらにその中でボリュームが大きいのは何かを調べないといけません。
対象のバケットには、以下の特徴がありました。
- 検討開始時点で保持するオブジェクト数は約15億個で、純増傾向にある
- プロダクションで稼働している複数のアプリケーションから作成・参照されている
- 雑多な用途に利用されており、キーやファイルタイプ、サイズなどがまちまち
オブジェクト数が少なければ、S3コンソール画面やAWS CLIでリストすることで地道に見ていってもいいかと思います。ただ、上述の通り、約15億個のオブジェクトを保持しており、加えてあちこちで作成・参照されていて量的な感覚も薄かったので、素朴な方法ではボリュームゾーンを見落とすリスクがあります。
キーのパスや拡張子などで用途を判別できる見込みはあったので、S3インベントリでオブジェクトの一覧を出力し、Athenaでクエリすることで、用途ごとに分類・集計することにしました。
S3インベントリは、S3バケットがある時点で保持する全オブジェクトの情報 (メタデータ) をレポートしてくれる機能です。メタデータには、バケット名、キー、サイズ、最終更新日などが含まれます (一覧はこちら) 。出力形式は、CSV、Apache ORC、Apache Parquetから選択できます。
Athenaでは、S3インベントリのレポートからクエリ可能なテーブルを作ることができます。S3インベントリが日次または週次で出力する先を指定することで、出力日時をパーティションキー (カラム名はdt、フォーマットはyyyy-MM-dd-HH-mm) としたテーブルとなります。
CREATE EXTERNAL TABLE IF NOT EXISTS s3_inventory.example_bucket (
bucket string,
key string,
size bigint,
last_modified_date timestamp
) PARTITIONED BY (dt string) ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.orc.OrcSerde' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.SymlinkTextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.IgnoreKeyTextOutputFormat' LOCATION 's3://temporary-bucket/s3-inventory/example-bucket/Weekly/hive/' TBLPROPERTIES (
"projection.enabled" = "true",
"projection.dt.type" = "date",
"projection.dt.format" = "yyyy-MM-dd-HH-mm",
"projection.dt.range" = "2022-01-01-00-00,NOW",
"projection.dt.interval" = "1",
"projection.dt.interval.unit" = "HOURS"
)
MSCK REPAIR TABLE `s3_inventory`.`example_bucket`分類・集計では以下のようなクエリを記述していました。分類 (kind) ごとに合計サイズ (sum_size_gb) を出しています。最終的にotherの合計サイズが0になるように、otherのキー (min_keyとmax_key) をWITH句内のSELECTのCASEへ分類を足していくというのを繰り返して、集計漏れがないようにしました。またクエリを繰り返し実行することになりますので、S3インベントリの出力形式には、Apache ORCを指定することでスキャン量を減らしました。
WITH t AS (
SELECT
-- 正規表現などでオブジェクトを分類する
CASE
-- ex. 10/archives/123456/123456789.tar.bz2
WHEN regexp_like(key, '^[0-9]+/archives/[0-9]+/[0-9]+.tar.bz2$') THEN 'archives_tar_bz2'
-- ex. 10/videos/123456/123456789.mp4
WHEN regexp_like(key, '^[0-9]+/videos/[0-9]+/[0-9]+.mp4$') THEN 'videos_mp4'
-- ... 他の分類を足していく ...
ELSE 'ohter'
END AS kind,
key,
size,
last_modified_date
FROM "s3_inventory"."example_bucket" -- 出力先
WHERE dt = '2023-12-10-01-00' -- パーティション
)
SELECT
kind,
COUNT(*) AS num_objects,
SUM(size) / 1000000000 AS sum_size_gb,
MIN(last_modified_date) as min_last_modified_date,
MAX(last_modified_date) as max_last_modified_date,
MIN(key) AS min_key,
MAX(key) AS max_key
FROM t
GROUP BY t.kind
ORDER BY t.kindこの調査によって対象バケットに含まれるオブジェクトのボリュームゾーンを発見し、それぞれへの対応策を考えられるようになりました。
オブジェクトタグとライフサイクルルールで古いオブジェクトを残さない
上の集計結果をもって、アプリケーション開発者などにヒアリングを行ったところ、合計サイズが最も大きかったオブジェクトは一定期間が経過したら削除できることが確認できました。
このオブジェクトについてはPUT時にオブジェクトタグを付与するようにアプリケーションの改修を行いました。さらに、このタグがついたオブジェクトを削除するライフサイクルルールを仕込んで、保持期間を過ぎたら削除するようにしました。
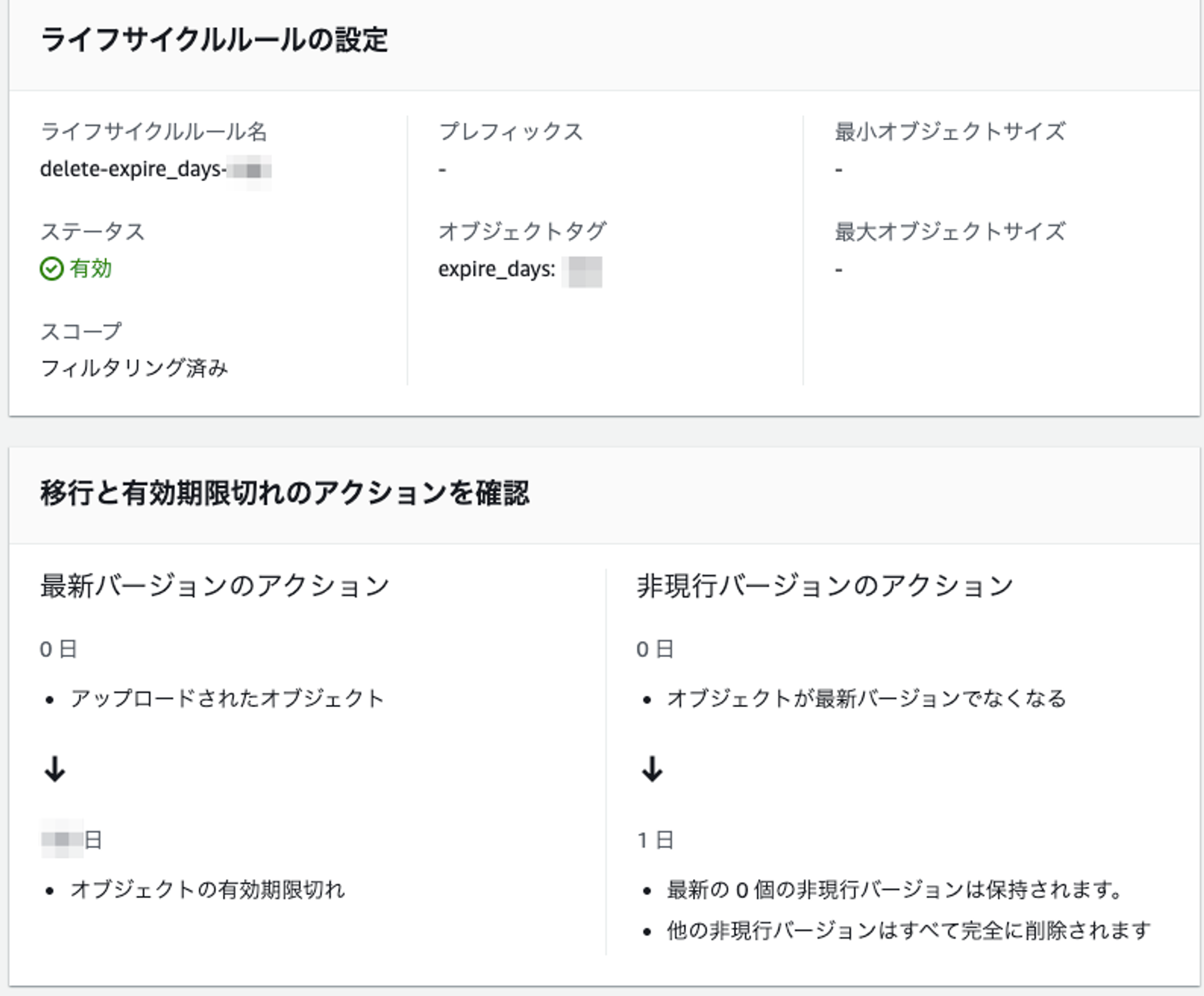
これによって、新たに作成されるオブジェクトは自動的に削除されるようになりました。
S3バッチオペレーションとLambdaで作成済みのオブジェクトを消す
一方で、作成済みの15億個のオブジェクトによってかなりのコストが毎月かかっており、これらを削除する必要もありました。過去に作成されたオブジェクトは、タグが付いていなかったり、データベースを参照して削除可否を判断しないといけなかったりと、要件としては複雑でした。
そこで、S3バッチオペレーションでまとめて削除することにしました。S3バッチオペレーションは、S3インベントリのレポートを入力として、オブジェクトごとに何らかの処理を行うための機能です。数十億個のオブジェクトに対しても、高速に処理できるスケーラブルなプラットフォームも具備しています。(S3バッチオペレーションでサポートしているレポート形式はCSVのみなので、集計用とは別で出力させました。)
S3バッチオペレーションには、オブジェクトのコピーやタグの付与などのよくあるユースケースに対応したプリセットのオペレーションもいくつか用意されていますが、上述の要件にはマッチしなかったので、Lambdaで実装することにしました。Lambdaにはオブジェクトごとに以下のようなメッセージが送られてきますので、キーを手がかりにして削除要否を判断し、可能であればDeleteObject APIで削除する、という実装になります。
{
"invocationId": "AAAAAAAAAAH4i...",
"job": { "id": "11111111-2222-3333-4444-555555555555" },
"tasks": [
{
"taskId": "AAAAAAAAAAHlT...",
"s3BucketArn": "arn:aws:s3:::example-bucket",
"s3Key": "10/archives/123456/123456789.tar.bz2",
"s3VersionId": null
}
],
"invocationSchemaVersion": "1.0"
}バッチオペレーションのポイントとはまりどころ
作業にあたって、いくつかポイントやはまりどころがありましたので紹介します。
コスト
Lambdaを使ったバッチオペレーションでは、2種類のコストがかかります。
- バッチオペレーション (東京リージョン, 2023/12/14 参照)
- 1ジョブあたり、0.25 USD
- 100万オブジェクトあたり、1.00 USD
- Lambda (東京リージョン, 2023/12/14 参照)
- 100万リクエストあたり、0.2 USD
- 加えて、コンピューティングリソース (メモリサイズ x 実行時間 x 並列数) にかかる料金
特に気をつけないといけないのがオブジェクト数に比例してかかる料金で、15億個のオブジェクトであれば、S3バッチオペレーションのジョブを1回実行するだけ (仮にLambda計算時間が0) で、1,700 USDかかることになります。
そのため、プロダクション環境でいきなり実行するのではなく、オブジェクト数が少ない開発環境やステージング環境で、Lambdaのコードが失敗なく実行できるか、意図したオブジェクトを削除できているかなどを入念にチェックして、イージーミスによるリトライを可能な限り減らすように作業を組みました。
Lambdaの実装
アプリケーションからの利用有無に基づいて削除可能かどうかを判断しないといけないオブジェクトもありました。具体的には、オブジェクトのキーからIDとなる数値文字列を抽出し、このIDでデータベースのテーブルを参照して、存在しなければ不要とみなして削除可能とする、というものです。
S3バッチオペレーションでは、Lambdaの実行時間に対しても料金がかかってきますので、極力余計な処理を省く必要がありました。加えて、高い並列度で分散処理するため、プロダクションのデータベースアクセスは回避しないといけません。
これらの要件・制約を勘案して、Lambdaの実装では以下の工夫をしました。なお、ランタイムとしてはPythonを使っています。
- 削除不可なIDのリストをあらかじめ作成する (約1,000万件)
- これでLambdaからのデータベースの参照が不要になる
- リストの件数を削るため、より数が少なかった削除不可の方を採用
- 削除不可IDリストをApache Parquetの形式にして最上層のレイヤに追加
- 圧縮によって、レイヤサイズやメモリサイズが削減され、さらにロード時間と照合速度も改善
- 他のLambda関数と共用しない最上層のレイヤに追加することで、他のLambda関数のサイズ増を回避
- Apache Arrowにアクセスするライブラリとしては、レイヤサイズを削減するためpyarrowではなくfastparquetを採用
- キーによるオブジェクトの分類が確定してから、削除不可IDリストのロードと照合を行う
- 削除不可IDリストのロードがオーバヘッドになってしまうため、その機会を減らす
これら工夫によって、平均実行時間は200~300msくらいに収まり、リーズナブルに削除できるようになりました。
S3のパーティショニング
ステージング環境での動作確認中に、少数 (数百件程度) ですが、以下のエラーが発生しました。
PermanentFailure: An error occurred (SlowDown) when calling the DeleteObject operation (reached max retries: 4): Please reduce your request rate.
調べたところ、S3のパーティショニングごとに設定されるリクエスト上限に引っかかってスロットリングされている、というものでした。
- バケットのプレフィックスに基づいてパーティショニングされる
- プレフィックスはキーの先頭からの文字列で、その長さはアクセスに応じて動的に変更され、ユーザからはコントロールできない
- パーティションごとに、PUT/COPY/POST/DELETEで3500 rps、GET/HEADで5000 rpsが確保される
- 特定パーティションへのリクエストレートが急激に高まると、503 (Slow Down) エラーになることがある
厄介なのは、プロダクションで稼働中のアプリケーションが、削除中のパーティションにアクセスするとスロットリングを受けてしまう可能性がある点です。一般的な削除であればS3のDeleteObjects APIでまとめて削除する (最大1000オブジェクト) ことでAPIアクセスを集約する、といった回避策も考えられますが、バッチオペレーションでは1回のLambda呼び出しで1オブジェクトの情報しか渡されないので採用できません。
そのため以下の対策を行い、プロダクションで実行しました。プロダクションでも同様のエラーに遭遇しましたが、並列度を下げたおかげで、発生は数件程度で収まりました。
- Lambdaの並列数を下げる
- そのバケットにアクセスするアプリケーションで、エラー時にリトライ処理されることを確認
削除の結果
S3バッチオペレーションによる削除を、7月・11月で2回に分けて実施しました。結果として約14億個のオブジェクトを削除し、サイズ (≒料金) で70%減になりました。
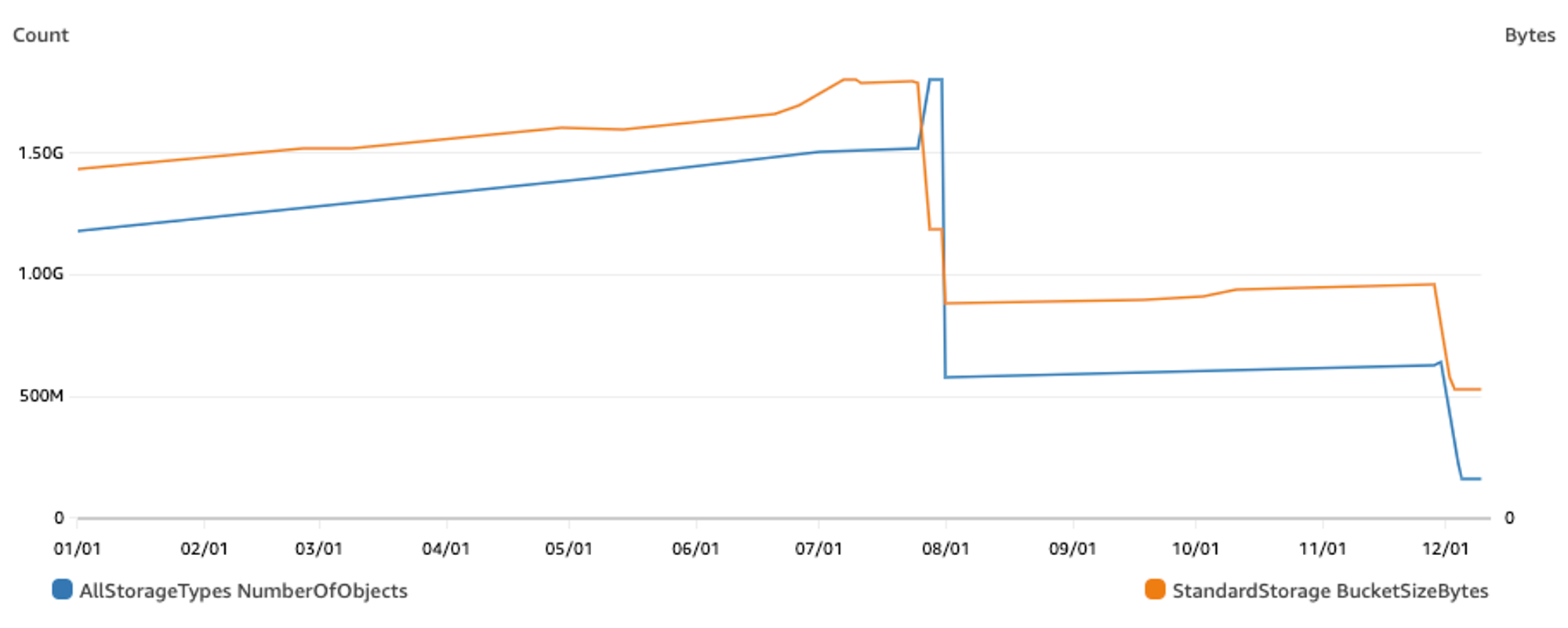
07/01~08/01でストレージサイズは減っているにも関わらずオブジェクト数が増えているところがあります。これは過去にバケットのバージョニングが有効になっている期間があり、そのときに作成されたオブジェクトをDeleteObjectだけでは削除しきれていないためでした。バージョニングされたオブジェクトをDeleteObjectすると削除マーカーだけが作られるので、そのオブジェクトのサイズは減らずに、削除マーカーが1オブジェクトとしてカウントされてオブジェクト数は増えてしまいます。残ってしまった削除済みのバージョニングオブジェクトは、ライフサイクルポリシーで削除するようにしました。
まとめ
S3のデータの削除のプロセスとテクニックについて、『DRIVE CHART』の運用で実際に行ったケースに沿ってご紹介しました。
特にS3は ”便利なファイル置き場” として様々な用途に共用してしまうと、保持するオブジェクトをそこまで利用していないはずなのに、思ったより毎月コストがかかっている、という負債にいつの間にかなりやすいものです。さらに、数十億個の規模になると直感がうまく機能しないようで、調べてみると意外なオブジェクトがコストに対して支配的だったりします。
大事なのは、作成時にはいつ・どうやって削除するかを決めて仕組みにしておくこと。そして、負債になっていると感じたときには、何に・どれだけお金がかかっているのかをきちんと調べることです。
最後となりましたが、本投稿のまとめです。
- バケットタグ + Cost Explorerでどのバケットの何の操作にお金がかかってるのかを知る ⇒ 本当にストレージにお金がかかってるのか? 実は過剰なPUTやLISTを行っているのではないか? という疑いを晴らしました
- S3インベントリとAthenaで何のオブジェクトがどれくらいあるかを知る ⇒ 動画は1ファイル数十MBと大きくて目立ってしまうが、実は数十KBの圧縮済みファイルの方が圧倒的大多数で総サイズも大きかった、という気づきを得られました
- オブジェクトタグとライフサイクルルールで古いオブジェクトを残さない ⇒ 理想は、アプリケーション実装時にこういった削除のポリシーも定めて仕込んでおきたいですね
- S3バッチオペレーションとLambdaで作成済みのオブジェクトを消す ⇒ オブジェクト数が膨大で、段階を踏んで慎重に進める必要もあったので、時間もお金もかかりました
We're Hiring!
📢
GO株式会社ではともに働くエンジニアを募集しています。
興味のある方は 採用ページ も見ていただけると嬉しいです。
Twitter @goinc_techtalk のフォローもよろしくお願いします!