

Kaggle のデータ分析コンペ Shopee - Price Match Guarantee で『10位 / 2,426チーム』を獲得しました
KaggleAI初めまして。MoTのAI技術開発部アルゴリズム第一グループの島越 [1]です。本ブログでは、私が最近ソロで10位を獲得したKaggleのコンペティション「Shopee - Price Match Guarantee」で行った取り組みについてと上位の手法について紹介したいと思います。なお、本記事で使用している画像は特に断りがない限り、上記コンペの画像を使用しております。
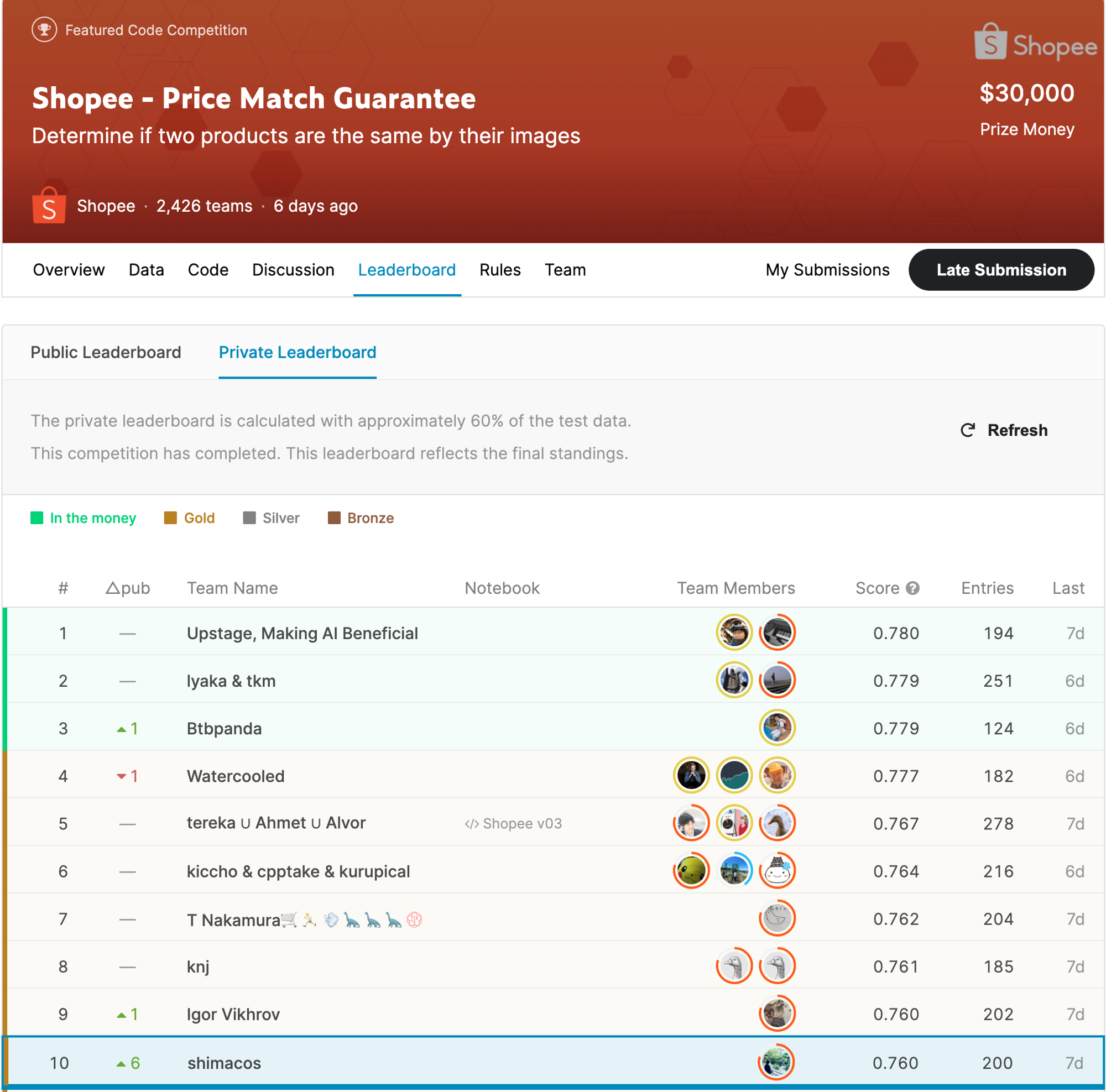
図1:最終順位発表後におけるShopee - Price Match GuaranteeのLeader Board
1. 本コンペについて
まず、今回のコンペがどのようなタスクを解く問題だったのかについてご紹介します。このコンペは、東南アジア最大級のECプラットフォームであるShopeeが開催したもので、データとしてはユーザが登録した商品画像と商品のタイトルが与えられます。また、ラベルとしてはユーザが登録した商品の種別が与えられています。このラベルは、ユーザが登録したものなので、ノイズが多く載っているものになっており、同じ画像や同じタイトルでも違うラベルがついていたりします。また、この種別というのは思った以上に細かく、同じ化粧品でも50mlのものと100mlのもので違うラベルになっていたりします。このようなユーザがつけたラベルを教師データとして、画像とタイトルのテキスト情報を用いて商品セットの中から同じ商品を抽出するモデルを作成することが今回のお題となっています。
評価指標としては、各商品毎のF1スコアとなっています。そのため、False PositiveやFalse Negativeの予測をどう減らすかや、「どの程度の予測値まで同じ商品とするか」という閾値をどう調整するかが重要な課題となっていました。また、各商品については50まで候補を提出することができ、50以上提出しても50でcapされることとなっていました。
また、今回のコンペはKaggle上のNotebookを用いて提出するコンペになっており、以下の様な制限がついていました。
- GPU:P100
- メモリ:13GB
- GPUを使用して推論時間が2hour以内
2. データ
再びの説明となりますが今回のコンペは、図2に示すようにデータセット全体の中からある商品に注目 (Query)したときに、どの商品が同じ商品かを予測する (Predict)するお題になっています。そのため、ある商品についての負例がとても多くなります。さらに、図3を見ると訓練データ内のほとんどが自分以外に1つや2つしか同じ商品がないことが分かります。
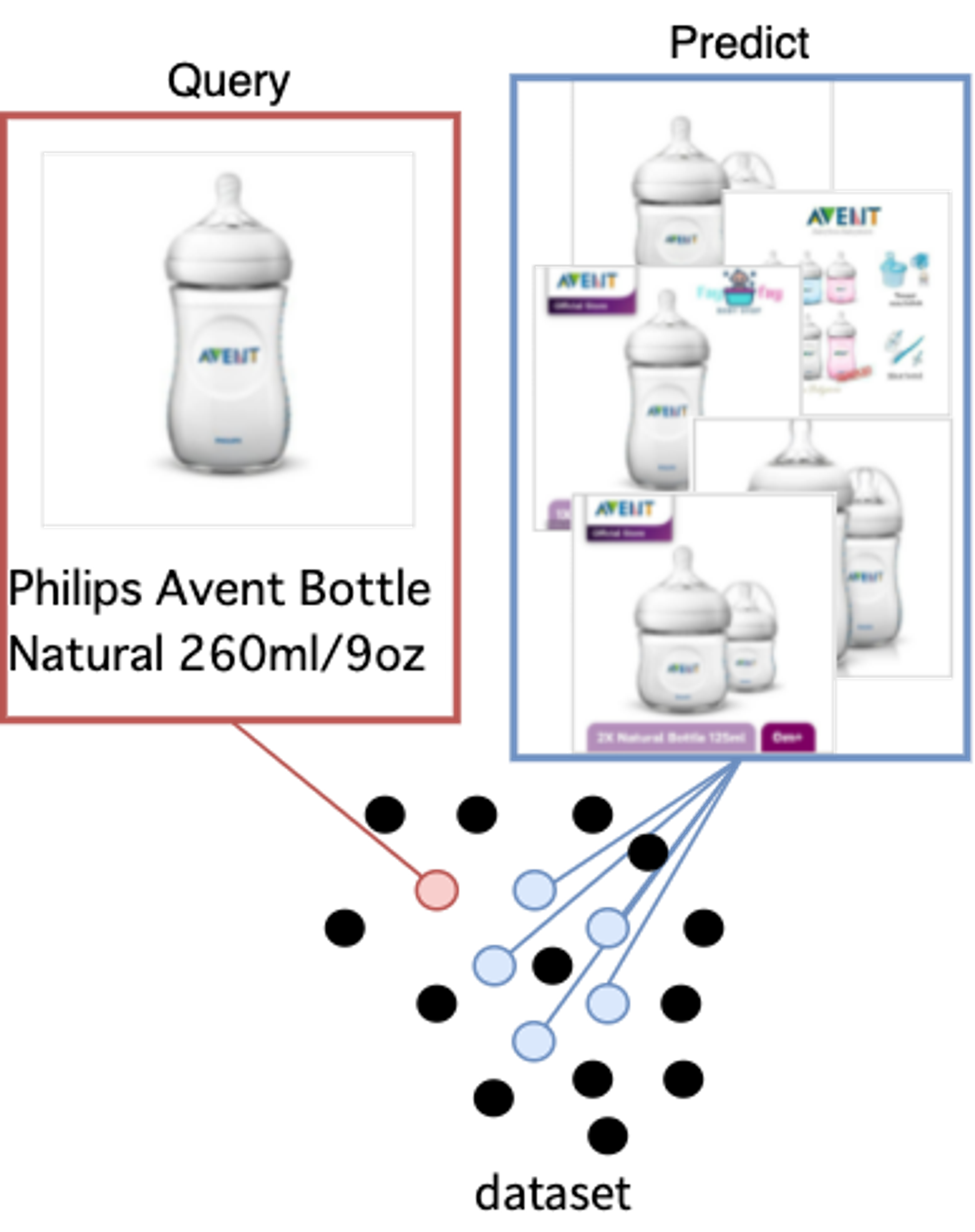
図2:コンペのタスクの概念図
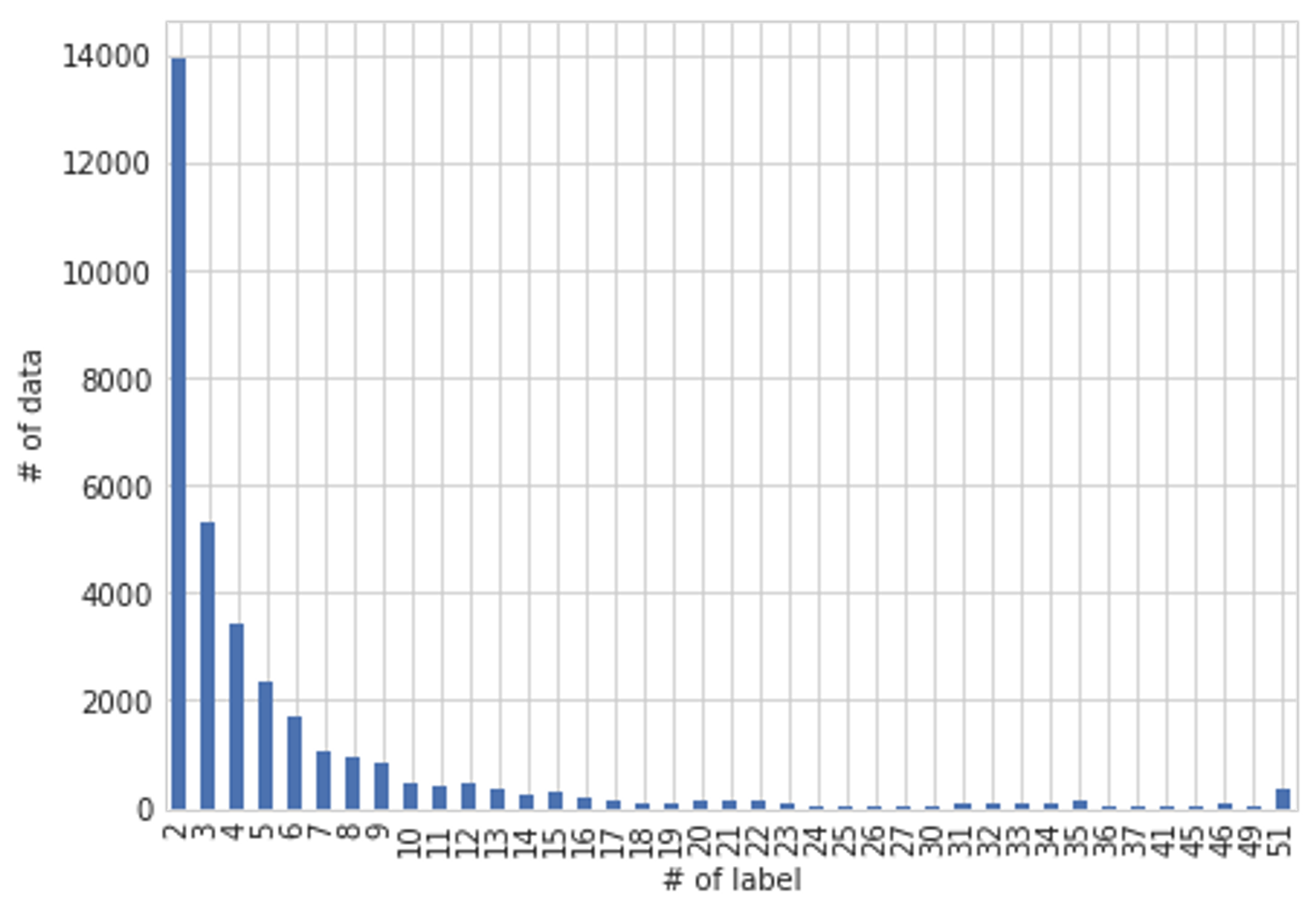
図3 : 同一商品数の分布
また、訓練データには34250件の商品が含まれていましたが、テストデータには70000件ほどの商品があるとホストから示唆されていました。また、序盤に参加者の分析によってテストデータの商品は訓練データに存在しないデータであることが示唆されていました。
以下にデータを見た上でのコンペの課題についてまとめます。
- 画像データとテキストデータが与えられた上で、それらをどう用いるか、どう組み合わせるか
- 同じ商品が2つしかないものが多く、それらをどう扱うか
- 訓練データとテストデータのサンプル数が異なり、それによって閾値の値が変わりそう
- テストデータは、恐らく訓練データとは異なる商品が大多数を占める
3. ベースライン
恐らく多くの参加者がMetric learning (距離学習)を用いた手法を行なっていたと思います。ここでは、Metric learningの詳細な説明は省きますが、CNNなどのNeural Networkの出力を1次元に集約したもの (Embedding)を同じClassのものは近づけて、違うClassのものは遠ざけるということを実現しようとする手法です。今回のコンペでは、最近のコンペでも有用性が多く報告されているArcFaceなどのSoftmaxベースの手法が多く用いられていました。ArcFaceについては、[2]の記事が非常に分かりやすいため、そちらを参照することをお勧めします。
ちなみにここでのCNNのことを画像全体から特徴を抽出する機構のため、Global Descriptorと呼んだり、CNNで抽出したEmbeddiingのことをGlobal Featureと呼んだりします。この辺りの画像検索における用語や歴史については、[3]の記事がわかりやすいと思います。
ベースラインとしては、多くのNotebookで行われているような
- 画像モデル:(何かしらのbackbone) + ArcFace
- テキストモデル: (BERT+ ArcFace) + TF-IDF
として予測をそれぞれ作成し、それらを組み合わせてユニークなものを予測するといったものが主流でした。今回のコンペでは、TF-IDFが割と強く初期に組み合わせるモデルとしては、BERTよりも有用でした。これは、訓練データ数が少ないということもあると思いますが、商品のマッチングだと細かい単語の違いなどが商品の違いに現れるため、単純にcountを取るTF-IDFが割と有用だったのではないかなと思います。しかし、多くの商品検索系の論文ではBERTの方が有用と言われていることから、問題設定や言語などが変わるとまた違う結果になるかもしれません。
4. 解法
以下の図は、私の解法の概略図となっています。今回のデータは画像とテキストデータ両方が与えられているため、それらのデータをどのように用いてどのように組み合わせるかも重要でした。私の場合は、以下の手順でシステムを構築しました。
- imageとtextのmodelを複数それぞれ学習させ、それらからEmbeddingを取得
- 1で抽出したEmbeddingを組み合わせたりしたものに対してQuery Expansion (QE)を行い、その結果に対してK近傍法 (KNN)で商品ペアの類似度を50近傍まで取得
- 2で取得した類似度を特徴量にしてLightGBMを学習
- 3で学習したLightGBMの予測値を重みとしたQuery Expansion (DQE)を図のABCとABCDEにのみ行う。
- 4の結果やLightGBMの予測値、TF-IDFの結果を組み合わせる + postprocess
これらの詳細について以下で述べていきます。
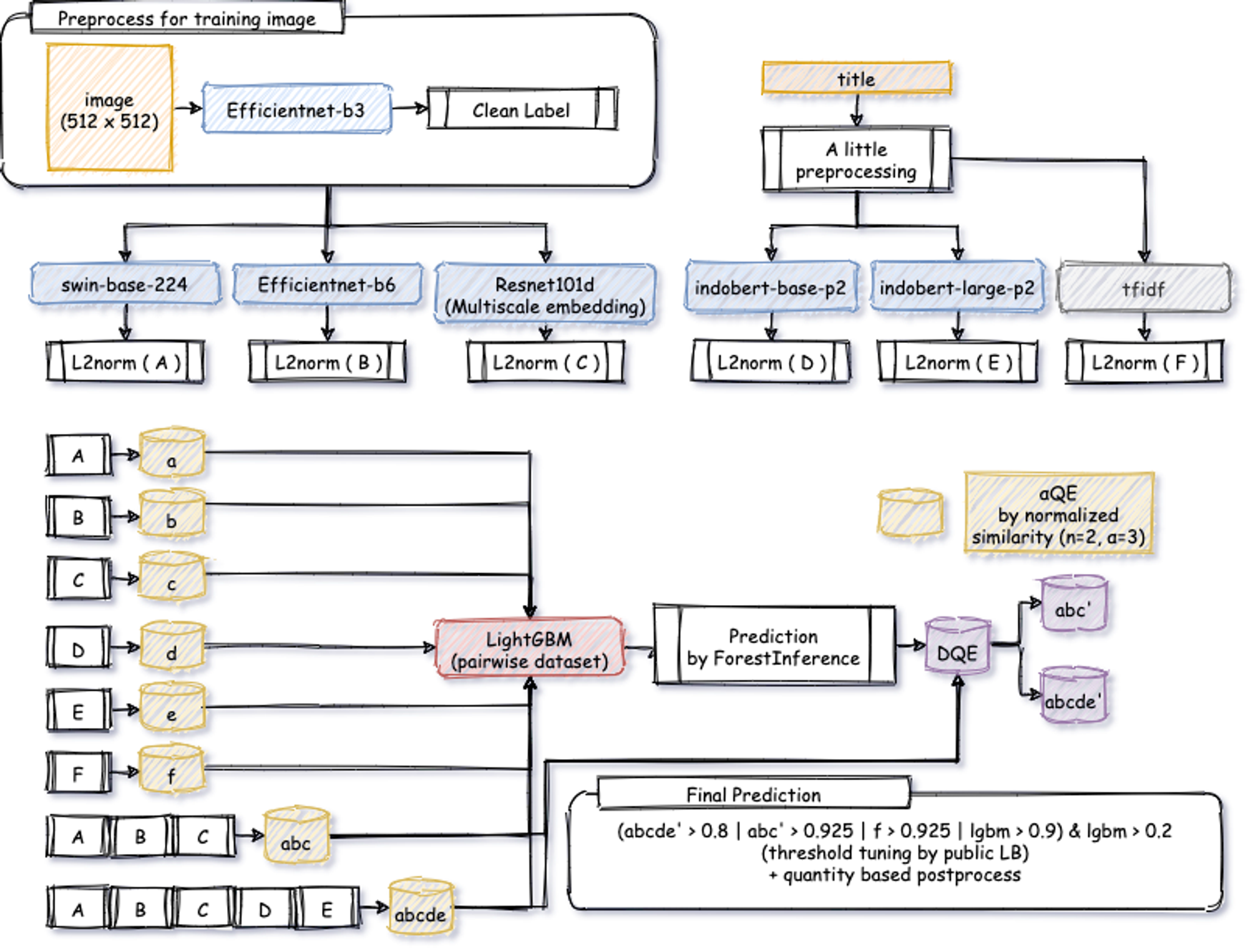
図4:10位の解法の概略図
4-1. Validation戦略
今回は、「各商品についてラベルが2つしか存在しないものが多い」ことや「testデータには見たことのない商品が多く含まれている」の二点から、GroupKFoldでラベルをグループとして5分割しました。これをStratifiedKFoldなどで行ってしまうと、検証データにラベルが1つしか存在しないデータが多くなり、F1 scoreが高めに出てしまう危険性があるので注意が必要です。
また、5分割で学習したmodelを全てNotebookにあげて推論してしまうと、それだけで推論時間の大半を使ってしまうことになるので、5分割で学習した後に全データで同じくらいのepochを学習させ、Notebookでは全データで学習したモデルを用いる戦略を取りました。
4-2. 画像モデル
ラベルクリーニング
上でも述べたように、画像が同じでもテキストが異なるためにラベルが異なるといった課題がありました。そのような画像を画像モデルだけで識別することは不可能なため、元のラベルのままにしてると学習時にノイズになることが考えられます。特に、Metric learningでは正解クラスとその他のクラスに大きなmarginを取って学習させるという性質があることから、このようなノイズは大きな問題となる可能性があります。そこで、まず元々のラベルで学習させたEfficientnetの予測値を用いて、ラベルを綺麗にすることにしました。具体的には、類似度が0.9以上だったら同じ画像とみなすといった処理を行いました。ただ、最終的にこれはあまりスコアに寄与しなかったように思います、、
訓練
あまりbackboneの探索には、時間をかけていませんでしたが図のようなmodelを3つ学習させました。単体モデルのCVとしては、ResNet101Dの最終層の特徴mapだけでなく、中間層の特徴mapも抜き出してconcatさせたモデルが一番強かったです。意図としては、MultiScaleな特徴を抽出することで小さい物体にも大きい物体にも頑健なモデルを作成しようとしました。また、modelに多様性を持たせるためにVision Transformerの一種であるswinも用いましたが、普通のVision Transformerよりも遥かに精度が良く、アンサンブルにも役に立ちました。Vision Transformerを用いる場合は、画像のNormalizeの値が通常のImageNetのものと違うので注意しましょう。
4-3. テキストモデル
前処理
本来であれば、画像と同じように同じテキストで違うラベルと言ったものをクリーニングするべきでしたが、テキストに対しては時間がなく適用しませんでした。前処理としては、単純にエスケープ文字列を修正したり、kgやmlなどの単位を抽出しその前の数字とのスペースを埋めるといったことを行いました。後半の処理は、数字と単位を引っくるめて一つの単語としてTF-IDFに認識してもらおうと思って行った方法でしたが、ちゃんとTF-IDFの精度が向上しました。
訓練
終盤まで、bert-base-uncasedを用いて訓練していたのですがあまり精度は出ておらず、TF-IDFの方がPublicで精度が出てました。今回のテキストはインドネシア語なので、何か特化したモデルがないかと探したところインドネシア後のコーパスで学習させたindobert[4]というものを見つけました。これを用いて学習させたところ、今までより遥かにいい精度が出たため、これを採用しました。
個人的に久しぶりにBERTを触ったため、学習させるのが最初難しかったです。BERTは画像モデルに比べてCatastrophic Forgettingという現象が起きやすくなっている印象で、画像モデルを学習させる感じで学習率をセットすると学習がなかなか上手くいきません。そのため、学習率のwarmupや学習率を小さめ(e-5オーダー)に取るといったことが必要となってきますので使用する際には注意が必要です。
4-4. 個人的なMetric LearningのTIPS
SoftmaxベースのMetric Learningを行う際のTipsについても少し紹介します。自分も序盤はなかなか学習が進まなかったりしてパラメータの調整が難しかったのですが、学習率を大きくし、warmupを大きめに行うことで学習が進みやすくなりました。学習の序盤だと普通のsoftmaxよりもクラス間の予測値の差が顕著に出ないため、学習が難しいのではないかなと思っています。
1位の解法でも色々と工夫は行われていて、
- marginを学習の間で徐々に大きくする
- 学習率のwarmupを大きめに取る
- ラベルの個数で重み付けを行った学習をする
- cosine softmaxを計算する部分の学習率を大きくする
- 勾配clippingを行う
などのチューニングを行ったと書かれています。個人的には、特に1つ目や2つ目は確かに重要そうな気がします。また、3つ目は2位のチームで行われていて、今回の様なラベルの個数が少ない様なサンプルが多い場合には有効だった様です。
また、今回のような多様なEmbeddingを用いてアンサンブルをするときにどうすればいいのかという問題に対して、多くの参加者が苦心したと思います。単純にEmbeddingの平均を取るやり方などが考えられますが、手元で試して一番良かったのは、各種EmbeddingをそれぞれL2 Normalizeしてからconcatするという方法です。モデルによってEmbeddingのスケールが違うので当たり前と言えば当たり前ですが、L2 normalizeせずにconcatしてしまうとそこまで改善が得られませんでした。このような細かい技術は、過去コンペの解法でもしれっと書かれているだけなので覚えておくと良いかもしれません。
4-5. Query Expansion
Query Expantsionは画像検索系の論文を調べるとほとんどの論文で載っているうような手法です。技術としてはとても簡単で、以下の疑似コードのようにquery近傍のembeddingについて、何かしらの集約を行い拡張したembeddingを作成する技術です。集約方法は、単純に近傍いくつかの平均を取るMean Query Expansion (MQE)や類似度で重みをつけた以下のコードのような Query Expansion (QE)などいくつかの派生系があります。これらについては、[5]の論文のRelated Worksにまとまってるので気になる方は参照してみてください。
def query_expansion(embeddings, similarity, alpha=3):
"""
入力のshapeは、
embeddings: [n_neighbor, n_feature]
similarity: [n_neighbor, 1]
を想定。
"""
weights = similarity ** alpha
expanded_embedding = (embeddings * weights).mean(0)
return expanded_embedding今回のコンペでは、QEに少し修正を加えて、近傍二つまでを抽出した上で、その二つの類似度をnormalizeしたものにQEをしたものが、一番効果がありました。これは、各商品について自分を含めて二つは同じ商品があることが保証されていることに起因しているのだと思います。図5は、図4のABCDEに対してQEを試した際の結果となっています。この場合は、CVが0.873 → 0.900まで上がっており、また閾値に対してもロバストになっていることが分かります。Public LB上でも、画像モデルとTF-IDFに対して行うことで、0.735 → 0.762くらいの効果があったと思います。
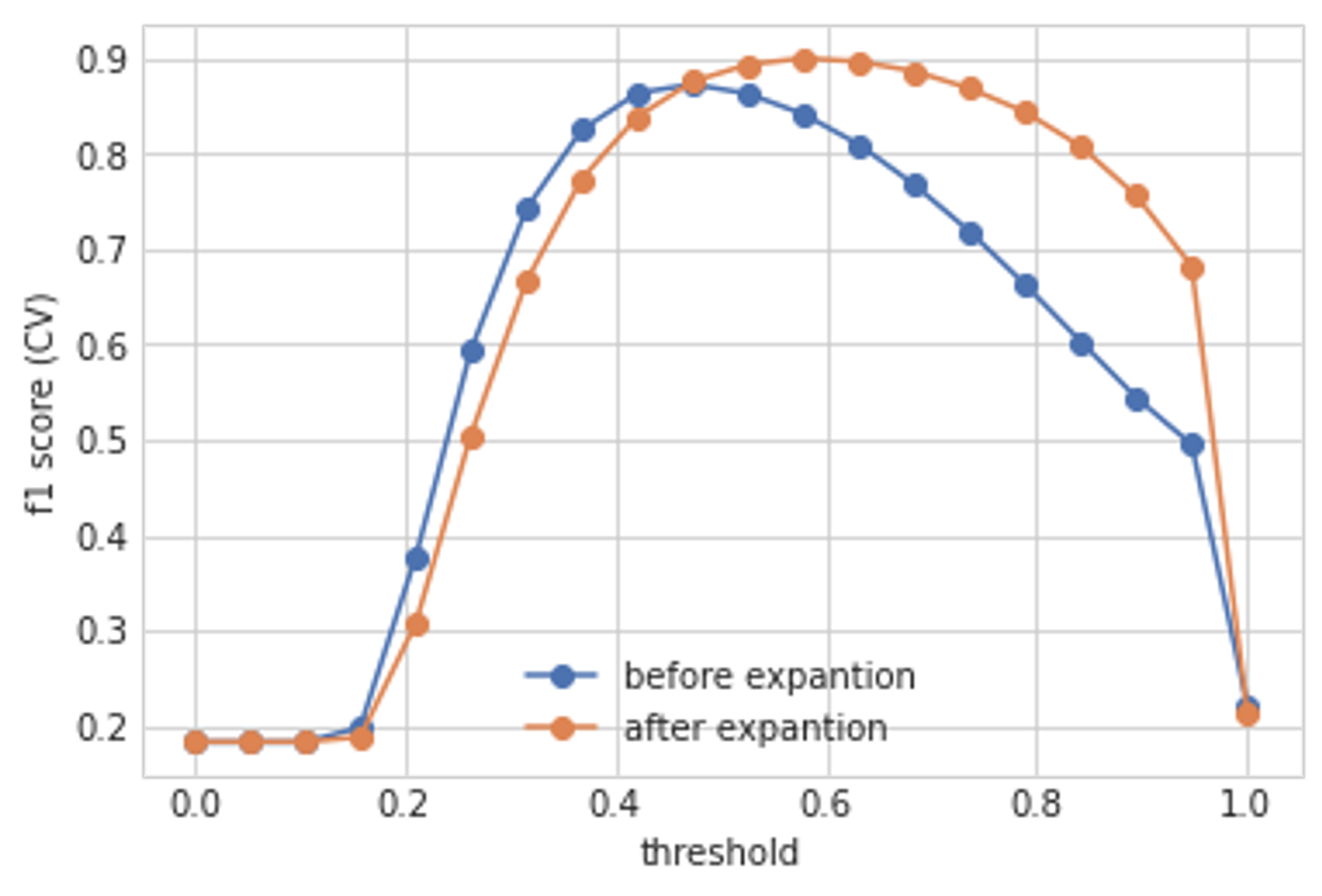
図5 : Query Expansionの効果
4-6. 閾値調整
シミュレーション
今回のコンペでは、どのように閾値を調整するかも重要な課題でした。例えば、訓練データと同じ閾値でテストデータについても予測を行うと、テストデータは70000件存在するためFalse Positiveの数も多くなってしまいます。そのため、False Positiveを少なくするために、訓練データよりも閾値を大きくすることが必要となってきますが、それがPublic LBのスコアで調整していいのかという問題があります。そこで、まず手元でPublicで閾値を調整して問題ないかを手元でシミュレーションしました。テストデータでは、まずテストデータ全体から予測値を70000件計算し、その内の40%でPublic LBを計算している様でしたので、その手順に則り以下の様にしました。
- 訓練データ全体に対してKNNを用いて、類似度を取得
- 訓練データからラベルをRandomにサンプリングし、そのラベルが含まれる訓練データをサブセットとして取得
- 1で得られた類似度を用いて、2のサブセットで最適な閾値を探索
- 2, 3を100回繰り返す
この手順で得られたF1スコアと閾値が以下の図です。この結果から、(少なくとも40%くらいのサンプリングでは) データセットサイズに最適な閾値が依存しないことが分かったので、Public LBで閾値を探索しても問題ないとしました。
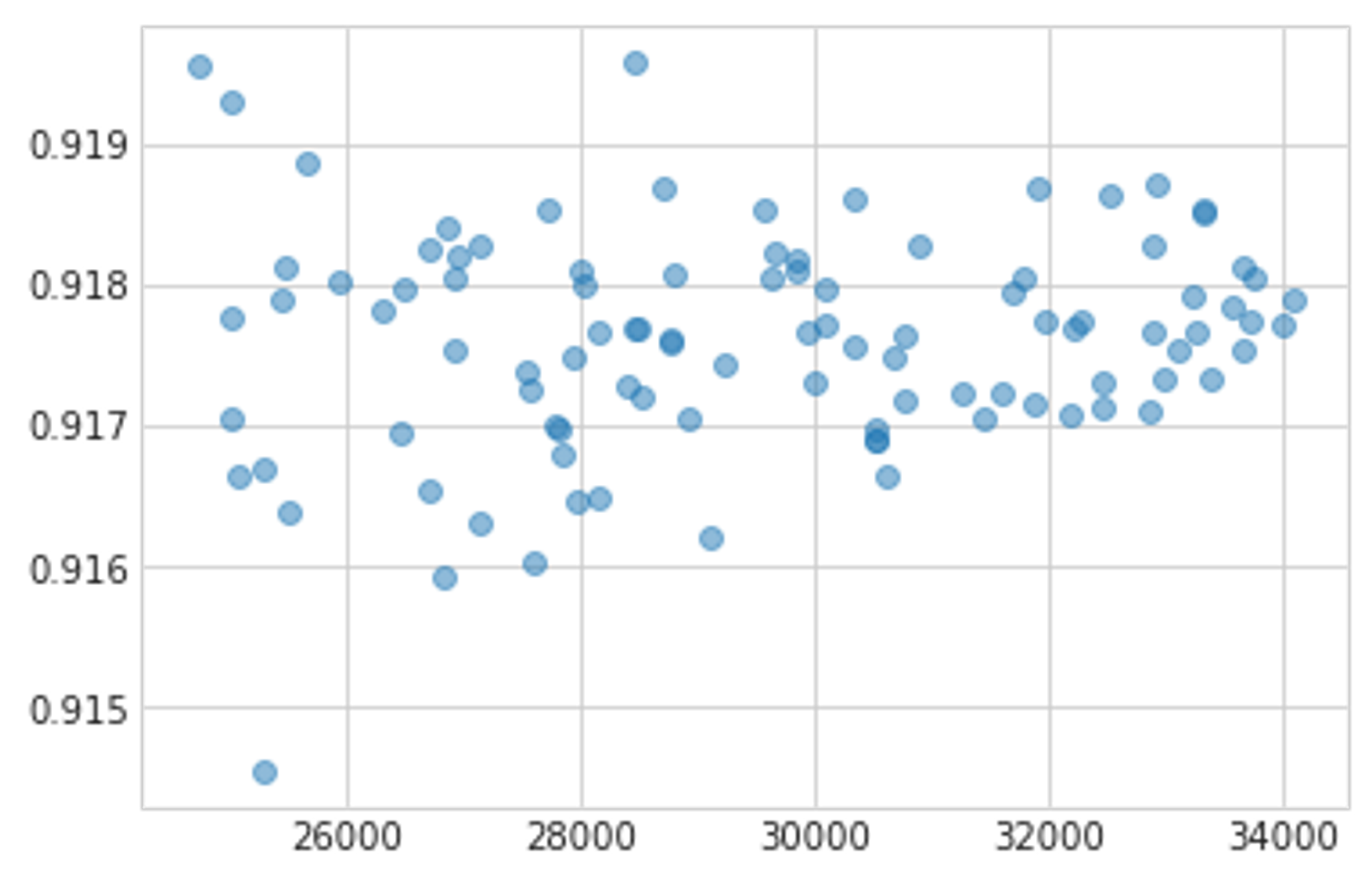
横軸:データセットサイズ 縦軸:F1スコア
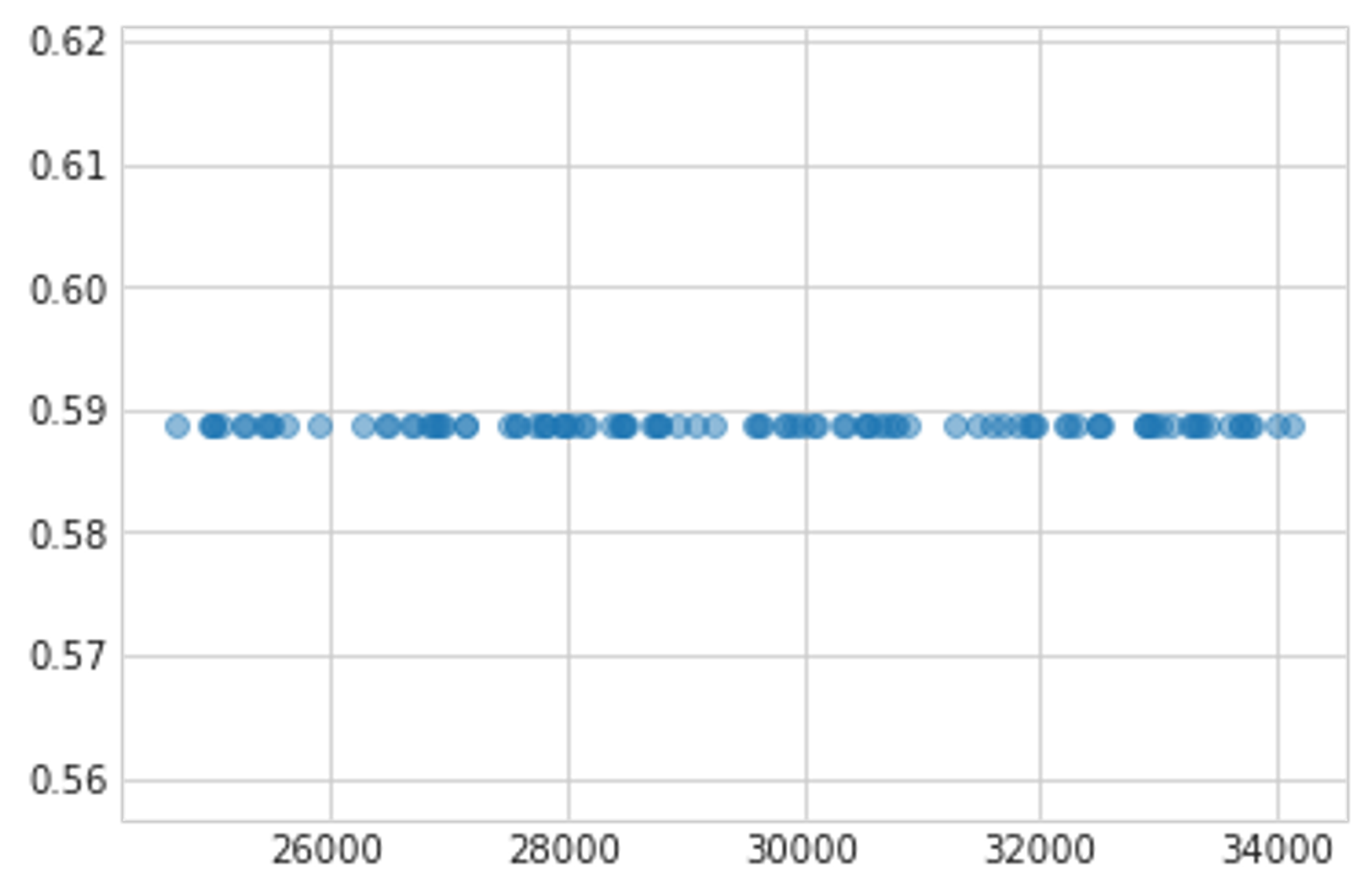
横軸:データセットサイズ 縦軸:最適な閾値
ここに関しては、参加者の中でも勘違いしている人が多く、40%のデータで評価しているのでKNNを適用する場合も40%しか使わないと思っている人が多いようでした。そのような勘違いをしていると上とは違う結果が得られてしまい、データセットが大きくなるほど閾値を上げなければいけないという結論になります。そのため、Private用に閾値を上げる処理をしてしまった人はshake downしてしまったのではないでしょうか。
予測の組み合わせ
手元のCVで評価した際には、TF-IDFを組み合わせない方がCVが良かったり、CNN + BERTでconcatしたもの (図4のABCDE) を単体で使用したものの方が CNNのみ (図4のABC)より遥かに良いのにPublic上ではスコアが下がるといった現象に悩まされていました。
そこで、ABCやDE, ABCDEの予測値がどの様な傾向を持ってるかを散布図を見ることで調査しました。図6は、ABCとABCDEの予測値の違いを示したものです。これを見ると、ABCDEが得意な部分もあればABCが得意な部分もあり、これがPublic LB上で悪さをしている可能性を考えました。そこで、色々な散布図を手元でチェックしながら、False Positveが少なく、True Positiveが多そうな場所を予測に追加していきました。この閾値はPublic LBで調整しましたが、上でやったsimulationの通り問題ないとしました。
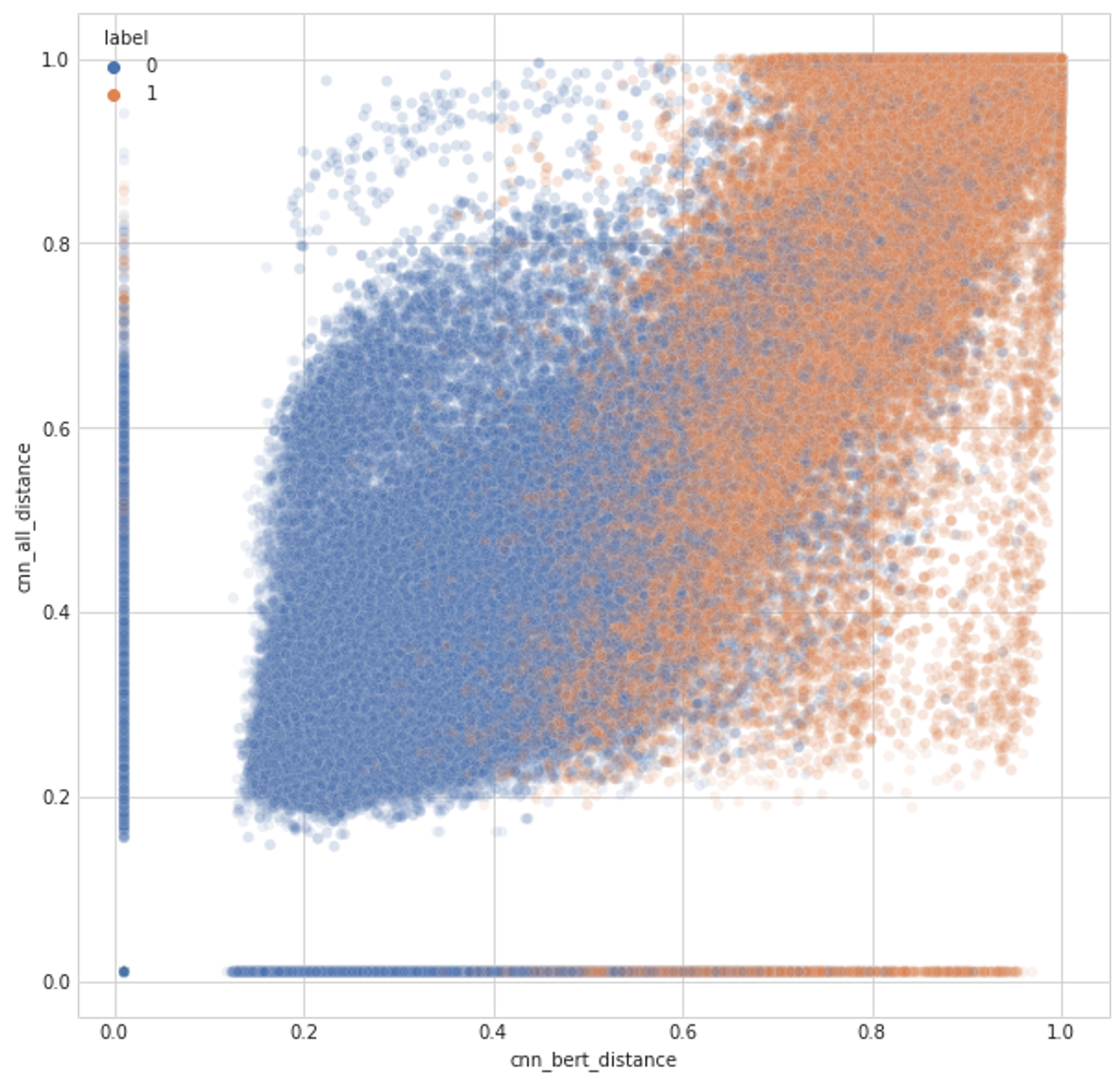
図6:CNNのみを使用した予測値(ABC) とCNNとBERTを使用した予測値 (ABCDE)の散布図
4-7. LightGBM
上のように最初は色々な予測値の閾値を調整して組み合わせていたのですが、これだとどうしても限界があると考え、機械学習ベースで色々なEmbeddingによる予測値の組み合わせを最適化できる方法を考えました。今回は、LightGBMで予測値を特徴量として、NNを学習したときと同じ分割方法で5 model学習を行いました。ここで、学習させるためのデータセットは各種商品とその近傍50サンプルのペアを用いて行いました。
ここでの予測は、テストデータだと程のデータ数になり、2 hourの推論制限内でこれの予測を行うのは当初困難でした。しかし、今回はcumlのForestInference[6]というライブラリを用いることで、高速に推論を行うことができました。
最終的に、LightGBMの予測値を上で説明したQE のsimilarity として用いることで得た予測やLightGBMの予測を組み合わせることで最終的な予測としました。
しかし、後日談になるのですが、このLightGBMを使う方法を思いついたのが最終日二日前とかであったため、閾値を探索する余裕がなく上記のような予測となりましたが、後日LightGBMのみで予測してみたところPublicで0.774、Privateで0.765のスコア (6位相当)が出ました。どうやら複雑な組み合わせをせず、LightGBMによって決定境界が最適化されてると信じて予測をすれば良かったようです笑
4-8. Postprocess
最後に、最初に説明したような50mlと100mlの商品の違いを検出するために、いくつかの単位について、その単位がQueryと近傍のペアに対して存在し、かつその前の数字も存在する場合に対してのみ予測から外すという処理を行いました。これによって、Public上で0.002程の改善がありました。
5. 上位解法
基本的に画像モデルやテキストモデルに対してmetric learningを用いてEmbeddingを出力するところまでは同様で、その後の処理などで各々の工夫点がありました。モデルとしては、NFNetを使用してる解法が多かったですが、自分は上手く学習させることができませんでした、、
1位
4-6の閾値調整の項で述べたように、画像モデルが得意な領域、テキストモデルが得意な領域、画像モデルとテキストモデルをconcatしたときに得意な領域というものがあります。そのため、1位のチームも3つのモデルの閾値を調整して下図のQ, A, D, E, F, Gの領域を予測とした様です。この閾値をどう調整したかは書かれていませんでしたが、Public LBで調整したのではないかと思われます。
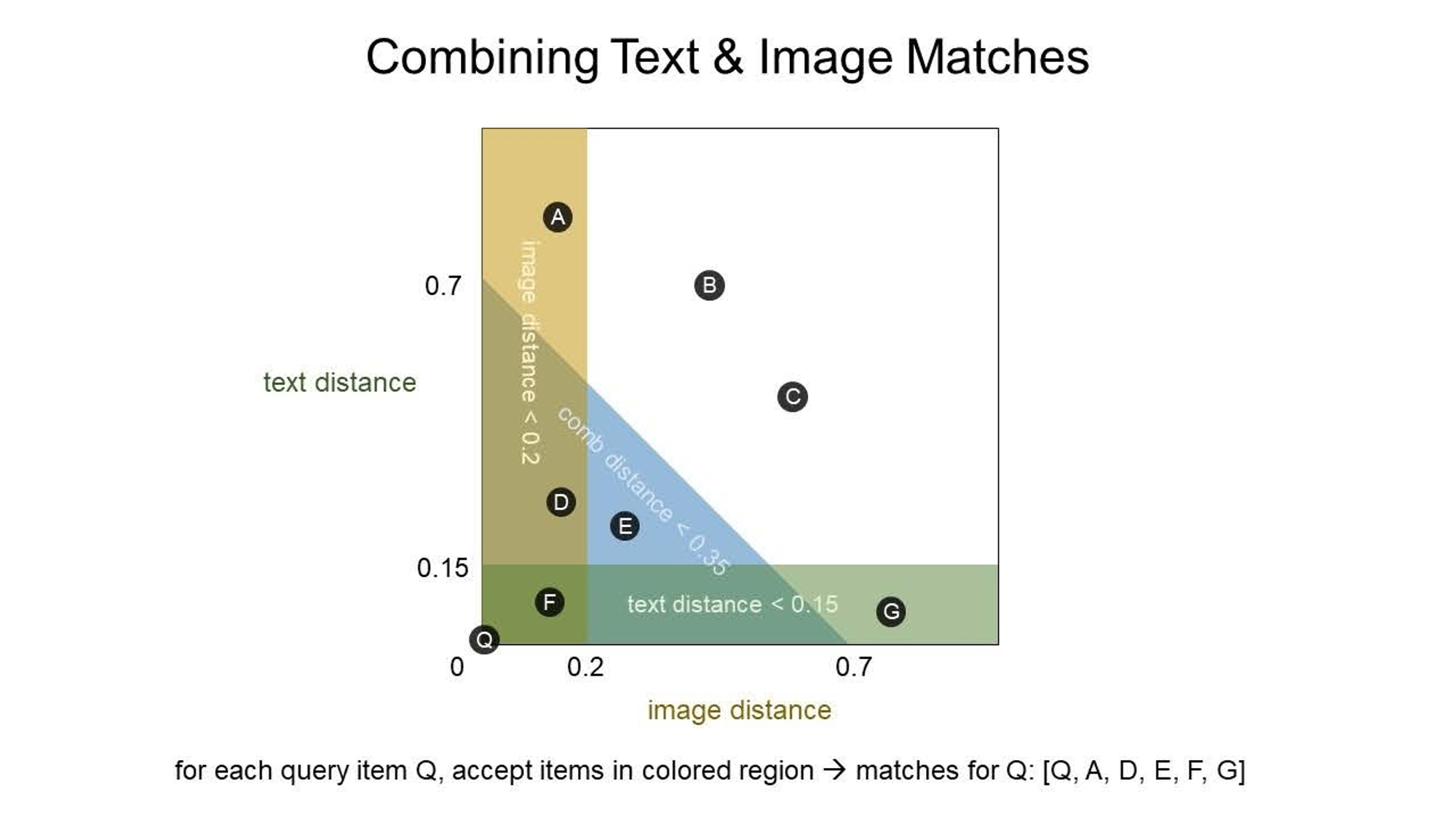
図7 : 予測の組み合わせ(
また、Query Expansionの方法として、Iterative Neighborhood Blending (INB)という独自の手法を行なっていました。この方法は以下のようなものです。
- まずKNNの結果から類似度を距離行列としたグラフを作成。
- グラフの各頂点からある閾値を超えた近傍の頂点のみ抜き出す。ただし、最低自分以外に1点は取るものとする。
- 2で抜き出した頂点のEmbeddingをエッジの重みで足し合わせる。ここで、自分自身の重みは1とする。
- この結果得られたEmbeddingからKNNを再び行い、1 - 3を繰り返す。
これを2回繰り返した結果得られた予測と画像モデルとテキストモデルの予測を組み合わせて最終的な予測とした様です。グラフから近傍を抜き出すときの閾値が重要だった様で、その他の閾値は簡単な調整のみ行い、INBの閾値をPublic LBに対して行った様です。
私もQEを複数回行うということは行いましたが上手くいかなかったので、グラフ構造を考慮することが重要だったのかもしれません。
2位
2位のチームは私の解法と似ていて、画像モデルやテキストモデル、それらを組み合わせたモデルから取得したEmbeddingでKNNを行った後に、LightGBMやGraph Attention Networkの二つのモデルを作成していました (実際は、LightGBMはチームメイトそれぞれで1つ作っているので3つ)。このチームは、私が終盤で気づいた様な2nd modelの重要性に序盤で気付いており、早い段階でそこの作り込みができていたので流石といったところでした。
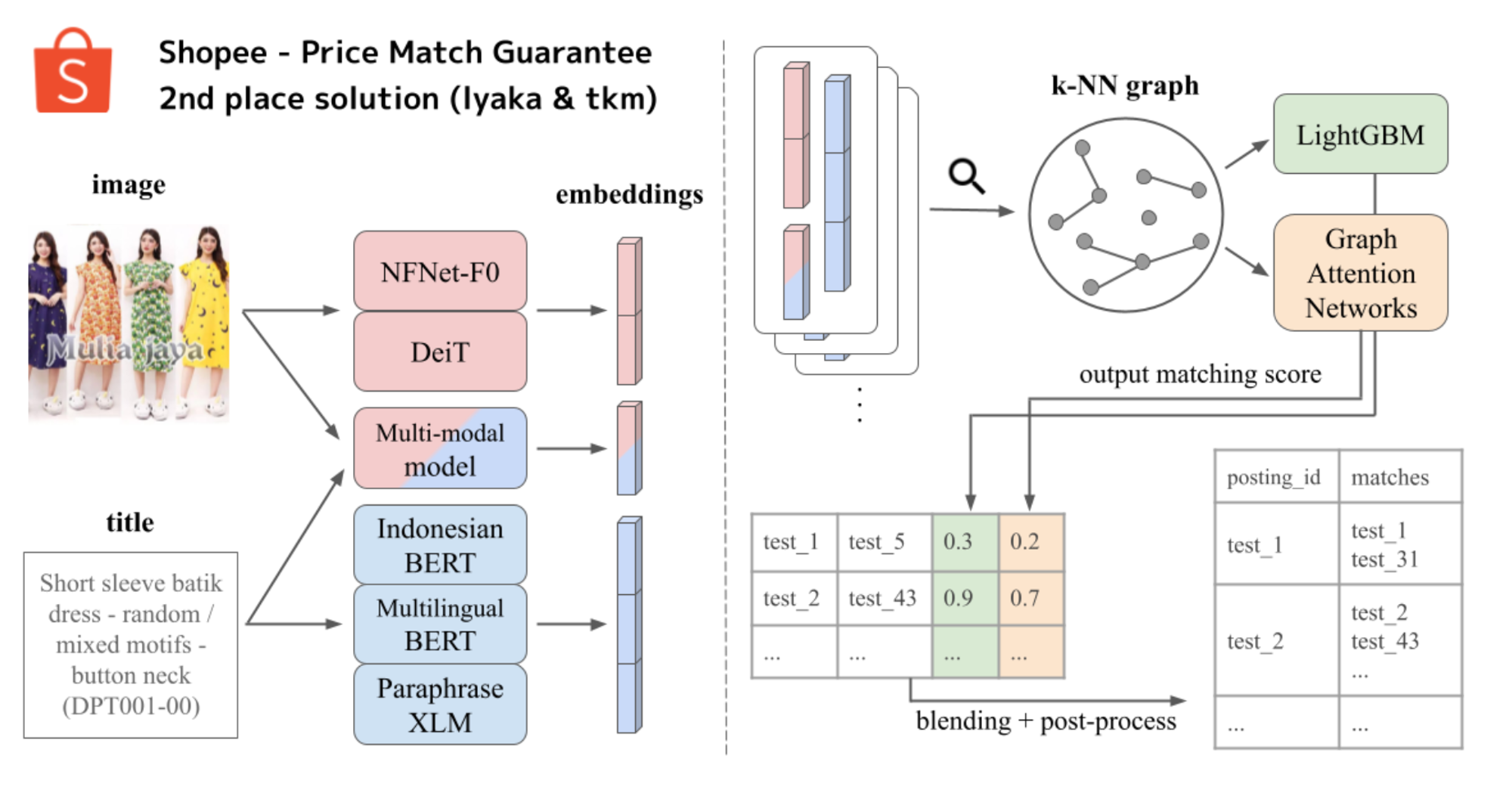
図9 : 2位の解法図 (
自分との解法の差分でいうと、
- 画像・テキストモデルを組み合わせたマルチモーダルモデルを作成している
- グラフ特徴量や、テキストの長さや編集距離などの元のデータに基づく特徴量、近傍の類似度平均特徴量などを多数加えている
- QEを行う前の類似度なども特徴量に加えている
- 2nd modelの多様性
などがあります。
また、多様なモデルやテクニックを組み込んでもメモリエラーをおこさなかったり、2 hourの推論に納めているのも流石で、codeも公開されているので気になる方は見てみても良いかもしれません。
3位
3位のチームも2位のチームと似ていて、2nd modelで500程の特徴量を作成してCatBoostで推論ということを行っています。他のチームと異なるのは、ArcFaceではなくtriplet lossを用いて学習を行っている点や、最終的な予測をCatBoostで推論した類似度 (類似確率) を利用した凝集型クラスタリングで行っている点です。ただし、このクラスタリングもパラメータを探索する必要はあった様です。
また、高速化テクとしてNvidia DALIを用いて画像の読み込みを行っていた様です。今回の様な推論時間制限が厳しいコンペでは、この様なGPUを用いた高速化のライブラリも重要になってきますね。
6. まとめ
今回のコンペはやれることの自由度が高く、その分考えることが多かったためにしんどいコンペでした。個人的には、検索系の技術に触れるのが初めてだったり、BERTの学習を上手くできないといった状態からのスタートだったため、技術のキャッチアップが大変でした。そのため、最初の1ヶ月程度は銅メダル圏内にも入らないといった感じだった気がします。過去の類似コンペや論文を漁り読みするといったインプットの時間が必要だったため、中々最終的な解法のアイデアにたどり着くのに時間がかかりました。今回のコンペのDiscussionやNotebookでは、上で述べた様なQEといった言葉は一言も出て来なかったので、DiscussionやNotebookばかり見てても上位にはいけないという典型的なコンペだった様に思います。知らない技術を勉強して、それをコンペで試して結果が出るという感じは個人的には楽しいコンペでした。
また、無邪気にKNNの結果からスパース行列使わずに隣接行列を表現したりするだけでメモリエラーになったり、何も考えずに5-foldのモデルで推論を行うと推論時間をオーバーしてしまったりするため、いかに効率の良いコードを書くかが重要なコンペでした。自分の場合は、スパース行列を適切に使用したり、CPUのメモリが足りない時は、cupyを用いてGPUで処理を行ったり、ForestInferenceを用いたりといった工夫を行いました。どれも今まで使用していないライブラリだったので、この様な部分も勉強になる良コンペでした。
最後になりましたが、Mobility Technologies では Data Scientist / Data Analyst を募集しています。大規模でユニークなデータを扱い、プロダクトに大きなインパクトを与えられるだけでなく、確かな技術力を持ったメンバーとともに切磋琢磨できるポジションなので、ご興味のある方は是非ご応募を検討していただけると幸いです!
採用ページはこちら >>> https://mo-t.com/recruit/
[1] DeNAより出向中
[2] モダンな深層距離学習 (deep metric learning) 手法: SphereFace, CosFace, ArcFace, https://qiita.com/yu4u/items/078054dfb5592cbb80cc
[3] Image Retrieval Overview (from Traditional Local Features to Recent Deep Learning Approaches), https://www.slideshare.net/ren4yu/image-retrieval-overview-from-traditional-local-features-to-recent-deep-learning-approaches
[4] Fajri Koto, Afshin Rahimi2 Jey Han, Lau and Timothy Baldwin1, IndoLEM and IndoBERT: A Benchmark Dataset and Pre-trained Language Model for Indonesian NLP, 2020
[5] Albert Gordo, Filip Radenovic, and Tamara Berg, Attention-Based Query Expansion Learning, 2020
[6] RAPIDS Forest Inference Library: Prediction at 100 million rows per second, https://medium.com/rapids-ai/rapids-forest-inference-library-prediction-at-100-million-rows-per-second-19558890bc35