

画像処理カンファレンスICCV2019参加レポート
行灯LaboAI学会December 05, 2019
💁🏻
※本記事は Mobility Technologies の前身である JapanTaxi 時代に公開していたもので、記事中での会社やサービスに関する記述は公開当時のものです。
ICCVについて
ICCVと言えば、CVPR、ECCVと並ぶComputerVisionのトップカンファレンスです。本年のICCV2019は、Workshops、Tutorialsを含めた全期間では10/27-11/2、そのうちMainConferenceは10/29-11/1という期間でソウルで開催されました。
前回のICCV2017と比較すると採択論文数が約620本から1000本以上、参加者が約4300人から7000人以上とおよそ1.5倍超の大幅拡大していました。先に挙げたCVPRも2018から2019にかけて同様に1.5倍超の規模拡大をしており、近年のComputerVision界隈の盛り上がりが伺えます。
今回、JapanTaxiからはセルゲイ、パヌメート、佐々木(トップ写真の左から順)の3名が参加いたしましたので、共同執筆という形で各人が気になったトピックや論文をピックアップして紹介しようと思います。
ICCV2019の傾向
ComputerVision界隈はDeepLearningが非常によく利用される分野ですが、すでに成熟が進んでおり、いかにDeepLearningを制御していくかという研究が多く見受けられました。 トピックとしてはより少ないデータから効率よく学習させる、あるドメインで学習した結果を別のドメインに適用できる様に変換する、画像であればどの部分に注目して推論を行っているかを制御/可視化する、などが多かったと思います。

Oral Session メイン会場の様子
聴講環境の観点からはMainConferenceは開催時間に対して口頭発表もポスター発表も数が多く見応えはあったのですが、一人で見て回るには大変な規模になっていたので、何人かで分担するのが良さそうです。
セッション&論文pick up
気になった論文などをいくつかpick upして紹介したいと思います。なお開催時点でacceptされた論文はこちらでアクセス可能です。
Tutorial & Workshop

以下のセッションに参加しました。
Tutorial : Large-Scale Visual Place Recognition and Image-Based Localization
(https://sites.google.com/view/lsvpr2019/home)
ここでは、Torsten Sattlerから提供されたこのチュートリアルのパートIIIに焦点を当てます。このパートでは、視覚に焦点を当てています
自己位置推定の問題
自己位置推定の問題には3つのアプローチがあります
a)画像検索 b)構造ベース c)ポーズ回帰
これらの方法はすべて、画像やカーナビゲーションからの位置検出に非常に役立ちます。

Workshop : Real-world recognition from low quality images and videos
セッションプログラム : (https://www.forlq.org/) 発表資料 : (http://openaccess.thecvf.com/ICCV2019_workshops/ICCV2019_RLQ.py)
このセッションでは2つの有用なプレゼンテーションが見つかりました。
一つは「Invited Talk 1: Deep Pedestrian Detection across Occlusion with Geometric Context」です。 このプレゼンテーションでは一般化した半教師ありsemantic-segmentationとの研究成果と、CompCars Datasetに関する情報が紹介されました。
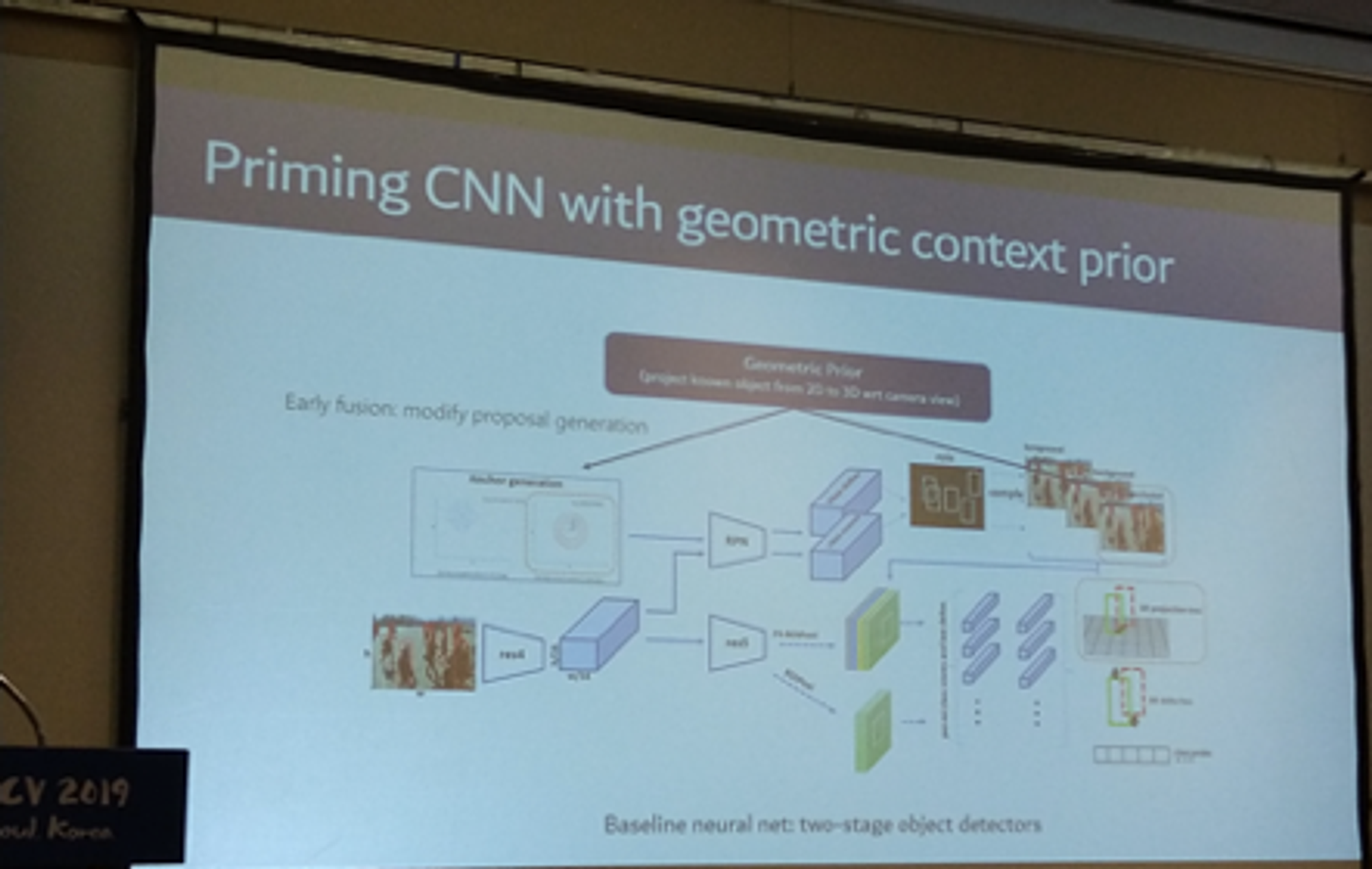
もう一つは「Invited Talk 3: Unconstrained Computer Vision」です。 こちらでは、静止画および動画から高精度に歩行者を認識する「Priming CNN with geometric context priming」が紹介されました。
どちらも弊社の事業に役立つと思います。

SinGAN: Learning a Generative Model from a Single Natural Image
著者 : Tamar Rott Shaham, Tali Dekel, Tomer Michaeli
[文献リンク] ICCV2019 Best Paper

(発表の様子) ※画像破損のため省略
元々のGAN(Generative adversarial networks 、敵対的生成ネットワーク)は数枚の画像を使って、色々な画像を生成します。でも、SinGANはGANのアイデアを利用し、一枚の画像を学習するだけで、その画像に似た別の自然な画像を生成できます。 上のスライドではSingle training image(学習画像)とGenerated image(モデルが生成した画像)が表示してあります。
(Section3 より引用) ※画像破損のため省略
以上は結果です。一番左の列が本物の画像(学習時に使用)、右側がSinGANの生成した結果です。さらに、SinGANで、自動でアニメーションを生成することもできます(参考動画)。実験の結果により、人間でも区別しにくい画像ができます。
(Section1.1 より引用) ※画像破損のため省略
SinGANは複数GANを重ねて(ピラミッドみたいな感じ)低い解像度から順に学習をさせることで最終的に高い解像度の画像を生成します。 Discriminatorは学習データが一枚しかないので、それぞれの画像から一部を切り出して、本物か偽物か判断させて、繰り返して学習させることになります。
普通の深層学習は大量の学習データが必要だし、入力も必要です。 でも、SinGANは一枚の画像のみ使って学習します。推論の時は入力が不要で、ランダムノイズだけ使います。 色々な結果を見てとても素晴らしいと思います。将来的にはこのアイデアを使って学習データが足りない時もデータを増やせそうだし、他にも色々できそうだと思います。
Semi-Supervised Learning by Augmented Distribution Alignment
著者 : Qin Wang, Wen Li, Luc Van Gool
[文献リンク]

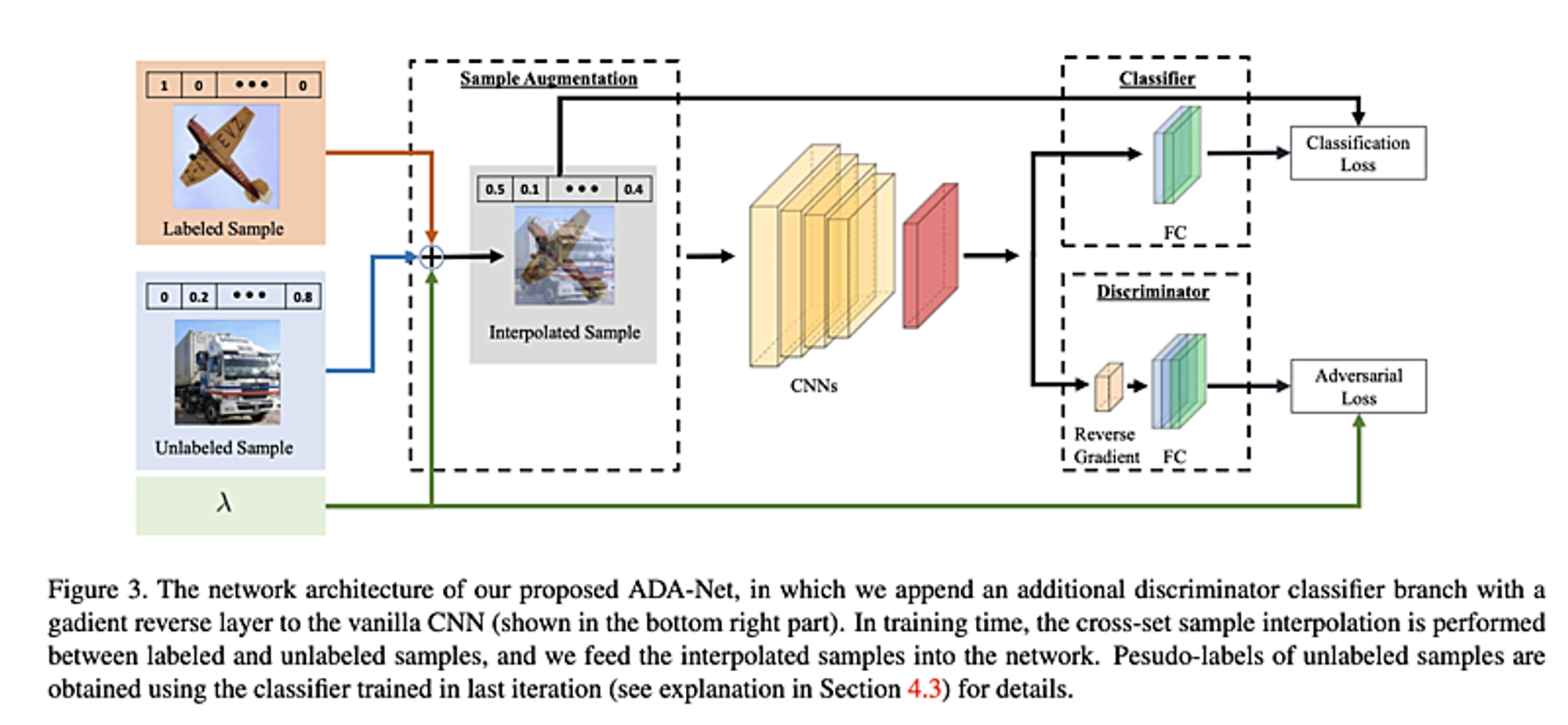
(Section4.2 より引用)
こちらの論文では上図の様にラベル有り教師データとラベル無し教師データを分布𝛽から取得した𝜆(0≤𝜆≤1)で混合したデータでClassifierおよびDiscriminatorの学習を通して任意の特徴量抽出器を学習させることで、Semi-Supervised学習(ごく一部だけ正解ラベルが付与されいている学習データでの学習)の性能を向上させています。
Classifier学習時はラベル有りデータの正解ラベルと、ラベル無しデータからその時点での最新世代の抽出器の出力を比率𝜆で混合した結果を正解とし、Discriminatorの学習時は特徴量抽出器の出力を見て0,1でラベル有り、ラベル無しと判定する代わりに混合比率𝜆を正解値として学習させています。
この様に、特徴量空間上では各データのラベルの有無の区別がつかない性質を保ちながら画像分類タスクを学習させることで、既存のSemi-Supervised学習の手法より高い分類性能を実現しています。
(Section5.4より引用)
シンプルなアイデアなので既存の様々なネットワークやタスクに応用できるのも魅力的です。
最後に
上記に紹介した以外にも、企業によるデモブース(NAVERやLINEなど)でComputerVison技術を利用した展示が多数あり、実応用の現状や盛り上がりも感じることができました。
昨今ではarXivをはじめ多くの論文にオープンアクセスできる機会は増えていますが、人の集まり方で注目されているジャンルや論文がわかりやすい、発表者自身とコミュニケーションをとることができる、など実際の学会ならではのメリットもあるので、このような学会は折を見て参加したいと思います。
💁🏻
※本記事は Mobility Technologies の前身である JapanTaxi 時代に公開していたもので、記事中での会社やサービスに関する記述は公開当時のものです。
Mobility Technologies では共に日本のモビリティを進化させていくエンジニアを募集しています。話を聞いてみたいという方は、是非 募集ページ からご相談ください!