

OptunaとKubeflow Pipelinesを用いた並列ハイパーパラメータチューニング
MLOpsOptunaAIはじめに
こんにちは。AI技術開発部 MLエンジニアリング第1グループの築山です。
以前、社内でOptunaとKubeflow Pipelines(以下KFP)を用いて並列ハイパーパラメータチューニングを行い、とあるプロダクト(後述する『お客様探索ナビ』の経路推薦システム)のパラメータに適用する機会がありました。
その際は社内向け勉強会のためにスライドをまとめ、以下のツイートとともにSlideShareで公開しており、多少の反響もいただいていました。
https://twitter.com/2kyym/status/1256147262738018304?s=20そのスライドがOptunaの開発者の方の目に留まり、「テックブログを書いて欲しい」と打診をいただき、今回執筆している次第です。
公開済みスライドと被る部分もありますが、基本的には
- 今回のユースケース
- OptunaとKFPの紹介・チュートリアル
- チューニングのフロー
- 使いやすさ・パフォーマンスへの寄与
- プロダクトに組み込むポイント
という流れで、図やソースコードを交えつつ解説していきます。
今回のユースケース
通常、ハイパーパラメータ(以後、ハイパラ)をチューニングしたい状況というとDNNモデルの学習率や層の数などのいわゆる「MLモデル学習のためのハイパラ」を思い浮かべる方が多いと思われますし、実際そういったユースケースが大半ではないでしょうか。
我々のユースケースはというと「あるプロダクトにおける経路推薦のための強化学習コンポーネントのパラメータを最適化したい」といったものでした。
この文章だけでは全体像が見えてこないかと思いますので、まずは『お客様探索ナビ』の機械学習システムやモデル評価について概観します。
『お客様探索ナビ』とは
MoTでは、タクシー配車アプリ『GO』を利用する乗務員向けに『お客様探索ナビ』という機械学習サービスを提供しています。
このサービスはざっくり説明すると「タクシーの流し乗務(駅待ちではない)において、お客様をピックアップしやすい営業経路を乗務員に推薦する」というものです。
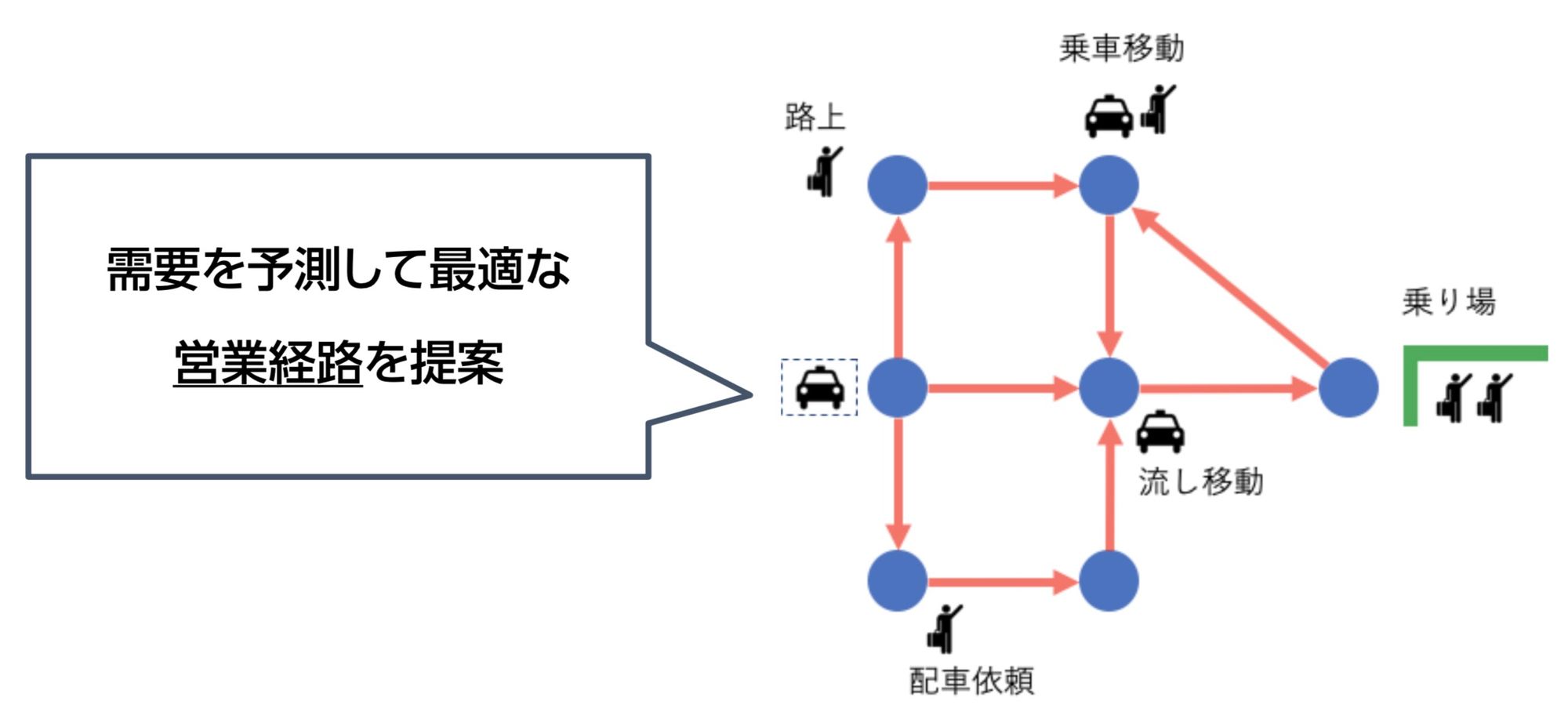
入社されたばかりの乗務員さんや、営業エリアの道に慣れていない乗務員さんでも、平均以上の営業収益を上げられるようにサポートすることが目標です。
機械学習ロジック
『お客様探索ナビ』がどのような流れで経路推薦を行っているのか、ざっくりと説明します。
乗務員さんに経路を提示するのが目標ですが、それを達成するために以下のようなステップを踏んでいます。
- 乗車数などの統計値を入力として、道路ごとに『直近30分に発生する乗車(需要)数』を予測するMLモデルを用意する
- 同じく統計値を入力として、道路ごとに『直近30分に発生するタクシー通過(供給)数』を予測するMLモデルを用意する
- 15分ごとに最新のデータを用いて2つのMLモデルで推論を行い、「道路ごとの需要・供給値」を更新し続ける
- 予測された需要・供給をもとに、強化学習を用いた経路推薦を行う
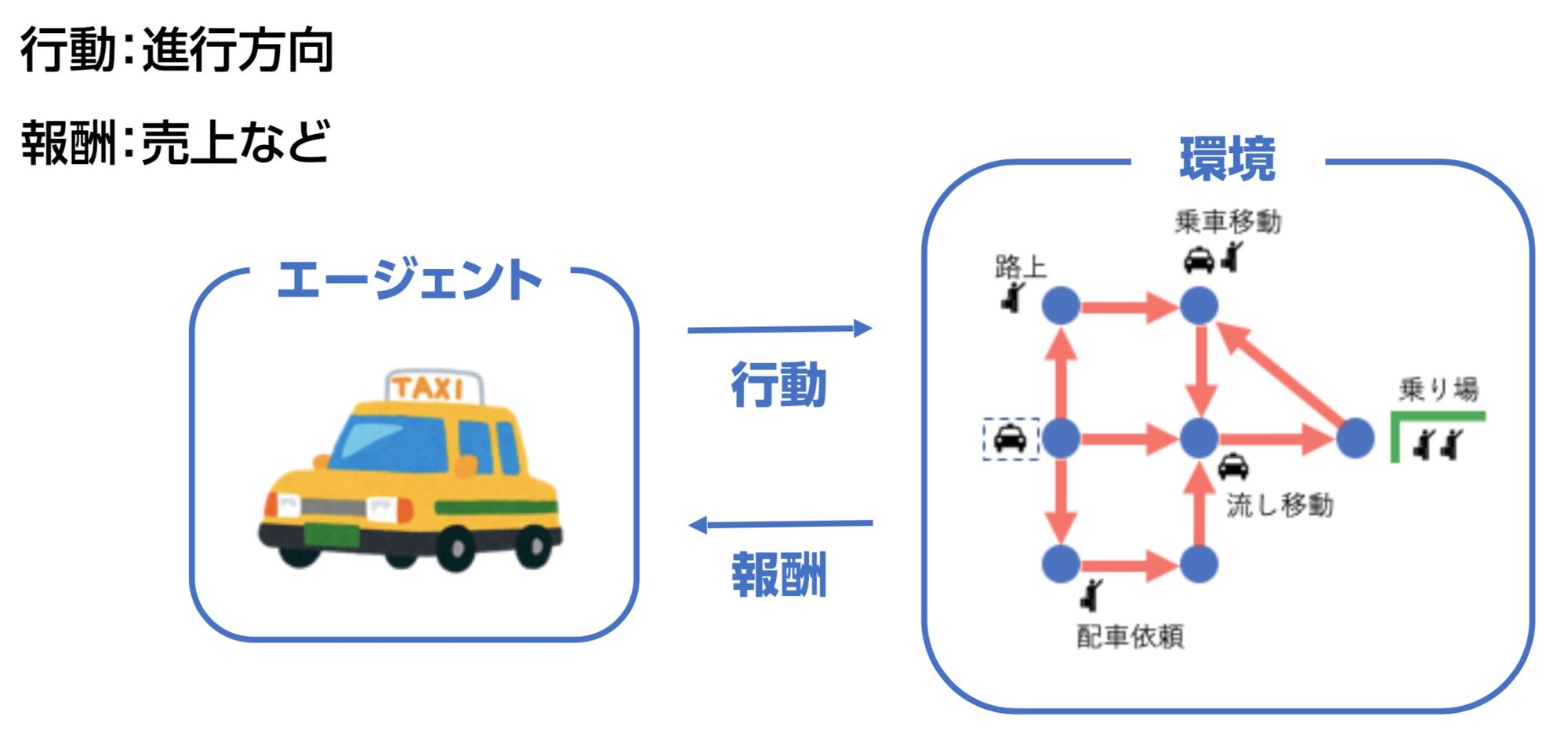
詳しいアルゴリズムは後述する参考資料に譲りますが、強化学習においてはエージェント=タクシーと考え、より多くの乗車が得られるように行動を最適化していきます。
参考資料(スライドと動画アーカイブ)
『お客様探索ナビ』のアルゴリズムについてもっと詳しく知りたいという方は、弊社の織田がDeNA TechCon 2019で発表した内容をご覧ください(前半)。
また今回紹介するハイパラチューニングについてだけでなく、『お客様探索ナビ』のアーキテクチャやMLOps全般について知りたいという方は、上記のスライドの後半か、もしくは私と鈴木がDeNA TechCon 2020で発表した内容をご覧ください。
Value Iterator のハイパーパラメータ
上述の強化学習フェーズでは Value Iterator というコンポーネントが用いられています。
ざっくりとですが、この Value Iterator にも複数のパラメータが存在し、需要・供給値だけでなくハイパーパラメータ群によっても推薦される経路は変化します。
当然経路によってシミュレーションで得られる営業収入(営収)、ひいては実際の乗務員さんの営収にも変化があるということになります。
こうした背景のもと、「Value Iteratorのハイパラ群をチューニングしたい」という声がチーム内で上がっていました。
具体的な状況は以下のようなものでした。
- Value Iteratorのハイパラは数多くあり、アルゴリズムエンジニアの決め打ちで固定したまま実証実験〜リリース直後まで運用されていた
- 『お客様探索ナビ』の性質上、地域ごとにモデルを作る場合があり、地域ごとに最適パラメータが異なる可能性がある
- 時間の経過によっても最適パラメータは変化していく可能性がある
これらの状況を踏まえ、以下のようなハイパラチューニングの方針を立てました。
- 大前提として、チューニングのプロセスが全て自動化されている
- 定期的に、もしくは必要に応じてワンタッチでチューニングが実行できる
- 時間がかかりすぎない
- Compute Engine等の計算機コストがかかりすぎない
ハイパラチューニングのためのフレームワークは数多くありますが、Optunaはチューニングを検討していた当時話題になっていたことに加え、チームメンバーがお試しで触ってみた感じ使いやすそう(直感的なインターフェイスや学習コストの低さ等)だということで採用が決まりました。
機械学習モデルのパフォーマンス評価とシミュレーション
なぜ並列チューニングのためのパイプラインにKFPを採用したのか、という話にも関わってくるのですが、『お客様探索ナビ』のモデル評価とシミュレーションについて少し説明します。
すでに述べたように『お客様探索ナビ』では2つのMLモデルを用いて道路ごとの需要・供給値を予測し、その値から強化学習を用いて経路を提示しているのですが、「実際にその経路に従って走った場合、どれくらいの営収を得られるか」を見るためのシミュレータが存在します。
実際の過去の需要・供給データからある日時にどこで実車が発生したかが分かるため、それと推薦経路を照らし合わせています。
モデルの更新時には誤差(ここではRMSE)だけでなく、シミュレーションによる営収も比較してデプロイするかを判定しています。
結局のところ、今回のチューニングでは以下の流れを繰り返し行うことになります。
- Value Iterator のパラメータを変更する
- 変更したパラメータでシミュレーションを実行し、営収を見る
またシミュレーションを行う際は1週間(7日間)をセットとする場合が多いのですが、弊チームでは元々7日分を並列して行い、集計まで自動化して簡単に実行できるようにKFPパイプラインが組まれていました。
この既存のパイプライン実装に手を加えることなくそのまま使い、チューニングまで自動化する際に都合がいいということで、KFPを採用することに決まりました。
OptunaとKFPの紹介・チュートリアル
OptunaとKFP自体に馴染みのない方のために、紹介とチュートリアル(かなり軽め)を挟んでおきます。
Optunaとは
Optunaはハイパーパラメータチューニングのためのオープンソースのフレームワークです。
2018年12月にOSSとして公開され、2020年1月に正式リリースされました。
言語は他のML系フレームワークに漏れずPythonです。
Optuna公式ページに挙げられている独自の特徴として、
- 複数のチューニング試行を簡単に分散・並列して実行できる(分散最適化)
- Define-by-Run(試行時に探索空間を定義)で目的関数が簡単に書ける
- 試行のPruning(枝刈り)によるチューニングの高速化
等があります。
全体的に、分散・並列チューニングの処理をシンプルに書くことができる設計になっていると感じます。
Optunaの簡単な使い方
以下が最もシンプルなOptunaのチューニングフローのソースコードです。
ちなみに以下のチュートリアルのコードはOptunaのドキュメントにてPython ScriptもしくはJypyter Notebookの形式で提供されています。
順を追って説明します。
import optuna
# 最小化したい目的関数(1試行ごとに行う処理)
def objective(trial):
x = trial.suggest_float("x", -10, 10)
return (x - 2) ** 2
study = optuna.create_study(direction="minimize")
study.optimize(objective, n_trials=100)Optunaにおいてチューニング(試行を繰り返し、最適なパラメータに収束するまで)の単位は Study、試行の単位はTrialと呼ばれます。
チューニングの際は目的関数 (Objective) に1回の試行、すなわち提案されたパラメータを用いて処理を行い、結果を取得するまでの処理を記述します。
上のソースコードではこのような流れとなります。
- create_study で新規Studyを定義。値を最小化したいので direction="minimize"とする。最大化の場合は “maximize” が使える
- study.optimize でチューニングの実行。試行数は100としている
- Objectiveではパラメータxの値をSuggestし、二次関数に与えてその値を返している
ちなみにStudyオブジェクトからは様々な情報が取得でき便利なため、参照する機会は多いです。
以下の例のように、これまで行った試行の情報や、最もパフォーマンスの良かったTrialオブジェクトを取得することが可能です。
study.best_params
>> {‘x’: 1.9926578647650126}
study.best_trial
>> FrozenTrial(number=26, state=<TrialState.COMPLETE: 1>, params={'x': 1.9926578647650126}, value=5.390694980884334e-05, datetime_start=xx, datetime_complete=xx, trial_id=26)
study.trials
>> [FrozenTrial(number=0, …), …]先程の例ではパラメータのSuggestに線形な浮動小数点数を用いていましたが、以下のような様々な空間を用いることが可能です。
# カテゴリカル
optimizer = trial.suggest_categorical("optimizer", ["MomentumSGD", "Adam"])
# 整数
num_layers = trial.suggest_int("num_layers", 1, 3)
# 線形な浮動小数点数
dropout_rate = trial.suggest_float("dropout_rate", 0.0, 1.0)
# 対数変換をした空間での浮動小数点
learning_rate = trial.suggest_float("learning_rate", 1e-5, 1e-2, log=True)
# 離散的な浮動小数点数
drop_path_rate = trial.suggest_float("drop_path_rate", 0.0, 1.0, step=0.1)OptunaにはStudyやTrialの他にStorageという概念が存在します。
名前の通りStudyやこれまでのTrialといった情報を格納するものですが、ユースケースに合わせて選択することができます。
- InMemoryStorage
- デフォルトの場合はこちら
- チューニングが実行されているリソースのメモリ上にStorageを確保する
- 基本的には Trial 情報の永続化はしない
- 1インスタンスのみで直列・並列にチューニングを行うケースでは、RDBStorageと比較して高速
- RDBStorage
- 外部のRDBにStorageを確保する
- MySQL, PostgreSQL, SQLite が使用可能
- StudyやTrialの情報が永続化されるため、分散最適化ならこれ一択
- 永続化によって、チューニング (Study) 単位での中断・再開が可能
OptunaではStudy開始時に n_jobs という引数でTrialの並列実行数を指定することができます。
今回はチューニングを実行するOptunaジョブは1つでしたが、KFPと n_jobs を用いてTrialの並列実行を行ったため、上のどちらのStorageを使うことも可能でした。
しかし過去のStudyやTrialを参照できるのはやはり便利で、またTrial数を徐々に増やしたいケースもあったため、GCPのCloud SQL上にMySQLサーバを立て、 RDBStorage を用いることにしました。
Kubeflow Pipelines (KFP) とは
KFPを包含するKubeflowはGoogleが開発しているフレームワークで、Kubernetes上で機械学習のライフサイクルを一通り実行するためのツール群が揃っています。
ちなみに、KFP以外のKubeflowのコンポーネントは今回は使いませんでした。
周囲でもKFPを使うチーム・企業は増えてきたように思いますが、それ以外のコンポーネントを使いこなしている話はあまり聞きません。
KFP自体は機械学習に特化したワークフローエンジンです。
ワークフローエンジンというとApache AirflowやDigDagが有名どころですが、個人的にKFPのML向きの便利機能として以下のようなものがあります。
- Experimentsという機能があり、実験ごとにパイプラインを用意し、入力パラメータを変更して実行までをWebUIからワンタッチで出来る
- パイプラインのタスクごとにInputやOutputを可視化でき、出力されたJupyter NotebookやConfusion MatrixなんかもWebUI上から直接確認できる
- Experimentsの実験実行ごとの一覧性が高く、使用したパラメータ値の比較などもしやすい
KFPのコアはArgoというこちらもML向けのOSSワークフローエンジンですが、パイプラインの定義などはArgoよりもPythonで分かりやすく書けると感じます。
なお『お客様探索ナビ』では、機械学習モデルのデプロイパイプラインや推論パイプラインなど、運用よりのユースケースではApache Airflowを用い、シミュレーションなど実験よりのユースケースでKFPを用いています。
このように必ずしもどちらかに寄せる必要はなく、使い分ける手もあります。
OptunaとKFPを用いた並列ハイパラチューニングのフロー
図解
使用するフレームワークの紹介が終わったところで、実際の『お客様探索ナビ』におけるチューニングフローと実装に解説に移ります。
import optuna
def objective(trial):
# 1.VI parameterをsuggest
# 2.そのparameterでsimulation jobをdeploy
# 3.終了後、営収値を集計
return 営収値
study = optuna.create_study(direction="maximize")
study.optimize(objective, n_trials=100, n_jobs=5)先程のサンプルコードをもとに方針を考えます。
シミュレーションにおける営収を最大化したいので direction="maximize"、一旦Trial数は100にしています。
Optunaのデフォルト最適化アルゴリズムである TPE はシーケンシャルなアルゴリズムであり、並列実行数を増やしすぎると最適化の精度に悪影響が出る可能性があるため、様子を見つつ n_jobs=5 にしておきます。
結果的に、直列実行と5並列の実行ではパフォーマンスに差はありませんでした。
目的関数には「新たにsuggestされたValue Iteratorのパラメータを用いてシミュレーションを実行(シミュレーションパイプラインをKFPにデプロイ)し、営収を集計する」までの処理を記述すれば良いことになります。
シミュレーション(7日分1セット)はKFPのパイプラインジョブとして存在し、個人の実験やデプロイパイプラインでの評価の際はこれをデプロイするコマンドを叩いていました。
実際のコードの解説をする前に、図を用いてどういうフローになっているか解説します。
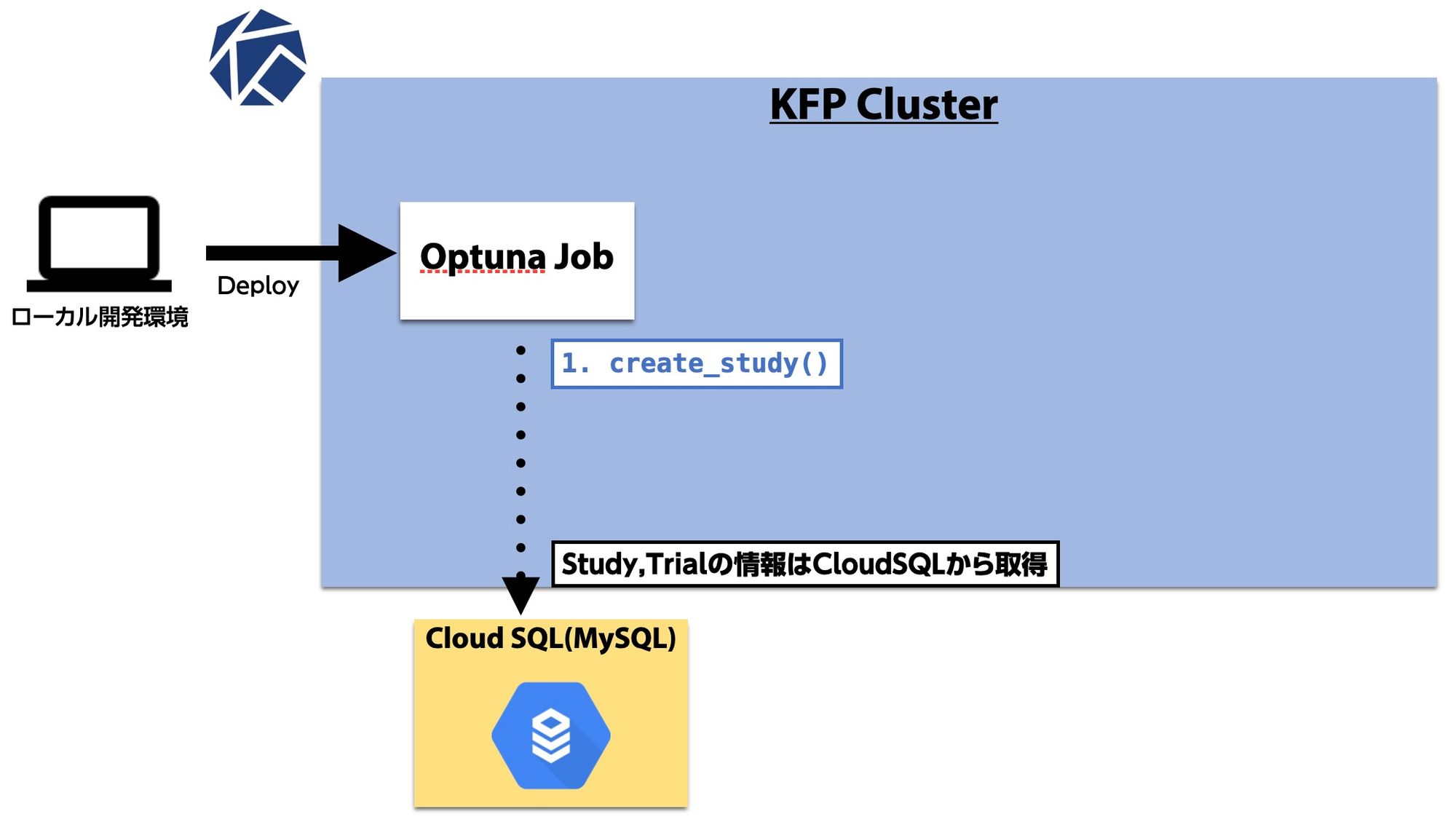
Optunaの実行はローカルで行うことも可能ですが、チューニングが終了するまで数時間待機するのは不便なので、Optunaの実行自体もKFP上のジョブとして用意しました。
まず、デプロイされたOptunaジョブでは新規チューニングを行うため create_study() を実行します。
前述したようにCloud SQL上にMySQLサーバを用意しているので、引数でそちらに接続するようにしてやります。
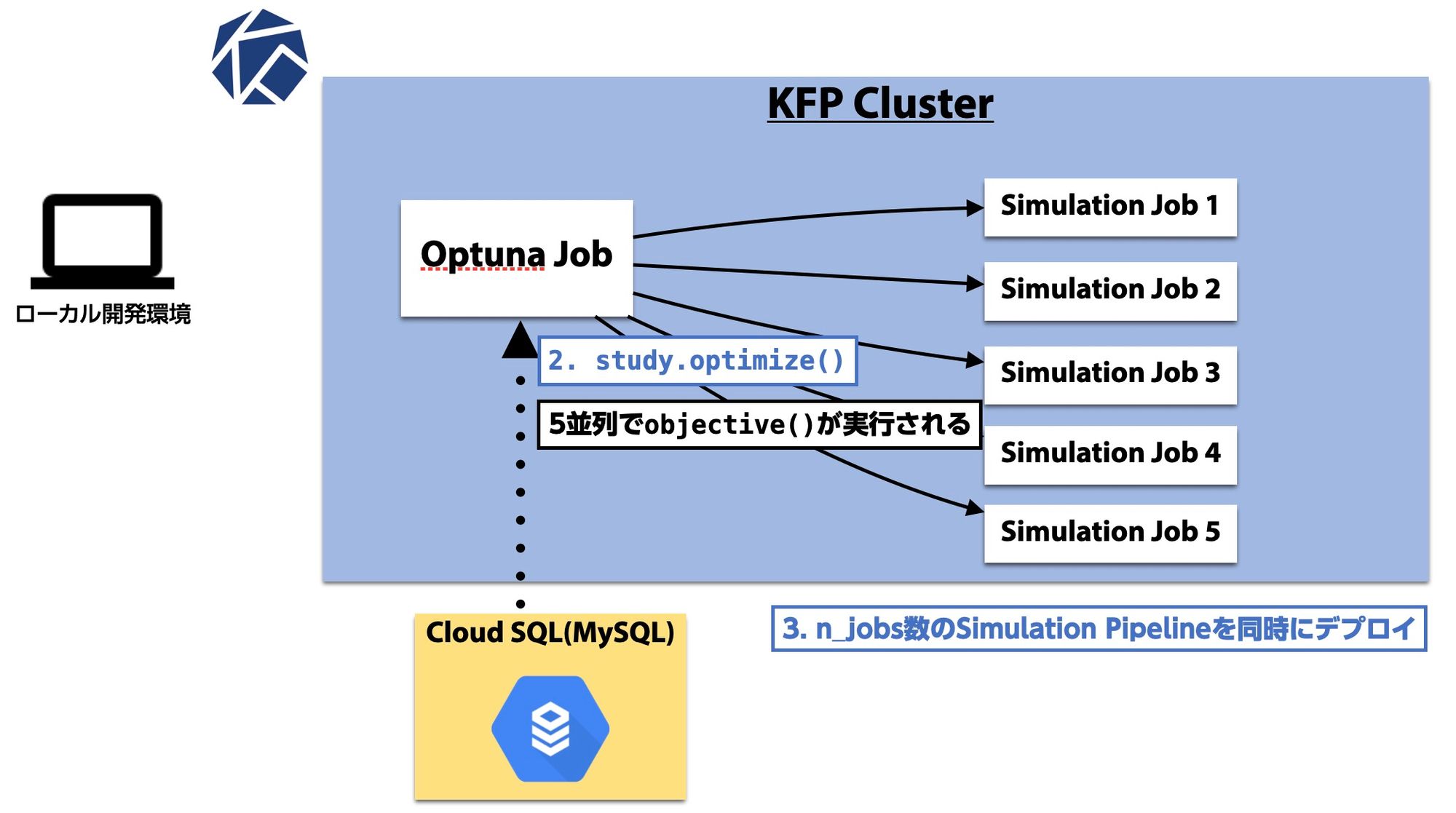
今回は並列実行数を5に設定したので、 study.optimize() を実行すると5つのスレッドで並列に目的関数の中の処理が実行されます。
目的関数では先程の方針で決めたように「新たにSuggestされたValue Iteratorのパラメータを用いてシミュレーションパイプラインをKFPにデプロイし、営収を集計する」処理がなされます。
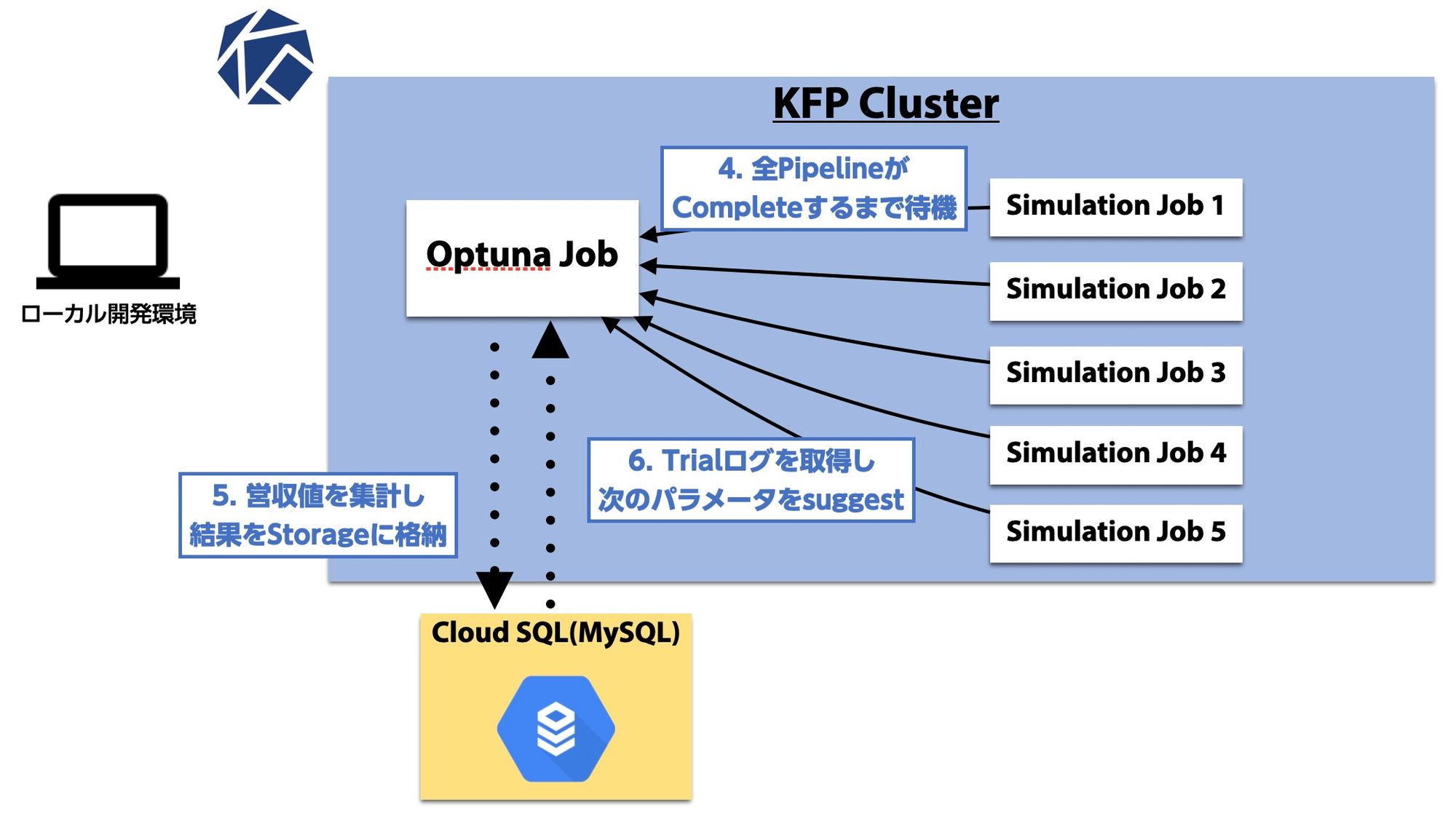
シミュレーションが完了するまでは各スレッドで待機することになります。
上の図では完了待機が5スレッドで同期しているようにも見えますが、実際にはスレッドごとにTrialを回しているので先にシミュレーションが完了したスレッドから次のステップへ進みます。
Trialが終わったら結果をStorageへ格納し(この辺りの処理はコードで意識しなくてよい)、次のTrialへと進みます。
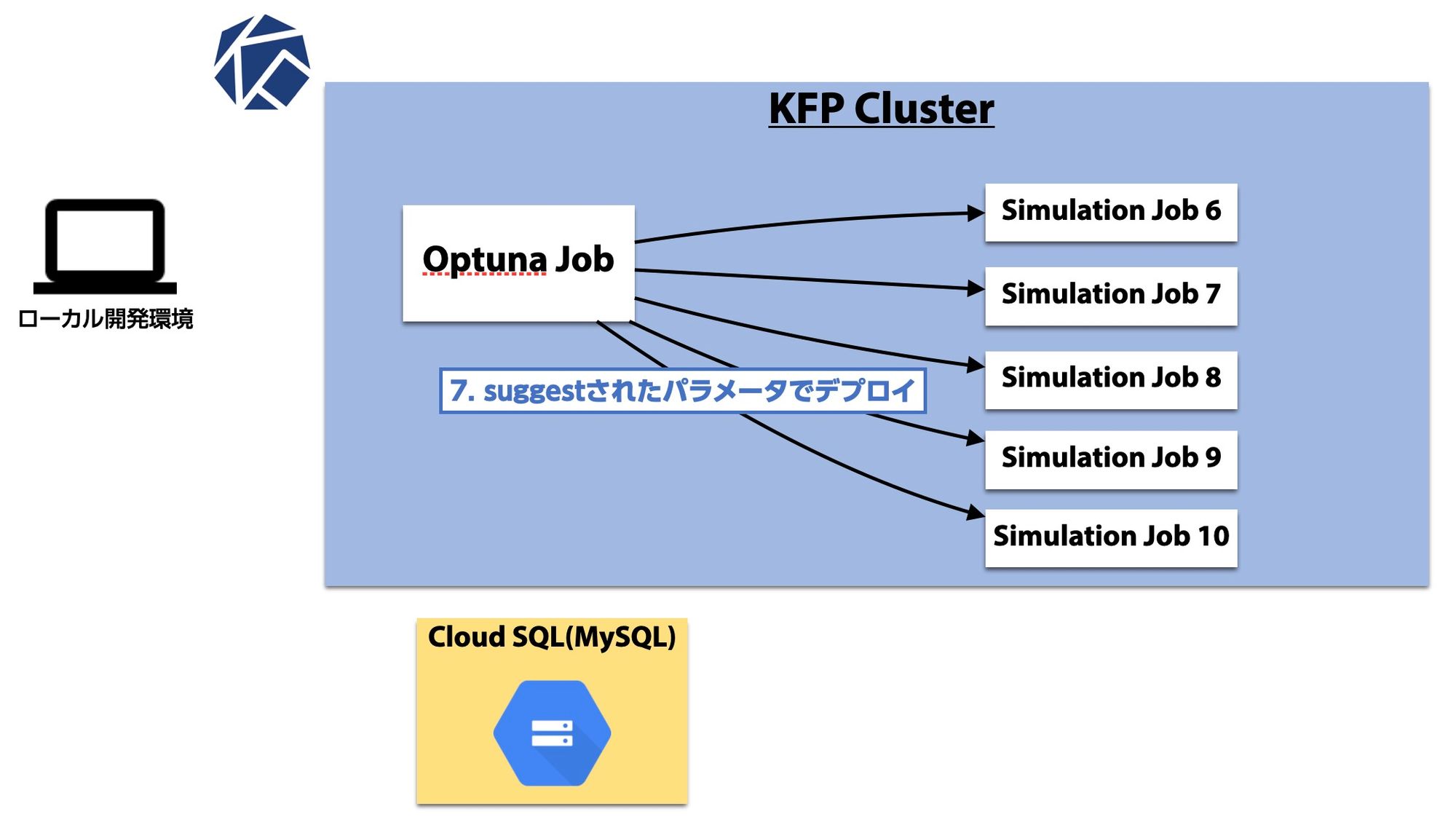
これまでのTrial(別スレッドのものも含む)情報から新たなパラメータをSuggestします。
これ以降はスレッドごとにこの流れを繰り返し、パフォーマンスすなわちシミュレーション営収が収束するまで続けます。
RDBStorage を用いているため、もし100回の試行が終わっても収束していなさそうな場合は、 optuna.load_study() で途中から再開できます。
コードベースの解説
ここからは上のステップに沿って実際のコードを解説していきます。
まずはOptunaジョブをデプロイするためのKFPのコードから。
Optuna Jobのデプロイ
def deploy_optuna(c, comment=None):
code_id = deploy_settings(c, comment=task_name)
resource_setting = format_resource_setting(
c.resource_setting,
settings["master_cpu"],
settings["master_memory"],
settings["master_node_pool"],
)
pipeline = wf.create_optuna_pipeline(code_id, optuna_settings, resource_setting)
wf.compile_pipeline(code_id, pipeline, pipeline_filename)
return wf.run_pipeline(code_id, user, pipeline_filename)あまり本質的でない部分も含んでいるため、重要な部分のみ解説していきます。
Optunaジョブのパイプライン自体の実装は wf.create_optuna_pipeline() メソッドにあり、この部分は後述します。
このメソッドでやっているのは作成したパイプラインをコンパイルし、 wf.run_pipeline() でKFPクラスタにデプロイすることだけです。
Optuna Job の KFP Pipeline Function
def create_optuna_pipeline(code_id, optuna_settings, resource_setting):
@kfp.dsl.pipeline(name=code_id)
def pipeline(config=json.dumps(optuna_settings)):
base_url = optuna_settings["base_url"]
msg = code_id + " is {{workflow.status}} " + base_url + "/{{workflow.uid}}"
exit_task = create_slack_notification_op(msg)
with dsl.ExitHandler(exit_task):
create_optuna_op(
code_id, optuna_settings, {"USER": "optuna-worker"}, resource_setting
)
return pipeline先程の wf.create_optuna_pipeline() の中身です。
KFPでは @kfp.dsl.pipeline デコレータを用いることでパイプライン関数を定義できます。
dsl.ExitHandler() にSlack通知処理を行うOperator(タスクの単位)を指定することで、成功失敗問わずジョブ終了時にSlackで通知しています。
肝心のOptunaを実行するタスクのOperatorは create_optuna_op() 以下で、次のステップで説明します。
Optuna Job の KFP Operator
def create_optuna_op(sim_id, optuna_settings, env_params, resource_setting):
command = ["inv", "run-optuna"]
arguments = [f"--settings={json.dumps(optuna_settings)}"]
op = dsl.ContainerOp(
name="optuna",
image=optuna_settings["image"],
command=command,
arguments=arguments,
file_outputs={"mlpipeline-ui-metadata": "/tmp/mlpipeline-ui-metadata.json"},
)
for k, v in env_params.items():
op.container.add_env_variable(V1EnvVar(name=k, value=v))
op = set_op_resource(op, resource_setting)
sidecar = kfp.dsl.Sidecar(
name="cloudsqlproxy",
image="gcr.io/cloudsql-docker/gce-proxy:1.14",
command=[
"/cloud_sql_proxy",
"-instances=dena-dummy-dev-gcp:us-central1:optuna=tcp:3306",
],
)
op.add_sidecar(sidecar)
return opcreate_optuna_op() では、Optunaジョブを実行するContainer Operatorを生成しています。
タスクはコンテナ単位で実行されるため、ここで任意のDocker Imageを指定しKFP上にデプロイします。
なお、Container OperatorにはSidecar Containerを指定することもできます。
今回はRDBStorageとしてCloudSQL上のMySQLサーバに接続する必要があるため、GCP公式の gcr.io/cloudsql-docker/gce-proxy を指定しました。
チューニング実行処理はOperatorに渡すImageに閉じ込めています。
Optuna Jobでのチューニング実行
def run_optuna(c, study_name="optuna", settings=None, comment=None):
study = optuna.create_study(
direction="maximize",
study_name=study_name,
storage=settings["study_storage"],
load_if_exists=True,
)
study.optimize(
create_objective(settings, study_name),
n_trials=settings["max_n_trials"],
n_jobs=settings["n_jobs"],
catch=(kfp_server_api.rest.ApiException, exceptions.UnexpectedExit),
)Operatorで実行されるコンテナではまずこのメソッドが実行されます。
やっていることはチュートリアルで提示したコードと全く同じです。
補足するとすれば、 create_study() の引数でStorageの接続先を指定していますが、フォーマットは mysql+pymysql://{user}:{password}@localhost/{cloudsql_datasetname} のようにすればOKです。
SidecarでCloudSQL Proxyを通じてGCP上のMySQLサーバに接続することができます。
ちなみに load_if_exists は既に同じIDのStudyがStorage上に存在する場合、新たにStudyを生成せずに既存のものを再開するための引数です。
最後に目的関数の中身で、1試行ごとに行われる処理を見ていきます。
目的関数
def create_objective(optuna_settings, study_name):
def objective(trial):
for k, v in optuna_settings["parameters"].items():
csv_args[k] = getattr(trial, v["distribution"])(
v["name"], v["min_value"], v["max_value"]
)
csv_path = f"{study_name}_{trial.trial_id}.csv"
make_setting_csv(csv_path, **csv_args)
completed_trials = len(
[
trial.state
for trial in trial.study.trials
if trial.state == optuna.structs.TrialState.COMPLETE
]
)
if completed_trials >= settings["n_trials"]:
print("Number of completed trials:", str(completed_trials))
print("Best trial:", trial.study.best_trial)
return
code_id, pipeline_filename = run(
c,
csv_path=csv_path,
days=settings["days"],
memory=settings[“worker_memory"],
build_only=True,
)
run_result = wf.run_pipeline(code_id, user, pipeline_filename)
run_name = wf.wait_for_simulation_completion(run_result)
bqla = BigQueryLogAnalyzer(run_name)
summary, metrics_cols = bqla.create_summary(
cost_table=settings["cost_table"]
)
summary_mean = summary.groupby("config_id")[metrics_cols].mean()
return float(summary_mean.revenue)まずValue Iteratorで最適化したいパラメータは複数あり、種類によって使いたいDistributionが異なっていたため、 getattr() を用いてパラメータごとに分布と探索範囲を定めてSuggestしています。
パラメータごとの分布や探索範囲はConfigファイルに事前に持っておきます。
次に study object から既に正常に完了した trial の数を集計し、最大試行数を超えていないかを確認します。
稀にシミュレーションの完了待機に失敗するケースがあり、単純な len(trials) では正確な完了数が分かりません。そのため、ここではイレギュラーな対応をしています。
こうした処理は、 study.optimize() の引数に指定するCallback関数を使っても実装できます。具体的にはCallback関数内で完了数を調べ、もし最大試行数に達していれば study.stop() で最適化を止めます。
run() はシミュレーションのパイプライン(Operators)を生成し、KFPにデプロイする処理です。
この部分は既存のものをそのまま用いているため解説は省きますが、シミュレーション項で述べたようなパイプラインを生成しているだけです。
最後にOptunaジョブのデプロイ時とは違い、 run_pipeline() 後にシミュレーションが完了するのを待機する処理があり、完了後に営収を集計して return しています。
以上が1回のTrialで行われる処理になります。
❌ NotionAPIでサポートされていないtypeが使用されています
比較評価
ここまで解説してきたフローを用いてチューニングをし、パフォーマンスが収束していそうであればパラメータの比較評価に移ります。
今回はチューニングされた新パラメータと旧パラメータのパフォーマンス比較を行う際、以下の流れを踏みました。
- シミュレーションは7日1セットなので、モデルを固定して 2019/10/1-2019/10/7 の期間でチューニングを行った
- チューニングされたパラメータが上記の1週間のみに適応していないことを確かめるため、 2019/10/8-2020/2/29 の期間で新旧パラメータ両方を用いてシミュレーションを行い、営収を比較した
- なおシミュレーションで用いる需要・供給値はモデル予測値・統計値両方を用いた(実際の運用でもモデル予測値だけでなく統計値を用いる場合がある)
比較ではシミュレーションにおいて、モデル予測値を用いた場合は1.4%、統計値を用いた場合は2.2%の営収改善が確認されました。
その後QAを行い、実際に引かれている経路にも問題がないということで、新パラメータの本番リリースまで至りました。
結局Optunaを用いた並列チューニングによって、アルゴリズムチーム側の改善施策が上手くハマった場合と同等の上がり幅を達成することができました。
Optunaの使いやすさ
先に述べたように、パラメータの比較評価では乗務員さんの営収がシミュレーション上で2%以上の改善を達成しました。
このパラメータは既に本番リリース済みで、現在の『お客様探索ナビ』では新パラメータに基づいた経路が引かれています。
実際に利用した乗務員さんの営収をリリース前後で比較まではしていないので、「実際に乗務員さんの営収が改善した!」とは発表できないのが惜しいところです(時期・時間帯・運などによっても左右されるため、実世界での比較が難しいという課題もあります)。
Optunaを実運用プロダクトで使ってみた感想をざっと箇条書きにするとこんな感じです。
- インターフェイスが直感的で、並列分散化のハードルが低い
- 試行部分を「パラメータを受け取り、結果を返す」というブラックボックスとして扱えるため、実装が複雑になりにくい
- 処理は目的関数に閉じ込めれば良いため、既存のシミュレーションの実行コードを手間なく利用することができた
- SDKが何気に便利
- StudyやTrialのObjectに欲しい情報が大体入っており、目的関数内の細かい処理や、チューニング後の分析がやりやすい
- 以上の理由から、学習コストが低い
- (実際に使い込んではいないが)カスタム性が高い
シンプルに書けることや学習コストの低さを推しましたが、但し書きとして、今回はシミュレーションが元々KFPパイプラインとして実装されていたために、KFPジョブが二重でデプロイされるという構成になっており、少々分かりづらいかもしれません。
この構成については当初「もっといい感じにできないか」と考えてはいたのですが、「むしろチューニングとシミュレーションが完全に疎結合になっていることが分かって良い」という意見も何人かから頂いたため、方針を変えず今に至ります。
まとめると、総じて理解しやすく実装しやすい設計になっていると感じ、学習にほとんど時間を掛けることなく実装に取り掛かることができました。
プロダクトに組み込む際のポイント
今回のケースでは、
- プロダクトの性質上、複数のモデルを作る可能性が高く、またモデルごとに最適パラメータが異なる可能性がある
- 時間経過によってもモデルの最適パラメータが異なる可能性がある
と、定期的な並列ハイパラチューニングを組むことのメリットが大きい状態でした。
こういった条件が揃っていたため、KFPを用いてチューニングフローを並列化・自動化し、定期的なチューニングの労力を出来る限り減らすように構築しました。
前述したようにOptunaではチューニングが必要な部分のロジックを「パラメータを受け取り、結果を返す」というブラックボックスとして扱えるため、既存のコードを疎結合にすることはそれほど難しくないように思います。
今回はあまり一般的でないユースケースであり、かつ条件が揃っていたためある程度手間をかけて自動化しましたが、一方で一般的なMLモデル学習のユースケースでは、例えば実験用インスタンス上で直列チューニングを実行するためにOptunaを試してみるだけでも十分メリットは享受できると感じます。
純粋に精度を上げたいモデルがあり、ハイパラチューニングを一回きりで直列に実行する。比較評価で精度が上がったら、今後はそのパラメータを採用する。といったような使い方ももちろん可能だと思います。
まとめると、何のハイパラをチューニングするかに依らず、一般的な流れとしては以下のようになるはずです。
- 入力(パラメータ)と出力(最適化したい値)を定める
- パラメータが数多くある場合、まずは3つなど少数から試してみるのもアリ
- 本当にチューニング対象としてよいパラメータかを確かめる
- ものによっては意味がないパラメータもある。今回も幾つか除外した
- チューニング部分を実装する。実験ロジックとは疎結合にできれば嬉しい
- 一例として、今回のようにKFPのExperiments Pipelineに実験を閉じ込める
- 入力を与え、出力を取得することさえ出来ればいい
- パラメータの数にも依るが、適当なTrial数を決め、収束するまでチューニングを回してみる。
- StudyをLoadすれば途中から再開もできるので、100→150→200と増やしていける
- 収束していそうなら、比較実験を行う
- 今回のケースでは「チューニング対象でない期間」でシミュレーションを行い、営収の上がり幅を確認した
- MLモデル学習のケースでは、チューニングはValidation AccuracyもしくはLossを対象として行い、チューニング後にTestデータでの精度を見るなど
- 比較実験の結果、チューニングされたパラメータを採用するかどうか決める
おわりに
少々長くなりましたが、以上になります。
KFPは元々シミュレーションで用いていたものも延長というのが大きいですが、Optunaは今回初めて導入しました。
再三書いたとおり、直感的なインターフェイス、必要十分なSDK、シンプルに書ける設計は大変使いやすかったです。
まだやれていないのですが、今回のように時間が経ってから再チューニングする意義がある場合は、定期的なチューニングパイプラインとしてスケジューリングしてしまい、上述の比較実験(別の期間での評価など)も合わせて自動化してしまうと尚更楽になりますね。
少しでもこの記事を読まれた方の参考になれば嬉しいです。では。