

JapanTaxi Translator 開発秘話
行灯LaboハードウェアFebruary 07, 2020
💁🏻
※本記事は Mobility Technologies の前身である JapanTaxi 時代に公開していたもので、記事中での会社やサービスに関する記述は公開当時のものです。

タクシー車両に搭載される『JapanTaxiタブレット』は、日本語/英語/中国語(簡体字・繁体字)/韓国語の多言語表示に対応する他、アジアのお客様が多く使用する決済アプリ『Alipay』『WeChat Pay』のキャッシュレス決済に対応しております。音声通訳機能『JapanTaxi Translator by POCKETALK』は、ソースネクストのAI通訳機『POCKETALK(ポケトーク) W』の翻訳機能をSDK化し『JapanTaxiタブレット』へ搭載したもので、音声通訳を行い、翻訳文を乗客側と乗務員側両方のタブレットそれぞれに表示・読み上げする機能です。現在は訪日外国人のお客様が多く乗車される京都と東京の一部車両で実証実験中です。
実証実験で得られたフィードバックの中でSpeechToText(音声から文字を起こす部分)で認識率が非常に悪いことがわかりました。今回は課題を解決した方法をお話したいと思います。
どのような対処をしたのか
まずは、なぜ失敗しているかを探るべく問題を切り分けて、「話す人の距離、音量、環境雑音」などを擬似的に発生させ検証を行いました。
ソフト要因なのかハード要因なのか切り分け
POCKETALK SDKはJapanTaxi DRIVER’S(乗務員向けタブレット)と、JapanTaxiタブレットで双方向にやり取りするため、両方に搭載されており各種機能が扱えます。JapanTaxi DRIVER’S側でのSpeechToTextの認識率はあまり悪くなく、JapanTaxiタブレットの認識率だけが悪い結果となり、ハード起因、もしくはロジックに問題がある可能生が出てきました。
どのくらいの距離から失敗するのか検証
まず、環境音はタクシーが走っている時(50dp~60dp)と止まっている時、発音者(70db~80db)で各言語(英語、中国語、韓国語)を10回づつ検証しました。結果、距離が離れるほど、認識率、翻訳率が悪くなっていく結果となりました

.
なぜその距離から失敗するのか
そこで以下のように仮説を立ててみました。
ロジックに問題がある?ノイズ?音声の音量に問題ある?
ロジックに問題がある?
検証中のファイルを全て取っていたのですが、音声ファイルを再生して聞いていると早送りで録音されているようなファイルがあることに気づきました。
処理を確認すると、音声ファイルを作成するスレッドの指定とrawからwaveファイルに変換するロジックに問題があり、早送りになっていました。
ノイズ
以下が音源の波形図です。認識しなかった音声ファイルを解析してみました。
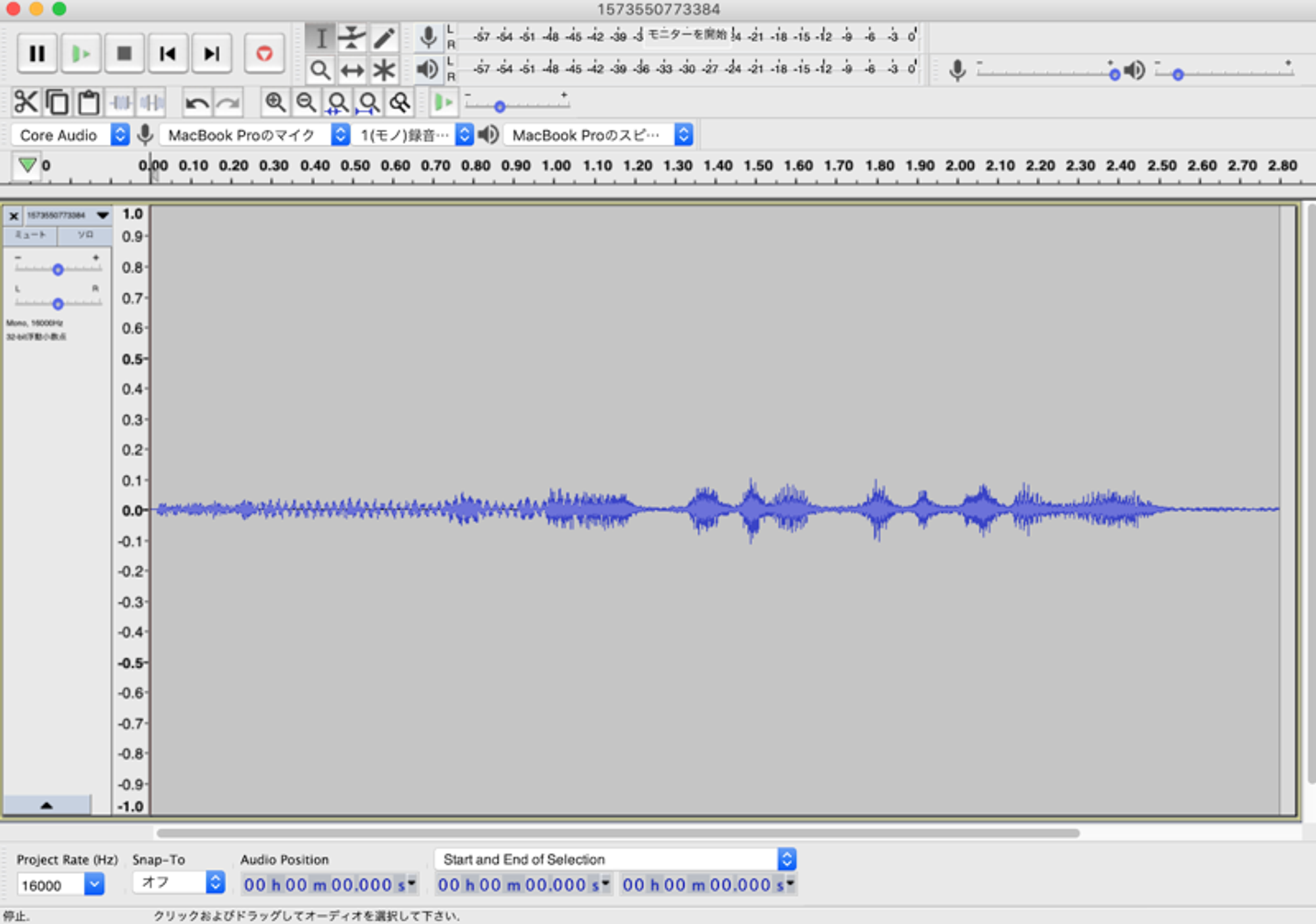
ノイズカットした波形図
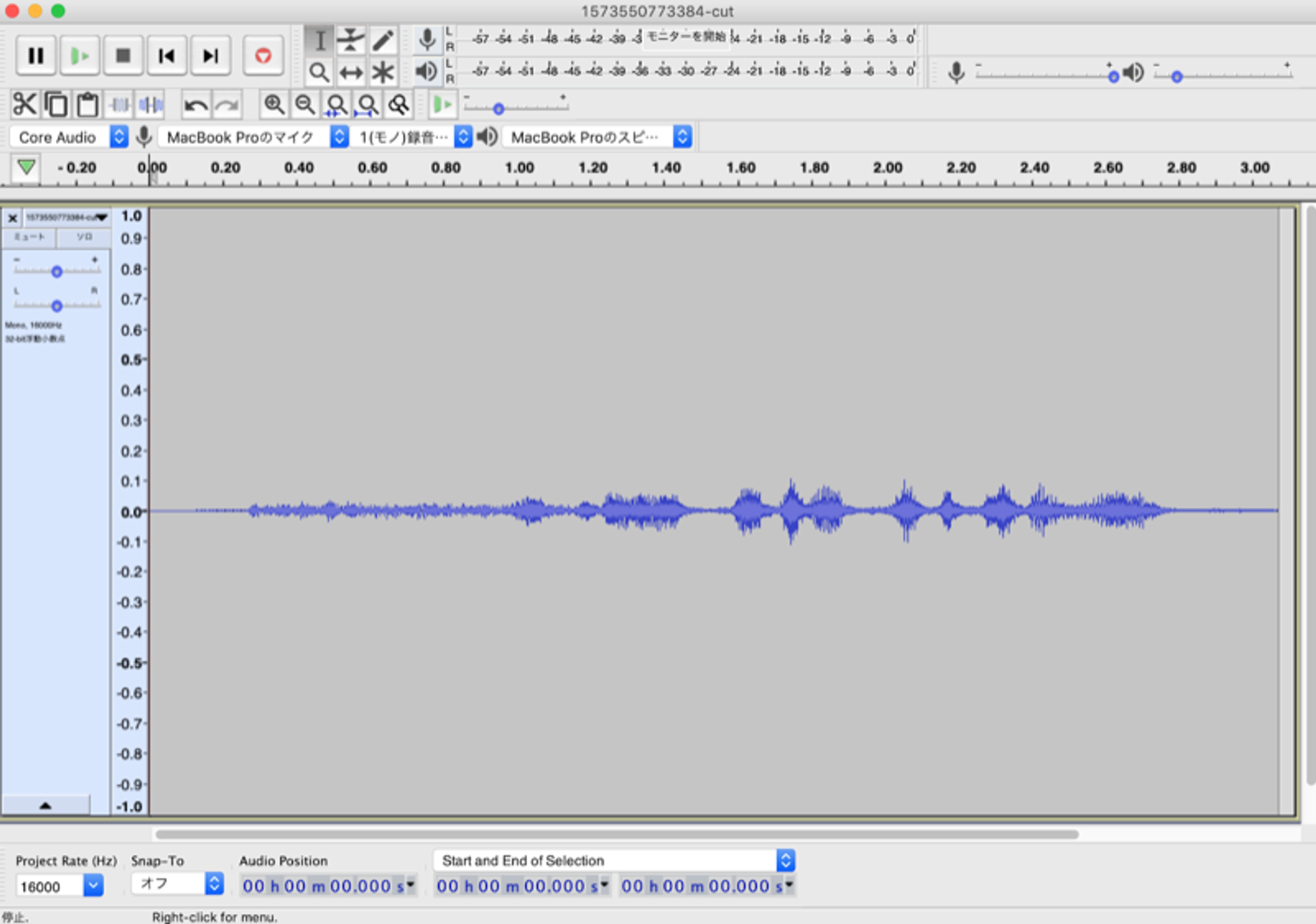
ノイズカットはffmpegを利用し、superequalizerというフィルターをかけました。
ちょっと細かく見辛いですが、開始1秒間くらいまでの、波が穏やかな感じになっています。ツールはAudaCityを使っています。
実際にノイズカットしたものをSDKに渡してみましたが、認識率が少し上がりました。
音声の音量に問題ある?
元の音源をノーマライズという手法で音量をあげてみました。ffmpegでvolumedetectつかってmax_volume取得してvolumeフィルタで音量を0dbに調整しました。
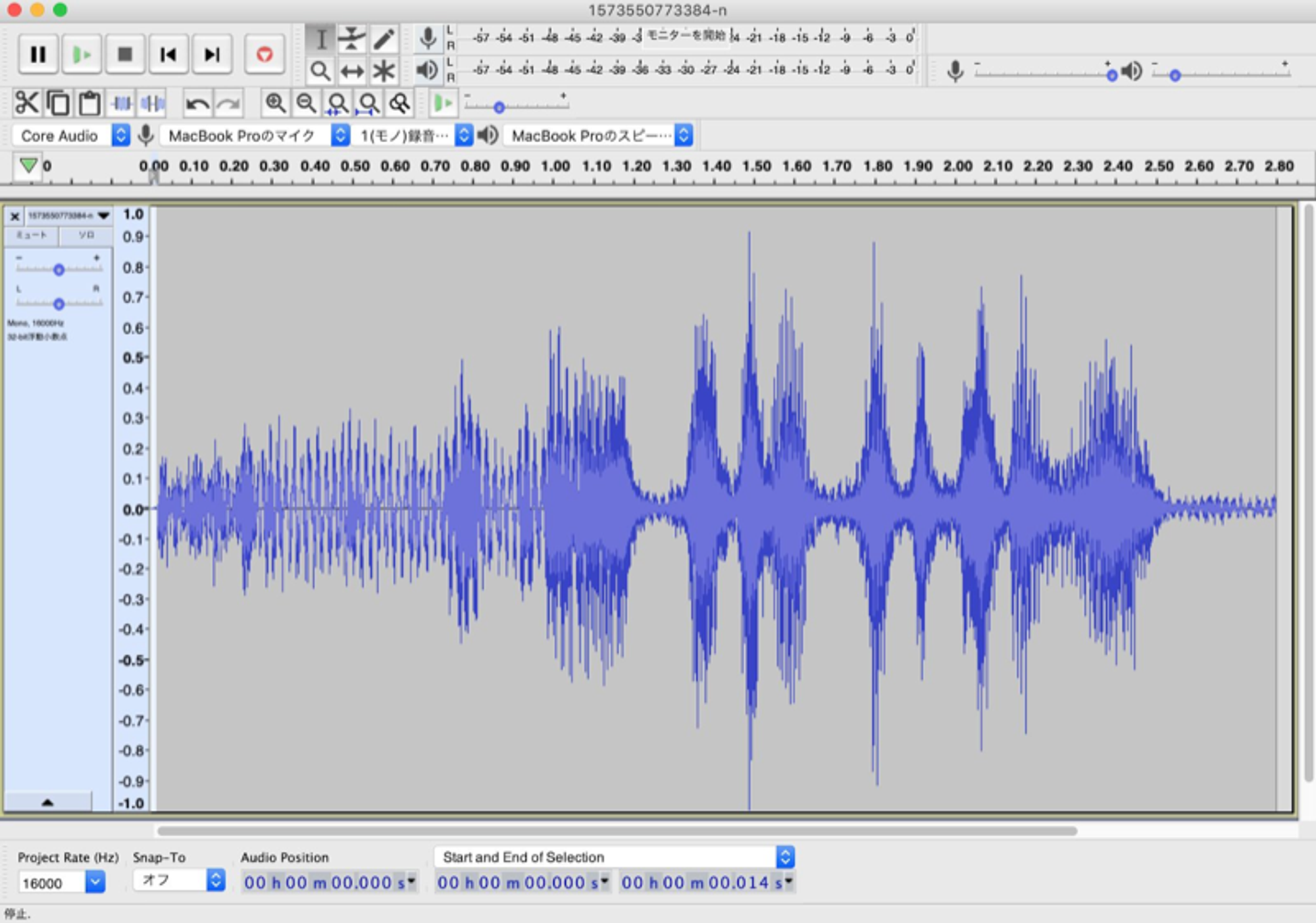
音声の音量は上がっていますが、同時にノイズまで、波が増えてしまっているような結果となりました。そのため、認識率は改善しませんでした。
対応した内容
以上のことから、ロジックの修正、ノイズカットを盛り込んで効果が改善されるか、モニタリングしてみることにしました。またSDKが対応できている音量も検証できたため、閾値を設けて音量に問題があれば、 エラーを表示するようにしました。Androidではffmpegを利用する場合Jniを介す必要があったのですが、mobile-ffmpegというライブラリを利用して実装を行いました。
結果
現在、対応した内容をリリースしモニタリング中です。
💁🏻
※本記事は Mobility Technologies の前身である JapanTaxi 時代に公開していたもので、記事中での会社やサービスに関する記述は公開当時のものです。
Mobility Technologies では共に日本のモビリティを進化させていくエンジニアを募集しています。話を聞いてみたいという方は、是非 募集ページ からご相談ください!