

[Engineer Challenge Week] Golangで実装するバックグラウンドダウンロード
ChallengeWeekGoアーキテクチャJanuary 12, 2023
初めましてタクシーアプリ「GO」の管理画面の開発を担当している加藤です。
本記事ではGO管理画面に導入したバックグラウンドダウンロードについて紹介します。
はじめに
本記事ではGO管理画面に導入したバックグラウンドダウンロードについてと設計時に考慮したポイントについて紹介します。
そもそもGO管理画面とはタクシーアプリ「GO」を導入いただいているタクシー事業者様が、「GO」を運用していくため、必要な管理機能を提供しているプロダクトです。
GO管理画面ではお客様の評価や配車履歴などをレポートとしてcsv出力する機能を複数提供しており、今回はそれらのレポートの一部にバックグラウンドダウンロードを導入した話になります。
GO管理画面のバックグラウンドダウンロードとは?
バックグラウンドダウンロードは非同期でダウンロードをする仕組みで、裏で常時起動しているworkerがリクエストを受け取り、ファイル生成処理を走らせつつ、生成後にユーザーがダウンロードできるようになるという仕組みです。
GO管理画面では下記のようなアーキテクチャで構成しております。
概要図
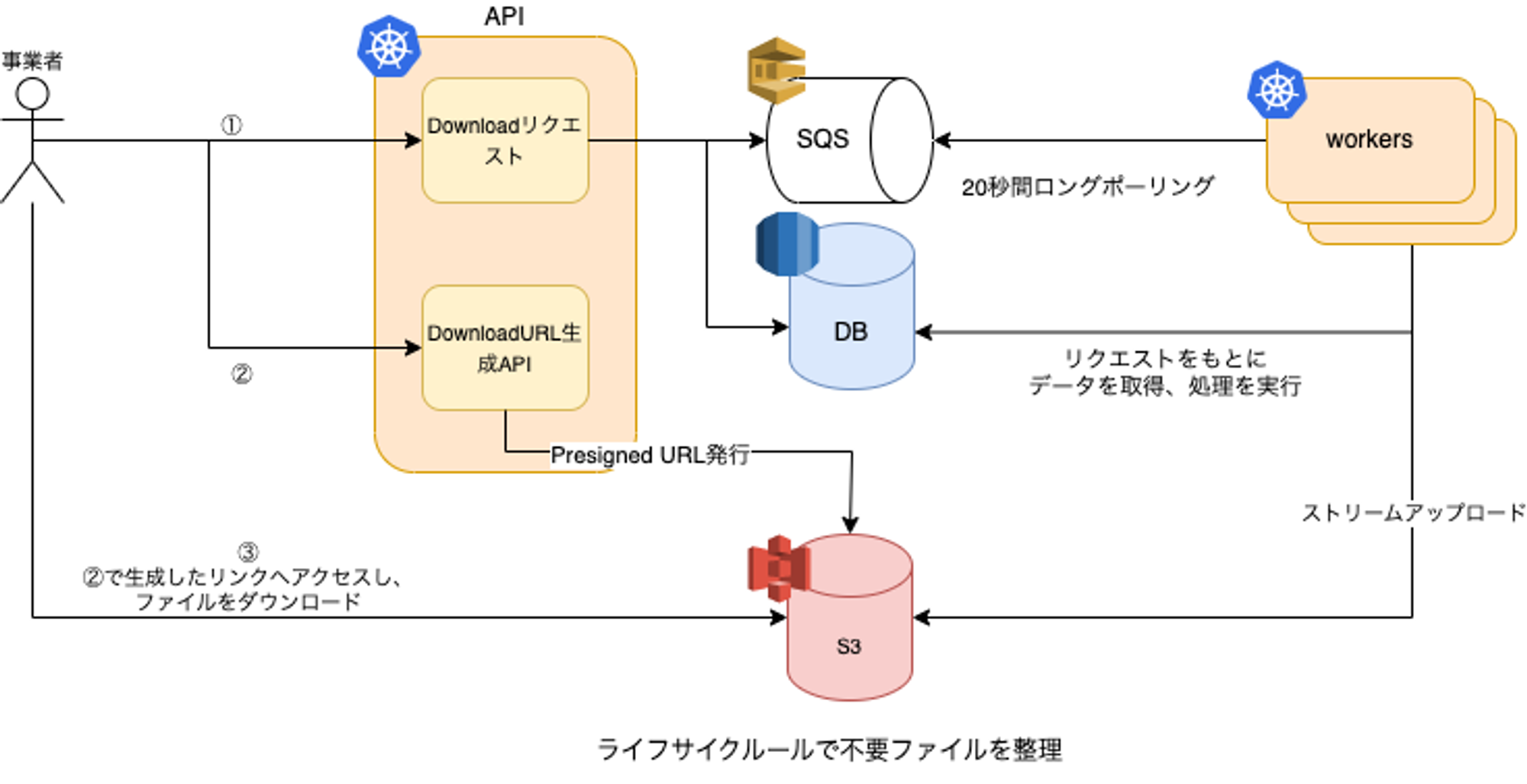
GO管理画面ではインフラはAWSを利用しているため、ファイルを配置するストレージとしてはS3、リクエストを検知するためのキューとしてSQSを採用してます。
また、概要図記載の通りですが、GO管理画面でのバックグラウンドダウンロードの処理の流れとしては以下のようになります。
- APIにダウンロードをリクエストし、キューとDBにダウンロードに必要な情報を書き込む。
- 画面とworkerで並行で下記の処理が進められる。
- worker: キューからリクエストを検知し、ファイル生成とS3へのアップロードを行う。
- 画面: ダウンロードページに遷移し、ファイル生成の完了を待機
- ファイル生成後、S3から対象レポートのPresigned URLを取得
- 取得したPresigned URLを叩いて、レポートをダウンロードする。
GO管理画面でバックグラウンドダウンロードを適用している画面の一例を紹介します。
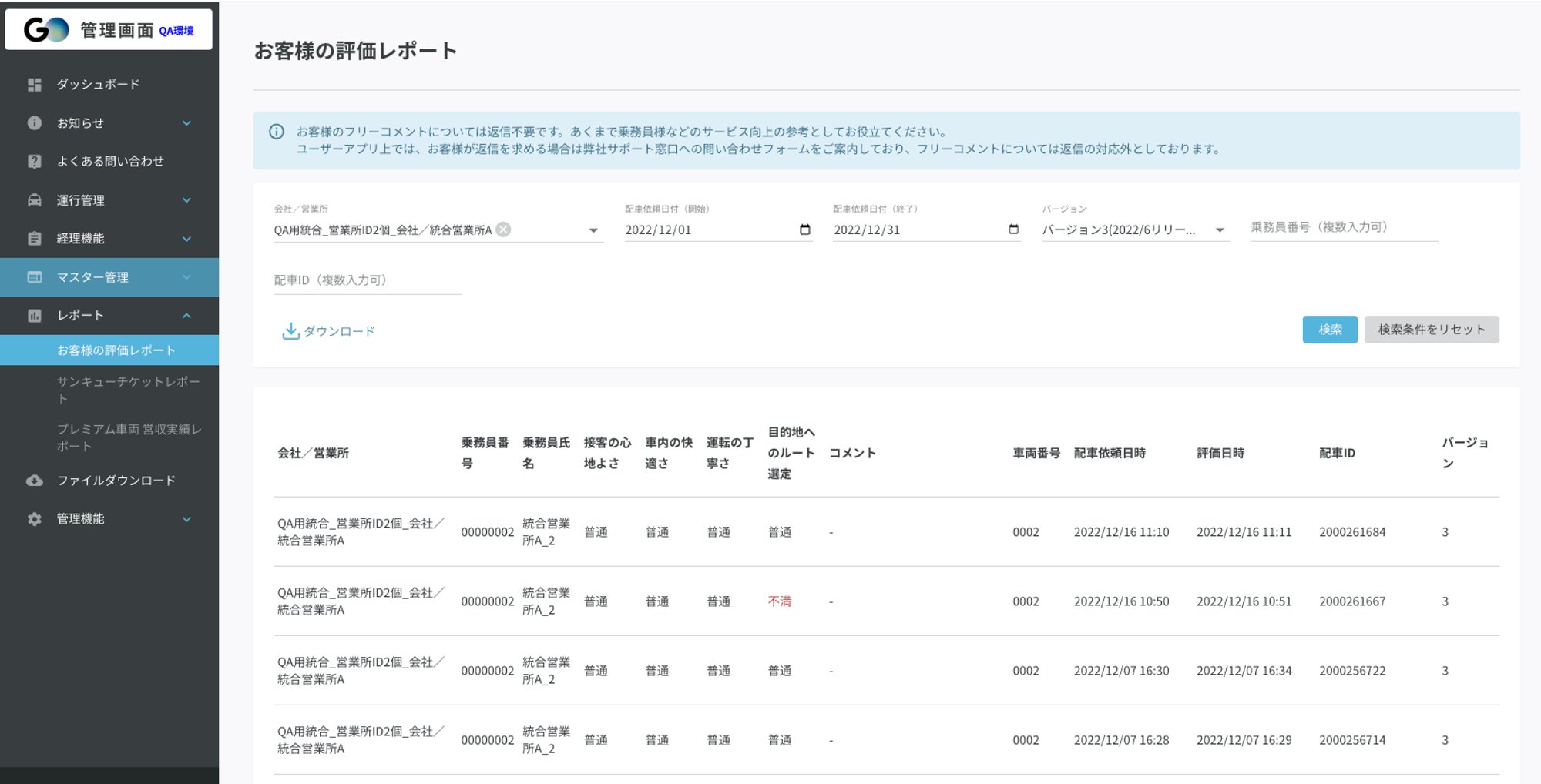
例えば、お客様の評価レポートだとダウンロードを実行するとリクエストが飛び、ファイルダウンロードページへ遷移します。生成完了後にダウンロードボタンが活性になります。
①お客様の評価レポートからバックグラウンドダウンロードのリクエストを送る
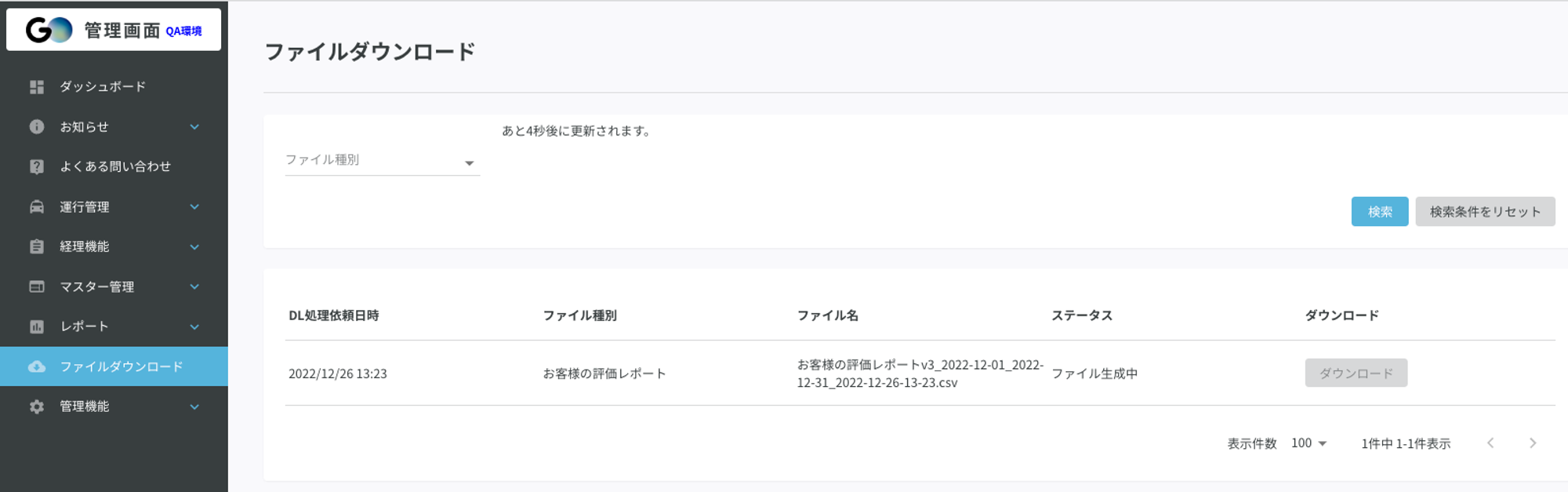
②ファイルダウンロード画面に遷移、workerがファイルを生成
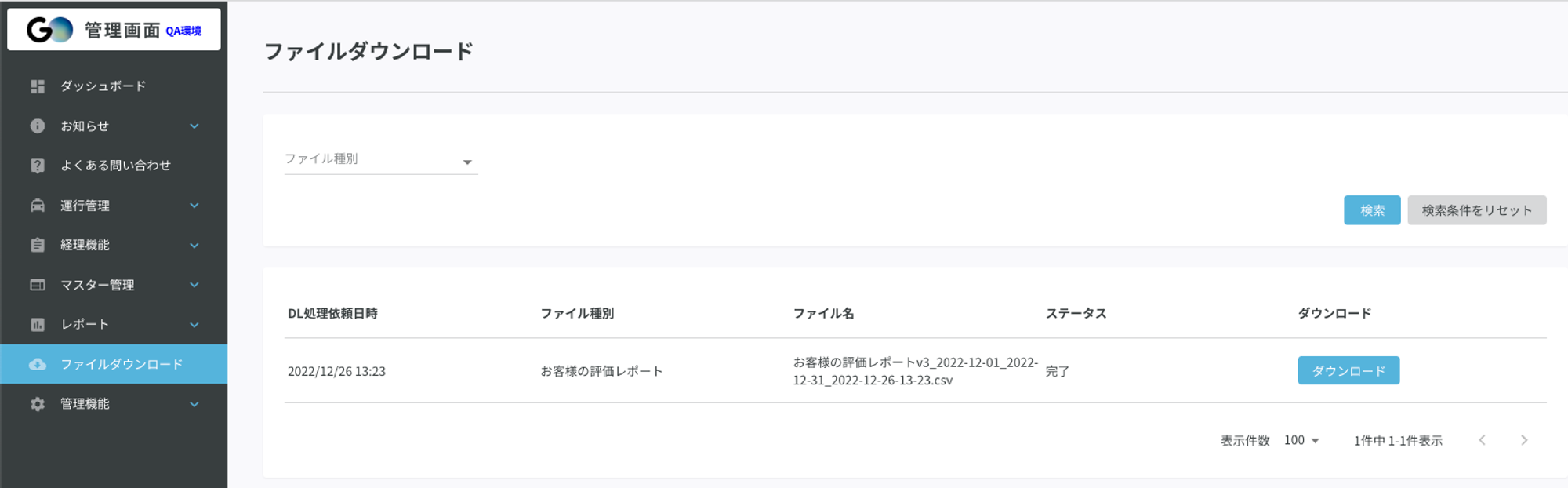
③ファイル生成が完了しダウンロード実行可能になる
バックグラウンドダウンロードにするメリット
csvでレポートをダウンロードする際に、通常のダウンロードではDBやAPIからデータを取得し、それをcsvファイルにリアルタイムで変換してクライアントに返します。
そこまでデータ量が多くなくクライアントに返すまでの時間が数秒程度であれば、それで問題ない(むしろそのほうが実装コスト的にもユーザー的にも良い)ですが、1ファイルで数百MBや数GBという量になってくると時間もかかり、メモリも食うのでサーバー負荷が高くなります。
そこでバックグラウンドダウンロードの仕組みにすることで、サーバーの負荷を軽減しつつ、ユーザーを待たせず自然な流れでダウンロードまで誘導することができます。
実装面でのポイント
実際にバックグラウンドダウンロードのアーキテクチャを構築してみた際にいくつか工夫したポイントがあるので紹介します。
Presigned URL(署名付きURL)でS3から直接ダウンロード
署名付きURLとは、リクエスト時における制限付きの権限と有効期限が設定された URLのことです。また、AWSのS3ではPresigned URLとも言われます。
GO管理画面ではAPI経由でPresigned URLを発行し、S3から直接ダウンロードするようにしております。
そうすることで、次の2点のメリットがあります。
- アプリケーションサーバーをレポートファイルが経由することなく、ダウンロードされるため、サーバーのメモリ消費を抑えることができます。
- クライアントから直接S3を操作させず、有効期限付きのURLを利用してダウンロードさせるため、セキュリティ的にも安全であると言えます。
ストリームアップロード
ストリームアップロードとは一括でデータを処理するのではなく、発生するデータをリアルタイムで処理してS3にアップロードすることです。
(GO管理画面では)csvのレポートを生成するのに次の4ステップを経てS3にアップロードします。
- APIやDBからデータを取得
- csvに整形
- gzip圧縮
- S3へのアップロード
この処理を直列で実行した場合下記のイメージ図のように、各工程の終了を待ち、次の処理を実行していきます。
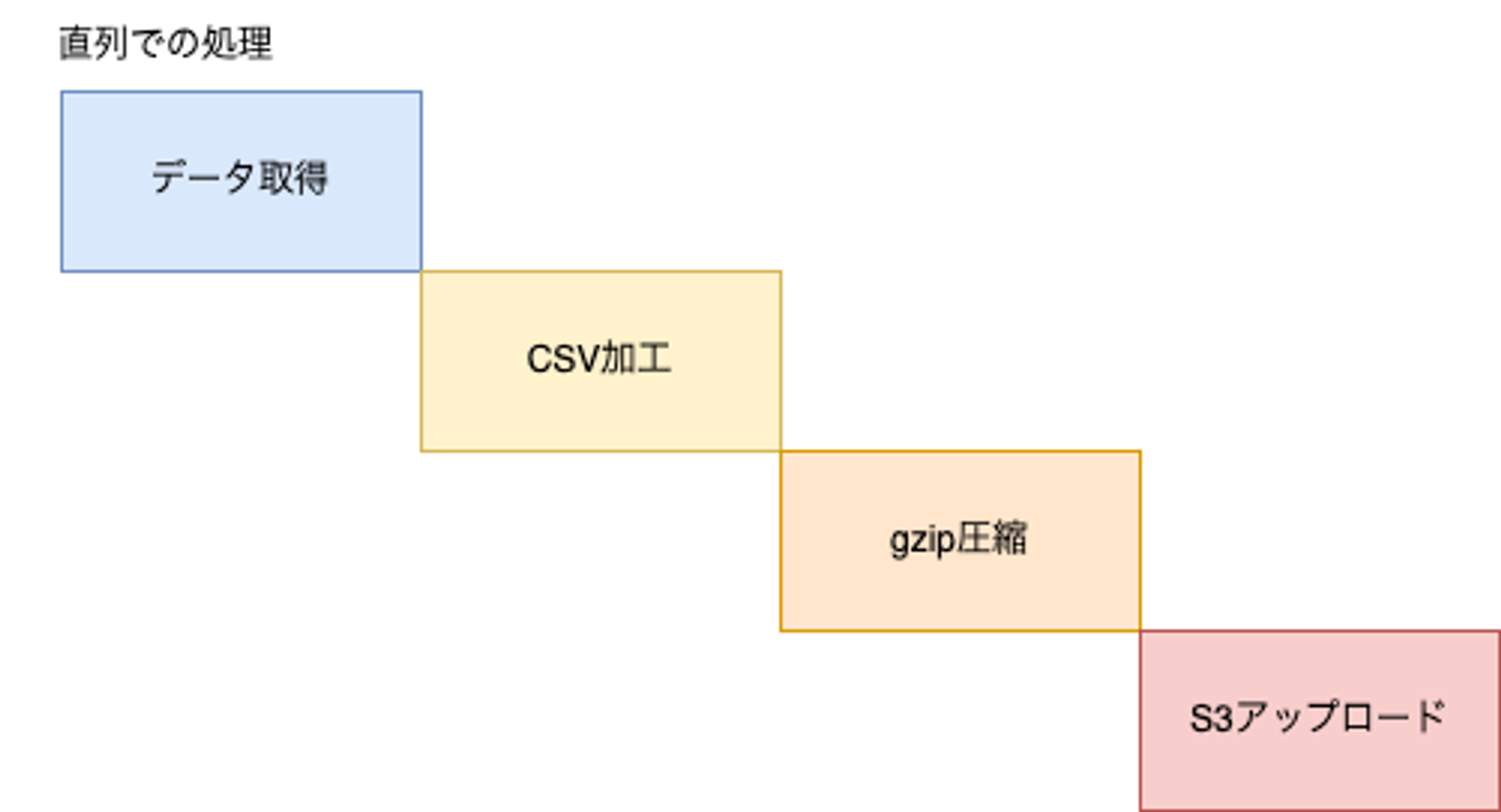
一方、ストリームアップロードでは下記のイメージ図のように各工程の完了を待たず、次の工程に流していきます。
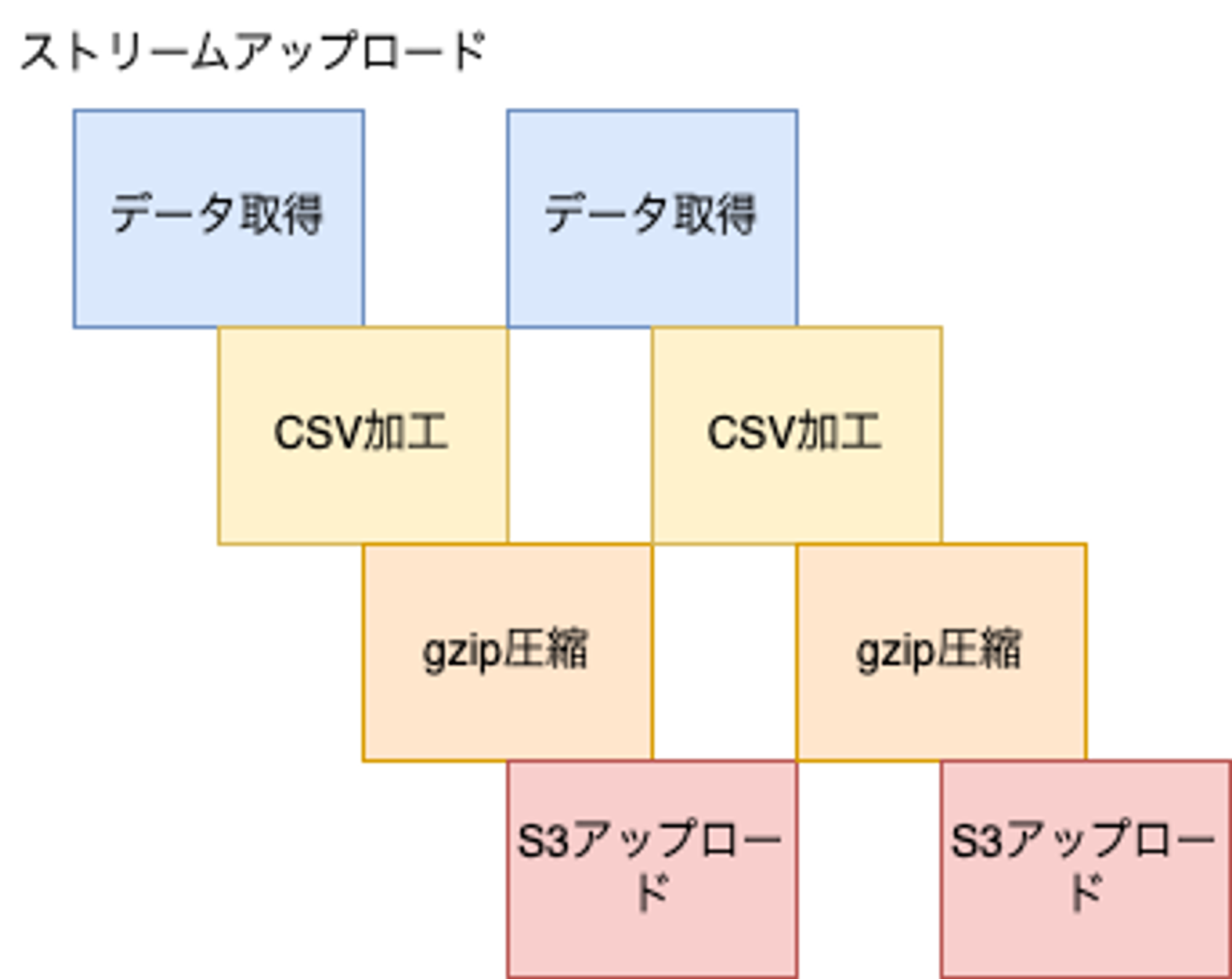
前工程が完了するのを待つ必要がないため直列で処理を行った場合と比較して、効率良くサーバーリソースを活用することができます。
ちなみに、Golangでストリームアップロードを書くにはio.Pipeを活用しパイプを繋いでいくことで実装できます。
io.pipeとは Golangで読み込みと書き込みを並行で進めることを可能にする標準ライブラリです。
io.pipeではメモリ内に同期パイプを作成し、 io.Writer にデータを書き込むと、 直接io.Reader にコピーされ、読み取りができます。
io.Pipeを使った下記のように実装します。
(下記の実装は公式のサンプルコードを参考にしております。)
package main
import (
"fmt"
"io"
"log"
"os"
)
func main() {
r, w := io.Pipe() // io.Reader と io.Writerを生成する
go func() { // 並行処理するためにゴルーチンにio.Writerを渡す
// io.Writerに値を書き込んでいく
fmt.Fprint(w, "some io.Reader stream to be read\n")
w.Close()
}()
// io.Writerに書き込まれるとio.Readerから読み取られる
if _, err := io.Copy(os.Stdout, r); err != nil {
log.Fatal(err)
}
}上記のサンプルコードのように、io.Writer を別のゴルーチンで行うことで、読み込みと書き込みを並行で進めることが可能になります。
また、S3へアップロードするライブラリのインターフェース( s3.PutObjectInput )に前工程の io.Reader を渡し上げることでストリーム処理でS3まであげることが可能です。
(詳細部分の実装は割愛しますが)ストリームアップロードの実装は下記のサンプルコードのようになります。
package main
import (
"context"
"fmt"
"io"
"log"
"github.com/aws/aws-sdk-go-v2/aws"
"github.com/aws/aws-sdk-go-v2/feature/s3/manager"
"github.com/aws/aws-sdk-go-v2/service/s3"
)
func main() {
// S3の初期化処理は割愛
s3Client := NewMyS3Client(cfg)
// ①データ取得 → csv加工
// データの取得処理は割愛
r, w := io.Pipe()
go func() {
defer w.Close()
// 取得したデータを受け取り、csv加工し、wに渡す処理を書く
}()
// ②csvデータ → gzip加工
zipr, zipw := io.Pipe()
go func() {
defer zipw.Close()
// 取得したデータを受け取り、csv加工し、wに渡す
writeSize, err := io.Copy(zipw, r)
if err != nil {
return
}
fmt.Println("書き込こんだサイズ: %d", writeSize)
}()
// ③S3に②のio.Readerを渡し、S3へアップロード
if err := s3Client.Upload("bucket", "key", zipr); err != nil {
log.Fatal(err)
}
}
// 以下はS3クライアントの仮実装。
type S3Client struct {
uploader *manager.Uploader
client *s3.Client
}
func NewMyS3Client(cfg aws.Config) *S3Client {
client := s3.NewFromConfig(cfg)
uploader := manager.NewUploader(client)
return &S3Client{
uploader: uploader,
client: client,
}
}
func (c *S3Client) Upload(bucket, key string, reader io.Reader) error {
if _, err := c.uploader.Upload(context.Background(), &s3.PutObjectInput{
Bucket: aws.String(bucket),
Key: aws.String(key),
Body: reader, // S3のupload用ライブラリのIFにもio.Readerを渡すことができる
}); err != nil {
return err
}
return nil
}S3クライアントの詳細については公式のドキュメントをご参照ください。
Graceful Shutdown
Graceful Shutdownとは、サーバーのプロセスを終了しようとした時に処理中のものがあった場合、途中で処理が切断されてしまうということを防ぎつつプロセスを終了する仕組みです。
GO管理画面ではGolangでGraceful Shutdownを自前で実装して用意しております。
具体的には下記のような制御を行うことでGraceful Shutdownを実現できます。
package main
import (
"context"
"fmt"
"os"
"os/signal"
"syscall"
)
type BackgroundDownload struct {
quit chan struct{}
done chan struct{}
}
func main() {
ctx := context.Background()
interrupt := make(chan os.Signal, 1)
signal.Notify(interrupt, os.Interrupt, syscall.SIGTERM, syscall.SIGHUP)
// 初期化
worker := &BackgroundDownload{
quit: make(chan struct{}),
done: make(chan struct{}),
}
go func() {
// goroutineでworkerを起動する
worker.Start(ctx)
}()
// 停止のシグナルを受けるまで後続処理を止めておく
select {
case <-interrupt:
break
case <-ctx.Done():
break
}
// ①停止のシグナルを受けグレースフルシャットダウンを実行
worker.gracefulStop(ctx)
}
func (d *BackgroundDownload) Start(ctx context.Context) error {
defer func() {
// ⑤doneのチャネルに送信
d.done <- struct{}{}
}()
// 無限ループでworker維持する
for {
select {
case <-d.quit: // ④gracefulStopからチャネルを受け取り、ループを抜ける
return nil
default:
}
fmt.Println("処理を実装する")
}
}
func (d *BackgroundDownload) gracefulStop(ctx context.Context) {
// ②quitのチャネルに送信
d.quit <- struct{}{}
// ③doneのチャネルを受信待ちで止める
<-d.done
// ⑥doneチャネルを受け取りgracefulStopの処理を終了する
}多少複雑にはなりますがこのように実装することによって、処理途中の場合でも完了させてから終了させることができます。
ロングポーリング
SQSはキューにメッセージがあったときに検知できるようにポーリングしておく必要があります。
ポーリングにはすぐにレスポンスが返るショートポーリングと、タイムアウト時間までwaitさせるロングポーリングの2種類があります。
デフォルトではショートポーリング(waitが0秒)で設定されていますが、ロングポーリング(waitを最大20秒)にすることで、タイムアウトの時間まで待つようになります。また、ロングポーリングの特徴としては、queueが途中で来た場合はタイムアウトまで待たずレスポンスを返します。
リクエスト回数を減らし、コストを抑えることができるため、基本的にはロングポーリングが推奨されてます。
ライフサイクルルール
バックグラウンドダウンロードのリクエスト毎にS3へレポートファイルを上げていくとファイル数が増加し続けます。
GO管理画面では1ヶ月以内にリクエストしたバックグラウンドダウンロードのみ表示されるため、それ以前に生成されたレポートに関しては不要となるため、ライフサイクルルールを設定することで自動的に削除されるようにしております。そうすることでS3の容量を減らし、不要なコストを削減してます。
おわりに
本記事ではGO管理画面に導入したバックグラウンドダウンロードについてと設計時に考慮したポイントについて紹介しました。GO管理画面ではバックグラウンドダウンロードを導入することで、重ためのダウンロード処理を効率よく捌くことができるようになりました。
バックグラウンドダウンロードのように非同期の処理をするアーキテクチャを考える際に本記事が参考になれば幸いです。
We're Hiring!
📢
Mobility Technologies ではともに働くエンジニアを募集しています。
興味のある方は 採用ページ も見ていただけると嬉しいです。
Twitter @goinc_techtalk のフォローもよろしくお願いします!