

Apache Arrow の紹介
AIデータ基盤PythonパフォーマンスAugust 17, 2023
タクシーアプリ『GO』のデータエンジニアをしている牧瀬です。
Apache Arrow という OSS を知り、弊社でも活用できる機会があるのではないかと興味を持ちました。本記事では Apache Arrow の概要を紹介します。
概要
Apache Arrow とは、インメモリのカラムナーフォーマット仕様および、それを操作するための各種プログラミング言語用のライブラリ実装です。
Apache Arrow が作られた目的は、大きなデータセットを高速に処理したり、データセットを異なるシステムやプログラミング言語の間で効率的にやりとりするためです。
なぜインメモリ?
- 一般的なカラムナーフォーマットの多くはストレージに保存する際のフォーマットですが、Apache Arrow はインメモリの仕様も定められています。 これは 1台のマシン上で異なる言語やプロセスの間でデータをやり取りする際、シリアライゼーションやコピーを行わずに効率良くデータをやり取りできるようにするためです。 なお、インメモリではない場合の仕様(シリアライゼーションフォーマット)も定められています。
なぜカラムナーフォーマット?
- インメモリでデータを保持する際に、カラムナーフォーマットを用いる理由ですが、データセットの列方向に処理を行う場合、SIMD が利用できたり、CPUのキャッシュが効きやすく高速化が見込めるためです。
なぜ仕様を定めている?
- 仕様を標準化し、様々なシステムが Arrow という共通の形式を採用すれば、システム毎にデータ形式を変換しなくて済み、効率的にデータをやりとりできるためです。
Apache Arrow では様々なプログラミング言語用のライブラリが提供されています。
- ネイティブ実装: C++, C#, Go, Java, JavaScript, Julia, Rust
- C++実装のラッパー: C, MATLAB, Python, R, Ruby
💡
本記事では Apache Arrow バージョン 12.0 をベースに説明します。
Arrow の Pandas 2.0 への導入
Arrow のユースケースについて、具体的にイメージしづらいと思いますので、実例を紹介します。
Python 使いの方にはおなじみのデータ分析用ライブラリ Pandas ですが、Pandas 2.0 から、numpy の代わりに Apache Arrow の Python 向け実装である pyarrow をバックエンドに使えるようになりました。
dtype に [pyarrow] を後置することで pyarrow バックエンドが利用されます。
>>> pandas.Series([1, 2, 3, 4], dtype='int64[pyarrow]')
0 1
1 2
2 3
3 4
dtype: int64[pyarrow]特徴
pyarrow バックエンドでは以下のメリットがあります。
- NA (欠損値) を正しくかつメモリ効率良く扱える
- より多くのデータ型をサポート
- 速度向上
- 他ライブラリとの効率の良いデータ連携
順に説明します。
NA (欠損値) を正しくかつメモリ効率良く扱える
Pandas では欠損値の扱いにぎこちない部分がありました。dtype を明示しない場合、None を含む整数の配列が勝手に float64 になることにハマった方も多いのではないでしょうか。
# 欠損値があると numpy の float64 になり、欠損値は NaN になる
>>> pandas.Series([1, 2, None, 4])
0 1.0
1 2.0
2 NaN
3 4.0
dtype: float64dtype=Int64 (大文字 I)を指定すると欠損値を扱えます。ただ、その実装はややメモリ効率が悪いものでした。
# dtype=Int64 (大文字 I)にすると扱えるが、、内部的には要素数分のバイト配列を持っており NA 1要素あたり 1バイトで表現している
>>> pandas.Series([1, 2, None, 4], dtype='Int64')
0 1
1 2
2 <NA>
3 4
dtype: Int64一方 pyarrow バックエンドでは、常に欠損値を正しく扱えます。
>>> pandas.Series([1, 2, None, 4], dtype='int64[pyarrow]')
0 1
1 2
2 <NA>
3 4
dtype: int64[pyarrow]Arrow では内部的に要素数の 1/8 の長さのバイト配列を持っており、欠損値 1要素あたり 1ビットで表現しています(validity bitmap)。これにより、比較的メモリ効率が良いです。
欠損値がない時は validity bitmap を持たないようにもできます(Arrow ライブラリの実装による)。
Numpy backend より多くのデータ型をサポート
従来だと dtype=object になるようなケースでも専用の型を持っており、型ごとに最適化された実装になっているため、高速に計算が行えます。
>>> ss = pandas.Series(['foo', 'bar', 'foobar'], dtype='string[pyarrow]')
>>> ss
0 foo
1 bar
2 foobar
dtype: string
>>> ss.str.contains("a")
0 False
1 True
2 True
dtype: booleanpyarrow は以下のデータ型をサポートしています。

速度向上
Arrow の計算処理は SIMD などを活用するようチューニングされていて高速です。特に string など numpy で充分サポートされていないデータ型の場合に顕著な差があるようです。
こちらのブログにベンチマーク結果があります。
pandas 2.0 and the Arrow revolution (part I)
ただし、速度の面については pandas + pyarrow が常に最速というわけではないようです。
- numpy バックエンドの方が速いケースもある。pandas へのインテグレーションがまだ充分ではないためらしい
- 同じく Arrow をバックエンドに使っている Polars の方が速いという話: Pandas 2.0はPolarsよりも速いのか? - Qiita
- Polars は Arrow の使用以外にも色々高速化の工夫がなされています
他ライブラリとの効率の良いデータ連携
通常、ライブラリ間でデータを受け渡す場合、それぞれの内部形式に変換が必要なため、データのコピーと変換処理が発生します。
しかし、バックエンドに Arrow を使っているソフトウェア同士なら、コピーも変換も発生せず、単にメモリの共有によりデータの受け渡しを行うことができます。
例: Arrow を使えば、Pandas のデータを Polars にメモリ経由で渡せる (pandas 2.0 and the Arrow revolution (part I))
# Pandas しかサポートしていないファイル形式の読み書きに Pandas を使い、計算処理を Polars で行う
loaded_pandas_data = pandas.read_sas(fname)
# pandas のデータ(pyarrow)を polars に受け渡す。コピーや変換は発生しない
polars_data = polars.from_pandas(loaded_pandas_data)
# perform operations with pandas polars
# polars のデータを pandas に受け渡す。コピーや変換は発生しない
to_export_pandas_data = polars.to_pandas(use_pyarrow_extension_array=True)
to_export_pandas_data.to_latex()PyArrow の機能
ユースケースがわかったところで、Apache Arrow はライブラリとしてはどのような機能を持っているのでしょうか。Python 向け実装である pyarrow を例に見ていきます。
基本的なコンテナ型
pyarrow の提供する機能は概念的には pandas に似ています。テーブル状のデータセットや、カラムを表現する配列があります。具体的には、以下のコンテナ型があります。
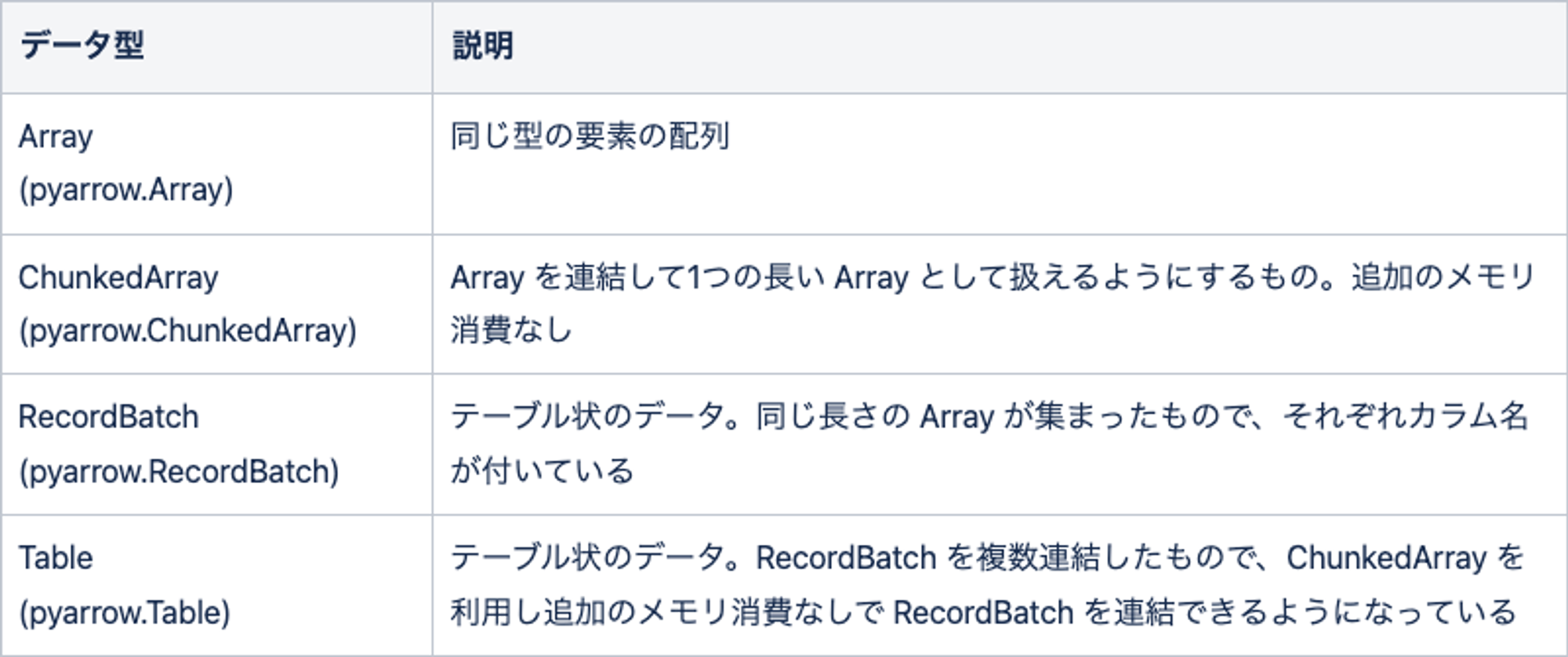
pandas で言えば Series にあたるものが Array/ChunkedArray、DataFrame にあたるものが RecordBatch/Table です。
各コンテナ型にはそれぞれ要素の型があり、指定できる要素の型は前節の表に示した通りです。
ChunkedArray などを見て気付いた方も居るかもしれませんが、これらのコンテナ型は immutable(不変) となっています。immutable なデータ型には以下の特徴があります。
- メモリ上に1つだけインスタンスを作って参照だけ持ち回せば良いので、コピーする必要がなくCPU・メモリ効率が良い
- 並列処理において複数スレッドから同じインスタンスを参照しても競合が起きない
- 参照回数 >>> 更新回数 となる 分析処理(OLAP)向き
- 逆に更新が多い処理にはあまり向いていない
File I/O
Arrow のデータをファイルに対して読み書きするためのメソッドが数多く提供されています。
汎用的なフォーマットに対応しているほか、Arrow 独自のフォーマットも提供されています。独自フォーマットの場合、memory mapped file を利用することで、さらに効率の良い読み書きや、巨大なファイルの読み書きが可能になります。
汎用的なフォーマット
Parquet, ORC, CSV, JSON 等々の読み書きができ、それらの処理は高度にチューニングされています。マルチスレッド読み込みなどもサポートされています。
import pyarrow as pa
import pyarrow.parquet as pq
# Parquet 書き込み
arr = pa.array(np.arange(100)) # => 0 .. 99
table = pa.Table.from_arrays([arr], names=["col1"])
pq.write_table(table, "example.parquet", compression=None)# Parquet 読み出し
table = pq.read_table("example.parquet")独自フォーマット(Arrow IPC Format)
Arrow 独自のシリアライゼーションフォーマット(Arrow IPC format)が用意されています。この形式の特徴は、データに関してはメモリ上のレイアウトと同一の形でシリアライズされることです。そのため、変換処理が不要となり、高速にファイル読み書きができます。
# Arrow IPC 書き込み
arr = pa.array(np.arange(100)) # => 0 .. 99
schema = pa.schema([
pa.field('nums', arr.type)
])
with pa.OSFile('arraydata.arrow', 'wb') as sink:
with pa.ipc.new_file(sink, schema=schema) as writer:
batch = pa.record_batch([arr], schema=schema)
writer.write(batch)Memory Mapped File
さらに、下の例のように、memory mapped file を利用してファイルを読み込むことができます。こうすることで、メモリに乗り切らないような巨大なファイルを扱うことができます。
# メモリマップしながら Arrow IPC 読み込み
with pa.memory_map('arraydata.arrow', 'r') as source:
loaded_arrays = pa.ipc.open_file(source).read_all()memory mapped file 自体は、先に説明した汎用ファイルフォーマットにも適用可能ですが、ファイルの先頭から順に読まなければいけないようなフォーマット(たとえばCSV)だと、メリットを生かしきれません。その点 Arrow IPC format であればファイルの途中から読むことができる形式であるため、memory mapped file との相性が良いです。
💡
memory mapped file とは:
OSの仮想記憶の仕組みを利用し、ファイルをメモリ上に直接読み込む方法。
システムコールやメモリコピーのオーバーヘッドを避けられるので高速。
また、メモリ上のアクセスした箇所だけファイルが読み込まれるので、メモリに載らないような巨大なファイルも読み込むことができる
高速なデータ操作
集計や数値演算、比較、文字列処理、日時処理、検索、ソート、グループ化など、ひととおりの機能は用意されています。またそれぞれのメソッドは SIMD などを活用してチューニングされています。
直接利用する機会は少ないと思うので、詳細はリンク先を参照ください。
Data Manipulation — Apache Arrow Python Cookbook documentation
Compute Functions — Apache Arrow
Arrow の仕様をチラ見する
Arrow の機能について見てきましたが、カラムナーフォーマット仕様であるという側面も気になるので、見ていきましょう。仕様についてはドキュメントに記載されています。
Arrow Columnar Format — Apache Arrow
インメモリのカラムナーフォーマット仕様
Int32 配列の例
Int32 Array [1, null, 2, 4, 8] を例に、メモリ上のフォーマットを見ていきましょう。
前提として、Arrow のデータはデータ本体とメタデータに分かれます。仕様でフォーマットが決まっているのはデータ本体のみで、メタデータは Arrow ライブラリが自身の実装に都合の良い形で持ちます。データ本体とは、下図の値バッファや Validity bitmap バッファが該当します。メタデータは配列要素の型、要素数、欠損値の個数、等です。
* 要素数: 5, 欠損値の個数: 1
* Validity bitmap バッファ:
|Byte 0 (validity bitmap) | Bytes 1-63 |
|-------------------------|-----------------------|
| 00011101 | 0 (padding) |
* 値バッファ:
|Bytes 0-3 | Bytes 4-7 | Bytes 8-11 | Bytes 12-15 | Bytes 16-19 | Bytes 20-63 |
|------------|-------------|-------------|-------------|-------------|-------------|
| 1 | unspecified | 2 | 4 | 8 | unspecified |上図で、Int32 配列の要素値は値バッファに格納されます。Int32 なので 4バイト単位にパックされます。欠損値の場合は、内容は問われません。
また、欠損値を表すために Validity bitmap バッファが使われます。これは各ビットが対応する配列要素の有無を表しています。1 が要素がある、0 が欠損を表します。LSB first、つまり低位のビットが配列の若い番号に対応します。
メモリ配置
ここで面白いのが、値バッファや Validity bitmap バッファはメモリ上の配置が規定されていることです。具体的には、8 バイト又は 64 バイト境界に配置(alignment)し、サイズを 8 バイト又は 64 バイトの倍数にする(padding)ことが推奨されています。
理由:
- 64ビットCPU においては、8バイト境界にあるデータの方が高速にアクセスできるため
- SIMD(Intel AVX-512 など) を活用する場合、64バイト境界にあるデータの方が高速にアクセスできるため
String 配列の例
次に String Array ["joe", null, null, "mark"] の例です。各要素が可変長の文字列の場合、どのようにレイアウトされるのでしょうか。
* 要素数: 4, 欠損値の個数: 2
* Validity bitmap バッファ:
| Byte 0 (validity bitmap) | Bytes 1-63 |
|--------------------------|-----------------------|
| 00001001 | 0 (padding) |
* オフセットバッファ (int32)
| Bytes 0-3 | Bytes 4-7 | Bytes 8-11 | Bytes 12-15 | Bytes 16-19 | Bytes 20-63 |
|------------|-------------|-------------|-------------|-------------|-------------|
| 0 | 3 | 3 | 3 | 7 | unspecified |
* 値配列:
* 要素数: 7, 欠損値の個数: 0
* Validity bitmap バッファ: Not required
* 値バッファ:
| Bytes 0-6 |
|----------------|
| joemark |String 配列の場合、まず、全ての文字列の内容を結合した文字列が値バッファに格納されます。そしてオフセットバッファというものが新たに追加されています。オフセットバッファは、配列のn番目の要素が値バッファ内のどこから始まるか、という情報を保持しており、n と n+1 番目を見ることで範囲がわかります。例えば、配列の 0 番目の要素はオフセットが 0 から始まり 3 で終わるので “joe”、配列の 3 番目の要素はオフセットが 3 から始まり 7 で終わるので “mark”、といった形です。
以上、基礎的な例を2つ見てきました。より複雑なデータ型もありますが、原則は同じで、同じ型(カラム)ごとに1次元の配列、すなわちメモリ上の連続した領域に配置するようになっています。
Arrow IPC (シリアライゼーションフォーマット) 仕様
Arrow データをファイル読み書きやネットワークを通じてやりとりするためのシリアライゼーションフォーマットについても軽く触れておきます。
簡単に言うと、メタデータは FlatBuffers 形式でシリアライズし、データ本体はメモリ上のフォーマットと同じ形式で書き出しています。
FlatBuffers は Google 製のシリアライズフォーマットで、Protocol Buffers に似てスキーマをコンパイルして利用する形のものです。
小ネタ
最後に、小ネタをいくつか紹介します。
Arrow は Pandas の原作者が作った
Apache Arrow and the "10 Things I Hate About pandas"
日本語訳: (翻訳)Apache Arrowと「pandasの10項目の課題」 - Qiita
今では Pandas の開発にはたくさんの OSS 開発者が関わっていますが、原作者は Wes McKinney という方です。この方が Pandas での経験や、データエンジニアとして Cloudera などビッグデータ系の色々な会社で経験してきた課題から Arrow を開発した、という経緯が上の記事に書かれています。面白いので、一読をお勧めします。
内製マップマッチエンジンに Arrow を採用できるかも?
弊社内製のマップマッチエンジン(生のGPSデータの誤差を補正して道路上の位置を推定し、経路情報を得るエンジン)は、全国分の地図データを保持するのに独自のファイル形式を採用しています。地図のグラフ構造を numpy の ndarray で持ち、numpy の memmap() を使うことで全国分の巨大なファイルの必要な所だけを短時間で読み込めるようにしています。
詳しい説明: オートモーティブの大規模データ処理を支える技術 後編: 大規模地図データ構造の最適化 | BLOG - DeNA Engineering
これは Arrow IPC format でやっていることに近いです。Arrow に興味を持ったのも、これがきっかけでした。
現状は独自フォーマットを採用していますが、Arrow を採用すると色々メリットがありそうです。
- メタデータのシリアライズも含めて高速化できるかも
- Apache Arrow 用の各種ツールが使えるなど、standardに沿うことによるメリット
- カラムを増やすなどの拡張がしやすくなるかも
まとめ
Apache Arrow の概要について紹介しました。Apache Arrow はまとまった日本語の資料が少なく、概要が掴みづらいと個人的に感じていたので、この記事が読者の皆さんの参考になれば幸いです。
参考文献
- Apache Arrow — Apache Arrow v12.0.0 : 公式サイト
- PyArrow Functionality — pandas 2.0.2 documentation
- pandas 2.0 and the Arrow revolution (part I)
- Apache Arrow Python Cookbook — Apache Arrow Python Cookbook documentation
- Apache Arrow and the "10 Things I Hate About pandas"
- (翻訳)Apache Arrowと「pandasの10項目の課題」 - Qiita
- Python: Pandas 2 系ではデータ型のバックエンドを変更できる - CUBE SUGAR CONTAINER
We're Hiring!
📢
GO株式会社ではともに働くエンジニアを募集しています。
興味のある方は 採用ページ も見ていただけると嬉しいです。
Twitter @goinc_techtalk のフォローもよろしくお願いします!