

Neovim v0.5リリース記念 v0.5の新機能を紹介します【後編】
エディタ前回はNeovimにLuaランタイムが組込みされた事によりNeovimのプラグインのエコシステムに大きな変化が起こったことを書きました。 後編ではNeovim v0.5から追加された大きな新機能であるTree-sitterとLSPクライアントについて解説してきます。この2つの機能はどちらもLuaで実装されており、Neovim v0.5以降のLuaランタイムが組込みされたNeovimでのみ動作します。 もし前編をご覧になっていなければ、前編のあとに後編をご覧になったほうが、より理解が深まると思いますので、時間に余裕があればぜひご一読ください。
Neovim v0.5リリース記念 v0.5の新機能を紹介します【前編】
Treesitter syntax engine
Neovim v0.5ではTree-sitterというライブラリが組込みされています。 Tree-sitterを用いる事により、Neovimがパースされたプログラムの構文を取得することが可能になりました。その恩恵としてNeovimはより細やかなシンタックスハイライトを表示できるようになり、Tree-sitterにより解析された構文をプラグインから取得することで、拡張されたテキストオブジェクトなど新たなプラグインの可能性を生み出しました。
Tree-sitterによるSyntax Highlihgt
シンプルにTree-sitterの力を示したいと思います。以下をご覧ください。
- 左がTree-sitterを活用したSyntax Highlihgt
- 右が従来のSyntax Highlihgt
ドット演算子で区切られた構造体と要素など細かいところまで別々にハイライトされていることがわかります。 なおカラースキーマはTree-sitterの利用を前提としたnvcodeというテーマを使用しています。私の最近のお気に入りのテーマです。
もともとVimのシンタックスハイライトは正規表現で処理されており、その処理に付随する実行速度の遅さやシンタックスファイルの記述や正確なシンタックスの実装が難しいことは問題になっていました。 参考までにTypeScriptのsyntaxを解析する正規表現を見てみると、なんとなく複雑なことをことがわかるのではないでしょうか?
シンタックスハイライトの処理とは、開いているソースコードに記述された各文字列が、プログラムの構造上どの属性を指しているかを判定し、その属性に応じた色をつけるという処理です。以前のNeovimではその属性を判定する手法として正規表現を用いてきました。Tree-sitterはこれまで正規表現でやっていた解析処理を担う事になります。 具体的にGoのソースコードをTree-sitterで解析した結果を以下に示します。
package main
import "fmt"
func main() {
fmt.Println("hello world")
}
package_clause [0, 0] - [0, 12]
package_identifier [0, 8] - [0, 12]
import_declaration [2, 0] - [2, 12]
import_spec [2, 7] - [2, 12]
path: interpreted_string_literal [2, 7] - [2, 12]
function_declaration [4, 0] - [6, 1]
name: identifier [4, 5] - [4, 9]
parameters: parameter_list [4, 9] - [4, 11]
body: block [4, 12] - [6, 1]
call_expression [5, 1] - [5, 27]
function: selector_expression [5, 1] - [5, 12]
operand: identifier [5, 1] - [5, 4]
field: field_identifier [5, 5] - [5, 12]
arguments: argument_list [5, 12] - [5, 27]
interpreted_string_literal [5, 13] - [5, 26]
なおAtomではNeovimに先んじてTree-sitterを利用したシンタックスハイライトおよびコード折りたたみが適用されています。
参考
Vimの正規表現とNeovimのTreesitter採用について、より詳しく書かれている方がいらっしゃったので紹介しておきます。
Tree-sitterとは何か、なぜNeovimに組込むのか
※ ここはそこまで本筋に関係ないので、読み飛ばしても大丈夫です。
Tree-sitterとは何か、なぜNeovimに組込みがされたのかについて少し詳しく見てみましょう。Tree-sitterのドキュメント冒頭には以下のように説明されています。
Tree-sitter is a parser generator tool and an incremental parsing library. It can build a concrete syntax tree for a source file and efficiently update the syntax tree as the source file is edited.
翻訳するとこうなります
Tree-sitterは、パーサージェネレータツールであり、漸進的分析(Incremental Parsing)ライブラリです。ソースファイルの具体的な構文木を構築し、ソースファイルが編集されると構文木を効率的に更新することができます。
読んでもあまり意味がわかりませんね。私も読んだ当初はよくわかりませんでした。
こういうときは順番に用語を読み解いていきましょう。まずパースを実行するパーサー(構文解析器)についてです。プログラムを解析/実行するためのコンパイラやインタプリタはプログラムの構文を解析するための機能を持っているのですが、一般的にこの解析は以下の流れで行われます。(細かいことは割愛しています)
- 字句解析器: プログラムをトークン列に変換する
- 構文解析器: トークン列を構文木に変換する
- 評価器: 構文木を評価しプログラムの結果を導き出す。またはバイトコードを生成する
このうちTree-sitterは1.字句解析器(レキサー)と2.構文解析器(パーサー)の役割を担います。ソースコードを入力に受け取り、構文木に変換するプログラムなわけですね。
このTree-sitterのパーサーはTree-sitter playgroundにアクセスすると気軽に試すことができます。先程例示した解析結果もこちらで実行したものです。またNeovim上で同様のことがnvim-treesitter/playgroundを導入すると編集しながらリアルタイムで実行できます。
レキサーおよびパーサーですが、解析対象となるプログラミング言語毎に分ける必要性があります。解析対象の構文自体が違うからです。しかしパーサーの作成は非常に大変な作業です。そこでTree-sitterがパーサージェネレータツールであるという点に注目しましょう。 パーサージェネレータとは何らかの形式的記述(DSL)を受け取り、パーサーを出力するツールのことです。Tree-sitter以外ではyaccやbisonなどが例として挙げられます。
Tree-sitterのドキュメントのパーサー作成ガイドを見るとTree-sitterを使ったパーサーの作成方法が記載されています。このドキュメントを基にtree-sitter-goを調べてみました。 Tree-sitterのパーサージェレレータに読み込ませるDSLはJavaScriptでgrammar.jsのような形で記述し、その結果として出力されるパーサーはCのソースとして出力されるようです。実際にNeovimから実行するのはCのソースになります。 生成用のCLIコマンドはRustで実装されており、npm経由でインストールするようですね。
さてここまでの話を踏まえてTree-sitterのREADMEに書かれた以下の記述を見るとTree-sitterがどうテキストエディタの構文解析機能として取り込むのに適した特性を持っているかがわかります。
- General enough to parse any programming language
- Fast enough to parse on every keystroke in a text editor
- Robust enough to provide useful results even in the presence of syntax errors
- Dependency-free so that the runtime library (which is written in pure C) can be embedded in any application
つまりエディタで編集するような様々なファイル形式に対してtreesitter一つでパーサーを作成が可能になり。 各言語を静的解析するパーサーはその目的(エラー検知や依存系解決など)から処理に時間がかかるが、Tree-sittterはその用途がシンタックスハイライトなどに限定されているがゆえに、テキストエディタで編集する都度にパース処理を走らせても問題ないほどに高速に動作する。更に漸進的分析(Incremental Parsing)を行うことで編集中の文法エラーを含むソースコードであっても問題なく読み飛ばせる。C言語で作成されたランタイムさえ組み込めば動作する。というわけです。
Tree-sitterについてより詳しく知りたい人は『Tree-sitter: a new parsing system for programming tools - GitHub Universe 2017』の動画をご覧になると良いかと思います。
NeovimからTree-sitterを利用する
NeovimからTree-sitterのランタイムを制御するためのコードは本体に組込みされており、Tree-sitterの構文木などにはAPI(:h treesitter)を経由でアクセスすることができますが、前述したとおり、パースを実行するためのパーサーは別で用意されているため、Neovim単体ではTree-sitterを利用できません。
パーサーのインストールなどを制御するプラグインはnvim-treesitter/nvim-treesitterとして分離されており、このプラグインを経由して各言語のパーサーをダウンロード/インストールすることでTree-sitterを利用できます。 nvim-treesitterを以下の設定で導入すると、各言語ごとのパーサーを自動でインストールします。
Plug 'nvim-treesitter/nvim-treesitter', {'do': ':TSUpdate'}
lua <<EOF
require'nvim-treesitter.configs'.setup {
ensure_installed = "maintained",
highlight = {
enable = true,
},
}
EOF
Tree-sitterの構文木を活用するプラグイン
Tree-sitterがNeovimにもたらした恩恵はシンタックスハイライトだけではありません。Neovimがソースコードの構文木を取得できるようになったことで、ソースコードの構造を利用したプラグインが生まれるようになりました。Tree-sitterに関連したNeovimのプラグインはnvim-treesitterというGitHub Organizationにまとめられています。
Tree-sitterの構文木を用いた自動補完やリファクタリングなど、用途は様々ですが、私が特にNeovimとTree-sitterのシナジーを感じているのはテキストオブジェクトです。 テキストオブジェクトは、他のエディタにはないVimのモードの概念がもたらした、Vimの特徴的な機能の一つです。
Vimのノーマルモード時のキーバインドには種類がありオペレータ(:h operator)とモーション(:h motion.txt)という分類があります。 オペレータは文字どおりテキストに対する操作で、モーションはjhjkなどの移動です。これらを組み合わせることで、Vimはノーマルモード時に他のエディタではできないような柔軟な操作を行うことができます。
テキストオブジェクト(:h text-objects)とはオペレータを入力したあとに実行できる特殊コマンドで、これを実行することでオペレータによる操作の範囲を柔軟に指定できます。 私がよく利用するのがiw(inner word)です。これは操作対象が文字列になりますdiwなら単語単位の削除、ciwなら単語単位で削除したあとにインサートモードになります。他にはdi"やci"といったダブルクォートで囲われた文字列に対する操作などができます。たとえばエラーメッセージを書き換えたいときなどに便利です。
デフォルトのVimの状態でもテキストオブジェクトはかなり有用ですが、これはプラグインで拡張できます。たとえば以下のような拡張テキストオブジェクトのプラグインを導入すると、より便利なテキストオブジェクトが使えます。
私が普段利用しているvim-sandwichではsaiw(でカーソル直下のワードを括弧でくくったり、sr"'でダブルクォートで囲われた文字列を、シングルクォートに置き換えたりという編集をすばやく行うことができます。
ここからが本題です。Tree-sitterとテキストオブジェクトを組み合わせることで、この拡張テキストオブジェクトでプログラムの構造を指定することが可能になりました。 この機能をNeovimに追加するためのプラグインがnvim-treesitter-textobjectsです。nvim-treesitter-textobjectsを導入することで、構文木をオペレータとして活用できます。
いくつかの例をご紹介しましょう。
関数の選択
lua <<EOF
require'nvim-treesitter.configs'.setup {
textobjects = {
select = {
enable = true,
lookahead = true,
keymaps = {
["af"] = "@function.outer",
["if"] = "@function.inner",
["ac"] = "@class.outer",
["ic"] = "@class.inner",
},
},
},
}
EOF
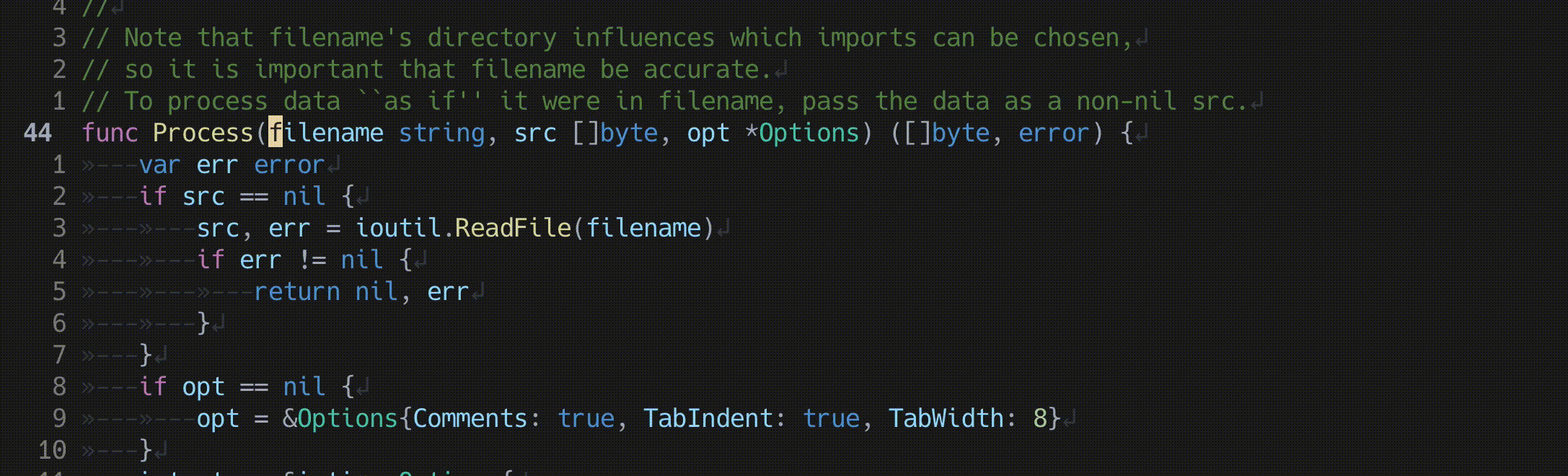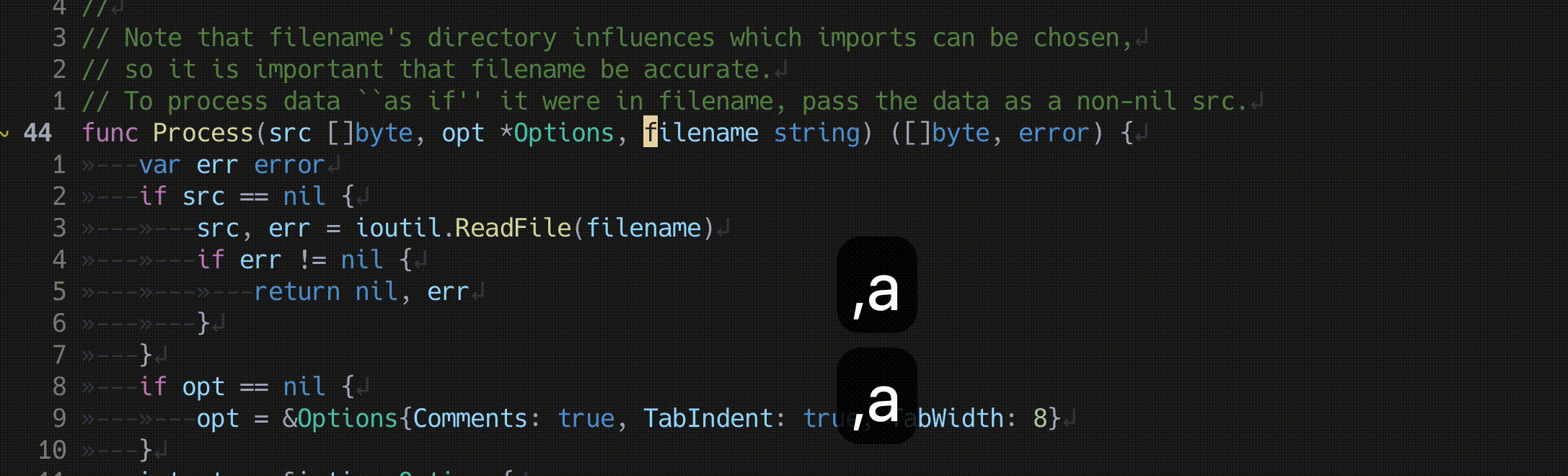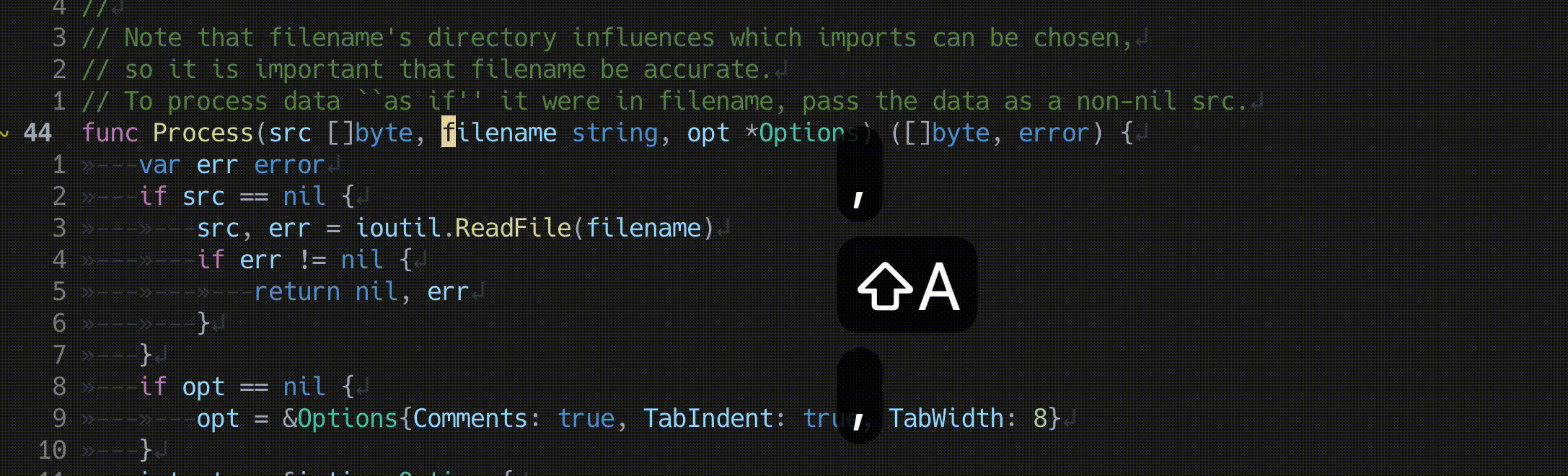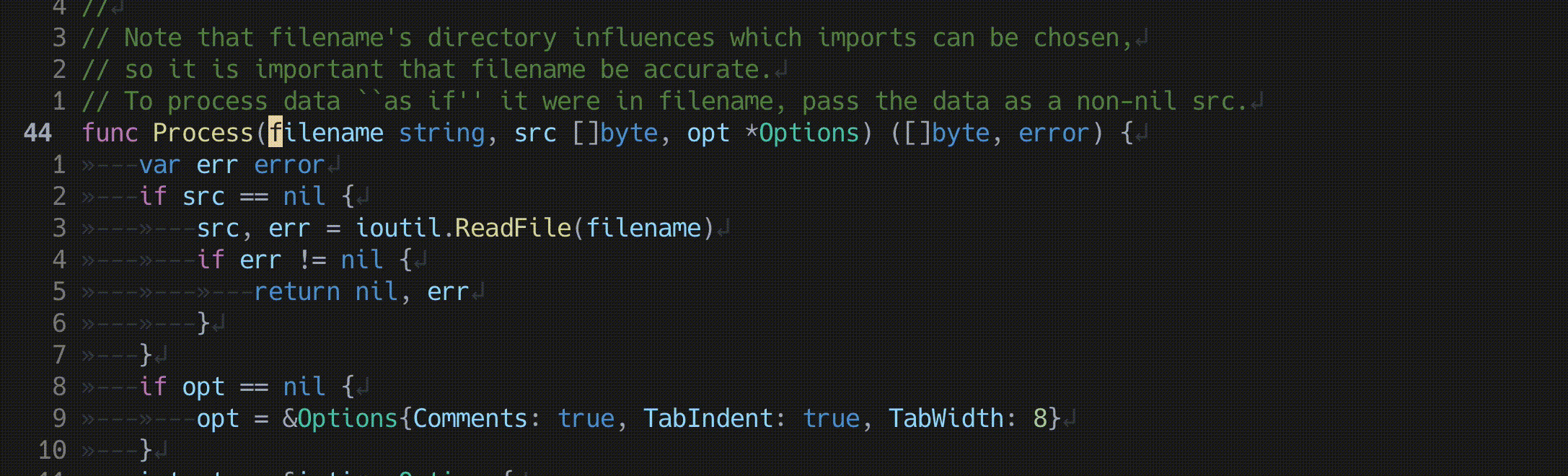
関数の引数の入れ替え
lua <<EOF
require'nvim-treesitter.configs'.setup {
textobjects = {
swap = {
enable = true,
swap_next = {
["<leader>a"] = "@parameter.inner",
},
swap_previous = {
["<leader>A"] = "@parameter.inner",
},
},
},
}
EOF
前後の関数間の移動
lua <<EOF
require'nvim-treesitter.configs'.setup {
textobjects = {
move = {
enable = true,
set_jumps = true, -- whether to set jumps in the jumplist
goto_next_start = {
["]m"] = "@function.outer",
["]]"] = "@class.outer",
},
goto_next_end = {
["]M"] = "@function.outer",
["]["] = "@class.outer",
},
goto_previous_start = {
["[m"] = "@function.outer",
["[["] = "@class.outer",
},
goto_previous_end = {
["[M"] = "@function.outer",
["[]"] = "@class.outer",
},
},
},
}
EOF
vim-goの拡張テキストオブジェクト
上記のようなプログラムの構造に対してテキストオブジェクトで指定するプラグインはすでにありました。vim-goの拡張テキストオブジェクトはmotionというGolangの静的解析ツールを用いることでこれを実現しています。 しかしこの機能はGolangのみで利用可能だったため、もしこの拡張テキストオブジェクトがすべての言語で利用できたならば、素晴らしい開発体験に違いないと考えていました。そしてそれは今実現されています。
LSP client
LSP client for code navigation, refactoring
Neovim v0.5にはビルドインされたLSP(Language Server Protocol)クライアント(以下nvim-lspと呼びます)が追加されました。
プログラミングをする上でエディタから提供されるインテリセンスは生産性に大きな影響を与えます。自動補完や定義ジャンプ、Linterを自動実行してエラー箇所を表示するDiagnosticsなどの機能の恩恵を受けている開発者は多いことでしょう。 LSP(Language Server Protocol)はそれらのプログラミング言語のインテリセンスを提供するサーバー、サーバーと通信するクライアント間の通信を標準化したプロトコルで、Microsoftにより策定されました。 最近ではJetBlainsなどの有償のIDEを除いて、テキストエディタのインテリセンスの多くはLSPを実装したLanguage Serverによって提供されています。 余談ですが私もSQLのLanguage Serverのsqlsの開発者だったりします。
LSPクライアントのVimプラグインもその重要性の高さから、活発に開発が行われており、nvim-lspと平行して以下のようなLSPクライアントが開発されてきました。coc.nvimは導入するとVimがIDEに変わったかのようにリッチな機能が提供されることで話題となり、とても人気があります。
nvim-lspがNeovimのStableビルドとしてリリースされたことで、現在も熾烈な競争を繰り広げているLSPクライアントというジャンルに、協力なライバルが参入することになります。
nvim-lspの利用方法
nvim-lspを利用するためにはNeovim v0.5に加えて、各言語のLanguage Serverの設定集であるnvim-lspconfigが必要になります。利用開始方法についても同リポジトリのREADMEに記載されています。ただし導入にあたり2点注意点があります。
1点目はLSPクライアントが呼び出すLanguage Serverは個別でダウンロードする必要があります。インストールを支援するためにvim-lspでいうvim-lsp-settingsのような、Language Serverの管理ツールもいくつか存在するため、活用すると良いでしょう。
もう1点はIDEに一般的な備わっている自動補完はnvim-lspに含まれていないため、別途プラグインの導入が必要になる点です。現状nvim-lspに対応している自動補完プラグインでは、Wikiで紹介されているnvim-compeが有力な候補になります。
nvim-lspとほかのLSPクライアントの比較
LSPという仕様が普及してきた現在、Vim/Neovimで動作するLSPクライアントはnvim-lsp以外にもすでにいくつかあるのは前述した通りです。これらのLSPクライアントの中で、nvim-lspを使うメリットは何かについても少し考えていきたいと思います。 しかし今現在どのLSPクライアントであっても極端な開発体験の差はないという前提で見ていただけると助かります。
個人的にnvim-lspで注目したいのは速度と外部プラグインから利用可能なLSPのAPI(:h lsp-api)です。
速度はnvim-lspがLuaによって実装されていることで、Vim scriptで実装されたLSPクライアントよりも、プログラム実行速度が優位であるのは間違いないと思います。場合によって膨大な処理を行う必要があるLSPクライアントならば恩恵はより大きなものになるでしょう。しかし私達の体感的な速度は言語の実行速度だけで決定しません。ほかの要素でVim script実装のLSPクライアントよりnvim-lspが遅くなることはあり得ることだと思います。 また何度も申し上げている通り、nvim-lspがLuaで実装されている関係上Neovim v0.5以降でしか動作しないためVimでは使えません。これは明確なデメリットですが、Neovimをメインで利用する限りにおいてはデメリットにはなりません。
Language Serverがソースコードを解析した結果はlsp-apiにより容易に取得することができます。たとえばvim.lsp.diagnostic.get()を利用することでLanguage ServerのDiagnosticsの結果を受け取れます。これはプラグイン開発者にとってはとても良いニュースです。
なぜかというと、最近のVimプラグインは単体で動作せず、ほかのプラグインの機能を利用または拡張するプラグインが増えているからです。たとえば選択的インタラクティブフィルタであるfzfを利用したVimプラグインは相当の数があります。 情報Aを絞り込みするプラグインを作るときに、ゼロから選択的インタラクティブフィルタの実装をするよりも、情報Aを作ってすでにあるfzfなどに渡してフィルタしたほうが、簡単に目的を実現できるからです。
LSPクライアントから受け取れる情報は非常に価値が高く、それを利用したいというプラグインも多くあります。私の作っているdeoplete-vim-lspはまさにその典型でvim-lspから受け取った補完の情報をdeoplete.nvim流すという糊(のり)のようなプラグインです。こういったプラグインはその振る舞いからGule Pluginなどと呼ばれたりもします。
LSPクライアントの情報を使ったGlue Pluginを作りたい人は私以外にもたくさんいるはずです。そしてGlue Pluginの作者達は思います。ある程度の後方互換性が保証された、簡単にLSPクライアントの情報を取得できるAPIがあればよいのに。おっとあるじゃないですかlsp-apiが。
すでにnvim-lspの情報を利用したプラグインはすでにあり、どれもリッチなUIを備えた便利そうなものです。
このような違いが今後大きな開発体験の違いにつながるかもしれません。Neovim v0.5がリリースされたことで、nvim-lspに関連するプラグインの開発もより活発になることが予想されます。
まとめ
今回お伝えしたかったのは、Neovim v0.5のリリース内容は今後のNeovimのプラグインのエコシステムに大きな影響を与えるということでした。 Neovim本体へのLua組込みによるLua製プラグイン。そしてそれを活用したTree-sitterとnvim-lspなど、すべてが地続きになっているのは非常におもしろいですね。 一方で以前からVim界隈で、懸念されていたVimとNeovimの仕様の分離がより強くまた形になりました。
Vimは40年以上前に開発された歴史あるエディタですが、この数年だけみても驚くほどの進化を遂げています。NeovimやVimを知らない人や最新の動向を追っていなかった人に、いまこんなすごいことがおきているんだよと、少しでもお伝えできていれば幸いです。これからもNeovimやVimの進化に目が離せません。