

サーバサイドのCPUによるAI推論の速度改善
AIMay 11, 2022
スマートドライビング事業部 システム開発部 AI基盤グループ の廣安です。ドライブレコーダー上で動作する交通事故削減支援システム『DRIVE CHART』のAI推論処理を行うEdge AIライブラリの開発やAIテスト環境の改善等を担当しています。この記事ではサーバサイドのCPU上でAI推論処理を高速に動作させるための方法と、運用中サービスに実際に適用して処理時間を1/3にまで改善できたという話をします。
DRIVE CHARTにおけるAIアルゴリズム改善とその課題
DRIVE CHARTは前回のブログで紹介したEdge AIライブラリが処理した内カメラ/外カメラの解析データ、映像記録、GPS/加速度といったセンサーデータをサーバ上で処理し、危険運転検知や運転行動のレポート作成を行っています。このレポート作成アルゴリズムの開発にあたっては、プロダクション環境とは別にAIテスト環境と呼ばれる収集された実走行データを使ったテストシステムをAWS上に構成し、データサイエンスチームを筆頭に継続的に改善を行っています(こちらのスライドを参照)。
プロダクション環境とAIテスト環境上では、Edge AIのモデルやサーバ上での解析向けのモデルを使用したAI推論処理を走らせていますが、大量のカメラ映像データを使った処理を行うために膨大な計算量がかかる事になり、結果として評価の開始から終了までに多大な時間がかかり、またその分AWSのコストも大きくなるという問題があります。
例えばAI推論を使った脇見検知を行うサービスがあるのですが、そのサービス上で5分の動画クエリを投げてからレスポンスが返ってくるまでの時間を測定したところ平均約75秒程度の時間がかかっていました。さらにそのサーバ内各処理の時間を測定して内訳を見てみたところ、その内の約66秒がPyTorchの推論時間(CPU推論モード)であり、およそ90%を占めていました(他は動画/画像の前処理やI/Oなど)。
高速化のアプローチ
そこで、実際にDNNモデルの推論処理を高速化していく必要が出てきました。高速化のアプローチとしては、以下のような方法が考えられます。
- DNNモデルを見直し、高速化するようアーキテクチャを変える
- DNNモデルで処理する入力映像から画像を間引く
- PyTorchのGPU推論モードを使用して推論処理を実行する
- CPU上でマルチスレッドやSIMDを使った高速推論を行う(対応したライブラリ等を適用する)
今回の高速化対応はできるだけ短期間で、しかもなるべく高速化適用前後で推論結果に対する影響が少ない対応が求められた事から、1や2のような方法は取れませんでした。3の方法で高速化する事は可能ですが、AWSのGPUインスタンスは安価で使えるスポットインスタンスが確保しづらく、多数のインスタンス上で大量のデータを並列に処理するという事がコスト的に実現しにくい問題があります。そのため今回は4で対応する事とし、そのためにどのような方法があるかについて調査をする事にしました。
AWS上で使用されているCPUについて
まず今回の高速化で対象となるAWSのサーバに搭載されているCPUについて説明します。AIテスト環境で使用しているAWSのインスタンスは、m5.largeやc5.largeのようなIntelのXeonプロセッサを搭載したものになります(詳しくはAWSのサイトを参照)。これらのインスタンスタイプ上にあるXeonプロセッサは、AVX512(Intel Advanced Vector Extensions 512)というSIMD命令に対応しており、512bit長のレジスタ上に並べられた数値群に対して並列演算を行う事で高速に計算処理をできるようになっています。
DNNモデルの計算処理は大半がCNNによる積和演算(MAC:Multiply-ACcumulate operation)になりますが、昨今のAVX512ではDL boostのようなINT8の積和演算専用の命令セットが用意される等してAI処理を高速に処理できるようになってきています(なお、今回の記事ではINT8量子化まではしなかったため、DL Boostは使われていません)。
AVX512の命令セットを使えば高速にAI推論処理を実行できる事になりますが、これらの命令セットを使用して高速推論を実行できる推論エンジンが存在しているので、それらを使う事で直接SIMD命令を使ったコーディングをするような必要はありません。
推論エンジンには次のようなものがあります。
- ONNX Runtime
- OpenVINO
- DeepSparse
- TVM
以下でそれぞれについて紹介していきます。
ONNX Runtime
Microsoftが開発している汎用的な推論エンジンです。その名の通りONNX(Open Neural Network Exchange)というDNNモデルのファイル形式を使った推論に対応しており、とりあえずONNXを使った推論を試してみたいという場合はこれを使う事が多いです。PyTorchやTensorflowのような主要なDLフレームワークはONNX形式ファイルの変換に対応しているのでそれらのフレームワークで学習したDNNモデルをONNX Runtimeを含むこれから紹介する推論エンジン上で使うのは容易です。
デフォルトではCPUを使った推論が実行されますが、様々なハードウェアプラットフォームに適した高速推論を実現するためExecution Providerというエクステンションに対応しているのが特徴です。後述のOpenVINOに対応したExecution Providerも用意されており、Intel製のプロセッサ上で推論したい場合はこちらを選択する方が高速に推論処理を実行できます。
ブラウザ上でWASMやWebGLを使って推論を行うONNX Runtime Webというものもあります。デモサイト上で簡単にローカル環境でONNXを使った推論を試す事ができるので、とりあえず触ってみたいという方はこちらで試してみるのが良いと思います。
ONNX Runtimeの実装言語はPython、C/C++の他C#、Java、JavaScript等多彩な言語に対応しています。また公式ではありませんがonnxruntime-rsというRust wrapperも開発されており、Rustからも使用できます。実行環境としてはLinux, Windows, MacだけでなくAndroidやiOSにも対応しておりモバイルデバイス上でも動作させる事が可能です。
以下にPythonでの推論実装コード例を示します。ここでrun()の引数inputsは入力レイヤのレイヤ名と入力テンソル(numpyのarray形式)が対応したdictになります。outputには出力レイヤの数分だけの出力テンソル(これもnumpyのarray形式)が配列で格納されます。

OpenVINO
Intel製の推論エンジンで、上記のAVX512に対応したCPUの他にもIntel製のGPU, VPU(*1), FPGA上で高速に推論できるのが特徴です。
OpenVINOはONNXファイル入力に対応しています。また、OpenVINOツールキット内にはモデル最適化適用ツールがあり、その出力であるIR(Intermediate Representation)という*.xmlと*.binの2ファイルで構成される中間形式の入力にも対応しています。このIRへの変換によってFP32の他にFP16やINT8のような精度での高速推論実行が可能になっています(ただし、ランタイム環境がFP16やINT8での計算に対応していない場合はエミュレーション処理されるらしく、却って遅くなる事もあります)。
また、OpenVINOにはWorkbenchというUI環境が用意されており、簡単にツールやAPIを試す事もできます。使い方も簡単で、ローカルで使いたい場合はこのページで自分の環境の情報を選択形式で入力していくと実行手順が表示されるので、その手順に従って実行するだけです。また、こちらのページによると、ローカルの環境にはないCPU/GPU等をDevCloud上で試すといった事も可能なようです。
実装言語はPythonとC/C++に対応しています。またツールキットには含まれていませんが、openvino-rsというcrateがintelのgithubリポジトリ上にあり、これを使う事でRustからOpenVINO APIをコールすることも可能です。実行環境はLinux, Windows、Macに対応しています。
以下のPythonコードのようにONNX Runtime同様、ONNX形式ファイルを読み込んで推論処理を実行する事ができます。またONNXファイルの代わりにIRのファイル名を指定する事で中間形式ファイルを読み込む事もできます。

DeepSparse
Neural Magic社が開発しているIntel CPU上で動作する高速推論エンジンです。独自のCPU専用の推論アルゴリズムを採用する事でCPUでGPUクラスのパフォーマンスが出せるというのが特徴です。仕組みについてはこちらの資料が詳しいですが、GPU上で行うようなレイヤ毎の並列演算は仕組み上CPUには不向きなため、モデルのsparse化を行った上で各CPUコアの並列演算をレイヤの深さ方向に実行するようなアルゴリズムを考案し採用しているようです。これによりCPUの大きいサイズのキャッシュを活かし、GPUと比較して低帯域のメモリを使って動作するCPU上でも高速推論を実行できると主張しています(下図はリンク先の資料より)。
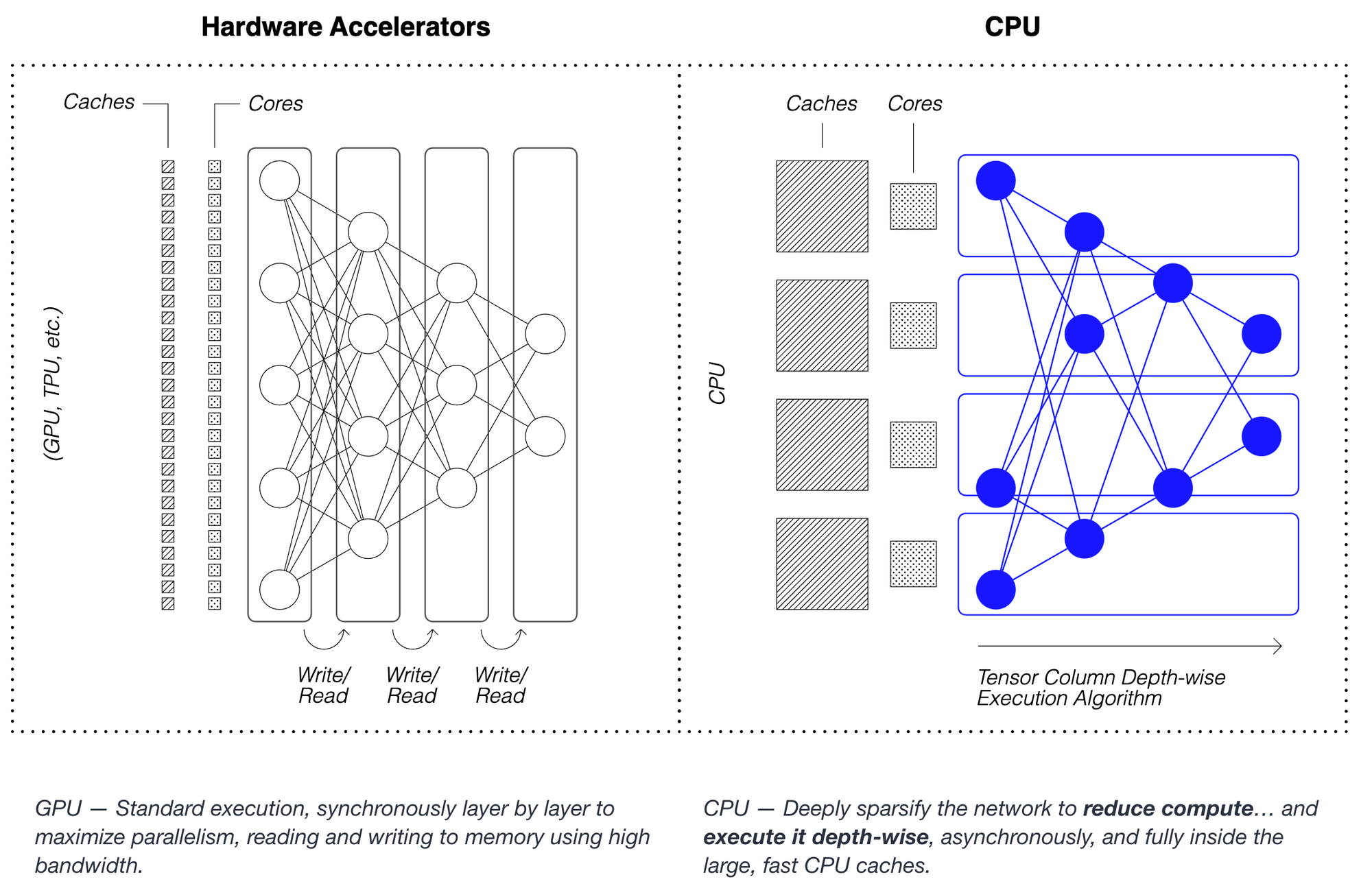
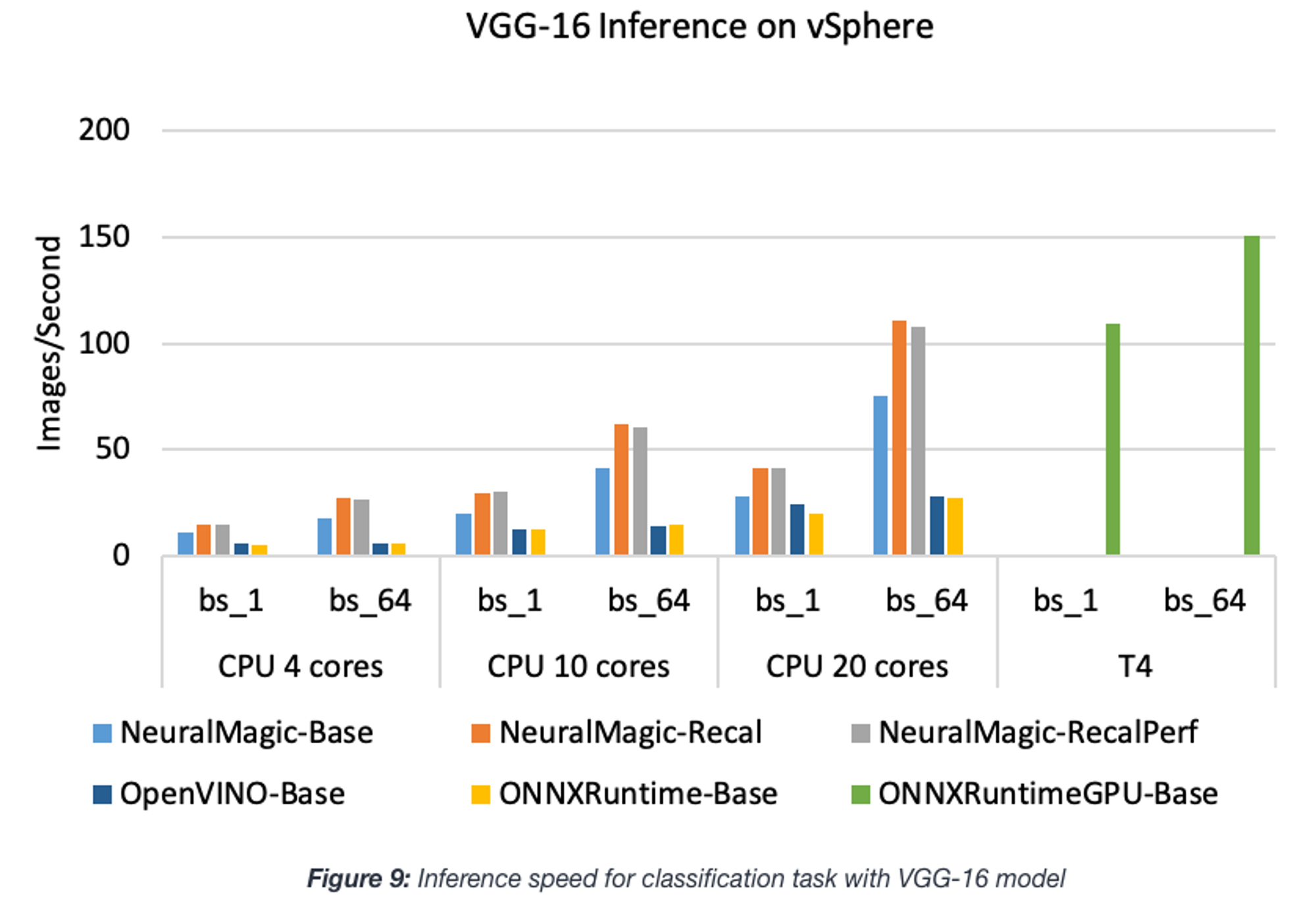
公式ドキュメントによると、DeepSparseをより高速に動作させるにはDNNモデルのpruningとquantizationが必要とありますが、こちらのブログによるONNX RuntimeとOpenVINOとの比較結果を見てみるとモデルによってはそれらを行わないでもONNX RuntimeやOpenVINOより速い事もあるようです(下図はリンク先のブログより。NeuralMagic-Baseがpruning/quantizationなし、NeuralMagic-Recal/RecalPerfがpruning/quantizationありに対応。bsはバッチサイズ)。
pruning/quantizationには現状DNNモデルの再学習が必要となっており、そのためのサポートツールとしてsparsifyというUIツールと、SparseMLというPyTorch, Tensorflow, Keras上で再学習を行うためのPythonライブラリが用意されています。これらのツールを使い最適化しつつ再学習したモデルをONNXに変換し、DeepSparse上で推論する事によりDNNモデルの精度を保持しつつCPU上での高速推論を可能としているようです。
DeepSparseの実装言語はPythonとC++に対応しています。ただし2022/4月時点でC++版のAPIはまだFixされておらず、v0.8.0でしか配布されていない点に注意が必要です。実行環境としてはLinuxのみ対応しており、MacやWindows上で使いたい場合はVMWareのような仮想環境が必要となります。
以下コードのように、DeepSparseもONNX形式ファイルを読み込んで簡単に推論を実行する事ができます。

Apache TVM
様々なDLフレームワークのモデルを様々なデバイス上で高速に動作させる事を目的としたコンパイラフレームワークです。Tensorflow, PyTorch, ONNXのようなモデルをRelay IRという中間表現に変換し、AutoTVMあるいはAutoScheduler(Ansor)というツールを使って目的デバイスに向けた最適化を行う事で高速な推論処理を可能としています(下図はtvmのUser Tutorialより。実際にDLフレームワークのモデルからコンパイル/最適化をして実デバイス上で実行できるマシンコードにするまでのフロー)。

多くのDLフレームワークに対応しており、デプロイ先のデバイスもGPUというハイパワーハイパフォーマンスのデバイスから、MCUのようなローパワーローパフォーマンスのデバイスに至るまで多数用意されているのが特徴です。ただし、コンパイルとチューニングという手順が必要な事からこれまで見てきたような推論エンジンと比べて扱いは非常に難しくなり、またTVMそのものと目的とするデバイスに対する深い知識も必要になってきます。自分も実際にあるモデルのチューニングをIntel CPU向けに試してみましたが、パラメータの設定等のやり方が悪いのか思ったようなパフォーマンスが出せず断念したという経緯があります(使える時間の都合もありましたが)。私見ではありますが、時間をかけてでも特定のデバイス上で最大のパフォーマンスを出したいという場合に使うのが良いのではないかと思います。
TVMの実装言語はC/C++, Rust, Go, Java, Python, JavaScript等多数に対応しています。
AWS環境上でのベンチマーク
Edge AIシミュレーション環境向けモデル
実際にEdge AIライブラリ上で使われているDNNモデルを使い、PyTorchと上で紹介した各推論エンジンでベンチマーク測定してみました(TVMは除く)。なお、Edge AIライブラリ自体はエッジ向けの環境上で動くものであるため、サーバ環境上で動かすときはIntel CPU上で動作するシミュレータを用意しています。今回のベンチマークはそのシミュレータのAI推論処理部分の測定を行っています。
測定用プログラムはPythonで実装を行いました。使ったモジュールのバージョンはそれぞれPyTorchがv1.10.1、ONNX Runtimeがv1.11.0、OpenVINOが2021.4.689、DeepSparseが0.11.2となっています。
ONNX RuntimeはExecution Providerを設定せずにデフォルトのCPUモードを使って測定を行いました。また、OpenVINOはIRへの変換を行った場合(with IR)とIRへの変換を行わずに直接ONNXを読み込んだ場合(without IR)で測定しましたが、CPU上での推論では差が殆どなかったのでIRありの結果は省略しています。
モデルは内向きカメラから顔検出と脇見検出のモデル、外向きカメラから物体検出とレーン検出のモデルを使用しました。測定環境にはAWSのc5.largeインスタンス(物理コア数1)を使用しました。
結果は以下になります。ウォームアップ用に5回推論処理を行い、その後50回推論処理を実行してその平均時間を測定しています。
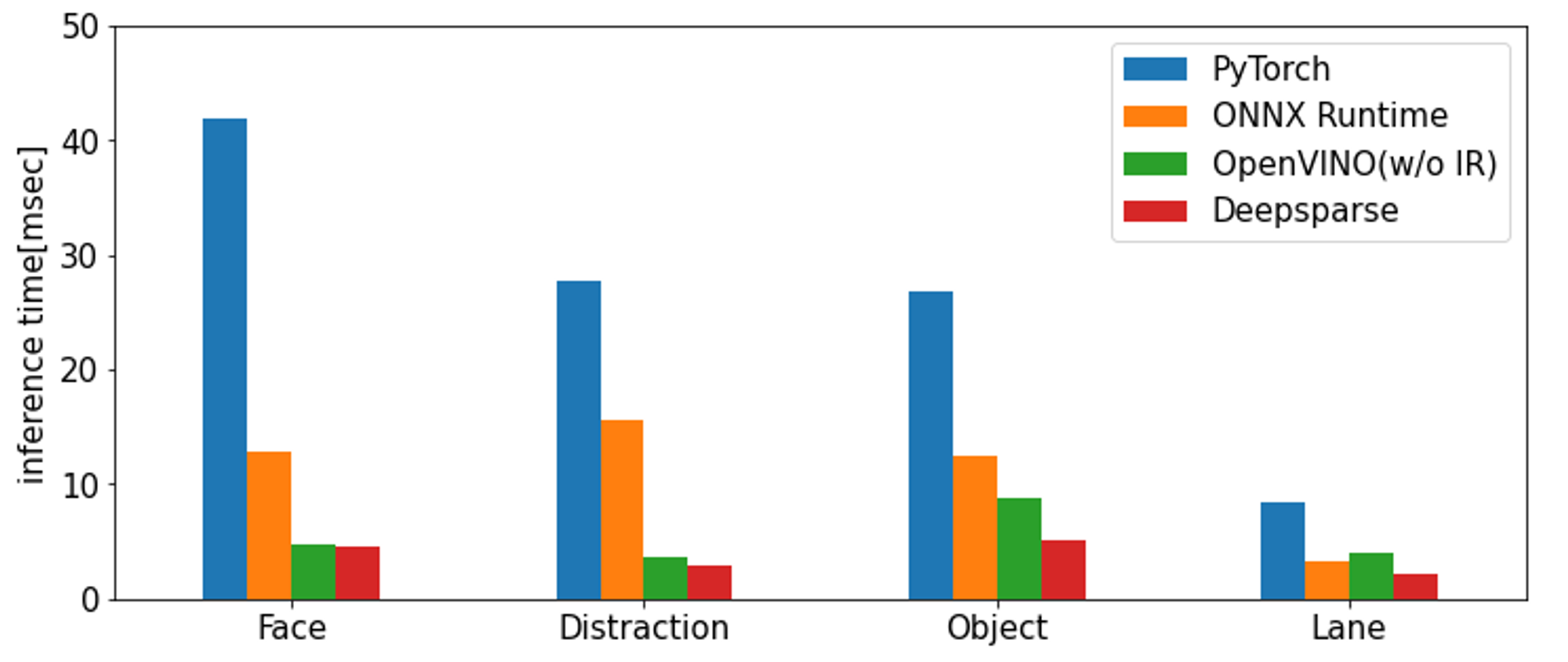
結果を見てみると、PyTorchで推論した場合とOpenVINO/DeepSparseを使った場合とで2〜10倍の差が出ている事がわかります。ONNX RuntimeのデフォルトのCPUモードはそれと比べると遅めになる事が多いようです。
また、各推論エンジンのCPUのコア数による性能差を見るため、c5.xlarge, c5.2xlarge, c5.4xlarge(それぞれ物理コア数が2, 4, 8)についても同様の測定を行い比較してみました。
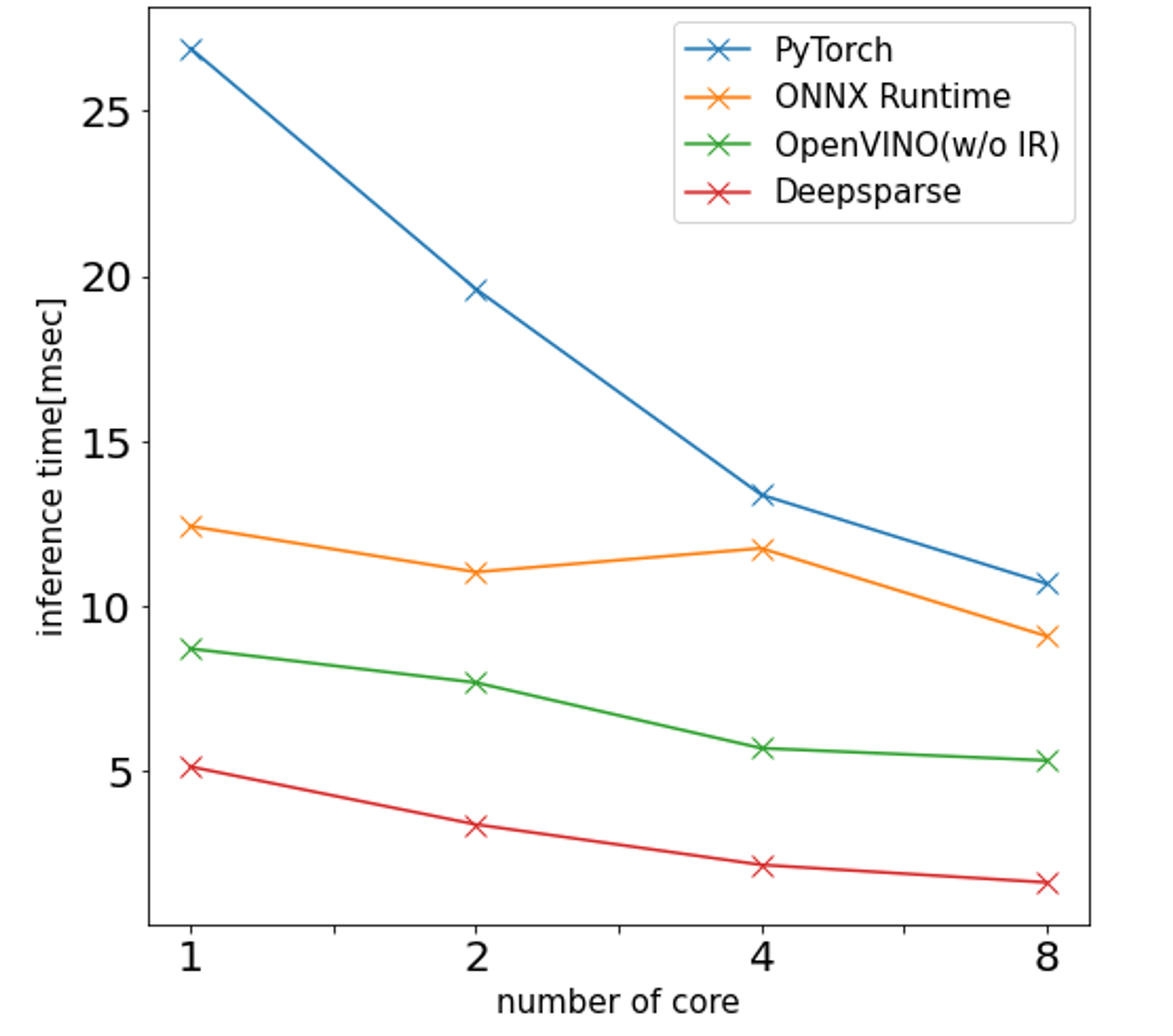
上図は物体検出モデルについて横軸をコア数、縦軸を推論時間としてまとめたものになります。これを見るとコアの数が増えるほど性能が上がっている事がわかります。ただし、コア数に正比例する程改善はしないようです(1コアと8コアの差は最大でも5倍程度でした)。
これらの結果を受けて、AIテスト環境上で動作しているEdge AIライブラリを使ったサービスについてはOpenVINOを使って推論を行うという事になりました。DeepSparseの方が速い傾向があったのですが、C++のAPIがまだFixされてない事からそちらは見送る事になりました(Edge AIライブラリはRust/C++で実装されているため)。
実際に修正を行って変更前後でサービス全体の時間測定もしてみましたが、数倍は速くなっている事が確認できました。
脇見検知サービス
冒頭で例として脇見検知のサービスの処理時間の問題をあげましたが、このサービスについてもOpenVINOを導入して処理時間測定を行ってみました。下図はクエリあたりの各モデルの推論処理時間の導入前後比較ですが顔検出の処理がおよそ1/7程度、脇見検出も1/2程度の処理時間になっている事がわかります。
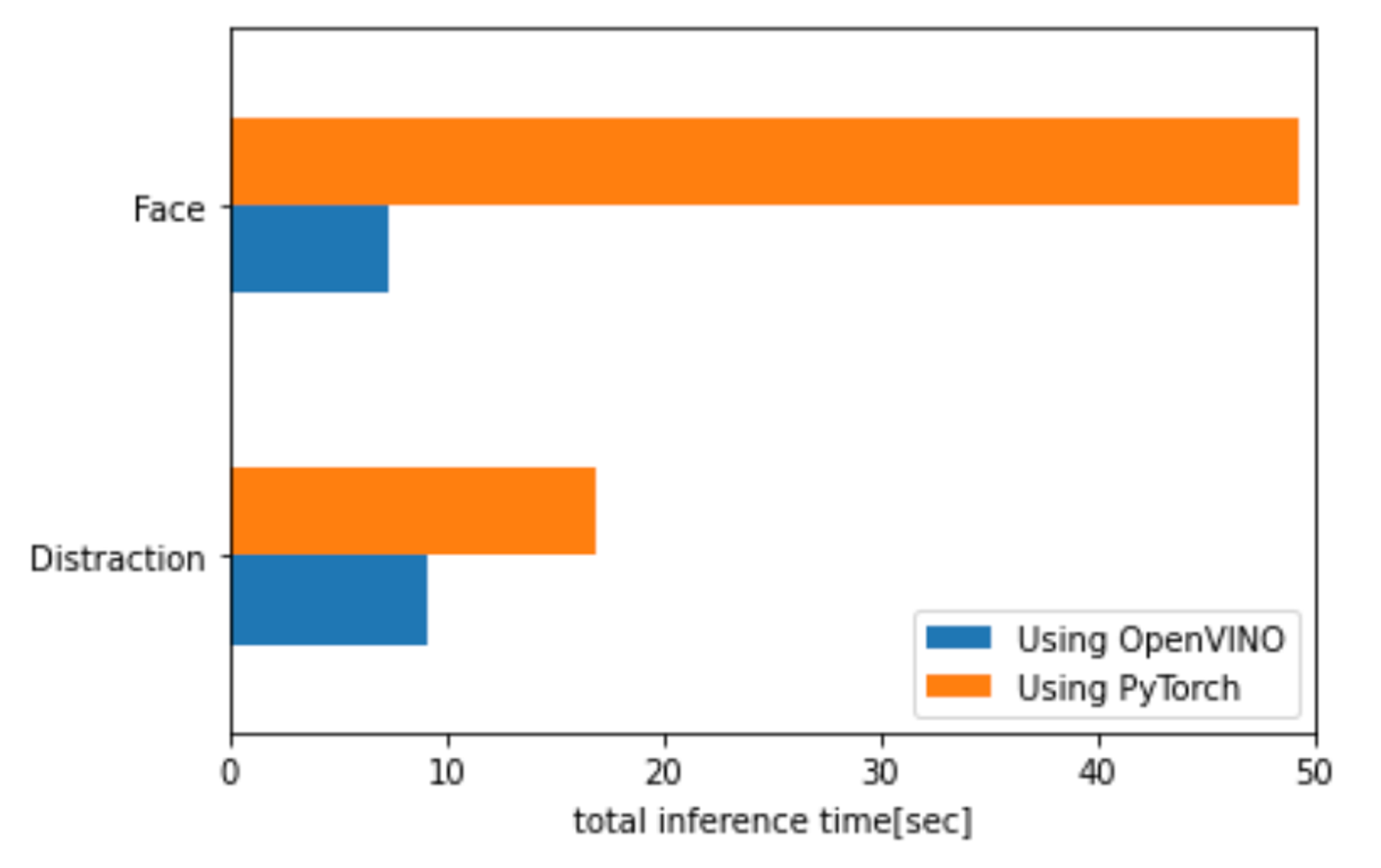
これにより導入前は5分の動画の推論に75秒程度かかっていたのが、導入後は25秒程度とおよそ1/3程度の時間で処理できるようになりました。
このサービスはEdge AIライブラリとは別のサーバ処理向けの重めのモデルを使っている関係もあり、プロダクション環境の全コストから見ても大きい割合を占めていたのですが、この処理時間短縮によりかなりのコスト改善を実現できました。
まとめ
本記事では、CPUを使ったAI推論の速度改善を行うために使える推論エンジンについて紹介するとともに、実際にそれを使ってどの程度速くなるのかという事を実際の事例を交えて説明しました。
今回はなるべく少ない手間で高速化を実現するという事で対応できませんでしたが、OpenVINOのINT8量子化や、DeepSparseのsparsemlやsparcifyを使った学習時のpruning/quantizationを対応すれば更に数倍高速に処理できる事が見込まれます。ただ多かれ少なかれ精度劣化が生じるため、その対応による影響範囲を検証するなど慎重に取り組む必要があります。こちらについても機会があれば取り組んでいきたいと考えています。
*1:VPUというのはVision Processing Unitの略で画像処理やAI処理に特化した計算処理ユニットになります。現在は生産が中止されていますが、Neural Compute Stick 2というUSBスティックタイプのデバイスを見た事がある方は多いと思います。最近一部界隈で話題になったOAK-D-LITEというAIカメラにもこのVPUが搭載されています。
We're Hiring!
📢
Mobility Technologies ではともに働くエンジニアを募集しています。
興味のある方は 採用ページ も見ていただけると嬉しいです。私たちのチームでもエンジニアを募集しています。
Twitter @mot_techtalk のフォローもよろしくお願いします!