

JapanTaxiで全社BIツールに「Looker」を採用した理由
行灯LaboLookerBIデータ基盤December 06, 2019
💁🏻
※本記事は Mobility Technologies の前身である JapanTaxi 時代に公開していたもので、記事中での会社やサービスに関する記述は公開当時のものです。
JapanTaxiでは、常に分析基盤の課題を整理し、下記のようにアーキテクチャの見直しを随時行っています。課題のアプローチとして適切であればどんどん新しいサービスやクラウドコンポーネントを活用しています。
分析基盤を Cloud Composer & trocco 構成に刷新しました
今回は、全社共通でプロダクト関連のデータを見るBIツールとして「Looker」を導入することを決定しましたので、既存の課題や導入判断ポイントをご紹介したいと思います。
課題について
既存環境の課題感は、主に次のようなものがありました。
- KPIなど指標の算出定義がバラバラになりやすい
- ダッシュボードなどの変更管理がしづらい
- メッシュで集計したマップ可視化のパフォーマンス
はじめ2つは、他社様の課題感と共通する部分かと思います。一つずつ少し詳しく解説したいと思います。
KPIなどの指標の算出定義がバラバラになりやすい
指標の算出定義のばらつきというのは、例えば、アプリから注文頂いたタクシーの配車数に、キャンセルされたものを含めるか含めないかみたいな定義の差異が発生するみたいなイメージです。(アプリの仕様上、タクシー確定後にユーザがキャンセルすることができます。)
これには大きく2つの理由があります。
一つ目は既存BI製品の活用と運用の仕方の問題です。
弊社ではこれまで他のBIツールを活用しており、社内で共有するダッシュボードやグラフは、デスクトップ版 (個人ローカル環境)で作成し、同製品のクラウド型サービスにパブリッシュし全社共有していました。 ただ、デスクトップ版からデータソースであるDWHのBigQueryに直接アクセスすることができるため、数字の定義をその時々で作れてしまい、これがばらつきを発生させる要因となっていました。
これを避けるためには、クラウド型の方にばらつかせるべきではない数字の定義を含めたデータソースを作って共有し、ダッシュボードなどを作るメンバにこれを原則使うことを統制すればよいと思います。
しかしながら、この方式にするとグラフやダッシュボードの表現力がかなり下がってしまうという問題があります。デスクトップ版でできることの一部が、クラウド型でできないことがあるためです。
そして、もう一つの理由は、人が増えたことです。
正直1年ほど前は、私一人、もしくはもう一人くらいのメンバーだけがこういうワークをしていたので、直接コミュニケーションを取れば問題にならなかったのですが、こういう作業をするメンバーが増え、問題化してきました。
ダッシュボードなどの変更管理がしづらい
これも人が増えたことと関連するのですが、これまではとあるダッシュボードやグラフなどを作成かつメンテナンスする人は一人の担当であることが多く、複数人で運用することはほぼありませんでした。
ただ、人が増えてきたことにより、Aさんが作ったダッシュボードをBさんが変更していて、Aさんが再び変更しようとしたら覚えのないものになっていて、びっくりしたりすることがでてきました。びっくりするだけならいいのですが、本来のダッシュボードの運用目的を理解しないBさんが、それに沿わないグラフをダッシュボードに加えてしまうなど、ビジネス上の不都合もでてきました。
また、まれにオペレーションミスでダッシュボードを消してしまうことがあり、運良くローカルにパブリッシュ前の元データが残っていたらいいのですが、それがない場合は、記憶を頼りに復元するという悲しい感じになります。
メッシュで集計したマップ可視化のパフォーマンス
分析する際に位置情報を扱うことが多い弊社では、以前に下記のブログでご紹介したような地域メッシュコードを単位とした集計分析・可視化をすることが多く、このようなマップをダッシュボードに含めて可視化・運用することがあります。
このような可視化マップをクラウド型で全社共有する際に、表示速度とデータ更新の手間の問題がありました。
クラウド型でこのマップを運用する場合、このメッシュコードのGeoJsonとBigQueryのデータを結合する必要があります。結合処理をクラウド側上で行うため、位置情報のデータ件数が多いと実用に耐えられないくらい表示が遅くなります。
これを避けるために、ある程度BigQuery上で集計したマートと作るという手もありますが、ドリルダウンの粒度を犠牲にするトレードオフを許容する必要があります。
また、このような結合を前提とする場合、BigQueryのデータを一旦抽出することが必須となり、データがオフラインになります。よって、データの鮮度を保つために定期的にデータを手動更新する再抽出の手間が発生します。
Looker でどう解決できたか
それぞれの課題について、Looker社様にもご協力いただいてPoCにより解決可能性を検証しました。
コードによる定義と統一インターフェースで数字の定義のばらつきを防止
Lookerでは、データの定義を LookML というものでコードとして定義します。Lookerは、WEBブラウザで利用するインターフェースのみとなり、グラフを作って可視化する場合に原則LookMLで定義した数字しか扱えません。これにより、数字の定義のばらつきを防ぐことができます。
Github連携により変更管理を実現
上記の用に定義したコードを Githubと連携 する事ができます。
ダッシュボードなど構成要素すべてをGithubで管理することができるので、変更の本番デプロイ承認や変更内容の記録や追跡など管理が非常にやり易くなります。
MapBoxのタイルを利用したカスタムマップで最適なメッシュ可視化を実現
詳しいやり方は こちら をご参照いただければと思いますが、MapBoxのタイルセットでメッシュを作り、それをLookerのカスタムマップから参照することで位置情報をメッシュ単位で集計して可視化する事ができます。
BigQueryの位置情報は、緯度経度で記録されているため、それぞれのレコードに対して任意のメッシュコードを緯度経度から算出し、その情報を付加したテーブルを予め作っています。そのコードで上のメッシュタイルセットとデータをLooker上で結合するイメージです。
検証の結果、表示スピードも実用に問題ないことが確認できました、こちらはBigQueryのデータを直接参照するためデータの鮮度も手間なく確保できます。
以下にイメージを載せておきます。(数値はダミーです。)
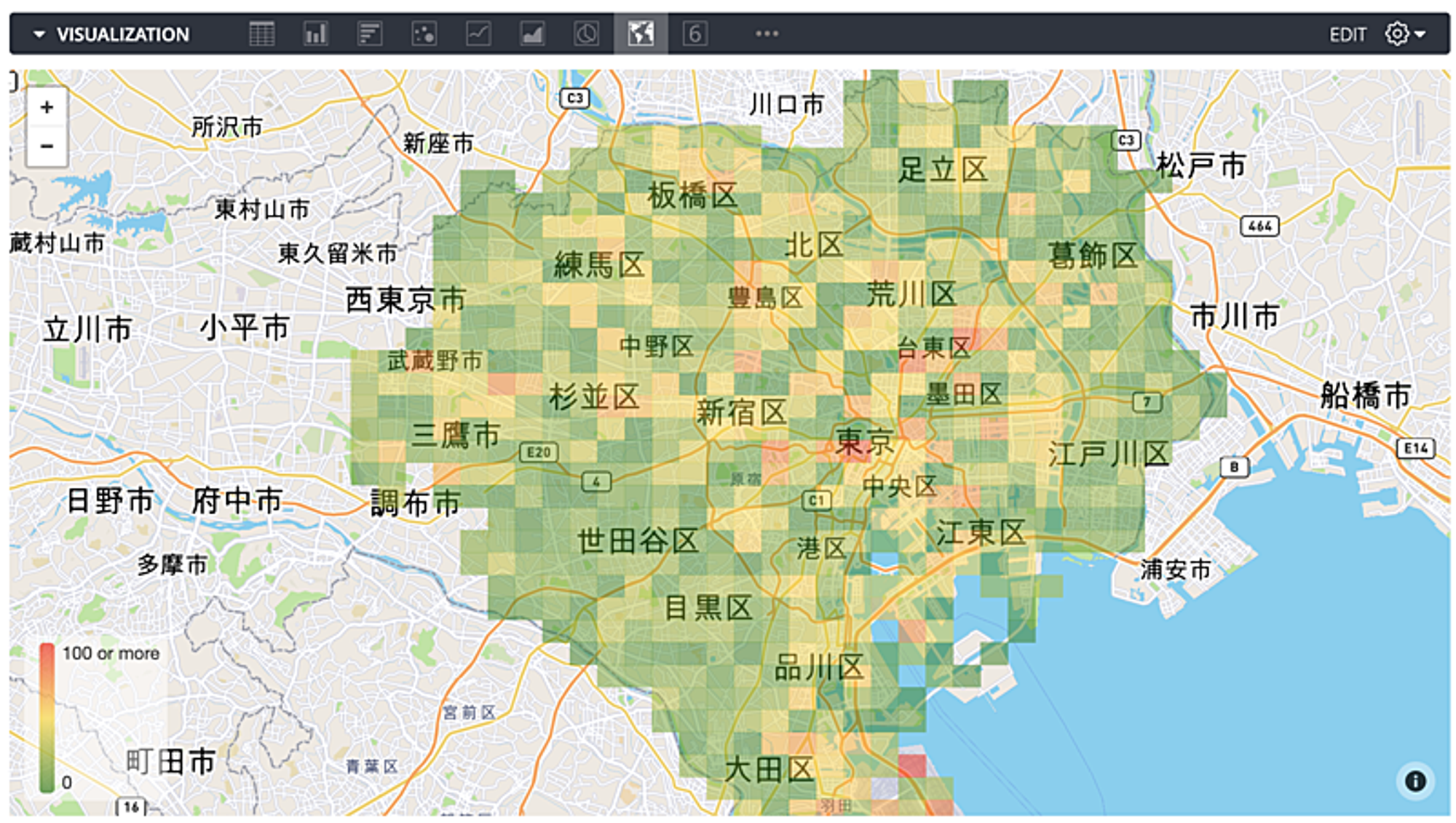
1kmメッシュで集計した位置情報データ(広域)
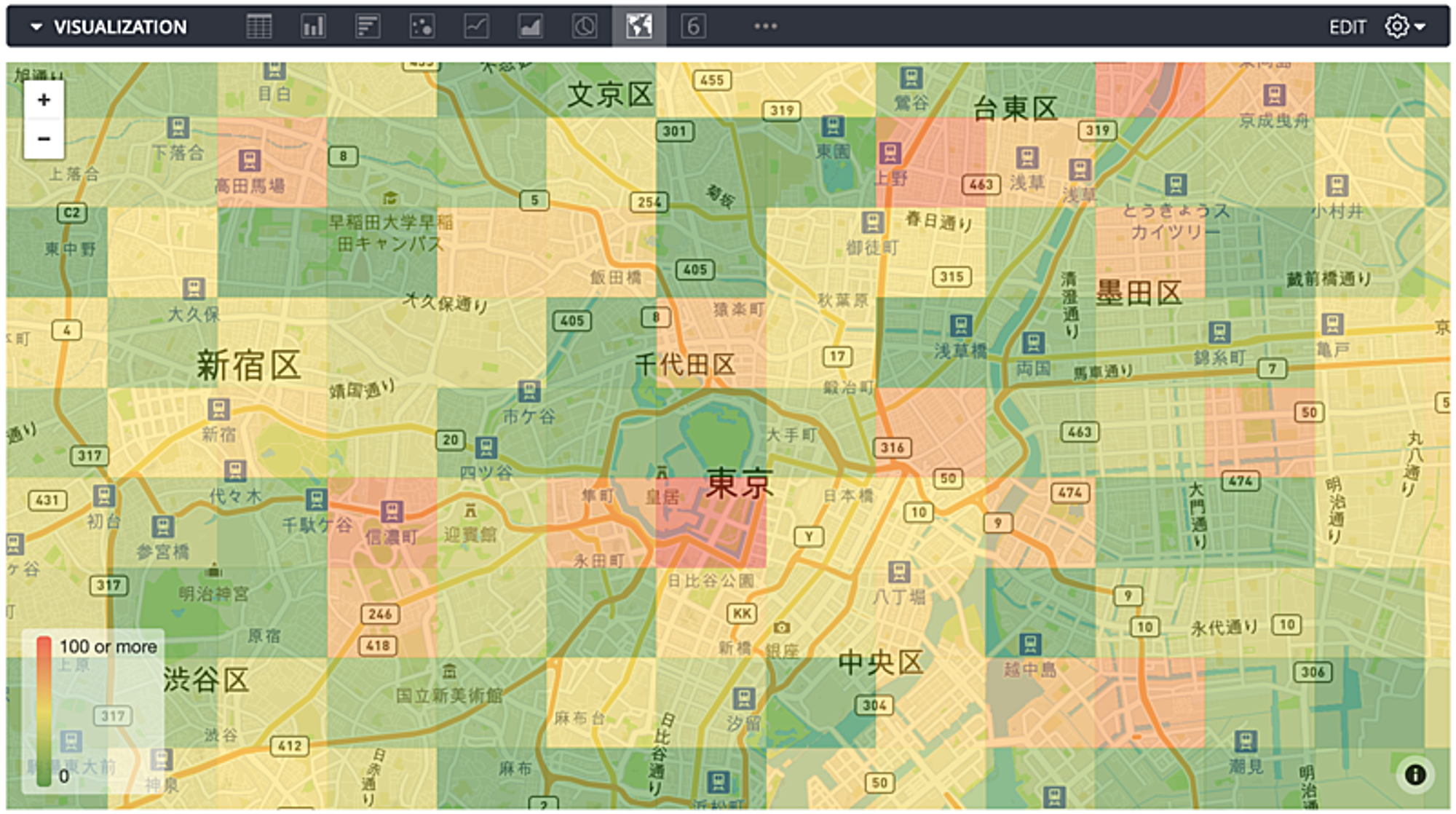
1kmメッシュで集計した位置情報データ(拡大)
結論
PoCにて満足する結果が得られましたので、今回は紹介しておりませんが、他の様々な論点も加味して導入を決定しました。たとえば、Slackへのレポート送信が楽な点などです。
ちなみに、これまで分析者が行っていたデスクトップ版を使ったアドホックであったり、ちょっとマニアックな分析は、引き続き他社製品を利用しています。
あくまでLookerは、社内のみんながよく参照する数字や定期的にモニタリングするもの、またその変化をある程度決まった範囲でドリルダウンして分析する用途に最適という判断をしております。
最後まで読んでいただいてありがとうございました。今回の弊社での検討内容が皆様の何かのお役に立ちますと幸いです。
💁🏻
※本記事は Mobility Technologies の前身である JapanTaxi 時代に公開していたもので、記事中での会社やサービスに関する記述は公開当時のものです。
Mobility Technologies では共に日本のモビリティを進化させていくエンジニアを募集しています。話を聞いてみたいという方は、是非 募集ページ からご相談ください!