

データマイニングのトップカンファレンス – KDD2019参加レポート
行灯LaboAI学会September 24, 2019
💁🏻
※本記事は Mobility Technologies の前身である JapanTaxi 時代に公開していたもので、記事中での会社やサービスに関する記述は公開当時のものです。

KDD について
KDD(Knowledge Discovery and Data Mining)はデータサイエンスとデータマイニング関連の有名な国際会議です。(https://kdd.org/kdd2019/) 2019年08月04日ー2019年08月08日にアメリカ、アラスカで開催された25回目のKDD(KDD 2019)に参加してきた内容について報告します。

個人的に面白かったセッション
聴講させて頂いた発表の中から面白かった発表を紹介します。
Deep Reinforcement Learning with Applications in Transportation

DiDi AI Labs
参考:https://outreach.didichuxing.com/internationalconference/kdd2019/tutorial/
強化学習を用いて交通システム(特にタクシー)を改善しています。例えば、タクシー配車アルゴリズム改善、交通信号制御システム、自動運転など様々な技術について扱っています。
- Double DQN(AAAI2016)
参考:https://arxiv.org/pdf/1509.06461.pdf
普通のDQNはQ-functionが一つだけあります。このQ-functionを利用してどのActionを選んだ方がいいかを決めます。でも、Q-functionはmaximizeすることがあるので、overestimationの問題があります。Double DQNはQ-functionを2つにします。一つ目はActionを選ぶために、二つ目はActionのvalueを算出するために使います。 このDouble DQNにより、学習がより安定します。

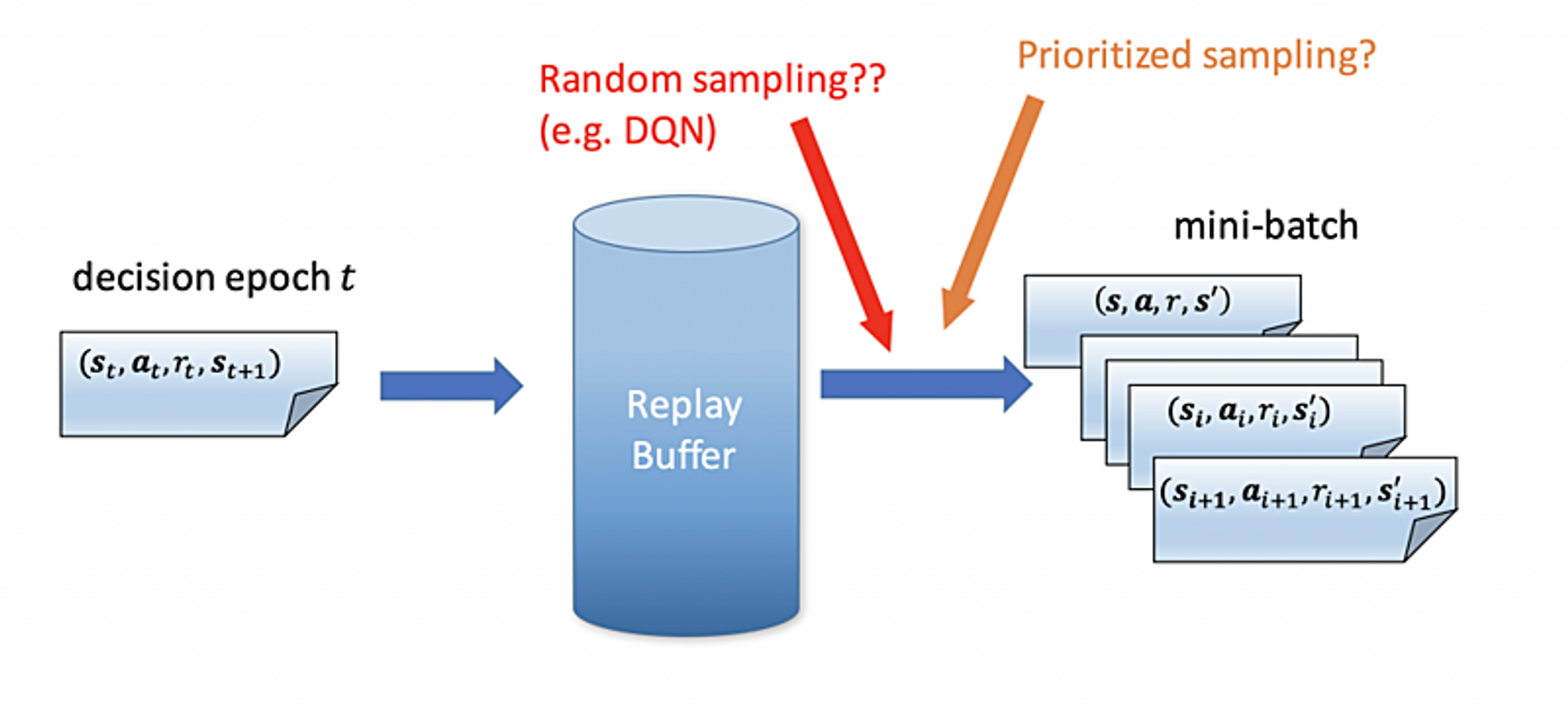
- Prioritized Experience Replay(ICLR2016)
参考:https://arxiv.org/pdf/1511.05952.pdf
使う学習データの優先度の算出方法は色々あります。例えば、greedyに一番エラー値が大きいデータを選ぶ方法などがあります。この結果は学習かかる時間を減らし、精度も高くなります。
Explainable AI in Industry

LinkedIn, Fiddler Labs
参考:https://sites.google.com/view/kdd19-explainable-ai-tutorial
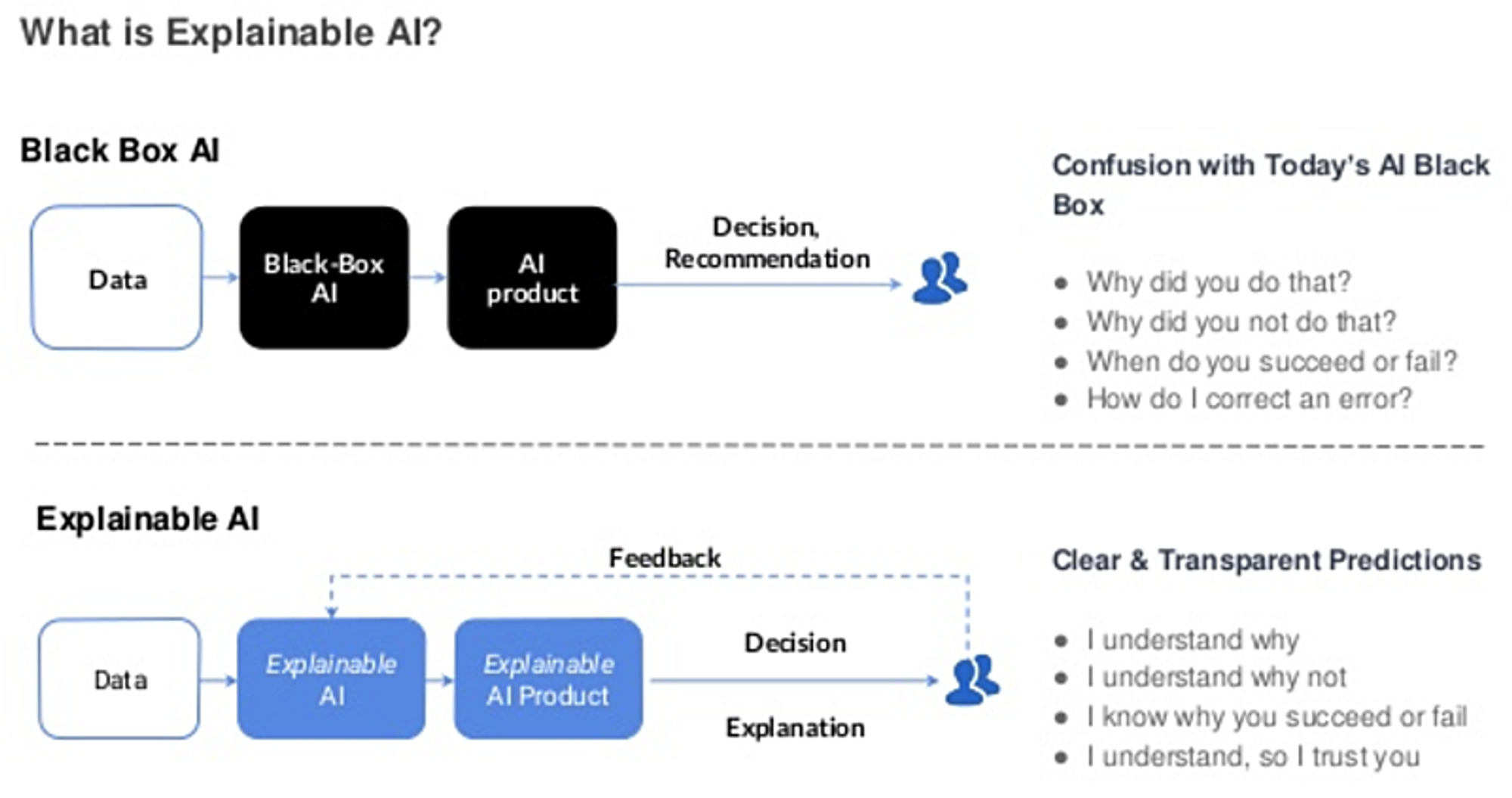
近年AIが流行っていますが、AIが推進する一方で、わからないところが多くなります。 AI、特に深層学習、はblack boxなので、どういう理由で出力が選ばれているのかわからない場合が多いです。つまり、今の時代のAIは説明できない場合が多いです。Explainable AIとは、説明できるAIの技術です。
- Ablations
これはとてもNaive approachです。入力のFeatureは全て使わないで、一部を抜いて推論して結果をみます。例えば、あるFeatureを使わなかった時に、結果が大分悪くなったらこのFeatureは重要だと言えます。逆に、あるFeatureを使わなかった時に結果が変わらなければ、このFeatureはあまり意味がないと言えます。

- Integrated Gradients(ICML 2017)
参考:https://arxiv.org/pdf/1703.01365.pdf
「どのFeatureが必要か」という問題は、可視化することで解決できる事もあります。このアイディアを踏まえて色々な可視化方法が生まれました。 Gradient(出力と入力の勾配を計算)は画像の可視化手法の一つですが、この論文が提案するのは普通のGradientだけではなくて、明るさを調整し、各明るさ(α)に対してIntegrateすることでより合理的な結果が出ます。
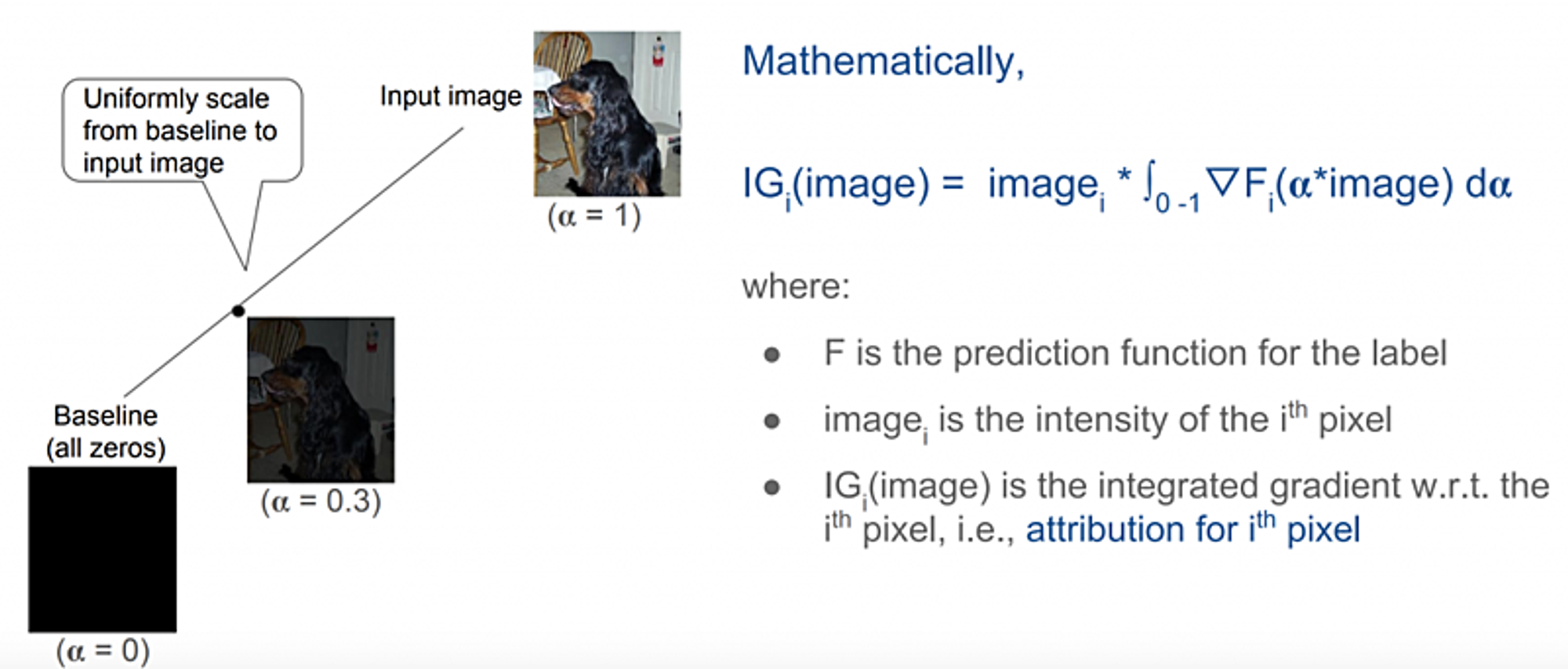
参考:http://theory.stanford.edu/~ataly/Talks/sri_attribution_talk_jun_2017.pdf

Integrated Gradientsの結果を見ると、どうして深層学習モデルの推定結果が間違っているのがわかるようになります。
Deep Learning for Education
ml4ed
参考: http://ml4ed.cc/2019-kdd-workshop/
参加する前は教育分野にどうやって深層学習を応用するのかさっぱりわかりませんでした。しかし、実はたくさん興味深い研究があります。
- Combating the Filter Bubble: Designing for Serendipity in a University Course Recommendation System (Zach Pardos and Weijie Jiang) 深層学習を用いて学生のコースを推薦するシステムを作成
- Using Machine Learning and Genetic Algorithms to Optimize Scholarship Allocation for Student Yield (Lovenoor Aulck, Dev Nambi, and Jevin West) 遺伝的アルゴリズムと機械学習を用いて奨学金の割り当てシステムを作成
- CrossLang: The System of Cross-lingual Plagiarism Detection (Oleg Bakhteev, Alexandr Ogaltsov, Andrey Khazov, Kamil Safin, and Rita Kuznetsova) 研究論文の剽窃チェック
AI & Security: Challenges, Lessons & Future Directions

Dawn Song
Professor, UC Berkeley Founder & CEO, Oasis Labs
参考:https://iotsecurity.engin.umich.edu/https://seclab.stanford.edu/AdvML2017/slides/dawn-stanford-ai-security-workshop-short-sep-2017.pdf(古いバーション)
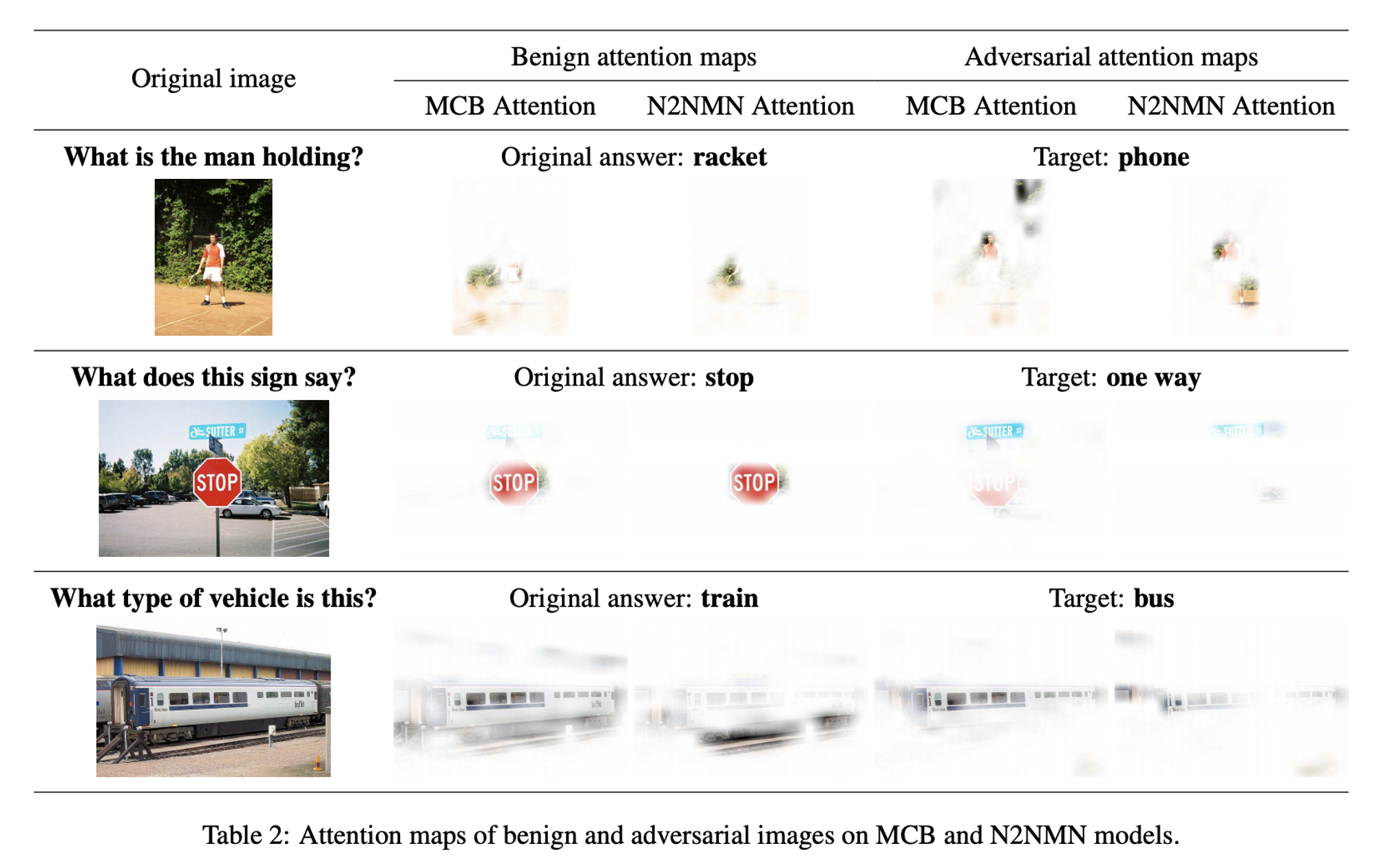
AIとSecurityは相互に影響を与えています。 AI→Securityの場合、AIを用いてSecurityを改善します。例えば、自動的に犯人からの攻撃を検出・防衛システムなどです。 逆に、Security→AIの場合、Adversarial Exampleを使ってAIを騙して、AIの結果を犯人がコントロールします。 Adversarial Exampleというものは、人が見ると本当のExampleと似ているけど、AIが見ると違う結果を出すものです。 先行研究ではAdversarial Exampleで色々な有名なモデルを騙しています。例えば、YOLO、Faster RCNN 、LISA-CNN、VQAなどです。

先行研究は色々な面白い論文があります。
- Robust Physical-World Attacks on Machine Learning Models (CVPR2018) 参考:https://arxiv.org/pdf/1707.08945.pdf adversarial examplesを作成するalgorithmを提案し、精度測定方法を提案。実験で良い結果が出ています。さらに、シミュレーション結果だけではなく、実際に印刷したものをカメラで撮影して実験しました。 結果:https://iotsecurity.engin.umich.edu/robust-physical-world-attacks-on-deep-learning-visual-classification/

- Note on Attacking Object Detectors with Adversarial Stickers (WOOT2018) 参考:https://arxiv.org/pdf/1712.08062.pdf 上記の論文と同じalgorithmでAdversarial Examplesを作成してobject detectionを攻撃しています。 結果:https://iotsecurity.engin.umich.edu/physical-adversarial-examples-for-object-detectors/
- Delving into Adversarial Attacks on Deep Policies (ICLR 2017) 参考:https://arxiv.org/pdf/1705.06452.pdf 強化学習をAdversarial Examplesで攻撃する論文です。
- Fooling Vision and Language Models Despite Localization and Attention Mechanism (CVPR2018) 参考:https://arxiv.org/pdf/1709.08693.pdf dense captioning systems と visual question answering (VQA)を攻撃する論文です。
Two-Sided Fairness for Repeated Matchings in Two-Sided Markets: A Case Study of a Ride-Hailing Platform
Max Planck Inst., Microsoft Research 参考:https://people.mpi-sws.org/~achakrab/papers/suhr_fair_matching_KDD19.pdf
普通はTwo-sided sharing economy platforms(例えば、Uber, Lyft, DiDi, Airbnb)はお客さんの満足度のみでmatching algorithmを行います。例えば、タクシーの場合は、お客さんの待ち時間をできるだけ短くします。しかし、お客さんのことだけを考えると、ドライバーには不平等です。 この論文が提案するのは、お客さんの満足度だけではなく、ドライバーのことも検討します。例えばタクシーの場合は、お客さんの待ち時間も検討し、ドライバーの売上の分布も検討します。
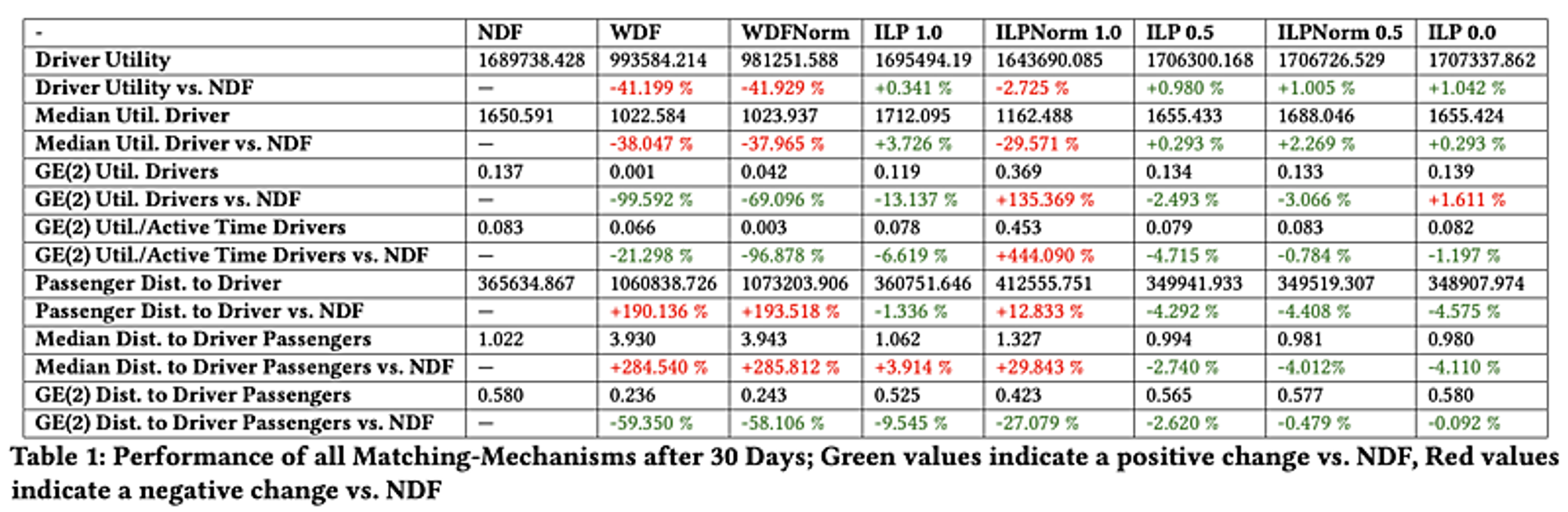
Nearest Driver First (NDF)とは一番近いドライバーを選ぶalgorithmです。つまり、お客さんの満足度で検討します。 Worst-Off Driver First (WDF)とは今売上が一番低いドライバーからお客さんを選ぶalgorithmです。つまり、ドライバーの売上を出来るだけ平等に分布するalgorithmです。 Integer Linear Program (ILP)とはこの論文が提案するalgorithmです。お客さんのこと(待ち時間の分布)とドライバーのこと(売上の分布)両方考えて最適化を行うalgorithmです。そのあとの数字は重さの引数です。 GEはGeneralized Entropy Index。この結果を見たら引数=0.5(お客さんの重さとドライバーの重みは同じ)で、一番いい結果になります。
最後に
今回はJapanTaxiとして初めての国際学会、さらに個人的にも初めてデータサイエンスのトップカンファレンスへの参加でした。 参加したセッションは技術的な説明だけではなく、AIトレンドとアプリケーション、トップリサーチャーのキャリア紹介などもありました。 色々な経験ができ、反省点もあり、大変勉強になりました。来年も参加したいと思います。
💁🏻
※本記事は Mobility Technologies の前身である JapanTaxi 時代に公開していたもので、記事中での会社やサービスに関する記述は公開当時のものです。
Mobility Technologies では共に日本のモビリティを進化させていくエンジニアを募集しています。話を聞いてみたいという方は、是非 募集ページ からご相談ください!