

Netflix社のMLOpsの事例を紹介します
行灯LaboMLOpsNovember 20, 2019
💁🏻
※本記事は Mobility Technologies の前身である JapanTaxi 時代に公開していたもので、記事中での会社やサービスに関する記述は公開当時のものです。


2019年9月24日にニューヨークで開催された機械学習運用カンファレンス「MLOps NYS」に参加しました。MLOpsとはMachine Learning Operationsの略であり、機械学習を実際のサービスに組み込んで運用するエンジニアリングの領域です。

その中で特に面白かったNetflix社の事例を紹介します!
Netflix社事例「A Human-Friendly Approach to MLOps」
Netflix社では、「Metaflow」と呼ばれる独自フレームワークを開発して、データサイエンティストに提供することにより、機械学習アプリケーションの開発・運用を社内で拡大することを実現している。
Netfliexのデータ分析の目標
コンテンツの発売前に、日毎の視聴者数の予測がしたい。これにより、優先度付やリソースの配置を考えている
ゴールは2つ
- 190カ国すべてのオフィスにて、データから一貫した洞察を得られるようにする
- 意思決定者のために正確で即時の情報を提供する
データ分析プロジェクトの進め方型と課題
- データ探索(〜2週間)
- notebookなどを用いて、データの振る舞いを理解して、どの特徴量を使うべきか等を探索する
- プロトタイピング(6〜8週間)
- 予測モデルのプロトタイプ開発、精度向上
- 本番化 (12〜14週間)
- 最も大変なステップ。ETL、 特徴量エンジニアリング、モデル学習、モデルサービング、バッチ予測、オンライン予測、監査、そしてスケジューリングなどが必要
- リリース後のモデル更新 (〜8週間)
- モデルの精度が劣化してきたら、バージョン1を安全にクローンして精度を向上させたバージョン2を作る必要がある
課題はプロトタイピング、本番化、リリース後のモデル更新に時間がかかること
「Metaflow」による解決
プロトタイピング、本番化、そしてリリース後のモデル更新の面倒な部分を支援するために、自社で独自のツール「Metaflow」を開発した。
Netflixのデータ分析で必要なスタックは以下である。
- 機械学習ライブラリ(Tensorflow/PyTouch/XGBoost)
- 特徴量エンジニアリング(Pandasを利用)
- モデルデプロイメント
- コラボレーティブツール(JupyterNotebook)
- 成果物のバージョニング
- ジョブスケジューリング(Mesonと連携(Airflowみたいなもの))
- 計算リソースの確保(Titusの活用(Kubenetesみたいなもの))
- データストア(S3)

Metaflowはこれらのスタック全体をカバーする

Metaflowの概要
MetaflowはPythonのライブラリとして提供され、データサイエンティストはライブラリをインストールして使う
Pythonのデコレータ(@マークで関数を修飾する機能)をうまく活用して、できるだけ簡単な記法で様々なことができる
プロトタイピングを楽にする機能
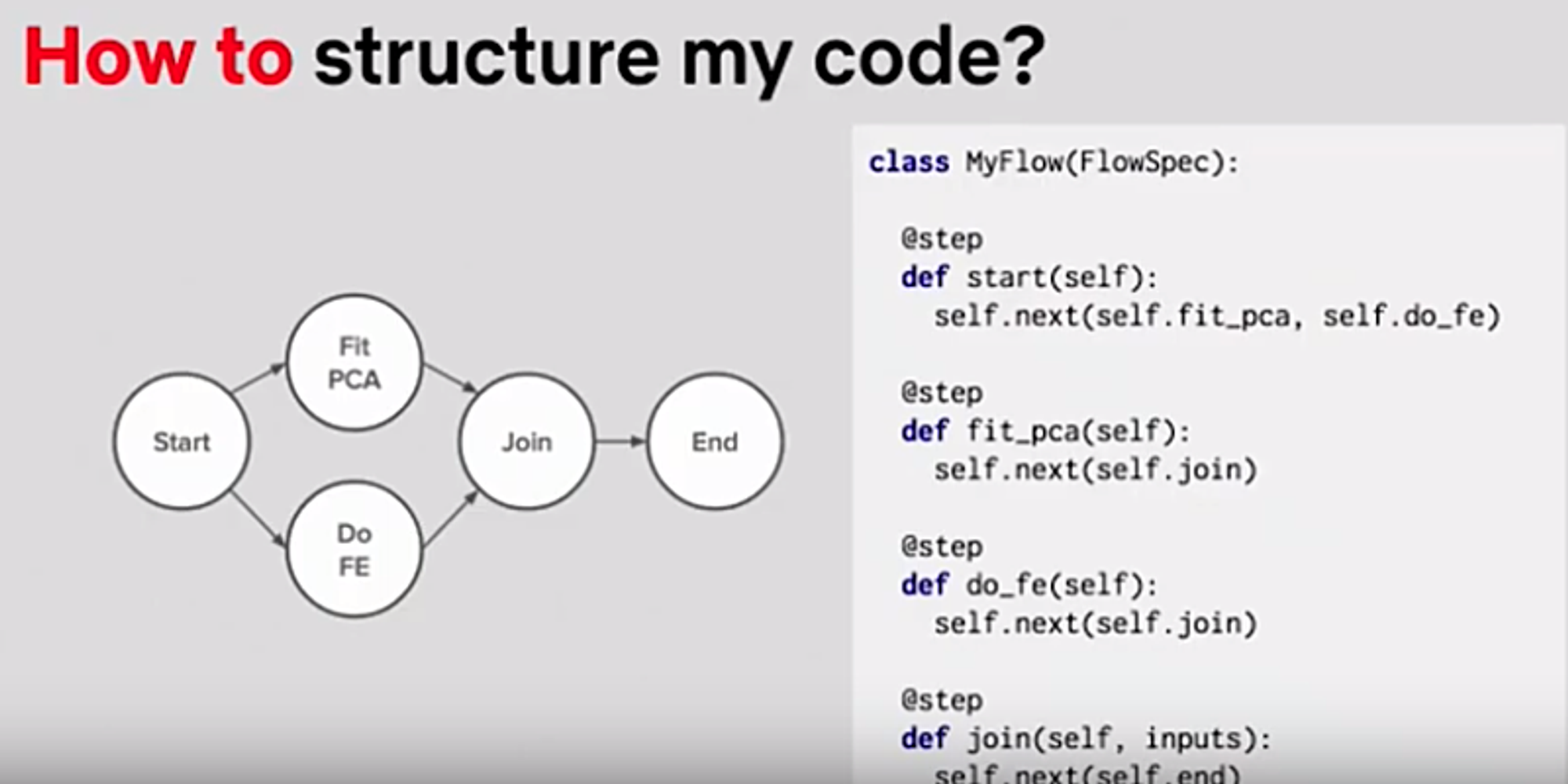
DAG(データアローダイアグラム)の生成
下図のような、PCA(主成分分析)とFE(特徴量エンジニアリング)を同時に行い合流するようなワークフローを作りたい場合、@stepといったデコレータを用いることで実現できる。また、途中で分岐するような処理をDAGをコードを使って作ることができる。これをローカルで作ることができる。作ったコードは「Artifact Store」に格納され、いつでも昔の状態を再現できる
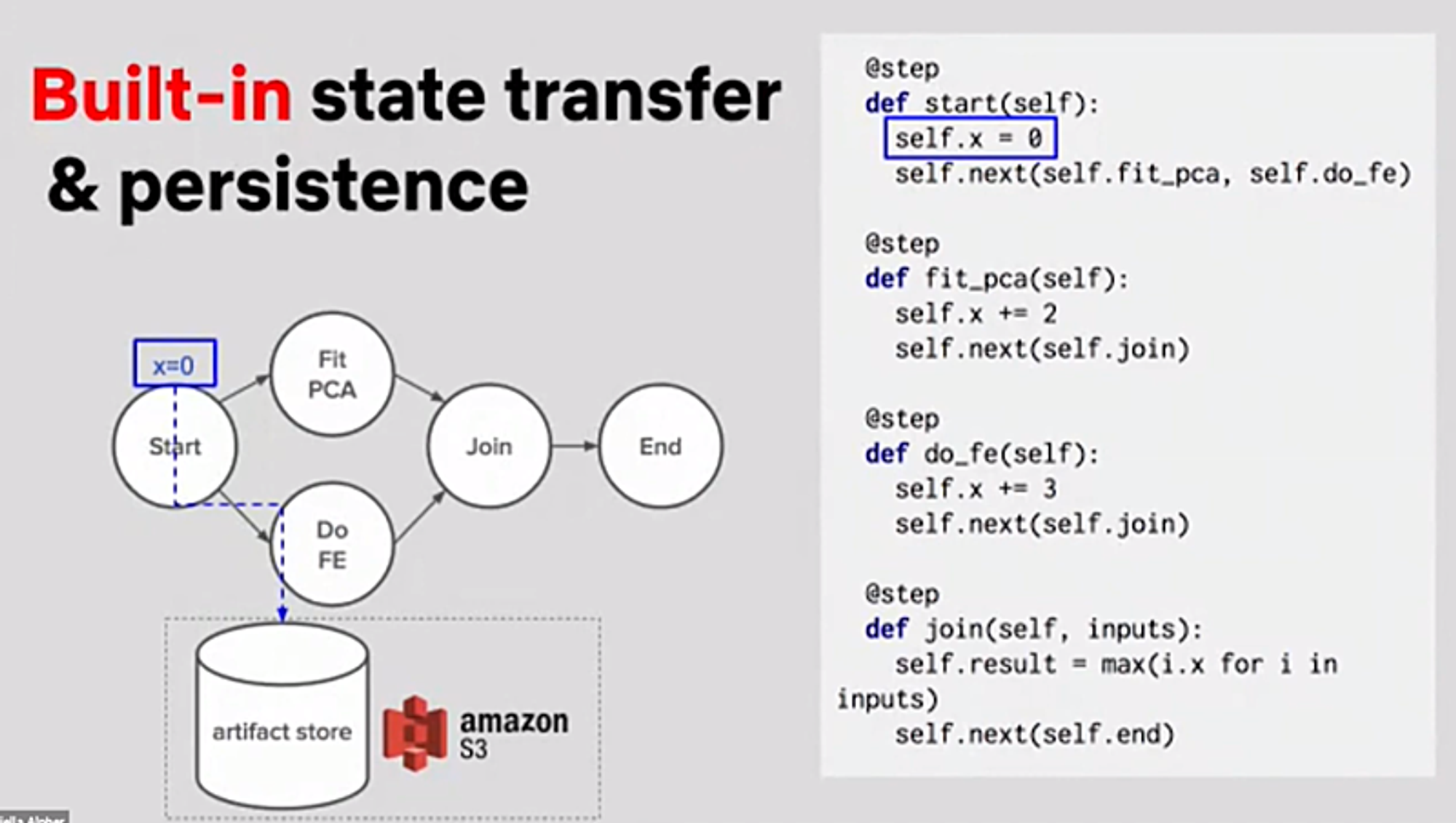
ステップの結果の永続化
前のステップの結果を次のステップで使うために、裏でS3に自動的に結果を保存してくれる。これにより、サイエンティストがローカルマシンで開発するときは簡単に開発できるし、本番で各ステップを別々のコンピュータで処理させたとしても問題なく動作する。
さらに各ステップの結果を永続化しておくことで、最後のステップだけが失敗した場合でもその直前から再開できるため、効率的に開発できる。
計算リソースの確保
以下のようにPythonのデコレータとしてCPUやメモリをしていすると、その関数はそのリソースを確保した上で動作してくれる。これにより特徴量抽出などに必要な計算リソースをサイエンティスト自身が簡単にチューニングできる。

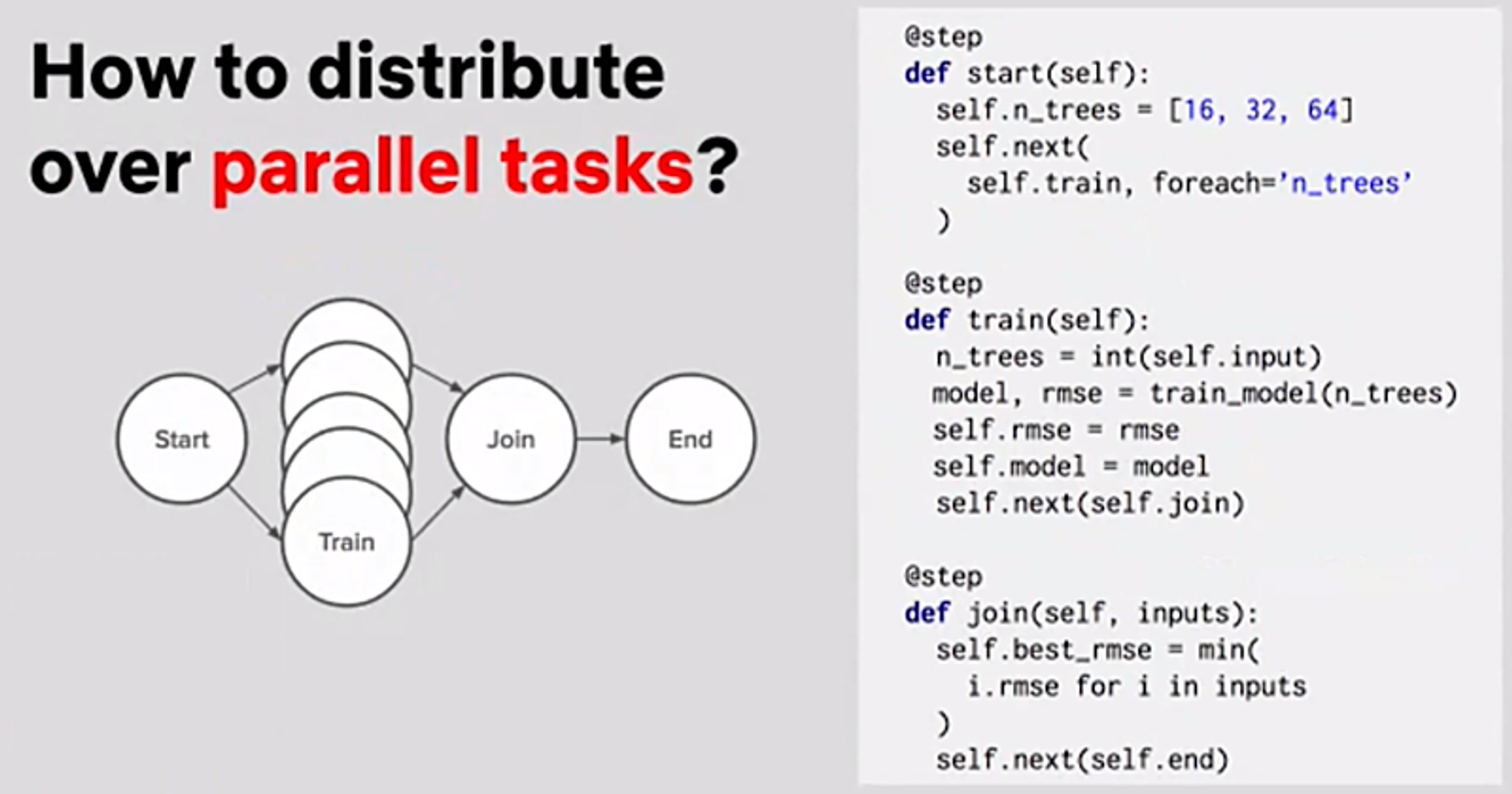
forループだけで並列処理
並列で処理したい処理があるforループを書くだけで並列実行される。
本番化を楽にする機能
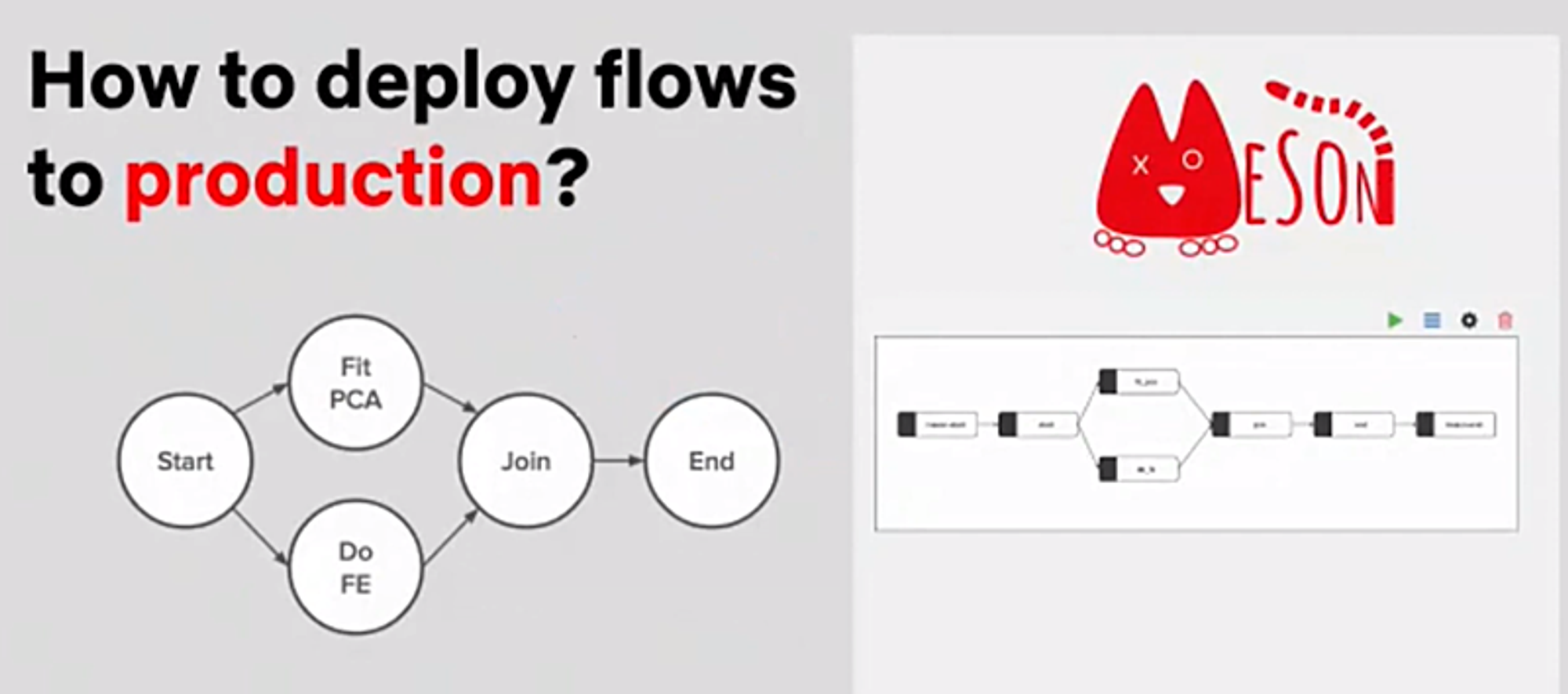
スケジューラーとの連携
Netflix社内の謹製スケジューラMESONにデプロイすることができる。
オンライン予測エンドポイントの作成
デコレータを書くだけでREST APIができる。

リリース後のモデル更新を楽にする機能
デバッグ
デプロイされたDAGの状態を、いつでも手元のnotebookで見ることができる。最終状態だけでなく、各ステップでの中間結果も見ることができる
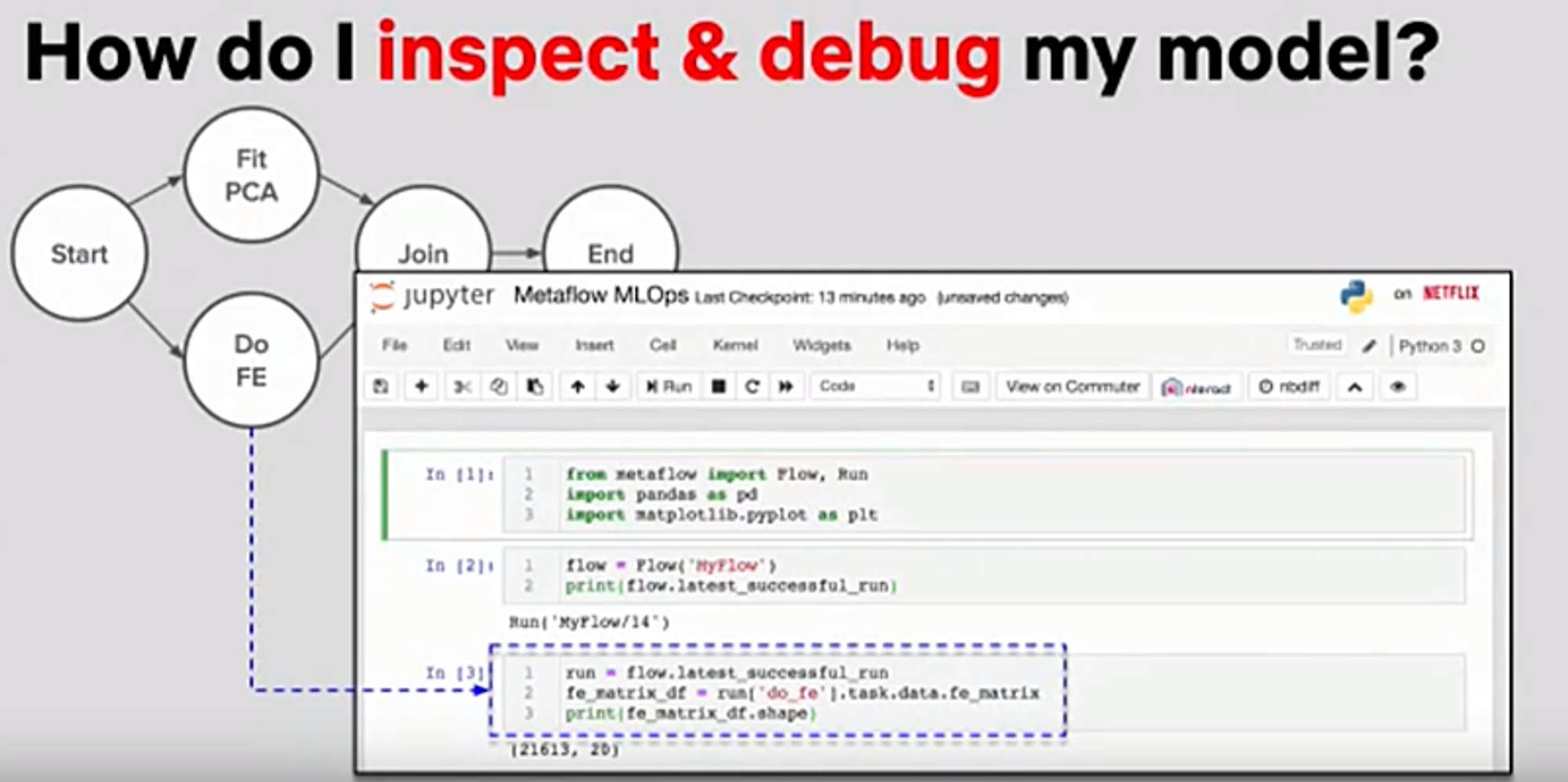
ネームスペースとバージョン管理
- ユーザのネームスペースと本番のネームスペースを用意
- ネームペース毎に成果物にタグを付けてバージョン管理
- ユーザは自分のネームスペースで独立して新しいモデルを開発できる
結果
- 社内のデータサイエンティストの中でブームになっている
- サイエンティストからは「本番デプロイの複雑さを軽減してくれた」と好評を得ている
- 社内で600を超えるプロジェクトで利用されている
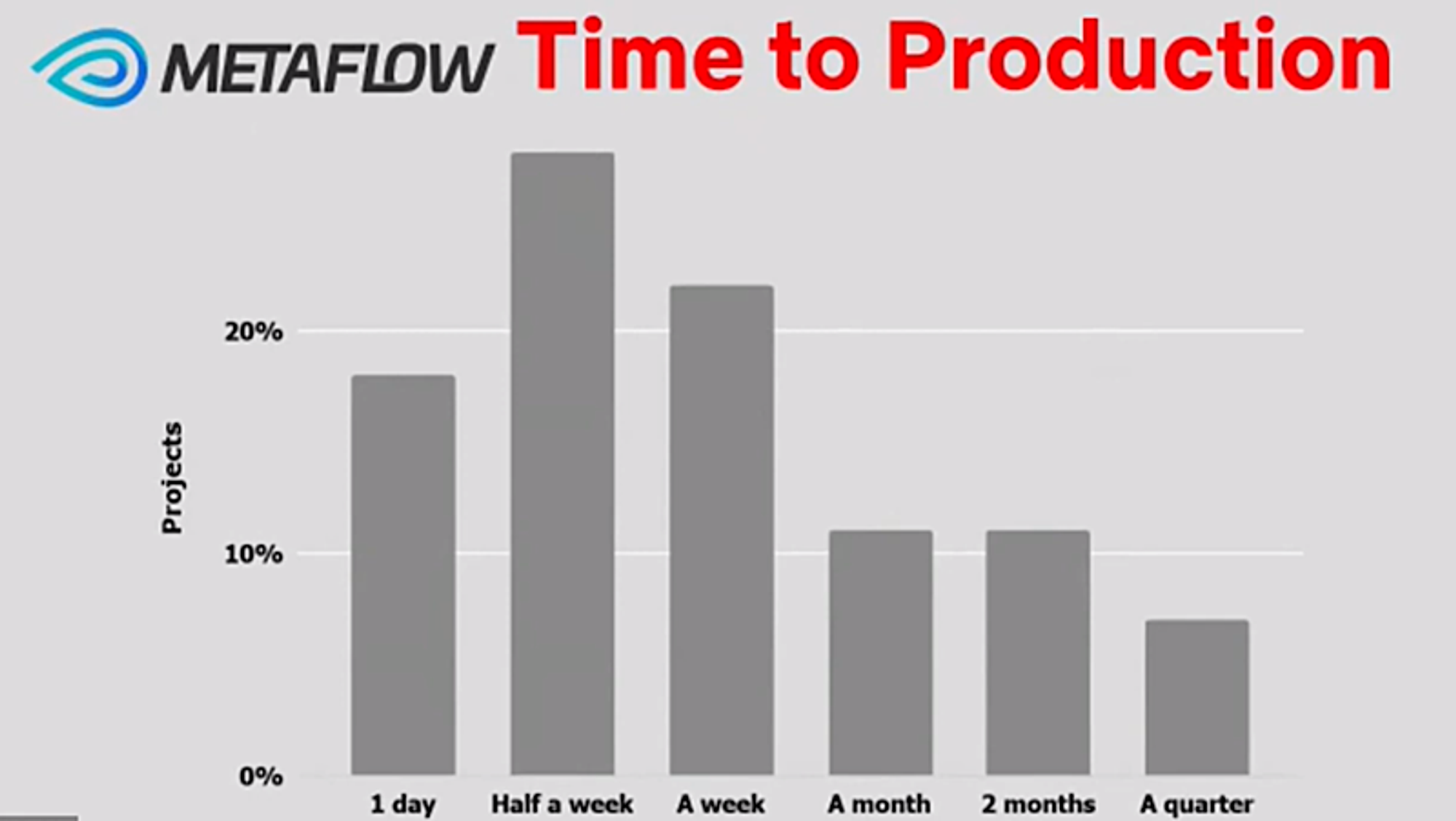
- 最初のモデルの本番化は、1週間未満で実現できているものが最も多い(下図)。
- オープンソース化した
質疑応答
- どうやって古いモデルを消している?→AWSのコストをモニタリングしている
- ユーザ数はどれくらい?→アクティブユーザ数は~100ぐらい
- モデルの旧戻しはどうやっている?→すべての成果物にバージョンを付与しているため、古いものを指定するだけ
所感
現在機械学習をサポートするプラットフォームはいろいろなITベンダが出しているのですが、これだけサイエンティストの目線に立って作られているツールは見たことありません。Pythonのデコレータはサイエンティストにとって使いやすいでし、インターフェースもサイエンティストの目線に立って非常に洗練されています。さすがNetflix社だと思いました。より詳しく知りたい人は、Youtubeの動画を見ることをおすすめします。
💁🏻
※本記事は Mobility Technologies の前身である JapanTaxi 時代に公開していたもので、記事中での会社やサービスに関する記述は公開当時のものです。
Mobility Technologies では共に日本のモビリティを進化させていくエンジニアを募集しています。話を聞いてみたいという方は、是非 募集ページ からご相談ください!