

ABテスト効果検証 -Bayesian Testing-
AIOctober 20, 2021
AI技術開発部分析グループ所属の秋月です。 分析グループは、タクシーアプリ「GO」におけるデータドリブンなビジネス意思決定を行うために、様々なユーザ分析、乗務員分析を行っています。 本記事では、ABテストを実施した際の効果検証に利用する Baysian Testing という手法を紹介します
ABテストについて
近年 ABテストは最も利用される仮説検証のフレームワークだと思います。
例として良く挙げられるのは WebサービスにおけるUI画面の変更がコンバージョン率にどう影響を与えるのか を比較するなどが有名ですね。
実施の目的として、UI変更が購買率などの指標にポジティブな影響を与えるのではないか、という仮説を検証するためだと思います。サイト内やアプリ内の利便性を常に向上し続けるため、ABテストによる仮説検証を回し続けるのはビジネス上、必要不可欠な事です。
ABテストで言うとマイクロソフト社は定常的に1日あたり250件の実験を実施していることをブログで公表しています。雑談ですが、上記ブログは『A/Bテスト実践ガイド』という書籍の一部になっており、非常におすすめです。
既存の効果検証手法
ABテストを実施した場合、最終的には AまたはB のどちらの施策を適用していくのかの意思決定が必要になってきます。その意思決定は早ければ早いほどビジネス上の優位性が高まるはずです。

意思決定の元になる効果検証に利用される手法はさまざまだと思いますが、一般的にはχ2検定やt検定に代表されるような頻度論をベースとした手法だと思います。
頻度論をベースにした検定を行うにあたって、事前に下記項目の設定をしなければなりません。
- ゴール指標の設定
- 帰無仮説H0 と 対立仮説H1の決定
- 有意水準(一般的に5%を設定する場合が多い)
- サンプルサイズの設定(検出力を元に決定)
頻度論をベースとした効果検証をする場合、検証するのはあくまで帰無仮説が棄却されるかどうかであり、検定を行う際に見られるA/B間の差分は効果量として見てません。
また、事前に決めておいたサンプルサイズに到達するまでの期間中/以降で検定を行うことは p-hacking(結果を「統計学的に有意」になりやすくする行為)となり、正しい意思決定につながりません。詳しくは『いかに研究デザインを有意に見せるか?』を参考にしてください。
試行するABテストによっては母集団のサイズが小さく、決められたサンプルサイズに届くまでに時間が掛かることが想定されます。

また、ABテストの結果の解釈性も、ABテストの実行者に向けた説明の容易さに繋がるため重要な項目の一つです。

Bayesian Testing とは
そこで、一般的に使われる効果検証手法による課題を解消する方法としてベイズ統計の枠組みを利用した Bayesian Testing と言う効果検証手法があります。
Bayesian Testing を利用することで下記のことが可能となります。
- サンプルサイズを明確に計測する必要がない
- 途中経過を出力することができる
- 結果が解釈しやすい
Bayesian Testing とはその名の通り、ベイズ統計を利用した効果検証手法です。
設定された事前分布に対して A/B それぞれで観測されたデータで事後分布を更新します。
集まったデータから A/Bそれぞれの効果量を確率分布として表現し、その差で優劣を比較することができます。
また、ベイズ統計を利用する際には事前分布を用意しなければなりません。事前分布は母集団に対する事前知識を反映した共役事前分布を設定することでより早く結論に辿り着くことができます。(実務上は 無情報事前分布や弱情報事前分布を設定することが多いです)

例えば、とあるイベントの発生確率は事前にベルヌーイ分布に従い 20% の確率で発生するとします。
この時 共役事前分布に Beta(alpha = 1, beta = 1) を設定して 20回の成功と80回の失敗が観測された場合 Beta(alpha = 21, beta = 81) の分布が得られます。
一方で、母集団に対する事前知識としてベータ分布の形状が Beta(alpha = 4, beta = 16) に近いことが分かっていて、それを共役事前分布に設定した場合 16回の成功と64回の失敗 を観測するだけでBeta(alpha = 21, beta = 81)の事後分布を得られるので、先ほどより早く結果を捉えることができます。
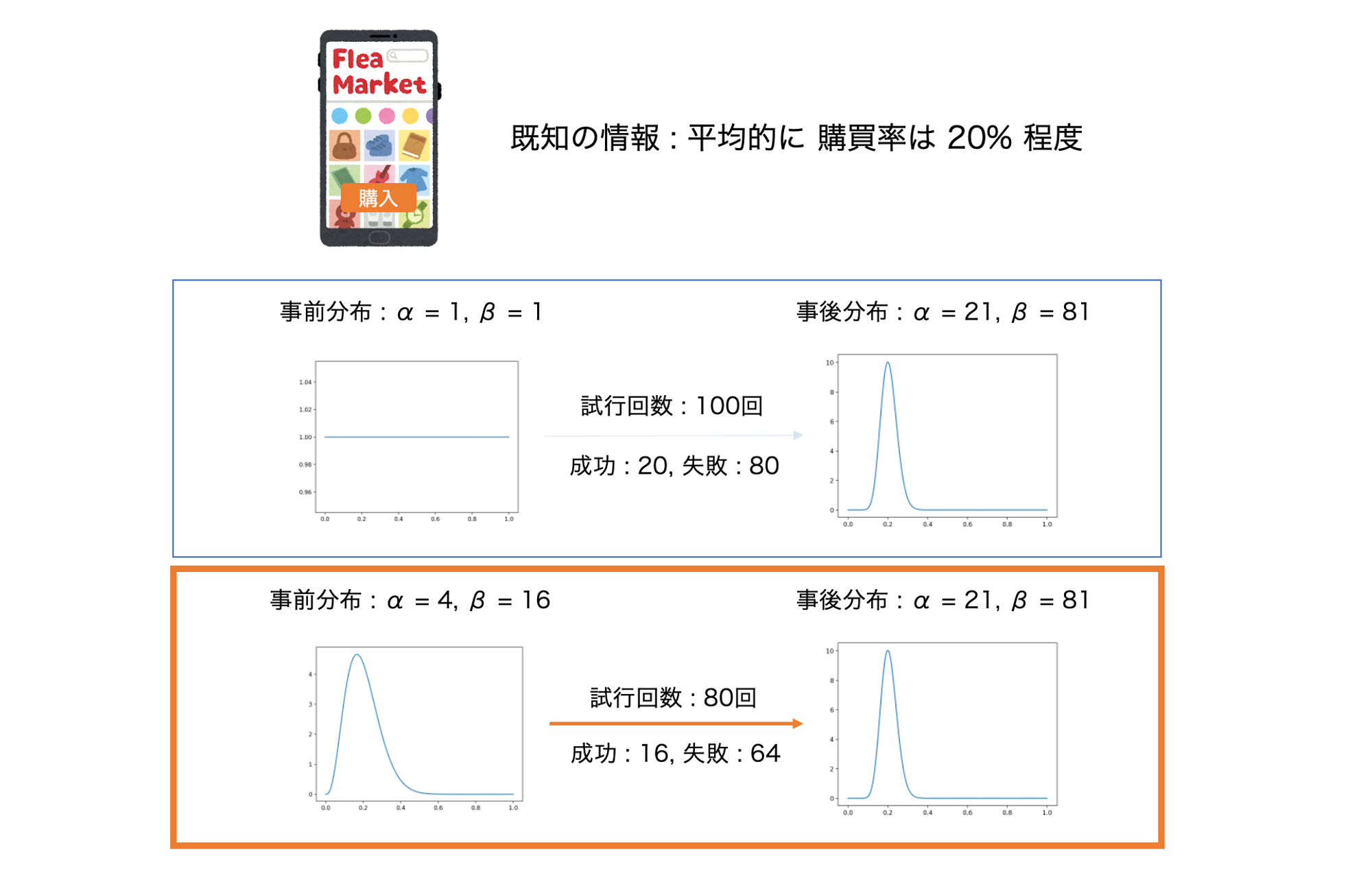
しかし、強い制約を設けてしまうと何かしらの影響で分布が変わってしまった場合に、その変化の検知に時間がかかってしまうケースが想定されます。
シミュレーション結果
今回 Bayesian Testing の雰囲気を味わっていただくためにシミュレーションのサンプルを用意しました。
例として今回は 下記のABテストをランダム化実験で行った想定をします。
- A(介入群) : ユーザーにクーポンを配布
- B(コントロール群) : ユーザーにクーポンを配布しない
A/Bそれぞれに、その後にコンバージョンしやすくなるかをBayesian Testingによって検討します。
初めに効果量として A>B となるようにデータを生成します。
#!usr/env/bin py
#-*- coding : utf-8 -*-
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
import matplotlib.animation as animation
np.random.seed(1)
def gen_data(prob = 0.0, n = 100):
return stats.bernoulli(prob).rvs(n)
## a の方が 10% ほど効果が出るようにダミーデータを生成する
a = gen_data(0.11, 1000)
b = gen_data(0.10, 1250)
print('Class A = Target : {} Conversion : {} CVR : {:.3f}'.format(len(a), np.sum(a == 1), np.sum(a==1)/len(a)))
print('Class B = Target : {} Conversion : {} CVR : {:.3f}'.format(len(b), np.sum(b == 1), np.sum(b==1)/len(b)))
>> Class A = Target : 1000 Conversion : 110 CVR : 0.110
>> Class B = Target : 1250 Conversion : 131 CVR : 0.105実際に生成したデータをもとに、ユーザーにクーポンを配布して、コンバージョンしやすくなるかどうかの検討を行います。施策に対して Bernoulli(ベルヌーイ)分布 を仮定し、 A/B どちらにも 共役事前分布に Beta分布を設定します。
## 事前分布には 弱い制約を設けた Beta分布を設定する
alpha_a, beta_a = 1,1
alpha_b, beta_b = 1,1
print('Class A prior_mean = {} prior_var = {}'.format(stats.beta(alpha_a,beta_a).mean(),stats.beta(alpha_a,beta_a).var()))
print('Class B prior_mean = {} prior_var = {}'.format(stats.beta(alpha_b,beta_b).mean(),stats.beta(alpha_b,beta_b).var()))
>> Class A prior_mean = 0.5 prior_var = 0.08333333333333333
>> Class B prior_mean = 0.5 prior_var = 0.08333333333333333今回のABテストで観測された A/B それぞれのデータを利用して、共役事前分布に対してベイズ更新を行って行きます。
## 事後分布のアップデート
def update_dist(n , data, prior_alpha, prior_beta):
prior_alpha += np.sum(data[:n] == 1)
prior_beta += np.sum(data[:n] == 0)
return prior_alpha, prior_beta
## 100 stepごとに現在の分布を出力する
def animation_update(n):
plt.cla()
a_prior_alpha, a_prior_beta = update_dist(int(n * 100), a, alpha_a, beta_a)
b_prior_alpha, b_prior_beta = update_dist(int(n * 100), b, alpha_b, beta_b)
x = np.linspace(0,1,1000)
a_cumdist = stats.beta(a_prior_alpha, a_prior_beta).pdf(x)
b_cumdist = stats.beta(b_prior_alpha, b_prior_beta).pdf(x)
plt.plot( x, a_cumdist, label = 'CLASS : A', alpha = 0.5, color = 'r')
plt.fill_betweenx(y = a_cumdist, x1 = x, color = 'r', alpha = 0.5)
plt.plot(x, b_cumdist, label = 'CLASS : B', alpha = 0.5, color = 'b')
plt.fill_betweenx(y = b_cumdist, x1 = x, color = 'b', alpha = 0.5)
plt.grid()
plt.title('Beta Update Distribute : STEP {}'.format(n*100))
plt.legend()
plt.xlim(0,0.2)
fig = plt.figure()
ani = animation.FuncAnimation(fig, animation_update, frames = 13, interval=500)
ani.save('UpdateBetaDistribution.gif')100step毎のA/Bそれぞれの分布を観測すると段々と A(コントロール群) の方がコンバージョン率が高くなっていることがわかります。
途中結果が視覚的に分かりやすく非常に良いですね。
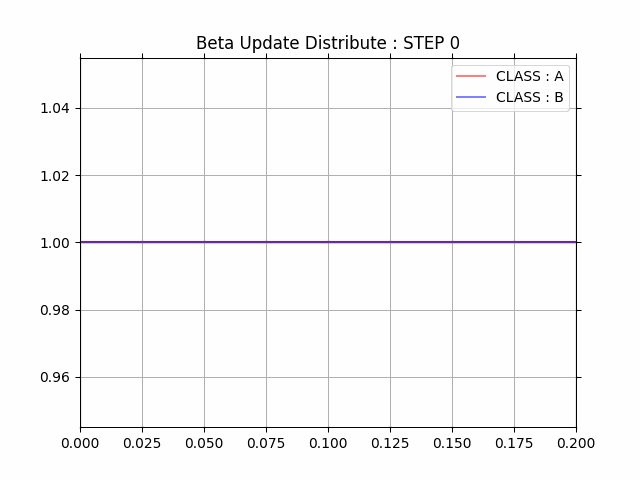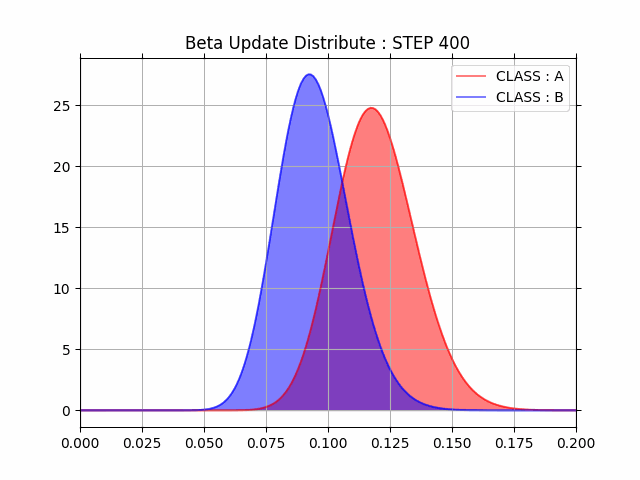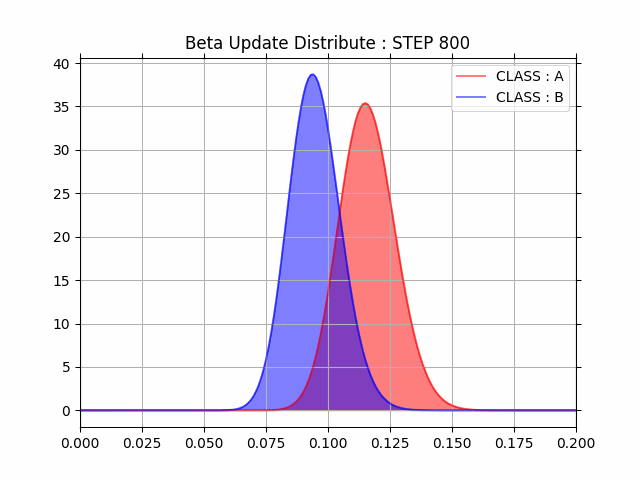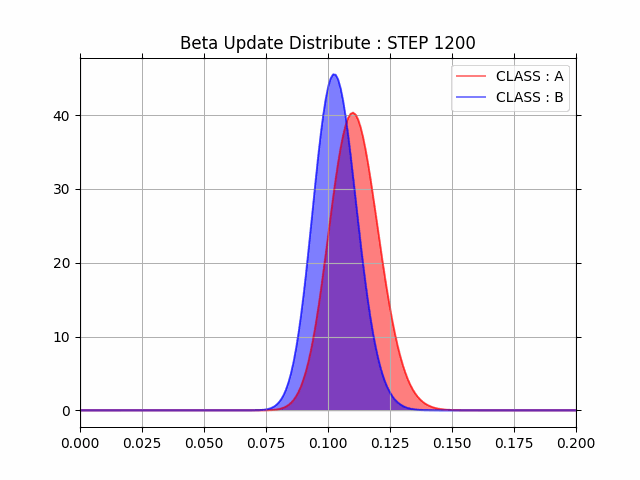
最終的に全データを利用した場合の事後分布は下記のようになりました。
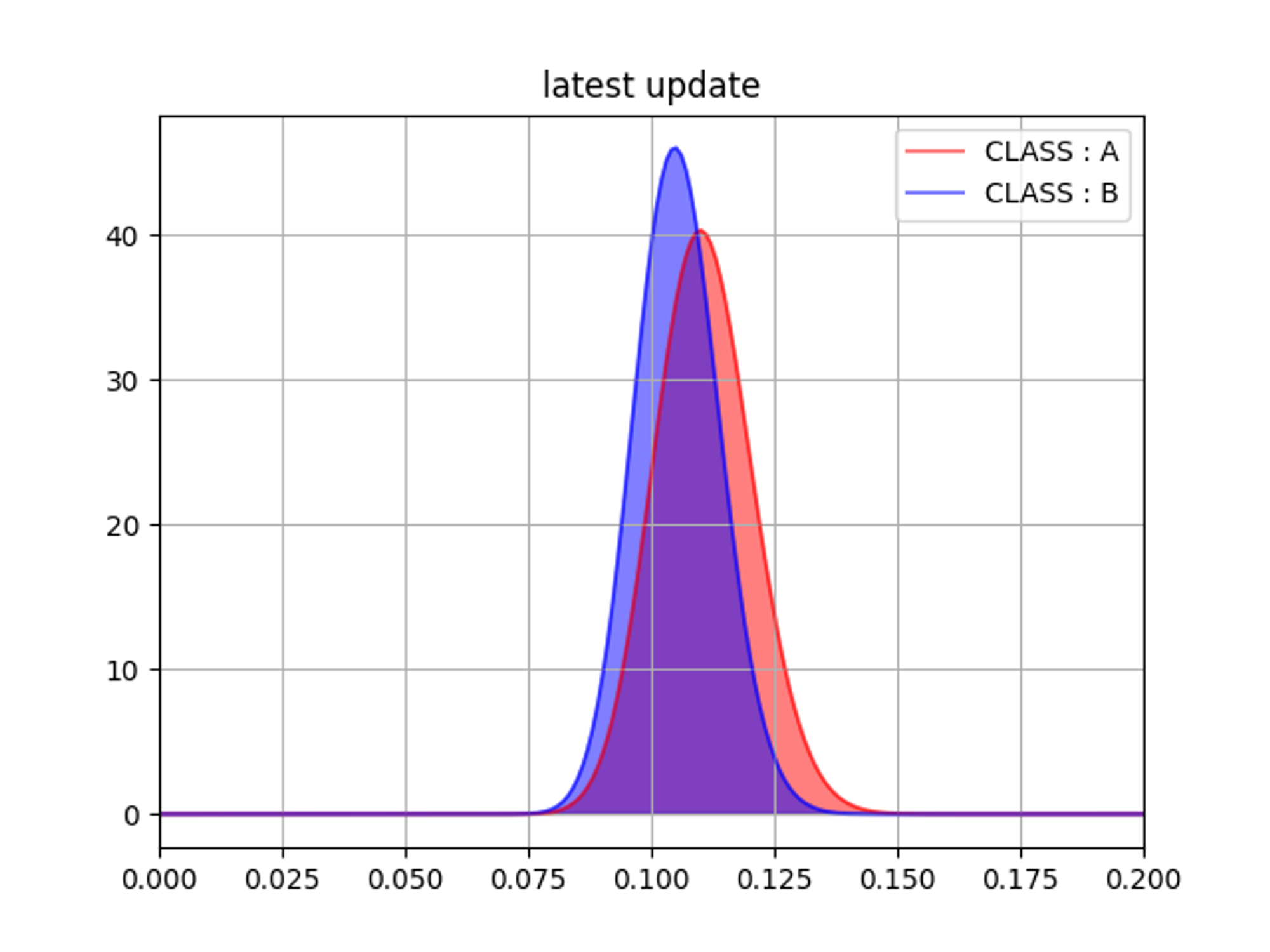
また、A/Bそれぞれの事後分布の平均値の差分を取ると A / B = 105% と A の施策の方が 5% ほど有効だというのが分かります。
## 全データを利用して A/Bそれぞれの事後分布を更新する
a_prior_alpha, a_prior_beta = update_dist(a.shape[0], a, alpha_a, beta_a)
b_prior_alpha, b_prior_beta = update_dist(b.shape[0], b, alpha_b, beta_b)
print('Class A = mean : {} , var : {}'.format(stats.beta(a_prior_alpha,a_prior_beta).mean(), stats.beta(a_prior_alpha,a_prior_beta).var()))
print('Class B = mean : {} , var : {}'.format(stats.beta(b_prior_alpha,b_prior_beta).mean(), stats.beta(b_prior_alpha,b_prior_beta).var()))
## A/B で得られた事後分布の平均値の比較
current_effect = stats.beta(a_prior_alpha,a_prior_beta).mean() / stats.beta(b_prior_alpha,b_prior_beta).mean()
print('Current Effect : {}%'.format(np.round(current_effect*100,2)))
>> Class A = mean : 0.11077844311377245 , var : 9.821194382359037e-05
>> Class B = mean : 0.10543130990415335 , var : 7.527178674864145e-05
>> Current Effect : 105.07%ここで、さらに A/Bそれぞれの事後分布を利用して上記の効果が発生する確率をみてみます。
A/Bそれぞれの事後分布から適当なサンプルを取得し、比較します。
※...[参考 : https://cdn2.hubspot.net/hubfs/310840/VWO_SmartStats_technical_whitepaper.pdf]
## A/B それぞれの事後分布からサンプルを5000件取得する
a_prior_samples = stats.beta(a_prior_alpha, a_prior_beta).rvs(5000)
b_prior_samples = stats.beta(b_prior_alpha, b_prior_beta).rvs(5000)
result = (a_prior_samples - b_prior_samples > 0).mean()
print('A vs B = {}%'.format(round(result * 100,2)))
>> A vs B = 65.18%今回の結果の解釈としては
- クラスA(介入群) と クラスB(コントロール群) では平均的に 5%ほど差が生まれている。
- クラスA(介入群) の方が クラスB(コントロール群) に比べて、コンバージョンしやすい確率が約65%
となります。
また、コンバージョンしやすい確率が65%なのですが、より有意な差を見たい場合は観察期間を伸ばしてあげる良いかもしれません。
試しに A/B それぞれのサンプルサイズを増やしてみると下記のような結果になります。
#!usr/env/bin py
#-*- coding : utf-8 -*-
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
import matplotlib.animation as animation
np.random.seed(1)
a = gen_data(0.11, 5000)
b = gen_data(0.10, 6000)
print('Class A = Target : {} Conversion : {} CVR : {:.3f}'.format(len(a), np.sum(a == 1), np.sum(a==1)/len(a)))
print('Class B = Target : {} Conversion : {} CVR : {:.3f}'.format(len(b), np.sum(b == 1), np.sum(b==1)/len(b)))
a_prior_alpha, a_prior_beta = update_dist(a.shape[0], a, alpha_a, beta_a)
b_prior_alpha, b_prior_beta = update_dist(b.shape[0], b, alpha_b, beta_b)
print('Class A = mean : {:.3f} , var : {:.5f}'.format(stats.beta(a_prior_alpha,a_prior_beta).mean(), stats.beta(a_prior_alpha,a_prior_beta).var()))
print('Class B = mean : {:.3f} , var : {:.5f}'.format(stats.beta(b_prior_alpha,b_prior_beta).mean(), stats.beta(b_prior_alpha,b_prior_beta).var()))
current_effect = stats.beta(a_prior_alpha,a_prior_beta).mean() / stats.beta(b_prior_alpha,b_prior_beta).mean()
print('Current Effect : {}%'.format(np.round(current_effect*100,2)))
a_prior_samples = stats.beta(a_prior_alpha, a_prior_beta).rvs(5000)
b_prior_samples = stats.beta(b_prior_alpha, b_prior_beta).rvs(5000)
result = (a_prior_samples - b_prior_samples > 0).mean()
print('A vs B = {}%'.format(round(result * 100,2)))
>> Class A = Target : 5000 Conversion : 530 CVR : 0.106
>> Class B = Target : 6000 Conversion : 570 CVR : 0.095
>> Class A = mean : 0.106 , var : 0.00002
>> Class B = mean : 0.095 , var : 0.00001
>> Current Effect : 111.59%
>> A vs B = 97.28%サンプルサイズを増やしてみると クラスA と クラスB では 11% ほど差が生まれており、その差が発生する確率が 97.28% まで上昇しました。
データ生成時の設定とほぼ同値になりましたね。
また、差が発生する確率が 97.28% ということは 有意水準 5% を超えており、この結果は統計的に有意だと言えることになります。
まとめ
以上 Bayesian Testing の簡単な紹介でした。
実際の ABテストの現場では、そもそもランダム化実験がちゃんとランダム化実験されているのか、から確認をしなければならず、仮にランダム化実験ではない場合、過少に(または過大に)効果の推定をしてしまうことも少なくありません。
そういった場合には同チームの島田が紹介しているように、統計的因果推論の枠組みを利用した効果量の推定が必要になってきます。今回の Bayesian Testing も面白いですが、統計的因果推論の考え方も非常に面白いのでご参考になったらと思います。
We're Hiring!
📢
MoT AI技術開発部分析グループではともに働くデータアナリストを募集しています!
興味のある方は 採用ページ も見ていただけると嬉しいです。
Twitter @mot_techtalk のフォローもよろしくお願いします!