

BigQuery JSON型によりログの効率化は可能か?
AIBigQueryMarch 20, 2023
AI技術開発部の老木です。今回、分析ログの増大が課題となりJSON型の導入を検討しました。分析ログをJSON化した際に問題となる配列の扱いについて紹介します。
適当に作ったログがでかすぎる。ログを出力・分析する人間によくある悩みではないでしょうか。そこで、大きすぎるログの容量削減にBigQueryのJSON型が利用できないかを検討しました。
課題
弊社では分析ログとしてJSONを格納した文字列を出力してきました。分析ログはスキーマの変化が激しく、そのたびにテーブルのスキーマ変更をする手間を避けるためです。
例えば、配車ロジックのログでは、以下のようなフォーマットのログが出力されます。これは、リクエストと車両をマッチングする際に、そのリクエスト情報と周辺にいた車両情報を含んでいます。このリクエスト情報が増えたり、車両情報が増えたり減ったりといったスキーマ変更が生じます。
{
"matching_ts": "2023-03-13T07:00:44Z", //マッチング時刻
"request": {
"request_id": 1,
"creation_time": "2023-03-13T07:00:38Z", //リクエスト作成時刻
...(その他リクエスト情報)
},
//周辺の車両情報
"cars": [
{
"car_id": 100,
"meter_status": 2,
...(その他車両情報),
//車両とリクエストの間の情報
"distance": 357
},
{
"car_id": 101,
...
}
]
}このログが1週間で2TBずつ蓄積しており取り回しが悪い状況になっていました。 その上、一部の情報にアクセスする際にもすべてのデータが読み出されていました。つまり、request_idだけ欲しくても、car_idやdistanceといった情報が読み出され課金されます。 結果、「1週間の中でdistanceの平均を出す」といった単純なクエリでもしっかり2TB課金されてしまいます。
とりあえずJSON型にしてみる
先ほどのフィールドをJSON型にしてみます。BigQueryのJSON型は、明確にJSONを格納するデータ型であり、
- 簡便なインターフェイス
- 一部要素にのみアクセスする際に読み込みバイト数が削減される
といった恩恵がある比較的最近の機能です。
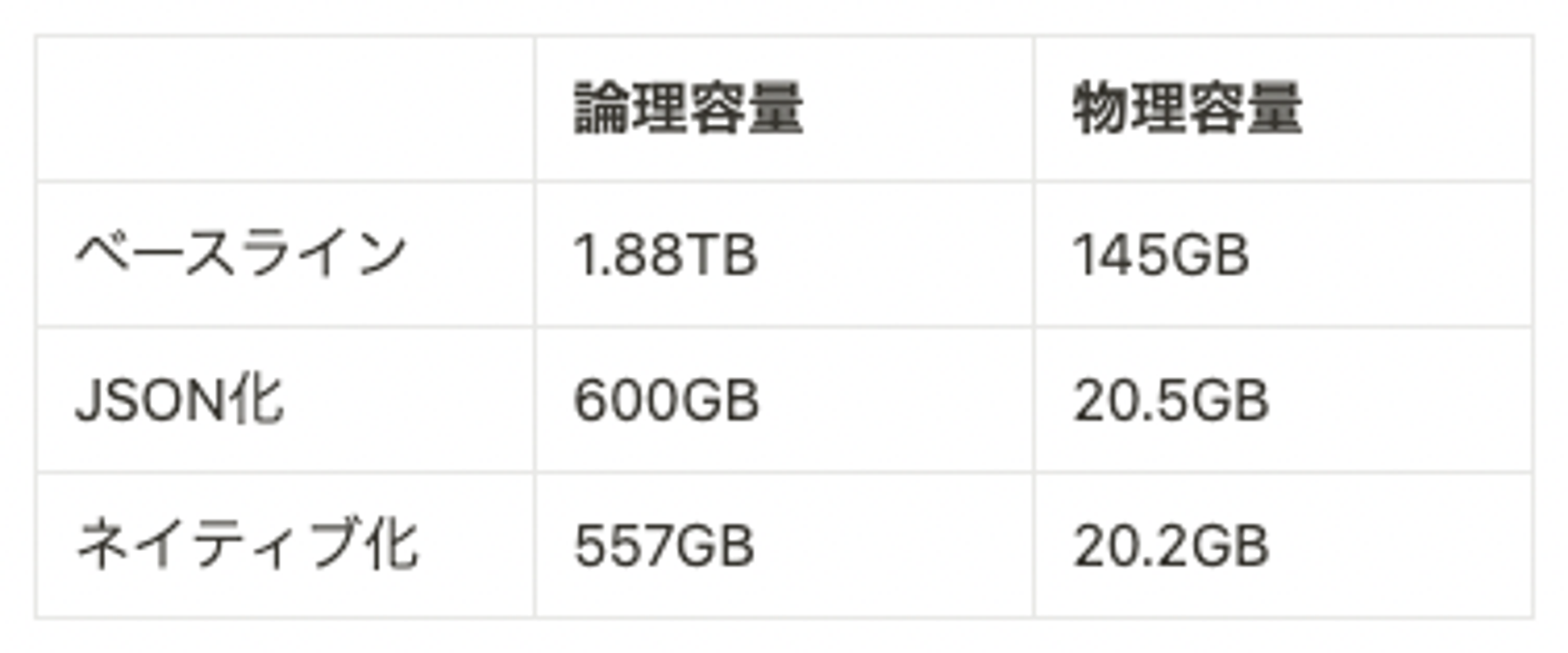
このJSON型にデータ型を変更しただけで、大幅に容量が低下しました。特に最近の料金プランではストレージ容量は物理容量で課金されるため、ストレージ料金が1/7程度に低下しました。 ネイティブ化は、JSONをパースし、すべての型をint64やstringといった型に変換したものです。これを見るとJSON化は手動で型を対応づけた際とほとんど同等の容量を達成していることがわかります。
次に、分析時の性能を見るため平均distanceを出してみます。
with base as (
SELECT
json_extract_array(payload, "$.cars") as targets
FROM json_table
)
select
avg(int64(t.distance)) as distance
from base, unnest(targets) as tこのとき、問い合わせ時の性能は以下のようになります。ベースラインでデータのフル読み込みが走ってしまっているのは想定通りですが、JSON化した場合もすべてのデータが読み込まれてしまっています。
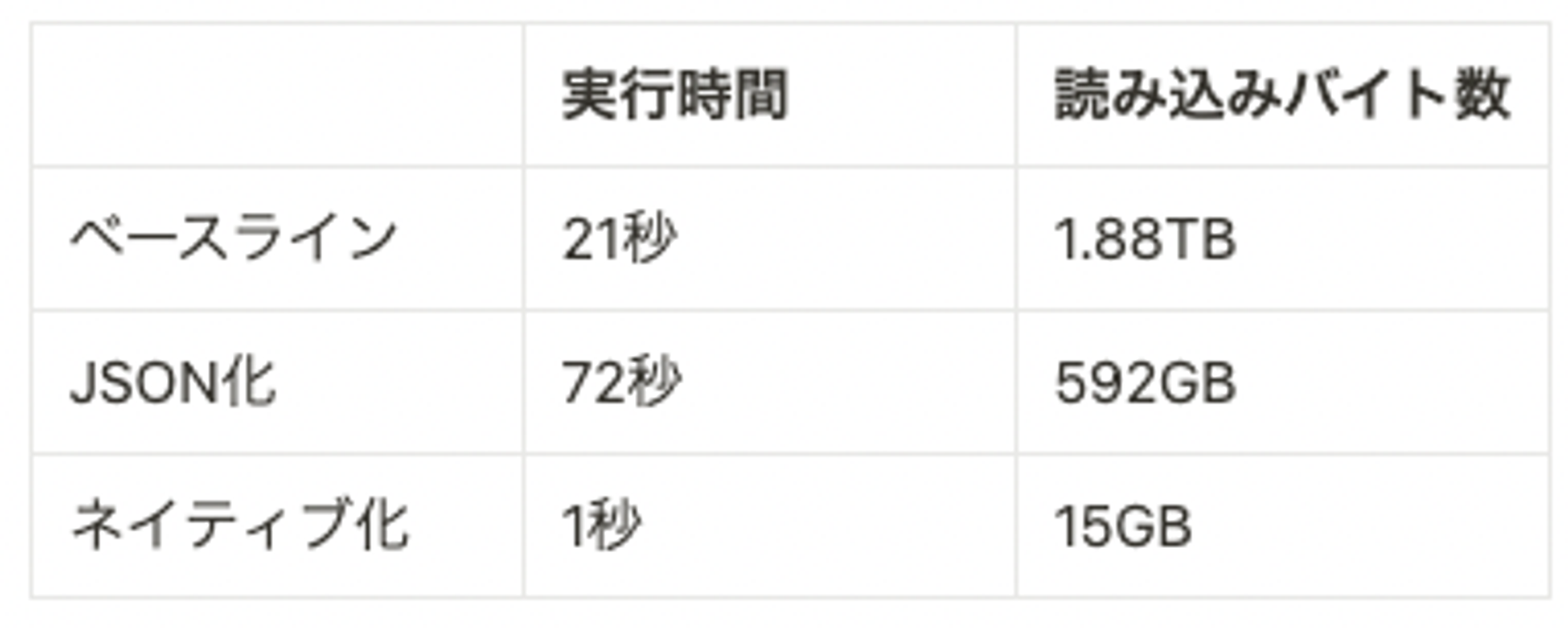
JSON型の読み込みバイト数が削減される、というのは誇大広告だったのでしょうか?
JSON型で読み込みバイト数を減らすには
読み込みバイト数が減らなかったのはJSON型において、構造体の配列 (array of structs: AoS) へのアクセスが最適化されていないためです。 JSON型において、構造体が配列に含まれている場合、その構造体の一部要素にアクセスすると、構造体のすべての要素が読み込まれてしまいます。(公式問い合わせ結果)
回避策として考えたのは、
- JSON型内部に配列を持たせられないので、JSON型のArrayを作る
- JSON型で構造体の配列でなく、配列の構造体 (structure of arrays)を持つ
- 配列の要素ごとに個別でログを出力することで、JSON型に配列が含まれないようにする
です。
JSON型のArrayを作る
ここまでログの構造として、複数のcarsを一つのJSON型に入れていました。これを一つのcarを一つのJSON型に格納し、そのJSON型のArrayをBigQueryに持たせるようにします。
"cars": [
{
"car_id": 100,
"meter_status": 2,
...(その他車両情報),
//車両とリクエストの間の情報
"distance": 357
},
{
"car_id": 101,
...
}
]つまり、一つのJSON型に含まれる要素は、以下のようになり配列をJSON型から追い出すことができます。
{
"car_id": 100,
"meter_status": 2,
...(その他車両情報),
//車両とリクエストの間の情報
"distance": 357
}しかし、このように表現してもdistanceにアクセスすると、すべての要素が読み込まれてしまうことがわかりました。Arrayに含まれるJSON型へのアクセスも残念ながら最適化されていないようです。
JSON型で構造体の配列でなく、配列の構造体を持つ
こちらはデータの持ち方として、以下のように要素ごとの配列を持ってしまうやり方です。 おそらく読み込みバイト数の問題は解消できますが、分析時に使いづらいデータ構造ではあるので、今回は採用を見送りました。
"car_ids": [100, 200, ...]
"distances": [357, 426, ...]配列の要素ごとに個別にログを出力する
これまではリクエストとその周辺にいる車両情報を一つのログエントリに出力してきました。これを、リクエストとその周辺にいる車両一台ごとに一つのログエントリを出力するようにします。つまり、一つのリクエストに対して以下のようなログが車両台数分出力されます。
{
"matching_ts": "2023-03-13T07:00:44Z", //マッチング時刻
"request": {
"request_id": 1,
"creation_time": "2023-03-13T07:00:38Z", //リクエスト作成時刻
...(その他リクエストの属性)
},
//周辺の車両情報
"car": {
"car_id": 100,
"meter_status": 2,
...(その他車両情報),
//車両とリクエストの間の情報
"distance": 357
}
}実験結果は次の表の通りです。この方式のデメリットは明らかで、リクエスト情報が重複して複数のログにあらわれてしまうため、論理容量・物理容量は増大します。一方で、読み込みバイト数は大幅に削減できており、データを部分的に読み出せていることがわかります。
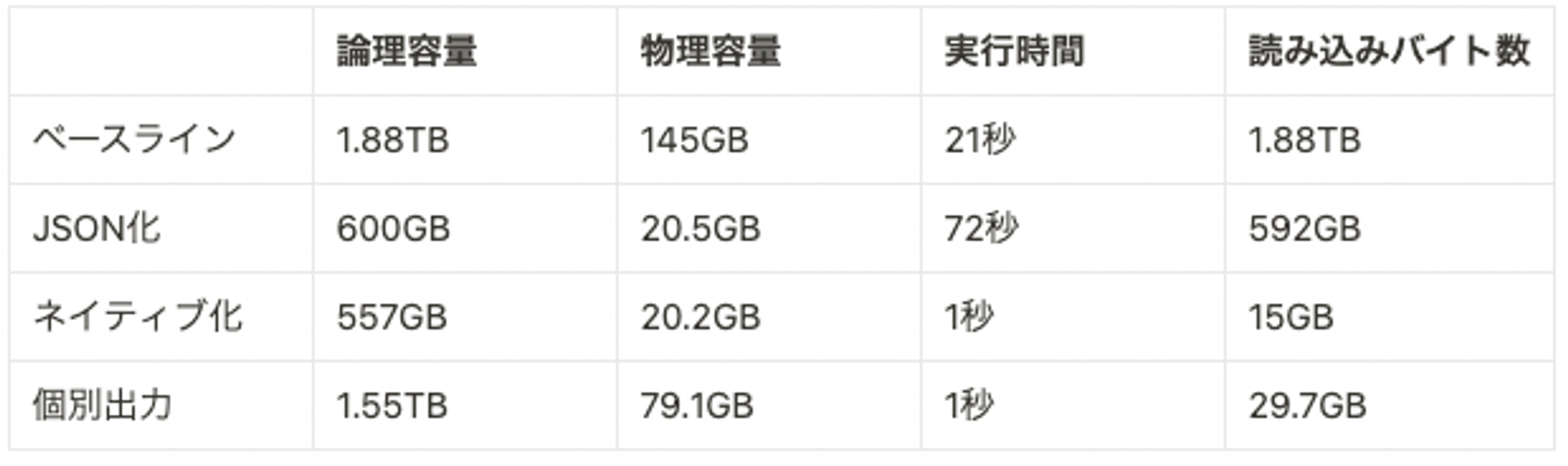
重複して出力される部分の容量が小さいログデータであれば、この方式が優れています。
まとめ
JSON型の利用は柔軟なスキーマのログデータ出力を促進します。 実験から、JSON型はスキーマによる型付けと同等のサイズを達成できることがわかりました。 一方で、JSON型の構造体の配列は読み出しの最適化がなされておらず、分析で頻繁に読み出すには適していませんでした。JSON型を使う際は、内部に構造体の配列を持たせないのが無難でしょう。
We're Hiring!
📢
Mobility Technologies ではともに働くエンジニアを募集しています。
興味のある方は 採用ページ も見ていただけると嬉しいです。
Twitter @goinc_techtalk のフォローもよろしくお願いします!