

MoTインターン取り組み報告 ~標識検出の高速化~
AIコンピュータビジョンインターンDecember 16, 2022
こんにちは、東京電機大学システムデザイン工学研究科修士1年の江藤謙(@pictur_etoken)と申します。大学では深層学習における分布外データの挙動についての研究をしています。私は10月から11月の2ヶ月間(都合により実質的な勤務時間は1ヶ月)、MoT初となるインターンに参加しました。今回のインターンでは、道路情報の自動差分抽出プロジェクトにおける、標識検出の高速化というタスクに取り組みました。本記事では、その取り組み内容についてご紹介したいと思います。
はじめに
道路情報の自動差分抽出プロジェクトは、ドライブレコーダの映像から標識などの道路上の物体を検出し、地図と比較することで現地と地図の差分を見つけて迅速な地図更新を実現することを目指しています。ここで、処理対象となるドライブレコーダの映像は膨大であり、映像あたりの処理時間が大きくなるとそれだけ運用コストが増大します。そこで今回のインターンでは、本プロジェクトのコスト削減を目的として標識検出の高速化に取り組みました。
高速化のアプローチ
標識検出の高速化にあたって、例えば以下のようなアプローチが考えられます。
- 標識検出モデルを改良し計算量を下げる
- フレームレートを落とし、処理する画像の枚数を減らす
- 標識検出モデルに入力する画像のサイズを小さくする
まず1.は、モデルを見直すため学習の再実行が必要になります。MoTが蓄積している学習データは膨大であり、試行錯誤しながら何度も学習を行うのは今回のインターン期間では難しいと考えました。
次に2.は、標識検出のみで考えると有効ですが、本プロジェクトではフレームを跨いで検出された標識をトラッキングする必要があり、フレームレートを落とすとトラッキングの精度に悪影響が出ると考えられます。
最後に3.ですが、これは推論時のみの工夫であるため再学習が不要、また後続の処理にも影響を与えないなどの利点があり、今回はこちらのアプローチを採用しました。しかし、画像の入力サイズをパラメータとした場合、標識検出の精度と推論にかかる時間は基本的にトレードオフの関係にあります。そのため本アプローチにおいては、画像の入力サイズを下げても検出精度をできるだけ維持できるような工夫を入れることが重要となります。
実験条件
標識検出モデル
本プロジェクトで既に標識検出のために学習済みであったYOLOv4 [1]を用いました。検出対象となる標識は「規制標識」の一部のみです。標識の種別についてはこちらが参考になります。
このモデルの学習・推論における入力画像サイズはこれまで800 x 800でした 。つまり今回のインターンでは、推論時の入力画像サイズを800 x 800よりも小さくすることで推論を高速化します。
マシンスペック(AWSのg4dn.xlargeインスタンスを利用)
CPU:Intel(R) Xeon(R) Platinum 8259CL CPU @ 2.50GHz
GPU:NVIDIA Tesla T4
メモリ:16GB
推論時間の計測
Pythonの標準ライブラリであるtimeモジュールで以下のように推論時間(inference_time)を計測しました。なおバッチサイズは1としています。画像の読み込み等は含まず、推論処理の時間だけを計測しました。ただし画像の読み込み後にその画像に対して何らかの処理を加えてから推論を行う場合は、追加した処理も推論時間に含めます。
image = cv2.imread(frame_filepath)
# 推論時間の計測開始
start = time.time()
# 推論実行
label_numbers, confidence_scores, boxes = model.detect(image)
# 推論時間の計測終了
inference_time = time.time() - start評価用データ
MoTにて収集済みのドライブレコーダ映像を用いました。画像サイズは1280 x 720です。
精度評価指標
本プロジェクトは、標識検出の再現率(Recall)90%を目標として進められていたため、今回のインターンでは再現率90%を維持しつつ推論を高速化することを目指しました。
入力画像サイズに対する検出精度と推論時間の変化
画像の入力サイズをパラメータとした場合、標識検出の精度と速度はトレードオフの関係にあると述べましたが、実際にこれを確認するために入力画像サイズを800 x 800から128 x 128まで縦横32画素ずつ小さくしていき検出精度と推論時間を調べました。結果は以下の通りです。
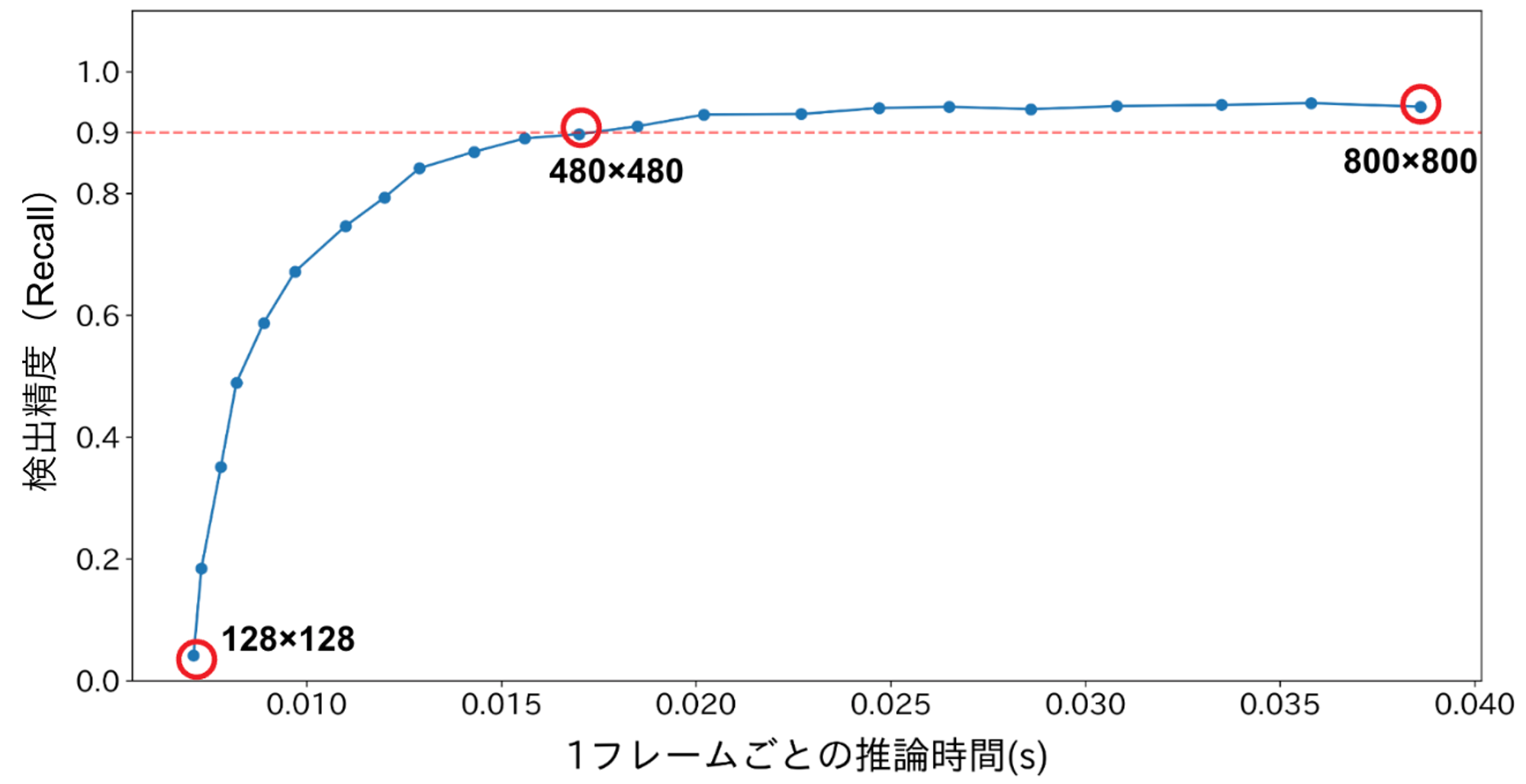
図1. 入力画像サイズを変えた場合の検出精度と推論時間の変化
図1において横軸は1フレームごとの推論時間、縦軸は検出精度(再現率)です。入力画像サイズはグラフの右から左に向かって小さくなっており、サイズが小さくなるほど推論時間は短くなることが分かります。対して検出精度は、右から左に行くにつれて最初のうちはほぼ一定ですが、480 × 480あたりから急激に低下していくことが確認できます。以降では、この結果を比較対象として、入力画像サイズが小さくなることによる精度低下を緩和する工夫を考えていきます。
画像からの固定領域の切り取り
図1における顕著な精度低下は、極端なリサイズ(縮小)により画像中の標識領域の解像度が小さくなりすぎていることが原因と考えられます。そこで、ドライブレコーダから得られた原画像(1280 x 720)をそのままリサイズするのではなく、不要な領域を切り取ってからリサイズすることで解像度低下を抑えることを考えます。
まず、ドライブレコーダから得られる画像の例を以下に示します。

図2. ドライブレコーダから得られる画像の例
これを見ると、標識は画像の中央から上にかけて写っていることが分かります。より正確な調査のため、学習データにおける標識の出現箇所のヒートマップを作成すると以下のようになります。
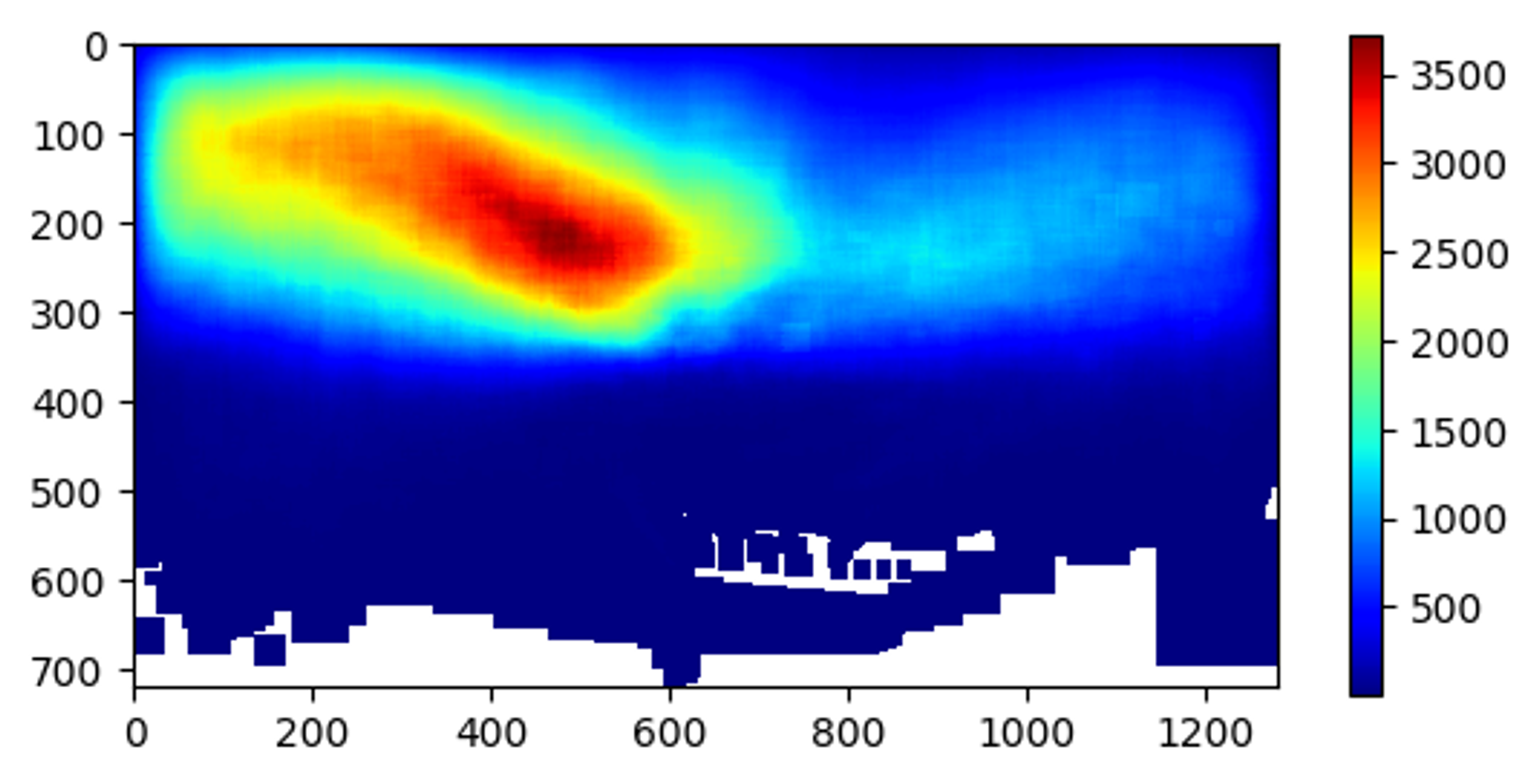
図3. 標識の出現箇所のヒートマップ
図3からも明らかなように、標識は大半が画像の上側に出現します。また中央から左にかけての出現頻度が特に高いですが、これは道幅の広い道路における画像が多く、進行方向に向かって右側の標識は非常に小さく写るため処理対象とならなかったことが一因と考えられます。
この結果から、車種やドライブレコーダ設置位置のばらつきによる変動を考慮しても画像の下側3割(216画素)程度を切り取っても検出精度への影響は少ないと考えました。また常に同じ箇所を固定的に切り取るため、切り取りに要する時間はほぼ無視できます。
下3割を切り取った状態で、再び画像サイズを800 x 800から128 x 128まで変化させた際の検出精度と推論時間の関係を調査しました。結果を以下に示します。
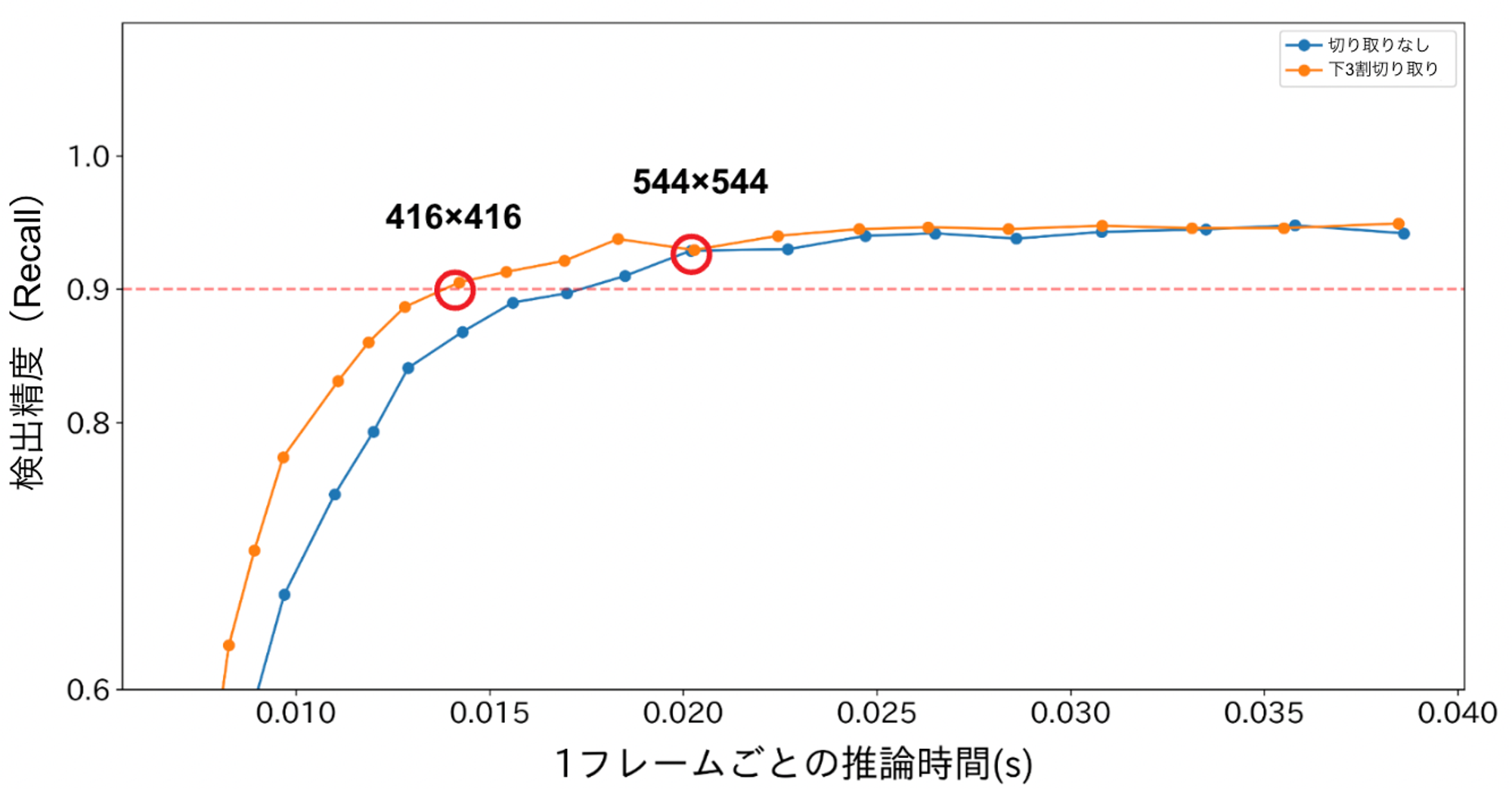
図4. 下3割を切り取った上で入力画像サイズを変えた場合の検出精度と推論時間の変化
図4における青のグラフが原画像をそのままリサイズした場合(図1と同じ)、オレンジのグラフが画像の下3割を切り取ってからリサイズした場合です。入力画像サイズが544 x 544よりも大きい場合は両者にほぼ差が見られませんが、それよりも小さいサイズでは下3割の切り取りによって精度低下が緩和されていることが分かります。再現率90%を維持できる最小サイズは416 x 416であり、800 x 800の場合の推論時間と比較して約2.7倍高速化できています。
以上より、単純に入力画像から下3割を切り取るだけでもある程度の効果が確認できたので、さらに他の領域も切り取ってみたいと思います。図3のヒートマップに基づき、下3割の他に標識があまり出現しないと思われる領域を追加で切り取るバリエーションを以下の4種類用意しました。
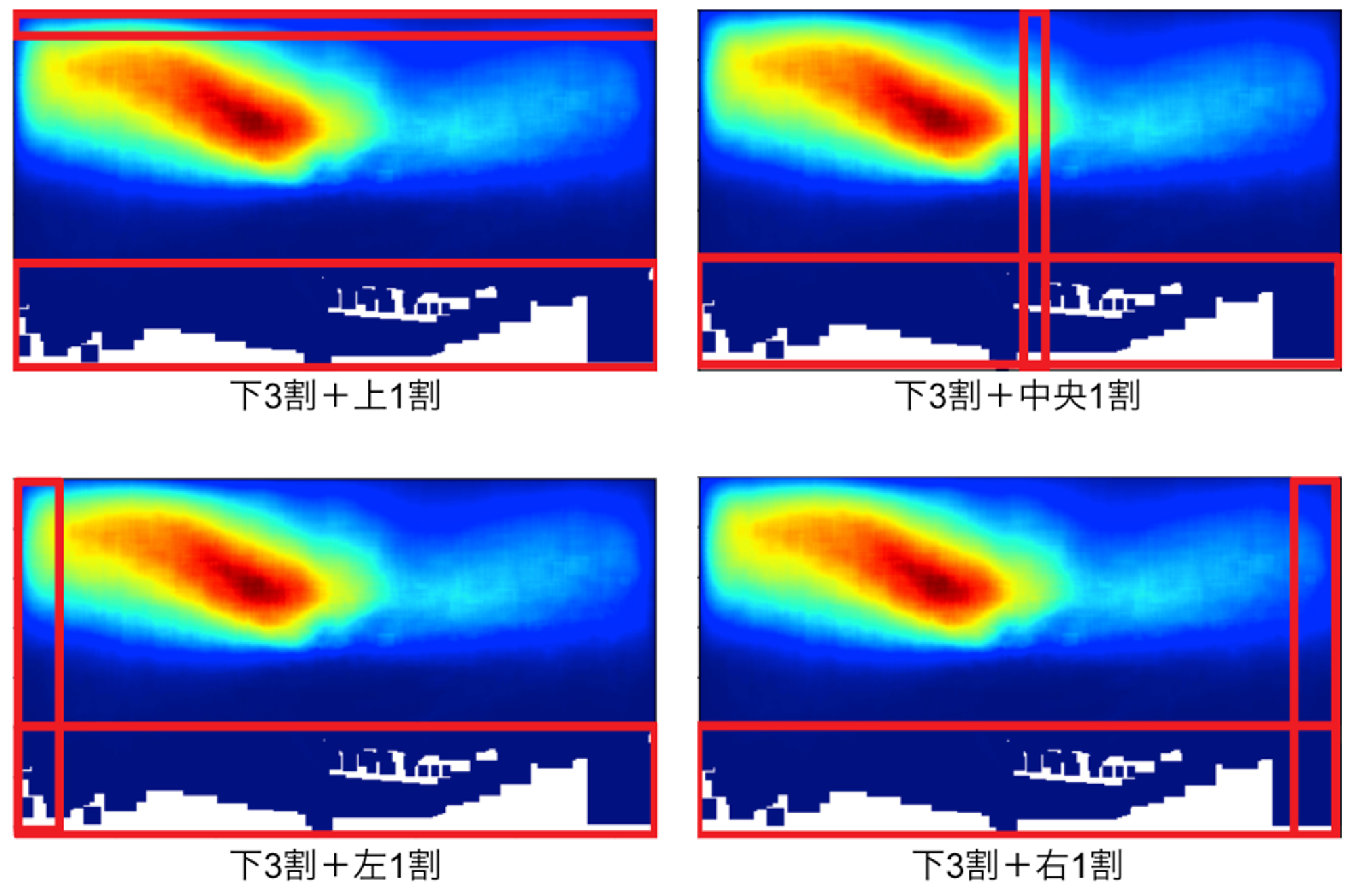
図5. 画像切り取りのバリエーション(赤枠で囲まれた領域が切り取り対象)
それぞれに対する実験結果は以下の通りです。なお入力画像サイズは480 × 480としています。
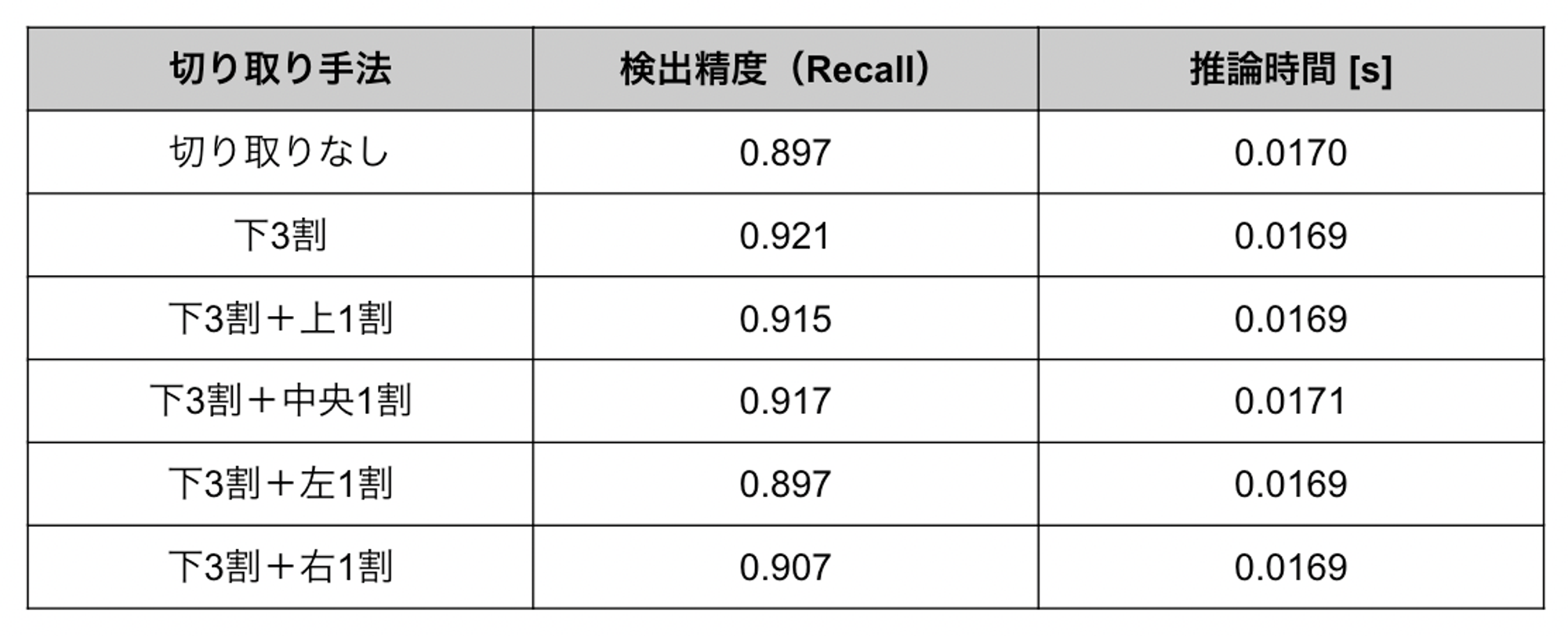
表1. 入力画像サイズ480 x 480における様々な切り取り手法の比較
表1を見ると、どの手法も下3割切り取りよりも精度が低くなっていることが分かります。図3のヒートマップを考慮して出現頻度がそれほど高くない領域を選んだものの、特に左側または右側の切り取りは精度に大きな悪影響を与えています。これはおそらく、標識が画像の左右端近くに写るのは標識が車両に最も接近して大きく(検出しやすく)なっている瞬間であり、左右の切り取りによってこうした瞬間を除外してしまうためであると考えられます。
色抽出による動的な画像の切り取り
ここまでの検討結果から、単純に画像から下3割の固定領域を切り取ることが効果的なことが分かりましたが、これは車種やカメラの設置位置のバリエーションを考えて余裕を持たせた切り取り幅となっています。しかし実際には画像によって最適な切り取り幅は異なるため、画像に応じて切り取り幅を動的に変えることが望ましいです。
そこで、今回の検出対象である規制標識が青もしくは赤色で構成されていることを利用し、色に基づいて標識が存在する領域を大まかに推定して下側の切り取り幅を変えることを考えてみました。この前処理の流れは以下のようになります。
- 入力画像の色空間をRGBからHSVに変換
- HSVのそれぞれを閾値処理して青と赤の領域を抽出
- 抽出された領域に基づき画像の下側からどれだけ切り取るかを決定
RGBからHSVへの変換はOpenCVのcvtColor()関数で簡単にできます。HSVに変換する理由としては、RGBよりも明るさの影響を受けにくいこと、任意の色を取り出しやすいことなどが挙げられます。今回は、青と赤について以下の範囲を抽出しました。
- 青:100 ≦ H ≦ 195、90 ≦ S ≦ 255、100 ≦ V ≦ 255
- 赤:0 ≦ H ≦ 10、64 ≦ S ≦ 255、50 ≦ V ≦ 255
ここで、OpenCVにおけるHSVの値域は0 ≦ H ≦ 179、64 ≦ S ≦ 255、0 ≦ V ≦ 255であることに注意してください。値の抽出(2値化)にはOpenCVのinRange()関数を用いました。実際の抽出結果例を以下に示します。
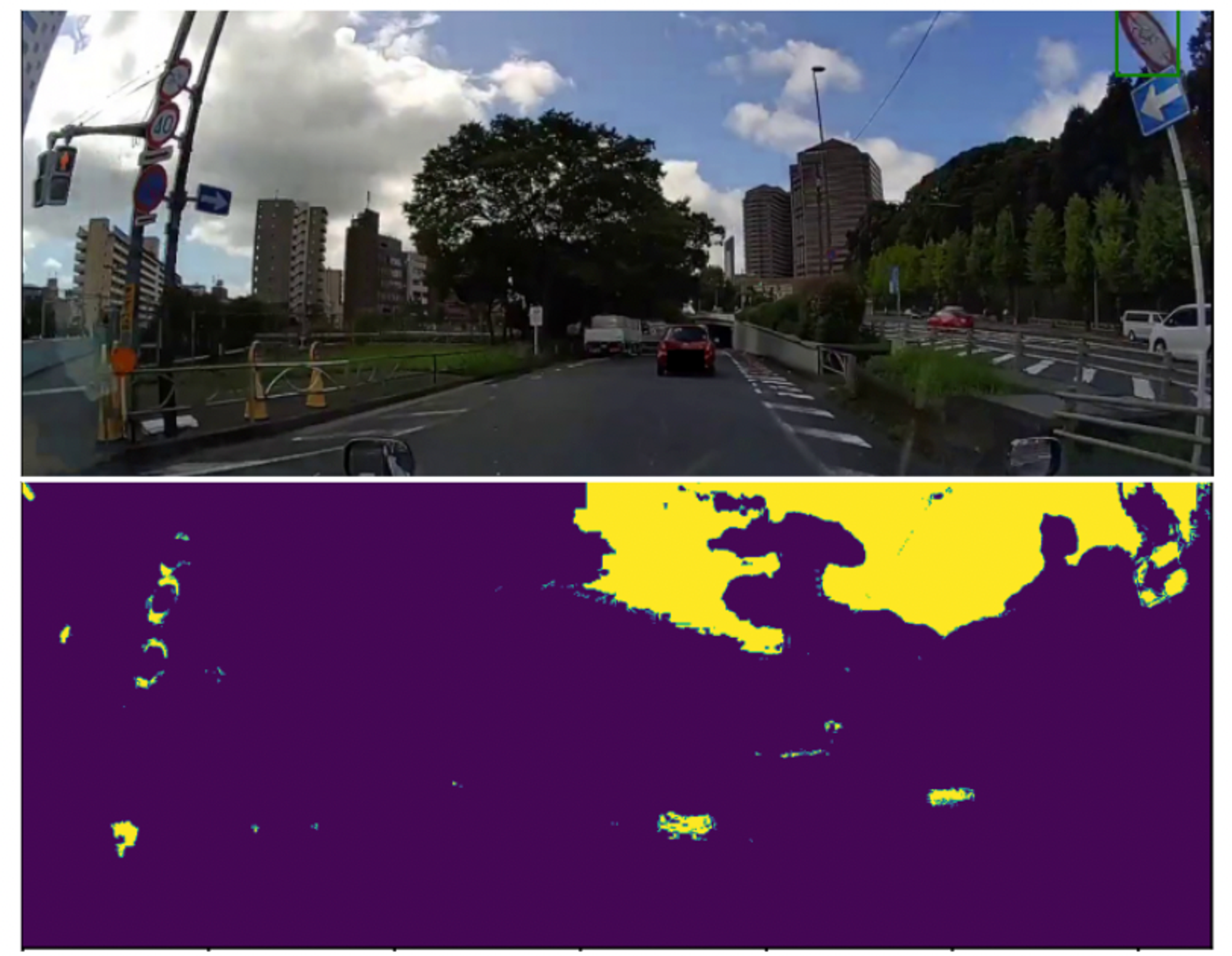
図6. 青色領域と赤色領域の抽出(上:入力画像 下:抽出結果)
図6を見ると、あまり精度は高くありませんが、大まかに標識の場所を抽出できていることが分かります。この抽出結果において、抽出された領域のうち最も画像下端に近い座標を求め、そこから下を全て切り取ります。つまり、下図における緑色の線より下を切り取ります。

図7. 色抽出結果に基づく切り取り位置の決定
固定的に下3割を切り取る手法と、色抽出により動的に切り取る手法を比較した結果を以下に示します。
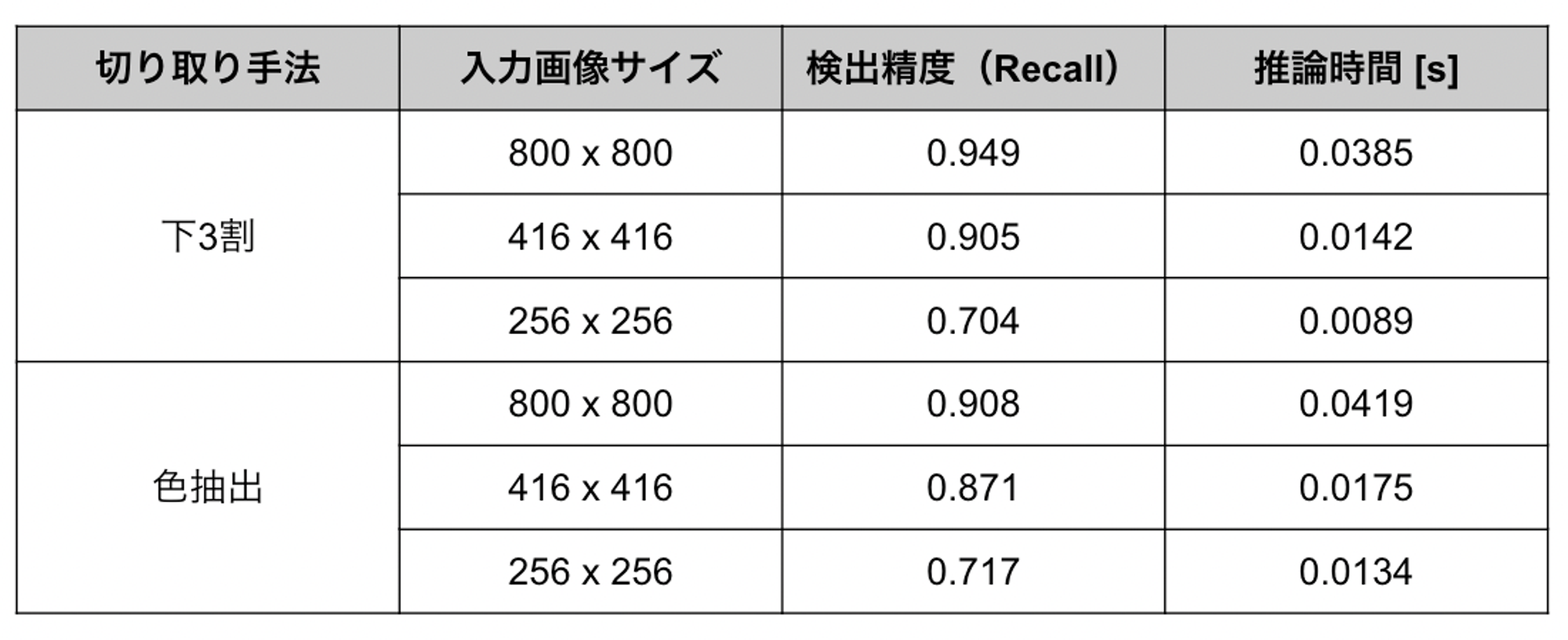
表2. 下3割切り取りと色抽出による切り取りの比較
表2を見ると、まず推論時間においては、色抽出を行うことで3〜4ミリ秒程度増加していることが分かります。次に検出精度においては、従来の入力画像サイズである800 x 800や、下3割を固定的に切り取る場合に再現率90%を達成できる最小サイズであった416 x 416においては色抽出を使った動的な切り取りによる精度改善は見られません。しかし、さらに小さい256 x 256では若干精度が改善しています。
色抽出を使った動的な切り取りが、下3割の固定的な切り取りと比較して精度改善につながる要因と、精度低下につながる要因をそれぞれ挙げると以下のようになるかと思います。
- 精度改善につながる要因
- 下3割の固定的な切り取りよりもさらに多くの領域を切り取ることで、リサイズによる解像度低下の影響を低減できる
- 精度低下につながる要因
- 色のみでは標識領域の抽出精度が低く、標識が存在する領域も切り取ってしまう
- 多くの領域を切り取ることになった場合にアスペクト比が原画像から著しく変わってしまう
入力画像サイズを小さくしていくにつれ、最初は精度低下につながる要因の方が強く働くが、ある段階から精度改善につながる要因がそれを上回っていくと考えられます。
今回は2つの要因が切り替わるポイントをうまく再現率90%のあたりに持ってくることができなかったのですが、例えば画像の下側のみでなく左右など他の部分も切り取る等の工夫によりさらに改善ができるのではないかと思っています。
画像のアスペクト比を考慮した切り取り
色抽出による画像の切り取りの部分で述べたように、切り取り後に原画像と著しく異なるアスペクト比になってしまうと精度低下につながる可能性があります。学習時のデータ拡張によりアスペクト比の変化に対するロバスト性はある程度高められますが、学習データから大きく逸脱したアスペクト比の画像に対しては十分な精度が出ないと考えられます。
ここで、YOLOv4の学習で用いられている独自のデータ拡張手法であるMosaicに注目します。これは、CutMix [2]のように画像を組み合わせることで新たな画像を作り出すのですが、図8のように4枚の画像をそれぞれランダムにクロップし、それらを組み合わせて1枚の画像としてモデルに入力するという手法です。

図8. Mosaicを適用した画像の一例(論文[1] Figure3を引用)
Mosaicはもちろん学習時にのみ使うことが一般的ですが、これを推論時にも使うことを考えてみます。ただ、複数の異なる画像を組み合わせるのではなく、1枚の画像から不要な領域を切り取った後、そこから複数の領域をクロップして組み合わせることで1枚の画像に再構成します。今回トライした組み合わせ方を以下に示します。
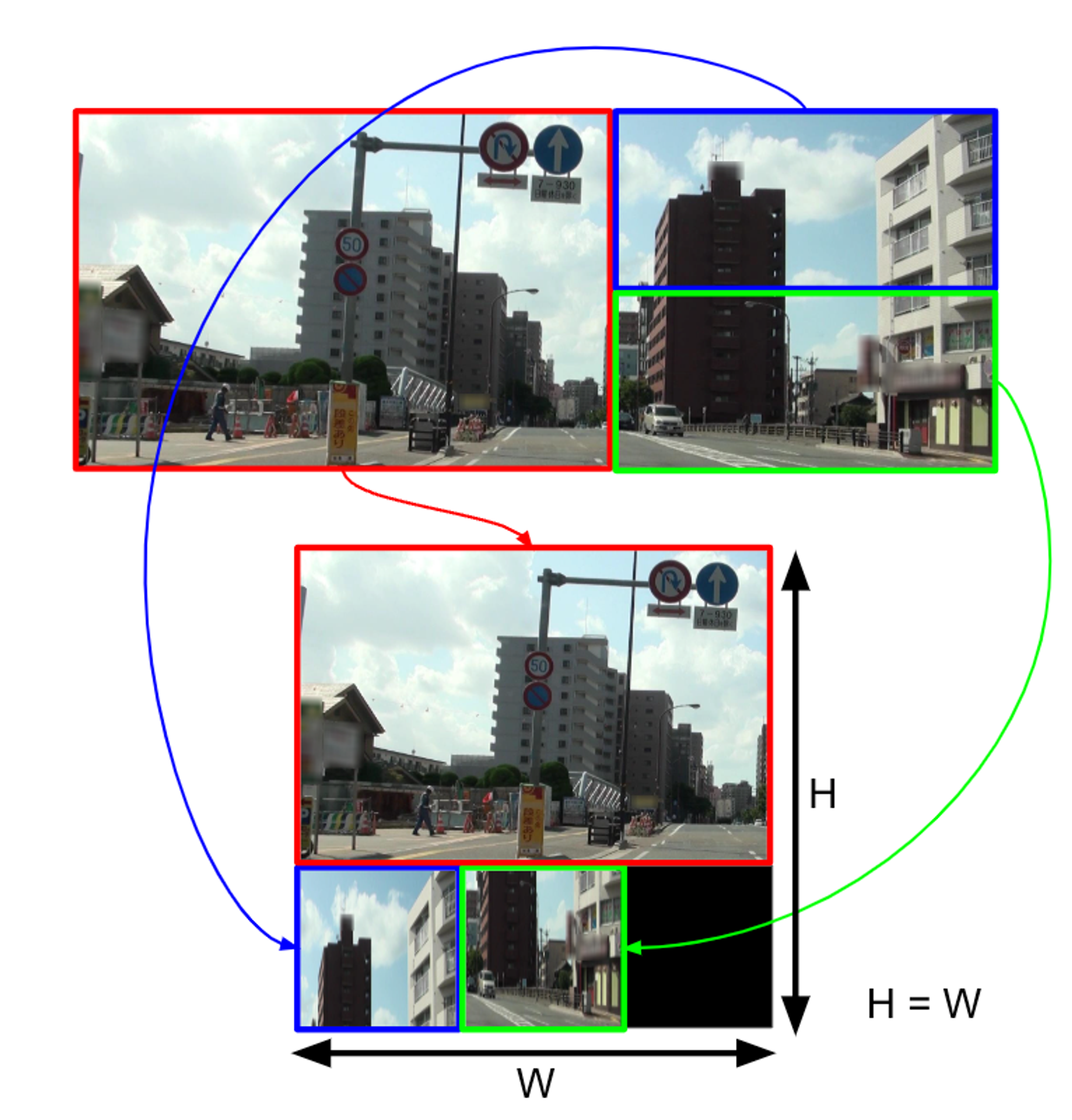
図9. 領域のクロップと組み合わせによる画像の再構成
図9のように複数の領域を組み合わせることで、不要な領域を取り除いた上で原画像のアスペクト比から大きく逸脱することなく標識検出モデルに入力する正方形の画像を作り出すことができると考えました。実験結果は以下の通りです。なお入力画像サイズは480 x 480としています。
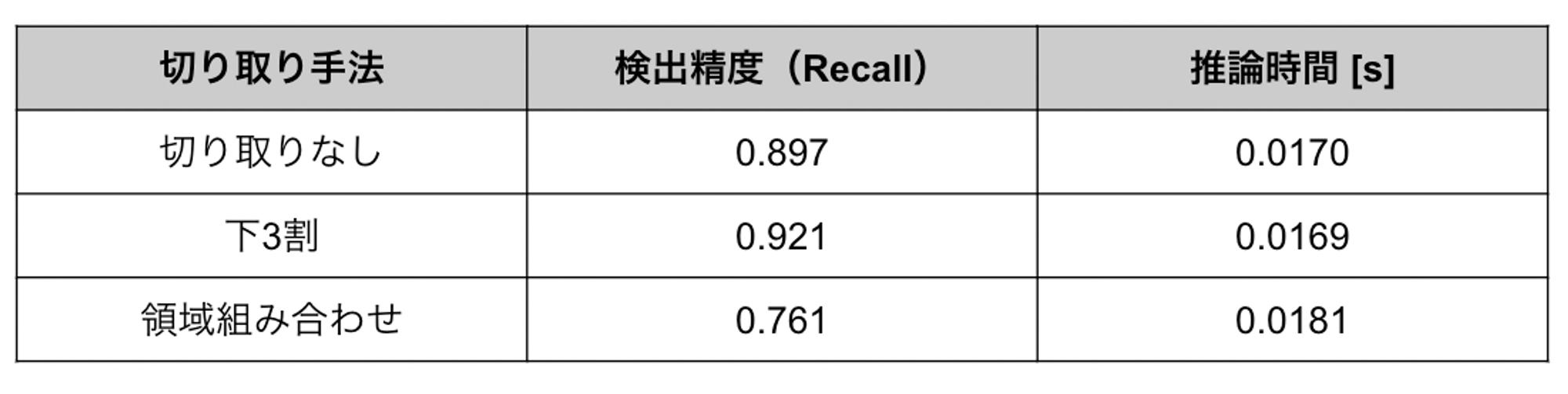
表3. 領域組み合わせと他手法の比較
表3を見ると、領域を組み合わせる手法では他と比べて大幅に精度が低下していることが分かります。これは1枚の画像から複数の領域をクロップする際に、検出対象となる標識が分断されてしまい、検出漏れや誤検出につながったことが原因と考えられます。
以上より、領域の組み合わせによる手法でも良い結果を得ることができませんでした。しかし、クロップする領域の選択やその組み合わせ方には様々なパターンがあり、タスク固有の性質を理解し、うまく工夫をすることができれば良い結果につながるのではないかと考えています。
まとめ・感想
今回のインターンでは道路情報の自動差分抽出プロジェクトにおける、標識検出の高速化というタスクに取り組みました。まず、標識が出現しないであろう領域を入力画像から固定的に切り取ることで、再現率90%を維持しつつ推論速度を2.7倍まで高速化することができました。その後も色抽出による手法や画像から複数の領域を取り出して組み合わせる手法などにトライしましたが、残念ながらさらに良い結果を出すことはできませんでした。しかし、シンプルな手法で改善ができたことは、保守運用の容易さも求められる実プロダクトにおいては意義があることだったと思います。今回のタスクでは、目的が推論の高速化であるため、無闇に処理を追加することができないという点が最も難しかったです。こうした点を克服するには、タスク固有の性質(今回だと標識の色や出現箇所など)を理解し、ドメイン知識を活用して問題を解きやすくすることが重要と感じました。
2ヶ月という限られた期間ではありましたが、MoTの社員の方々のおかげで非常に充実したインターン生活を送ることができました。特に、メンターの鈴木さん(@x_ttyszk)をはじめ、プロジェクトメンバーやCVエンジニアの方々には毎日のミーティングやディスカッション、ランチでの交流など、多くのサポートをして頂きました。大学に戻ってもMoTで学んだことを忘れずに、精一杯頑張っていきたいと思います。本当にありがとうございました。
参考文献
[1] Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv, 2020.
[2] Sangdoo Yun, Dongyoon Han, Seong Joon Oh, Sanghyuk Chun, Junsuk Choe, and Youngjoon Yoo. CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features. ICCV, 2019.
We're Hiring!
📢
Mobility Technologies ではともに働くエンジニアを募集しています。
興味のある方は 採用ページ も見ていただけると嬉しいです。
Twitter @mot_techtalk のフォローもよろしくお願いします!