

BigQuery で統計処理を完結させる
AIBigQueryAugust 06, 2021
はじめまして、AI技術開発部 分析グループ の浅見です。
Mobility Technologies(MoT)では、BigQuery上でログの保存やデータマート運用を行い、集計や分析をした上で、LookerやGoogleスプレッドシートで効果検証などをレポート化しています。BigQueryはとても強力なツールなのですが、統計処理を入れようとすると、PythonやRなどの別モジュールを構築する必要があり、メンテナンスコストが発生してしまいます。
🤔
複雑な処理をするならまだしも、単純な統計処理のためにわざわざそこまでしたくない!
そんな時のため、BigQuery内で統計処理を完結させるちょっとしたTipsを紹介します。
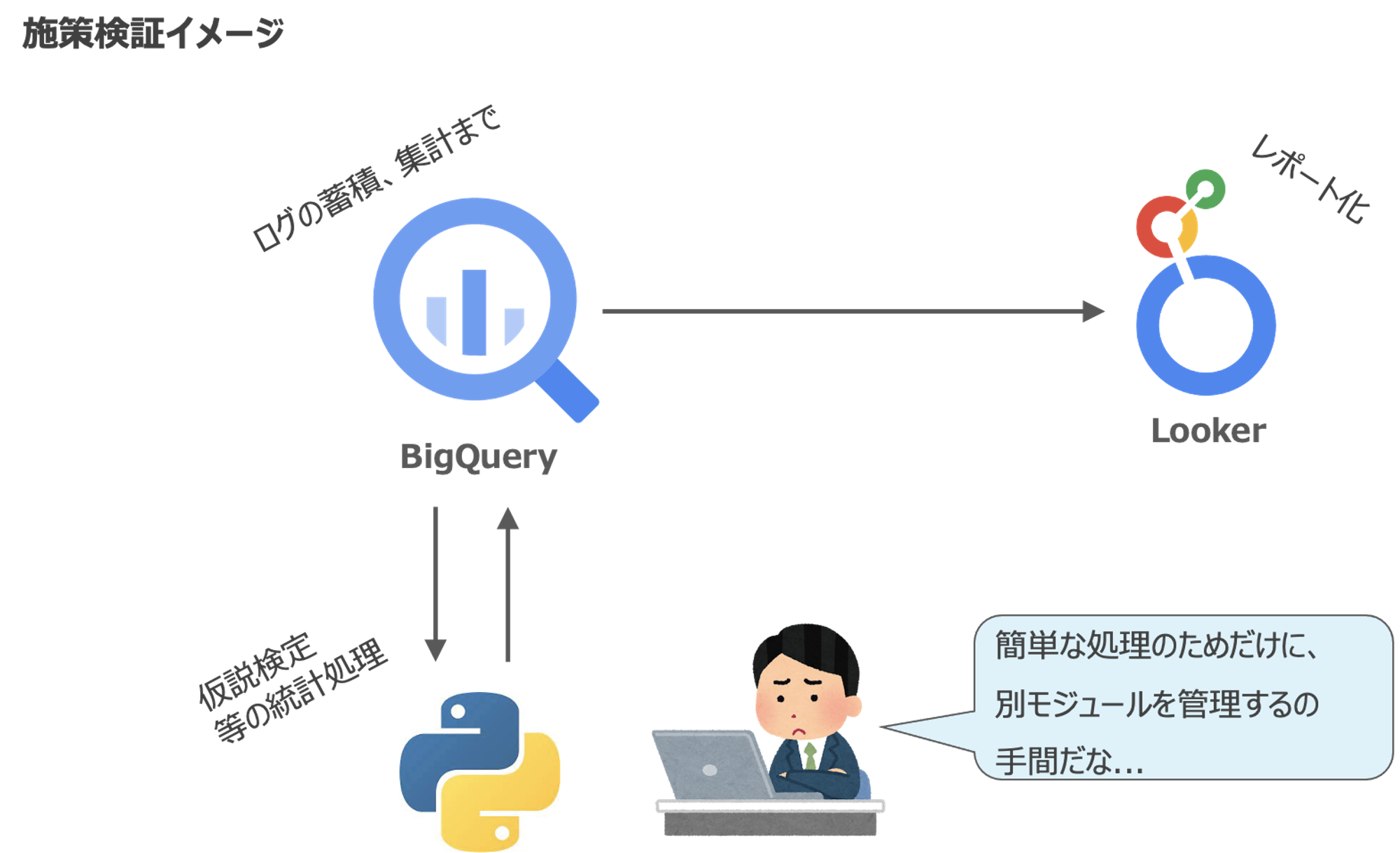
UDFを最大限活用しましょう!
本記事の基本的な発想としては、
BigQueryでは、統計処理を行う関数はそこまで充実していません。例えば、t分布の累積分布関数(CDF)さえ計算できれば、t検定のp値を得ることができるのですが、BigQueryの統計集計関数ではこれを扱うことができません[1]。
しかし、BigQueryでは通常の関数の他にユーザ定義関数(User-Defined Functions、以下UDF)を利用することができます。UDFには SQL型 とJavaScript 型があり、JavaScript型の場合は外部ライブラリを参照することも可能です[2]。
本記事の基本的な発想としては、
💡
CDFなどの計算はJavaScriptの統計パッケージの力を借りて、UDFで独自の統計処理を実装してしまおう
というものです。
以下、簡単な例で確認してみましょう。
作り方
JavaScriptライブラリの選定
- 今回はJavaScriptの統計パッケージJStatを選択し、pre-bundled scriptをUNPKG経由で入手します
- JStatの場合は、 https://unpkg.com/jstat/dist/jstat.js から入手できます
- 取得したパッケージにjstat.jsなど適当な名前を付けて、BigQueryからアクセス可能なGoogle Cloud Storage上に格納します
- 今回の例ではgs://your-bucket-name/javascript_lib_for_bq/jstat.jsに格納したものとします
例1:t検定UDFをつくってみる
平均値の比較というシンプルなケースを想定して簡単なUDFを作ってみます。JStatにはttest関数も用意されていますが、t値の計算まではSQL内の関数で計算し、最後のt分布のCDFの計算のみJavaScriptで計算する方針で作ってみます。
t分布のCDFの計算するUDFは以下のように定義することができます。
両側検定のp値を出力するUDF
UDF tPvalueの入力
| 型 | 意味 | 入力 |
|---|---|---|
| FLOAT64 | 自由度 | dof |
| FLOAT64 | SQLで計算したt値 | t |
CREATE TEMPORARY FUNCTION tPvalue(t FLOAT64, dof FLOAT64)
RETURNS FLOAT64
LANGUAGE js AS """
return Math.min(jStat.jStat['studentt'].cdf(t, dof), 1-jStat.jStat['studentt'].cdf(t, dof))*2
"""
/* OPTIONSでGCSに保存したJavaScript Libraryを指定する */
OPTIONS (
library=["gs://your-bucket-name/javascript_lib_for_bq/jstat.js"]
);
-- 全部 両側 5% になるようにテストデータをセット
-- http://www3.u-toyama.ac.jp/kkarato/2019/statistics/table/t.pdf
with test_data AS (
SELECT 1 AS dof, 12.706 AS t
UNION ALL SELECT 2, 4.303
UNION ALL SELECT 3, 3.182
UNION ALL SELECT 4, 2.776
UNION ALL SELECT 5, 2.571
UNION ALL SELECT 6, 2.447
UNION ALL SELECT 7, 2.365
UNION ALL SELECT 8, 2.306
UNION ALL SELECT 9, 2.262
UNION ALL SELECT 10, 2.228
UNION ALL SELECT 20, 2.086
UNION ALL SELECT 25, 2.060
UNION ALL SELECT 30, 2.042
UNION ALL SELECT 35, 2.030
UNION ALL SELECT 40, 2.021
UNION ALL SELECT 45, 2.014
UNION ALL SELECT 50, 2.009
UNION ALL SELECT 60, 2.000
UNION ALL SELECT 80, 1.990
UNION ALL SELECT 120, 1.980
/*t値の正負を確認*/
UNION ALL SELECT 120, -1.980
)
SELECT
*
,tPvalue(t, dof) AS jstat_t_cdf_result -- 全て5%になるか検証してみましょう
FROM
test_data上記のようにGCS上にJavaScriptのパッケージ(jstat.js)を格納し参照することで、統計処理をBigQuery内で完結することが可能です。
このUDFを利用して、さらに2つの配列からt検定を実施するUDFを作ってみましょう。
2つの配列を入力としてt検定(両側)を行うUDF
UDF tTestの出力
| 意味 | 出力 (STRUCT型) |
|---|---|
| 自由度 (簡易計算) | dof |
| p値 | p_value |
| t値 | t_value |
CREATE TEMPORARY FUNCTION tTest (data ARRAY<FLOAT64>, data2 ARRAY<FLOAT64>)
AS ((
WITH dataset AS (
SELECT
d AS x
FROM UNNEST(data) AS d
)
,dataset2 AS (
SELECT
d AS x2
FROM UNNEST(data2) AS d
)
,stats_table AS(
SELECT
AVG(x) AS avg_x
,AVG(x2) AS avg_x2
,VAR_POP(x) AS var
,VAR_POP(x2) AS var2
,ARRAY_LENGTH(data) AS len
,ARRAY_LENGTH(data2) AS len2
,ARRAY_LENGTH(data) +ARRAY_LENGTH(data2) -2 AS dof -- 注意! これはblog用の簡易自由度計算です
FROM dataset, dataset2
)
,value_table AS (
SELECT
SAFE_DIVIDE((avg_x - avg_x2), SQRT(var/len + var2/len2)) AS t_value
FROM
stats_table
)
SELECT
STRUCT (
t_value
,dof
,tPvalue(t_value, dof) AS p_value -- 上で定義した tPvalue UDF を利用します
)
FROM
stats_table, value_table
));ここではblog用に簡潔にするため、自由度計算を両群の分散はほとんど等しいものとして計算しています[3]。
例2:順位和検定UDFをつくってみる
ここまで理解できれば応用の幅は広がります。例えば、順位和検定を同様の定順で作成してみましょう。
- 実装については Scipy のmannwhitneyuを参考にしました
- 今回はblog用の簡易版のため、配列内に重複がある場合の補正ロジックは入っていません
2つの配列を入力として順位和検定(両側)を行うUDF
UDF rankSumTestの出力
| 意味 | 出力 (STRUCT型) |
|---|---|
| p値 | p_value |
| 配列に重複があったときの警告メッセージ (下記実装は簡易版のため重複時の処理は未実装です) | warning_message |
| u値 | max_u_value |
| z値 | z_value |
/*標準正規分布のCDFを返すUDF*/
CREATE TEMPORARY FUNCTION normalPvalue(z FLOAT64)
RETURNS FLOAT64
LANGUAGE js AS """
return Math.min(jStat.jStat['normal'].cdf(z, 0, 1), 1-jStat.jStat['normal'].cdf(z, 0, 1))*2
"""
OPTIONS (
library=["gs://your-bucket-name/javascript_lib_for_bq/jstat.js"]
);
/*2つの配列を入力とし、順位和検定(両側)を行う*/
CREATE TEMPORARY FUNCTION rankSumTest(data ARRAY<FLOAT64>, data2 ARRAY<FLOAT64>)
AS ((
WITH dataset AS (
SELECT
d AS x
FROM UNNEST(data) AS d
)
,dataset2 AS (
SELECT
d AS x
FROM UNNEST(data2) AS d
)
,rank_dataset AS (
SELECT
*
, RANK() OVER (ORDER BY x ASC) AS rank
FROM
(
SELECT *, 1 AS label FROM dataset
UNION ALL
SELECT *, 0 AS label FROM dataset2
)
)
,u_value_table AS (
SELECT
label
,SUM(rank) AS rank_sum
,COUNT(rank) AS cnt
,SUM(rank) - COUNT(rank)*(COUNT(rank)+1)/2 AS u_value
FROM rank_dataset
GROUP BY label
)
,result AS(
SELECT
max_u_value
,(max_u_value - mu - 0.5)/sigma AS z_value -- 0.5は連続値補正
,normalPvalue((max_u_value - mu - 0.5)/sigma) AS p_value -- 両側test
FROM (
SELECT
MAX(u_value) AS max_u_value
,CAST(ROUND(EXP(SUM(LN(cnt)))/2) AS INT64) AS mu -- EXP(SUM(LN(cnt))) = m + n
,SQRT(EXP(SUM(LN(cnt))) * (SUM(cnt)+1)/12) AS sigma
FROM u_value_table
)
)
,duplicated_check AS (
SELECT
COUNT(x) - COUNT(DISTINCT x) AS duplicated_cnt
FROM
rank_dataset
)
SELECT
STRUCT (
max_u_value
,z_value
,p_value
,CASE WHEN duplicated_check.duplicated_cnt> 0
THEN "重複データがあり検定結果に影響を与える可能性があります"
ELSE Null
END AS warning_message
)
FROM
result
,duplicated_check
));まとめ
上記のような統計的仮説検定以外にも、
- 簡単な回帰(重回帰)モデルの構築 [4]
- 有限変動信頼性理論 [5]
などにも拡張することが可能です。
このように外部パッケージを参照することで、BigQuery内で簡単な統計処理を完結させることができ、PythonやR用に別途システムを構築するといったエンジニアリングコストを節約することができます。
この記事をもとに皆様のBigQueryライフがまた少し快適になれば幸いです。
お知らせ
今回は仮説検定の細かい実装効率化の話をさせてもらいましたが、AI技術開発部分析グループでは、
- A/Bテストや準実験の設計支援や効果の推定・可視化といった統計的因果推論タスク
- 顧客理解促進のための顧客属性の推定タスク
- 需供のシミュレーションなど
データによって意思決定を適切にサポートすべく日々チャレンジしています。
📢
ご興味のある方は 採用ページ からお気軽にご連絡いただければと思います。
脚注
[1] 2021年8月現在 詳細については公式ホームページを参照
[2] 公式ホームページ: ユーザー定義関数を参照
[3] Welch's t-testの場合、本来は、サタスウェイトの公式(Satterthwaite equation)に従って計算すべきです。詳しくは以下の教科書を参照
[4] BigQuery MLで重回帰の構築自体は可能ですが、各係数の統計値(p値など)を得るためには、UDFを構築する必要があります
[5] 信頼性理論(credibility theory)とは、
- ある指標を推定するのに、できるだけ個別の実績データを活かしたい
- しかし、実測値をそのまま推定値とみなせるほどの観測値を有していない
のような場面で、「実測値をどの程度信頼していいか、信頼できないのであればどのように補正すればよいのか」を考えるリスク理論(損害保険数理)の一つ。その中でも最も古典的なものが、有限変動信頼性理論(limited fluctuation credibility theory)。詳しくは以下の教科書を参照
- 岩沢宏和(2010)『リスク・セオリーの基礎』培風館